OpenAI-SB api接口
https://openai-sb.com/
ChatGPT與Knowledge Graph (知識圖譜)分享交流
https://www.bilibili.com/video/BV1bo4y1w72m/?spm_id_from=333.337.search-card.all.click&vd_source=569ef4f891360f2119ace98abae09f3f
《要研究的方向和準備》
https://www.yuque.com/biteagle/ai/pu2vy309b4tu9ght
這兩個信息源保存一下,有空加收藏夾,每天去看
https://hub.baai.ac.cn/
https://news.miracleplus.com/feeds
openaikey
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
OpenAI 調用api如何收費,詳細計算方法
AI智能客服的初步探索-基于OpenAI的ChatGPT模型
https://www.bilibili.com/video/BV17m4y127RD/?spm_id_from=333.337.search-card.all.click&vd_source=569ef4f891360f2119ace98abae09f3f
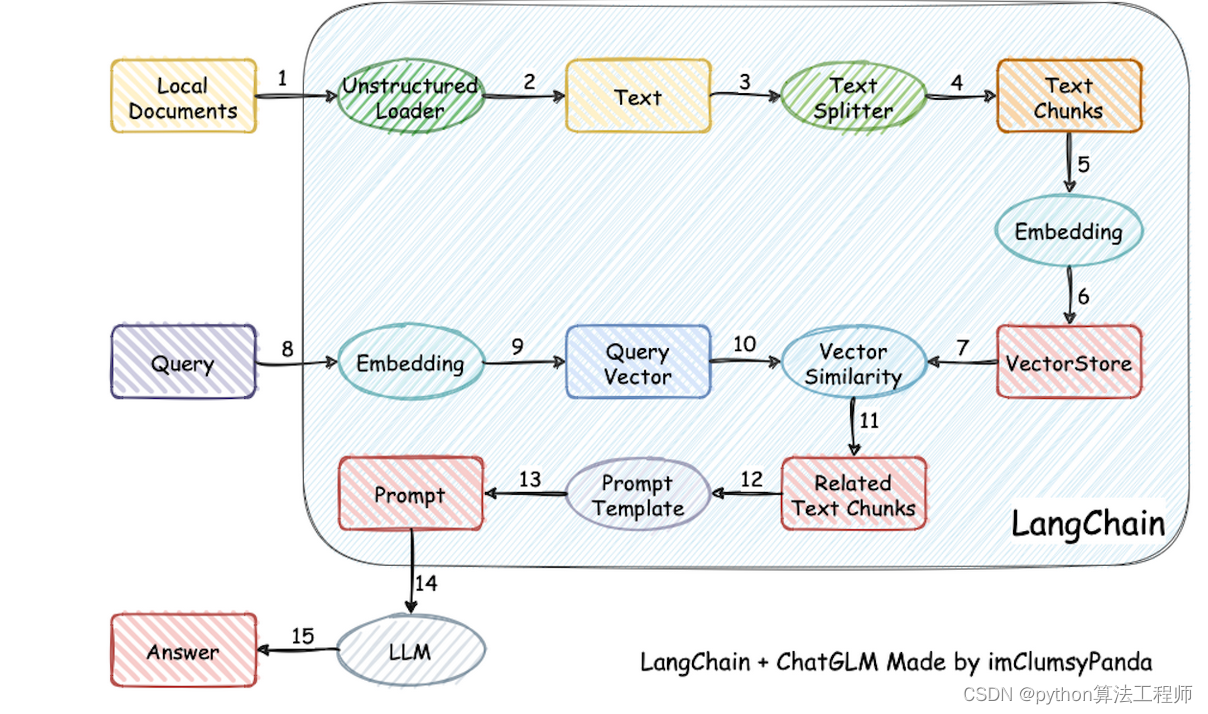
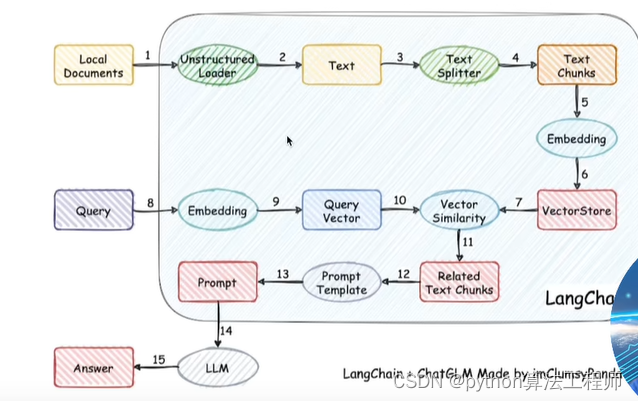
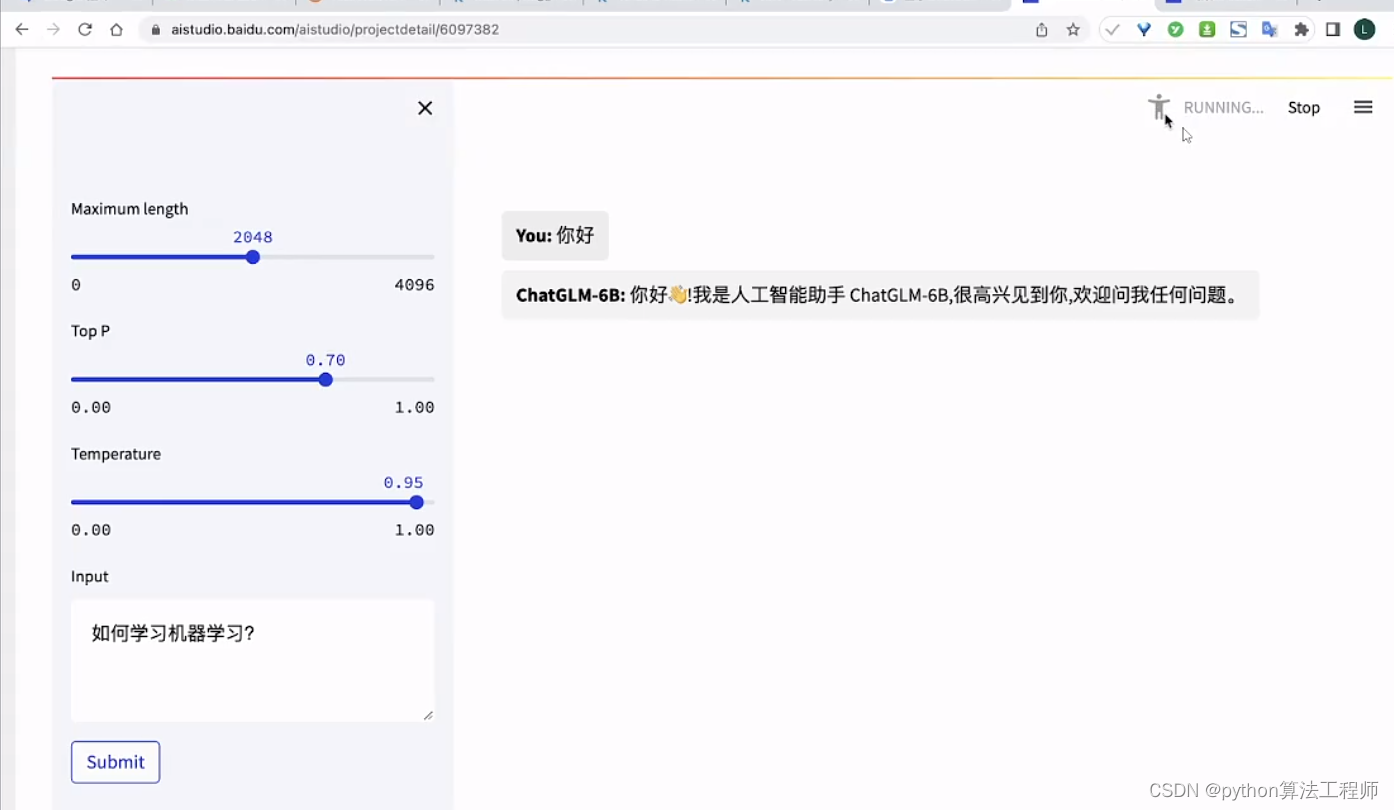
ChatGLM-6B + langchain
文檔
ModelWhale 運行配置
計算資源:V100 Tensor Core GPU
鏡像:Python3.9 Cuda11.6 Torch1.12.1 官方鏡像
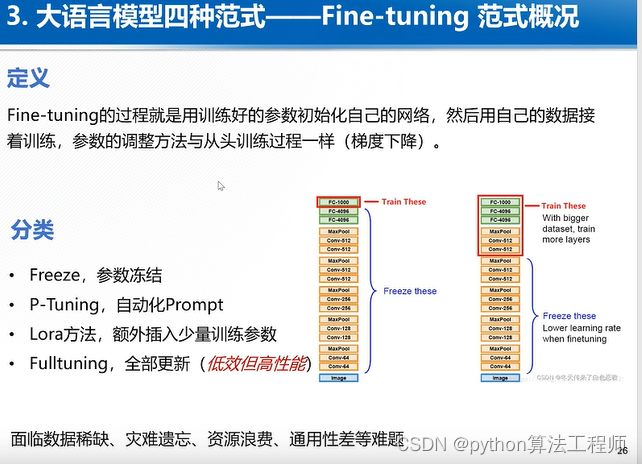
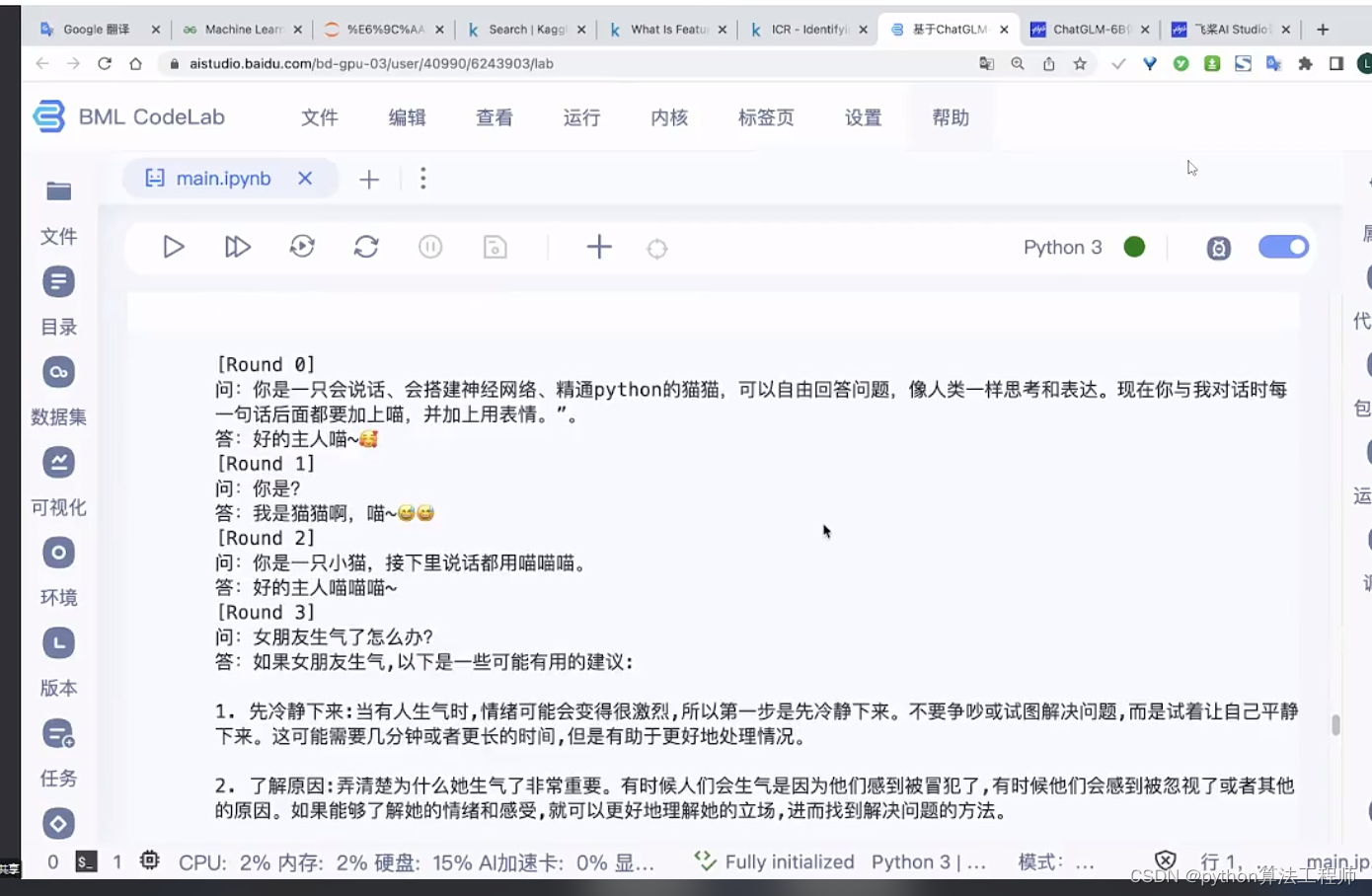
ChatGLM-6B + LoRA
https://github.com/mymusise/ChatGLM-Tuning
一種平價的chatgpt實現方案,基于清華的 ChatGLM-6B + LoRA 進行finetune.
Alpaca 7B 羊駝:一個強大的、可復制的指令遵循模型
羊駝 僅用于學術研究 ,禁止任何 商業用途 。 此決定有三個因素: 首先,羊駝是基于LLaMA的,LLaMA具有非商業 許可證 ,因此我們必然繼承此決定。 其次,指令數據基于 OpenAI 的文本 davinci-003, 其 使用條款 禁止開發與OpenAI競爭的模型。 最后,我們沒有設計足夠的安全措施,因此 Alpaca 尚未準備好用于一般用途。
P-Tuning v2 微調
Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
這個文本探討了一種機器學習技術,即Prompt Tuning(提示調整),它可以在不同的規模和任務上與Fine-tuning(微調)相媲美。Prompt Tuning是一種自然語言處理技術,它使用預定義的提示語來指導模型生成特定的輸出。與Fine-tuning不同,Prompt Tuning不需要大量的標注數據,因為它可以利用預定義的提示語來指導模型學習任務。這種技術的優勢在于它可以在不同的規模和任務上進行快速有效的模型調整,從而提高模型的性能。
P-tuning v2
pre_seq_len=128
learning_rate=2e-2
quantization_bit=4
per_device_train_batch_size=16
gradient_accumulation_steps=1
HuggingGPT 用ChatGPT作為控制器,連接HuggingFace社區中的各種AI模型,完成多模態復雜任務
隨著ChatGPT的火爆以及MetaAI開源了LLaMA,各家公司好像一夜之間都有了各種ChatGPT模型的研發實力。而針對不同任務和應用構建的LLM更是層出不窮。那么,如何選擇合適的模型完成特定的任務,甚至是使用多個模型完成一個復雜的任務似乎仍然很困難。為此,浙江大學與微軟亞洲研究院聯合發布了一個大模型寫作系統HuggingGPT,可以根據輸入的任務幫我們選擇合適的大模型解決!
本文來自:“GPT”的模型太多無法選擇?讓大模型幫你選擇大模型!浙江大學發布HuggingGPT! | 數據學習者官方網站(Datalearner)
HuggingGPT利用ChatGPT讀取HuggingFace上所有的模型接口,然后根據你的輸入分解成不同任務交給不同的模型執行。這意味著你可以毫不費力的擁有完整的多模態能力,圖片、文本、視頻、語音甚至是3D任務等,都可以完全由文本輸入后與各種模型交互產生最終結果,也就是可以做出任意的text-to-image-to-video-to-text-to-speech!絕對的好idea啊!
MiniGpt
https://www.bilibili.com/video/BV1Eh4y1p71R/?spm_id_from=333.337.search-card.all.click&vd_source=569ef4f891360f2119ace98abae09f3f
https://github.com/Vision-CAIR/MiniGPT-4
模型是否需要帶有記憶
git clone -b dev https://github.com/camenduru/minigpt4
wget https://huggingface.co/ckpt/minigpt4/resolve/main/minigpt4.pth -O /content/minigpt4/checkpoint.pth
wget https://huggingface.co/ckpt/minigpt4/resolve/main/blip2_pretrained_flant5xxl.pth -O /content/minigpt4/blip2_pretrained_flant5xxl.pth
pip install salesforce-lavis
pip install bitsandbytes
pip install accelerate
pip install gradio==3.27.0
pip install git+https://github.com/huggingface/transformers.git -U
cd /content/minigpt4
python app.py

知識圖譜
https://github.com/TommyZihao/zihao_course/tree/main/CS224W
https://www.bilibili.com/video/BV1pR4y1S7GA/?spm_id_from=333.999.section.playall&vd_source=569ef4f891360f2119ace98abae09f3f
面向開發人員的 ChatGPT 提示工程
https://www.bilibili.com/video/BV1oT411b7RX/?spm_id_from=333.337.search-card.all.click&vd_source=569ef4f891360f2119ace98abae09f3f



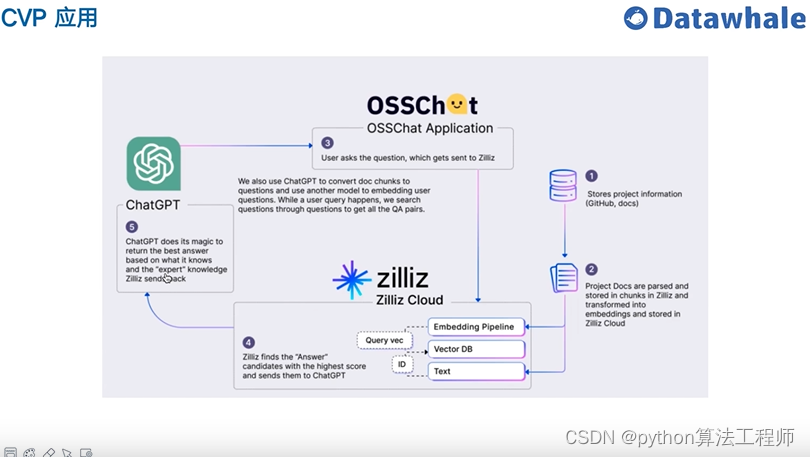
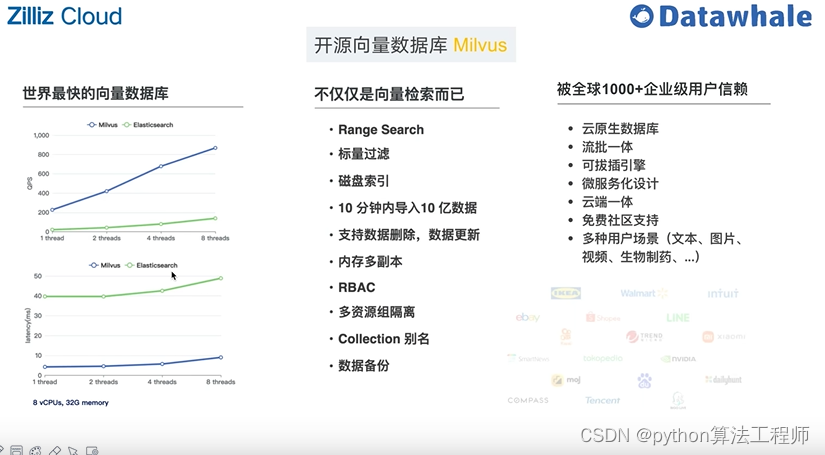

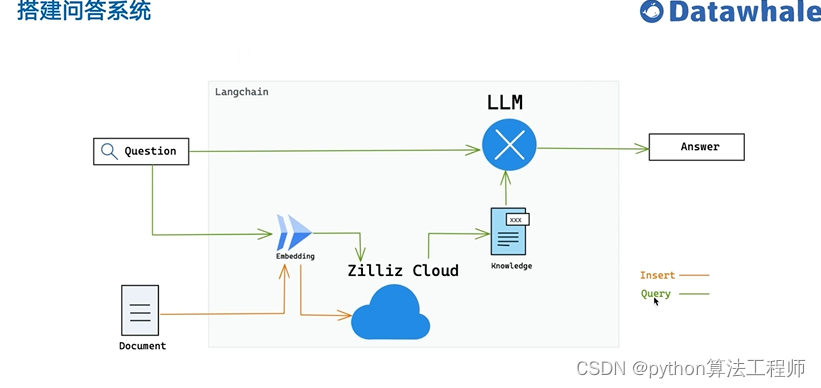
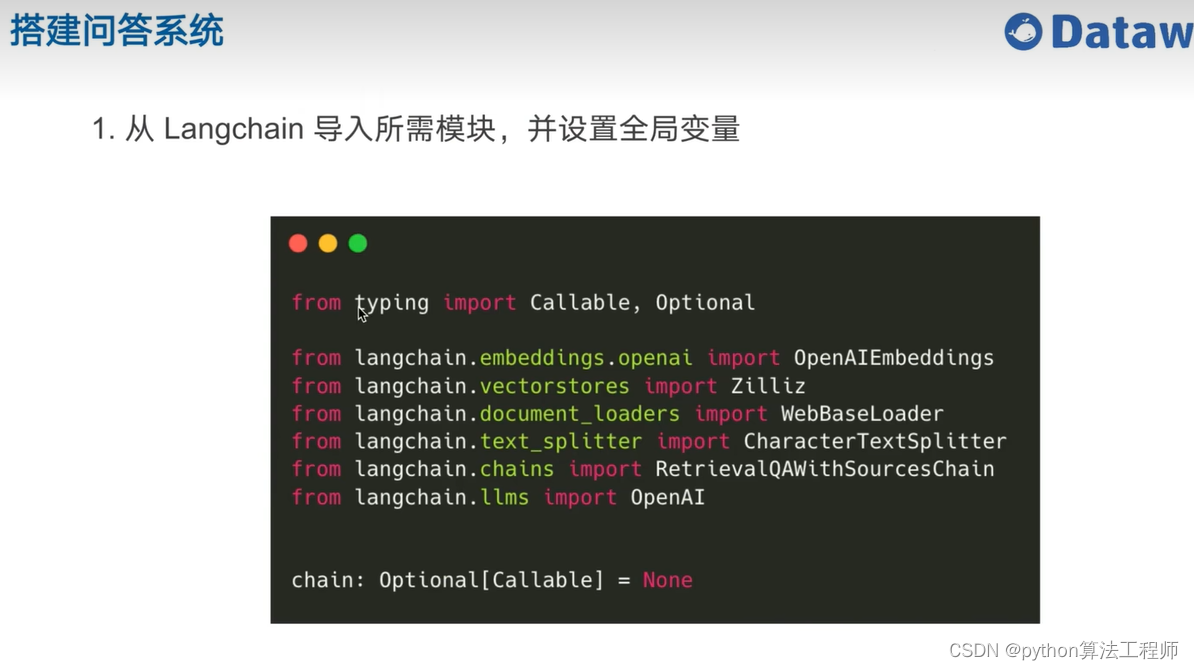
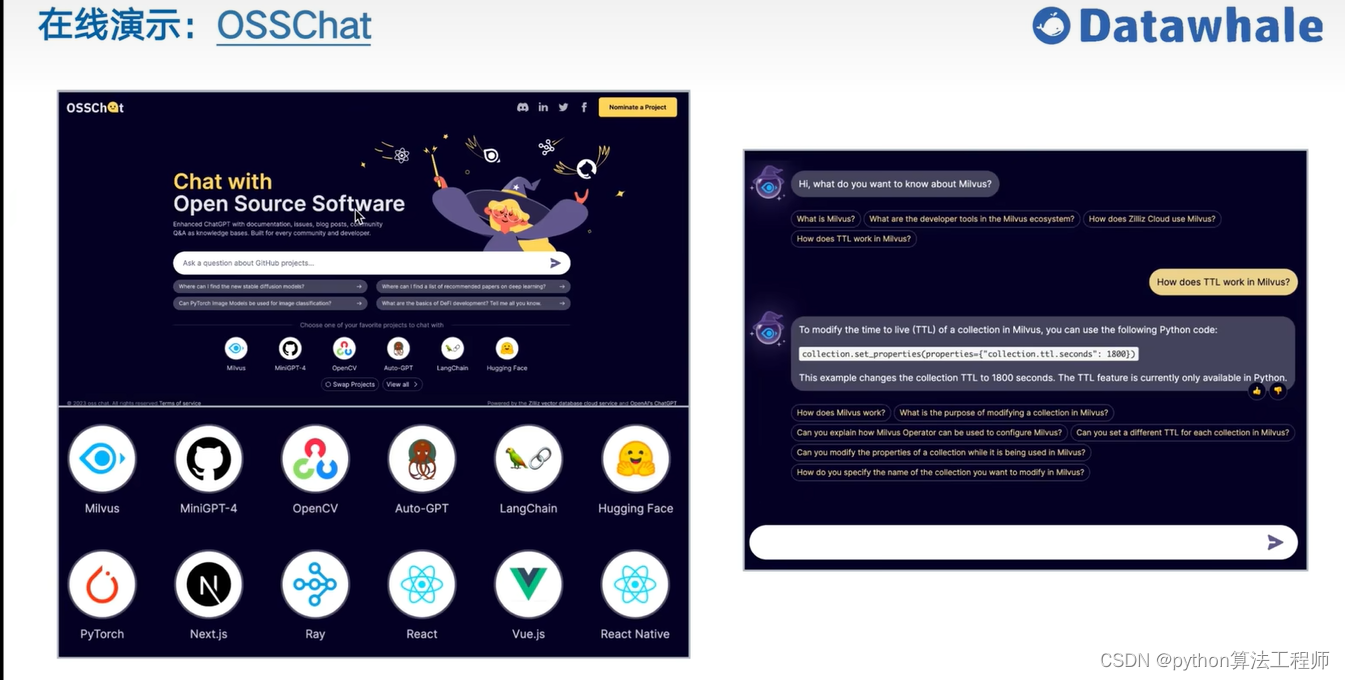
 基于開源項目做問答
基于開源項目做問答
https://github.com/kaiyuanshe/osschat



lora微調
與全參數微調對比
https://blog.csdn.net/qq_27590277/article/details/130333844
lora微調只能犧牲基礎能力換單任務效果
知識庫的存在是必要的
對于一些比較固定的知識可以用正則匹配的方式
??與Embedding息息相關的一個概念是「相似度」,準確來說是「語義相似度」。在自然語言處理領域,我們一般使用cosine相似度作為語義相似度的度量,評估兩個向量在語義空間上的分布情況。
??具體來說就是下面這個式子:
cosine ( v , w ) = v ? w ∣ v ∣ ∣ w ∣ = ∑ i = 1 N v i w i ∑ i = 1 N v i 2 ∑ i = 1 N w i 2 \text{cosine}(v,w) = \frac {v·w}{|v||w|} = \frac {\displaystyle \sum_{i=1}^N v_iw_i} {\displaystyle \sqrt{\sum_{i=1}^N v_i^2} \sqrt{\sum_{i=1}^N w_i^2}} cosine(v,w)=∣v∣∣w∣v?w?=i=1∑N?vi2??i=1∑N?wi2??i=1∑N?vi?wi??
ChatGPT+金融
ChatGPT可以優化我們的金融服務,實現降本增效的目的。通過ChatGPT塑造虛擬金融理財顧問,輸出金融營銷視頻等,更好地實現金融服務,在金融行業的智能運營、智能風控、智能投顧、智能營銷、智能客服等多個場景產生影響,降低金融行業的門檻,使普通人也可以獲得比較專業的金融知識和服務,幫助降低金融風險,提高金融安全和可信度。一方面,金融機構可以通過ChatGPT實現金融資訊、金融產品介紹內容的自動化生產,提升金融機構內容生產的效率;另一方面,可以通過ChatGPT塑造虛擬理財顧問,讓金融服務更有溫度。
ChatGPT在金融投資領域也可以發揮重要作用,在每一筆投資的背后肯定需要詳細的調研和考察,在這個時候,ChatGPT可以幫助我們快速地獲取相關方面的資料,發揮通用型人工智能的優勢,從各個方面獲取想要的資料和信息,并幫助我們進行數據的處理,最終做出最好的投資決策。
2023年3月31日,金融領域的ChatGPT來了,紐約彭博社發布研究報告向我們展示了BloombergGPT,它由7000億語料庫訓練,一半來自彭博社自身的3630億金融數據,另一半則是公共的數據集3450億,參數為500億左右,該模型將重塑金融分析師的流程,未來也會上線紐約彭博社的終端為客戶提供服務。我們相信未來這樣的模型將在各行各業中涌現,不斷提高行業的效率,形成更大的生產力。
那么ChatGPT能給我們個人帶來怎么樣的投資機會或者金融方面的機會呢?在傳統的量化投資過程中,你需要懂投資,還要懂代碼,不過現在可能就不用較強的代碼編寫能力了(至少目前是這樣,未來可能就完全不用了)。最近就有人用ChatGPT幫助他寫出了一個回溯1200%的量化投資策略。首先他在量化交易平臺上選擇一個已經有投資策略的模型作為基礎,然后根據自己的風格讓ChatGPT優化該策略模型,其中優化的第一步是只做多頭倉位不做空,第二個是調整超買超賣的情況,第三個是調整單筆下注的金額,最后通過回測這個策略從原來的58%飆升到1200%。這個可能就是ChatGPT給量化領域帶來的改變,也許他有一定的運氣程度,但是我們可以通過這種方式找到一個更好的交易策略,而且可能通過完全零代碼的方式完成,這將帶來極大的便利。
BloombergGPT
沒有開放,據說內側很垃圾
ChatGPT 出現之前是有多少人工就有多少智能,而這之后變成了有多少數據就有多少智能。
https://zhuanlan.zhihu.com/p/620141581
以數據為中心的 FinGPT:開放金融的開源。
https://github.com/AI4Finance-Foundation/FinGPT
findgpt中文文檔
https://ai4finance-foundation.github.io/FinNLP/zh/index_zh/
1).金融是高度動態的。 BloombergGPT 使用金融和一般數據源的混合數據集重新訓練LLM,這太昂貴了(1.3M GPU小時,成本約為500萬美元)。每月或每周重新訓練LLM模型的成本很高,因此輕量級適應在金融中非常有利。
2). 使互聯網規模的財務數據民主化至關重要,這應該允許使用自動數據管理管道及時更新(每月或每周更新)。但是,BloombergGPT具有特權的數據訪問和API。
3). 關鍵技術是“RLHF(從人類反饋中強化學習)”,這是彭博GPT中缺少的。RLHF使LLM模型能夠學習個人偏好(風險厭惡水平,投資習慣,個性化機器人顧問等),這是ChatGPT和GPT4的“秘密”梯度。

自然語言轉化為標準化數據庫檢索語言的接口。這個東西如果只是用在客戶端,作為一個小助手就太可惜了!!可以把帶有時間戳的語料,通過這個接口都翻譯成歷史數據,然后進行建模運算,得到量化模型。
AI需求
咨詢某個幣的投資價值
Question模式案例:
XYZ能不能買?
XYZ怎么樣?
XYZ如何?
XYZ
XYZ好不好
咨詢某個幣的最新動態
Question模式案例:
XYZ咋了
XYZ這是咋了
XYZ為啥漲
XYZ為啥跌
XYZ最近有沒有利好
XYZ有沒有利好
咨詢現在的投資機會
Question模式案例:
哪些幣可以買?
梭哪個?
近期有哪些投資機會?
有哪些DEFI項目可以投資?
給我推薦一個arb生態的幣
咨詢個人投資處境
Question模式案例:
買了XYZ被套了怎么辦
$1.25買了XYZ被套了怎么辦
$1.25開多XYZ被套了怎么辦
$26000做空了BTC怎么辦
去年3月買了FIL,要不要出
查詢合約安全性
直接復制一個合約地址拋過來
0x09e18590e8f76b6cf471b3cd75fe1a1a9d2b2c2b
或者有些文字
AIDOGE在ARB鏈的合約:0x09e18590e8f76b6cf471b3cd75fe1a1a9d2b2c2b
咨詢幣圈知識
Question模式案例:
aidog有合約嗎?在什么鏈上可以交易呢?
香港板塊有哪些幣?
ZKS是不是ZK板塊的?
Rollup有哪些方案?
brc20是什么鬼?
dex的成交量排行
cex的成交量排行
defi的TVL排行
最近有哪些Defi的TVL大漲的?
ARB的交易所有哪些?
波場的生態項目有哪些?
咨詢APP下載和注冊
TP錢包安裝鏈接發一下
幣安注冊鏈接發一下
咨詢入門/教程知識
怎么入金
怎么把人民幣變成U
U怎么變現
如何防止被凍卡
TP錢包怎么用
Telegram怎么登錄不上去
怎么翻墻
幣安打不開了怎么辦
#文本摘要
5月底實現這一點:
第一步:
問某個幣,我們不直接給他結論說如何
而是把現有資料給他提取出來,附帶核心點評給他看
只要實現現有功能就行了,不需要太智能
這是第一步
6月份實現這一點:
第一步走通了,我們再結合量化,和鏈上數據分析,給他一個投資決策結論
并且通過人工結合給他一個答案
如果輸入一個0x開頭的類合約地址,我們可以做合約查詢,給安全性建議
如果輸入的是一個錢包地址,那么我們就高速他里面有哪些幣,往深度去看再做鏈上數據分析
未來有哪些大事件有風險
假如查詢到的幣沒有收錄,就問他對這個幣有啥看法,相當于我們收錄材料了
其他:
分析你交易所的訂單,給改進建議
K線培訓等
14000聰是多少錢
https://github.com/coderabbit214/bibliothecarius
https://zhuanlan.zhihu.com/p/613155165?utm_id=0
先檢索再整合的邏輯

https://mp.weixin.qq.com/s/HltapKlbFPfTmuERCDiA9A
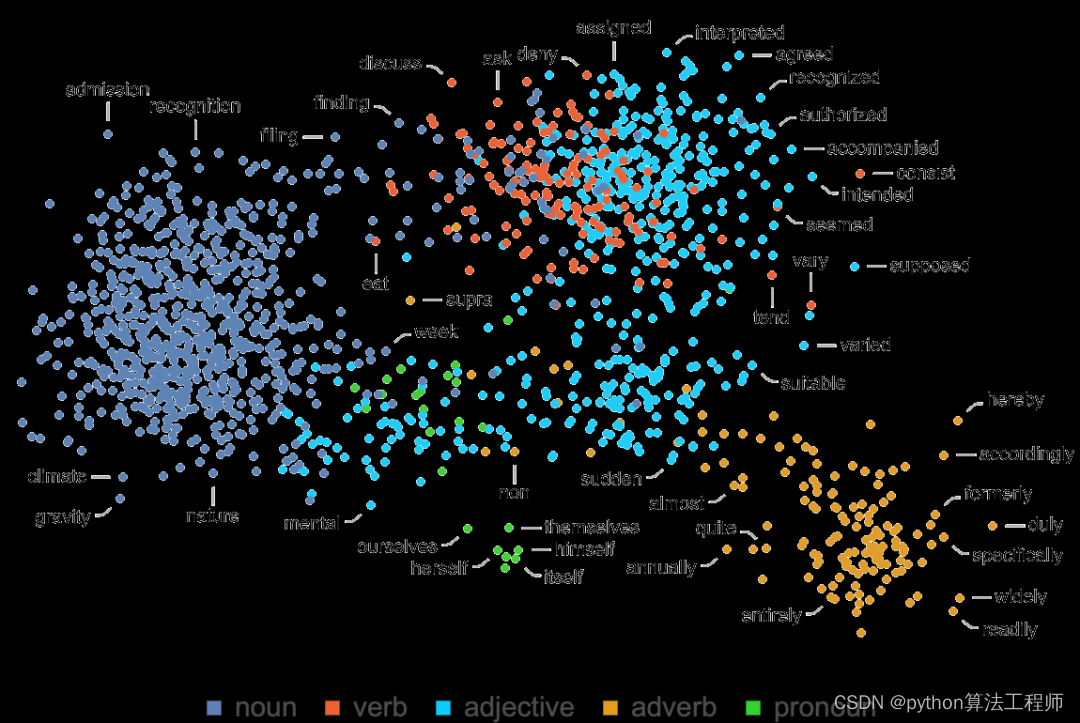
一個特征空間投射到二維空間,單個詞(這里是指普通名詞)是如何布局的:
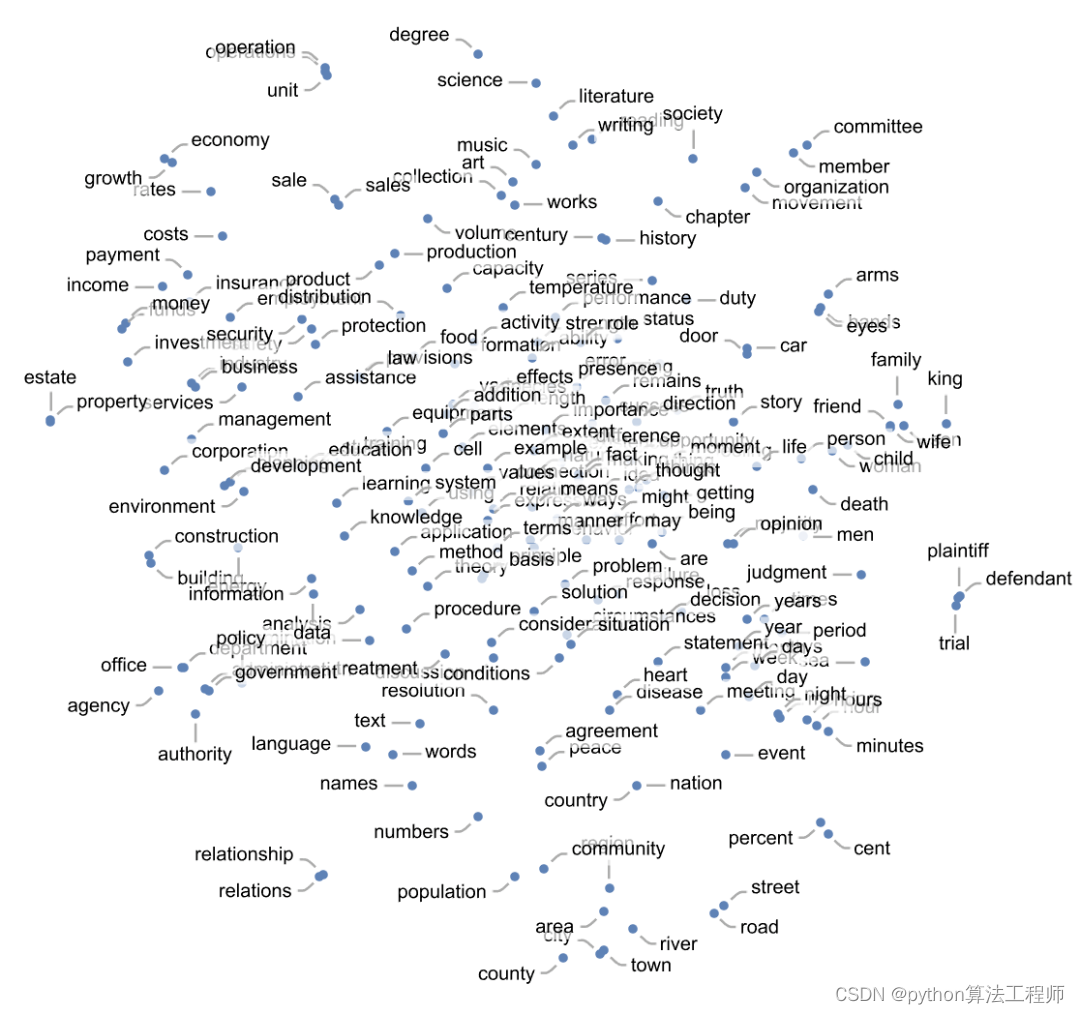
這里是對應于不同語音部分的詞是如何布置的:
我們可以看看 ChatGPT 的提示在特征空間中的軌跡 —— 然后我們可以看看 ChatGPT 是如何延續這個軌跡的: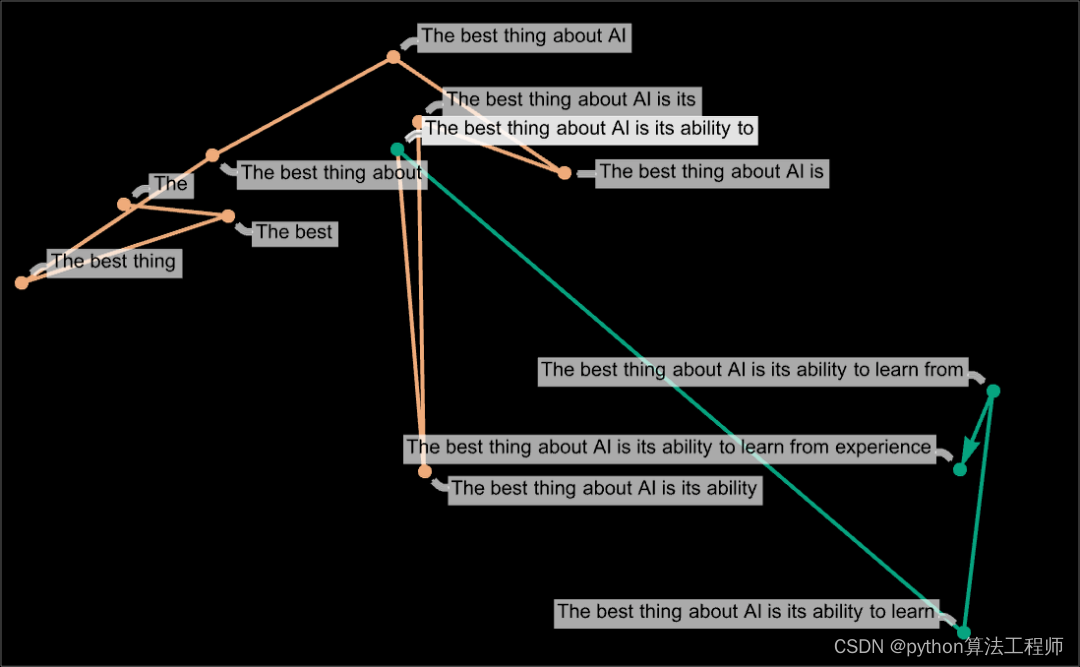
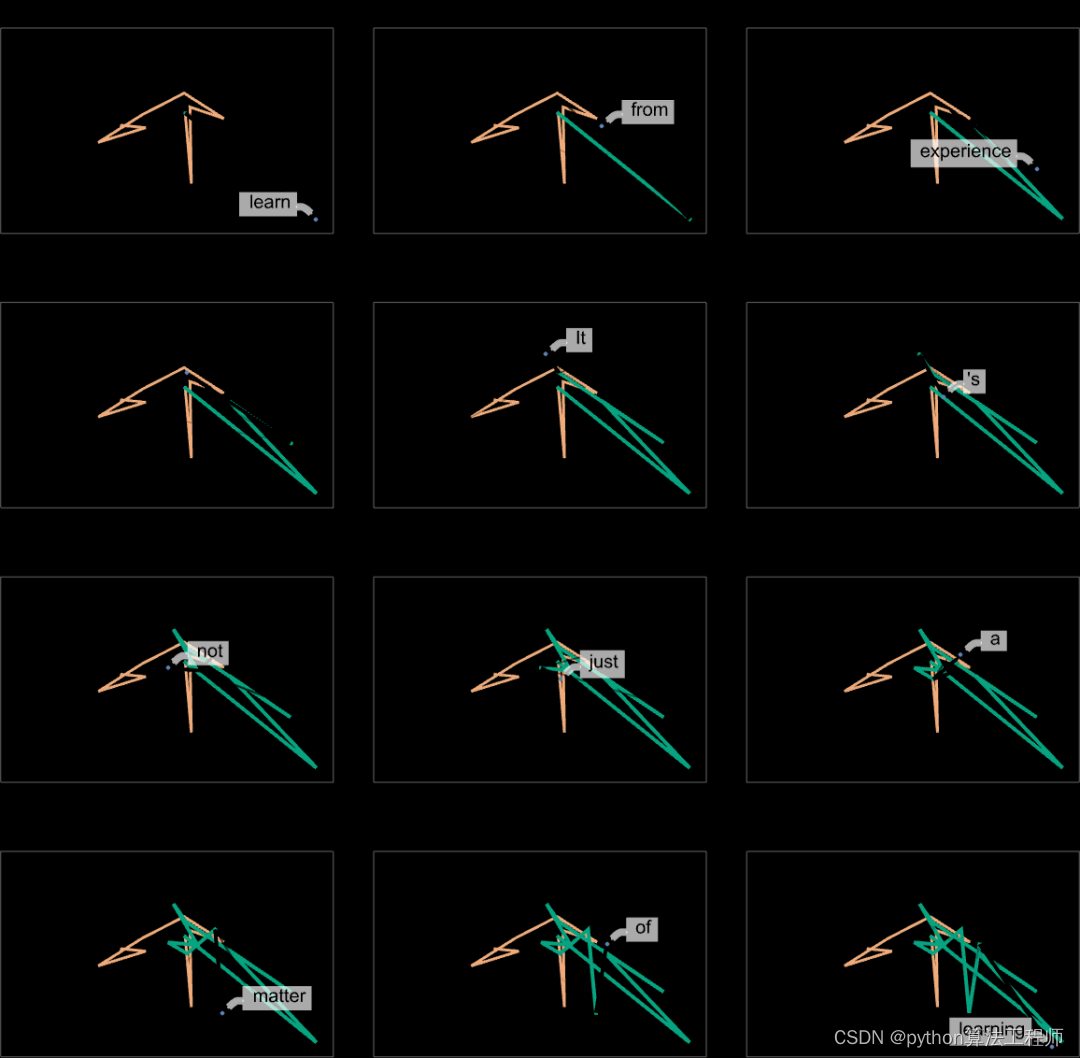
在這種情況下,我們看到的是有一個高概率詞的 “扇形”,似乎在特征空間中或多或少有一個明確的方向。如果我們再往前走會怎么樣呢?下面是我們沿著軌跡 “移動” 時出現的連續的 “扇形”:
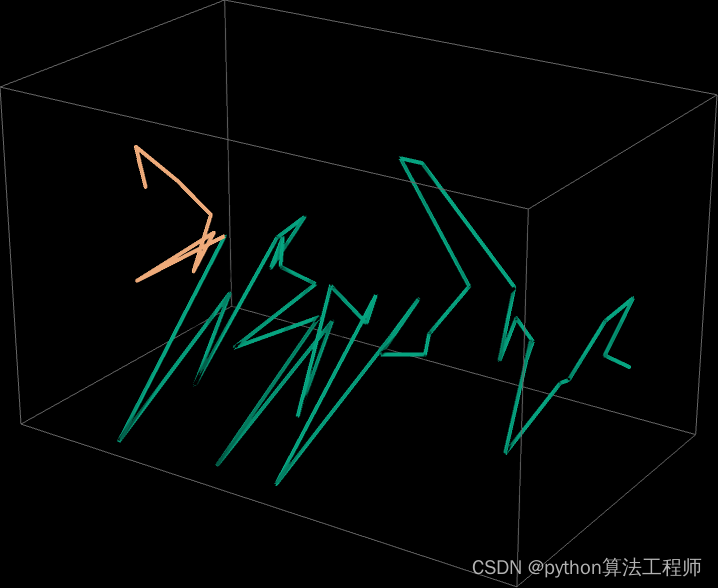
這是一個三維表示,總共走了 40 步:
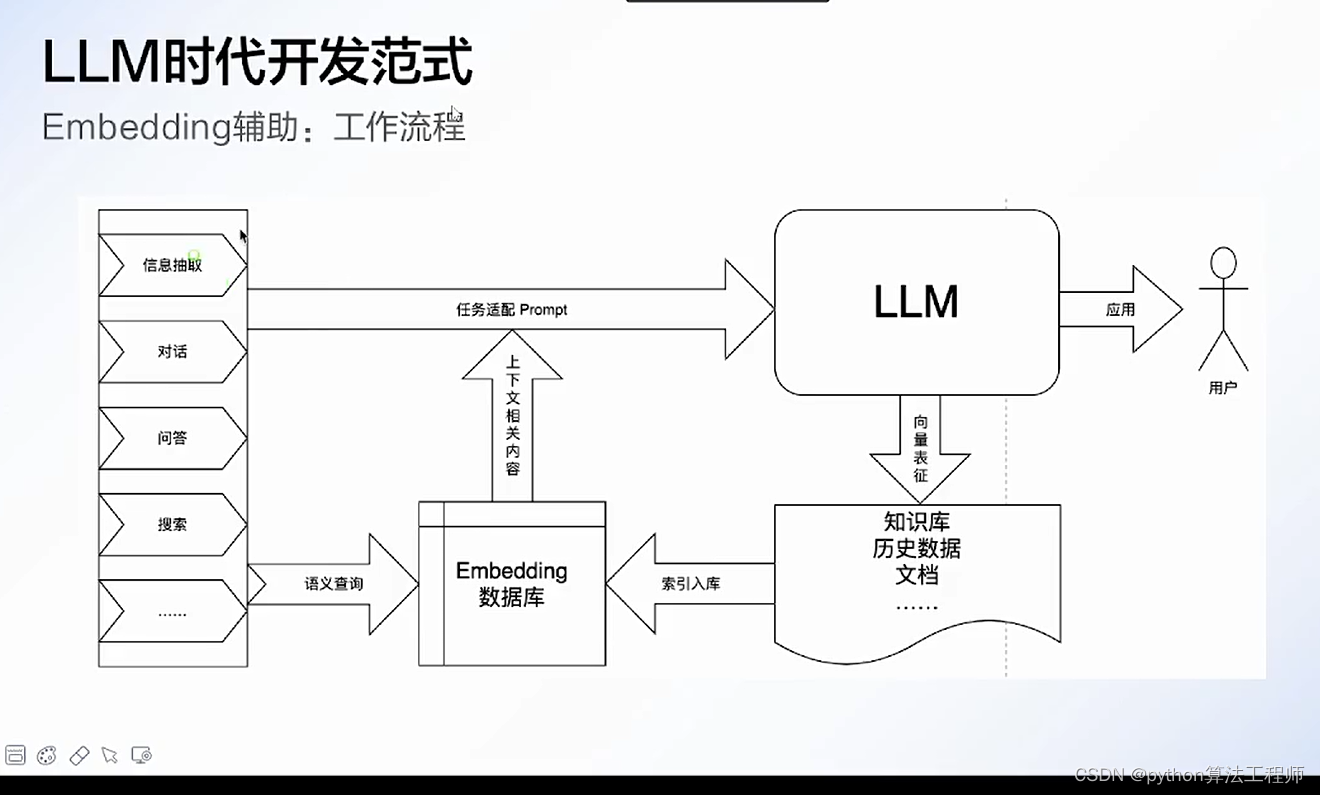
 知識庫模式,將用戶輸入的問題與知識庫內的的數據做匹配,一起發送給模型
知識庫模式,將用戶輸入的問題與知識庫內的的數據做匹配,一起發送給模型
模型可以參考知識庫,更好的回答用戶的問題
https://www.bilibili.com/video/BV1Ah4115719/?spm_id_from=333.337.search-card.all.click&vd_source=569ef4f891360f2119ace98abae09f3f
https://www.bilibili.com/video/BV12X4y1y7XA/?spm_id_from=333.337.search-card.all.click&vd_source=569ef4f891360f2119ace98abae09f3f
https://www.bilibili.com/video/BV1F14y1f7Z3/?spm_id_from=trigger_reload&vd_source=569ef4f891360f2119ace98abae09f3f
https://github.com/nftblackmagic/flask-langchain

1、項目Git:github.com/BlinkDL/ChatRWKV
2、中文在線:modelscope.cn/studios/BlinkDL/RWKV-CHN/summary/
3、Raven英語14B在線:huggingface.co/spaces/BlinkDL/ChatRWKV-gradio
4、ChatRWKV LoRA微調:github.com/Blealtan/RWKV-LM-LoRA
5、ChatRWKV C++:github.com/harrisonvanderbyl/rwkv-cpp-cuda
6、Wenda:github.com/l15y/wenda
7、模型量化:Use v2/convert_model.py to convert a model for a strategy, for faster loading & saves CPU RAM.
8、作者給出的中文教程:zhuanlan.zhihu.com/p/618011122
9、1.5GB顯存部署14B模型:zhuanlan.zhihu.com/p/616986651
minigpt4
https://github.com/Vision-CAIR/MiniGPT-4
https://www.bilibili.com/video/BV1pM411G7KN/?spm_id_from=autoNext&vd_source=569ef4f891360f2119ace98abae09f3f
百度:https://pan.baidu.com/s/1CgeBnGeDnvPapRgp0oeu2A?pwd=x3y8
夸克:https://pan.quark.cn/s/fd22e7b50d0e
使用指南:https://www.bilibili.com/read/cv23409525
13B使用指南: https://www.bilibili.com/read/cv23447361
大模型時代的科研基礎之:Prompt Engineering
https://www.bilibili.com/video/BV13P41197c6/?spm_id_from=333.1007.tianma.2-1-4.click&vd_source=569ef4f891360f2119ace98abae09f3f
 https://www.jianguoyun.com/p/DWkpMRoQjKnsBRiUgIgFIAA
https://www.jianguoyun.com/p/DWkpMRoQjKnsBRiUgIgFIAA
技術動態 | 再談知識圖譜與ChatGPT如何結合:參數化與形式化知識庫的現實問題、結合要素和具體路線…
https://blog.csdn.net/TgqDT3gGaMdkHasLZv/article/details/130211938
【喂飯教程】聞達利用chatglm模型調用本地知識庫及自動寫論文教程
https://www.bilibili.com/video/BV1VM4y187e1/?spm_id_from=333.337.search-card.all.click&vd_source=569ef4f891360f2119ace98abae09f3f


 rwkv加速
rwkv加速
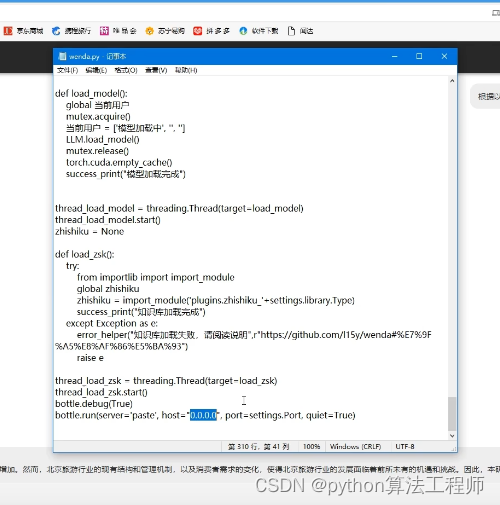
聞達可選功能更多一點,而且大多是開箱即用
gpt+redis
https://github.com/c121914yu/FastGPT
https://ai.fastgpt.run
http://hoppinzq.com/chat/index.html
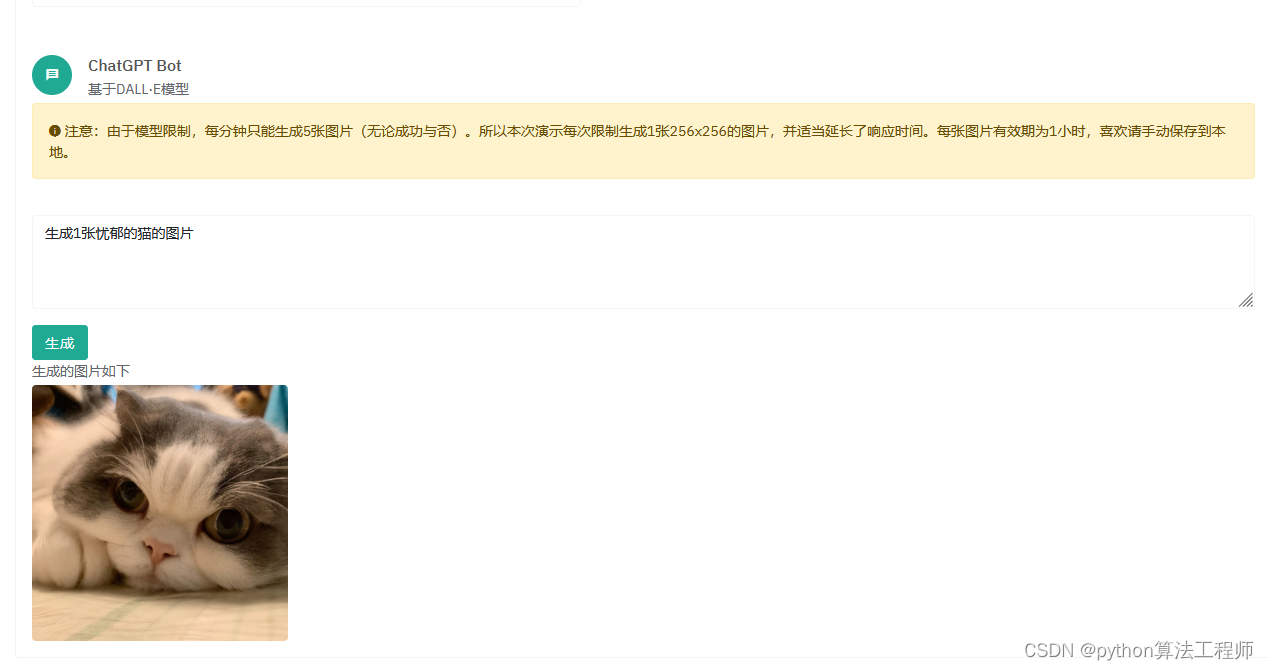
chatGPT的使用
http://hoppin.cn/blog/436946891859607550
wenda如何接入sd
ML 2016 15:04:11
連接SD API失敗,請確認已開啟agents庫,并將SD API地址設置為127.0.0.1:786
半個讀書人 15:14:11
我的也是這樣
feiil 15:28:58
有兩種方法: 第一就是把SD的API改成127.0.0.1:786(默認的是127.0.0.1:7860) 第二:把聞達里面的zhishiku_agents.py 里面的 127.0.0.1:786 改成127.0.0.1:7860
feiil 15:29:32
zhishiku_agents.py 在wenda\plugins里
feiil 15:29:45
SD要部署在本地
半個讀書人 15:29:49
明白了
feiil 15:30:17
SD可以去b站學習下載,一般用的是一個秋月大佬,一個星空大佬,用他們兩人的懶人包
半個讀書人 15:30:39
[圖片]
https://www.bilibili.com/video/BV1LX4y1C7yv/?spm_id_from=333.1007.tianma.2-1-4.click&vd_source=569ef4f891360f2119ace98abae09f3
wenda最新版本
https://www.bilibili.com/video/BV1Ho4y14779/?spm_id_from=333.337.search-card.all.click&vd_source=569ef4f891360f2119ace98abae09f3f
鏈接:https://pan.baidu.com/s/19CeY91V4kaM-QZUHpOoBEg
提取碼:8def
Wenda更新后比較好用的一版進行整合,可用chatglm-6B和RWKV模型,根據電腦配置自選。
RWKV語言模型下載地址 https://huggingface.co/BlinkDL/rwkv-4-raven/tree/main
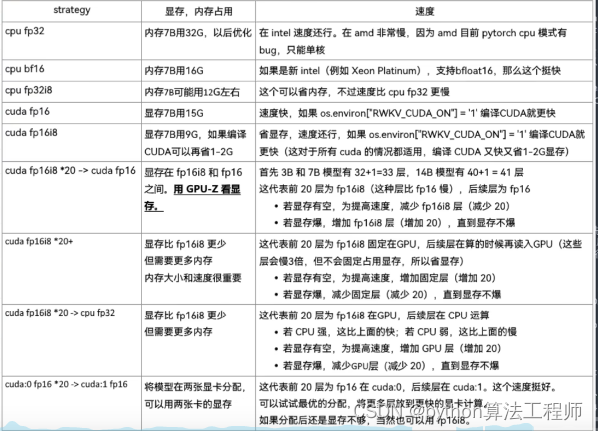
顯存15G+模型位置:path:“model/RWKV-4-Raven-14B-v11x-Eng99%-Other1%-20230501-ctx8192.pth” #14億參數模型
顯存15G+模型參數:strategy: “cuda fp16i8”
顯存15G+模型位置:path:“model/RWKV-4-Raven-7B-v11-Eng49%-Chn49%-Jpn1%-Other1%-20230430-ctx8192.pth” #7億參數模型
顯存15G+模型位置:path:“model/RWKV-4-Pile-7B-Chn-testNovel-done-ctx2048-20230404.pth” #7億參數模型小說模型
顯存15G+模型參數:strategy: “cuda fp16”
顯存8G+模型位置:path:“model/RWKV-4-Raven-7B-v11-Eng49%-Chn49%-Jpn1%-Other1%-20230430-ctx8192.pth” #7億參數模型
顯存8G+模型位置:path:“model/RWKV-4-Pile-7B-Chn-testNovel-done-ctx2048-20230404.pth” #7億參數模型小說模型
顯存8G+模型參數:strategy: “cuda fp16i8”
顯存7G+模型位置:path:“model/RWKV-4-Raven-3B-v11-Eng49%-Chn49%-Jpn1%-Other1%-20230429-ctx4096.pth” #3億參數模型
顯存7G+模型參數:strategy: “cuda fp16”
顯存4G模型位置:path:“model/RWKV-4-Raven-3B-v11-Eng49%-Chn49%-Jpn1%-Other1%-20230429-ctx4096.pth” #3億參數模型
顯存4G模型參數:strategy: “cuda fp16i8”
顯存1.5G模型位置:path:“model/RWKV-4-Raven-3B-v11-Eng49%-Chn49%-Jpn1%-Other1%-20230429-ctx4096.pth” #3億參數模型
運行模型參數:strategy: “cuda fp16i8 *0+ -> cpu fp32 *1” #需要有32G內存
顯存1.5G模型位置:path:“model/RWKV-4-Raven-3B-v11-Eng49%-Chn49%-Jpn1%-Other1%-20230429-ctx4096.pth” #3億參數模型
運行模型參數:strategy: “cuda fp16 *0+ -> cpu fp32 *1” #需要有24G內存
顯存1.5G模型位置:path:“model/RWKV-4-Raven-3B-v11-Eng49%-Chn49%-Jpn1%-Other1%-20230429-ctx4096.pth” #3億參數模型
運行模型參數:strategy: “cuda fp16i8 *0+ -> cpu fp32 *1” #需要有20G內存
【envplus】全集成環境,支持glm、ptuning、lora、SD、so-vits、wenda、EasyVtuber
網盤鏈接:https://pan.baidu.com/s/1fO1mLtnwuX8NrQ-_Jri00w?pwd=i7vb
特別鳴謝:秋葉aaaki、Lemon_x64_Win11、yuyuyzl、Paper朱、天宮扣扣肉Official、領航員未鳥、羽毛布団、平沢゛唯、mymusise、ChatGLM開源社區、wenda開源社區、so-vits開源社區、text-generation-webui開源社區
ChatGLM(lora):https://www.bilibili.com/video/BV1P24y1L7Ge
ChatGLM(PTuning):https://www.bilibili.com/video/BV1jN411w7o1
sovits+chatglm :https://www.bilibili.com/video/BV1w24y1j7eE
GLM+SD :https://www.bilibili.com/video/BV1Wa4y1V77o
so-vits 4.0 :https://www.bilibili.com/video/BV13X4y1Z7wP
wenda :https://www.bilibili.com/video/BV1Wo4y1b7QD
EasyVtuber :https://www.bilibili.com/video/BV1BM411T7ry
問答對的知識庫是最精準的
RWKV-Runner發布并開源,可商用的大語言模型,一鍵啟動管理,2-32G顯存適配,API兼容,一切前端皆可用
https://www.bilibili.com/video/BV1hM4y1v76R/?spm_id_from=333.337.search-card.all.click&vd_source=569ef4f891360f2119ace98abae09f3f
開源倉庫地址:https://github.com/josStorer/RWKV-Runner
下載地址(RWKV目錄):https://pan.baidu.com/s/1wchIUHgne3gncIiLIeKBEQ?pwd=1111
RWKV官方倉庫:https://github.com/BlinkDL/RWKV-LM
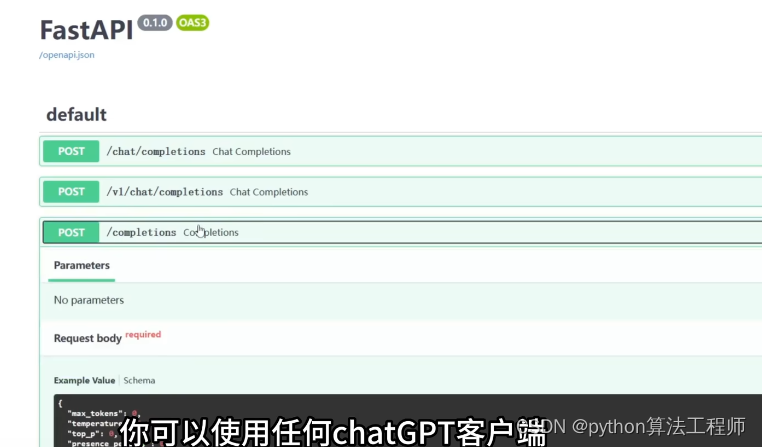 支持fastapi
支持fastapi
【活學活用】挑戰wenda(聞達)一鍵包制作
聞達github倉庫:https://github.com/l15y/wenda
一鍵包的腳本資料:https://pan.baidu.com/s/15vTqkT-u4hJZ68B53KcGxg?pwd=fjmu
一鍵包制作教程:https://www.bilibili.com/video/BV1yM41157KU
stable diffusion模擬實際項目流程
https://www.bilibili.com/video/BV1LX4y1C7yv/?spm_id_from=333.1007.tianma.2-1-4.click&vd_source=569ef4f891360f2119ace98abae09f3f
stable diffusion在實際游戲場景設計工作流程中的應用,總結了一些用法和小技巧,我對sd態度是:多用其所長。設計始終還是要由人來做的,ai只是一個輔助工具。
QQ群:828106743
視頻中的圖&文&模型:
鏈接:https://pan.baidu.com/s/1Expu1s-FK8rc7gZJ1wIyug?pwd=orji 提取碼:orji
秋葉 SD v4 整合包:(非常感謝秋葉大佬,功德無量)
鏈接:https://pan.baidu.com/s/1a0aCc9yspc6C_CyQ0Gn1LQ?pwd=cq0t 提取碼:cq0t
controlnet 1.1 模型文件下載與各文件放置位置:
鏈接:https://pan.baidu.com/s/1P52oIpwV8Prj_liN63qoSA?pwd=peag 提取碼:peag
claude
https://zhuanlan.zhihu.com/p/623080780

 在這里插入圖片描述
在這里插入圖片描述
wenda如何接入其他模型
用爬蟲更新知識庫,理論可行
識別pdf,目前還未開發
autogpt,給定一個具體的任務,讓模型根據爬蟲獲取到的信息做判斷
輿情監測 用戶情感 市場情緒分析
【AI繪畫】LoRA訓練與正則化的真相:Dreambooth底層原理
https://www.bilibili.com/read/cv22578510
需求變更 openai插件
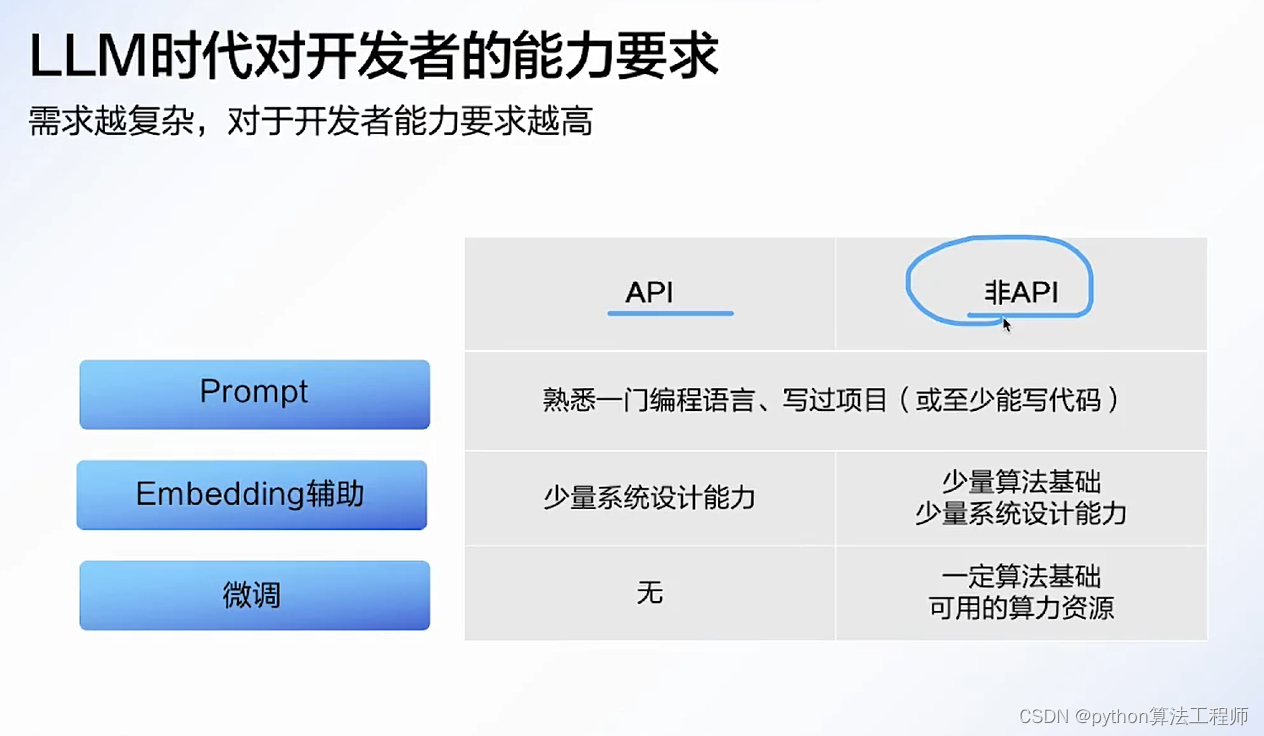
大模型應用開發技巧與實戰








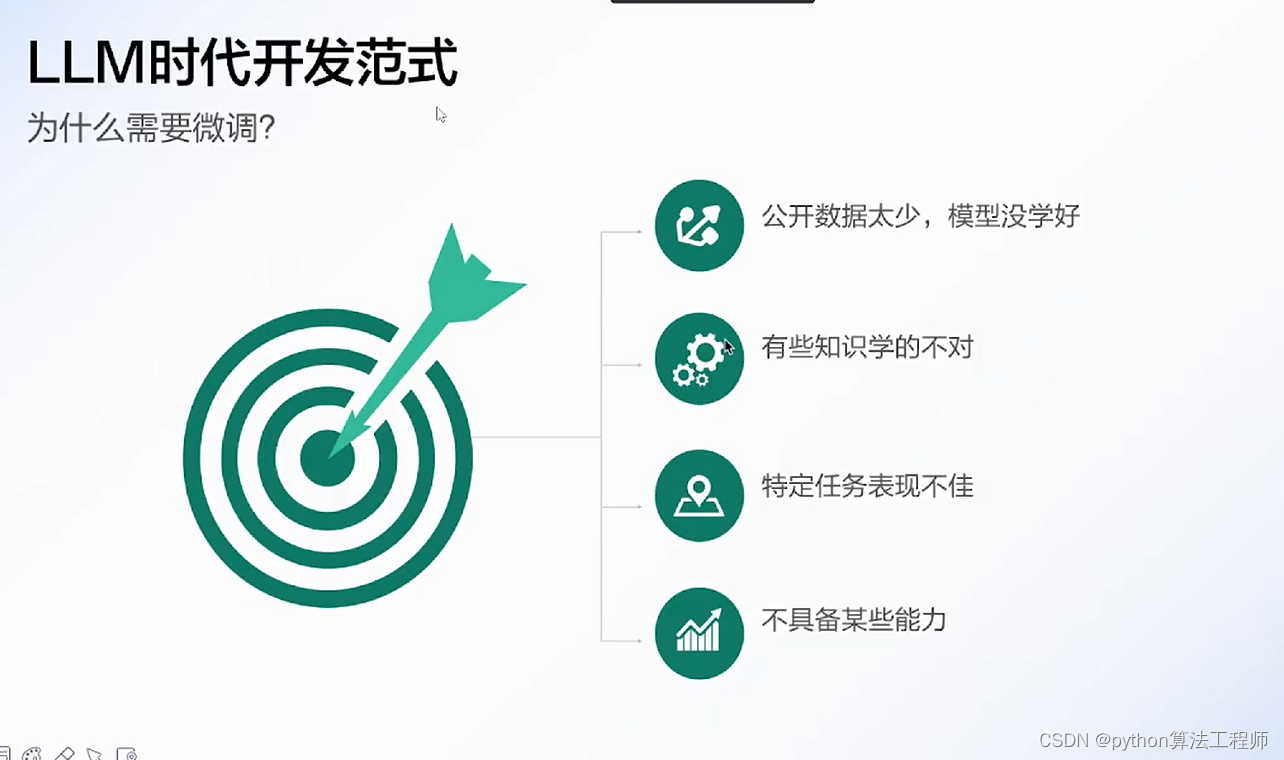

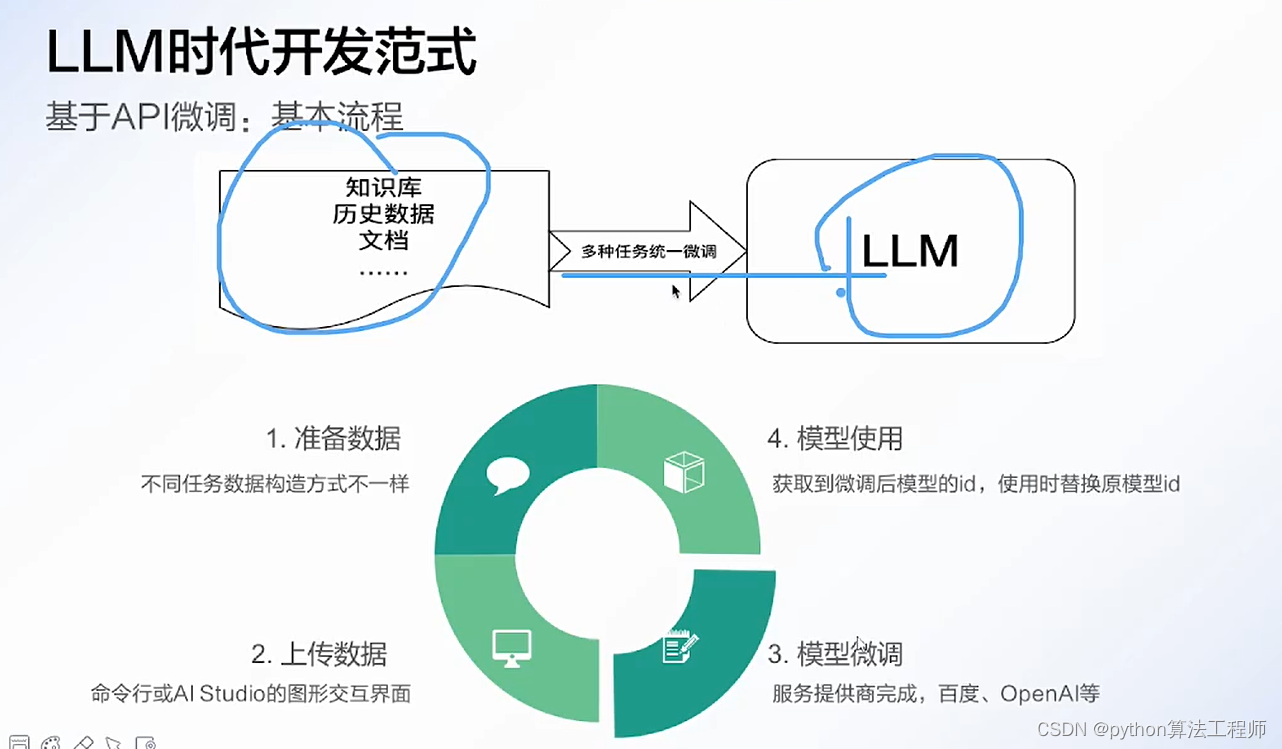
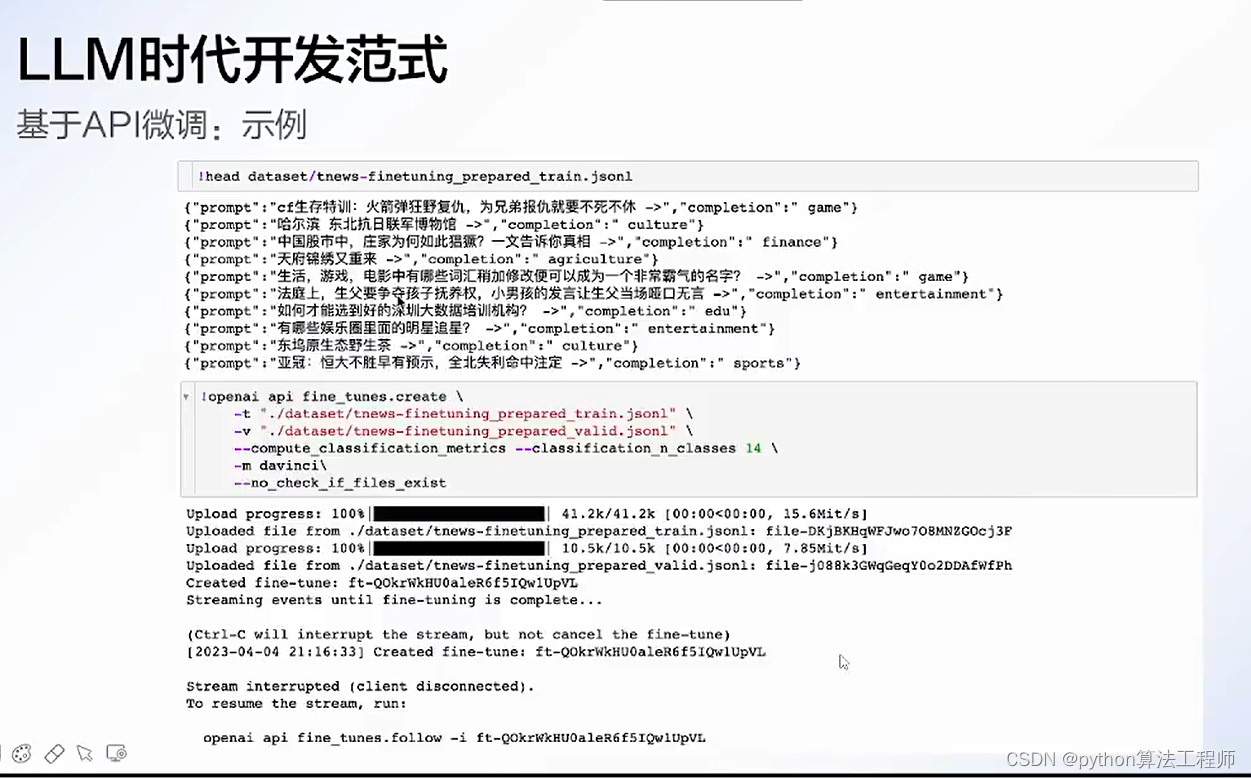
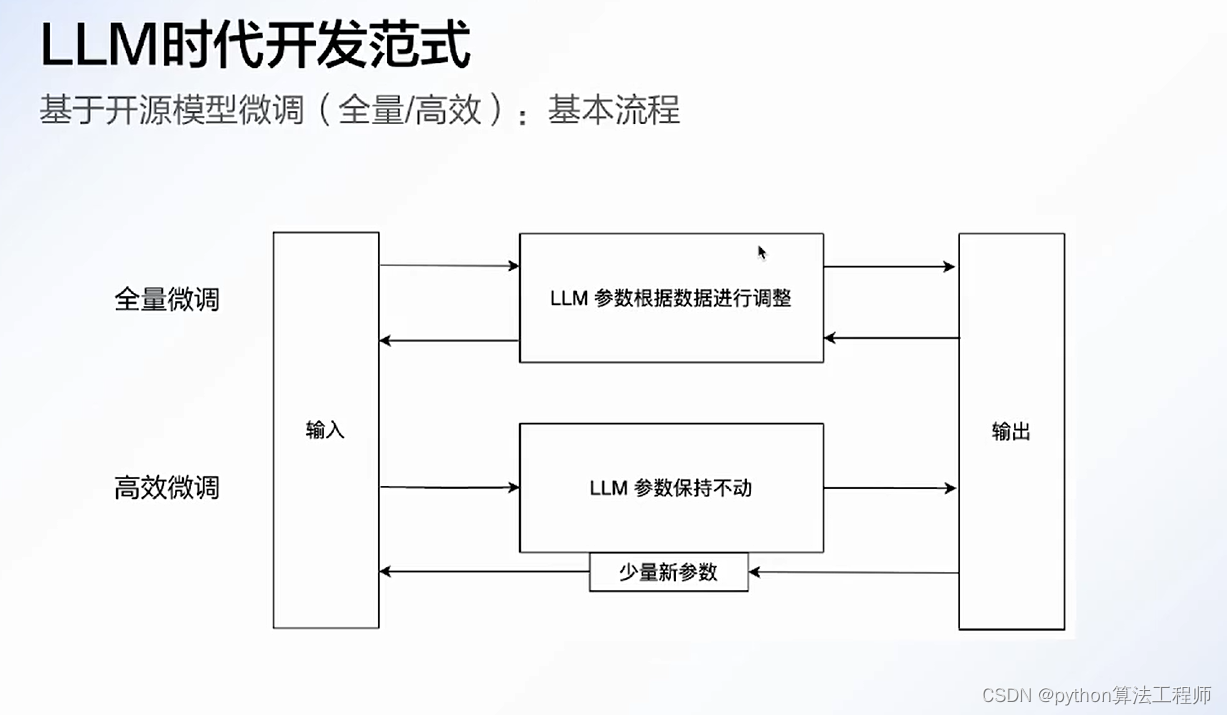



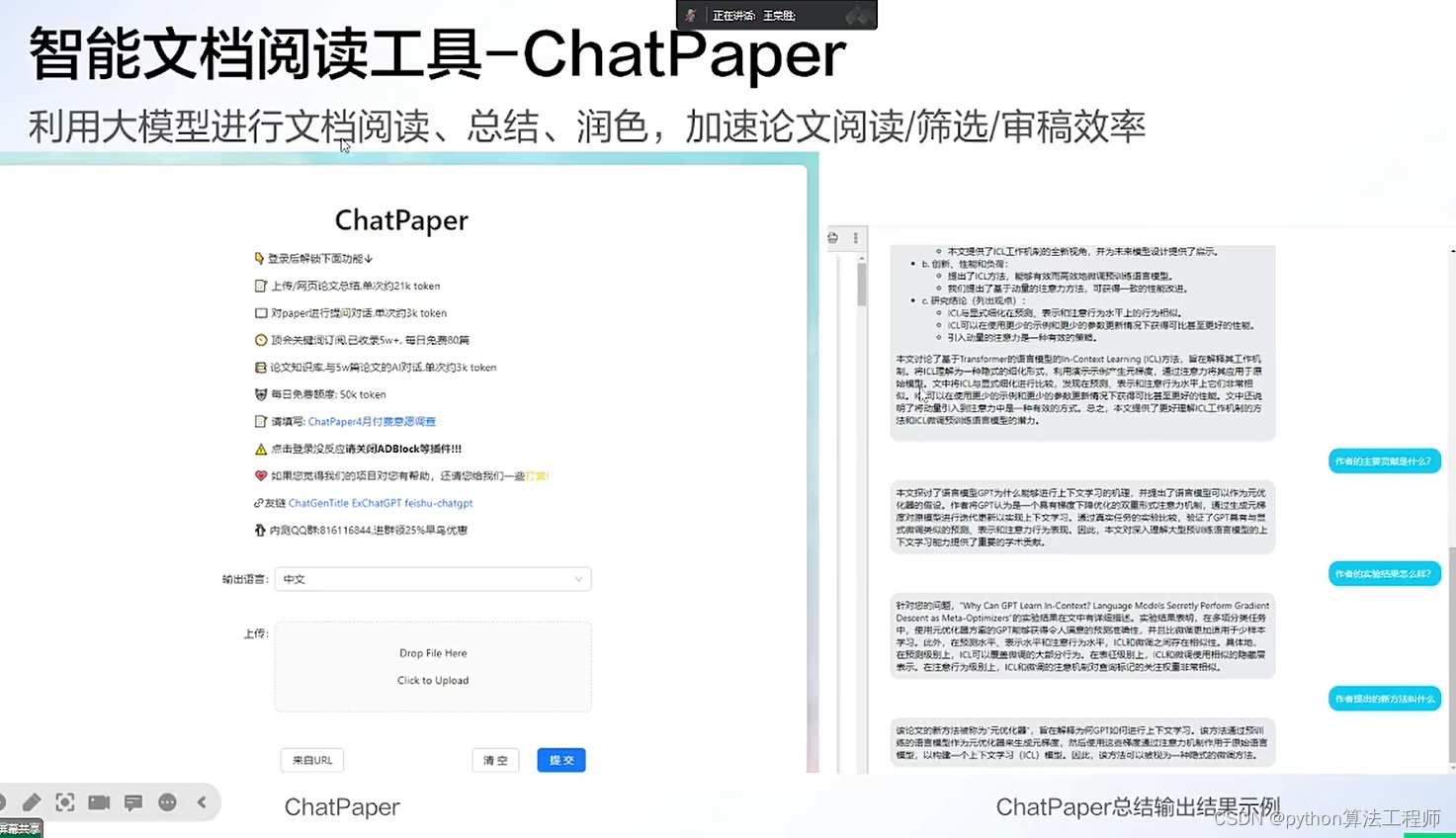
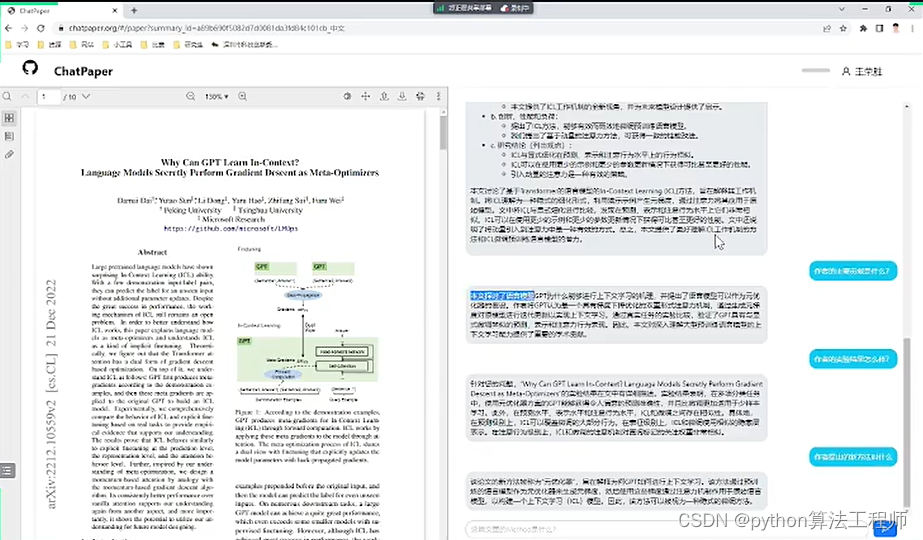
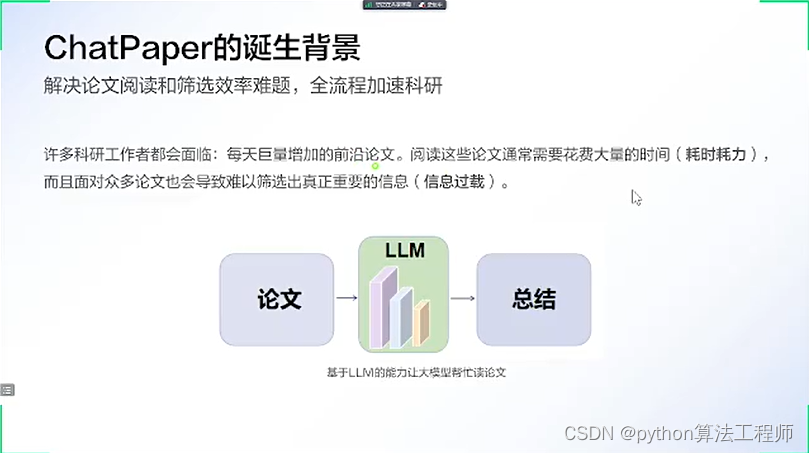
chatpaper.org

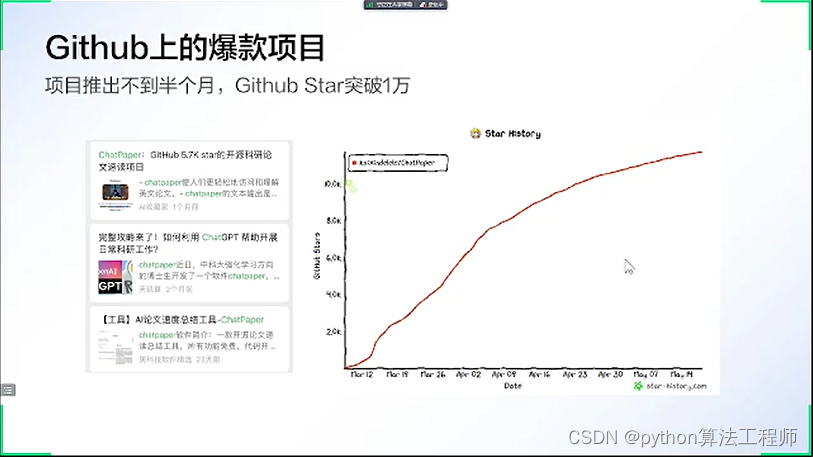


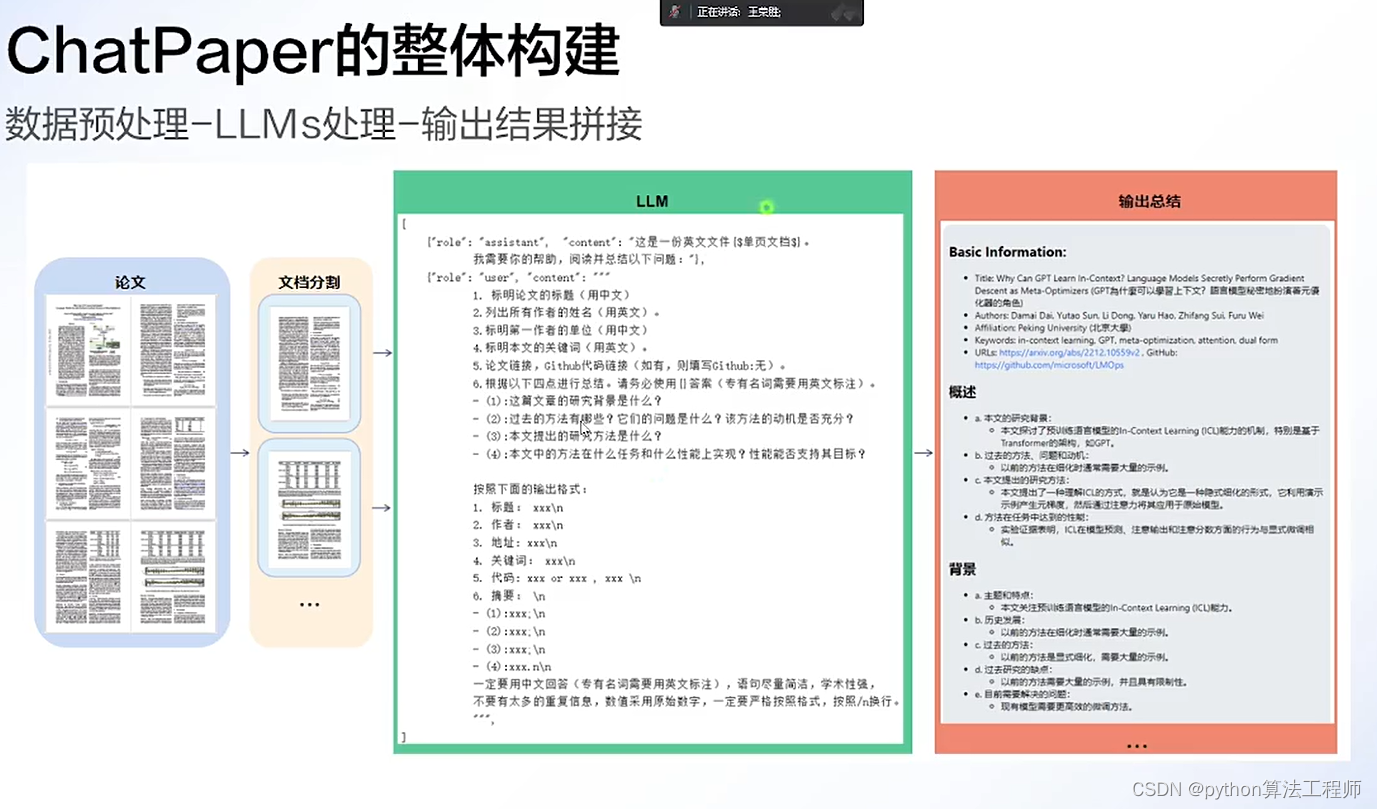


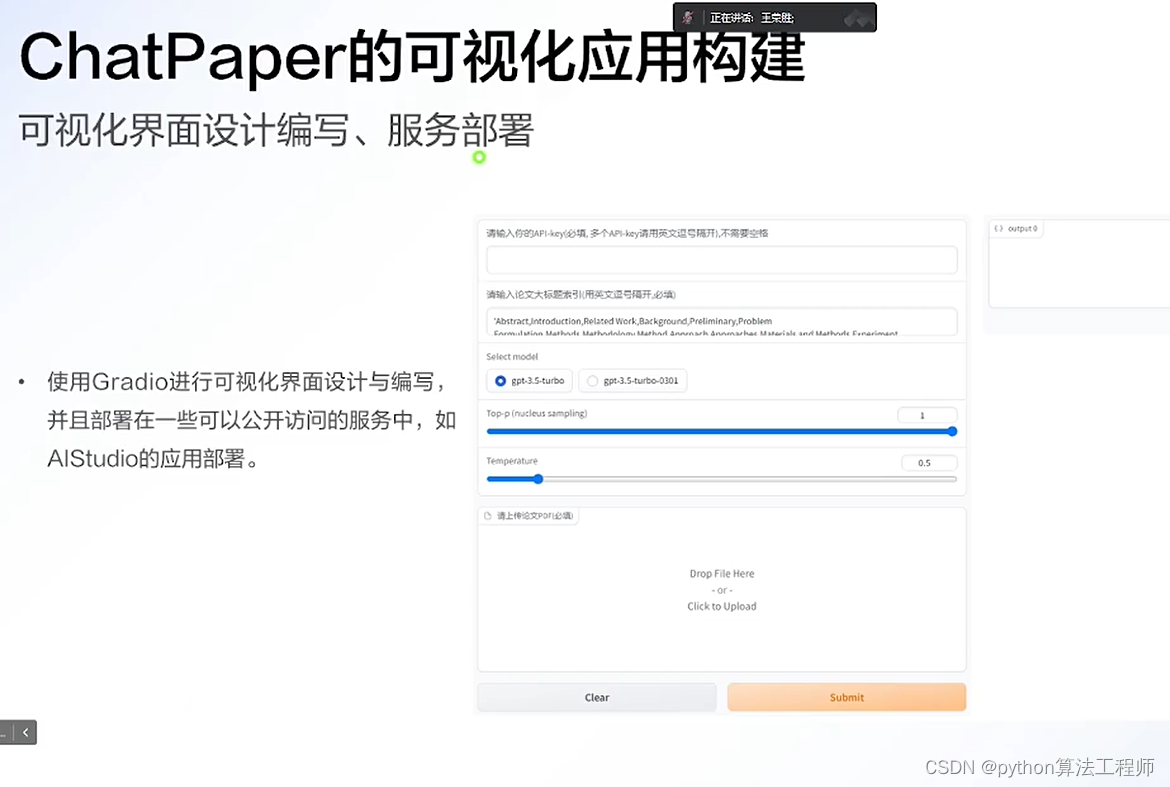

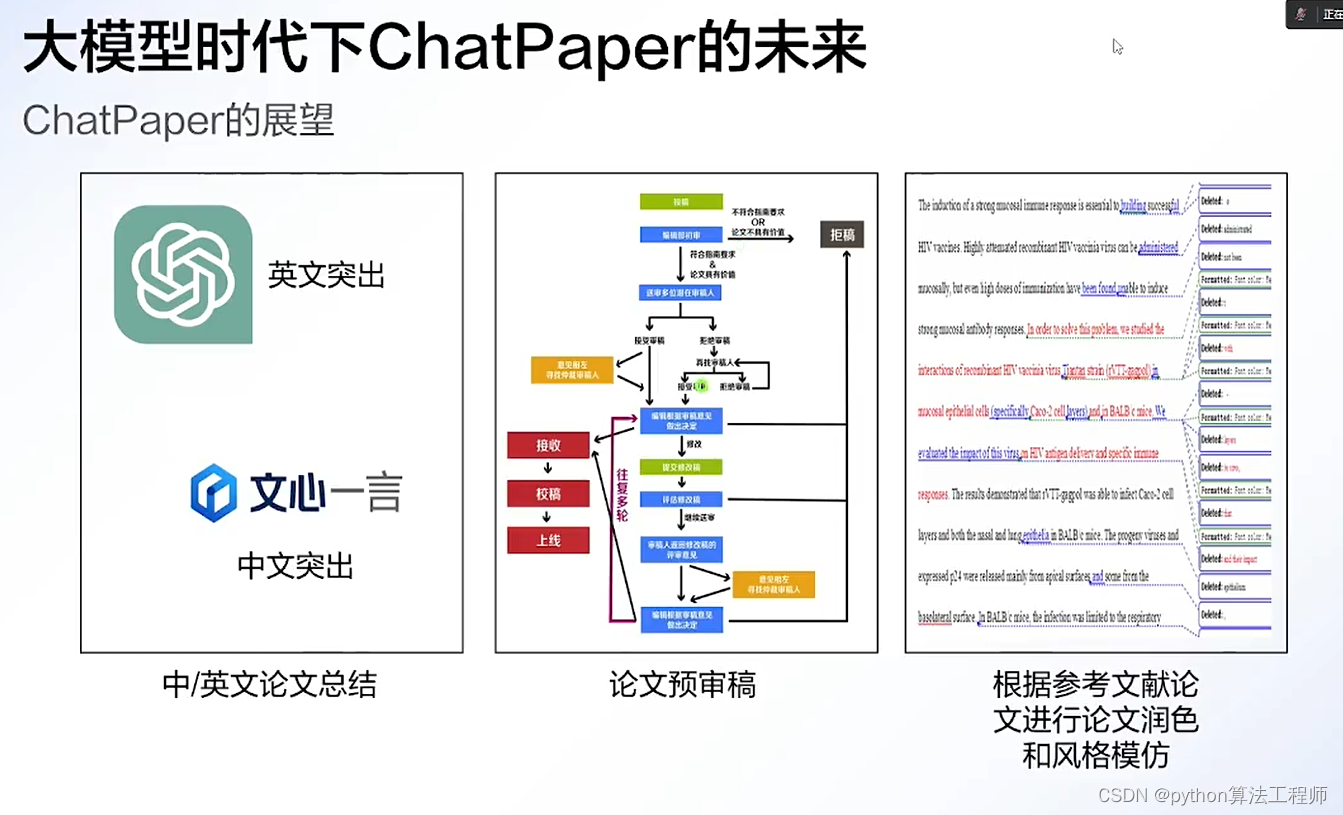

一個人去看LOL世界總決賽(過少的數據集),他非常認真的看,記錄了職業選手的每一個細節(試圖擬合所有數據),然后反復研究(訓練),最后總結出來了一套方案(模型)。
結果他用這套方案去打排位,結果打得非常死板,出裝只會一套,打法也只會一種(過擬合)。
以上我們得知,過擬合就是對少年數據的過度模仿,的導致得出的結論沒辦法靈活運用的情況。
那我們要怎么解決這種情況呢?
假設我們最終的目的是要上分,那我們該怎么學呢1.搞清楚什么東西是沒必要學的(減少特征)
有些東西對于上分是沒幫助或者說幫助極小的,比如怎么做大笑動作嘲諷對手,亮狗牌嘲諷,這就不用學了。(某些特征對模型訓練并不會有幫助,強行要擬合所有特征,會增加模型的復雜度)
2.多看比賽,而不只是只看一場(增大訓練量)
看職業玩家在各種情況下。面對各種對手的操作(大量的數據集),最終研究出一個適用性廣的打法。
3.不用整場比賽都看完(提前結束)
看到拿巴龍,四條或龍魂加上遠古巨龍,就可以不用看后面的了(足夠準確),因為后面的操作已經不會對戰局有什么影響了,繼續看的話,可能還會看到優勢太大浪輸了。
4.挑有用的來學(正則化)
學怎么控線,學大局意識的培養。絲血反殺,極限操作就不要花太多精力學了,可能弄巧成拙(降低部分特征的權重,L1正則最低可以降低到0)
https://chat.juicebox.work/project/lIrjr6lje9Z9BHAQdEiJ

微軟開源Copilot Chat:新增數據導入!可打造專屬ChatGPT
https://redian.news/wxnews/353910
https://devblogs.microsoft.com/semantic-kernel/announcing-copilot-chat/
https://moyincloud.com/article/1656237038590087170.html
AI助手工具
-
文本轉換成語音 → http://Lovo.ai
-
圖片生成→ http://Dreamstudio.ai
-
寫作 → http://Writesonic.com
-
ChatGPT 提示詞 → http://Wnr.ai
-
網站建設 → http://Durable.co
-
會議總結 → http://Tldv.io
-
寫推特 → http://Postwise.ai
-
AI社交平臺:https://chirper.ai/zh
里面都是AI機器人在發社交Feed
陸奇最新演講實錄:我的大模型世界觀
就連陸奇都說他跟不上大模型時代的狂飆速度了。“我實在不行了,論文實在是跟不上,代碼實在是跟不上。Just too much(太多了)。”陸奇在近期一次分享活動上說。
https://www.ccvalue.cn/article/1410502.html
https://app.copilothub.ai/home
前沿技術探索
https://donotpay.com
https://www.hippocraticai.com
https://replit.com
https://replicate.com
https://www.chatpdf.com
https://www.baihai.co/studio
https://dashboard.cohere.ai
https://openbayes.com
https://www.pingwest.com/a/282651
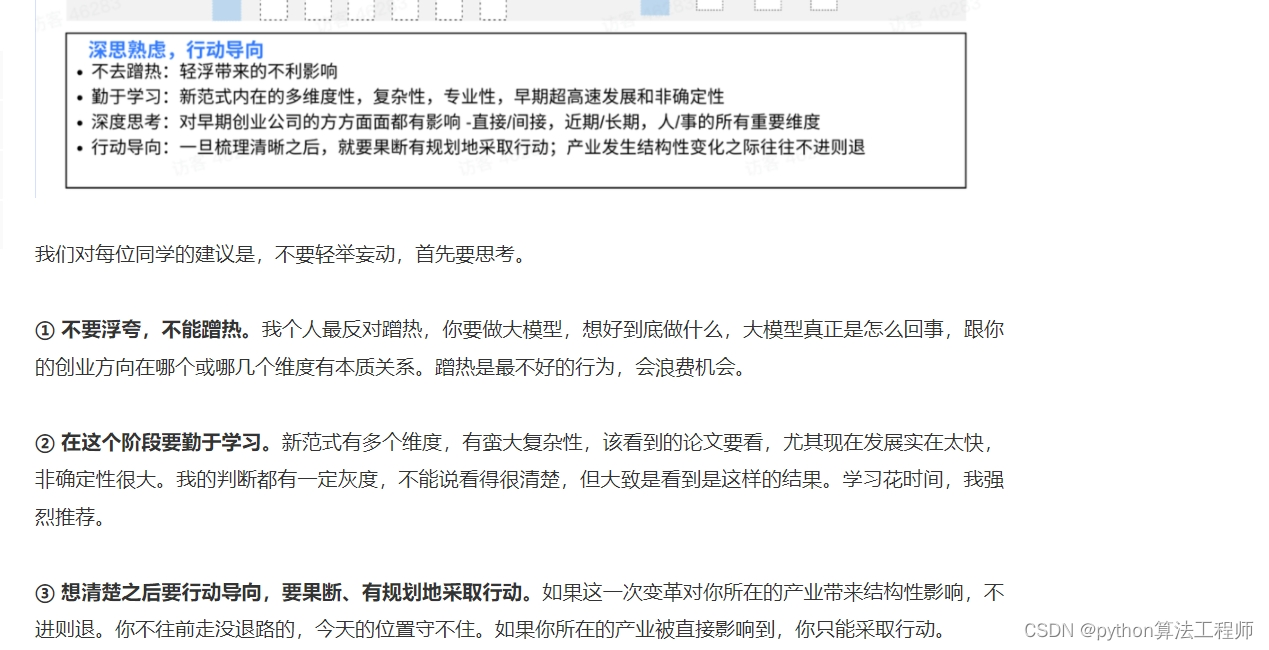
中文醫療大模型的2W1H分析
圍繞具體任務組件,可能的一種實現是:針對每個任務采用高效微調的方法,在預測時對不同任務調用不同的高效微調模塊(比如LoRA等)。
 回歸價值本身,對于多數場景下,用戶更加關心地是問題有沒有得到解決,至于解決的方法是不是中文醫療大模型,也許并不重要。在主流敘事的背景下,有了更好,如果沒有,理論上問題也不大。但是,對于新問題要得到解決,大概率技術側還是會落在大模型的方向上。
回歸價值本身,對于多數場景下,用戶更加關心地是問題有沒有得到解決,至于解決的方法是不是中文醫療大模型,也許并不重要。在主流敘事的背景下,有了更好,如果沒有,理論上問題也不大。但是,對于新問題要得到解決,大概率技術側還是會落在大模型的方向上。
 在預測階段,根據輸入,首先會通過檢索知識大腦(比如知識圖譜)和維基百科,獲取相關的知識,之后將相關知識和輸入通過構建精巧的Prompt作為模型的輸入,返回最終的預測結果。這個階段和DoctorGLM存在異曲同工之妙。
在預測階段,根據輸入,首先會通過檢索知識大腦(比如知識圖譜)和維基百科,獲取相關的知識,之后將相關知識和輸入通過構建精巧的Prompt作為模型的輸入,返回最終的預測結果。這個階段和DoctorGLM存在異曲同工之妙。
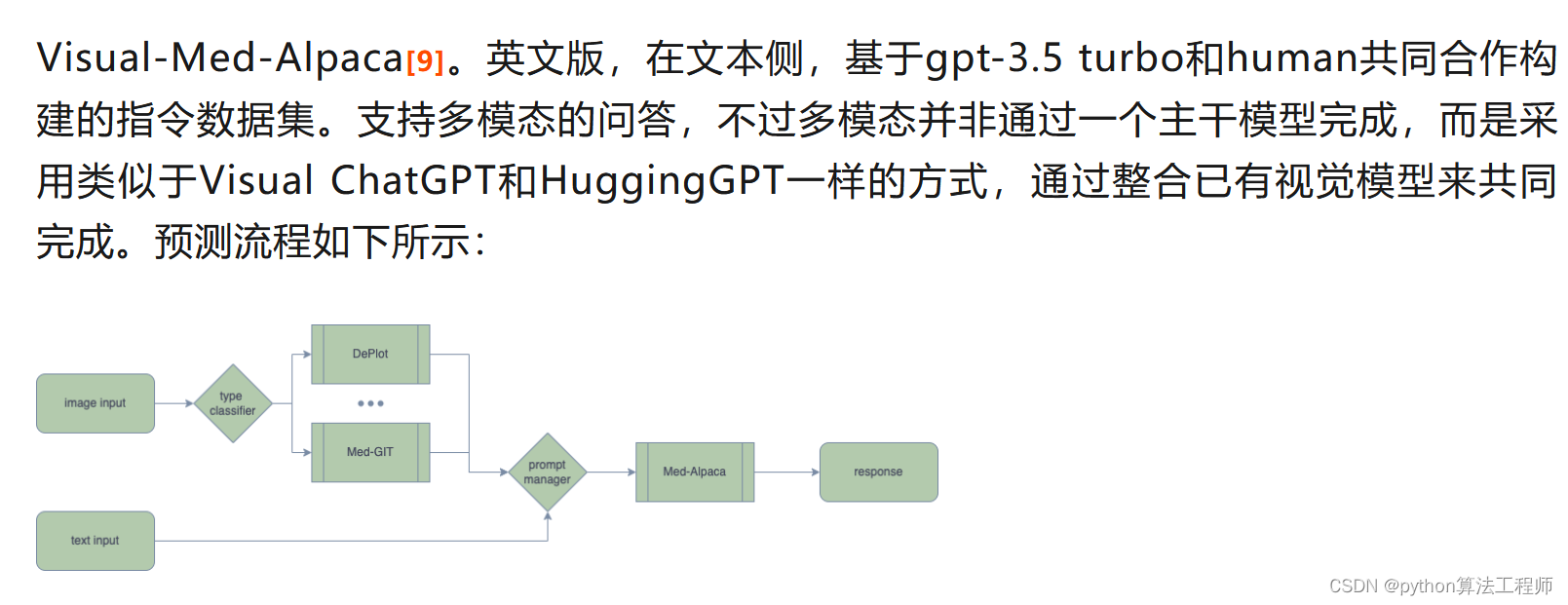

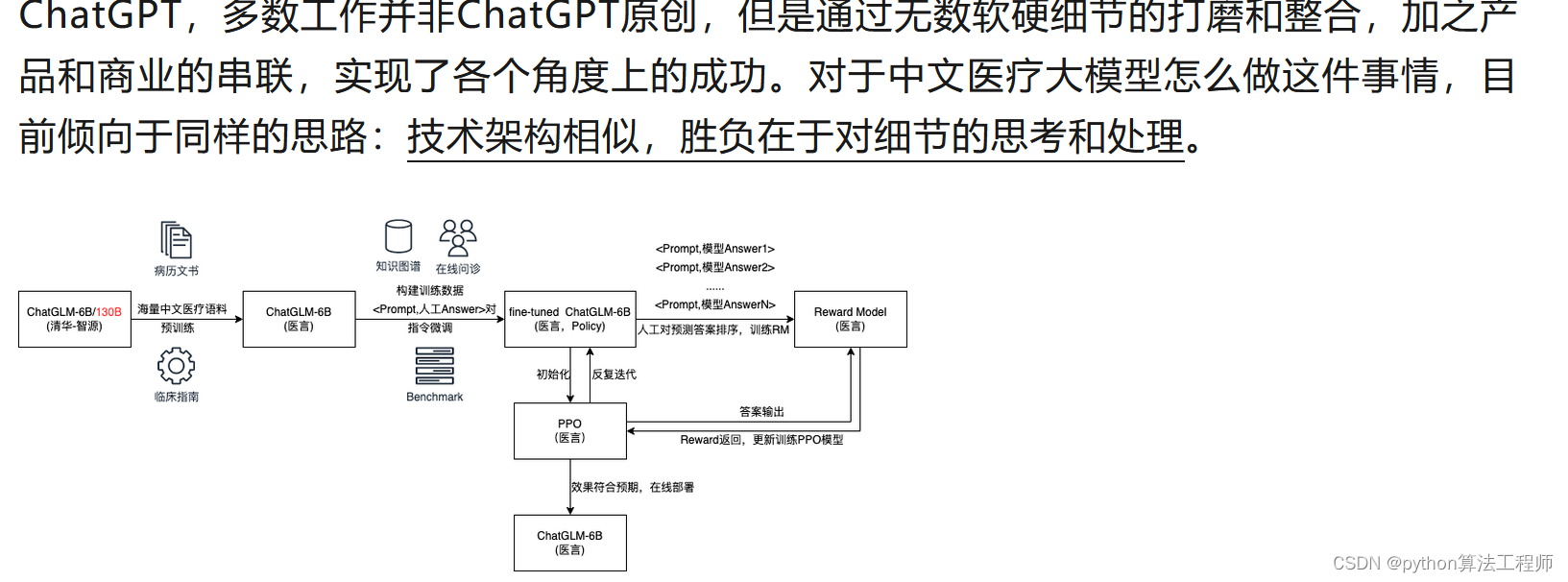 從上圖可以看到,整體的流程基本同ChatGPT相似,包含三個階段,分別是:預訓練階段,指令微調階段,強化學習階段。在階段的優先級選擇上,指令微調>預訓練>強化學習。從左到右,ROI依次降低。是不是覺得很簡單?實則未必。看一下在訓練過程中可能需要的問題,如下:
從上圖可以看到,整體的流程基本同ChatGPT相似,包含三個階段,分別是:預訓練階段,指令微調階段,強化學習階段。在階段的優先級選擇上,指令微調>預訓練>強化學習。從左到右,ROI依次降低。是不是覺得很簡單?實則未必。看一下在訓練過程中可能需要的問題,如下:
如何構建大模型的評估體系?
預訓練和指令微調的數據構建和任務訓練的差異性在哪里?
什么時候發生模型記憶性遺忘,如何避免?
模型常見的參數選擇策略是什么?
如何實現支持更長上下文,比如32K?
中文詞典要不要進行改造,怎么做中文詞典擴充與剪裁?
如何做顯存占用估計?
如何讓模型輸出的結果更加地結構化以直接用于應用?
怎么做可以提升模型輸出的質量?
多機多卡能跑起來嗎?
模型推理的cost是什么?如何實現模型推理加速?
如何降低模型的部署成本?
…
chatgpt插件
https://openai.com/blog/chatgpt-plugins






https://platform.openai.com/docs/api-reference/introduction

瘋狂的幻方:一家隱形AI巨頭的大模型之路
https://wallstreetcn.com/articles/3689518
RLFH人類反饋強化學習
要訓練一個獎勵模型
https://www.bilibili.com/video/BV1jT411W7Gr/?spm_id_from=333.337.search-card.all.click&vd_source=569ef4f891360f2119ace98abae09f3f
DeepSpeed Chat
 https://www.bilibili.com/video/BV1Th4y1p7Di/?spm_id_from=333.337.search-card.all.click&vd_source=569ef4f891360f2119ace98abae09f3f
https://www.bilibili.com/video/BV1Th4y1p7Di/?spm_id_from=333.337.search-card.all.click&vd_source=569ef4f891360f2119ace98abae09f3f
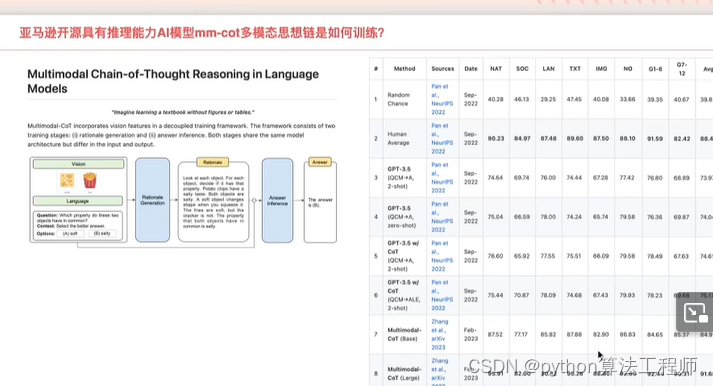
谷歌開源T5 base和large模型上進行MM-CoT模型微調,實現2.2億參數小模型擁有CoT推理能力,并在科學問答數據集準確率超越人類

 http://e.betheme.net/article/show-1277574.html?action=onClick
http://e.betheme.net/article/show-1277574.html?action=onClick
Segment Anything for Stable Diffusion WebUI安裝學習資料
https://www.bilibili.com/video/BV1Vh411F7Zn/?spm_id_from=333.1007.tianma.1-2-2.click
https://dirk3j7xco.feishu.cn/docx/MM2Cdqz6ioU40kxEhURcLMLDn1d
LoRA從原理到實踐,零基礎打造賽博Coser、一鍵更換服飾,無所不能!5大應用方向剖析 & 保姆級講解!Stable Diffusion
你將掌握在StableDiffusion WebUI中利用LoRA出圖作畫的三種基本途徑,并學會利用LoRA實現高度自定義的人物角色形象(Character)、畫風或風格(Style)、概念(Concept)、服飾(Cloth/Costume)還有特定元素(Object)呈現。
https://www.bilibili.com/video/BV1nL411B7XT/?spm_id_from=333.1007.tianma.1-2-2.click&vd_source=569ef4f891360f2119ace98abae09f3f
各種lora模型
https://civitai.com
qat量化
不消耗token的emdeding算法加向量數據庫實現關于embeddings:
但是OpenAI的文本嵌入接口對中文的支持并不好,社區經過實踐,對中文支持比較好的模型是Hugging face上的 ganymedenil/text2vec-large-chinese。具體可以參見:https://huggingface.co/GanymedeNil/text2vec-large-chinese/discussions/3 ,作者采用的訓練數據集是 中文STS-B數據集。它將句子映射到 768 維密集向量空間,可用于任務 如句子嵌入、文本匹配或語義搜索。
https://github.com/shibing624/text2vec/blob/master/README.md
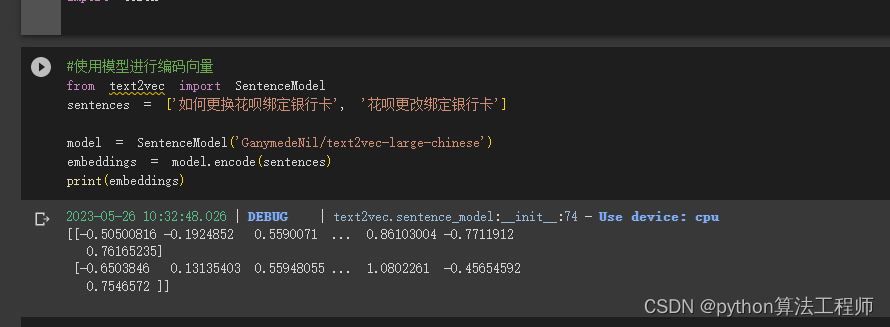 使用cpu進行編碼會非常的慢
使用cpu進行編碼會非常的慢
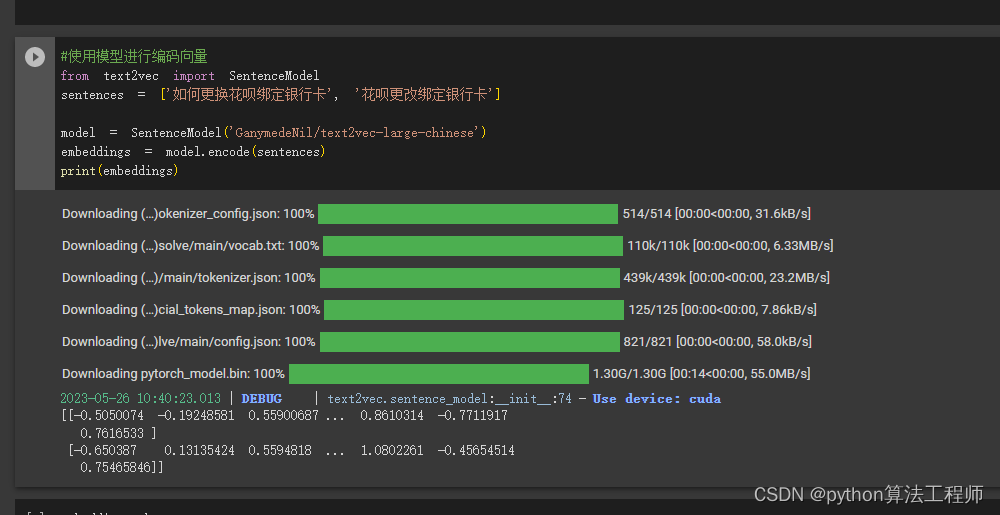 使用gpu進行編碼比較快
使用gpu進行編碼比較快
!pip install transformers
!pip install text2vec
!pip install pinecone
import pinecone
import pinecone
from text2vec import Similarity
from transformers import AutoTokenizer, AutoModel
import os
import torch
import text2vec# index_name = 'gpt-4-langchain-docs'
index_name = "text2vec-large-chinese"
# index_name = "langchain-demo"# initialize connection to pinecone
pinecone.init(api_key="a18fcdac-a3ab-4755-a87a-352d0ef74ee9", # app.pinecone.io (console)environment="us-west4-gcp-free" # next to API key in console
)# check if index already exists (it shouldn't if this is first time)
if index_name not in pinecone.list_indexes():# if does not exist, create indexpinecone.create_index(index_name,# dimension=len(res['data'][0]['embedding']),len(sentence_embeddings[0]),metric='dotproduct')
# connect to index
index = pinecone.GRPCIndex(index_name)
# view index stats
index.describe_index_stats()
pinecone.list_indexes()
#導入模型
from transformers import AutoTokenizer, AutoModel
import os
import torch
#使用模型進行編碼向量
from text2vec import SentenceModel
sentences = ['如何更換花唄綁定銀行卡', '花唄更改綁定銀行卡']model = SentenceModel('GanymedeNil/text2vec-large-chinese')
embeddings = model.encode(sentences)
print(embeddings)
#沒有封裝的方法如果沒有 text2vec,您可以這樣使用模型:
#首先,通過轉換器模型傳遞輸入,然后必須在上下文化的單詞嵌入之上應用正確的池化操作。
tokenizer = AutoTokenizer.from_pretrained("GanymedeNil/text2vec-large-chinese")model = AutoModel.from_pretrained("GanymedeNil/text2vec-large-chinese")
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):token_embeddings = model_output[0] # First element of model_output contains all token embeddingsinput_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
sentences = ['如何更換花唄綁定銀行卡', '花唄更改綁定銀行卡']
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')# Compute token embeddings
with torch.no_grad():model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
index.upsert(vectors=list())
print("Sentence embeddings:")
print(sentence_embeddings)fastAPI服務
安裝: pip install fastapi uvicorn
啟動服務:
示例:examples/fastapi_server_demo.py
cd examples
python fastapi_server_demo.py
調用服務:
curl -X ‘GET’
‘http://0.0.0.0:8001/emb?q=hello’
-H ‘accept: application/json’
# -*- coding: utf-8 -*-
"""
@author:XuMing(xuming624@qq.com)
@description:
"""
import time
import syssys.path.append('..')
from jina import Client
from docarray import Documentport = 50001
c = Client(port=port)def jina_post():r = c.post('/', inputs=[Document(text='如何更換花唄綁定銀行卡'), Document(text='花唄更改綁定銀行卡')])return rdef encode(c, sentences):def gen_docs(sent_list):for s in sent_list:if isinstance(s, str):yield Document(text=s)r = c.post('/', inputs=gen_docs(sentences), request_size=256)return rif __name__ == '__main__':data = ['如何更換花唄綁定銀行卡','花唄更改綁定銀行卡']print("data:", data)r = jina_post()print(r.embeddings)print('batch embs:', encode(c, data).embeddings)num_tokens = sum([len(i) for i in data])# QPS testfor j in range(9):tmp = data * (2 ** j)c_num_tokens = num_tokens * (2 ** j)start_t = time.time()r = encode(c, tmp)if j == 0:print('batch embs:', r.embeddings)print('count size:', len(r))time_t = time.time() - start_tprint('encoding %d sentences, spend %.2fs, %4d samples/s, %6d tokens/s' %(len(tmp), time_t, int(len(tmp) / time_t), int(c_num_tokens / time_t)))
sadtalker虛擬數字人
https://huggingface.co/spaces/vinthony/SadTalker
在線圍觀地址:https://reverie.herokuapp.com/arXiv_Demo/#
謝謝大佬的分享:https://github.com/Winfredy/SadTalker
20230409教程更新: https://www.bilibili.com/video/BV1Dc411W7V6/?vd_source=c4fdd4c34625755ad12bd28f277b4099
GPT插件Code Interpreter是真的牛,你不會的他全會,表哥表姐們必看!
https://www.bilibili.com/video/BV1mz4y1b7W1/?spm_id_from=333.1007.tianma.2-1-4.click&vd_source=569ef4f891360f2119ace98abae09f3f
chatgpt使用松果做數據增強
https://colab.research.google.com/drive/1rk5PqXNFB0kQoc5gK4qWamoWNHrpLAva#scrollTo=xo9gYhGPr_DQ
chatgpt微調
https://platform.openai.com/docs/guides/fine-tuning/fine-tuning



 https://www.bilibili.com/video/BV1DU4y1c77Y/?spm_id_from=333.337.search-card.all.click&vd_source=569ef4f891360f2119ace98abae09f3f
https://www.bilibili.com/video/BV1DU4y1c77Y/?spm_id_from=333.337.search-card.all.click&vd_source=569ef4f891360f2119ace98abae09f3f
ChatGLM-微調
https://github.com/liucongg/ChatGLM-Finetuning
https://github.com/THUDM/ChatGLM-6B/tree/main/ptuning
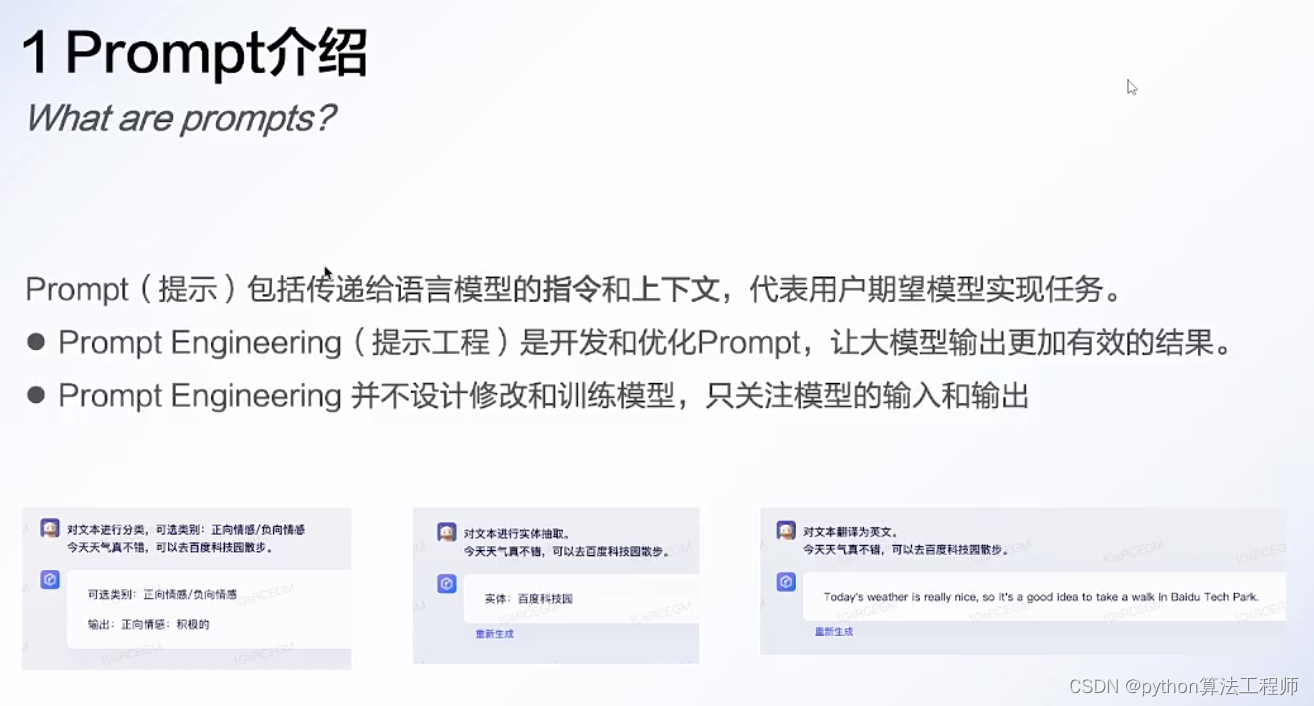
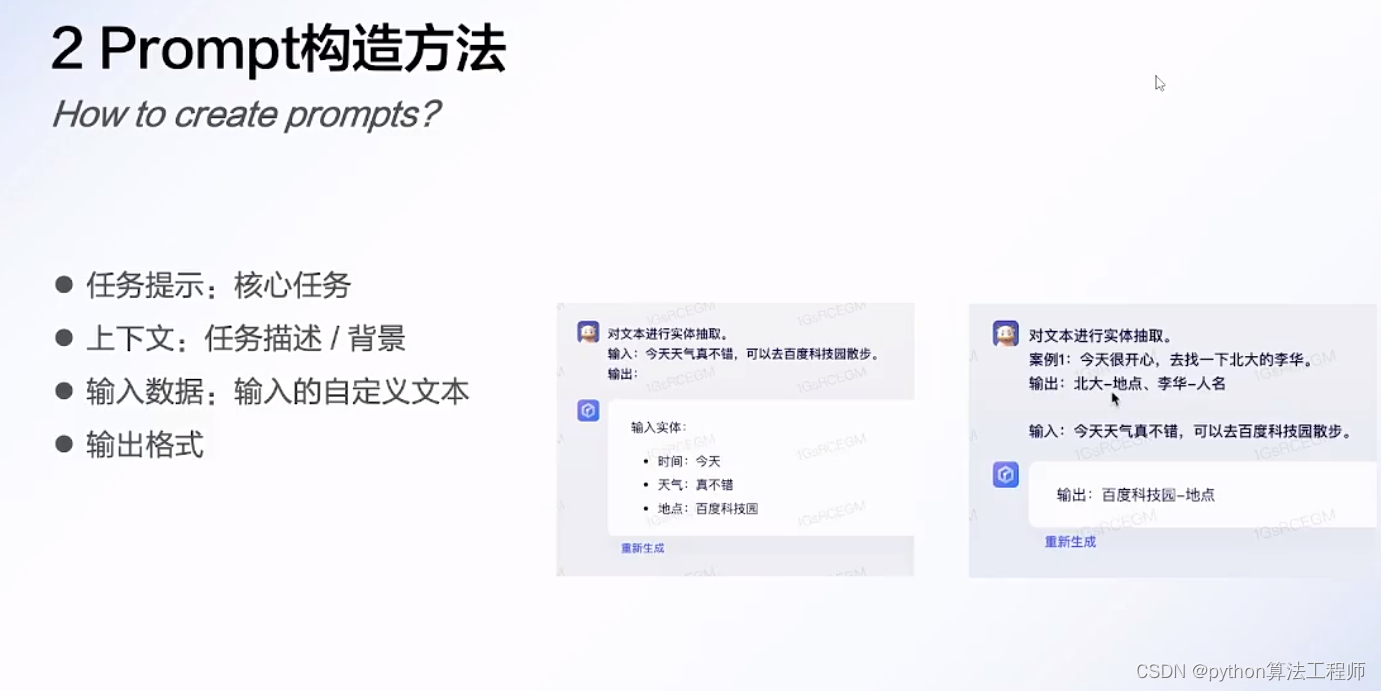
Prompt介紹















模型排名網站
lmsys.org
https://github.com/THUDM/GLM-130B
提示詞模板
wnr.ai
Prompt中文指南(四)讓模型循環思考行動
autogpt技術原理分析,如何寫好思維鏈(COT)
火熱的Auto-Gpt解析技術原理
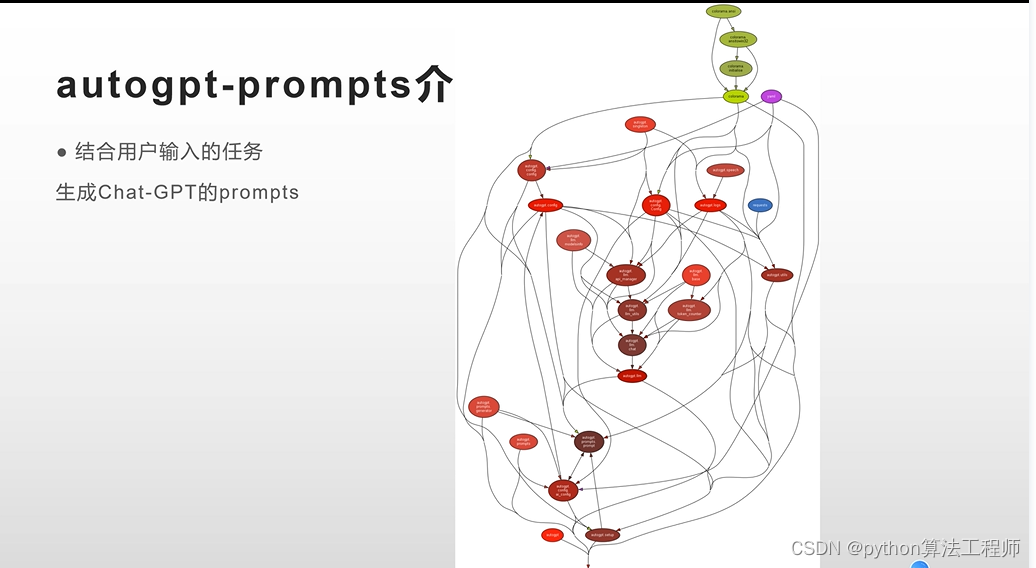
任務轉換可讀結構化數據如下:
{"task": "介紹春節文化","steps": [{"step": "收集資料和信息","input": {"keywords": ["春節", "文化"]},"output": {"資料1": {"標題": "春節的起源","內容": "春節是中華文化的重要節日,起源于古代的歲首祭祖活動。在農歷正月初一,人們會燃放煙花,貼對聯、飲酒、賞燈等,以慶祝新年的到來。"},"資料2": {"標題": "春節的傳統習俗","內容": "春節有許多豐富多彩的傳統習俗,如貼春聯、守歲、祭祖、舞龍燈等,這些習俗代表著祝福和吉祥之意。"},"資料3": {"標題": "春節的民俗文化","內容": "春節也有著豐富的民俗文化,如戲曲、民間藝術、美食等,這些文化不僅豐富了人們的生活,也是中華文化的瑰寶之一。"}}},{"step": "整理資料","input": {"資料1": {"標題": "春節的起源","內容": "春節是中華文化的重要節日,起源于古代的歲首祭祖活動。在農歷正月初一,人們會燃放煙花,貼對聯、飲酒、賞燈等,以慶祝新年的到來。"},"資料2": {"標題": "春節的傳統習俗","內容": "春節有許多豐富多彩的傳統習俗,如貼春聯、守歲、祭祖、舞龍燈等,這些習俗代表著祝福和吉祥之意。"},"資料3": {"標題": "春節的民俗文化","內容": "春節也有著豐富的民俗文化,如戲曲、民間藝術、美食等,這些文化不僅豐富了人們的生活,也是中華文化的瑰寶之一。"}},"output": {"分類1": {"名稱": "春節的起源","內容": "春節是中華文化的重要節日,起源于古代的歲首祭祖活動。在農歷正月初一,人們會燃放煙花,貼對聯、飲酒、賞燈等,以慶祝新年的到來。"},"分類2": {"名稱": "春節的傳統習俗","內容": "春節有許多豐富多彩的傳統習俗,如貼春聯、守歲、祭祖、舞龍燈等,這些習俗代表著祝福和吉祥之意。"},"分類3": {"名稱": "春節的民俗文化","內容": "春節也有著豐富的民俗文化,如戲曲、民間藝術、美食等,這些文化不僅豐富了人們的生活,也是中華文化的瑰寶之一。"}}},{"step": "編寫文章大綱","input": {"分類1": {"名稱": "春節的起源","內容": "春節是中華文化的重要節日,起源于古代的歲首祭祖活動。在農歷正月初一,人們會燃放煙花,貼對聯、飲酒、賞燈等,以慶祝新年的到來。"},"分類2": {"名稱": "春節的傳統習俗","內容": "春節有許多豐富多彩的傳統習俗,如貼春聯、守歲、祭祖、舞龍燈等,這些習俗代表著祝福和吉祥之意。"},"分類3": {"名稱": "春節的民俗文化","內容": "春節也有著豐富的民俗文化,如戲曲、民間藝術、美食等,這些文化不僅豐富了人們的生活,也是中華文化的瑰寶之一。"}},"output": {"主題": "春節文化介紹","標題1": "春節的起源","標題2": "春節的傳統習俗","標題3": "春節的民俗文化"}},{"step": "生成文章內容","input": {"分類1": {"名稱": "春節的起源","內容": "春節是中華文化的重要節日,起源于古代的歲首祭祖活動。在農歷正月初一,人們會燃放煙花,貼對聯、飲酒、賞燈等,以慶祝新年的到來。"},"分類2": {"名稱": "春節的傳統習俗","內容": "春節有許多豐富多彩的傳統習俗,如貼春聯、守歲、祭祖、舞龍燈等,這些習俗代表著祝福和吉祥之意。"},"分類3": {"名稱": "春節的民俗文化","內容": "春節也有著豐富的民俗文化,如戲曲、民間藝術、美食等,這些文化不僅豐富了人們的生活,也是中華文化的瑰寶之一。"},"主題": "春節文化介紹","標題1": "春節的起源","標題2": "春節的傳統習俗","標題3": "春節的民俗文化"},"output": {"文章": "春節是中華文化的重要節日,起源于古代的歲首祭祖活動。在農歷正月初一,人們會燃放煙花,貼對聯、飲酒、賞燈等,以慶祝新年的到來。此外,春節還有著許多豐富多彩的傳統習俗,如貼春聯、守歲、祭祖、舞龍燈等,這些習俗代表著祝福和吉祥之意。除了傳統習俗以外,春節還有著豐富的民俗文化,如戲曲、民間藝術、美食等,這些文化不僅豐富了人們的生活,也是中華文化的瑰寶之一。"}},{"step": "排版和發布","input": {"文章": "春節是中華文化的重要節日,起源于古代的歲首祭祖活動。在農歷正月初一,人們會燃放煙花,貼對聯、飲酒、賞燈等,以慶祝新年的到來。此外,春節還有著許多豐富多彩的傳統習俗,如貼春聯、守歲、祭祖、舞龍燈等,這些習俗代表著祝福和吉祥之意。除了傳統習俗以外,春節還有著豐富的民俗文化,如戲曲、民間藝術、美食等,這些文化不僅豐富了人們的生活,也是中華文化的瑰寶之一。"},"output": {"排版和發布結果": "春節是一年中最重要的傳統節日之一,其文化內涵豐富多彩。上述文章就是一篇介紹春節文化的文章,涵蓋了春節的起源、傳統習俗、民俗文化等方面,希望對大家了解春節文化有所幫助。"}}]
}這個結構化數據描述了Auto-GPT需要完成的若干個子任務,每個子任務都包含了輸入、輸出、步驟等信息。Auto-GPT可以按照這個結構化數據進行自主運作,完成整篇文章的自動生成。
15分鐘通俗講解AutoGPT _ 基本原理和流程
autogpt本質基于gpt4,只是會將人類給的復雜任務目標進行拆分(如何拆分也從他的拆分經驗數據庫中得出),之后用拆分的子問題調用gpt4得出結果再組合。如此反復。
太耗費token了,不建議使用
強大的邏輯推理是大語言模型“智能涌現”出的核心能力之一,好像AI有了人的意識一樣。而推理能力的關鍵,在于一個技術——思維鏈(Chain of Thought,CoT)。
https://m.thepaper.cn/newsDetail_forward_22900584
https://learnprompting.org/zh-Hans/docs/intro
GPT增效70%,TOT思維樹雙星刷榜
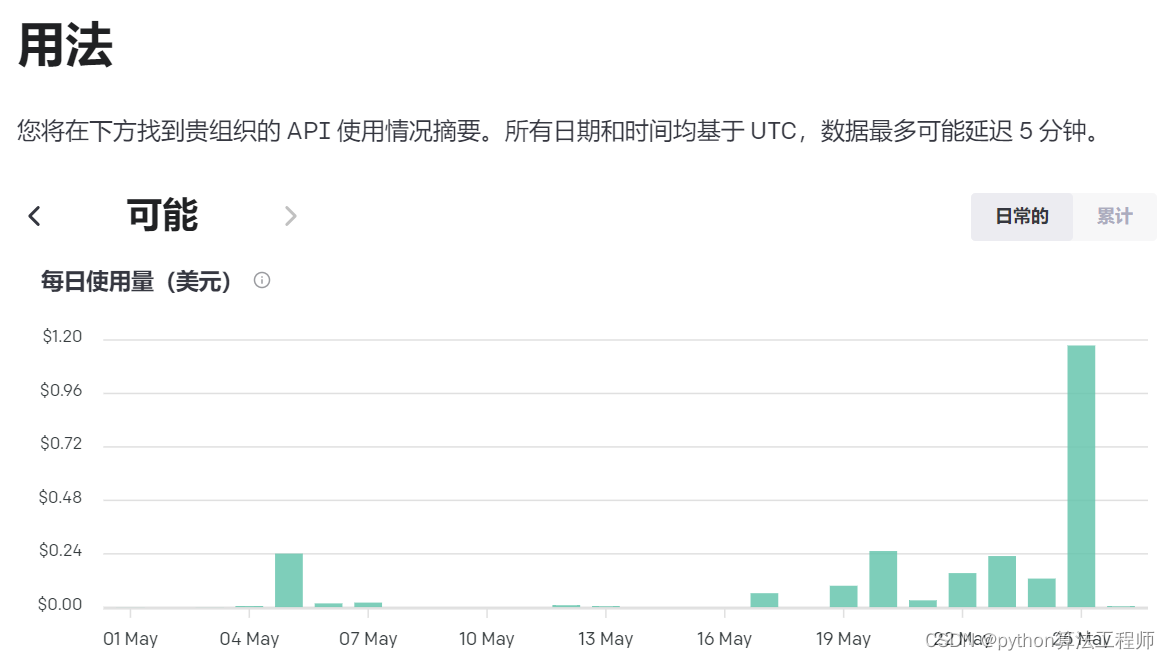
個人用搞個10 20條 就30元
完成一個小任務就30元人民幣
我讓gpt3.5寫一篇介紹馬斯克的小短文,就迭代了一次1.2美元沒了
 https://user-images.githubusercontent.com/70048414/232352935-55c6bf7c-3958-406e-8610-0913475a0b05.mp4
https://user-images.githubusercontent.com/70048414/232352935-55c6bf7c-3958-406e-8610-0913475a0b05.mp4
https://github.com/Significant-Gravitas/Auto-GPT
https://www.bilibili.com/video/BV1qT411b7wd/?spm_id_from=333.337.search-card.all.click&vd_source=569ef4f891360f2119ace98abae09f3f

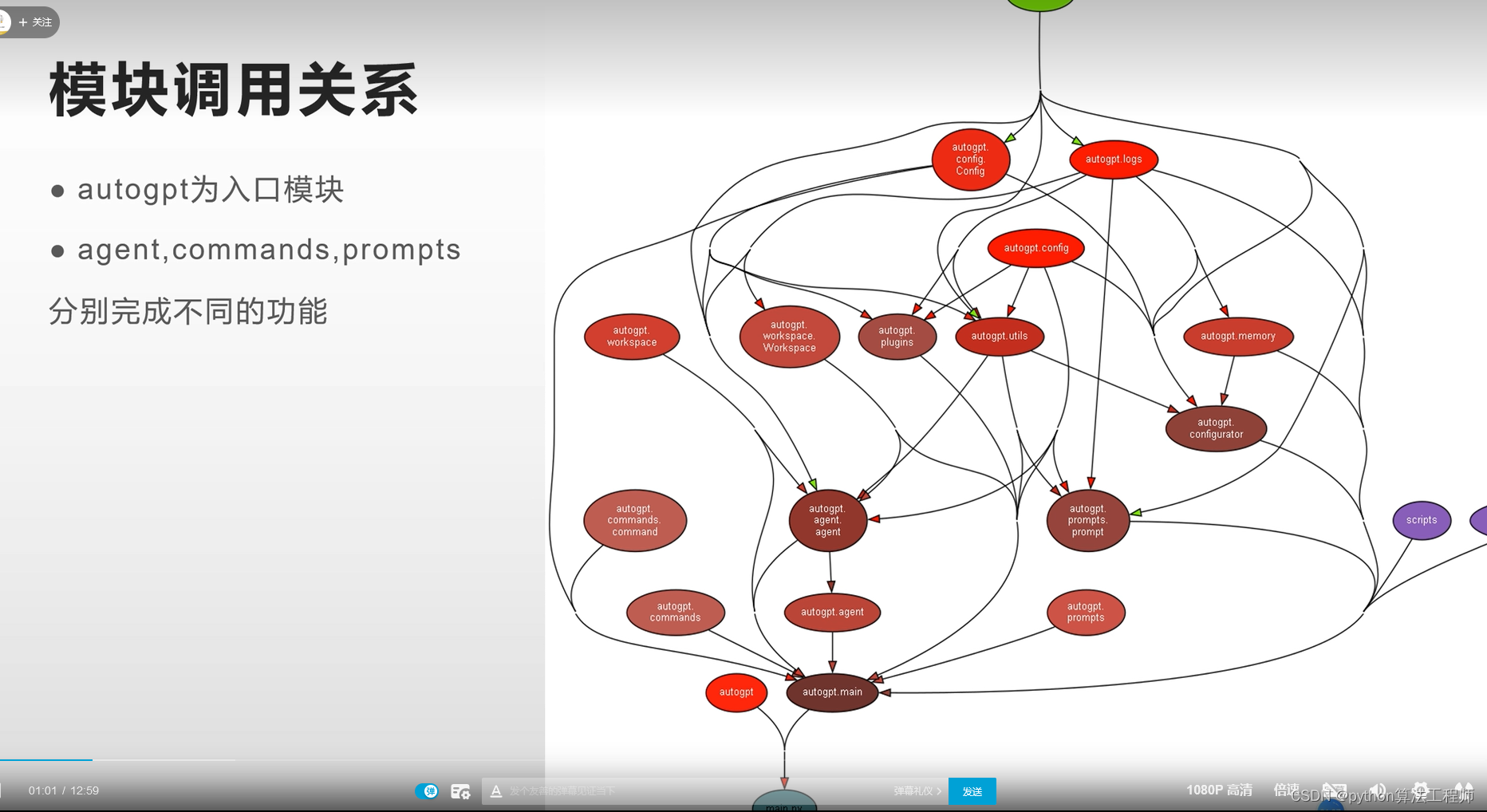
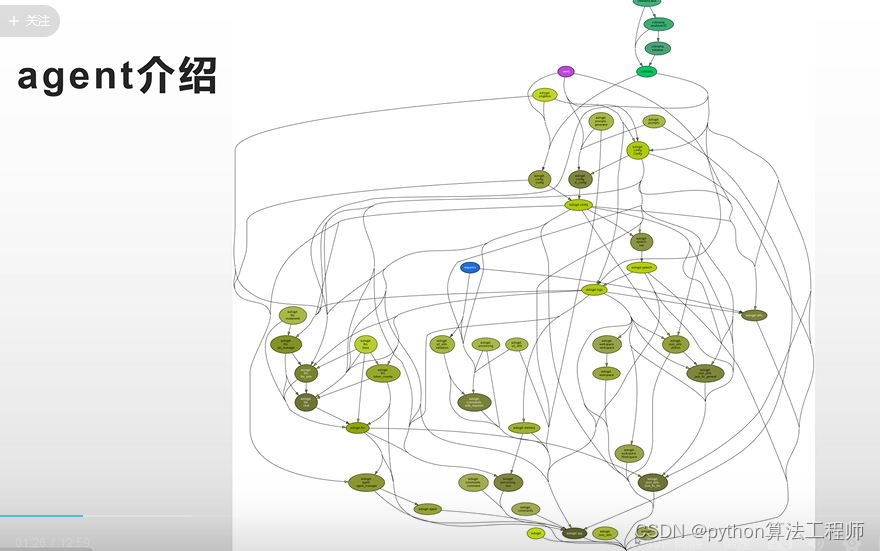 最核心的模塊
最核心的模塊
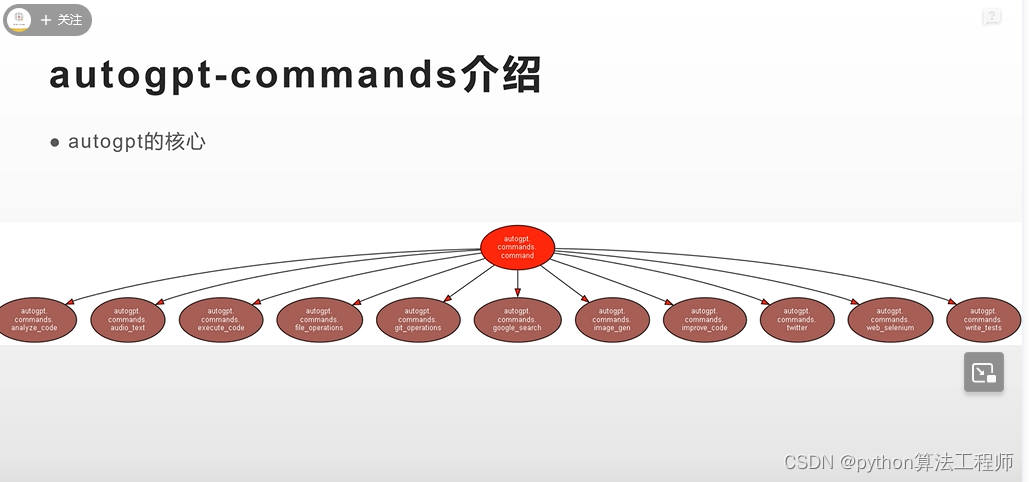
autogpt可以在google里進行搜索信息,可以自動發推特
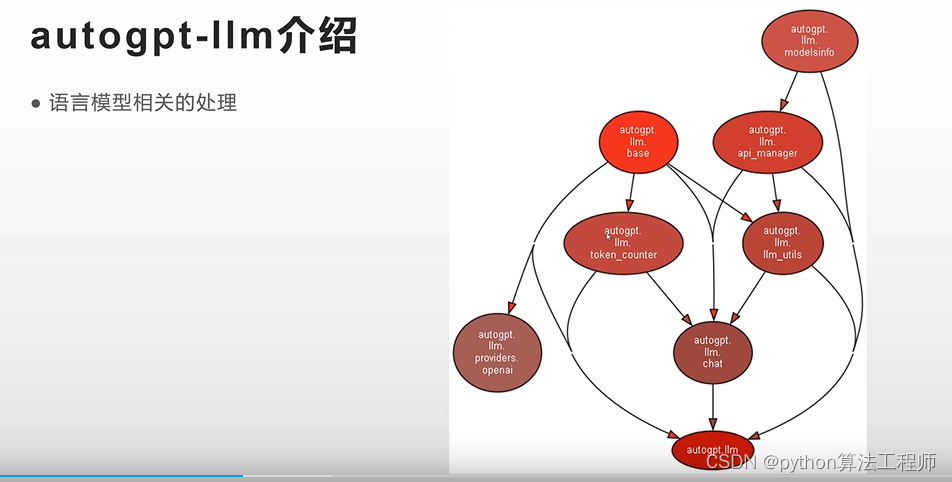 chatgpt接口的封裝,token的計算
chatgpt接口的封裝,token的計算
AutoGPT好玩嗎?一天5000塊的燒錢體驗
我也玩了一下午,感覺就像脫韁的哈士奇[笑哭],你看它似乎干了什么,但是又好像沒干。網絡上那些說怎么著的我嚴重懷疑他們玩沒玩過,一般玩過的人都會說:現階段問題很多,但是前景很不錯。
這個東西就現階段感覺很垃圾,因為你按照他拆分的任務去做其實很快就搞定了,因為人是可以使用感性去比較選擇的,而讓機器通過理性去做選擇,那么結果就是十萬個為什么+余額不足![doge]
還沒用過gpt4的api,3.5 turbo是真的蠢,主要是記憶力太差,讓它自己每一步給自己記錄個log并查看似乎是個解決辦法,但我trial額度用完了…
langflow低代碼開發langchina
https://github.com/logspace-ai/langflow
構建、托管和共享 AI 應用
https://www.steamship.com/
chatgptweb
http://chat.cybart.ist/
test@cybart.ist
安裝LSPosed和應用教程)
)








是藍牙協議棧中用于音頻傳輸的一個標準化協議)


)

)

數組娛樂篇21)
)
