1.?KNN算法-分類
1.1?樣本距離判斷
? ? ? ??明可夫斯基距離:歐式距離,明可夫斯基距離的特殊情況;曼哈頓距離,明可夫斯基距離的特殊情況。
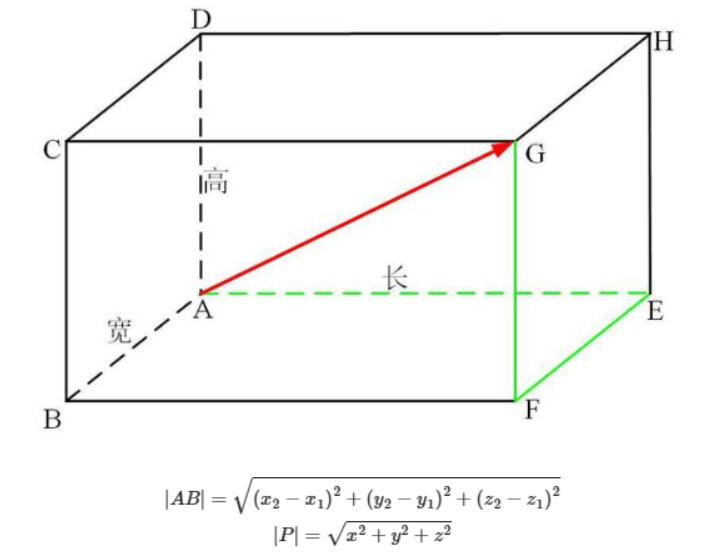
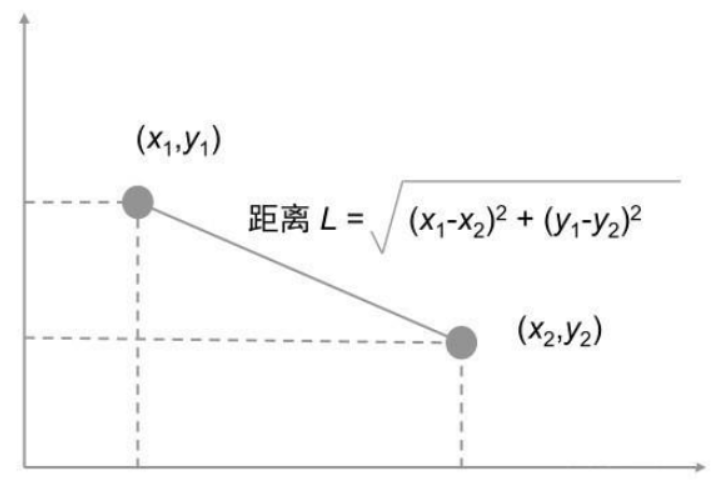
????????兩個樣本的距離公式可以通過如下公式進行計算,又稱為歐式距離。
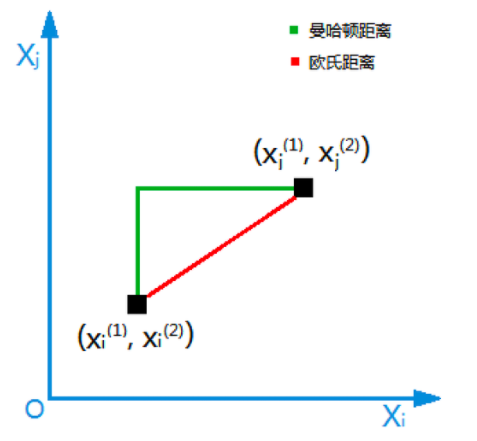
????????(1)歐式距離:
? ? ? ? (2)曼哈頓距離:
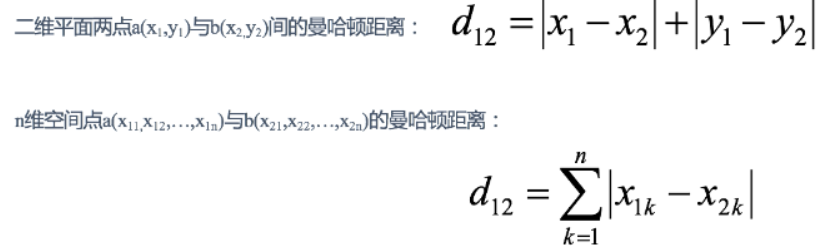
1.2?KNN 算法原理
????????K-近鄰算法(K-Nearest Neighbors,簡稱KNN),根據K個鄰居樣本的類別來判斷當前樣本的類別;如果一個樣本在特征空間中的k個最相似(最鄰近)樣本中的大多數屬于某個類別,則該類本也屬于這個類別,比如: 有10000個樣本,選出7個到樣本A的距離最近的,然后這7個樣本中假設:類別1有2個,類別2有3個,類別3有2個,那么就認為A樣本屬于類別2,因為它的7個鄰居中類別2最多(近朱者赤近墨者黑)。
? ? ? ? 示例:
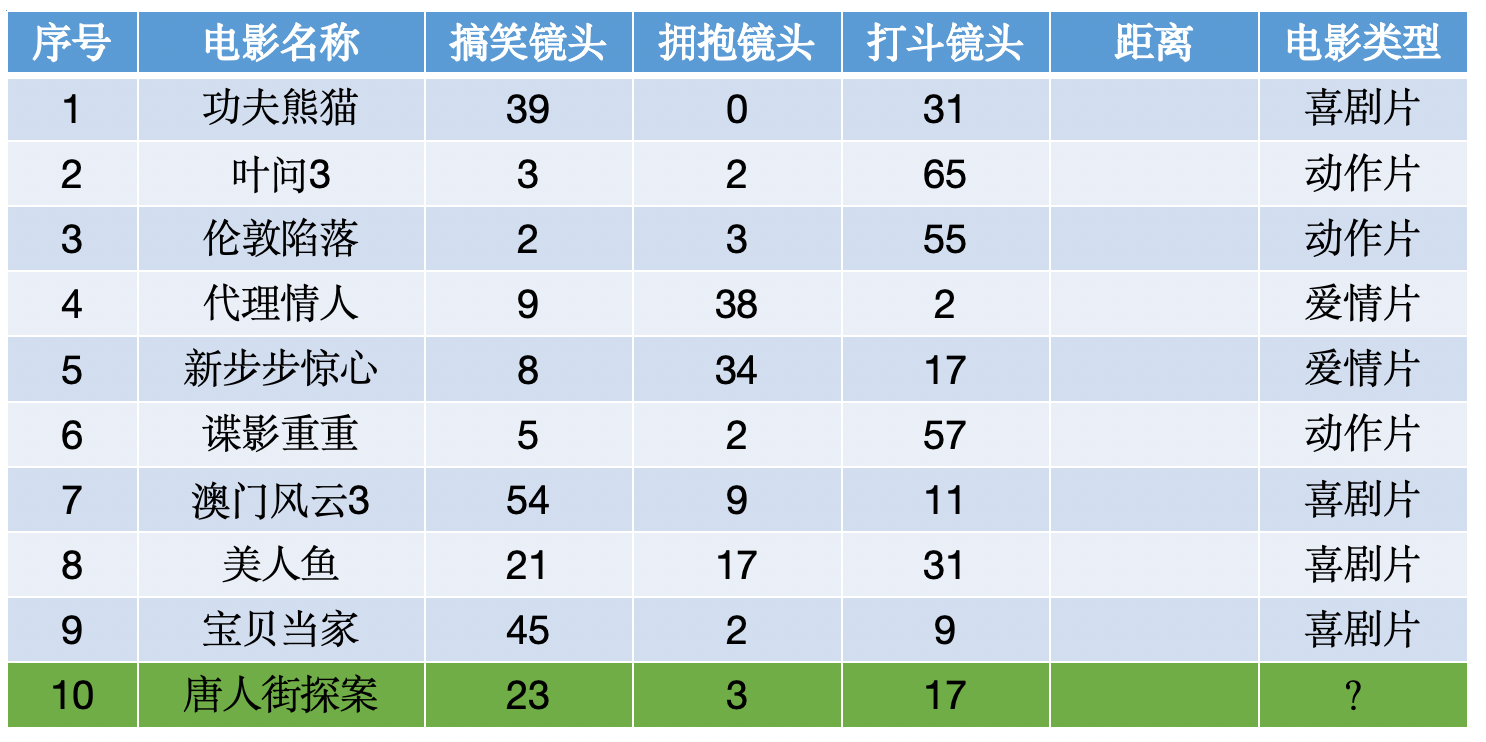
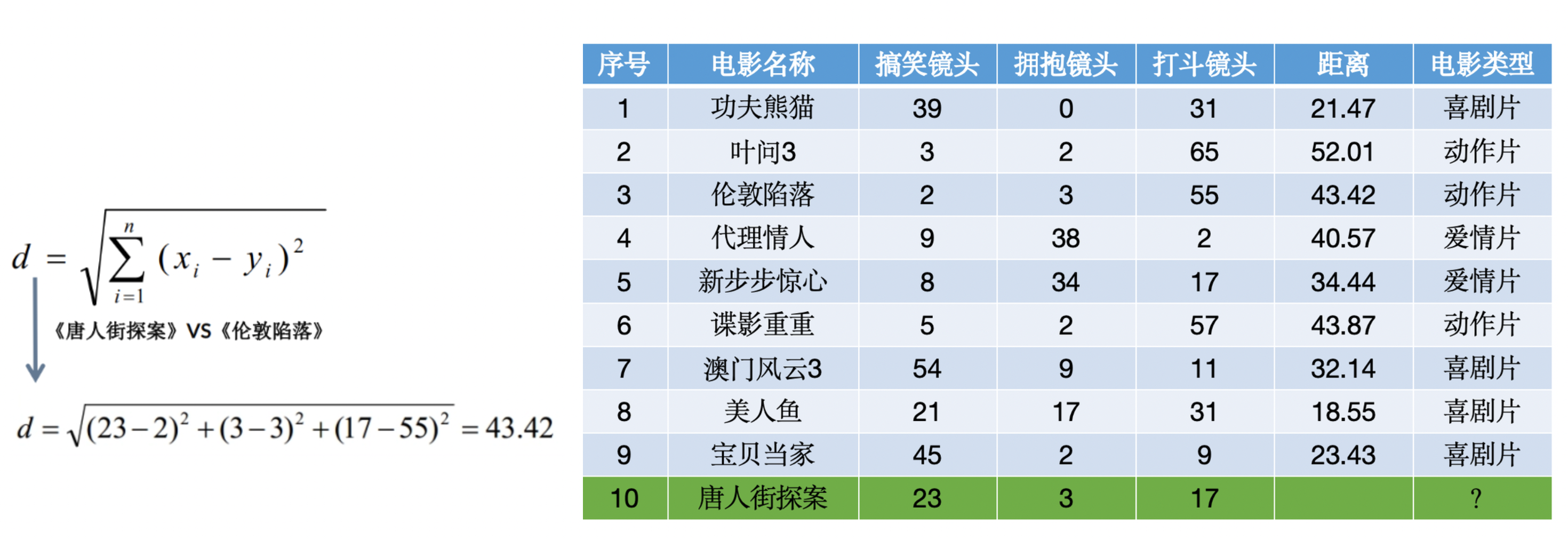
????????使用KNN算法預測《唐人街探案》電影屬于哪種類型?分別計算每個電影和預測電影的距離然后求解:
1.3?KNN缺點
????????對于大規模數據集,計算量大,因為需要計算測試樣本與所有訓練樣本的距離。對于高維數據,距離度量可能變得不那么有意義,這就是所謂的“維度災難”需要選擇合適的k值和距離度量,這可能需要一些實驗和調整。
1.4 API 介紹
????????class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, algorithm='auto')
????????參數: ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
????????(1)n_neighbors:?
?? ??? ?????????int, default=5,默認情況下用于kneighbors查詢的近鄰數,就是K。
????????(2)algorithm:
????????????????{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, default=’auto’。找到近鄰的方式,注意不是計算距離的方式,與機器學習算法沒有什么關系,開發中請使用默認值'auto'。
????????方法:
????????????????(1) fit(x,y) :使用X作為訓練數據和y作為目標數據。
????????????????(2) predict(x):預測提供的數據,得到預測數據。
? ? ? ? 示例:
# 用KNN算法對鳶尾花進行分類
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier# 1)獲取數據
iris = load_iris()# 只有4個特征, 150個樣本
print(iris.data.shape) # (150,4)
# 4個特征的描述 ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
print(iris.feature_names)# 150個目標,對應150個樣本的類別
print(iris.target.shape) # (150,)
# 目標值只有0 1 2這三種值,說明150個樣本屬于三類中的其中一種
print(iris.target) # [0 0 0...1 1 1 ...2 2 2]
# 目標值三種值代表的三種類型的描述。
print(iris.target_names) # ['setosa' 'versicolor' 'virginica']# 2)劃分數據集# x_train訓練特征,y_train訓練目標, x_test測試特征,y_test測試目標
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# print(x_train.shape, x_test.shape, y_train.shape, y_test.shape) #(112, 4) (38, 4) (112,) (38,)# 3)特征工程:標準化, 只有4個特征
transfer = StandardScaler()
# 對訓練特征做標準化, 對測試特征做相同的標準化,因為fit_transform中已經有fit進行計算了,所以對x_test只需要做transform了
# 訓練用的什么數據,模式就只能識別什么樣的數據。
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)# 4)KNN算法預估器, k=7表示找7個鄰近來判斷自身類型.
estimator = KNeighborsClassifier(n_neighbors=7)
estimator.fit(x_train, y_train) # 該步驟就是estimator根據訓練特征和訓練目標在自己學習,讓它自己變聰敏
# 5)模型評估 測試一下聰敏的estimator能力
# 方法1:直接比對真實值和預測值,
y_predict = estimator.predict(x_test) # y_predict預測的目標結果
print("y_predict:\n", y_predict)
print("直接比對真實值和預測值:\n", y_test == y_predict)# 方法2:計算準確率,
score = estimator.score(x_test, y_test)
print("準確率為:\n", score) # 0.9473684210526315????????模型保存與加載:
import joblib
# 保存模型
joblib.dump(estimator, "my_ridge.pkl")
# 加載模型
estimator = joblib.load("my_ridge.pkl")
#使用模型預測
y_test=estimator.predict([[0.4,0.2,0.4,0.7]])
print(y_test)2.?模型選擇與調優
2.1?交叉驗證
2.1.1?保留交叉驗證HoldOut
????????HoldOut Cross-validation(Train-Test Split)在這種交叉驗證技術中,整個數據集被隨機地劃分為訓練集和驗證集。根據經驗法則,整個數據集的近70%被用作訓練集,其余30%被用作驗證集。也就是我們最常使用的,直接劃分數據集的方法。
????????優點:很簡單很容易執行。
????????缺點:不適用于不平衡的數據集。假設我們有一個不平衡的數據集,有0類和1類。假設80%的數據屬于 “0 “類,其余20%的數據屬于 “1 “類。這種情況下,訓練集的大小為80%,測試數據的大小為數據集的20%。可能發生的情況是,所有80%的 “0 “類數據都在訓練集中,而所有 “1 “類數據都在測試集中。因此,我們的模型將不能很好地概括我們的測試數據,因為它之前沒有見過 “1 “類的數據;一大塊數據被剝奪了訓練模型的機會。
????????在小數據集的情況下,有一部分數據將被保留下來用于測試模型,這些數據可能具有重要的特征,而我們的模型可能會因為沒有在這些數據上進行訓練而錯過。
2.1.2?K-折交叉驗證(K-fold)
????????(K-fold Cross Validation,記為K-CV或K-fold):K-Fold交叉驗證技術中,整個數據集被劃分為K個大小相同的部分。每個分區被稱為 一個”Fold”。所以我們有K個部分,我們稱之為K-Fold。一個Fold被用作驗證集,其余的K-1個Fold被用作訓練集。
????????該技術重復K次,直到每個Fold都被用作驗證集,其余的作為訓練集,模型的最終準確度是通過取k個模型驗證數據的平均準確度來計算的。

2.1.3?分層k-折交叉驗證Stratified k-fold
????????Stratified k-fold cross validation:K-折交叉驗證的變種, 分層的意思是說在每一折中都保持著原始數據中各個類別的比例關系,比如說:原始數據有3類,比例為1:2:1,采用3折分層交叉驗證,那么劃分的3折中,每一折中的數據類別保持著1:2:1的比例,這樣的驗證結果更加可信。
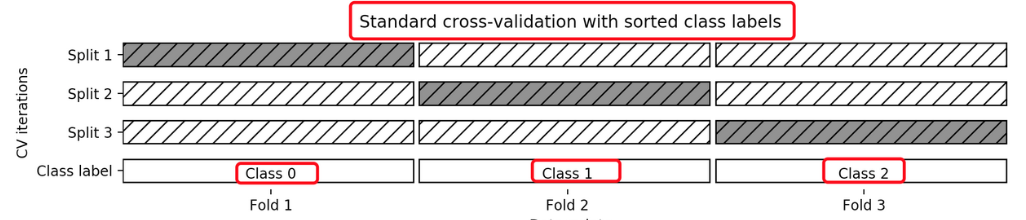
2.1.4 API 介紹
????????from sklearn.model_selection import StratifiedKFold:普通K折交叉驗證和分層K折交叉驗證的使用是一樣的 只是引入的類不同。
????????from sklearn.model_selection import KFold:使用時只是KFold這個類名不一樣其他代碼完全一樣。
????????strat_k_fold=sklearn.model_selection.StratifiedKFold(n_splits=5, shuffle=True, random_state=42):n_splits劃分為幾個折疊,shuffle是否在拆分之前被打亂(隨機化),False則按照順序拆分,random_state隨機因子
????????indexs=strat_k_fold.split(X,y):返回一個可迭代對象,一共有5個折疊,每個折疊對應的是訓練集和測試集的下標,然后可以用for循環取出每一個折疊對應的X和y下標來訪問到對應的測試數據集和訓練數據集 以及測試目標集和訓練目標集。
????????for train_index, test_index in indexs:
????????????????X[train_index],y[train_index],X[test_index ],y[test_index ]
? ? ? ? 示例:
from sklearn.datasets import load_iris
from sklearn.model_selection import StratifiedKFold
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler# 加載數據
iris = load_iris()
X = iris.data
y = iris.target# 初始化分層k-折交叉驗證器
#n_splits劃分為幾個折疊
#shuffle是否在拆分之前被打亂(隨機化),False則按照順序拆分
#random_state隨機因子
strat_k_fold = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)# 創建一個K近鄰分類器實例
knn = KNeighborsClassifier(n_neighbors=7)# 進行交叉驗證
accuracies = []
for train_index, test_index in strat_k_fold.split(X, y):print(train_index, test_index)X_train, X_test = X[train_index], X[test_index]y_train, y_test = y[train_index], y[test_index]# 數據預處理(標準化)scaler = StandardScaler()X_train_scaled = scaler.fit_transform(X_train)X_test_scaled = scaler.transform(X_test)# 使用K近鄰分類器進行訓練knn.fit(X_train_scaled, y_train)# 輸出每次折疊的準確性得分score = knn.score(X_test_scaled ,y_test)print(score)accuracies.append(score)#把分數添加到外面列表中
print(sum(accuracies)/len(accuracies))#平均得分#使用StratifiedKFold來創建5個折疊,每個折疊中鳶尾花數據集的類別分布與整體數據集的分布一致。然后我們對每個折疊進行了訓練和測試,計算了分類器的準確性。2.2?超參數搜索
????????超參數搜索也叫網格搜索(Grid Search),比如在KNN算法中,n_neighbors是一個可以人為設置的參數,所以就是一個超參數。網格搜索能自動的幫助我們找到最好的超參數值。
2.2.1 API?介紹
????????class sklearn.model_selection.GridSearchCV(estimator, param_grid)
????????說明:
????????同時進行交叉驗證(CV)、和網格搜索(GridSearch),GridSearchCV實際上也是一個估計器(estimator),同時它有幾個重要屬性:
? ? ????????? best_params_ ?最佳參數
? ? ? ????????best_score_ 在訓練集中的準確率
? ? ? ????????best_estimator_ 最佳估計器
? ? ? ????????cv_results_ 交叉驗證過程描述
? ? ? ????????best_index_最佳k在列表中的下標
????????參數:
?? ?????????estimator: scikit-learn估計器實例
?? ?????????param_grid:以參數名稱(str)作為鍵,將參數設置列表嘗試作為值的字典
?? ??? ?????????示例: {"n_neighbors": [1, 3, 5, 7, 9, 11]}
? ????????? cv: 確定交叉驗證切分策略,值為:
? ? ? ????????? (1)None ?默認5折
? ? ? ????????? (2)integer ?設置多少折
? ? ? ????????? 如果估計器是分類器,使用"分層k-折交叉驗證(StratifiedKFold)"。在所有其他情況下,使用KFold。
? ? ? ? 示例:
# 用KNN算法對鳶尾花進行分類,添加網格搜索和交叉驗證
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCVdef knn_iris_gscv():# 1)獲取數據iris = load_iris()# 2)劃分數據集x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)# 3)特征工程:標準化transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test)# 4)KNN算法預估器, 這里就不傳參數n_neighbors了,交給GridSearchCV來傳遞estimator = KNeighborsClassifier()# 加入網格搜索與交叉驗證, GridSearchCV會讓k分別等于1,2,5,7,9,11進行網格搜索償試。cv=10表示進行10次交叉驗證estimator = GridSearchCV(estimator, param_grid={"n_neighbors": [1, 3, 5, 7, 9, 11]}, cv=10)estimator.fit(x_train, y_train)# 5)模型評估# 方法1:直接比對真實值和預測值y_predict = estimator.predict(x_test)print("y_predict:\n", y_predict)print("直接比對真實值和預測值:\n", y_test == y_predict)# 方法2:計算準確率score = estimator.score(x_test, y_test)print("在測試集中的準確率為:\n", score) #0.9736842105263158# 最佳參數:best_params_print("最佳參數:\n", estimator.best_params_) #{'n_neighbors': 3}, 說明k=3時最好# 最佳結果:best_score_print("在訓練集中的準確率:\n", estimator.best_score_) #0.9553030303030303# 最佳估計器:best_estimator_print("最佳估計器:\n", estimator.best_estimator_) # KNeighborsClassifier(n_neighbors=3)# 交叉驗證結果:cv_results_print("交叉驗證過程描述:\n", estimator.cv_results_)#最佳參數組合的索引:最佳k在列表中的下標print("最佳參數組合的索引:\n",estimator.best_index_)#通常情況下,直接使用best_params_更為方便return Noneknn_iris_gscv()3.?樸素貝葉斯分類
3.1 貝葉斯分類理論
????????假設現在我們有一個數據集,它由兩類數據組成,數據分布如下圖所示:
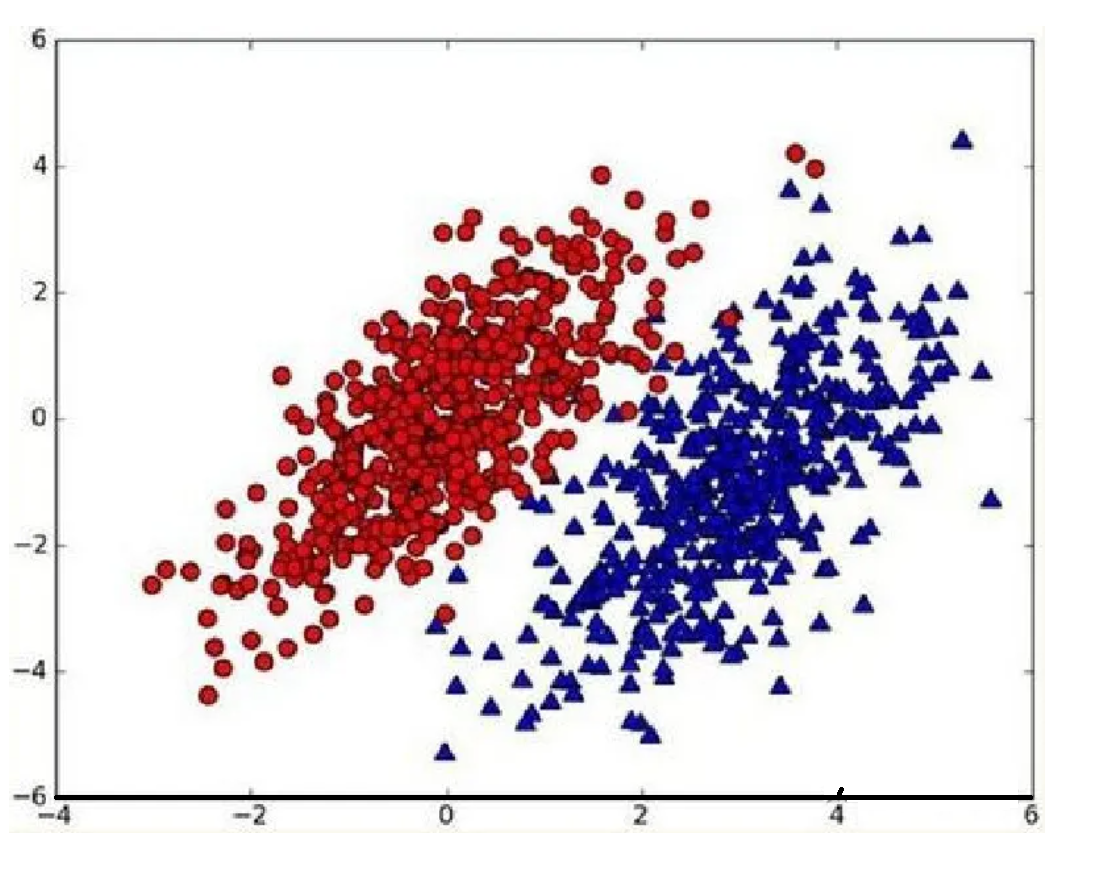
????????我們現在用p1(x,y)表示數據點(x,y)屬于類別1(圖中紅色圓點表示的類別)的概率,用p2(x,y)表示數據點(x,y)屬于類別2(圖中藍色三角形表示的類別)的概率,那么對于一個新數據點(x,y),可以用下面的規則來判斷它的類別:
????????- 如果p1(x,y)>p2(x,y),那么類別為1;
????????- 如果p1(x,y)<p2(x,y),那么類別為2。
????????也就是說,我們會選擇高概率對應的類別。這就是貝葉斯決策理論的核心思想,即選擇具有最高概率的決策。已經了解了貝葉斯決策理論的核心思想,那么接下來,就是學習如何計算p1和p2概率。
3.2?條件概率
????????在學習計算p1 和p2概率之前,我們需要了解什么是條件概率(Conditional probability),就是指在事件B發生的情況下,事件A發生的概率,用P(A|B)來表示。
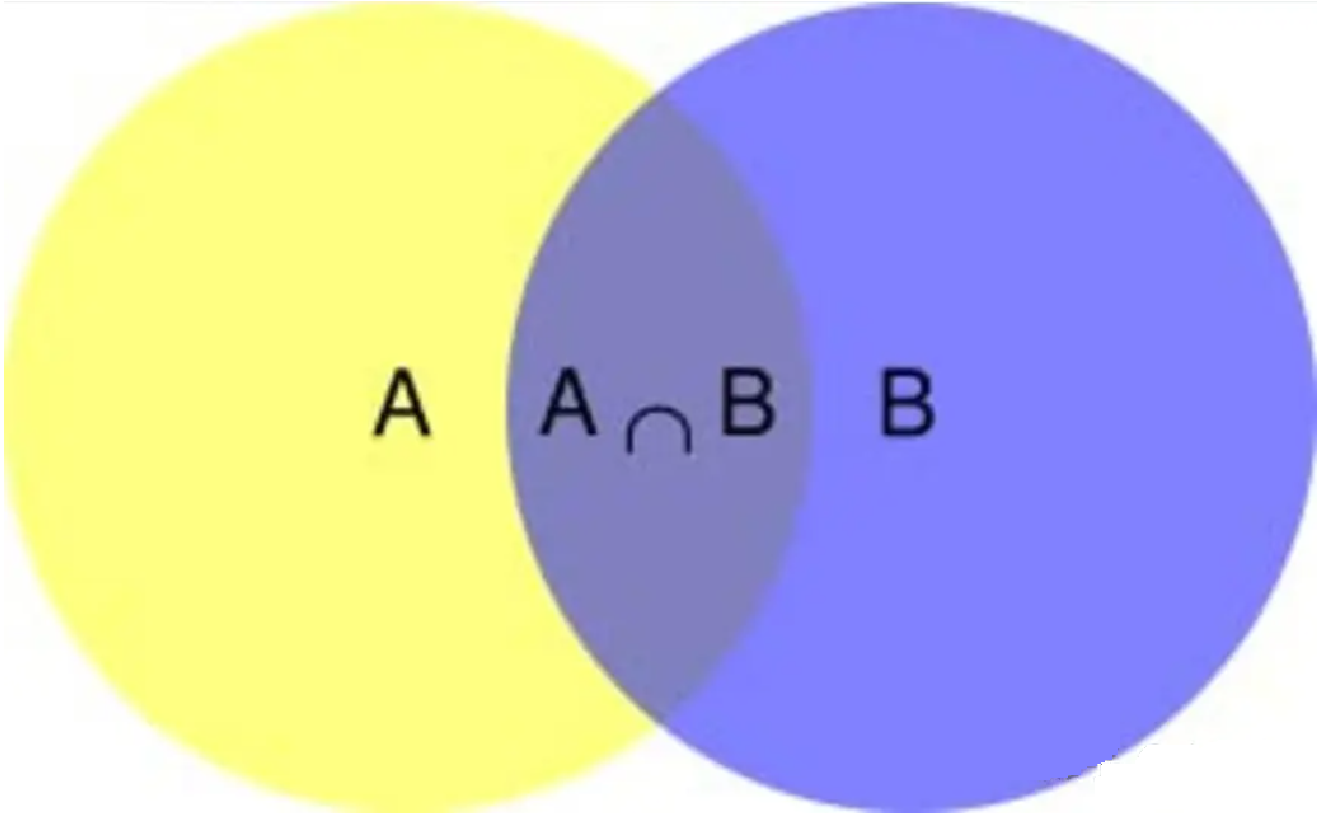
????????根據文氏圖,可以很清楚地看到在事件B發生的情況下,事件A發生的概率就是P(A∩B)除以P(B)。
????????𝑃(𝐴|𝐵)=𝑃(𝐴∩𝐵)/𝑃(𝐵),因此:𝑃(𝐴∩𝐵)=𝑃(𝐴|𝐵)*𝑃(𝐵),
????????同理可得:
????????𝑃(𝐴∩𝐵)=𝑃(𝐵|𝐴)*𝑃(𝐴),
????????即:
????????𝑃(𝐴|𝐵)=𝑃(B|A)*𝑃(𝐴)/𝑃(𝐵)
????????這就是條件概率的計算公式。
3.3?全概率公式
????????除了條件概率以外,在計算p1和p2的時候,還要用到全概率公式,因此,這里繼續推導全概率公式。假定樣本空間S,是兩個事件A與A'的和。
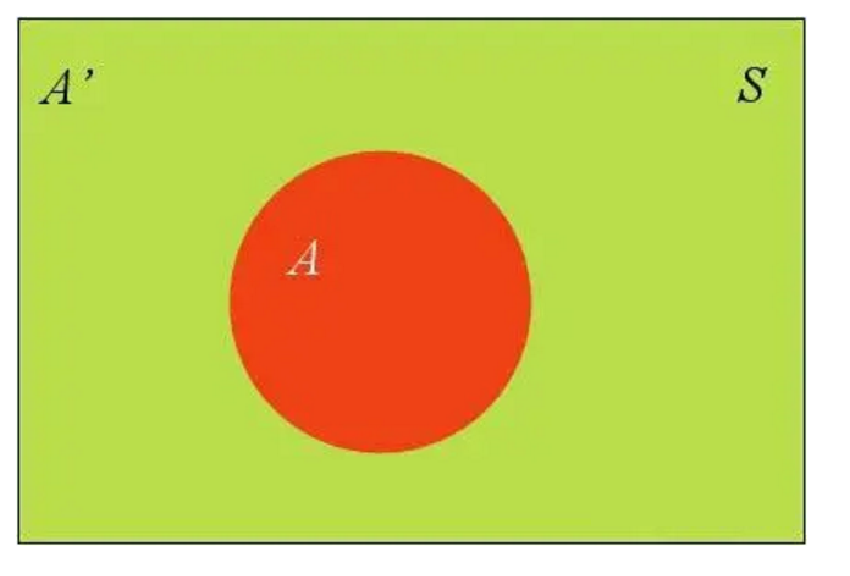
????????上圖中,紅色部分是事件A,綠色部分是事件A',它們共同構成了樣本空間S。在這種情況下,事件B可以劃分成兩個部分。
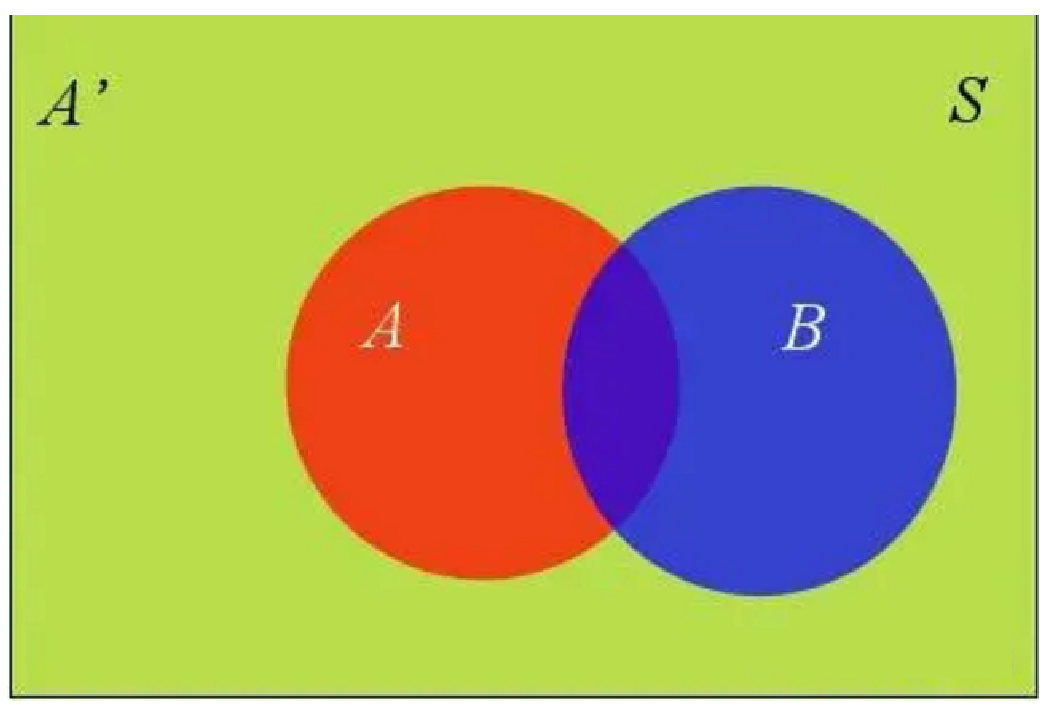
????????即:𝑃(𝐵)=𝑃(𝐵∩𝐴)+𝑃(𝐵∩𝐴′),
????????在上面的推導當中,我們已知:𝑃(𝐵∩𝐴)=𝑃(𝐵|𝐴)𝑃(𝐴),
????????所以:𝑃(𝐵)=𝑃(𝐵|𝐴)𝑃(𝐴)+𝑃(𝐵|𝐴′)𝑃(𝐴′),
????????這就是全概率公式。它的含義是,如果A和A'構成樣本空間的一個劃分,那么事件B的概率,就等于A和A'的概率分別乘以B對這兩個事件的條件概率之和。
????????將這個公式代入上一節的條件概率公式,就得到了條件概率的另一種寫法:
????????????????????????????????
3.4?貝葉斯推斷
????????對條件概率公式進行變形,可以得到如下形式:
![]()
????????我們把P(A)稱為"先驗概率"(Prior probability),即在B事件發生之前,我們對A事件概率的一個判斷。
????????P(A|B)稱為"后驗概率"(Posterior probability),即在B事件發生之后,我們對A事件概率的重新評估。
????????P(B|A)/P(B)稱為"可能性函數"(Likelyhood),這是一個調整因子,使得預估概率更接近真實概率。
????????所以,條件概率可以理解成的式子:后驗概率 = 先驗概率x調整因子
????????這就是貝葉斯推斷的含義。我們先預估一個"先驗概率",然后加入實驗結果,看這個實驗到底是增強還是削弱了"先驗概率",由此得到更接近事實的"后驗概率"。
3.5?樸素貝葉斯推斷
????????理解了貝葉斯推斷,那么讓我們繼續看看樸素貝葉斯。貝葉斯和樸素貝葉斯的概念是不同的,區別就在于“樸素”二字,樸素貝葉斯對條件概率分布做了**條件獨立**性的假設。 比如下面的公式,假設有n個特征:
????????根據貝葉斯定理,后驗概率 P(a|X) ?可以表示為:
????????????????????????????????????????????????
???其中:
-
P(X|a) 是給定類別 ( a ) 下觀測到特征向量 X=(x_1, x_2, ..., x_n) 的概率;
-
P(a) 是類別 a 的先驗概率;
-
P(X) 是觀測到特征向量 X 的邊緣概率,通常作為歸一化常數處理。
????????樸素貝葉斯分類器的關鍵假設是特征之間的條件獨立性,即給定類別 a ,特征和
(其中
相互獨立。)
????????因此,我們可以將聯合概率 P(X|a) 分解為各個特征的概率乘積:
?????????????????????????
????????將這個條件獨立性假設應用于貝葉斯公式,我們得到:
??????????????????????????????????????????????????????
????????這樣,樸素貝葉斯分類器就可以通過計算每種可能類別的條件概率和先驗概率,然后選擇具有最高概率的類別作為預測結果。
????????這樣我們就可以進行計算了。如果有些迷糊,讓我們從一個例子開始講起,你會看到貝葉斯分類器很好懂,一點都不難。
| 紋理 | 色澤 | 鼔聲 | 類別 | |
| 1 | 清晰 | 清綠 | 清脆 | 好瓜 |
| 2 | 模糊 | 烏黑 | 濁響 | 壞瓜 |
| 3 | 模糊 | 清綠 | 濁響 | 壞瓜 |
| 4 | 清晰 | 烏黑 | 沉悶 | 好瓜 |
| 5 | 清晰 | 清綠 | 濁響 | 好瓜 |
| 6 | 模糊 | 烏黑 | 沉悶 | 壞瓜 |
| 7 | 清晰 | 烏黑 | 清脆 | 好瓜 |
| 8 | 模糊 | 清綠 | 沉悶 | 好瓜 |
| 9 | 清晰 | 烏黑 | 濁響 | 壞瓜 |
| 10 | 模糊 | 清綠 | 清脆 | 好瓜 |
| 11 | 清晰 | 清綠 | 沉悶 | ? |
| 12 | 模糊 | 烏黑 | 濁響 | ? |
示例:
p(a|X) = p(X|a)* p(a)/p(X) #貝葉斯公式
p(X|a) = p(x1,x2,x3...xn|a) = p(x1|a)*p(x2|a)*p(x3|a)...p(xn|a)
p(X) = p(x1,x2,x3...xn) = p(x1)*p(x2)*p(x3)...p(xn)
p(a|X) = p(x1|a)*p(x2|a)*p(x3|a)...p(xn|a) * p(a) / p(x1)*p(x2)*p(x3)...p(xn) #樸素貝葉斯公式P(好瓜)=(好瓜數量)/所有瓜
P(壞瓜)=(壞瓜數量)/所有瓜
p(紋理清晰)=(紋理清晰數量)/所有瓜
p(紋理清晰|好瓜)= 好瓜中紋理清晰數量/好瓜數量
p(紋理清晰|壞瓜)= 壞瓜中紋理清晰數量/壞瓜數量p(好瓜|紋理清晰,色澤清綠,鼓聲沉悶)=【p(好瓜)】*【p(紋理清晰,色澤清綠,鼓聲沉悶|好瓜)】/【p(紋理清晰,色澤清綠,鼓聲沉悶)】=【p(好瓜)】*【p(紋理清晰|好瓜)*p(色澤清綠|好瓜)*p(鼓聲沉悶|好瓜)】/【p(紋理清晰)*p(色澤清綠)*p(鼓聲沉悶)】p(壞瓜|紋理清晰,色澤清綠,鼓聲沉悶)=【p(壞瓜)*p(紋理清晰|壞瓜)*p(色澤清綠|壞瓜)*p(鼓聲沉悶|壞瓜)】/【p(紋理清晰)*p(色澤清綠)*p(鼓聲沉悶)】從公式中判斷"p(好瓜|紋理清晰,色澤清綠,鼓聲沉悶)"和"p(壞瓜|紋理清晰,色澤清綠,鼓聲沉悶)"時,因為它們的分母
值是相同的,[值都是p(紋理清晰)*p(色澤清綠)*p(鼓聲沉悶)],所以只要計算它們的分子就可以判斷是"好瓜"還是"壞瓜"之間誰大誰小了,所以沒有必要計算分母
p(好瓜) = 6/10
p(壞瓜)=4/10
p(紋理清晰|好瓜) = 4/6
p(色澤清綠|好瓜) = 4/6
p(鼓聲沉悶|好瓜) = 2/6
p(紋理清晰|壞瓜) = 1/4
p(色澤清綠|壞瓜) = 1/4
p(鼓聲沉悶|壞瓜) = 1/4
把以上計算代入公式的分子
p(好瓜)*p(紋理清晰|好瓜)*p(色澤清綠|好瓜)*p(鼓聲沉悶|好瓜) = 4/45
p(壞瓜)*p(紋理清晰|壞瓜)*p(色澤清綠|壞瓜)*p(鼓聲沉悶|壞瓜) = 1/160
所以
p(好瓜|紋理清晰,色澤清綠,鼓聲沉悶) > p(壞瓜|紋理清晰,色澤清綠,鼓聲沉悶),
所以把(紋理清晰,色澤清綠,鼓聲沉悶)的樣本歸類為好瓜3.6?拉普拉斯平滑系數
????????某些事件或特征可能從未出現過,這會導致它們的概率被估計為零。然而,在實際應用中,即使某個事件或特征沒有出現在訓練集中,也不能完全排除它在未來樣本中出現的可能性。拉普拉斯平滑技術可以避免這種“零概率陷阱”,公式為:
![]()
????????一般α取值1,m的值為總特征數量,通過這種方法,即使某個特征在訓練集中從未出現過,它的概率也不會被估計為零,而是會被賦予一個很小但非零的值,從而避免了模型在面對新數據時可能出現的過擬合或預測錯誤。比如計算判斷新瓜(紋理清晰,色澤淡白,鼓聲沉悶)是好和壞時,因為在樣本中色澤淡白沒有出現,導致出現0值,會影響計算結果,要采用拉普拉斯平滑系數。
p(好瓜|紋理清晰,色澤淡白,鼓聲沉悶)=【p(好瓜)】*【p(紋理清晰|好瓜)*p(色澤淡白|好瓜)*p(鼓聲沉悶|好瓜)】/【p(紋理清晰)*p(色澤淡白)*p(鼓聲沉悶)】
p(壞瓜|紋理清晰,色澤淡白,鼓聲沉悶)=【p(壞瓜)】*【p(紋理清晰|壞瓜)*p(色澤淡白|壞瓜)*p(鼓聲沉悶|壞瓜)】/【p(紋理清晰)*p(色澤淡白)*p(鼓聲沉悶)】
p(紋理清晰|好瓜)= (4+1)/(6+3) # +1是因為防止零概率 +3是因為有3個特征(紋理,色澤,鼓聲)
p(色澤淡白|好瓜)= (0+1)/(6+3)
p(鼓聲沉悶|好瓜) = (2+1)/(6+3)
p(紋理清晰|壞瓜)= (1+1)/(4+3)
p(色澤淡白|壞瓜)= (0+1)/(4+3)
p(鼓聲沉悶|壞瓜) = (1+1)/(4+3) ? ? ? ? 示例:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
# 1)獲取數據
news =load_iris()
# 2)劃分數據集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target)
# 3)特征工程:不用做標準化
# 4)樸素貝葉斯算法預估器流程
estimator = MultinomialNB()
estimator.fit(x_train, y_train)
# 5)模型評估
score = estimator.score(x_test, y_test)
print("準確率為:\n", score)
# 6)預測
index=estimator.predict([[2,2,3,1]])
print("預測:\n",index,news.target_names,news.target_names[index])(動態規劃))



ldconfig)



網絡學習之堡壘機)








)

