?
目錄
蕪湖~~~支持向量機(SVM)
1. 引言
2. 基本思想
3. 數學模型
3.1 超平面定義
3.2 分類間隔與目標函數
3.3 軟間隔與松弛變量
4. 核函數方法(Kernel Trick)
4.1 核函數定義
4.2 常用核函數
5. SVM 的幾種類型
6. SVM 的訓練與預測流程
6.1 模型訓練
6.2 模型預測
7. 優點與局限
7.1 優點
7.2 局限
8. SVM 與多分類問題
9.代碼示例
9. 應用場景
10. 小結
蕪湖~~~支持向量機(SVM)
1. 引言
????????支持向量機(Support Vector Machine,簡稱 SVM)是一種基于統計學習理論的監督學習模型,最早由 Vladimir Vapnik 等人提出,廣泛應用于分類(Classification)與回歸(Regression)任務中。由于其優越的泛化能力和堅實的理論基礎,SVM 成為現代機器學習領域的重要算法之一,特別適合于高維、小樣本以及非線性問題。
2. 基本思想
SVM 的核心思想是:
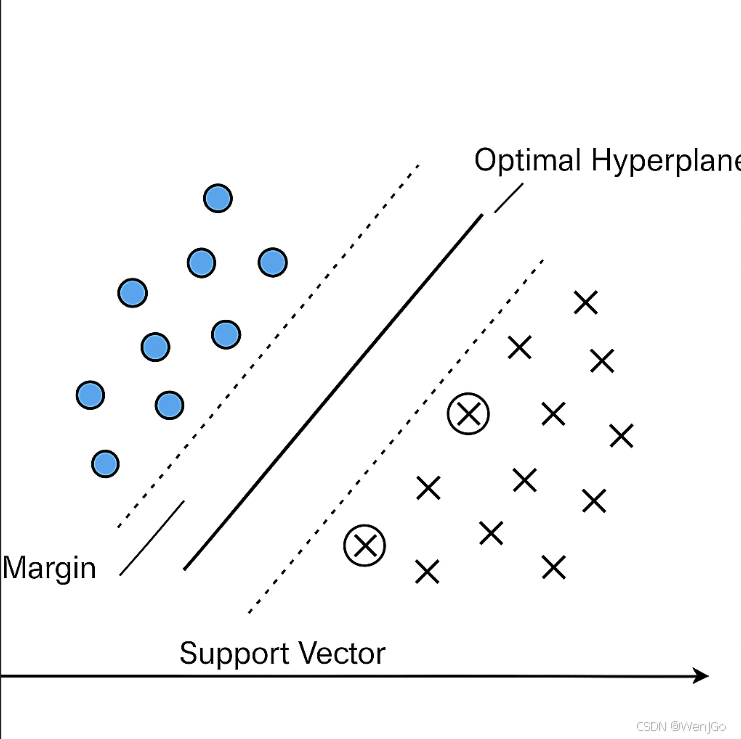
在特征空間中尋找一個最優分離超平面(Optimal Hyperplane),使得該超平面能夠最大限度地將不同類別的樣本分隔開,并具有? ?最大化間隔(Margin Maximization) 的特性。
????????如下圖所示,對于線性可分問題,SVM 會選取離兩個類別最近樣本點(即支持向量)距離最大的分割平面作為最終分類器。
3. 數學模型
3.1 超平面定義
在 n 維空間中,一個超平面的定義如下:
其中:
-
w:法向量,決定超平面方向;
-
b :偏置項,決定超平面距離原點的位置;
-
x :輸入樣本。
3.2 分類間隔與目標函數
對于樣本 ,其分類間隔定義為:
SVM 的目標是最大化所有樣本的最小分類間隔,即:
為簡化計算,通常轉化為以下凸優化問題(硬間隔 SVM):
3.3 軟間隔與松弛變量
當數據線性不可分時,引入松弛變量 和懲罰系數 C,得到軟間隔 SVM:
其中:
-
C :控制對誤分類的懲罰程度;
-
:表示樣本違反間隔的程度。
4. 核函數方法(Kernel Trick)
????????許多實際問題是非線性可分的。SVM 借助核函數技術將數據映射到高維特征空間,在高維空間中實現線性可分。
4.1 核函數定義
核函數 實際上是一個隱式內積:
其中 是非線性映射函數,無需顯式計算。
4.2 常用核函數
| 核函數 | 表達式 | 說明 |
|---|---|---|
| 線性核(Linear) | 適用于線性問題 | |
| 多項式核(Polynomial) | 控制多項式的復雜度 | |
| RBF核(高斯核) | 廣泛使用,處理非線性問題 | |
| Sigmoid核 | 類似神經網絡激活函數 |
5. SVM 的幾種類型
| 類型 | 描述 |
|---|---|
| C-SVC | 最常用的分類 SVM,帶懲罰系數 C |
| NU-SVC | 用參數 |
| EPS-SVR | 支持向量回歸(SVR)類型,用于回歸問題 |
| NU-SVR | 用 |
6. SVM 的訓練與預測流程
6.1 模型訓練
-
輸入:訓練樣本(特征向量 + 標簽)
-
設置 SVM 參數(核函數、C、γ等)
-
求解優化問題(使用 SMO、梯度下降等方法)
-
得到模型(支持向量、權重、偏置)
6.2 模型預測
預測函數定義為:
其中, 是拉格朗日乘子,僅對支持向量不為零。
7. 優點與局限
7.1 優點
-
理論基礎堅實(VC維理論)
-
對高維、小樣本數據表現良好
-
可處理非線性問題(通過核方法)
-
具有稀疏解(依賴于少數支持向量)
7.2 局限
-
對大規模數據訓練速度慢,內存消耗大
-
核函數和參數選擇依賴經驗
-
不易處理多分類問題(需借助一對一/一對多策略)
8. SVM 與多分類問題
SVM 原生為二分類模型,但可通過以下策略擴展為多分類:
-
一對一(One-vs-One, OvO):為每兩個類別訓練一個分類器,投票決定最終分類;
-
一對多(One-vs-Rest, OvR):為每一個類別與其余類別訓練一個分類器,選擇概率最大者;
-
結構 SVM:直接擴展的多類模型(不常見于 OpenCV 實現中)。
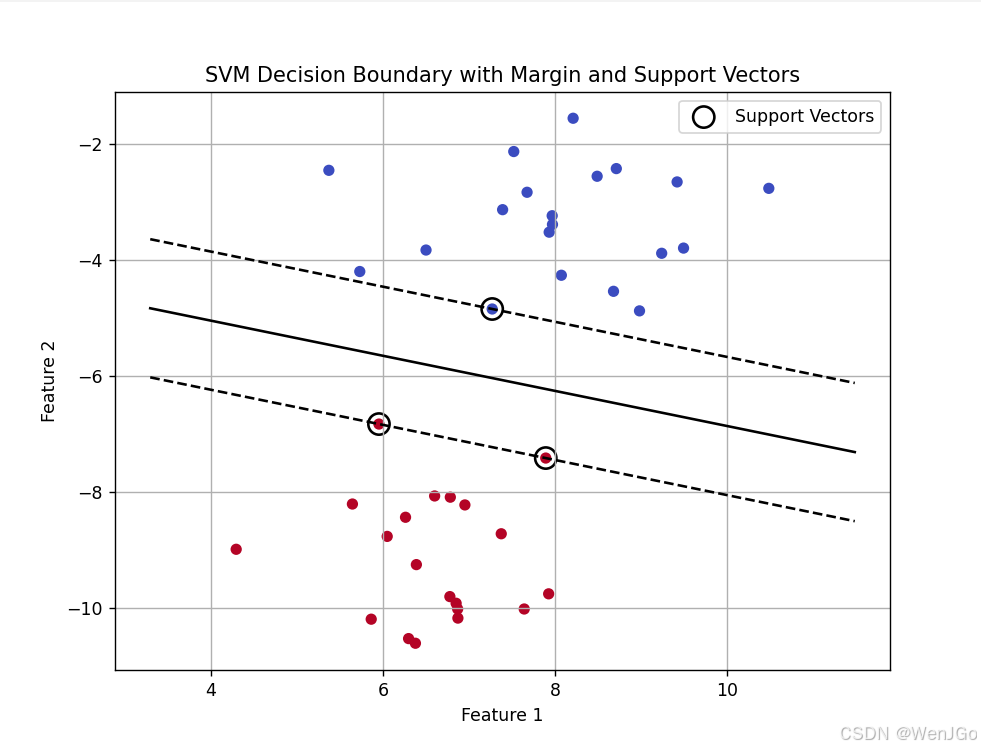
9.代碼示例
基于 Python 的 scikit-learn 和 matplotlib 實現。這個代碼會:
-
創建兩類可分數據;
-
用 SVM 訓練分類器;
-
可視化:
-
支持向量(用圈標出)
-
決策邊界(黑線)
-
間隔邊界(虛線)
-
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.datasets import make_blobs# 生成兩個類別的樣本數據
X, y = make_blobs(n_samples=40, centers=2, random_state=6)# 擬合一個線性支持向量分類器
clf = svm.SVC(kernel='linear', C=1.0)
clf.fit(X, y)# 獲取模型的參數
w = clf.coef_[0]
a = -w[0] / w[1]
xx = np.linspace(min(X[:, 0]) - 1, max(X[:, 0]) + 1)
yy = a * xx - (clf.intercept_[0]) / w[1]# 計算邊界線(間隔)
margin = 1 / np.linalg.norm(w)
yy_down = yy - np.sqrt(1 + a ** 2) * margin
yy_up = yy + np.sqrt(1 + a ** 2) * margin# 繪圖
plt.figure(figsize=(8, 6))# 分類點
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.coolwarm, s=30)# 決策邊界
plt.plot(xx, yy, 'k-')# 間隔邊界
plt.plot(xx, yy_down, 'k--')
plt.plot(xx, yy_up, 'k--')# 支持向量
plt.scatter(clf.support_vectors_[:, 0],clf.support_vectors_[:, 1],s=150, facecolors='none', edgecolors='k', linewidths=1.5, label='Support Vectors')plt.legend()
plt.title("SVM Decision Boundary with Margin and Support Vectors")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.grid(True)
plt.show()
9. 應用場景
SVM 被廣泛應用于以下任務:
-
圖像分類、人臉識別、字符識別(如 OCR)
-
基因數據分析與醫學診斷
-
文字情感分類與垃圾郵件檢測
-
股票趨勢預測與回歸任務
10. 小結
????????支持向量機是一種功能強大的分類與回歸工具,其“最大間隔 + 核技巧”的方法為機器學習提供了堅實的模型選擇方式。在合適的參數和核函數配置下,SVM 能夠提供強魯棒性與良好的泛化能力。對于中小規模問題,SVM 是值得優先嘗試的模型之一。
用一句最簡單的話講明白SVM支持向量機
????????SVM支持向量機是一種機器學習算法,它通過找到一個最優的超平面來分類數據點,使得不同類別的數據點盡可能分開。
)













安裝LSPosed和應用教程)
)



