緒論:沖擊藍橋杯一起加油!!
每日激勵:“不設限和自我肯定的心態:I can do all things。 — Stephen Curry”

緒論?:
————————
早關注不迷路,話不多說安全帶系好,發車啦(建議電腦觀看)。
遞歸
1. 什么是遞歸
簡單來說:就是函數自己調用自己
2. 為什么會用到遞歸
常見的遞歸有:二叉樹的遍歷、快排、歸并
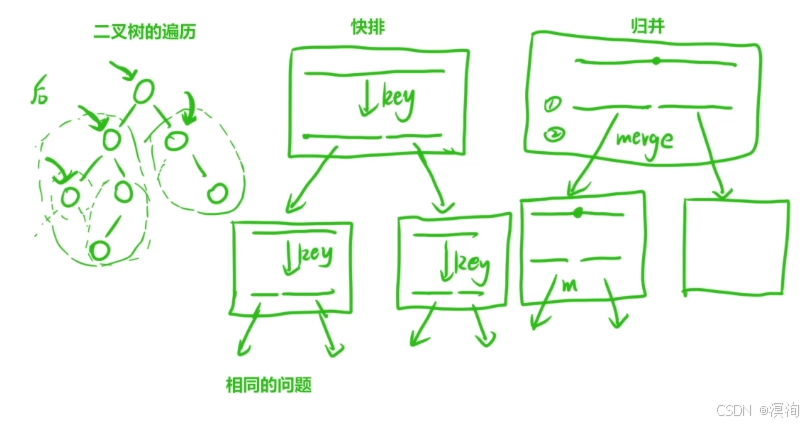
其中遞歸的本質:
- 解決主問題,衍生相同的子問題
- 在處理子問題的時候,又出現了相同的子問題
- 所以本質就是不斷自己調用自己,通過縮小問題最終解決最小子問題
3. 如何理解遞歸(非常重要!)
對于理解遞歸,可以從下面三個方向理解:
- 遞歸展開的細節圖
- 二叉樹中的題目
- 宏觀看待遞歸的過程
- 不要在意遞歸的展開圖
- 把遞歸的函數當成一個黑盒(具體里面如何操作關心,給他數據,返回結果)
- 相信這個黑盒一定能完成這個任務
(這個后面慢慢的到來,請繼續往后看)
4. 如何寫好一個遞歸?
- 先找到相同的子問題
- 根據子問題:決定了函數頭的設計
- 本質也就是分析題目,然后得出解決子問題可能需要用到的參數(一般來說可以先粗力度的得到一個函數頭,然后再在編寫代碼中不斷彌補)
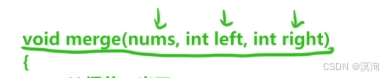
- 只關心某個子問題是如何解決的
- 把他看成一個黑盒,并相信他能夠替你完成任務
- 也就決定了函數體的書寫,我們僅僅去想某個子問題的解決方法
- 因為這樣再次調用該函數的時候,雖然條件參數可能不同,但子問題的解決方法是一致的
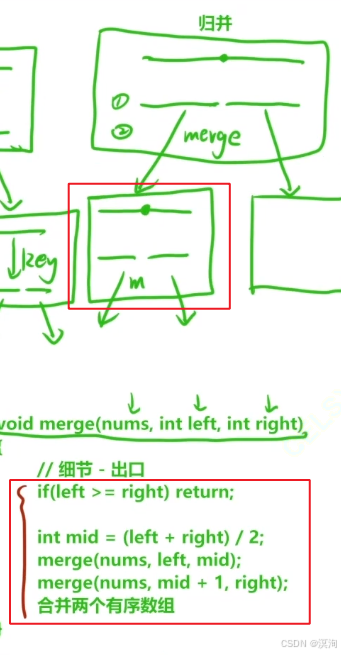
- 最后再注意一下遞歸函數的出口即可
- 也就是防止無限遞歸的情況
總結:解決簡單遞歸的三步:
非常重要,不過通過大量練習相信你就能很好的理解(可能初次看會迷糊~)
- 通過題目寫出dfs的函數頭
- 根據子問題寫出函數內部邏輯
- 注意一下遞歸出口
深度優先遍歷 vs 寬度優先遍歷 vs 暴搜
-
深度優先遍歷(搜索)dfs(depth):
- 通俗的來說就是:一條路走到黑
- 通俗的來說就是:一條路走到黑
-
寬度優先遍歷(搜索)bfs(Breadth):
- 本質也就是:一層一層的遍歷樹
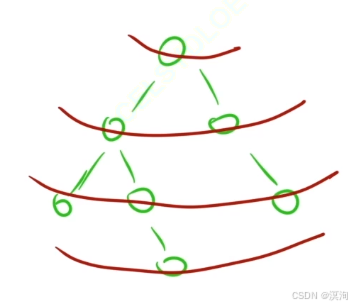
- 本質也就是:一層一層的遍歷樹
-
搜索(暴搜):
- 本質就是暴力枚舉一遍所有的情況,或者說就是將樹中的所有節點都進行一次遍歷
-
搜索問題的拓展:
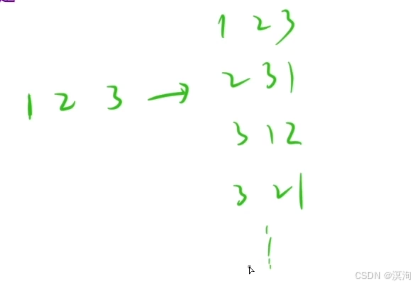
拿全排列問題舉例:
全排列是將一組數中的所有情況排出來(如下圖)
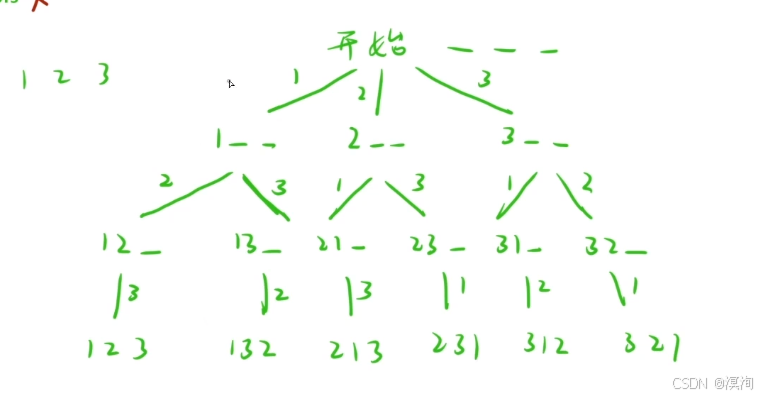
那么可以使用樹狀圖(決策樹)的方式解決具體如下圖
此時畫出來后,我們需要的答案最終就能通過遞歸搜索的方式獲取到:
所以說我們不能對于dfs、bfs來說局限于二叉樹,而是當我們能畫出類似的決策樹的形式畫出來那么就能使用dfs/bfs
回溯與剪枝(非常重要!)
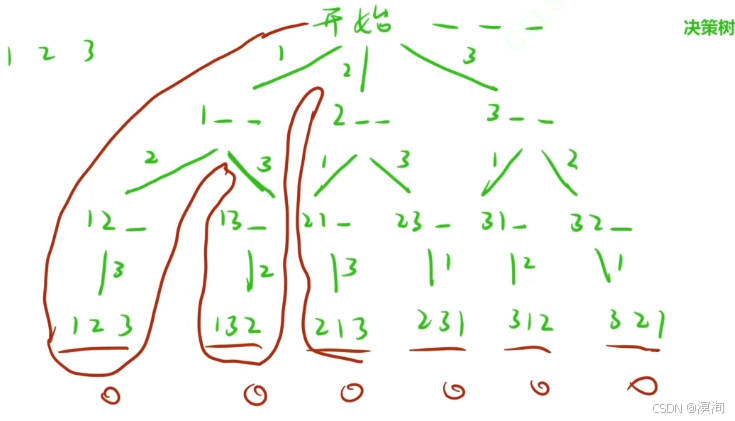
- 回溯的本質:其實就是深搜中當我們嘗試某種情況時,發現這種情況行不通,退回到上一級的操作就是回溯
(如下圖紅線)
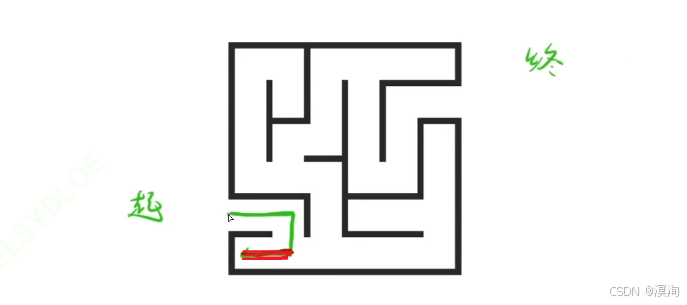
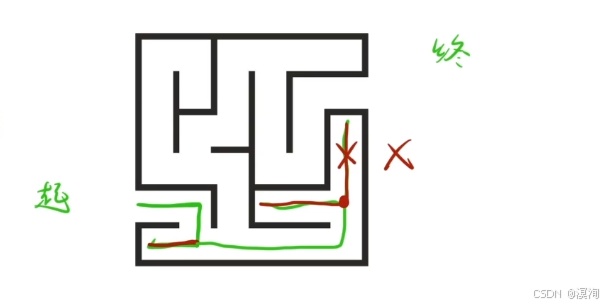
- 剪枝來說:在我們回溯過程后可能遇到兩種可以走的情況,而其中一種情況已經走過了知道行不通,那么這條路就代表被剪枝了
(具體如下圖)
下面將通過5道題目帶你理解遞歸,其中注意理解遞歸的三步(函數頭,函數體,遞歸出口)
具體訓練:
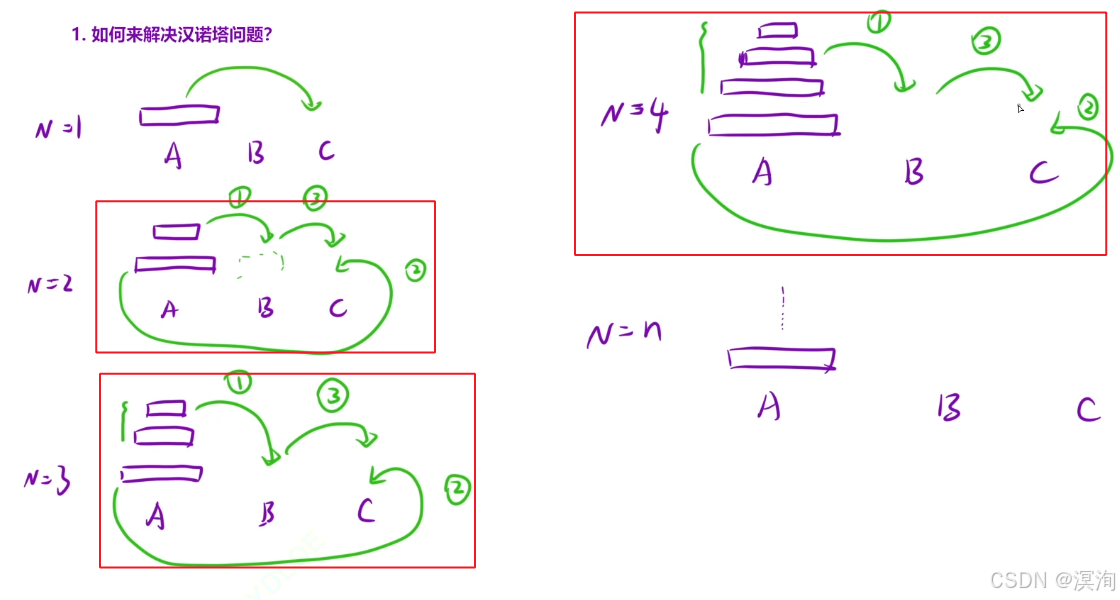
1. 漢諾塔
題目:
分析題目并提出,解決方法:

在過程中不允許大盤子摞在小盤子上面!
題解核心邏輯:
漢諾塔問題,可以用遞歸解決
如何來解決漢諾塔問題?
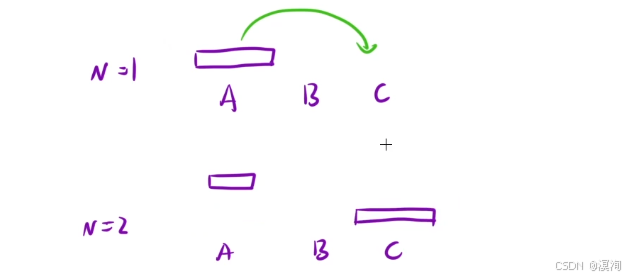
- 在N >= 2 時,我們要考慮先將最大的盤子放到 C柱上
問題就轉移成了:
- 先把最大盤子上面的所有先放在B柱上,然后在移動 最大的盤子 到C柱
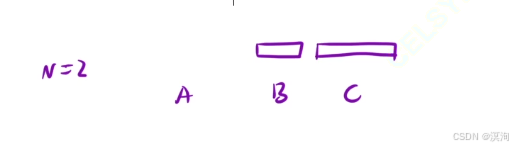
- 第三步就是將所有B柱上的盤子在移動到C柱上
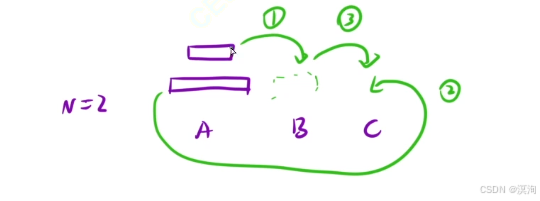
- 再次理解:當N = 3時,看最上面的兩個盤子,它的本質其實就是N = 2的情況,只不過這次是移動到B柱

- 這里注意理解的是:操作1和操作3的本質是一樣的,只不過借助的柱子不一樣!
- 那么 N = … 他們的本質都是一樣了,他們都是:
- 執行步驟1,將最大盤子上面的小盤子全部轉移到B
- 執行步驟2,將最大盤子全部轉移到C
- 執行步驟3,再將B上的轉移到C即可完成
- 所以為什么可以用遞歸:解決大問題的時候,出現了相同的子問題,解決子問題的時候又出現了相同的子問題
如何寫代碼:
- 挖掘重復子問題(函數頭)
- 也就是上面的 步驟 1、 2、3所需要的
- 該題本質是:將 x 柱上的一堆盤子,借助 y 柱子,轉移到 z 柱子上
- 那么函數頭也就如下圖
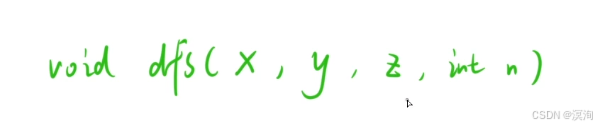
- 只關心某一個子問題在做什么(函數體)
- 宏觀的分析三個步驟的具體:

- 宏觀的分析三個步驟的具體:
- 函數出口
- 不難發現就是 N = 1 的時候是不同的,直接將A柱的盤子直接放到C柱上
- 那么當N=1時,將A柱的盤子直接放到C柱上,然后就可以退出了

具體步驟代碼如下:
class Solution {
public:
//1. 挖掘重復子問題(得出函數頭)
//將n個盤子移動到 借助柱子移動到目標柱子void h(vector<int>& A, vector<int>& B, vector<int>& C,int n){//出口:if(n == 1){// 將 A 上的移動到 C上C.push_back(A.back());A.pop_back();return ;}//2. 分析子問題:(得到函數體所需要的操作,并且相信他能完成)
//先將 A 柱上的 n-1 個移動到 B盤h(A,C,B,n-1);
//將 A 中的最后一個盤子移動到 C上C.push_back(A.back());A.pop_back();
//在將B上的盤子借助A全部移動到C上h(B,A,C,n-1);} void hanota(vector<int>& A, vector<int>& B, vector<int>& C) {h(A,B,C,A.size());}
};
2. 合并兩個有序鏈表
題目:
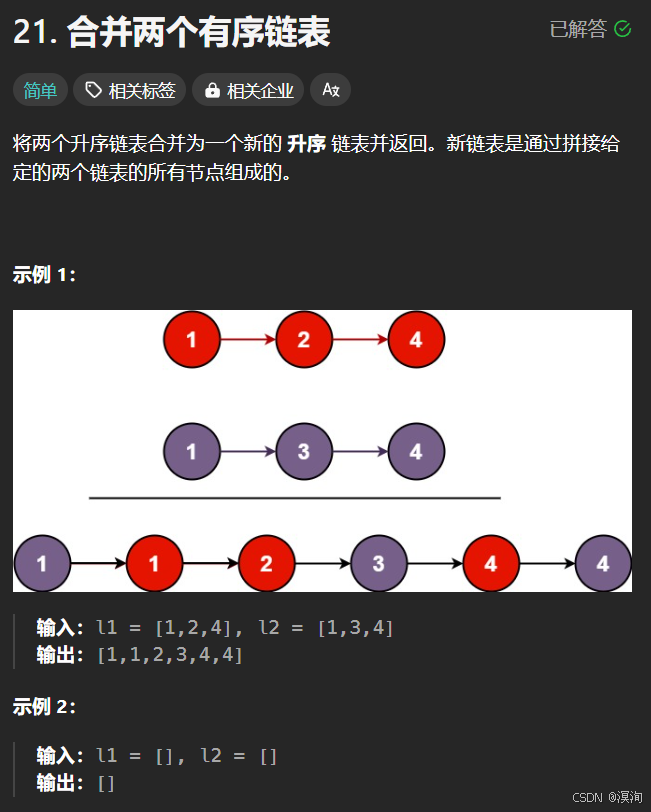
分析題目并提出,解決方法:
題目很好理解:就是拼接兩個鏈表,過程中不允許創建空間
分析本題查看是否有重復子問題:
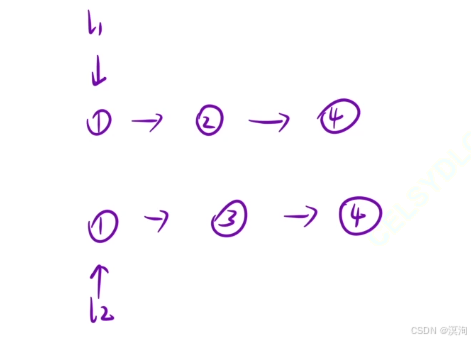
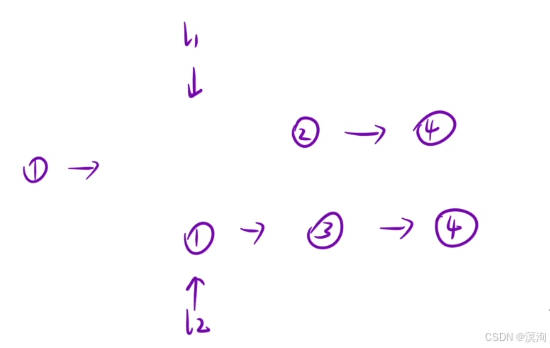
-
重復子問題(函數頭的設計)
- 合并兩個有序鏈表
- 那么也就僅需要兩個 鏈表

-
只關心某個子問題(函數體的設計)
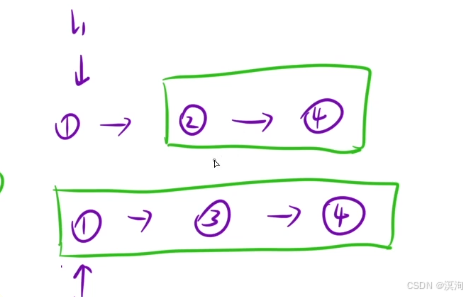
- 比大小(兩個鏈表進行比較)得到較小的結點
- 將較小的結點看做合并后的鏈表頭結點(通過修改該結點的next指針完成)
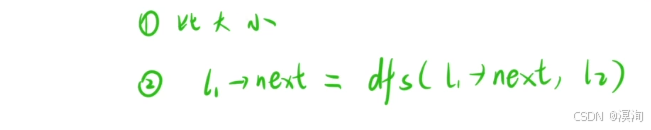
- 最終返回 較小的結點
-
遞歸出口
- 那個指針先為空返回另外一個指針
總結:遞歸 = 重復子問題 + 宏觀看待遞歸問題
題解核心邏輯:
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:
//分析函數的目的:合并兩個鏈表:所以函數頭就是 兩個鏈表即可ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
//編寫出口:判斷那個鏈表先為空,返回另外一個if(list1 == nullptr) return list2;if(list2 == nullptr) return list1;//編寫子問題的具體操作:完成函數體//1. 找到較小的if(list1->val <= list2->val){list1->next = mergeTwoLists(list1->next,list2);return list1; }else{list2->next = mergeTwoLists(list1,list2->next);return list2; }}
};
小總結:
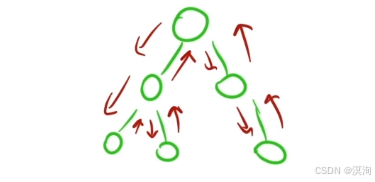
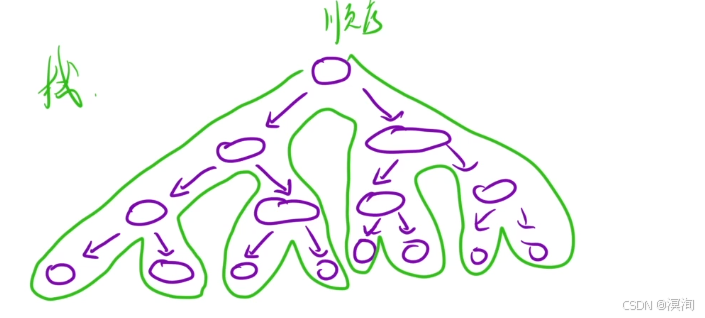
遞歸 VS 深搜
遞歸的展開圖,其實就是對一棵樹做一次深度優先遍歷(dfs)
而在遞歸的過程中需要一個 棧 進行保存,歷史數據
循環(迭代) vs 遞歸
它們是能相互轉換的,那么什么時候,用哪一個呢?
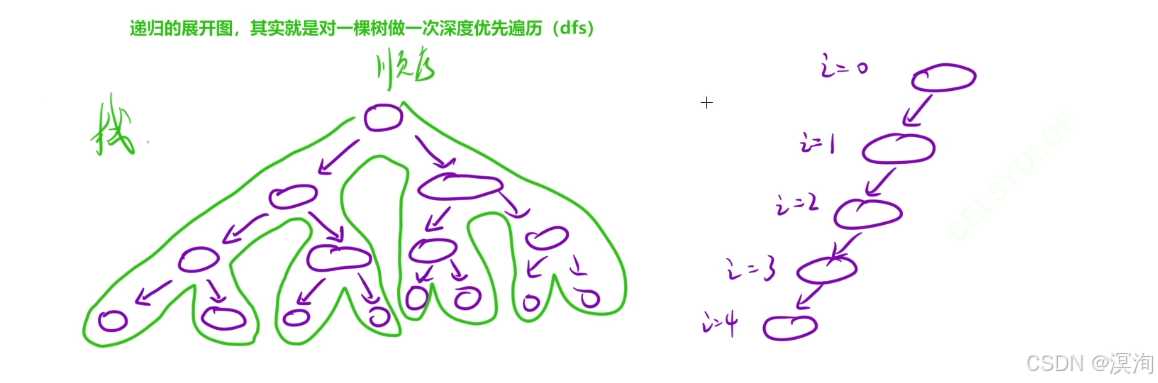
通過上面的分析和上圖理解到:
- 當我們的一個遍歷過程需要用到類似棧的東西進行保存數據時,就是比較麻煩的情況了,此時我們使用遞歸的形式就能很簡單方便的寫出程序
- 而當一些遍歷過程比較簡單,如上圖右邊結構,此時遍歷僅僅只需要單方向的那么,此時就沒必要使用遞歸,因為一個簡單的遍歷循環即可完成
3. 反轉鏈表
題目:
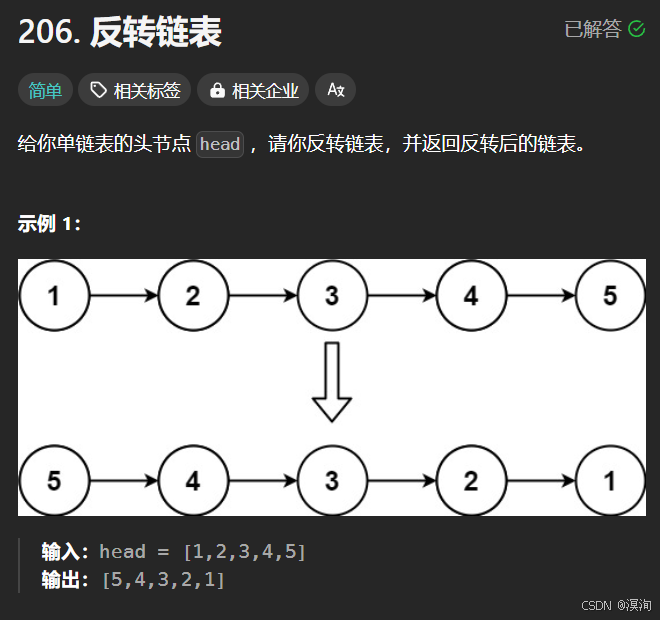
分析題目并提出,解決方法:
宏觀角度看待問題:
- 讓當前結點后面的鏈表先逆序,并且把頭結點返回
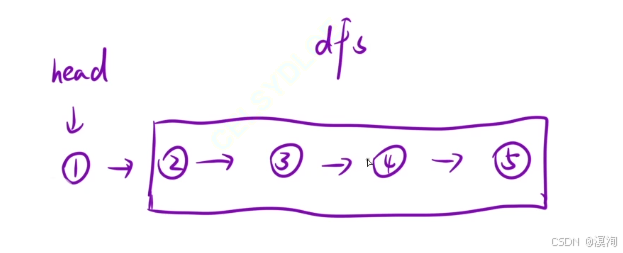
- 讓當前結點添加到逆置后的鏈表
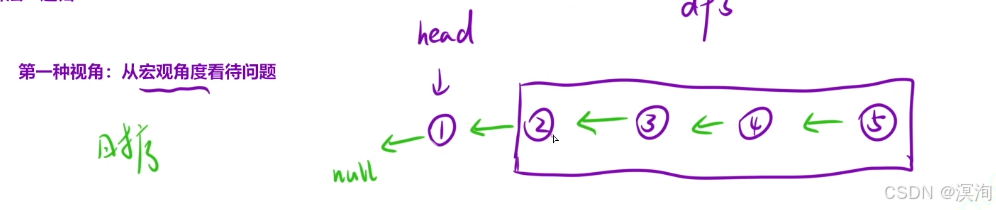
第二個視角:將鏈表看成一顆樹:
- 不斷深度遍歷到最后一個結點
- 返回最后一個結點
- 到達倒數第二層:執行將自己下一個結點的next置為自己,然后自己置為null(這里置為是為了保持所以子操作一致)
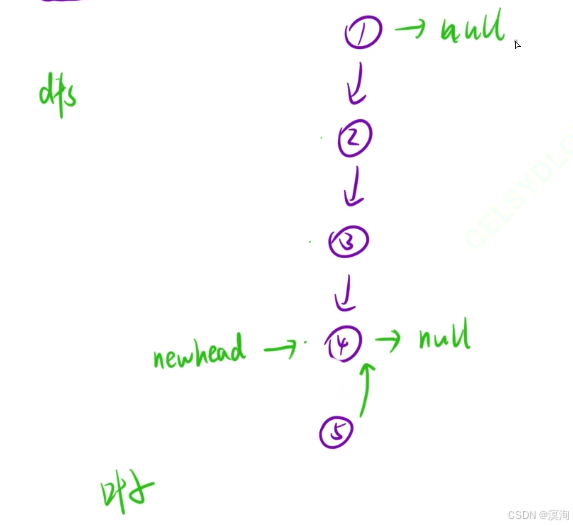
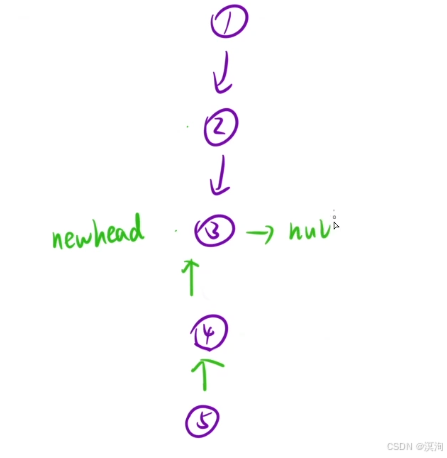
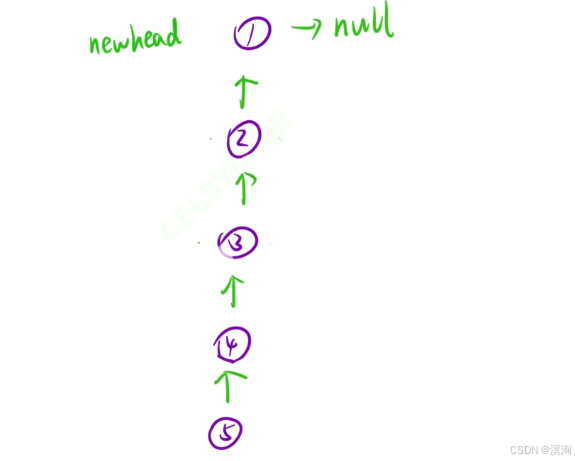
題解核心邏輯:
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* reverseList(ListNode* head) {//使用遞歸的方式//宏觀的看待問題://翻轉鏈表(所以函數頭就只需要一個鏈表即可,還需要返回新頭結點)//子問題(將自己的next的next置為自己,再將自己置為空,并且還需要將最后的頭結點返回回來)//出口:(當head為空時退出,表示遍歷到了最后結點)//head == nullptr 時為了防止沒有結點的情況if(head == nullptr || head->next == nullptr){return head;//返回結點}ListNode* newhaed = reverseList(head->next);head->next->next = head;head->next = nullptr;return newhaed;}
};
4. 兩兩交換鏈表中的節點
題目:
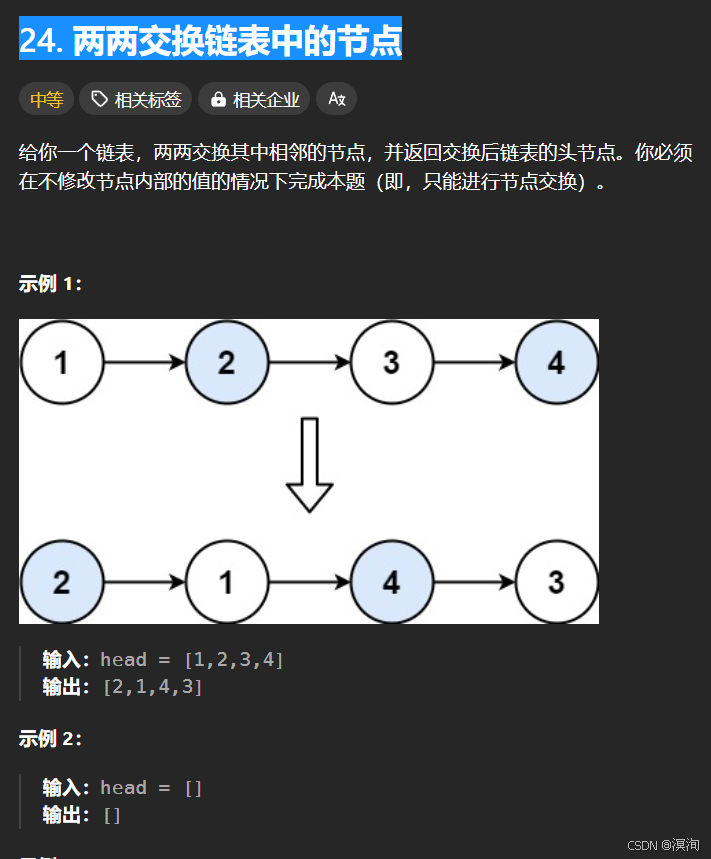
分析題目并提出,解決方法:
遞歸思想(宏觀看待):
- 分析題目得到遞歸思想:將給到的鏈表中的兩兩進行交換順序,那么也就僅需要一個鏈表參數即可
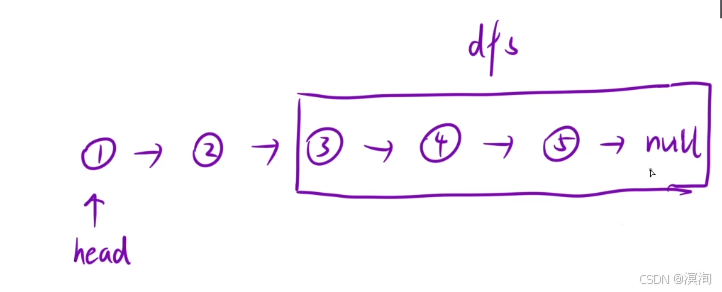
- 看待某個子問題:
- dfs會返回一個新的鏈表的結點,使用tmp記錄
- 將當前head的next的next指向haed,再將head的next指向tmp(完成交換的目的)
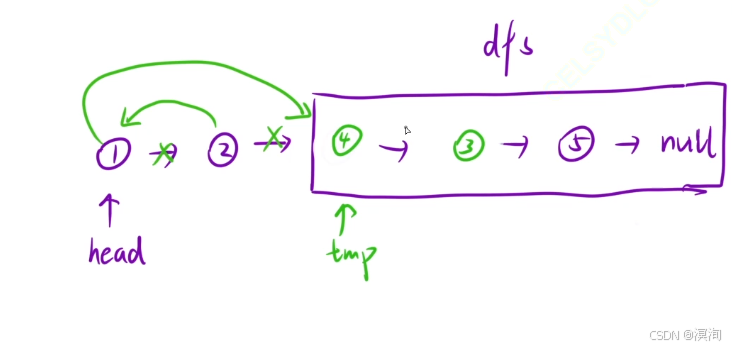
- 退出情況,當head為空是退出
- 注意其中是以兩個結點看成一起的,所以退出條件是:
- 當 head為空 || head->next 為空
題解核心邏輯:
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* swapPairs(ListNode* head) {//退出條件:if(head == nullptr || head->next == nullptr){return head;//返回當前結點}//子問題://1. 獲取dfs后面的頭結點ListNode* tmp = swapPairs(head->next->next);ListNode* ret = head->next;ret->next = head;head->next = tmp;return ret;}
};
5. Pow(x, n)
題目:

分析題目并提出,解決方法:
很好理解 就是 求x n等于多少
解法1:暴力循環,讓 x 乘 n 次即可(會超時)
解法二:
快速冪
快速冪的實現:
- 遞歸實現
- 循環實現
本題將遞歸實現:
例子:當我們要求 316:
- 就是將 316 不斷的對半看(具體如下圖)
先求出 38 這樣 38 * 38 = 316 同理 38 = 34 * 34 。。。
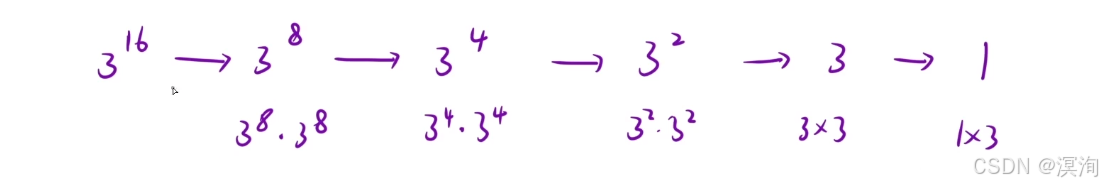
- 其中暴力解法要求 16 次,而使用這種方法只用求logn次
- 附:當 n 為奇數時:多乘一個自身即可
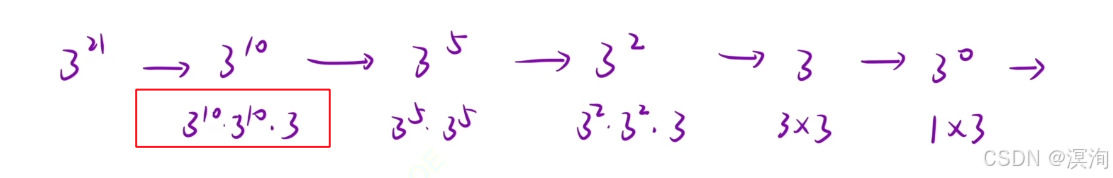
- 相同子問題 -->函數頭
- 求一個 x的n次冪 ==> pow(x,n)
- 只關心每個子問題做了什么 – > 函數體
- 其中需要 判斷 n 的奇偶性
- 通過遞歸獲取自身的值,并且判斷奇偶性得出是否要多乘1位
- 遞歸出口
- 當 n == 0 時返回1(這樣上層 n = 1 處等于 1 * x(1 * 1 * x))

特殊情況:
- 當 n == 0 時返回1(這樣上層 n = 1 處等于 1 * x(1 * 1 * x))
- n 為負數:
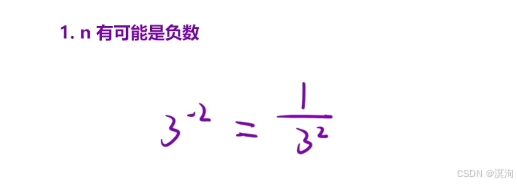
- n 可能是 -231 當變成整數就可能越界,所以得使用long long(整形的范圍是 -231 ~ 231 - 1)
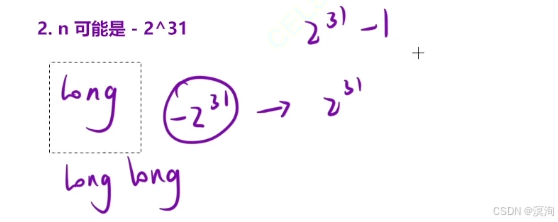
題解核心邏輯:
- 其中注意 -(long long)n 這里的操作:它是將 n 的類型轉換成了long long(并且不能寫在-前面,只能挨著n)
- 只有這樣當 n = -231 時強轉為正數后就不會溢出
class Solution {
public:double myPow(double x, int n) {//遞歸實現://將 x^n 看成 x^(n/2) * x^(n/2) ...return n >= 0 ? pow(x,n) : 1/pow(x,-(long long)n);}double pow(double x,long long n){if(n == 0) return 1;double tmp= myPow(x,n/2);return n % 2 == 0 ? tmp * tmp : tmp * tmp * x;}
};
![[ctfshow web入門] web5](http://pic.xiahunao.cn/[ctfshow web入門] web5)





)
)





)



)

