Linux系列
文章目錄
- Linux系列
- 前言
- 一、磁盤
- 1.1 初識磁盤
- 1.2 磁盤的物理結構
- 1.3 磁盤的存儲結構
- 1.4 磁盤的邏輯結構
- 二、文件系統
- 2.1 系統對磁盤的管理
- 2.2 文件在磁盤中的操作
前言
Linux 文件系統是操作系統中用于管理和組織存儲設備(如硬盤、SSD、USB 等)上數據的一種核心機制。本篇我們將操作系統如何對未打開的文件進行管理的。
一、磁盤
磁盤是是計算機硬件中的唯一的機械設備,被廣泛的運用于企業級存儲,學習磁盤對數據的存儲,對我們學習操作系統的文件系統有很大幫助。
1.1 初識磁盤
隨著計算機行業的發展,磁盤由于存儲效率較低,慢慢的在我們的私人電腦中被固態硬盤所替代,但是在企業中,磁盤依舊是存儲的主流。這是因為:
1、相較于固態硬盤來說,磁盤的成本較低。
2、磁盤雖然效率低,但是容量較大,在企業中往往存在海量的不常訪問數據需要保存,所以磁盤就成了比較適合的選擇,
3、固態硬盤在存儲和刪除數據是對自身會有一定損耗,長時間的使用會有數據丟失的風險。
1.2 磁盤的物理結構

一個磁盤會包含好幾個盤片,每個盤片具有兩個盤面,這兩個盤面都會進行數據存儲,每個盤面都會配有對應的磁頭,在工作時,磁盤會在主軸的帶動下開始旋轉,磁頭則會在磁臂的帶動下開始水平擺動,這個過程磁頭并不會和磁盤接觸。
1.3 磁盤的存儲結構
下面我們來對一個磁面進行分析:
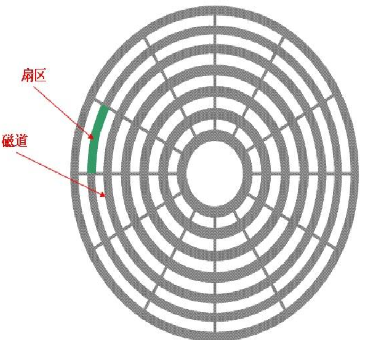
在一個磁面中,以主軸為圓心,向外會分成多個同心園,我們稱這些同心圓為磁道,這些磁道又會被等分為多分弧段,這些弧段就叫做扇區,在磁盤進行數據的讀寫時就是以扇區為最小單位,每個扇區一般為512字節,從主軸向外扇區的長度是不同的,為了保證存儲空間一致,設計規定離主軸越遠數據的存儲密度越小。
拓展: 磁盤在工作時,主軸帶動磁盤旋轉,磁頭通過擺動來確定數據在哪個磁面、磁道,當確定磁道后,磁頭停止擺動,此時磁盤繼續旋轉完成數據讀寫工作。
為了對方便管理,我們磁面、磁道、扇區進行編號,當我們要對磁盤數據進行訪問時,就可以通過編號快速完成,具體怎么進行的我們下面介紹。
1.4 磁盤的邏輯結構
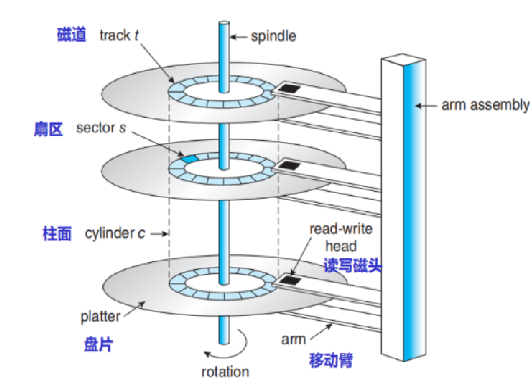
由于磁盤的大小相同,且磁臂是被固定的,這時再將磁盤劃分磁道,我們就會得到一個由磁道組成的柱面結構,當我們對磁盤進行訪問時,我們就可以先確定在哪一個柱面(cylinder),也就是磁盤,然后再確定再哪一個盤片(platter),由于每個盤片都配有一個磁頭,所以我們是通過 磁頭(head) 來確定的,再確定磁道(track),最后確定扇區(sector) 我們稱這種定位方法為 CHS定位法。為了將它于操作系統建立聯系,我們需要將它進一步抽象。
不知到大家有沒有接觸過磁帶,來看下圖:

左側圖片是磁帶卷起的樣子,會呈現出一個圓類似于盤面,當我們將它展開就會呈現出右側有寬度的帶子,我們可以依據這個特性將盤面中的磁道抽象為一個,條帶子:
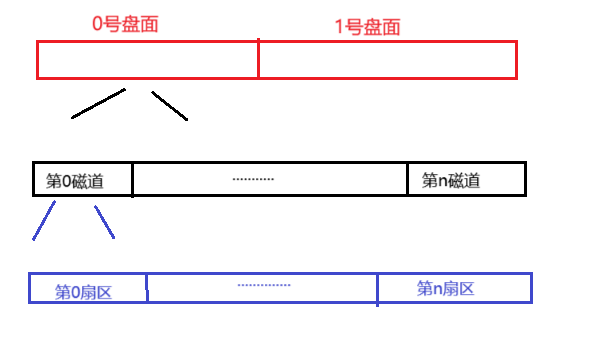
這里我們就可以將所有盤面全部抽象為一個線性結構(當成數組也可以,為了方便這里僅畫出了一個盤),這時我們對磁盤的訪問,就變為了對線性結構的訪問,當操作系統要定位一個扇區時,我們只需要知道這個扇區的地址就可以完成對扇區的訪問了,如要查找扇區編號為:355
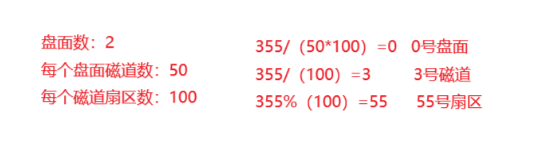
由于是從0開始編號,所以計算時只需要向下取整即可。
這樣我們就成功定位到了扇區,而我們將這種編號稱為LBA地址,定位過程就是LAB地址轉化為CHS地址的過程。
二、文件系統
2.1 系統對磁盤的管理
我們可以確切的感受到,在我們的計算機中,磁盤是非常大的,如果操作系統直接對他進程管理,效率是非常低的,那么該如何讓操作系統對它進行管理呢?對于這個問題,我們的工程師采用了分治思想,將整個磁盤劃分為小塊空間,通過對所以小塊空間的管理,達到對整個磁盤的管理。
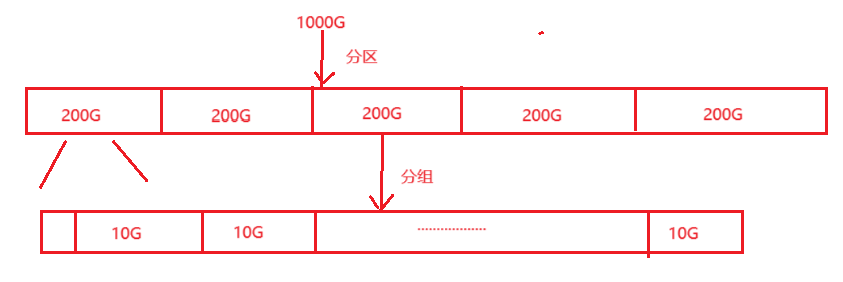
這樣操作系統只需要完成對每個組的管理,就可以達到對整個磁盤的管理。
每個組又會被劃分為以下幾個區:

具體如何管理我們結合文件在磁盤中的存儲,進行分析:
我們知道文件=內容+屬性,而在Linux中文件的內容和屬性是分開進行存儲的,那么兩者分開存儲是如和建立聯系的呢?或者說是如何管理的呢?
存儲屬性信息: 在Linux中每個文件都會對應一個inode結構體,這個結構體(對象)的大小是固定的,通常為128字節,文件的所有信息都存儲在這個結構體對象中,其中并包含文件名,這是因為,Linux并不通過文件名進行查找文件,每個inode都會有一個編號,操作系統通過編號進行查找。上圖的inode Table就是inode表(inode集合,下面會再次解釋)。
存儲文件內容: 在Linux文件內容是存儲在上圖Data blocks區域中的,而這個區域被劃分為塊(這些塊也是會被分配編號的),操作系統在訪問磁盤時是以塊為單位進行訪問的,塊中包含多個扇區,通常塊的大小為4KB,此處可以理解為對讀取性能的優化,因為當計算機要訪問一段數據是,這段數據周圍的數據也有很大可能被訪問,所以直接讀取4KB,這是一種以空間換時間的方法。(這個塊大小是可以修改的,感興趣的可以去了解)
屬性與內容建立聯系: 在inode對象中會存在,一個數組,數組中存儲的是該文件內容存儲塊的編號。
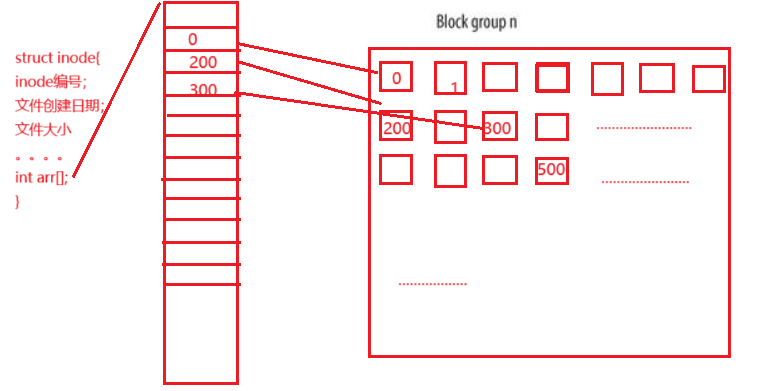
這樣我們就大概的知道了,存儲邏輯了,下面我們解釋一下,組中各個模塊的含義。

Boot Block:引導塊,引導操作系統啟動,我們不做研究。
Super Block:超級塊,存儲文件系統的整個信息(整個分區信息),包含bolck和inode的總量,未使用的量,一個bolck和inode的大小,文件系統狀態(是否干凈卸載)等。
Group Descriptor Table:塊組描述符,描述塊組的屬性信息。
Block Bitmap:塊位圖,記錄Date bolck中的塊是否被使用,通過塊編號映射,相信學過位圖的都可以理解。
inode Bitmap:inode位圖,標識inode是否被使用。
復習的時候再看看超級塊-----這句話給作者看的
2.2 文件在磁盤中的操作
我通過對文件的增、刪、查、改,帶領大家熟悉上面知識。
查看文件的inode編號:
ls -li

還可以使用stat 文件名查看更多信息,大家自己去了解一下。
創建文件:
創建文件時,將文件存儲在哪個分區,路徑會幫助我們,這里我們就不關心了,首先操作系統根據,超級塊中的信息,剩余inode和bolck較多的組,遍歷該組的inode Bitmap,得到未被使用的inode編號,找到該inode將文件屬性存儲,并將對應位置位圖置1,再遍歷Block Bitmap得到未被使用的塊編號,找到對應塊,將文件內容存儲,并將對應位置位圖置1,再將對應的塊編號,存入該文件inode的數組中。
讀取文件:
讀取文件首先查找文件,拿到該文件的inode編號,根據編號找到對應的分組(LBA->CHS),找到inode中存儲塊編號的數組,那到塊編號,讀取塊數據。
修改文件:
首先拿到該文件的inode編號,根據編號找到對應的分組(LBA->CHS),找到inode中存儲塊編號的數組,那到塊編號,修改數據。
刪除文件:
首先拿到該文件的inode編號,根據編號找到對應的分組(LBA->CHS),找到inode中存儲塊編號的數組,那到塊編號,使用塊編號,將塊位圖對應位置置0(表示未被使用),通過inode編號將inode位圖置0。
通過上面的方法我們就可實現文件的增、刪、查、改了,但是我們還面臨一個問題,操作系統該如何來獲取文件的inode編號呢?
我們首先來看這樣一個問題:

上面我們說,操作系統在磁盤訪問文件不通過文件名,是通過inode進行的,但現在為什么操作系統不認識它呢?
要回答這個問題我們就得思考一下,目錄文件在磁盤中存儲的內容是什么了,在磁盤中目錄文件存儲的其實是,該目錄下的文件名與文件inode編號的映射關系,當在用戶訪問文件時,操作系統就會根據當前目錄的inode編號,找到當前目錄的內容,從而通過映射關系找到對應文件的inode編號,這樣就可以得到用戶要訪問文件的inode,但是當前目錄文件的inode又從哪來呢,當然是通過它的上級目錄了,就像這樣一直索引,知道找到操作系統啟動時固定的,目錄inode編號,然后逐級返回。這個過程為路徑解析,但是由于太過復雜影響效率,所以操作系統會將常用路徑解析后緩存在dentry緩存。

這樣我們就將這個問題完美解決了。


】dataset 工具,Parquet和Arrow 數據文件格式,load dataset 方法)










)
)



裝飾器模式)
