聲明:
? ? ? ?本文基于嗶站博主【Shusenwang】的視頻課程【RNN模型及NLP應用】,結合自身的理解所作,旨在幫助大家了解學習NLP自然語言處理基礎知識。配合著視頻課程學習效果更佳。
材料來源:【Shusenwang】的視頻課程【RNN模型及NLP應用】
視頻鏈接:
RNN模型與NLP應用(5/9):多層RNN、雙向RNN、預訓練_嗶哩嗶哩_bilibili
一、學習目標
1.了解什么是多層RNN、雙向RNN、預訓練
2.學會代碼實現多層RNN、雙向RNN、預訓練
3.2.清楚這三種RNN模型的底層邏輯
?二、多層RNN、雙向RNN、預訓練
1.多層RNN
將RNN堆疊起來構成深度RNN神經網絡,以下為示意圖:
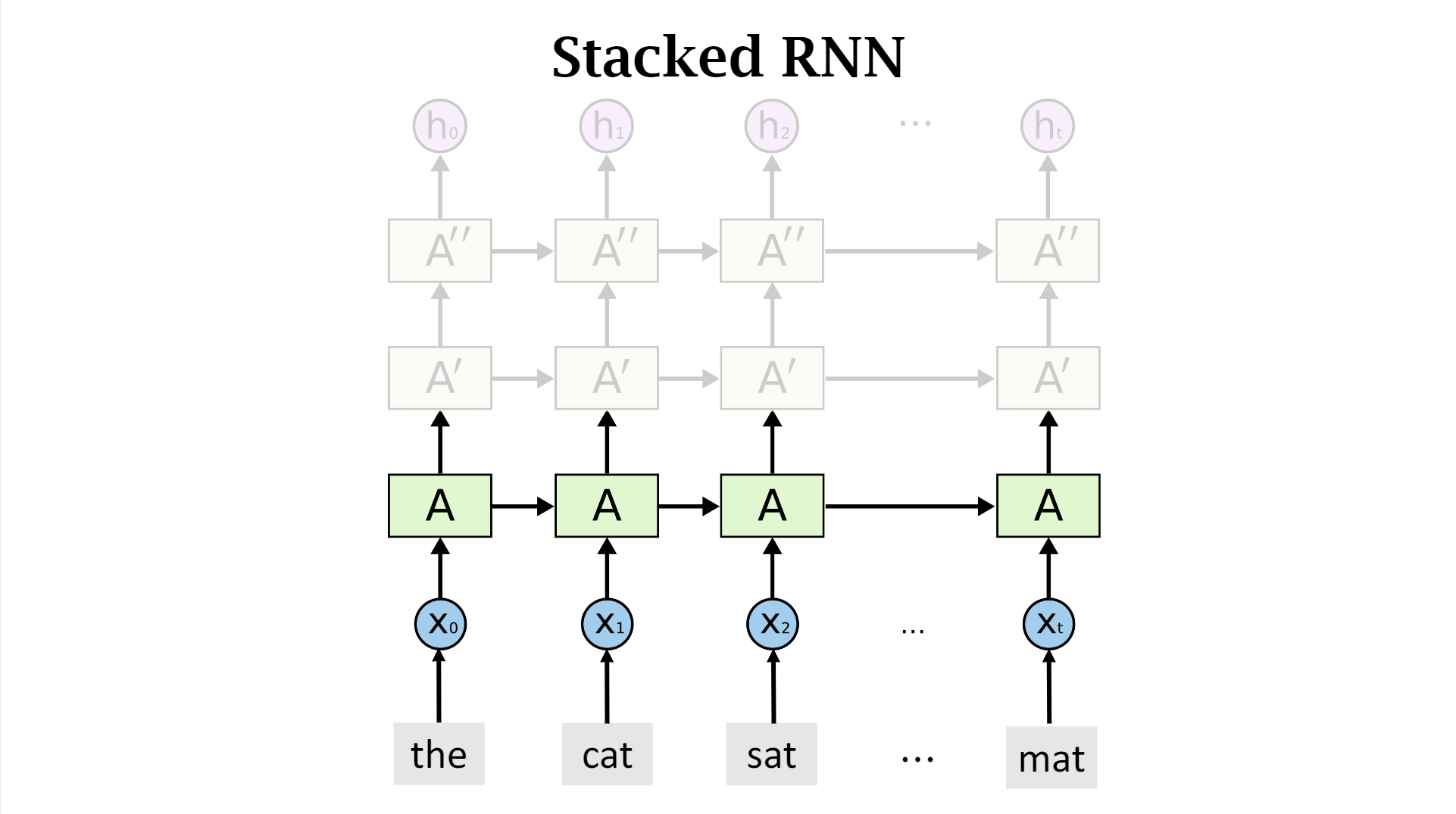
神經網絡每一步都會更新狀態h,每一個狀態向量h都有兩個copies,一個輸出,一個用來傳給下一節點。這一層輸出的h,用于上一層的輸入。以此類推,第二層的狀態向量一個用來傳給下一個時間點,另一個用來作為第三層的輸入。

最后一層的ht是最終的輸出。
代碼實現:
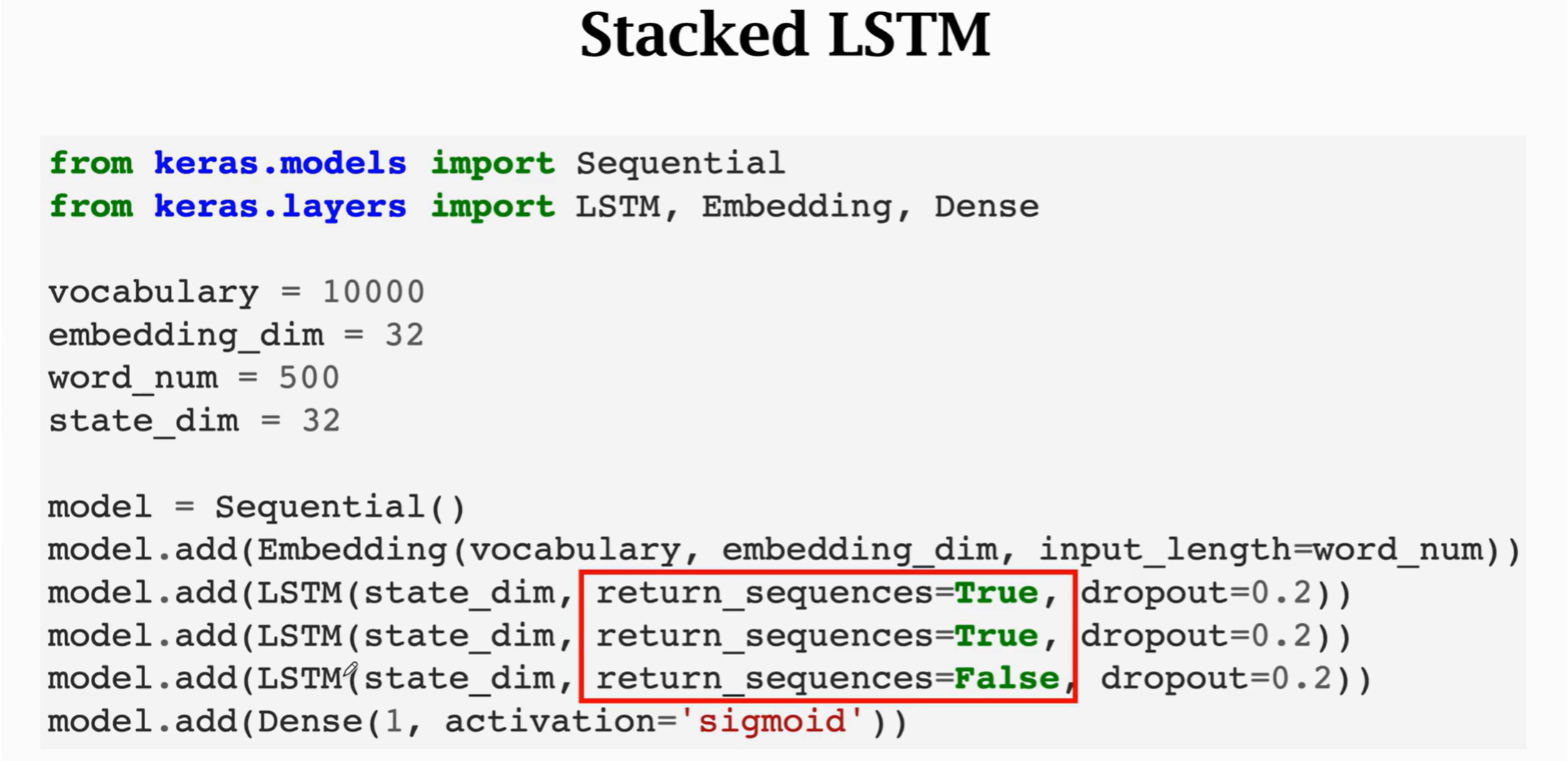
? ? ? ?上圖中紅色方框標記處:用了三個LSTM層,第一層return_sequence=true,第一層LSTM的輸出需要作為第二層的輸入;第二層return_sequence=true,第二層LSTM的輸出需要作為第三層的輸入,而第三層return_sequence=flase,第三層LSTM的輸出為最終輸出。
2.雙向RNN
訓練兩條RNN,一條從左往右輸出,一條從右往左輸出。
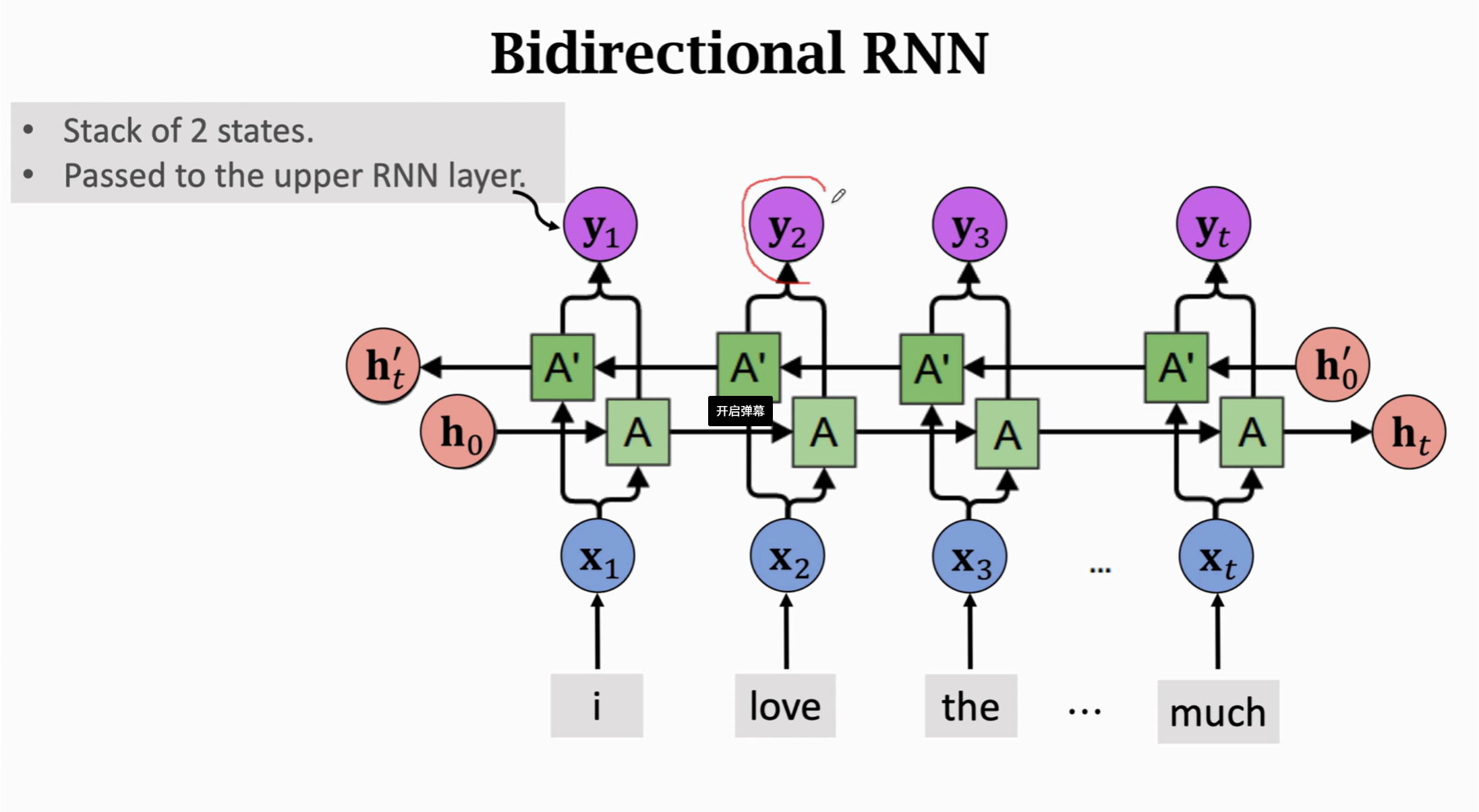
同一個輸入X同時輸給兩條RNN,兩條RNN互相獨立,互不影響。
如果有多條RNN,那么將最上面的內一行的y作為輸入再傳給下一條RNN。
最后只取左右兩邊的ht和ht',如下圖:

代碼實現:
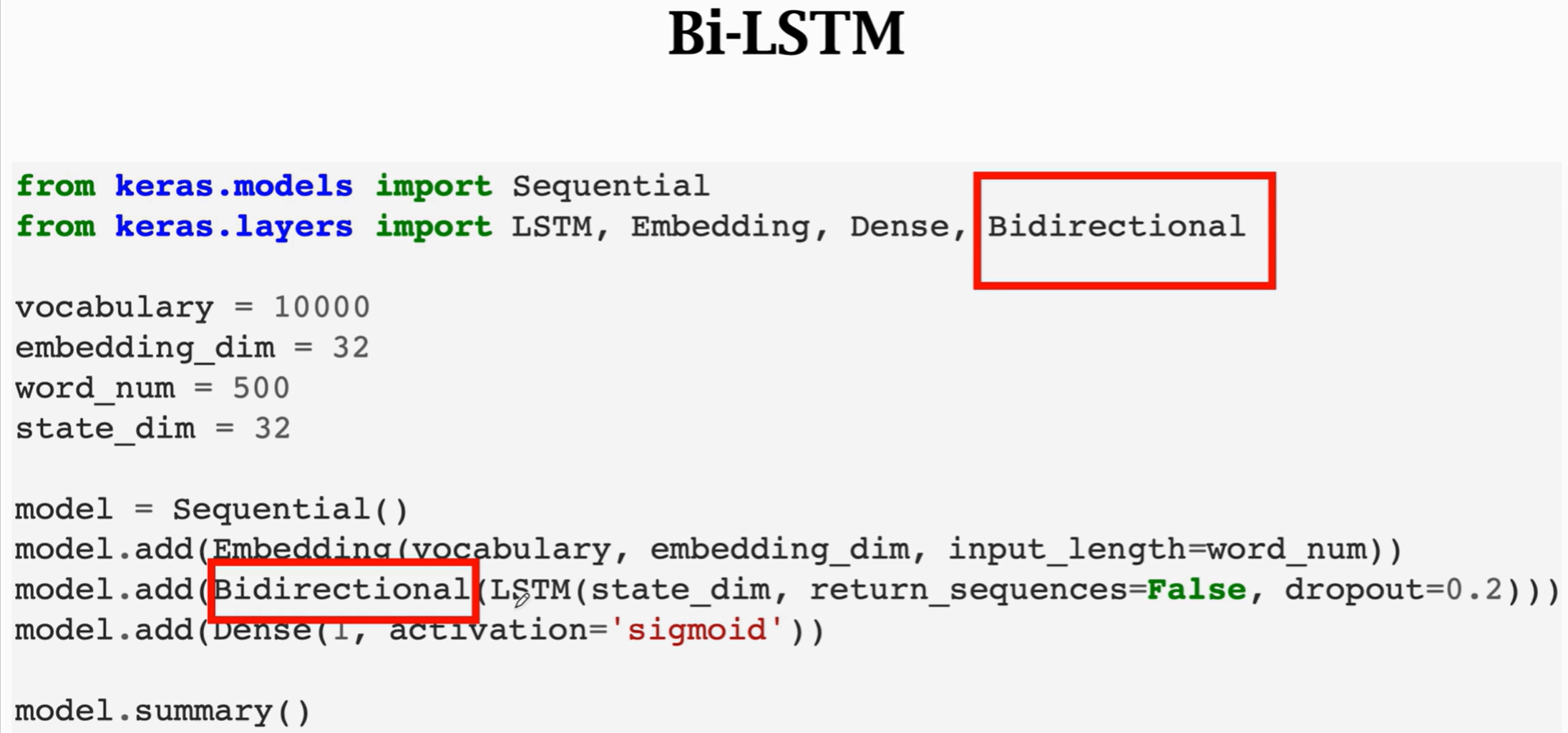
要實現雙向RNN,則需要導入Bidirectional層,然后在標準的LSTM外套一個Bidirectional層即可
3.預訓練
預訓練在深度學習中非常常用,比如在訓練卷積神經網絡中,如果網絡足夠大,但數據集不夠大,
這時候你就可以在Imagenet(大規模的注釋圖像數據庫)上做預訓練,這樣可以讓神經網絡有更好的初始化,也可以避免overfitting(過擬合)
訓練RNN的時候也是這個道理

? ? ? ?如上圖所示,這個RNN模型的embedding層有320000個參數,那么在數據集很小的情況下,該模型很可能會產生過擬合。
那么RNN預訓練具體是這么做的:
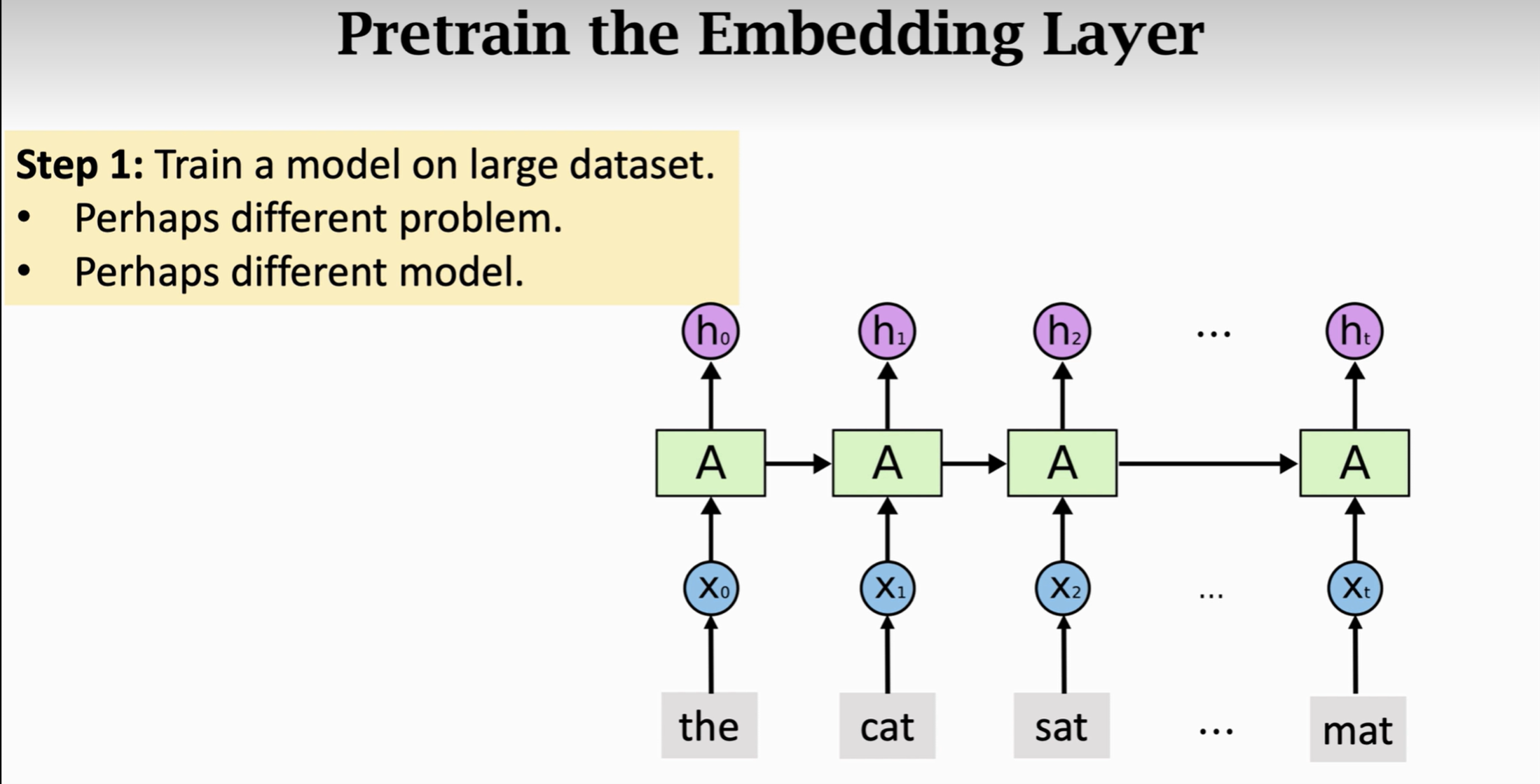
? ? 【首先】要找到一個足夠大的數據集,可以是情感芬妮下的數據集,也可以是其他類型的數據,但是任務最好是接近原來情感分析的任務,最好是學出來的詞向量帶有正面或負面的情感詞。兩個任務越相似,預訓練出來的transform(表現)就會越好。這個神經網絡的結構是什么樣的都可以,只要他有embedding層就行。
? ? ?【其次】就是要在大數據集上訓練這個神經網絡,訓練好后把上面的層丟掉,只保留eembedding層和訓練好的模型參數
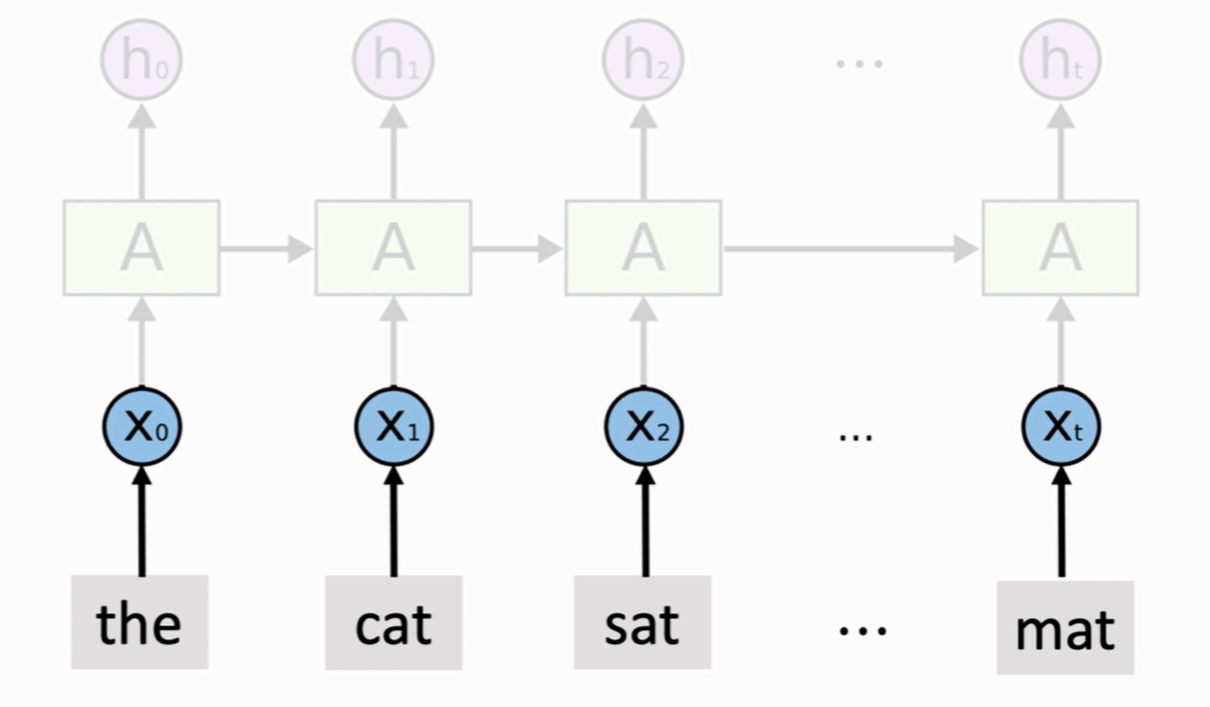
【最后】再搭建我們自己的RNN模型
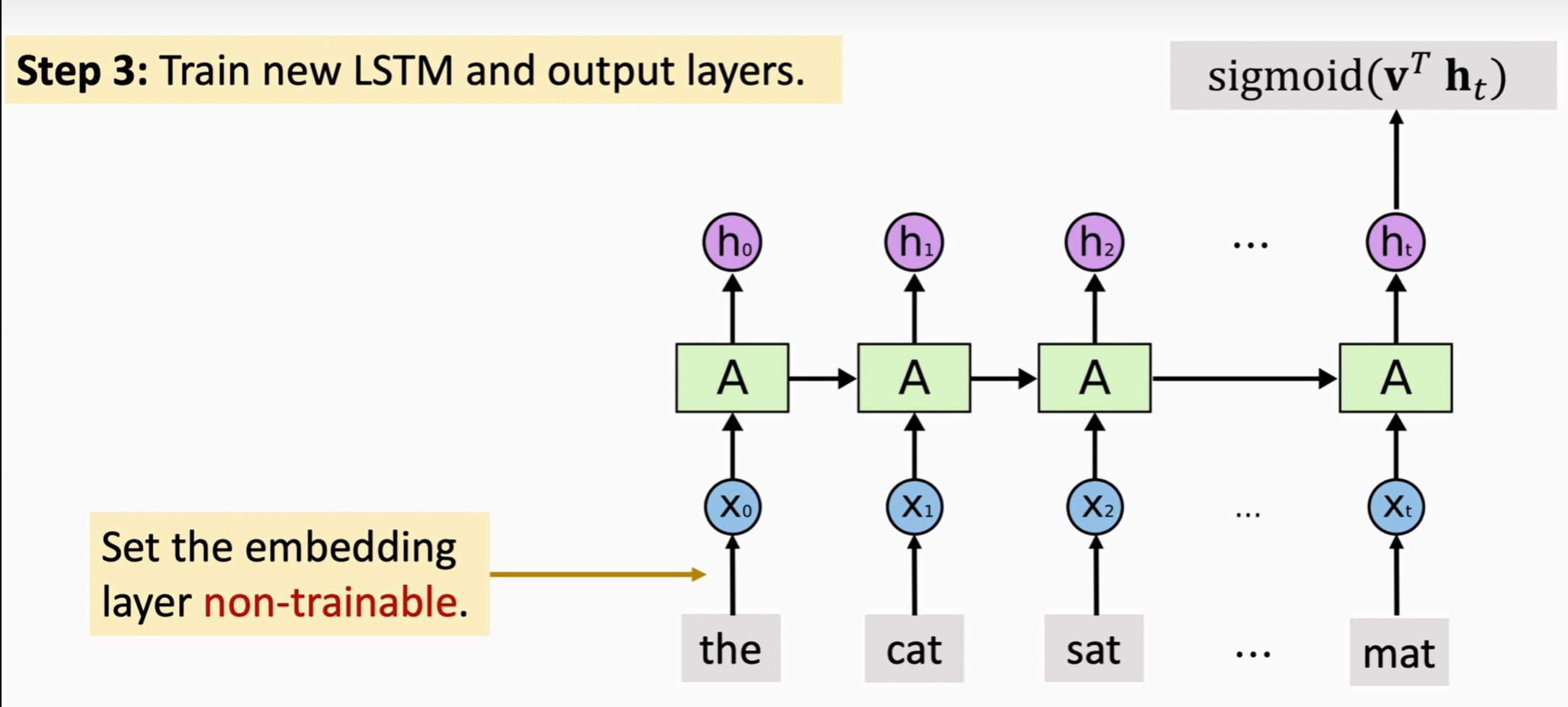
? ? ? ?新的RNN層和全連接層的參數都是隨機初始化的,而下面的embedding層是預訓練出來的,要把embedding層固定住,不要訓練embedding層
三、總結

①能用SimpleRNN的情況下,肯定可以用LSTM,LSTM的效果要比Simple RNN好,因此我們應該都用LSTM
②提升RNN效果的方式之一就是使用雙向RNN,雙向RNN比單向的訓練效果好。
③多層RNN的容量比單層大,如果訓練數據比較多,那么多層的RNN訓練效果比單層的好
④RNN的embedding層中參數往往都很多,那么在數據集較小的情況下,訓練可能會出現over fitting(過擬合),因為我們就需要在大數據集上先進行預訓練。


)

)




和功率密度測試)

)







