NVIDIA AgentIQ 詳細介紹
1. 引言
NVIDIA AgentIQ 是一個靈活的庫,旨在將企業代理(無論使用何種框架)與各種數據源和工具無縫集成。通過將代理、工具和代理工作流視為簡單的函數調用,AgentIQ 實現了真正的可組合性:一次構建,隨處復用。
AgentIQ 的設計理念是簡化 AI 代理的開發、部署和管理過程,使開發者能夠專注于解決業務問題,而不是處理底層技術細節。無論您是使用哪種代理框架,AgentIQ 都能與之集成,讓您充分利用現有技術棧,同時享受 AgentIQ 帶來的便利和強大功能。
主要功能和優勢
NVIDIA AgentIQ 提供了一系列強大的功能,使其成為開發和管理 AI 代理的理想選擇:
-
框架無關性:與任何代理框架兼容,您可以使用當前的技術棧,無需重新平臺化。
-
可重用性:每個代理、工具或工作流都可以組合和重新利用,使開發者能夠在新場景中利用現有工作。
-
快速開發:從預構建的代理、工具或工作流開始,根據需求進行自定義。
-
性能分析:分析整個工作流直至工具和代理級別,跟蹤輸入/輸出令牌和時間,識別瓶頸。
-
可觀測性:使用任何與 OpenTelemetry 兼容的可觀測性工具監控和調試工作流。
-
評估系統:使用內置評估工具驗證和維護代理工作流的準確性。
-
用戶界面:使用 AgentIQ UI 聊天界面與代理交互,可視化輸出并調試工作流。
-
MCP 兼容性:與模型上下文協議(Model Context Protocol,MCP)兼容,允許使用 MCP 服務器提供的工具作為 AgentIQ 函數。
適用場景和目標用戶
NVIDIA AgentIQ 適用于各種場景,特別是那些需要 AI 代理與多種數據源和工具交互的場景:
- 企業應用開發:需要將 AI 代理集成到現有企業系統中的開發團隊。
- 研究人員和數據科學家:需要快速原型設計和測試不同代理架構的研究人員。
- AI 解決方案提供商:需要構建可靠、可擴展的 AI 代理解決方案的公司。
- 開發者和工程師:希望利用 AI 代理技術但不想被特定框架限制的開發者。
使用 NVIDIA AgentIQ,您可以快速行動,自由實驗,并確保所有代理驅動項目的可靠性。在接下來的章節中,我們將深入探討 AgentIQ 的核心特性、安裝部署步驟、使用方法以及實際案例分析,幫助您全面了解這個強大的工具。
2. NVIDIA AgentIQ 核心特性
NVIDIA AgentIQ 的核心特性圍繞著簡化 AI 代理開發和管理的目標設計。本章將詳細介紹 AgentIQ 的架構、工作流程、工具集成能力以及評估系統,幫助您理解這個強大工具的內部工作原理。
架構概述
AgentIQ 采用模塊化架構,將代理、工具和工作流抽象為函數,實現高度的可組合性和可重用性。其核心架構包括以下組件:
-
函數(Functions):AgentIQ 中的基本構建塊,可以是工具、代理或工作流。每個函數都有明確定義的輸入和輸出,使其可以輕松組合。
-
工作流(Workflows):定義代理如何使用工具和與用戶交互的流程。AgentIQ 支持多種工作流類型,包括 ReAct、函數調用和自定義工作流。
-
語言模型(LLMs):AgentIQ 支持多種語言模型,包括 NVIDIA NIM 服務、OpenAI 和 Anthropic 等。
-
嵌入模型(Embedders):用于文本嵌入的模型,支持向量搜索和相似度計算。
-
評估系統(Evaluation System):用于測試和驗證代理工作流的性能和準確性。
工作流程
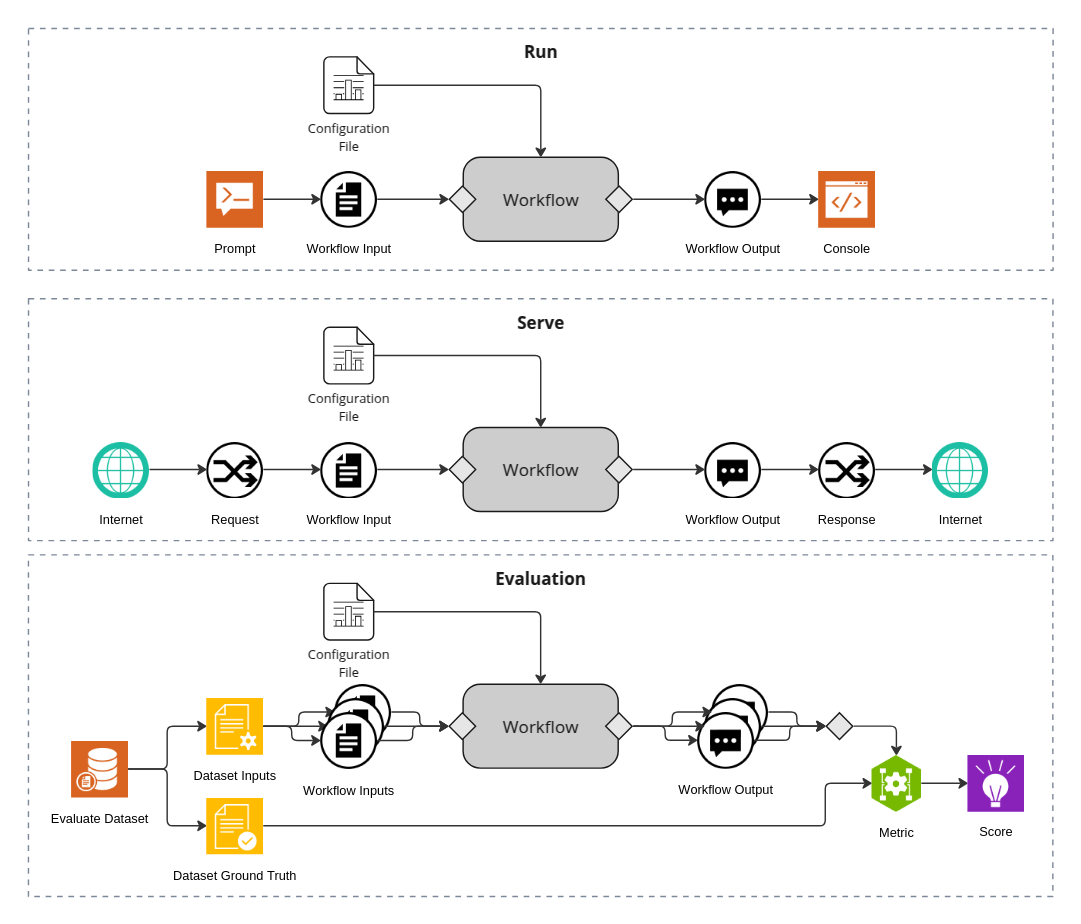
AgentIQ 的工作流程基于函數調用模型,簡化了代理與工具的交互:
-
配置定義:通過 YAML 配置文件定義工作流、工具、模型和參數。
-
函數注冊:工具和代理作為函數注冊到 AgentIQ 系統中。
-
工作流執行:工作流協調代理和工具的交互,處理輸入和輸出。
-
結果生成:工作流生成最終結果并返回給用戶。
這種基于函數的方法使得工作流可以輕松組合和重用,大大提高了開發效率。
工具集成
AgentIQ 的一個主要優勢是其強大的工具集成能力。它提供了多種內置工具,并支持自定義工具的創建:
-
內置工具:包括網頁查詢、搜索引擎、數據庫連接、文件操作等。
-
自定義工具:開發者可以創建自己的工具,并將其注冊為 AgentIQ 函數。
-
工具鏈:多個工具可以組合成工具鏈,實現復雜的功能。
-
MCP 工具:支持使用 Model Context Protocol 服務器提供的工具。
評估系統
AgentIQ 內置了強大的評估系統,用于測試和驗證代理工作流的性能:
-
評估指標:支持多種評估指標,包括精確匹配、語義相似度、RAGAS 指標等。
-
數據集管理:支持創建和管理評估數據集。
-
結果分析:提供詳細的評估結果分析,幫助識別問題和優化機會。
-
持續評估:支持工作流的持續評估,確保性能穩定。
可觀測性和性能分析
AgentIQ 提供了全面的可觀測性和性能分析功能:
-
OpenTelemetry 集成:支持與 OpenTelemetry 兼容的可觀測性工具集成。
-
性能分析:跟蹤工作流、工具和代理的執行時間和令牌使用情況。
-
日志記錄:詳細的日志記錄,幫助調試和優化。
-
可視化:通過 AgentIQ UI 可視化工作流執行過程和結果。
通過這些核心特性,NVIDIA AgentIQ 為開發者提供了一個強大、靈活且易于使用的平臺,用于構建和管理 AI 代理。在下一章中,我們將詳細介紹如何安裝和部署 AgentIQ。
NVIDIA AgentIQ 安裝和部署步驟
本章將詳細介紹如何安裝和部署 NVIDIA AgentIQ,包括環境準備、安裝方法、驗證安裝以及獲取必要的 API 密鑰。我們還將提供常見安裝問題的解決方案,確保您能夠順利開始使用 AgentIQ。
環境準備和前置條件
在開始安裝 NVIDIA AgentIQ 之前,請確保您的系統滿足以下前置條件:
- 安裝 Git
- 安裝 Git Large File Storage (LFS)
- 安裝 uv(Python 包管理工具)
AgentIQ 是一個 Python 庫,不需要 GPU 即可運行工作流。您可以在以下環境中部署核心工作流:
- Ubuntu 或其他 Linux 發行版(包括 WSL)
- Python 虛擬環境
從源代碼安裝
從源代碼安裝 AgentIQ 是最常用的方法,特別是對于開發和測試目的。以下是詳細的安裝步驟:
- 克隆 AgentIQ 倉庫到本地機器:
# 克隆 AgentIQ 倉庫到本地
git clone git@github.com:NVIDIA/AgentIQ.git agentiq
# 進入克隆的倉庫目錄
cd agentiq
- 初始化、獲取并更新 Git 倉庫中的子模塊:
# 初始化并更新所有子模塊,--init 表示初始化,--recursive 表示遞歸處理所有嵌套的子模塊
git submodule update --init --recursive
- 通過下載 LFS 文件獲取數據集:
# 安裝 Git LFS 擴展,用于處理大文件
git lfs install
# 獲取 LFS 文件的元數據
git lfs fetch
# 將 LFS 文件拉取到本地工作目錄
git lfs pull
- 創建 Python 虛擬環境:
# 使用 uv 創建虛擬環境,--seed 參數初始化環境
uv venv --seed .venv
# 激活創建的虛擬環境
source .venv/bin/activate
- 安裝 AgentIQ 庫。您可以選擇安裝完整版(包含所有可選依賴)或僅安裝核心功能:
# 安裝完整版 AgentIQ,包含所有可選依賴
# --all-groups 安裝所有開發工具組
# --all-extras 安裝所有額外依賴
uv sync --all-groups --all-extras# 或者,僅安裝核心 AgentIQ
# -e 表示可編輯模式安裝,適合開發環境
uv pip install -e .
如果您只需要特定的插件,可以單獨安裝它們:
# 安裝 langchain 插件,使用方括號指定額外依賴
uv pip install -e '.[langchain]'# 安裝性能分析相關的依賴
uv pip install -e .[profiling]
- 驗證安裝是否成功:
# 顯示 aiq 命令的幫助信息,驗證命令可用
aiq --help
# 顯示 aiq 的版本信息
aiq --version
如果安裝成功,aiq 命令將顯示幫助信息和當前版本。
使用包管理器安裝
當 AgentIQ 工作流準備部署到生產環境時,部署的工作流需要聲明對 agentiq 包的依賴,以及所需的插件。建議使用版本號的前兩位數字來聲明依賴。
對于使用 pyproject.toml 文件的項目,可以這樣聲明依賴:
dependencies = [# ~=1.0 表示兼容 1.0.x 的任何版本"agentiq[langchain]~=1.0",# 添加工作流需要的其他依賴
]
對于使用 requirements.txt 文件的項目:
# ==1.0.* 表示匹配 1.0.x 的任何版本
agentiq[langchain]==1.0.*
獲取 API 密鑰
根據您運行的工作流,您可能需要從相應的服務獲取 API 密鑰。大多數 AgentIQ 工作流需要一個 NVIDIA API 密鑰,通過 NVIDIA_API_KEY 環境變量定義。
您可以通過訪問 build.nvidia.com 并創建賬戶來獲取 API 密鑰。獲取密鑰后,將其設置為環境變量:
# 設置 NVIDIA API 密鑰為環境變量
export NVIDIA_API_KEY=<您的API密鑰>
常見安裝問題及解決方案
問題:Git LFS 文件未正確下載
解決方案:確保 Git LFS 已正確安裝,并重新運行以下命令:
# 重新安裝 Git LFS
git lfs install
# 重新獲取 LFS 文件元數據
git lfs fetch
# 重新拉取 LFS 文件到工作目錄
git lfs pull
問題:依賴沖突
解決方案:創建一個新的虛擬環境,并使用 --all-groups --all-extras 選項安裝 AgentIQ:
# 創建新的虛擬環境,避免與現有環境沖突
uv venv --seed .venv_new
# 激活新創建的虛擬環境
source .venv_new/bin/activate
# 安裝所有依賴
uv sync --all-groups --all-extras
問題:aiq 命令未找到
解決方案:確保虛擬環境已激活,并檢查安裝是否成功:
# 確保虛擬環境已激活
source .venv/bin/activate
# 查找 aiq 命令的路徑,驗證是否正確安裝
which aiq
如果仍然找不到命令,嘗試重新安裝:
# 重新以可編輯模式安裝 AgentIQ
uv pip install -e .
問題:無法訪問 NVIDIA API
解決方案:確保您已正確設置 NVIDIA API 密鑰環境變量,并檢查網絡連接:
# 檢查 API 密鑰是否正確設置
echo $NVIDIA_API_KEY
# 測試與 NVIDIA 服務器的網絡連接
curl -I https://build.nvidia.com
通過按照上述步驟,您應該能夠成功安裝和部署 NVIDIA AgentIQ。在下一章中,我們將介紹如何開始使用 AgentIQ,包括運行示例工作流和基本命令行界面的使用。
NVIDIA AgentIQ 入門指南
本章將介紹如何開始使用 NVIDIA AgentIQ,包括基本概念、命令行界面、運行示例工作流以及使用 AgentIQ UI。通過本章內容,您將能夠快速上手 AgentIQ,并開始構建自己的 AI 代理應用。
基本概念
在開始使用 AgentIQ 之前,了解一些基本概念是很有幫助的:
-
工作流(Workflow):定義代理如何使用工具和與用戶交互的流程。AgentIQ 支持多種工作流類型,包括 ReAct、函數調用和自定義工作流。
-
函數(Function):AgentIQ 中的基本構建塊,可以是工具、代理或工作流。每個函數都有明確定義的輸入和輸出。
-
工具(Tool):代理可以使用的功能,如網頁查詢、搜索引擎、數據庫連接等。
-
語言模型(LLM):驅動代理的大型語言模型,如 NVIDIA NIM 服務提供的模型。
-
嵌入模型(Embedder):用于文本嵌入的模型,支持向量搜索和相似度計算。
命令行界面
AgentIQ 提供了一個強大的命令行界面(CLI),用于管理和運行工作流。以下是一些基本命令:
查看幫助信息
# 顯示 aiq 命令的幫助信息
aiq --help# 顯示特定子命令的幫助信息
aiq run --help
aiq serve --help
aiq eval --help
查看版本信息
# 顯示 AgentIQ 的版本信息
aiq --version
查看可用組件
# 查看所有可用的組件類型
aiq info components# 查看特定類型的組件
aiq info components -t function
aiq info components -t llm_provider
aiq info components -t workflow
運行示例工作流
AgentIQ 提供了多個示例工作流,幫助您快速上手。以下是運行簡單工作流的步驟:
-
確保您已經完成了安裝和設置 API 密鑰的步驟。
-
運行簡單工作流:
# 運行簡單工作流
aiq run --config_file examples/simple/configs/config.yml --input "你好,請介紹一下自己"
- 觀察工作流的輸出,包括代理的思考過程和最終回答。
使用 AgentIQ 用戶界面和 API 服務器
AgentIQ 提供了一個用戶界面,使您能夠以可視化方式與運行中的工作流交互。根據官方文檔,AgentIQ 提供了以下類型的工作流交互:
- generate non-streaming
- generate streaming
- chat non-streaming
- chat streaming
您可以通過以下方式使用 AgentIQ 的用戶界面功能:
- 啟動 AgentIQ 服務器:
# 使用 FastAPI 啟動 AgentIQ 服務器
aiq start fastapi --config_file examples/simple/configs/config.yml
-
服務器啟動后,您可以訪問 API 文檔(默認地址為 http://localhost:8000/docs)。
-
通過用戶界面,您可以:
- 查看聊天歷史
- 通過 HTTP API 與工作流交互
- 通過 WebSocket 與工作流交互
- 啟用或禁用工作流中間步驟
- 展開所有工作流中間步驟
- 覆蓋具有相同 ID 的中間步驟
示例工作流概述
AgentIQ 包含多個示例工作流,展示了不同的功能和用例:
-
簡單工作流(Simple):基本的問答工作流,展示了 ReAct 代理的工作方式。
-
網頁查詢(Webpage Query):展示如何使用代理查詢網頁內容。
-
搜索引擎(Search Engine):展示如何使用代理搜索互聯網信息。
-
數據分析(Data Analysis):展示如何使用代理進行數據分析任務。
-
多代理(Multi-Agent):展示如何使用多個代理協作完成任務。
您可以在 examples 目錄中找到這些示例工作流,并通過查看它們的配置文件和代碼來學習如何構建自己的工作流。
創建第一個工作流
現在,讓我們創建一個簡單的工作流:
- 創建一個新的工作流目錄:
# 創建工作流目錄
mkdir -p my_workflow/configs
- 創建配置文件
my_workflow/configs/config.yml:
# my_workflow/configs/config.ymlfunctions:current_datetime:_type: current_datetimellms:nim_llm:_type: nimmodel_name: meta/llama-3.1-70b-instructtemperature: 0.0workflow:_type: react_agenttool_names: [current_datetime]llm_name: nim_llmverbose: true
- 運行工作流:
# 運行工作流
aiq run --config_file my_workflow/configs/config.yml --input "現在是什么時間?"
這個簡單的工作流使用 current_datetime 工具來回答關于當前時間的問題。
通過本章內容,您應該已經了解了如何開始使用 NVIDIA AgentIQ,包括基本概念、命令行界面、運行示例工作流以及使用 AgentIQ UI。在下一章中,我們將深入探討 AgentIQ 的工作流配置和使用方法。
NVIDIA AgentIQ 工作流配置和使用
本章將詳細介紹 NVIDIA AgentIQ 的工作流配置和使用方法,包括工作流配置文件結構、使用各種命令運行工作流以及使用 Python API 的方法。通過本章內容,您將能夠深入理解 AgentIQ 工作流的配置和運行機制。
工作流配置文件結構
AgentIQ 工作流由 YAML 配置文件定義,該文件指定了工作流中使用的工具和模型,以及一般配置設置。工作流配置文件通常分為四個主要部分:functions、llms、embedders 和 workflow。
以下是一個簡單工作流的配置文件示例:
# examples/simple/configs/config.ymlfunctions:webpage_query:_type: webpage_query # 工具類型,這里是網頁查詢工具webpage_url: https://docs.smith.langchain.com/user_guide # 要查詢的網頁URLdescription: "搜索關于 LangSmith 的信息。對于任何關于 LangSmith 的問題,您必須使用此工具!" # 工具描述,指導LLM如何使用embedder_name: nv-embedqa-e5-v5 # 用于文本嵌入的模型名稱chunk_size: 512 # 文本分塊大小,用于處理長文本current_datetime:_type: current_datetime # 獲取當前日期和時間的工具llms:nim_llm:_type: nim # LLM類型,這里使用NVIDIA Inference Microservicesmodel_name: meta/llama-3.1-70b-instruct # 使用的模型名稱temperature: 0.0 # 生成文本的隨機性參數,0表示最確定性的輸出embedders:nv-embedqa-e5-v5:_type: nim # 嵌入器類型model_name: nvidia/nv-embedqa-e5-v5 # 使用的嵌入模型名稱workflow:_type: react_agent # 工作流類型,這里是ReAct代理tool_names: [webpage_query, current_datetime] # 工作流使用的工具列表llm_name: nim_llm # 工作流使用的LLM名稱verbose: true # 是否輸出詳細信息retry_parsing_errors: true # 是否重試解析錯誤max_retries: 3 # 最大重試次數
讓我們詳細解析這個配置文件的各個部分:
functions 部分
functions 部分定義了工作流中使用的工具。在上面的例子中,定義了兩個工具:
-
webpage_query:用于查詢網頁內容的工具_type:工具類型webpage_url:要查詢的網頁 URLdescription:工具描述,用于指導 LLM 如何使用該工具embedder_name:用于嵌入的模型名稱chunk_size:文本分塊大小
-
current_datetime:獲取當前日期和時間的工具
llms 部分
llms 部分定義了工作流中使用的語言模型:
nim_llm:使用 NVIDIA Inference Microservices (NIM) 的 LLM_type:LLM 類型model_name:使用的模型名稱temperature:生成文本的隨機性參數
embedders 部分
embedders 部分定義了用于文本嵌入的模型:
nv-embedqa-e5-v5:NVIDIA 的嵌入模型_type:嵌入器類型model_name:使用的模型名稱
workflow 部分
workflow 部分定義了工作流本身:
_type:工作流類型,這里是react_agenttool_names:工作流使用的工具列表llm_name:工作流使用的 LLM 名稱verbose:是否輸出詳細信息retry_parsing_errors:是否重試解析錯誤max_retries:最大重試次數
使用 aiq run 命令運行工作流
aiq run 命令是運行工作流的最簡單方式。它接收一個配置文件和輸入內容:
# 基本語法
aiq run --config_file <配置文件路徑> [--input "問題?" | --input_file <輸入文件路徑>]
# --config_file: 指定工作流配置文件的路徑
# --input: 直接提供輸入問題
# --input_file: 從文件中讀取輸入問題
例如,運行簡單工作流并提供輸入問題:
# 使用直接輸入運行工作流
aiq run --config_file examples/simple/configs/config.yml --input "什么是LangSmith?"
# 使用配置文件examples/simple/configs/config.yml運行工作流
# 輸入問題是"什么是LangSmith?"
您也可以通過文件提供輸入:
# 創建輸入文件
echo "什么是LangSmith?" > .tmp/input.txt
# 將問題"什么是LangSmith?"寫入.tmp/input.txt文件# 使用文件輸入運行工作流
aiq run --config_file examples/simple/configs/config.yml --input_file .tmp/input.txt
# 使用配置文件examples/simple/configs/config.yml運行工作流
# 從.tmp/input.txt文件讀取輸入問題
覆蓋配置參數
您可以使用 --override 參數在運行時覆蓋配置文件中的參數:
# 覆蓋 LLM 的溫度參數
aiq run --config_file examples/simple/configs/config.yml --input "什么是LangSmith?" \--override llms.nim_llm.temperature 0.7
# 使用配置文件運行工作流,但覆蓋LLM的溫度參數為0.7
# 格式為 --override 參數路徑 參數值
您也可以覆蓋多個參數:
# 覆蓋多個參數
aiq run --config_file examples/simple/configs/config.yml --input "什么是LangSmith?" \--override llms.nim_llm.temperature 0.7 \--override llms.nim_llm.model_name meta/llama-3.3-70b-instruct
# 同時覆蓋溫度參數和模型名稱
# 可以連續使用多個--override參數覆蓋不同的配置項
使用 aiq serve 命令部署工作流
aiq serve 命令啟動一個 Web 服務器,監聽傳入請求并運行指定的工作流:
# 啟動工作流服務器
aiq serve --config_file examples/simple/configs/config.yml
# 使用配置文件啟動Web服務器
# 默認監聽端口8000和端點/generate
默認情況下,服務器監聽端口 8000 和端點 /generate。您可以使用以下命令自定義端口和端點:
# 自定義端口和端點
aiq serve --config_file examples/simple/configs/config.yml --port 9000 --endpoint /api/generate
# --port 9000: 指定服務器監聽端口為9000
# --endpoint /api/generate: 指定API端點為/api/generate
在另一個終端中,您可以使用 curl 發送請求與服務器交互:
# 向工作流服務器發送請求
curl --request POST \--url http://localhost:8000/generate \--header 'Content-Type: application/json' \--data '{"input_message": "什么是LangSmith?"
}'
# --request POST: 指定HTTP方法為POST
# --url: 指定服務器URL
# --header: 設置Content-Type頭為application/json
# --data: 提供JSON格式的請求體,包含input_message字段
使用 aiq eval 命令評估工作流
aiq eval 命令用于評估工作流的準確性:
# 評估工作流
aiq eval --config_file examples/simple/configs/eval_config.yml
# 使用評估配置文件運行工作流評估
# 評估配置文件包含工作流配置和評估特定配置
評估配置文件 (eval_config.yml) 是工作流配置文件的超集,包含額外的評估字段。以下是一個評估配置示例:
# examples/simple/configs/eval_config.yml# 包含基本工作流配置
functions:webpage_query:_type: webpage_querywebpage_url: https://docs.smith.langchain.com/user_guidedescription: "搜索關于 LangSmith 的信息。對于任何關于 LangSmith 的問題,您必須使用此工具!"embedder_name: nv-embedqa-e5-v5chunk_size: 512current_datetime:_type: current_datetimellms:nim_llm:_type: nimmodel_name: meta/llama-3.1-70b-instructtemperature: 0.0embedders:nv-embedqa-e5-v5:_type: nimmodel_name: nvidia/nv-embedqa-e5-v5workflow:_type: react_agenttool_names: [webpage_query, current_datetime]llm_name: nim_llmverbose: trueretry_parsing_errors: truemax_retries: 3# 評估特定配置
eval:general:output_dir: ./.tmp/aiq/examples/simple/ # 評估結果輸出目錄dataset:_type: json # 數據集類型file_path: examples/simple/data/langsmith.json # 數據集文件路徑evaluators:exact_match: # 精確匹配評估器_type: exact_match # 評估器類型
使用 Python API
除了命令行界面外,AgentIQ 還提供了 Python API,使您能夠以編程方式運行和管理工作流。以下是一個使用 Python API 運行工作流的示例:
from aiq.runner import AIQRunner # 導入AIQRunner類
import yaml # 導入yaml模塊用于解析YAML文件# 加載配置文件
with open("examples/simple/configs/config.yml", "r") as f:config = yaml.safe_load(f) # 解析YAML配置文件# 創建 AIQRunner 實例
runner = AIQRunner(config) # 使用配置創建運行器實例# 運行工作流
result = runner.run("什么是LangSmith?") # 運行工作流并傳入輸入問題# 打印結果
print(result) # 輸出工作流執行結果
使用 Python API 的優勢在于它提供了更大的靈活性和可編程性,使您能夠將 AgentIQ 工作流集成到更大的應用程序中。
通過本章內容,您應該已經了解了 AgentIQ 工作流的配置和使用方法。在下一章中,我們將探討如何自定義工作流,包括修改現有工作流、添加工具和創建新工作流。
NVIDIA AgentIQ 自定義工作流
本章將詳細介紹如何自定義 NVIDIA AgentIQ 工作流,包括修改現有工作流、添加工具到工作流、創建新工具和工作流以及工作流參數覆蓋。通過本章內容,您將能夠根據自己的需求定制 AgentIQ 工作流。
修改現有工作流
在前面的章節中,我們已經了解了工作流配置文件的結構。現在,我們將探討如何修改現有工作流以滿足特定需求。
每個工作流 YAML 文件包含多個可以修改的配置參數。雖然可以直接復制和修改原始 YAML 文件,但有些參數可以使用 --override 標志在不修改原始文件的情況下覆蓋。
使用 --override 修改參數
例如,要修改 LLM 的溫度參數,可以使用以下命令:
# 覆蓋 LLM 的溫度參數
aiq run --config_file examples/simple/configs/config.yml --input "什么是LangSmith?" \--override llms.nim_llm.temperature 0.7
# 使用--override參數覆蓋配置文件中的LLM溫度參數
# 格式為:--override 參數路徑 參數值
讓我們看一個更復雜的例子,修改 LLM 模型和溫度:
# 覆蓋 LLM 模型和溫度
aiq run --config_file examples/simple/configs/config.yml --input "什么是LangSmith?" \--override llms.nim_llm.temperature 0.7 \--override llms.nim_llm.model_name meta/llama-3.3-70b-instruct
# 同時覆蓋兩個參數:溫度和模型名稱
# 可以連續使用多個--override參數來修改不同的配置項
查看可用參數
要查看特定組件的所有可用參數,可以使用 aiq info components 命令:
# 查看 NIM LLM 提供商的參數
aiq info components -t llm_provider -q nim
# -t llm_provider:指定組件類型為LLM提供商
# -q nim:查詢名稱為nim的組件
# 這將顯示NIM LLM提供商的所有可配置參數及其默認值
這將顯示所有可配置的參數及其默認值。
添加工具到工作流
在前面的例子中,我們使用了一個包含兩個工具的工作流:webpage_query 和 current_datetime。現在,我們將探討如何向工作流添加新工具。
添加 Web 搜索工具
假設我們想添加一個 Web 搜索工具,以便工作流可以搜索互聯網上的信息。我們需要修改配置文件,添加新工具并更新工作流配置:
# 添加 web_search 工具的配置文件functions:webpage_query:_type: webpage_query # 網頁查詢工具類型webpage_url: https://docs.smith.langchain.com/user_guide # 要查詢的網頁URLdescription: "搜索關于 LangSmith 的信息。對于任何關于 LangSmith 的問題,您必須使用此工具!" # 工具描述embedder_name: nv-embedqa-e5-v5 # 用于嵌入的模型名稱chunk_size: 512 # 文本分塊大小current_datetime:_type: current_datetime # 獲取當前日期和時間的工具web_search:_type: web_search # 新添加的Web搜索工具description: "搜索互聯網上的信息。對于 LangSmith 以外的問題,使用此工具。" # 工具描述search_engine: "google" # 使用的搜索引擎num_results: 3 # 返回的搜索結果數量llms:nim_llm:_type: nimmodel_name: meta/llama-3.1-70b-instructtemperature: 0.0embedders:nv-embedqa-e5-v5:_type: nimmodel_name: nvidia/nv-embedqa-e5-v5workflow:_type: react_agenttool_names: [webpage_query, current_datetime, web_search] # 更新工具列表,添加web_searchllm_name: nim_llmverbose: trueretry_parsing_errors: truemax_retries: 3
注意我們在 functions 部分添加了 web_search 工具,并在 workflow 部分的 tool_names 列表中包含了這個新工具。
查詢可用工具
AgentIQ 包含多個內置工具,可以添加到任何工作流中。要查詢可用的工具,可以使用以下命令:
# 查詢所有可用的函數(工具)
aiq info components -t function
# -t function:指定查詢組件類型為function(工具)
# 這將列出所有可用的內置工具及其描述
創建新工具和工作流
除了使用內置工具外,您還可以創建自己的自定義工具和工作流。AgentIQ 提供了 aiq workflow create 命令來簡化這個過程。
創建新工作流
以下是創建新工作流的步驟:
# 創建一個新的工作流
aiq workflow create --workflow-dir examples text_file_ingest
# --workflow-dir examples:指定工作流目錄為examples
# text_file_ingest:新工作流的名稱
# 這個命令會創建一個新的工作流項目結構
這個命令會執行以下操作:
- 創建一個新目錄
examples/text_file_ingest - 設置必要的文件和文件夾
- 安裝新的 Python 包到您的環境中
創建的目錄結構如下:
examples/
└── text_file_ingest/├── configs/│ └── config.yml├── data/├── pyproject.toml├── README.md└── src/└── aiq_text_file_ingest/├── __init__.py└── functions/└── __init__.py
創建自定義工具
現在,讓我們創建一個自定義工具,用于從本地文本文件中提取信息。首先,在 src/aiq_text_file_ingest/functions/ 目錄下創建一個新文件 text_reader.py:
# src/aiq_text_file_ingest/functions/text_reader.pyfrom typing import Dict, Any, Optional # 導入類型提示所需的類型
import os # 導入操作系統模塊,用于文件路徑操作def text_reader(file_path: str, start_line: Optional[int] = 0, end_line: Optional[int] = None) -> Dict[str, Any]:"""從文本文件中讀取內容。參數:file_path: 要讀取的文本文件路徑start_line: 開始讀取的行號(從0開始)end_line: 結束讀取的行號(不包含)返回:包含文件內容的字典"""# 檢查文件是否存在if not os.path.exists(file_path):return {"error": f"文件不存在: {file_path}"} # 如果文件不存在,返回錯誤信息try:with open(file_path, 'r', encoding='utf-8') as f: # 以UTF-8編碼打開文件lines = f.readlines() # 讀取所有行# 應用行范圍if end_line is None:content = lines[start_line:] # 如果沒有指定結束行,讀取從開始行到文件末尾else:content = lines[start_line:end_line] # 否則讀取指定范圍的行return {"content": "".join(content), # 將讀取的行合并為一個字符串"total_lines": len(lines), # 返回文件總行數"read_lines": len(content) # 返回實際讀取的行數}except Exception as e:return {"error": f"讀取文件時出錯: {str(e)}"} # 捕獲并返回任何讀取錯誤
然后,在 __init__.py 文件中注冊這個函數:
# src/aiq_text_file_ingest/functions/__init__.pyfrom .text_reader import text_reader # 導入text_reader函數__all__ = ["text_reader"] # 聲明模塊公開的函數,使其可被導入
更新工作流配置
接下來,更新 configs/config.yml 文件以使用新創建的工具:
# configs/config.ymlfunctions:text_reader:_type: text_reader # 使用我們創建的自定義工具description: "從文本文件中讀取內容。提供文件路徑、開始行和結束行(可選)。" # 工具描述llms:nim_llm:_type: nimmodel_name: meta/llama-3.1-70b-instructtemperature: 0.0workflow:_type: react_agenttool_names: [text_reader] # 工作流使用的工具列表,只包含我們的自定義工具llm_name: nim_llmverbose: trueretry_parsing_errors: truemax_retries: 3
重新構建并運行
創建自定義工具后,需要重新構建工作流并運行:
# 重新安裝工作流包
uv pip install -e examples/text_file_ingest
# -e 表示可編輯模式安裝,適合開發環境
# 這將安裝我們創建的自定義工作流包# 運行工作流
aiq run --config_file examples/text_file_ingest/configs/config.yml --input "請讀取 /path/to/example.txt 文件的內容"
# 使用我們的自定義工作流配置運行工作流
# 輸入是一個請求讀取文件內容的問題
工作流參數覆蓋
除了使用 --override 標志外,您還可以在配置文件中使用環境變量來覆蓋參數。這對于在不同環境中部署工作流特別有用。
使用環境變量
在配置文件中,您可以使用 ${ENV_VAR} 語法引用環境變量:
# 使用環境變量的配置文件functions:webpage_query:_type: webpage_querywebpage_url: ${WEBPAGE_URL:-https://docs.smith.langchain.com/user_guide} # 使用環境變量WEBPAGE_URL,如果未設置則使用默認值description: "搜索關于 LangSmith 的信息。對于任何關于 LangSmith 的問題,您必須使用此工具!"embedder_name: nv-embedqa-e5-v5chunk_size: 512llms:nim_llm:_type: nimmodel_name: ${MODEL_NAME:-meta/llama-3.1-70b-instruct} # 使用環境變量MODEL_NAME,如果未設置則使用默認值temperature: ${TEMPERATURE:-0.0} # 使用環境變量TEMPERATURE,如果未設置則使用默認值# ... 其余配置 ...
在這個例子中,如果環境變量 WEBPAGE_URL、MODEL_NAME 或 TEMPERATURE 已設置,則使用它們的值;否則,使用冒號后面的默認值。
設置環境變量并運行
# 設置環境變量并運行工作流
export WEBPAGE_URL="https://python.langchain.com/docs/get_started" # 設置網頁URL環境變量
export MODEL_NAME="meta/llama-3.3-70b-instruct" # 設置模型名稱環境變量
export TEMPERATURE="0.5" # 設置溫度參數環境變量aiq run --config_file examples/simple/configs/config.yml --input "什么是LangChain?"
# 運行工作流,配置將使用我們設置的環境變量值
通過本章內容,您應該已經了解了如何自定義 AgentIQ 工作流,包括修改現有工作流、添加工具、創建新工具和工作流以及使用參數覆蓋。在下一章中,我們將通過實際案例分析,展示如何應用這些知識構建實用的 AI 代理應用。
NVIDIA AgentIQ 案例分析
本章將通過四個具體案例,展示如何使用 NVIDIA AgentIQ 構建和部署不同類型的 AI 代理應用。這些案例涵蓋了從簡單問答到復雜工具集成的多種場景,幫助您理解 AgentIQ 的實際應用方式。
案例一:構建簡單問答工作流
我們的第一個案例是構建一個簡單的問答工作流,它能夠回答關于 LangSmith 的問題。這個案例基于我們之前討論過的 examples/simple 工作流。
工作流配置
首先,讓我們回顧一下工作流配置:
# examples/simple/configs/config.ymlfunctions:webpage_query:_type: webpage_query # 網頁查詢工具類型webpage_url: https://docs.smith.langchain.com/user_guide # 要查詢的LangSmith文檔URLdescription: "搜索關于 LangSmith 的信息。對于任何關于 LangSmith 的問題,您必須使用此工具!" # 工具描述embedder_name: nv-embedqa-e5-v5 # 用于文本嵌入的模型名稱chunk_size: 512 # 文本分塊大小current_datetime:_type: current_datetime # 獲取當前日期和時間的工具llms:nim_llm:_type: nim # LLM類型model_name: meta/llama-3.1-70b-instruct # 使用的模型名稱temperature: 0.0 # 生成文本的隨機性參數embedders:nv-embedqa-e5-v5:_type: nim # 嵌入器類型model_name: nvidia/nv-embedqa-e5-v5 # 使用的嵌入模型名稱workflow:_type: react_agent # 工作流類型tool_names: [webpage_query, current_datetime] # 工作流使用的工具列表llm_name: nim_llm # 工作流使用的LLM名稱verbose: true # 是否輸出詳細信息retry_parsing_errors: true # 是否重試解析錯誤max_retries: 3 # 最大重試次數
運行工作流
安裝并運行工作流:
# 安裝工作流
uv pip install -e examples/simple
# -e 表示可編輯模式安裝,適合開發環境
# 安裝examples/simple目錄下的工作流包# 運行工作流
aiq run --config_file examples/simple/configs/config.yml --input "什么是LangSmith?它有哪些主要功能?"
# 使用配置文件運行工作流
# 輸入問題是"什么是LangSmith?它有哪些主要功能?"
工作流執行過程
當我們運行這個工作流時,以下是執行過程:
- 工作流接收用戶輸入:“什么是LangSmith?它有哪些主要功能?”
- ReAct Agent 分析問題,確定需要使用
webpage_query工具 webpage_query工具查詢 LangSmith 用戶指南網頁- 使用嵌入模型
nv-embedqa-e5-v5對網頁內容進行嵌入 - 檢索與問題最相關的內容
- LLM 生成最終回答
輸出示例
Workflow Result:
LangSmith 是一個用于 LLM 應用程序開發、監控和測試的平臺。它支持應用程序開發生命周期中的各種工作流,包括:主要功能:
1. 原型設計:快速實驗不同的提示、模型類型和檢索策略
2. 調試:使用跟蹤和應用程序跟蹤調試問題
3. 測試:創建數據集并運行評估
4. 監控:監控生產中的應用程序
5. 自動化:設置自動化以簡化工作流程
6. 線程:管理對話歷史記錄
7. 注釋跟蹤:添加元數據和反饋
8. 數據集管理:將運行添加到數據集中LangSmith 提供了一個統一的界面,使開發人員能夠更有效地構建、評估和監控他們的 LLM 應用程序。
案例二:添加網頁查詢功能
在第二個案例中,我們將擴展前一個工作流,添加一個通用的網頁查詢功能,使代理能夠查詢任何指定的網頁。
創建新工作流
首先,我們創建一個新的工作流:
# 創建新工作流
aiq workflow create --workflow-dir examples web_query
# --workflow-dir examples:指定工作流目錄為examples
# web_query:新工作流的名稱
# 這個命令會創建一個新的工作流項目結構
自定義工作流配置
修改配置文件 examples/web_query/configs/config.yml:
# examples/web_query/configs/config.ymlfunctions:dynamic_webpage_query:_type: dynamic_webpage_query # 動態網頁查詢工具類型description: "查詢任何網頁的內容。提供完整的URL,包括http://或https://前綴。" # 工具描述embedder_name: nv-embedqa-e5-v5 # 用于文本嵌入的模型名稱chunk_size: 512 # 文本分塊大小current_datetime:_type: current_datetime # 獲取當前日期和時間的工具llms:nim_llm:_type: nim # LLM類型model_name: meta/llama-3.1-70b-instruct # 使用的模型名稱temperature: 0.0 # 生成文本的隨機性參數embedders:nv-embedqa-e5-v5:_type: nim # 嵌入器類型model_name: nvidia/nv-embedqa-e5-v5 # 使用的嵌入模型名稱workflow:_type: react_agent # 工作流類型tool_names: [dynamic_webpage_query, current_datetime] # 工作流使用的工具列表llm_name: nim_llm # 工作流使用的LLM名稱verbose: true # 是否輸出詳細信息retry_parsing_errors: true # 是否重試解析錯誤max_retries: 3 # 最大重試次數
創建動態網頁查詢工具
在 src/aiq_web_query/functions/ 目錄下創建 dynamic_webpage_query.py 文件:
# src/aiq_web_query/functions/dynamic_webpage_query.pyfrom typing import Dict, Any, Optional # 導入類型提示所需的類型
import requests # 導入HTTP請求庫
from bs4 import BeautifulSoup # 導入HTML解析庫
import numpy as np # 導入數值計算庫
from aiq.embedders import get_embedder # 導入AgentIQ嵌入器獲取函數def dynamic_webpage_query(query: str, # 查詢文本url: str, # 要查詢的網頁URLembedder_name: str = "nv-embedqa-e5-v5", # 默認使用的嵌入模型chunk_size: int = 512, # 默認文本分塊大小top_k: int = 3 # 默認返回的最相關塊數量
) -> Dict[str, Any]:"""查詢指定網頁的內容并返回與查詢最相關的部分。參數:query: 查詢文本url: 要查詢的網頁URLembedder_name: 用于嵌入的模型名稱chunk_size: 文本分塊大小top_k: 返回的最相關塊數量返回:包含查詢結果的字典"""try:# 獲取網頁內容response = requests.get(url) # 發送GET請求獲取網頁response.raise_for_status() # 如果請求失敗,拋出異常# 解析HTMLsoup = BeautifulSoup(response.text, 'html.parser') # 使用BeautifulSoup解析HTML# 提取文本內容text = soup.get_text(separator=' ', strip=True) # 提取所有文本,使用空格分隔,去除首尾空白# 分塊chunks = []for i in range(0, len(text), chunk_size): # 按指定大小分塊chunks.append(text[i:i+chunk_size])if not chunks:return {"result": "網頁內容為空"} # 如果沒有內容,返回空結果# 獲取嵌入器embedder = get_embedder(embedder_name) # 獲取指定的嵌入模型# 計算查詢和塊的嵌入query_embedding = embedder.embed_query(query) # 計算查詢文本的嵌入向量chunk_embeddings = embedder.embed_documents(chunks) # 計算所有文本塊的嵌入向量# 計算相似度similarities = []for chunk_embedding in chunk_embeddings:similarity = np.dot(query_embedding, chunk_embedding) # 計算點積相似度similarities.append(similarity)# 獲取最相關的塊top_indices = np.argsort(similarities)[-top_k:][::-1] # 獲取相似度最高的top_k個索引top_chunks = [chunks[i] for i in top_indices] # 獲取對應的文本塊return {"result": "\n\n".join(top_chunks), # 將最相關的塊合并為結果"url": url # 返回查詢的URL}except Exception as e:return {"error": f"查詢網頁時出錯: {str(e)}"} # 捕獲并返回任何錯誤
在 __init__.py 文件中注冊這個函數:
# src/aiq_web_query/functions/__init__.pyfrom .dynamic_webpage_query import dynamic_webpage_query # 導入動態網頁查詢函數__all__ = ["dynamic_webpage_query"] # 聲明模塊公開的函數,使其可被導入
安裝并運行工作流
# 安裝工作流
uv pip install -e examples/web_query
# -e 表示可編輯模式安裝,適合開發環境
# 安裝examples/web_query目錄下的工作流包# 運行工作流
aiq run --config_file examples/web_query/configs/config.yml --input "請查詢 https://python.langchain.com/docs/get_started 并告訴我 LangChain 是什么"
# 使用配置文件運行工作流
# 輸入是一個請求查詢LangChain文檔并解釋LangChain的問題
案例三:創建自定義工具
在第三個案例中,我們將創建一個更復雜的自定義工具,用于執行 Python 代碼并返回結果。這對于數據分析和計算任務特別有用。
創建新工作流
# 創建新工作流
aiq workflow create --workflow-dir examples code_executor
# --workflow-dir examples:指定工作流目錄為examples
# code_executor:新工作流的名稱
# 這個命令會創建一個新的工作流項目結構
創建代碼執行工具
在 src/aiq_code_executor/functions/ 目錄下創建 python_executor.py 文件:
# src/aiq_code_executor/functions/python_executor.pyfrom typing import Dict, Any # 導入類型提示所需的類型
import sys # 導入系統模塊
import io # 導入輸入輸出模塊
import traceback # 導入異常跟蹤模塊
from contextlib import redirect_stdout, redirect_stderr # 導入上下文管理器,用于重定向輸出def python_executor(code: str, timeout: int = 10) -> Dict[str, Any]:"""執行Python代碼并返回結果。參數:code: 要執行的Python代碼timeout: 執行超時時間(秒)返回:包含執行結果的字典"""# 捕獲標準輸出和標準錯誤stdout_capture = io.StringIO() # 創建標準輸出捕獲器stderr_capture = io.StringIO() # 創建標準錯誤捕獲器# 存儲執行結果result = None # 初始化結果變量error = None # 初始化錯誤變量try:# 設置執行環境exec_globals = {"__builtins__": __builtins__, # 包含Python內置函數和變量"print": print, # 提供print函數"Exception": Exception, # 提供Exception類}# 重定向輸出with redirect_stdout(stdout_capture), redirect_stderr(stderr_capture):# 執行代碼try:# 使用 exec 執行代碼塊exec(code, exec_globals) # 在指定的全局命名空間中執行代碼# 如果代碼中有 result 變量,獲取它if "result" in exec_globals:result = exec_globals["result"] # 獲取代碼執行后的result變量except Exception as e:error = f"{type(e).__name__}: {str(e)}\n{traceback.format_exc()}" # 捕獲并格式化執行錯誤# 獲取捕獲的輸出stdout = stdout_capture.getvalue() # 獲取標準輸出內容stderr = stderr_capture.getvalue() # 獲取標準錯誤內容# 構建返回結果return {"result": result, # 返回執行結果"stdout": stdout, # 返回標準輸出"stderr": stderr, # 返回標準錯誤"error": error # 返回錯誤信息}except Exception as e:return {"error": f"執行代碼時出錯: {str(e)}"} # 捕獲并返回任何執行錯誤
在 __init__.py 文件中注冊這個函數:
# src/aiq_code_executor/functions/__init__.pyfrom .python_executor import python_executor # 導入Python代碼執行函數__all__ = ["python_executor"] # 聲明模塊公開的函數,使其可被導入
更新工作流配置
修改配置文件 examples/code_executor/configs/config.yml:
# examples/code_executor/configs/config.ymlfunctions:python_executor:_type: python_executor # Python代碼執行工具類型description: "執行Python代碼并返回結果。提供完整的Python代碼塊。" # 工具描述current_datetime:_type: current_datetime # 獲取當前日期和時間的工具llms:nim_llm:_type: nim # LLM類型model_name: meta/llama-3.1-70b-instruct # 使用的模型名稱temperature: 0.0 # 生成文本的隨機性參數workflow:_type: react_agent # 工作流類型tool_names: [python_executor, current_datetime] # 工作流使用的工具列表llm_name: nim_llm # 工作流使用的LLM名稱verbose: true # 是否輸出詳細信息retry_parsing_errors: true # 是否重試解析錯誤max_retries: 3 # 最大重試次數
安裝并運行工作流
# 安裝工作流
uv pip install -e examples/code_executor
# -e 表示可編輯模式安裝,適合開發環境
# 安裝examples/code_executor目錄下的工作流包# 運行工作流
aiq run --config_file examples/code_executor/configs/config.yml --input "請計算斐波那契數列的前10個數字"
# 使用配置文件運行工作流
# 輸入是一個請求計算斐波那契數列的問題
示例輸出
Workflow Result:
斐波那契數列的前10個數字是:0, 1, 1, 2, 3, 5, 8, 13, 21, 34我使用Python代碼計算了這個結果:```python
def fibonacci(n):"""生成斐波那契數列的前n個數字"""fib_sequence = [0, 1]for i in range(2, n):fib_sequence.append(fib_sequence[i-1] + fib_sequence[i-2])return fib_sequence# 計算前10個斐波那契數
result = fibonacci(10)
print("斐波那契數列的前10個數字:", result)
執行結果顯示了斐波那契數列的前10個數字:[0, 1, 1, 2, 3, 5, 8, 13, 21, 34]
## 案例四:評估工作流性能在最后一個案例中,我們將展示如何評估工作流的性能,這對于確保 AI 代理的質量和可靠性至關重要。### 創建評估數據集首先,我們需要創建一個評估數據集。在 `examples/simple/data/` 目錄下創建 `eval_dataset.json` 文件:```json
[{"id": 1,"input": "什么是LangSmith?","expected_output": "LangSmith是一個用于LLM應用程序開發、監控和測試的平臺。"},{"id": 2,"input": "如何使用LangSmith進行原型設計?","expected_output": "使用LangSmith進行原型設計,可以快速實驗不同的提示、模型類型和檢索策略。"},{"id": 3,"input": "LangSmith有哪些主要功能?","expected_output": "LangSmith的主要功能包括原型設計、調試、測試、監控、自動化、線程管理、注釋跟蹤和數據集管理。"}
]
創建評估配置
創建評估配置文件 examples/simple/configs/eval_config.yml:
# examples/simple/configs/eval_config.yml# 包含基本工作流配置
functions:webpage_query:_type: webpage_query # 網頁查詢工具類型webpage_url: https://docs.smith.langchain.com/user_guide # 要查詢的網頁URLdescription: "搜索關于 LangSmith 的信息。對于任何關于 LangSmith 的問題,您必須使用此工具!" # 工具描述embedder_name: nv-embedqa-e5-v5 # 用于嵌入的模型名稱chunk_size: 512 # 文本分塊大小current_datetime:_type: current_datetime # 獲取當前日期和時間的工具llms:nim_llm:_type: nim # LLM類型model_name: meta/llama-3.1-70b-instruct # 使用的模型名稱temperature: 0.0 # 生成文本的隨機性參數embedders:nv-embedqa-e5-v5:_type: nim # 嵌入器類型model_name: nvidia/nv-embedqa-e5-v5 # 使用的嵌入模型名稱workflow:_type: react_agent # 工作流類型tool_names: [webpage_query, current_datetime] # 工作流使用的工具列表llm_name: nim_llm # 工作流使用的LLM名稱verbose: true # 是否輸出詳細信息retry_parsing_errors: true # 是否重試解析錯誤max_retries: 3 # 最大重試次數# 評估特定配置
eval:general:output_dir: ./.tmp/aiq/examples/simple/ # 評估結果輸出目錄dataset:_type: json # 數據集類型file_path: examples/simple/data/eval_dataset.json # 數據集文件路徑evaluators:exact_match: # 精確匹配評估器_type: exact_match # 評估器類型semantic_similarity: # 語義相似度評估器_type: semantic_similarity # 評估器類型llm_name: nim_llm # 使用的LLM名稱ragas: # RAGAS評估器_type: ragas # 評估器類型metrics: ["faithfulness", "answer_relevancy"] # 使用的評估指標
運行評估
# 運行評估
aiq eval --config_file examples/simple/configs/eval_config.yml
# 使用評估配置文件運行工作流評估
# 評估結果將保存在指定的輸出目錄中
分析評估結果
評估完成后,結果將保存在指定的輸出目錄中。您可以查看詳細的評估指標,包括:
- 精確匹配分數:衡量生成的答案與預期答案的精確匹配程度
- 語義相似度:衡量生成的答案與預期答案的語義相似程度
- RAGAS 指標:
- 忠實度:生成的答案是否忠實于檢索的上下文
- 答案相關性:生成的答案與問題的相關程度
通過這些指標,您可以全面評估工作流的性能,并根據需要進行優化。
可視化評估結果
您可以使用 Python 腳本可視化評估結果:
# visualization.pyimport json # 導入JSON處理模塊
import matplotlib.pyplot as plt # 導入繪圖模塊
import pandas as pd # 導入數據分析模塊# 加載評估結果
with open('./.tmp/aiq/examples/simple/eval_results.json', 'r') as f:results = json.load(f) # 從JSON文件加載評估結果# 提取指標
metrics = {'exact_match': [], # 存儲精確匹配分數'semantic_similarity': [], # 存儲語義相似度分數'faithfulness': [], # 存儲忠實度分數'answer_relevancy': [] # 存儲答案相關性分數
}for item in results['eval_output_items']:# 從每個評估項中提取各項指標分數metrics['exact_match'].append(item['evaluators'].get('exact_match', {}).get('score', 0))metrics['semantic_similarity'].append(item['evaluators'].get('semantic_similarity', {}).get('score', 0))metrics['faithfulness'].append(item['evaluators'].get('ragas', {}).get('faithfulness', 0))metrics['answer_relevancy'].append(item['evaluators'].get('ragas', {}).get('answer_relevancy', 0))# 創建DataFrame
df = pd.DataFrame(metrics) # 將指標數據轉換為DataFrame# 計算平均分數
avg_scores = df.mean() # 計算每個指標的平均分數# 繪制條形圖
plt.figure(figsize=(10, 6)) # 創建圖形,設置大小
avg_scores.plot(kind='bar', color=['blue', 'green', 'orange', 'red']) # 繪制條形圖
plt.title('工作流評估指標平均分數') # 設置圖表標題
plt.ylabel('分數') # 設置Y軸標簽
plt.ylim(0, 1) # 設置Y軸范圍
plt.grid(axis='y', linestyle='--', alpha=0.7) # 添加網格線
plt.savefig('evaluation_metrics.png') # 保存圖表為PNG文件
plt.close() # 關閉圖表# 打印平均分數
print("評估指標平均分數:")
for metric, score in avg_scores.items():print(f"{metric}: {score:.4f}") # 打印每個指標的平均分數,保留4位小數
通過這四個案例,我們展示了 NVIDIA AgentIQ 在不同場景下的應用方式,從簡單的問答到復雜的代碼執行和性能評估。這些案例涵蓋了 AgentIQ 的核心功能,幫助您理解如何利用這個強大的工具構建自己的 AI 代理應用。
總結與展望
在本博客中,我們深入探討了 NVIDIA AgentIQ 這一強大的 AI 代理開發工具。從基本概念到實際應用案例,我們全面介紹了 AgentIQ 的各個方面,幫助您理解如何利用這個工具構建和部署 AI 代理應用。
主要內容回顧
我們首先介紹了 AgentIQ 的核心特性和設計理念,包括其框架無關性、可重用性、快速開發能力以及強大的評估系統。這些特性使 AgentIQ 成為開發和管理 AI 代理的理想選擇。
接著,我們詳細講解了 AgentIQ 的安裝和部署步驟,包括環境準備、從源代碼安裝、使用包管理器安裝以及獲取必要的 API 密鑰。我們還提供了常見安裝問題的解決方案,確保您能夠順利開始使用 AgentIQ。
在入門指南中,我們介紹了 AgentIQ 的基本概念、命令行界面、運行示例工作流以及使用 AgentIQ UI 的方法。這些基礎知識為后續的深入學習奠定了基礎。
我們深入探討了 AgentIQ 的工作流配置和使用方法,包括工作流配置文件結構、使用各種命令運行工作流以及使用 Python API 的方法。這些內容幫助您理解 AgentIQ 工作流的配置和運行機制。
在自定義工作流章節中,我們介紹了如何修改現有工作流、添加工具到工作流、創建新工具和工作流以及工作流參數覆蓋。這些知識使您能夠根據自己的需求定制 AgentIQ 工作流。
最后,我們通過四個具體案例,展示了如何使用 NVIDIA AgentIQ 構建和部署不同類型的 AI 代理應用。這些案例涵蓋了從簡單問答到復雜工具集成的多種場景,幫助您理解 AgentIQ 的實際應用方式。
AgentIQ 的優勢
通過本博客的學習,我們可以總結出 NVIDIA AgentIQ 的幾個主要優勢:
-
靈活性和可擴展性:AgentIQ 的模塊化架構和函數抽象使其具有極高的靈活性和可擴展性,能夠適應各種應用場景。
-
易于使用:AgentIQ 提供了簡潔的命令行界面和 Python API,使開發者能夠快速上手并構建復雜的 AI 代理應用。
-
強大的工具集成:AgentIQ 支持多種內置工具,并允許開發者創建自定義工具,大大擴展了 AI 代理的能力。
-
全面的評估系統:AgentIQ 內置了強大的評估系統,使開發者能夠全面評估工作流的性能,并根據需要進行優化。
-
與 NVIDIA 生態系統的集成:作為 NVIDIA 產品,AgentIQ 與 NVIDIA 的其他 AI 工具和服務無縫集成,提供了更強大的功能和更好的性能。
未來展望
隨著 AI 技術的不斷發展,NVIDIA AgentIQ 也將持續演進,提供更多功能和更好的性能。未來,我們可以期待以下方面的發展:
-
更多預構建工具和工作流:AgentIQ 可能會提供更多預構建的工具和工作流,使開發者能夠更快地構建復雜的 AI 代理應用。
-
更強大的評估和監控功能:隨著 AI 代理在生產環境中的應用越來越廣泛,AgentIQ 可能會提供更強大的評估和監控功能,確保 AI 代理的質量和可靠性。
-
更深入的生態系統集成:AgentIQ 可能會與更多的 NVIDIA 產品和第三方工具集成,提供更全面的解決方案。
-
更多的學習資源和社區支持:隨著 AgentIQ 用戶的增加,我們可以期待更多的學習資源和社區支持,幫助開發者更好地使用 AgentIQ。
結語
NVIDIA AgentIQ 是一個強大的 AI 代理開發工具,它簡化了 AI 代理的開發、部署和管理過程,使開發者能夠專注于解決業務問題,而不是處理底層技術細節。通過本博客的學習,您應該已經掌握了使用 AgentIQ 構建和部署 AI 代理應用的基本知識和技能。
我們鼓勵您繼續探索 AgentIQ 的更多功能,并將其應用到您的實際項目中。隨著您對 AgentIQ 的深入了解和使用,您將能夠構建更復雜、更強大的 AI 代理應用,為您的業務帶來更大的價值。
祝您在 AI 代理開發之旅中取得成功!
)



)



——Webpack 6調優、模塊聯邦升級、Tree Shaking突破)



)






