? ? ? 此處重點討論在特定條件下,重建場景的三維結構和相機的三維姿態的一些應用實現。下面是完整投影公式最通用的表示方式。
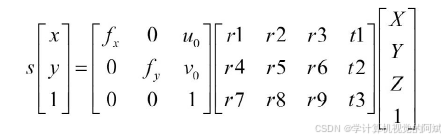
? ? ? ? 在上述公式中,可以了解到,真實物體轉為平面之后,s系數丟失了,因而無法會的三維坐標,而s系數其實是與直接距離Z相關,實際上,如果知道物體到相機成像平面距離,相機的內參、外參就可以獲得空間坐標:

1. 相機標定
? ? ? ?相機標定就是設置相機各種參數(即投影公式中的內參,外參)的過程。當然也可以使用相機廠家提供的技術參數,利用正確的相機標定方法,即可得到精確的標定信息。
? ? ? 相機標定的基本原理:確定場景中一系列點的三維坐標并拍攝這個場景,然后觀測這些點
在圖像上投影的位置。有了足夠多的三維點和圖像上對應的二維點,就可以根據投影方程推斷出
準確的相機參數。
? ? ? (1)一種方法是對一個包含大量三維點的場景取像(一些車輛在出場會使用)。
? ? ? (2)更實用的做法是從不同的視角為一些三維點拍攝多個照片。這種方法相對比較簡單,但是它除了需要計算相機本身的參數,還需要計算每個相機視圖的位置,OpenCV 推薦使用國際象棋棋盤的圖案生成用于標定的三維場景點的集合。

? ? ? ? 這個圖案在每個方塊的角點位置創建場景點;由于圖案是平面的,可以假設棋盤位于Z=0 且X 和Y 的坐標軸與網格對齊的位置。
// 1. 輸出圖像角點的向量
std::vector<cv::Point2f> imageCorners;
// 棋盤內部角點的數量
cv::Size boardSize(7,5);
// 獲得棋盤角點
bool found = cv::findChessboardCorners(
image, // 包含棋盤圖案的圖像
boardSize, // 圖案的尺寸
imageCorners); // 檢測到的角點列表// 2. 畫出角點
cv::drawChessboardCorners(image, boardSize,
imageCorners, found); // 找到的角點? ? ? ? 連接角點的線條的次序,就是角點在向量中存儲的次序。在進行標定前,需要指定相關的三維點。指定這些點時可自由選擇單位(例如厘米或英寸),不過最簡單的辦法是將方塊的邊長指定為一個單位。這樣第一個點的坐標就是(0, 0, 0)(假設棋盤的縱深坐標為Z = 0),第二個點的坐標是(1, 0, 0),最后一個點的坐標是(6, 4, 0)。這個圖案共有35 個點;若要進行精確的標定,這些點是遠遠不夠的。為了得到更多的點,需要從不同的視角對同一個標定圖案拍攝更多的照片。可以在相機前移動圖案,也可以在棋盤周圍移動相機。從數學的角度看,這兩種方法是完全等效的。OpenCV 的標定函數假定由標定圖案確定坐標系,并計算相機相對于坐標系的旋轉量和平移量。
// 打開棋盤圖像,提取角點
int CameraCalibrator::addChessboardPoints(
const std::vector<std::string> & filelist, // 文件名列表
cv::Size & boardSize) { // 標定面板的大小
// 棋盤上的角點
std::vector<cv::Point2f> imageCorners;
std::vector<cv::Point3f> objectCorners;
// 場景中的三維點:
// 在棋盤坐標系中,初始化棋盤中的角點
// 角點的三維坐標(X,Y,Z)= (i,j,0)
for (int i=0; i<boardSize.height; i++) {
for (int j=0; j<boardSize.width; j++) {
objectCorners.push_back(cv::Point3f(i, j, 0.0f));
}
}
// 圖像上的二維點:
cv::Mat image; // 用于存儲棋盤圖像
int successes = 0;
// 處理所有視角
for (int i=0; i<filelist.size(); i++) {
// 打開圖像
image = cv::imread(filelist[i],0);
// 取得棋盤中的角點
bool found = cv::findChessboardCorners(
image, // 包含棋盤圖案的圖像
boardSize, // 圖案的大小
imageCorners); // 檢測到角點的列表
// 取得角點上的亞像素級精度
if (found) {
cv::cornerSubPix(image, imageCorners,
cv::Size(5,5), // 搜索窗口的半徑
cv::Size(-1,-1),
cv::TermCriteria( cv::TermCriteria::MAX_ITER +
cv::TermCriteria::EPS,30, // 最大迭代次數
0.1)); // 最小精度
// 如果棋盤是完好的,就把它加入結果
if (imageCorners.size() == boardSize.area()) {
// 加入從同一個視角得到的圖像和場景點
addPoints(imageCorners, objectCorners);
successes++;
}
}
// 如果棋盤是完好的,就把它加入結果
if (imageCorners.size() == boardSize.area()) {
// 加入從同一個視角得到的圖像和場景點
addPoints(imageCorners, objectCorners);
successes++;
}
}
return successes;
}? ? ? ? ? ? ?

? ? 處理完足夠數量的棋盤圖像后(這時就有了大量的三維場景點/二維圖像點的對應關系),就可以開始計算標定參數了:
// 返回重投影誤差
double CameraCalibrator::calibrate(cv::Size &imageSize) {
// 輸出旋轉量和平移量
std::vector<cv::Mat> rvecs, tvecs;
// 開始標定
return calibrateCamera(objectPoints, // 三維點imagePoints, // 圖像點imageSize, // 圖像尺寸cameraMatrix, // 輸出相機矩陣distCoeffs, // 輸出畸變矩陣rvecs, tvecs, // Rs、Tsflag); // 設置選項
}
//根據經驗,10~20 個棋盤圖像就足夠了,但是這些圖像的深度和拍攝視角必須不同? ? ? ?用剛標定的相機拍攝的所有圖像,在標定類中增加了一個額外畸變矯正的方法:
// 去除圖像中的畸變(標定后)
cv::Mat CameraCalibrator::remap(const cv::Mat &image) {
cv::Mat undistorted;
if (mustInitUndistort) { // 每個標定過程調用一次
cv::initUndistortRectifyMap(
cameraMatrix, // 計算得到的相機矩陣
distCoeffs, // 計算得到的畸變矩陣
cv::Mat(), // 可選矯正項(無)
cv::Mat(), // 生成無畸變的相機矩陣
image.size(), // 無畸變圖像的尺寸
CV_32FC1, // 輸出圖片的類型
map1, map2); // x 和y 映射功能
mustInitUndistort= false;
}
// 應用映射功能
cv::remap(image, undistorted, map1, map2,
cv::INTER_LINEAR); // 插值類型
return undistorted;
}
2. 相機姿態還原
? ? ? ?標定后,相機就可以用來構建照片與現實場景的對應關系。如果一個物體的三維結構是已知的,就能得到它在相機傳感器上的成像情況。如果該方程中的大多數項目是已知的,利用若干張照片,就可以計算出其他元素(二維或三維)的值。在已知三維結構的情況下,計算出相機的姿態。
// 根據三維/二維點得到相機姿態
cv::Mat rvec, tvec;
cv::solvePnP(
objectPoints, imagePoints, // 對應的三維/二維點
cameraMatrix, cameraDistCoeffs, // 標定
rvec, tvec); // 輸出姿態
// 轉換成三維旋轉矩陣
cv::Mat rotation;
cv::Rodrigues(rvec, rotation);? ? ?本質是求解剛體變換(旋轉和平移),這就是透視n 點定位(Perspective-n-Point,PnP)問題,把物體坐標轉換到以相機為中心的坐標系上(即以焦點為坐標原點)。
? ? ?在OpenCV 中,cv::viz 是一個基于可視化工具包(Visualization Toolkit,VTK)的附加模塊。它是一個強大的三維計算機視覺框架,可以創建虛擬的三維環境,并添加各種物體。它會創建可視化的窗口,用來顯示從特定視角觀察到的虛擬環境。
// 1 創建viz 窗口
cv::viz::Viz3d visualizer("Viz window");
visualizer.setBackgroundColor(cv::viz::Color::white());// 2 創建一個虛擬相機
cv::viz::WCameraPosition cam(
cMatrix, // 內部參數矩陣
image, // 平面上顯示的圖像
30.0, // 縮放因子
cv::viz::Color::black());
// 在環境中添加虛擬相機
visualizer.showWidget("Camera", cam);// 3 用長方體表示虛擬的長椅
cv::viz::WCube plane1(cv::Point3f(0.0, 45.0, 0.0),
cv::Point3f(242.5, 21.0, -9.0),
true, // 顯示線條框架
cv::viz::Color::blue());
plane1.setRenderingProperty(cv::viz::LINE_WIDTH, 4.0);
cv::viz::WCube plane2(cv::Point3f(0.0, 9.0, -9.0),
cv::Point3f(242.5, 0.0, 44.5),
true, // 顯示線條框架
cv::viz::Color::blue());
plane2.setRenderingProperty(cv::viz::LINE_WIDTH, 4.0);// 4 把虛擬物體加入到環境中
visualizer.showWidget("top", plane1);
visualizer.showWidget("bottom", plane2);cv::Mat rotation;
// 將rotation 轉換成3×3 的旋轉矩陣
cv::Rodrigues(rvec, rotation);
// 移動長椅
cv::Affine3d pose(rotation, tvec);
visualizer.setWidgetPose("top", pose);
visualizer.setWidgetPose("bottom", pose);
最后用一個循環,不斷顯示可視化窗口。中間暫停1 毫秒,以響應鼠標事件:
// 循環顯示
while(cv::waitKey(100)==-1 && !visualizer.wasStopped()) {
visualizer.spinOnce(1, // 暫停1 毫秒
true); // 重繪
}
3. 用標定相機實現三維重建
? ? ? ? 當從多個視角觀察同一個場景時,即使沒有三維場景的任何信息,也可以重建三維姿態和結構。我們這次將利用不同視角下圖像點之間的關系,計算出三維信息。
? ? ? ?相機的標定參數是能夠獲取到的,因此可以使用世界坐標系,還可以用它在相機姿態和對應點的位置之間建立一個物理約束。這里引入一個新的數學實體——本質矩陣。簡單來說,本質矩陣就是經過標定的基礎矩陣。
// 找出image1 和image2 之間的本質矩陣
cv::Mat inliers;
cv::Mat essential = cv::findEssentialMat(points1, points2,
Matrix, // 內部參數 相當于給出了內參
cv::RANSAC,
0.9, 1.0, // RANSAC 方法
inliers); // 提取到的內點? ? ? 將匹配到的同名點調用triangulate 函數,計算三角剖分點的位置:
// 根據旋轉量R 和平移量T 構建投影矩陣
cv::Mat projection2(3, 4, CV_64F); // 3×4 的投影矩陣
rotation.copyTo(projection2(cv::Rect(0, 0, 3, 3)));
translation.copyTo(projection2.colRange(3, 4));
// 構建通用投影矩陣
cv::Mat projection1(3, 4, CV_64F, 0.); // 3×4 的投影矩陣
cv::Mat diag(cv::Mat::eye(3, 3, CV_64F));
diag.copyTo(projection1(cv::Rect(0, 0, 3, 3)));
// 用于存儲內點
std::vector<cv::Vec2d> inlierPts1;
std::vector<cv::Vec2d> inlierPts2;
// 創建輸入內點的容器,用于三角剖分
int j(0);
for (int i = 0; i < inliers.rows; i++) {
if (inliers.at<uchar>(i)) {
inlierPts1.push_back(cv::Vec2d(points1[i].x, points1[i].y));
inlierPts2.push_back(cv::Vec2d(points2[i].x, points2[i].y));
}
}
// 矯正并標準化圖像點
std::vector<cv::Vec2d> points1u;
cv::undistortPoints(inlierPts1, points1u,
cameraMatrix, cameraDistCoeffs);
std::vector<cv::Vec2d> points2u;
cv::undistortPoints(inlierPts2, points2u,
cameraMatrix, cameraDistCoeffs);
// 三角剖分
std::vector<cv::Vec3d> points3D;
triangulate(projection1, projection2,
points1u, points2u, points3D);? ? ? ? 圖中有兩個相機,相對的旋轉量為R,平移量為T。平移向量T 剛好連接了兩個相機的投影中心點。此外,向量x 連接第一個相機的中心點與一個圖像點,向量x'連接第二個相機的中心點
與對應的圖像點。因為這兩個相機之間的移動量是已知的,所以可以用與第二個相機的相對值來表示x 的方向,記為Rx。仔細觀察圖像點的幾何形狀,就能發現T、Rx 和x'在同一個平面上。這個關系可用數學公式表示![]()
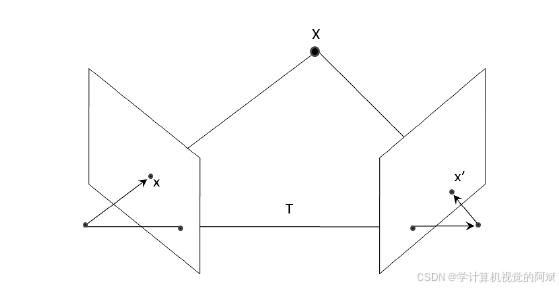
? ? ? ?由于噪聲和數字化過程的影響,理想情況下應該相交的投影線在實際中一般不會相交。所以用最小二乘法就可以大致找到交點的位置。但這種方法無法重建無窮遠處的點,因為它們的齊次坐標的第4 個元素為0,而不是假定的1。還有一點很重要,三維重建只受限于縮放因子。如果要測量實際尺寸,就必須預先確定至少一個長度值,例如兩個相機之間的實際距離或者畫面中某個物體的實際高度。
4. 計算立體圖像的深度
? ? ? ? 人類用兩只眼睛觀察三維世界,裝上兩臺相機后,機器也可以看到三維世界,這就是立體視覺。在同一個設備上安裝兩臺相機,讓它們觀察同一個場景,并且兩者之間有固定的基線(即相機之間的距離),就構成了一個立體視覺裝置。
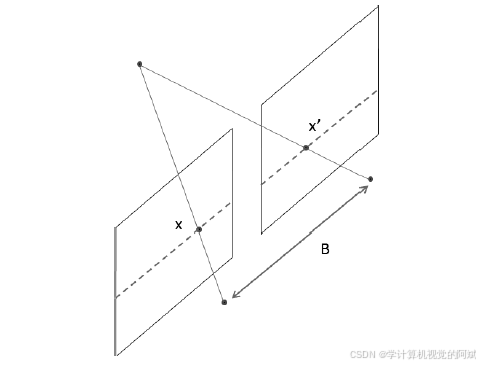
? ? ? ? 兩臺相機之間只有水平方向的平移,因此它們的所有對極線都是水平方向的。這意味著所有關聯點的y 坐標都是相同的,只需要在一維的線條上尋找匹配項即可。關聯點x 坐標的差值則取決于點的深度。無窮遠處的點對應圖像點的坐標相同,都是(x, y),而它們離裝置越近,x 坐標的差值就越大,這時計算差值x -x'(注意要除以s 以符合齊次坐標系),并分離出z 坐標,可得到:![]()
// 1 計算單應變換矯正量
cv::Mat h1, h2;
cv::stereoRectifyUncalibrated(points1, points2,
fundamental,
image1.size(), h1, h2);// 2 用變換實現圖像矯正
cv::Mat rectified1;
cv::warpPerspective(image1, rectified1, h1, image1.size());
cv::Mat rectified2;
cv::warpPerspective(image2, rectified2, h2, image1.size());// 3 計算視差
cv::Mat disparity;
cv::Ptr<cv::StereoMatcher> pStereo =
cv::StereoSGBM::create(0, // 最小視差32, // 最大視差5); // 塊的大小
pStereo->compute(rectified1, rectified2, disparity);



、雙引號( )和反引號( `)使用)
:DMP與PCP系統核心功能剖析)



)


安裝步驟)


——client子窗口功能)
-張量拼接操作)
)


