目錄
一、multi-head 共享
二、attention結構
1.傳統的Tranformer結構
2.GPTJ —— 平行放置的Transformer結構
三、歸一化層位置的選擇
1.Post LN:
2.Pre-LN【目前主流】:
3.Sandwich-LN:
四、歸一化函數選擇
1.傳統的歸一化函數 LayerNorm
2.RMSNorm
五、激活函數
六、LLama2結構
七、MoE架構 混合專家模型
? ? ? ? ? ? ? ? ? ? ? ? ????????????????????SWITCH TRANSFORMERS
八、DeepSeek Moe
九、位置編碼和長度外推性
1.為何需要位置編碼
2.長度外推性
3.目前的主流位置編碼
Ⅰ、正余弦位置編碼
Ⅱ、可學習位置編碼
Ⅲ、ROPE相對位置編碼
Ⅳ、Alibi位置編碼
① 相對位置矩陣生成
② 頭特定斜率參數
③ 偏差矩陣計算
④ 偏差注入與注意力計算
Ⅴ、總結
十、DeepSeek MLA —— Multi - head Latent Attention(多頭潛在注意力)
I will love you in your freezing night
Please just hold me tight
????????????????????????????????????????????????????????—— 25.3.27
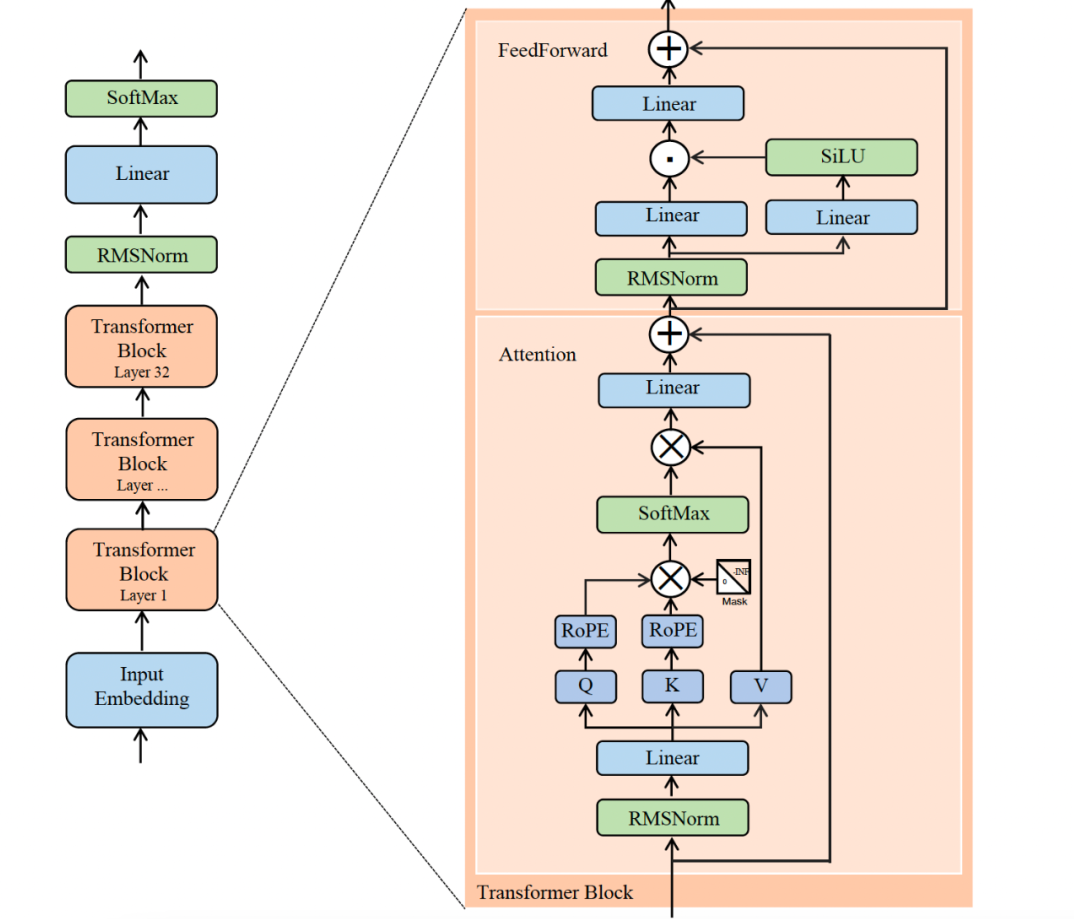
大語言模型都是基于transformer結構來做
一、multi-head 共享
Values:10×64
Keys:10×64
Queries:10×64
多頭注意力(MHA) —— 12個頭: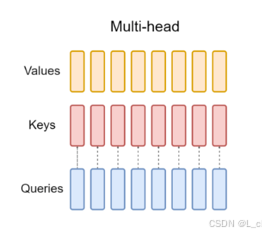
縮小Key和Value,多查詢注意力(MQA) —— 1個頭:
縮小Key和Value,分組查詢注意力(GQA) —— 4個頭: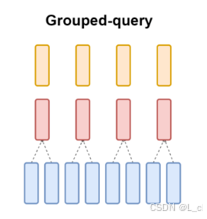
效果隨頭的數量減少而減弱,減少運算量,加速訓練
二、attention結構
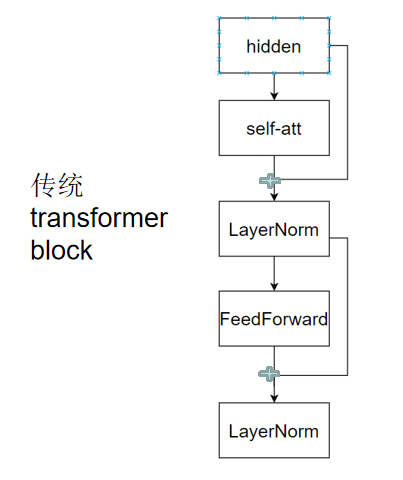
1.傳統的Tranformer結構
????????多層感知機(MLP)位于多頭自注意力機制之后,對自注意力機制輸出的特征表示進行進一步的非線性變換。自注意力機制雖然能夠有效地捕捉序列中的長距離依賴關系,生成豐富的上下文感知表示,但這些表示可能仍然需要進一步處理,以更好地適應下游任務。MLP 通過將輸入特征映射到一個更高維的空間,然后再投影回原始維度,能夠增強特征的表達能力,使模型能夠學習到更復雜的模式。
公式:

MLP(多層感知機)的作用是:對經過注意力機制和層歸一化處理后的特征進行非線性變換
流程:
① 第一次層歸一化:對輸入?x?進行層歸一化(LayerNorm),得到 LayerNorm(x),穩定數據分布。
② 注意力計算:將?LayerNorm(x)?輸入到注意力模塊(Attention),計算?Attention(LayerNorm(x)),捕捉序列依賴關系。
③ 第一次殘差連接:將?x?與 Attention(LayerNorm(x))?相加,即?x + Attention(LayerNorm(x)),保留原始信息并促進梯度傳播。
④ 第二次層歸一化:對殘差連接結果進行層歸一化,得到 LayerNorm(x + Attention(LayerNorm(x)),再次穩定數據分布。
⑤ MLP 變換:將 LayerNorm(x + Attention(LayerNorm(x)))?輸入到多層感知機(MLP),通過非線性變換提取高級特征,得到?MLP(LayerNorm(x + Attention(LayerNorm(x))))。
⑥ 第二次殘差連接:將原始輸入?x?與?MLP 的輸出相加,得到最終結果?y = x + MLP(LayerNorm(x + Attention(LayerNorm(x)))),融合原始信息與處理后的特征。

MLP的核心作用:
① 增加非線性:MLP 通過激活函數(如 ReLU)引入非線性,使模型能學習更復雜的映射關系。
② 特征變換與融合:對注意力處理后的特征進行二次加工,整合不同維度的信息,提升特征的表征能力。
③ 配合殘差連接:最終輸出?y?再次通過殘差連接(x + MLP(?)),確保原始信息不丟失,同時促進梯度傳播,防止訓練中的梯度消失問題。
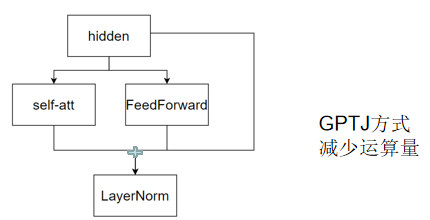
2.GPTJ —— 平行放置的Transformer結構
GPTJ結構,平行放置attention layer和feed forward layer
moss, palm用的這種結構,目前不算太主流
公式:
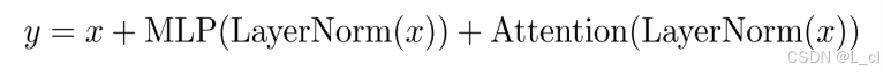
流程:
① 層歸一化:對輸入?x?進行層歸一化(LayerNorm),得到 LayerNorm(x),穩定特征分布。
② 并行處理:
????????將?LayerNorm(x)?輸入到?MLP?模塊,計算?MLP(LayerNorm(x)),通過非線性變換提取特征。
????????將?LayerNorm(x)?輸入到?Attention?模塊,計算?Attention(LayerNorm(x)),捕捉序列依賴關系。
③ 殘差融合:將原始輸入?x、MLP?的輸出、Attention?的輸出相加,即?y = x + MLP(LayerNorm(x)) + Attention(LayerNorm(x)),實現信息融合與殘差連接,保留原始信息并促進梯度傳播。
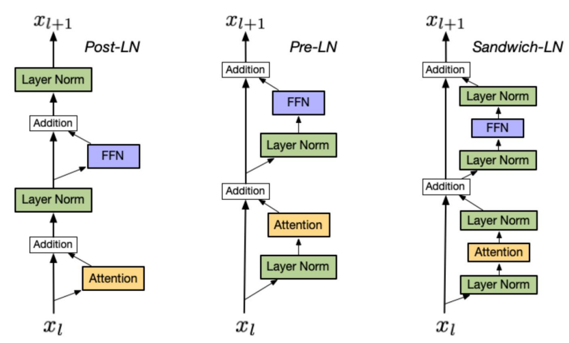
三、歸一化層位置的選擇
1.Post LN:
流程:先進行子層計算,再對子層輸出進行層歸一化,最后殘差連接。
特點:子層輸出可能因未歸一化而波動較大,深層訓練時穩定性較差,但早期 Transformer 架構常用此方式。使用post-LN的深層transformer容易出現訓練不穩定的問題。
2.Pre-LN【目前主流】:
流程:在進入子層(如注意力層或 MLP 層)之前先進行層歸一化
特點:使每個子層的輸入分布穩定,緩解梯度消失問題,便于深層模型訓練;相比于Post-LN,使用Pre-LN的深層transformer訓練更穩定,可以緩解訓練不穩定問題;相比于Post-LN,Pre-LN的模型效果略差。
3.Sandwich-LN:
流程:在子層的輸入和輸出端都應用層歸一化,形成 “三明治” 結構。
在pre-LN的基礎上,額外插入了一個layer norm
Cogview用來避免值爆炸的問題。
特點:結合 Pre - LN 和 Post - LN 的優勢,進一步穩定特征分布,同時增強模型對特征的表達能力
缺點:訓練不穩定,可能會導致訓練崩潰。
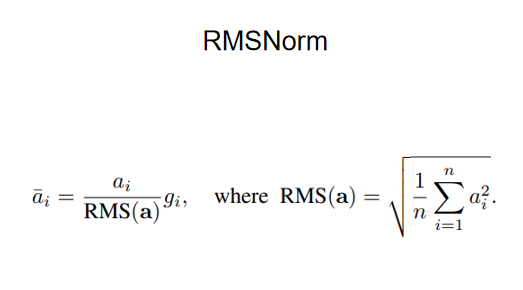
四、歸一化函數選擇
1.傳統的歸一化函數 LayerNorm

2.RMSNorm
目前主流做法是:將Norm層提前到attention之前
五、激活函數
FeedFoward層所使用激活函數的演進
初始Transformer:relu()
Bert:gelu()
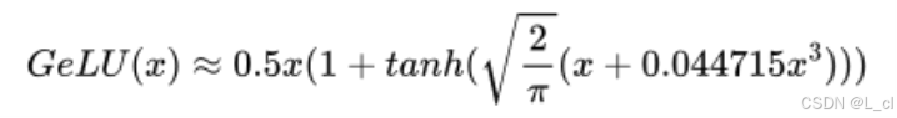
目前最主流的激活函數:Swish()

六、LLama2結構
分詞器:使用字節對編碼(BPE)算法,詞匯表大小為 32,000 tokens,支持多語言文本的高效編碼。? ?
????????① 初始化詞匯表:把文本中所有單詞分解成最小字符單位,這些字符構成初步詞匯表 。比如單詞 “look” 會被分解為 “l”“o”“o”“k”。
? ? ? ? ② 統計字符對頻率:遍歷文本,計算每對相鄰字符出現的頻次。例如在單詞 “look” 中,字符對為(“l”,“o”)、(“o”,“o”)、(“o”,“k” ) ,在整個文本范圍內統計它們出現的次數。
? ? ? ? ③ 合并最頻繁字符對:找出出現頻率最高的字符對,將其合并成一個新符號。比如統計后發現 “lo” 出現頻率最高,就把 “l” 和 “o” 合并為 “lo” 。
? ? ? ? ④ 更新文本和詞匯表:在文本中把所有該字符對的實例替換為新合并的符號,同時更新詞匯表。如 “look” 變為 “lo”“ok” ,詞匯表中新增 “lo”。
? ? ? ? ⑤ 重復迭代:不斷重復步驟 2 - 4 ,直到達到預設的詞匯表大小,或者字符對不再頻繁出現。
位置編碼:采用旋轉位置編碼(RoPE),通過旋轉矩陣實現相對位置關系建模,支持上下文窗口擴展至 4096 tokens。
預歸一化:在每個 Transformer 層的輸入前應用RMSNorm(均方根歸一化),而非傳統的 LayerNorm,提高訓練穩定性和收斂速度。
多頭注意力(MHA):
????????分組查詢注意力(GQA):在 70B 版本中,將查詢頭分為 G 組,每組共享鍵(K)和值(V)投影。例如:70B 模型采用 32 組,每組 2 個查詢頭,總頭數 64 個。這種設計減少了內存占用,尤其在長序列推理時優勢顯著1315。
????????多查詢注意力(MQA):7B 和 13B 模型采用 MQA,所有查詢頭共享同一組 K 和 V,進一步降低參數規模315。
前饋網絡(FFN):使用SwiGLU 激活函數,公式為SwiGLU(x) = x * σ(β * x) * W,其中 σ 為 Sigmoid 函數,β 為可學習參數。相比 ReLU,SwiGLU 在保持非線性能力的同時提升了模型表達能力。
語言建模頭:通過線性層將最終隱藏狀態映射到詞匯表空間,輸出下一個 token 的概率分布。
七、MoE架構 混合專家模型
????????MOE 的核心思想是將復雜任務分解為多個 “專家” 子模型,每個專家專注于處理特定類型的輸入,通過門控機制動態決定輸入數據由哪些專家處理
輸入層:將原始數據編碼為特征向量。
門控網絡(Gating Network):計算每個輸入分配給不同專家的概率。
????????實現方式:
? ? ? ? ? ? ? ? ① 軟門控:使用 Softmax 或 Sigmoid 函數計算概率,允許多個專家共同處理輸入(如 Google Switch Transformer)。
? ? ? ? ? ? ? ? ② 硬門控:僅選擇一個專家處理輸入(如 BERT-MOE)。
????????負載均衡:通過正則化(如 L2 損失)避免某些專家過載。
專家網絡(Expert Network):多個獨立的子模型,每個專家負責處理特定類型的輸入。
????????結構:每個專家是一個獨立的神經網絡(如 MLP、Transformer 塊),可共享或獨立訓練。
????????多樣性:不同專家可學習不同的特征模式,例如一個專家擅長處理文本分類,另一個擅長翻譯。
????????并行計算:輸入僅激活部分專家,減少冗余計算。
輸出層:整合專家的輸出結果,生成最終預測。
? ? ? ? ? ? ? ? ? ? ? ? ????????????????????SWITCH TRANSFORMERS
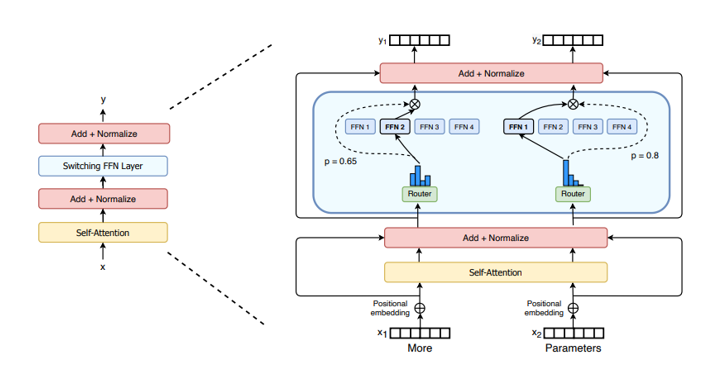
MoE架構,會帶來分類預測和整體模型的參數數量不同
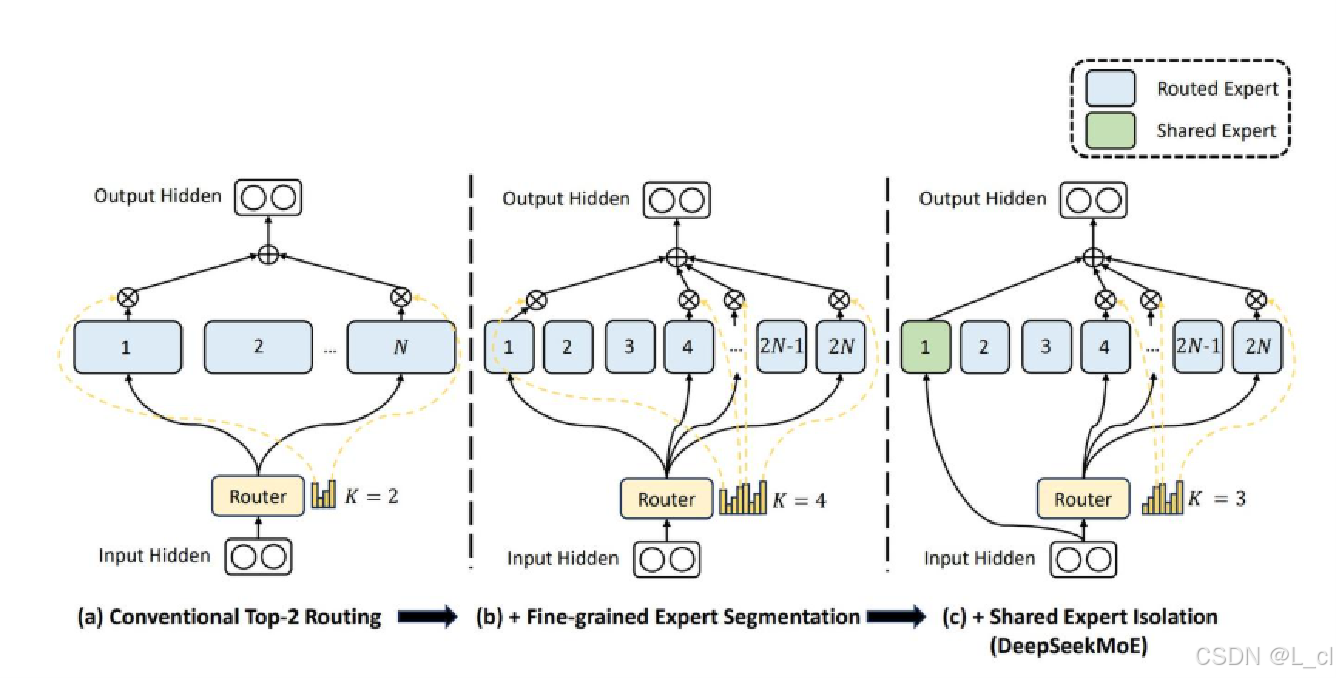
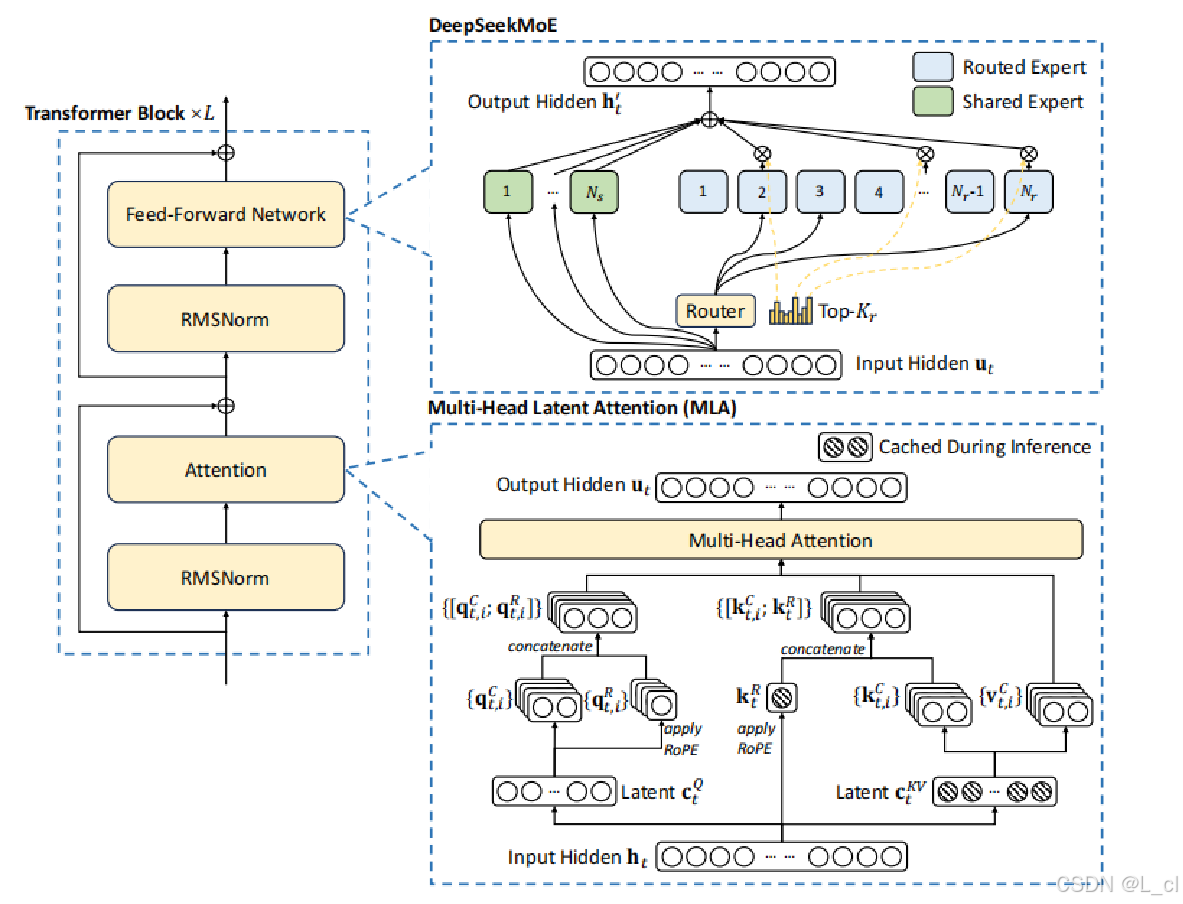
八、DeepSeek Moe
????????除了隨機挑選專家外,還有一位專家總是在工作(一位專家主要做工作,其余隨機挑選的專家進行改進)
如圖所示,增加了“共享專家”,總是會使用這個“專家”進行計算,其余的按照傳統Moe方式由模型自己隨機進行挑選
九、位置編碼和長度外推性
1.為何需要位置編碼
由于transformer中使用的都是線性層,編碼過程中沒有明顯的位置信息
字詞位置的交換,僅相當于矩陣中行位置的交換
這帶來并行計算的優勢,但是也弱化了語序信息
因此需要引入位置編碼來彌補
如果不引入位置編碼,當語序位置不同時,最終歸一化后也并不能體現出差異;
引入位置編碼,當語序改變時,每個位置位置編碼的權重值不同,整體相乘后,值也會發生變化;

2.長度外推性
預測時序列長度比訓練時候長,模型依然有好的表現,稱為有較好的長度外推性
比如: 訓練樣本最大長度為512;預測過程中輸入的樣本長度為1024
長度外推性是一種理想的性質,并非是必要的
3.目前的主流位置編碼
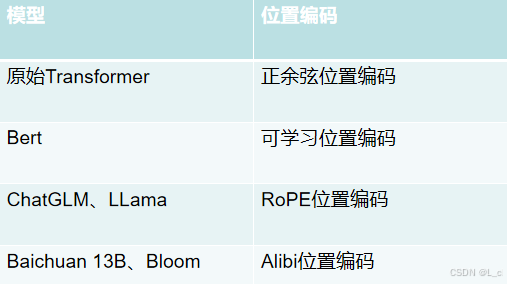
相對位置編碼是目前LLM的主流
RoPE是相對位置編碼的主流
Ⅰ、正余弦位置編碼

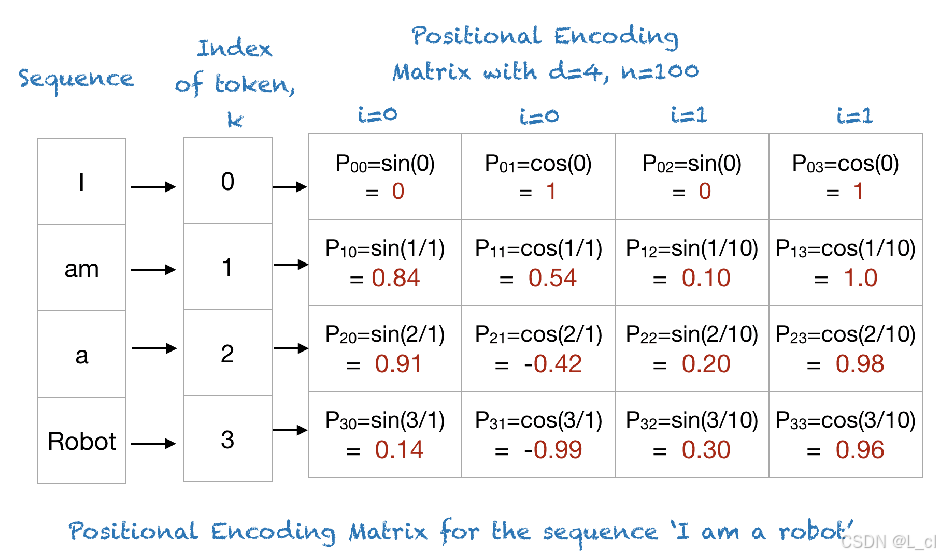
優點:① 理論上可以進行一定程度的外推,但是效果不是很好?② 是一個固定的位置編碼
位置編碼向量 + token向量 得到編碼后的embedding
我們稱之為Positional Encoding
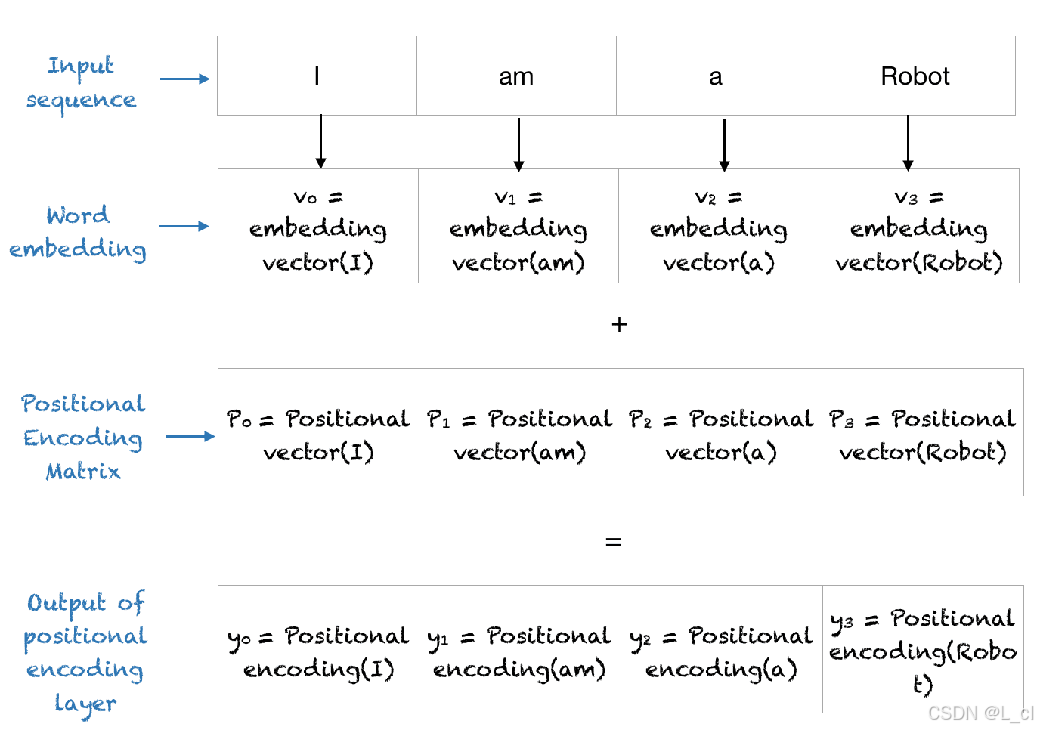
Ⅱ、可學習位置編碼
一般稱為position embedding,以Bert為代表
如同token embedding一樣,隨機初始化之后,靠梯度更新學習調整
缺點:無法外推,需要預設最大長度
Ⅲ、ROPE相對位置編碼
????????ROPE(Rotary Position Embedding,旋轉位置編碼)是一種結合絕對位置編碼與相對位置編碼優勢的技術,通過旋轉矩陣將位置信息融入自注意力機制,使模型能顯式學習相對位置關系。
ROPE 對查詢(Q)和鍵(K)向量的每個偶數 - 奇數維度對進行旋轉:

相對位置編碼在計算Self-attention時做這個注意力矩陣
公式: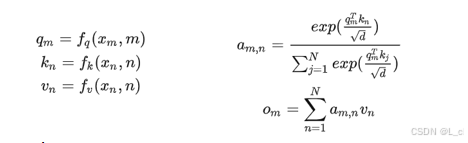
相對位置編碼需要找到符合如下條件的f、q函數:
x_m:輸入的Embedding
m:相對位置
f_q:對x_m和相對位置m做的一種變換
x_n:輸入的Embedding
n:相對位置
f_k:對x_n和相對位置n做的一種變換
g:對于q和k做上述變換后再做內積得到的一種相對位置編碼
![]()
施加在Transformer每一個q、k相乘計算之后使用,沒有長度限制,只與傳入的m、n值有關,計算其差值
最后找到的函數:
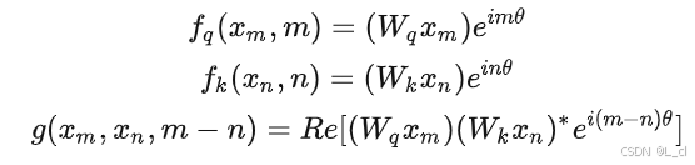 ?—— Re代表[值]的實數部分
?—— Re代表[值]的實數部分


Ⅳ、Alibi位置編碼
????????ALiBi(Attention with Linear Biases)是一種非學習型相對位置編碼方法,通過在注意力分數中注入線性偏差來隱式編碼序列的相對位置關系。其核心思想是利用注意力機制的數學特性,在不引入額外參數的情況下提升模型對長序列的處理能力。
????????ALiBi 的核心是在注意力分數計算階段直接添加位置偏差,而非通過位置嵌入或旋轉操作。
① 相對位置矩陣生成

② 頭特定斜率參數

③ 偏差矩陣計算

④ 偏差注入與注意力計算

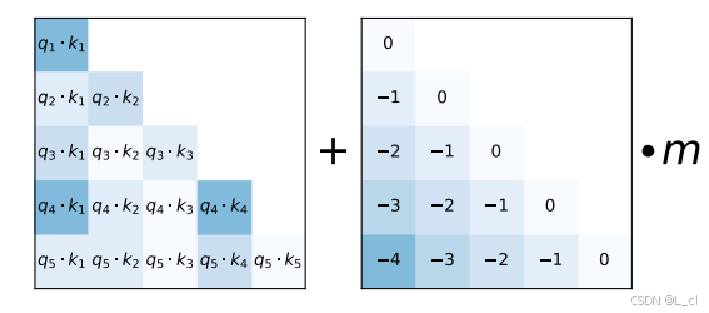
公式:![]()
值越大,兩位置差距越大,值越小,兩位置差距越小
多個頭時,乘以不同的系數值
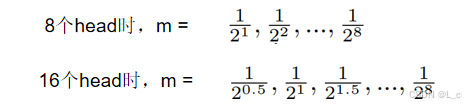
Ⅴ、總結
對于文本類NLP任務,位置信息是很重要的
可學習的位置編碼缺點在于沒有長度外推性
相對位置編碼不需要學習,有一定的長度外推性,但是相對位置編碼具有天然的遠程衰減性
目前的主流是RoPE和Alibi兩種相對位置編碼
十、DeepSeek MLA —— Multi - head Latent Attention(多頭潛在注意力)
主要著重于self-attention的重點
通過一個大的線性層計算Q、K
將Q、K拆分為Q1,Q2和K1和K2,
Q1,K1過RoPE相對位置編碼,Q2和K2不過RoPE相對位置編碼
然后將Q1和Q2相加,K1和K2相加
Q、K拆分的比例通過實驗確定

效果: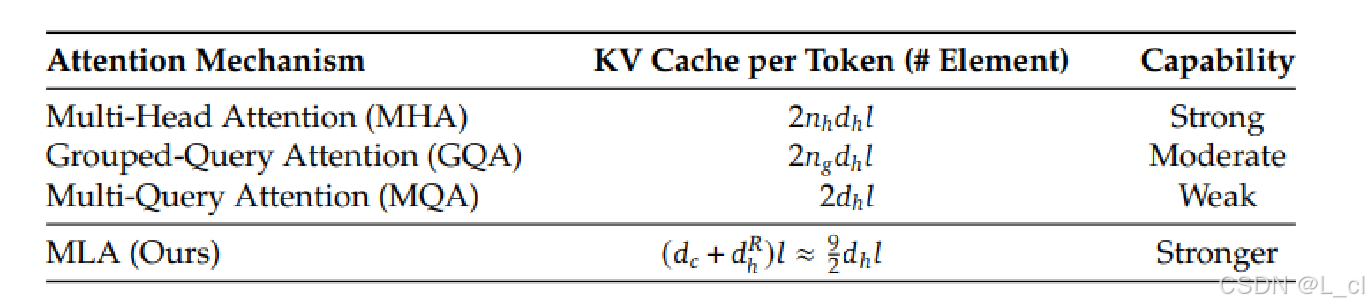
)




和功率密度測試)

)











