來自上傳文件中的文章《Evolving from Rule-based Classifier: Machine Learning Powered Auto Remediation in Netflix Data Platform》
本文介紹了Netflix如何將基于規則的錯誤分類器與機器學習服務集成,實現Spark作業失敗的自動修復。技術亮點包括結合規則和ML智能、多目標優化性能與成本、全自動化配置應用。方法通過ML模型預測重試成功率和成本,利用貝葉斯優化推薦最佳配置。應用場景如自動修復內存配置錯誤和未分類錯誤,顯著提升修復率和節省計算成本。
文章目錄
- 1 引言
- 1基于規則的分類器:基礎與挑戰
- 1.1 基礎
- 1.2 挑戰
- 2 進化為自動修復:服務架構
- 2.1 方法論
- 2.2 服務集成
- 3 進化為自動修復:機器學習服務
- 3.1 概述
- 3.2 預測模型
- 3.3 優化器
- 4 生產環境推廣
- 5 超越錯誤處理:邁向資源合理配置
本文是Netflix利用數據洞察和機器學習(ML)提升大數據作業性能和成本效率的系列工作中的第一篇。運營自動化——包括但不限于自動診斷、自動修復、自動配置、自動調優、自動擴展、自動調試和自動測試——是現代數據平臺成功的關鍵。在這篇博客中,我們介紹了“自動修復”項目,該項目將當前使用的基于規則的分類器與機器學習服務集成,旨在實現對失敗作業的自動修復,無需人工干預。我們已在生產環境中部署了自動修復,用于處理Spark作業的內存配置錯誤和未分類錯誤,觀察到其高效性和有效性(例如,自動修復了56%的內存配置錯誤,節省了所有錯誤導致的50%貨幣成本),并展現出進一步提升的巨大潛力。
1 引言
Netflix每天在多個大數據平臺層級運行成千上萬的工作流和數百萬個作業。由于如此分布式大規模系統的廣泛范圍和復雜性,即使失敗作業僅占總負載的一小部分,診斷和修復作業失敗也會帶來巨大的運營負擔。
為實現高效的錯誤處理,Netflix開發了一個名為Pensive的錯誤分類服務,利用基于規則的分類器進行錯誤分類。該規則分類器基于預定義規則集對作業錯誤進行分類,并為調度器決定是否重試作業以及工程師診斷和修復失敗提供洞察。
然而,隨著系統規模和復雜性的增加,基于規則的分類器面臨挑戰,尤其是在支持運營自動化方面有限,特別是處理內存配置錯誤和未分類錯誤時。因此,運營成本隨著失敗作業數量線性增長。在某些情況下——例如診斷和修復因內存溢出(OOM)錯誤導致的失敗——需要跨團隊的聯合努力,涉及用戶本人、支持工程師和領域專家。
為解決這些挑戰,我們開發了一個新功能,稱為_自動修復_,它將規則分類器與機器學習服務集成。基于規則分類器的分類結果,機器學習服務預測重試成功概率和重試成本,并選擇最佳候選配置作為推薦;配置服務則自動應用這些推薦。其主要優勢如下:
- 集成智能。 自動修復并未完全廢棄現有的規則分類器,而是將其與機器學習服務結合,充分利用兩者優勢:規則分類器提供基于領域專家上下文的靜態、確定性的錯誤類別分類結果;機器學習服務則針對每個作業提供性能和成本感知的推薦。通過集成智能,我們能夠滿足不同錯誤修復的需求。
- 全自動化。 錯誤分類、獲取推薦和應用推薦的流程完全自動化。它將推薦與重試決策一起提供給調度器,特別是使用在線配置服務存儲并應用推薦配置,從而無需人工干預。
- 多目標優化。 自動修復生成推薦時同時考慮性能(即重試成功概率)和計算成本效率(即作業運行的貨幣成本),避免盲目推薦資源消耗過高的配置。例如,對于內存配置錯誤,它搜索多個與作業執行內存使用相關的參數,推薦能最小化失敗概率與計算成本線性組合的配置組合。
這些優勢已通過生產環境中修復Spark作業失敗的部署得到驗證。我們觀察到自動修復能夠成功修復約56%的內存配置錯誤,在線應用推薦配置無需人工干預;同時,由于能夠推薦新配置使內存配置成功,或禁用不必要的重試,節省了約50%的成本。我們還注意到通過模型調優有很大的提升潛力(詳見“生產環境推廣”部分)。
1基于規則的分類器:基礎與挑戰
1.1 基礎
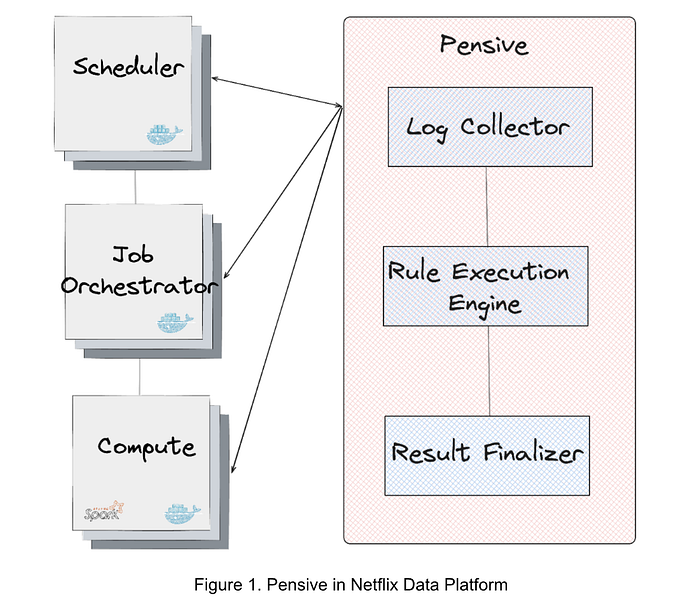
圖1展示了數據平臺中的錯誤分類服務Pensive。它利用基于規則的分類器,由三個組件組成:
- 日志收集器負責從不同平臺層(如調度器、作業編排器和計算集群)拉取日志以進行錯誤分類。
- 規則執行引擎負責將收集的日志與預定義規則集匹配。每條規則包含(1)錯誤名稱、來源、日志和摘要,以及該錯誤是否可重啟;(2)用于從日志中識別錯誤的正則表達式。例如,名為SparkDriverOOM的規則包含信息:如果Spark作業的stdout日志匹配正則表達式
_SparkOutOfMemoryError:_,則該錯誤被分類為用戶錯誤,且不可重啟。 - 結果終結器負責基于匹配的規則最終確定錯誤分類結果。如果匹配到一條或多條規則,則優先級最高(列表中最前)的規則決定最終結果;若無規則匹配,則該錯誤視為未分類。
1.2 挑戰
盡管基于規則的分類器簡單且有效,但其在處理配置錯誤和分類新錯誤方面能力有限,面臨以下挑戰:
- 內存配置錯誤。 規則分類器提供是否重啟的錯誤分類結果,但對于非暫時性錯誤,仍依賴工程師手動修復。最顯著的例子是內存配置錯誤。此類錯誤通常由作業內存配置不當引起:內存過小導致OOM錯誤,內存過大則浪費集群資源。更復雜的是,某些內存配置錯誤需調整多個參數,正確配置不僅需要手動操作,還需Spark作業執行的專業知識。此外,數據規模和作業定義變化也會導致性能退化。數據平臺每月約有600個內存配置錯誤,及時修復需要大量工程投入。
- 未分類錯誤。 規則分類器依賴工程師基于已知上下文手動添加識別錯誤的規則,否則錯誤將被歸為未分類。由于數據平臺各層遷移及應用多樣性,現有規則可能失效,新增規則需投入工程且受部署周期限制。盡管已添加300多條規則,但約50%的失敗仍未分類。對于未分類錯誤,作業可能按照默認重試策略多次重試,若錯誤為非暫時性,這些失敗重試導致不必要的運行成本。
2 進化為自動修復:服務架構
2.1 方法論
為應對上述挑戰,我們的基本方法是將規則分類器與機器學習服務集成生成推薦,并使用配置服務自動應用推薦:
- 生成推薦。 首先用規則分類器對所有錯誤進行基于預定義規則的初步分類,隨后由機器學習服務對內存配置錯誤和未分類錯誤提供推薦。
- 應用推薦。 使用在線配置服務存儲并應用推薦配置。該流程全自動,生成推薦和應用推薦的服務解耦。
2.2 服務集成
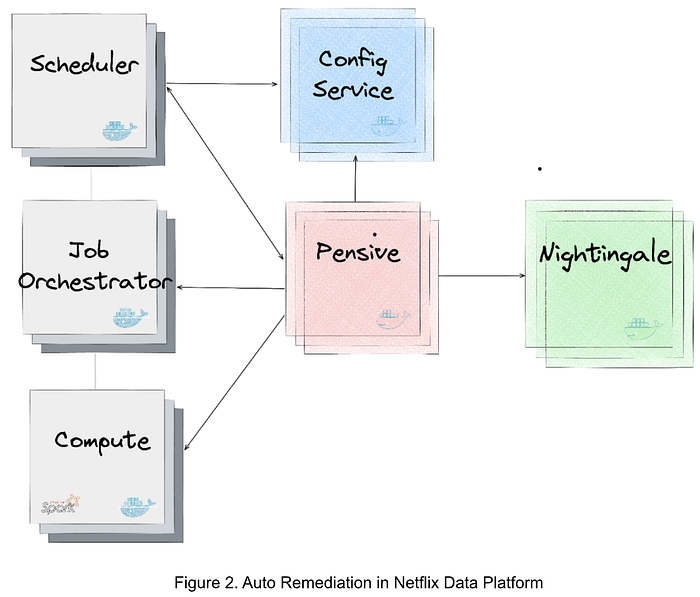
圖2展示了數據平臺中生成和應用推薦的服務集成。主要服務如下:
- Nightingale 是運行機器學習模型的服務,該模型使用Metaflow訓練,負責生成重試推薦。推薦包括(1)錯誤是否可重啟;(2)若可重啟,推薦的重試配置。
- ConfigService 是在線配置服務。推薦配置以JSON補丁形式保存,作用域定義了可使用推薦配置的作業。當調度器調用ConfigService獲取推薦配置時,傳入原始配置,ConfigService返回應用JSON補丁后的變更配置,調度器據此用新配置重試作業。
- Pensive 是利用規則分類器的錯誤分類服務。它調用Nightingale獲取推薦并將推薦配置存入ConfigService,供調度器重試時使用。
- Scheduler 負責調度作業(當前實現基于Netflix Maestro)。每當作業失敗,調用Pensive獲取錯誤分類以決定是否重試,并調用ConfigService獲取重試配置。
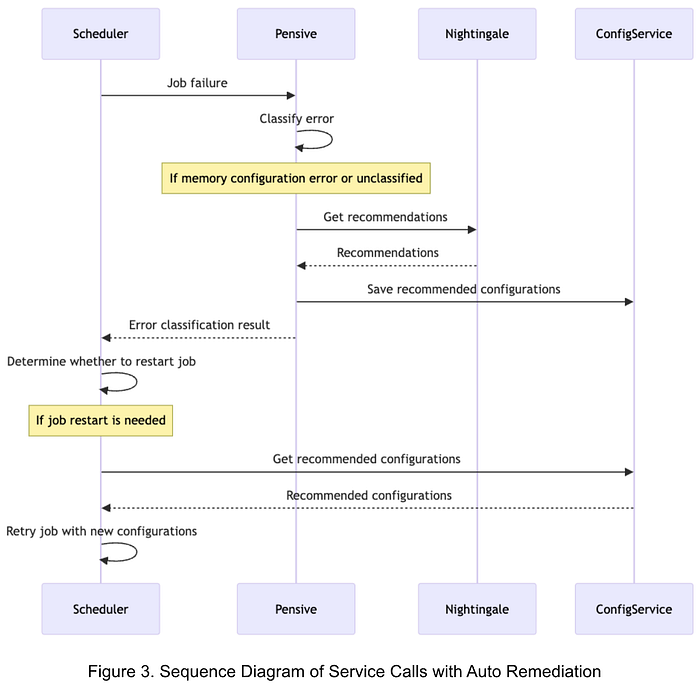
圖3展示了自動修復的服務調用順序:
- 作業失敗時,調度器調用Pensive獲取錯誤分類。
- Pensive基于規則分類器進行錯誤分類。若判定為內存配置錯誤或未分類錯誤,則調用Nightingale獲取推薦。
- Pensive更新錯誤分類結果,保存推薦配置至ConfigService,并將分類結果返回調度器。
- 調度器根據分類結果決定是否重試。
- 重試前,調度器調用ConfigService獲取推薦配置,使用新配置重試作業。
3 進化為自動修復:機器學習服務
3.1 概述
機器學習服務Nightingale旨在為失敗作業生成兼顧重試成功概率和運行成本的重試策略。它包含兩個主要組件:
- 預測模型:聯合估計重試成功概率和重試成本(美元),條件基于重試屬性。
- 優化器:探索Spark配置參數空間,推薦最小化重試失敗概率和成本線性組合的配置。
預測模型每日離線重新訓練,優化器在RESTful服務中運行,作業失敗時調用。若找到可行配置,響應包含推薦配置,ConfigService據此變更重試配置;若無可行方案,響應包含禁用重試的標志,避免浪費計算資源。
3.2 預測模型
為探索不同配置下的重試成功率和成本變化,我們利用作業日志中記錄的重試結果和執行成本作為可靠標簽。由于共享特征集預測兩個目標,標簽充足且需快速在線推理以滿足SLO,我們將問題建模為多輸出監督學習,采用簡單的多層感知機(MLP)模型,設有兩個輸出頭分別預測兩個目標。
訓練: 訓練集中的每條記錄代表一次潛在重試,之前因內存配置錯誤或未分類錯誤失敗。標簽為:a)重試是否失敗,b)重試成本。輸入特征主要是作業的非結構化元數據,如Spark執行計劃、執行用戶、Spark配置參數及其他作業屬性。我們將特征分為可解析為數值和不可解析兩類。對高基數且動態的非數值特征(如用戶名)使用特征哈希處理,生成低維嵌入,與歸一化數值特征連接后輸入后續層。
推理: 通過驗證審核后,模型版本存儲于內部ML平臺提供的Metaflow Hosting服務。優化器針對每個配置請求多次調用模型預測函數,詳見下文。
3.3 優化器
作業失敗時,向Nightingale發送作業標識符,服務據此構造用于推理的特征向量。部分特征為可變的Spark配置參數(如spark.executor.memory、spark.executor.cores),這些是領域專家精選的調優參數。我們使用Meta的Ax庫實現貝葉斯優化,探索配置空間并生成推薦。每次迭代,優化器生成一組候選參數值(如spark.executor.memory=7192 MB,spark.executor.cores=8),調用預測模型估計該配置下的重試失敗概率和成本(即修改特征向量中的參數值)。迭代固定次數后,優化器返回最優配置(最小化失敗概率和成本的線性組合),供ConfigService使用。如無可行配置,禁用重試。
迭代式設計的缺點是任何瓶頸都會阻塞完成并導致超時,初期我們觀察到不少此類情況。通過分析發現,延遲主要來自候選生成步驟(即基于前次評估結果決定下一步方向)。該問題已反饋至Ax庫開發者,新增了GPU加速API選項。利用該選項后,超時率顯著降低。
4 生產環境推廣
我們已在生產環境部署自動修復,處理Spark作業的內存配置錯誤和未分類錯誤。除重試成功率和成本效率外,用戶體驗是主要關注點:
- 內存配置錯誤: 由于無新配置的重試通常失敗,自動修復能成功重試,減少運營負擔并節省運行成本。失敗重試不會惡化用戶體驗。
- 未分類錯誤: 自動修復根據機器學習模型預測是否重試。若重試成功概率極低,推薦禁用重試,節省不必要的運行成本。對于業務關鍵且用戶偏好總重試的作業,可通過新增規則使錯誤由規則分類器識別,跳過機器學習服務推薦。這體現了規則分類器與機器學習服務集成智能的優勢。
生產部署表明,自動修復能有效提供內存配置錯誤的配置推薦,自動修復約56%的內存配置錯誤,無需人工干預。同時,通過推薦新配置或禁用不必要重試,節省約50%的計算成本。性能與成本的權衡可通過機器學習服務調優來實現更高成功率或更多成本節約。
值得注意的是,目前機器學習服務采用保守策略禁用重試,避免影響偏好總重試的用戶。雖然這類情況可通過新增規則解決,我們認為逐步調整目標函數以逐漸禁用更多重試,有助于提供理想用戶體驗。鑒于當前禁用策略較保守,自動修復未來有潛力在不影響用戶體驗的前提下帶來更多成本節約。
5 超越錯誤處理:邁向資源合理配置
自動修復是我們利用數據洞察和機器學習提升用戶體驗、降低運營負擔和提升數據平臺成本效率的第一步。它聚焦于自動修復失敗作業,但也為自動化其他運維任務鋪路。
我們正在推動的一個項目稱為_資源合理配置_,旨在重新配置定時大數據作業,使其請求適當的資源。例如,我們觀察到Spark作業請求的平均執行器內存約為其最大實際使用內存的四倍,存在顯著的資源過度配置。除了作業本身配置外,執行作業的容器資源過度配置亦可減少以節省成本。通過啟發式和機器學習方法,我們能夠推斷合適的作業執行配置,最大限度減少資源浪費,節省數百萬美元/年且不影響性能。與自動修復類似,這些配置可通過ConfigService自動應用,無需人工干預。資源合理配置項目正在進行中,后續將通過專門的技術博客詳細介紹,敬請關注。


第7講:VS實用調試技巧)














-組件)

