文章目錄
- 1. HTTP定義
- 2. HTTP交互
- 3. HTTP報文格式
- 3.1 抓包工具-fiddler
- 3.2 抓包操作
- 3.3 報文格式
- 3.3.1 請求報文
- 3.3.2 響應報文
- 4. URL
- 5. 請求頭中的方法
- 6. GET和POST的區別
- 7. HTTP報頭
- 7.1 Host
- 7.2 Content_Length
- 7.3 Content_Type
- 7.4 User-Agent(UA)
- 7.5 Referer
- 7.6 Cookie
- 8 狀態碼
- 9. 構造HTTP請求
- 9.1 PostMan
- 9.2 通過代碼
- 10. HTTPS
- 10.1 加密
- 10.2 HTTPS工作流程
- 對稱加密
- 非對稱加密
- 證書
1. HTTP定義
HTTP(超文本傳輸協議)是一種工作在應用層的協議,應用場景主要用于網站,即瀏覽器和服務器之間的數據傳輸,客戶端(手機、PC)和服務器之間的數據傳輸,也很可能是 HTTP。
超文本傳輸協議
文本:字符串(能在utf8/gbk碼表上找到合法字符)
超文本:不僅可以傳輸字符串,也可以傳輸圖片,特殊格式等,比如html
富文本:word文檔
HTTP版本
HTTP在3.0版本之前,都是基于TCP實現的,而在3.0版本之后是基于UDP實現的,提升了傳輸效率,安全性也提到了明顯的改善,當前使用廣泛的是HTTP1.1版本,是基于TCP實現的。
2. HTTP交互
HTTP的交互過程是典型的“一問一答”的形式。

這種交互過程對于網站開發來說已經基本夠用,但是,有的網站會彈出廣告,點進去服務器會主動先發一條消息,像把QQ這樣的聊天窗口搬到網頁上來,對方發來消息我們這邊還有提示,這種情況HTTP的不能勝任。
上述場景是服務器主動給瀏覽器發消息,就稱為消息推送
應用層這里還提供了一個和 HTTP 搭配的協議,websocket (HTTP 的跟班,針對 HTTP 的能力進行補充的)
3. HTTP報文格式
3.1 抓包工具-fiddler
抓包工具,本質上是一個"代理程序",能夠獲取到網絡上傳輸的數據,并顯示出來,從而給程序員提供一些參考。
wireshark:高大全,可以抓各種協議數據包,TCP、IP、UDP、以太網…(使用起來更復雜一點)
fiddler:專注 HTTP 的抓包----https://www.telerik.com/download/fiddler
抓包工具其實就是一種"代理"程序,能夠獲取網絡上的數據并顯示出來給我們一些參考。
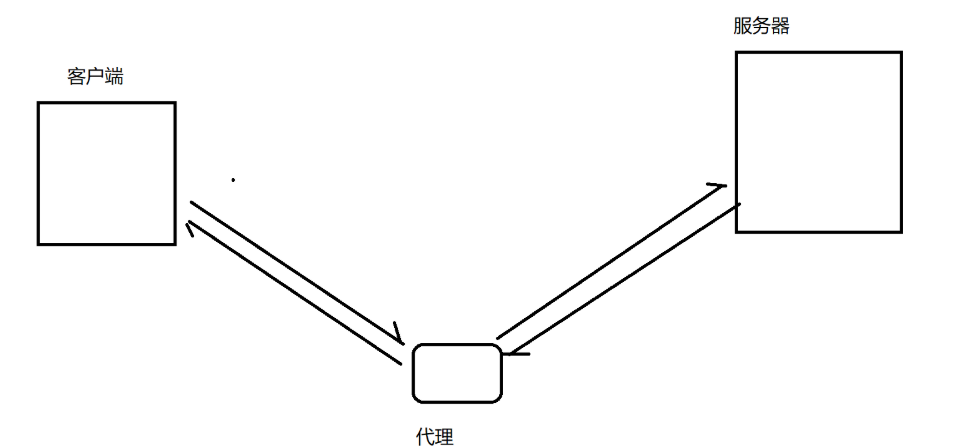 同時,代理分成兩種
同時,代理分成兩種
1.正向代理(客戶端的代言人):比如我會求室友幫我帶一份飯,此時室友就是我的代理
2.反向代理(服務器的代言人):比如食堂大媽今天也不想動彈,此時會讓他的兒子來賣飯,此時他的兒子就是反向代理
翻墻效果:用來翻墻的代理,本質上是通過一個可以被訪問到的境外服務器部署代理服務器的。
3.2 抓包操作
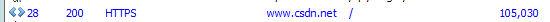
上面藍色的表示的是返回一個html,表示一個網站的入口請求。
查看明細:
 通過使用該工具查看HTTP交互過程中的請求與交互的詳細信息。
通過使用該工具查看HTTP交互過程中的請求與交互的詳細信息。
3.3 報文格式
3.3.1 請求報文
HTTP請求的報文格式分為4個部分
1.首行------三部分用空格分開
GET https://www.csdn.net/ HTTP/1.1
GET:表示方法
https://www.csdn.net/:表示URL
HTTP/1.1:表示的是HTTP的版本號
2.請求頭(采用鍵值對的方式)------用空格/冒號分開

3.空行:請求頭結束會有一個空行,就是用來表示請求頭結束。
4.正文:body(也就是載荷),有的請求有載荷,有的則沒有。
3.3.2 響應報文
HTTP的響應報文格式也分為4個部分。
1.首行
HTTP/1.1:表示的是HTTP的版本號
200:狀態碼
OK:狀態碼描述

2.響應頭(同樣也是鍵值對)
3.空行(標志著響應頭結束)
4.正文body(載荷部分)
4. URL
URL用來描述一個網絡資源的位置。

http:// :協議,當前使用的是什么協議(HTTP/HTTPS…)
user:pass :登錄信息,并不常用,因為不安全
www.example.jp :IP地址,用域名訪問,通過地址知道服務器位置
80 :端口號,通過端口知道具體訪問服務器的哪個程序
dir/index.htm :路徑,通過路徑知道訪問的是哪個資源(此處可以是一個文件,也可以是一個虛擬文件)
uid=1 :查找字符串(quary string),針對請求做出的補充
ch1 :片段標識符,標識當前頁面的某個部分,通過不同的標識可以完成頁面的跳轉
URL encode
在quary string(查找字符串)中有很多程序員自定義的鍵值對
在URL中很多字符都有特殊的含義 : / # @等
如果quary string中也有相同的符號怎么辦,此時我們就需要轉義,當然對于漢字我們也需要轉義,通過ASCII進行對應轉義
5. 請求頭中的方法

標準文檔的解釋
GET:從服務器獲取一個資源(讀操作)
POST:往服務器放一個東西(寫操作)
GET的使用場景
從服務器獲取一個數據,十分常見
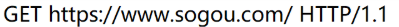
POST的使用場景
大部分用于上傳、登錄
登錄操作使用的是POST方法,登錄的用戶名使用的是json數據格式組織登錄的,密碼并不是我們自己設置的密碼,而是進行了base64編碼(加密),將編碼傳輸到服務器。
密碼后面有 == 基本上就是base64編碼,Base64 是一種將二進制數據編碼為 ASCII 字符串的編碼方式,常用于在文本協議(如 HTTP、電子郵件)中安全傳輸二進制內容。

6. GET和POST的區別
GET和POST的區別(經典面試題)
本質上GET和POST沒有區別,使用GET的場景也能用POST,使用POST的場景也能使用GET。
但是在使用習慣上二者還是有區別的:
1.GET習慣把數據放到URL中,POST習慣把數據放到body(載荷)中。
同樣GET也可以把數據放到body中,但是有的瀏覽器會有限制;
POST也可以放到URL中,大多數是沒有限制。
2.語義上的區別,標準文檔中GET適用于讀取數據,POST用于傳輸數據。
3.關于冪等性,標準文檔中,建議GET是冪等的,POST無要求。(冪等就是一個輸入只對應一個輸出)
4.GET可以被瀏覽器收藏夾收藏,POST不可以。
一些關于GET和POST的解釋也不是很準確,大家理性看待
1.POST比GET更加安全
依據:GET傳輸的數據是放在URL中的,而POST存放的數據是放在body中的。
登錄場景中,如果密碼放到URL中可能會被看到,所以不安全,但是POST也是可以被心懷叵測的人抓包得到body。
辟謠:真正保證安全的,不是使用什么方法,而是對數據進行加密。
2.GET傳輸的數據量很小,POST傳輸的數據量很大。
以前確實是這樣的,但是現在標準文檔明確指出對GET的URL不做長度的限制。
3.GET只能攜帶文本數據,POST只能攜帶二進制數據。
這個說法不一定完全錯,URL是通過quary string來保存數據,quary string是只能包含文本數據的,但是urlencode可以對二進制文件進行編碼,自然也就成了文本了。
POST請求中也不是經常攜帶二進制數據,而是對二進制文件進行urlencode進行轉碼。
7. HTTP報頭

7.1 Host
表示服務器主機的IP地址和端口號,這里的Host和URL中的IP地址、端囗絕大部分情況下都是一樣的.

7.2 Content_Length
表示body(正文)中的數據長度,HTTP底層是基于TCP實現的,連續傳輸多個HTTP數據報,此時接收方這邊的接收緩沖區里就會積累多個包的數據,應用程序在讀取這些數據的時候就需要明確包之間的邊界,以防止出現“粘包問題”。
7.3 Content_Type
表示body(正文)中的數據格式,body可以傳輸很多種格式的,包括程序員也可以自己約定任意的格式。
請求中的格式
application/json --body就是json的數據格式
application/x-www-form-urlencode --稱為form表單,通過HTML中的form標簽構造出來的一種格式,特點就是把quary string放到body里。
multipart/form-data --上傳文件使用
響應中的格式
text/plain:純文本
text/html:返回HTML
text/css:返回css
application/Javascript:返回js
application/json:返回json
image/png:返回圖片
image/jpg:返回圖片
由于瀏覽器和服務器之間要進行多次網絡交互,整體的過程比較低效,為了提升效率,把一些固定不變的內容在瀏覽器本地的機器硬盤上進行緩存(css,圖片,js,很少發生改變的類型)。保存到硬盤上之后,后續再請求,就可以直接從硬盤上讀取數據,減少了網絡交互的開銷。
7.4 User-Agent(UA)
表示當前訪問的操作系統的信息以及瀏覽器信息。
UA在以前是常用的,由于用戶的設備存在差異,就可以通過UA區別設備,從而正確返回用戶想要的數據。
響應式布局(前端提出的解決上述問題的技術方案),通過一套代碼,適應不同尺寸的顯示器。也就是 CSS3 提供了一個特性,“媒體查詢”,可以感知到當前屏幕的尺寸,根據不同的尺寸,應用不同的樣式。
7.5 Referer
表示當前的頁面是由哪個頁面跳轉而來。
瀏覽器中,直接輸入url、點擊收藏夾打開的網頁,此時是沒有referer。
示例:廣告業務中,某廣告公司在不同的網站部署廣告,廣告公司有一臺服務器來計算來自不同網站的廣告的點擊量,如果知道該點擊來自哪個網站,就需要用到referer。
7.6 Cookie
Cookie就是持久化的保存一些信息,本質上是瀏覽器這邊本地持久化存儲數據的機制。
瀏覽器作為電腦上的一個程序,能否直接讀寫本地磁盤文件呢?
當然不可以,系統提供了API操作文件,作為一個程序當然可以調用這些API來操作了。理論上完全可行,但是瀏覽器禁止了這種做法,(瀏覽器并沒有給網頁提供這樣的API),一個網頁不能直接的讀寫硬盤文件。(為了信息安全以及硬盤安全)
瀏覽器選擇退而求其次,給網頁提供了這樣的 API,能夠有限度的存儲數據(按照鍵值對的格式),但不能隨意的訪問文件系統。
瀏覽器提供的網頁可以存儲數據的機制:Cookie、LocalStorage、IndexDB
Cookie字段的使用
HTTP請求中的Cookie字段,就是把本地存儲的Cookie信息發送到服務器這邊; HTTP
響應中會有一個Set-Cookie字段,就是服務器告訴瀏覽器你要在本地保存哪些信息。
結論
Cookie 從哪里來?服務器返回給瀏覽器的,通常都是首次訪問/登錄成功之后。
Cookie 到哪里去?Cookie會存儲在瀏覽器本地主機的硬盤上,后續每次訪問服務器都會帶上Cookie。不同的客戶端,保存的Cookie是不同的,即使是同一個主機,使用不同瀏覽器,Cookie 大概率也不同。
Cookie 中存什么?鍵值對格式的數據,這里的內容都是程序員自定義的,和 query string 一樣外人無從理解。
cookie在瀏覽器這邊如何組織? 在硬盤本地保存,是按照不同的域名為維度分別存儲。
Cookie 的用途是什么?用來在客戶端保存數據,其中最主要的是保存用戶的身份標識,服務器就可以通過標識來區分用戶。
- 個人感覺它的作用就是服務器讓客戶端在預定的位置本地存儲部分信息,每次客戶端訪問服務器,服務器會讀取一下在預定的位置本地存儲部分信息,從而區分不同客戶端
8 狀態碼

在響應中,上述的200就是一個狀態碼,HTTP中的狀態碼都是約定好的。
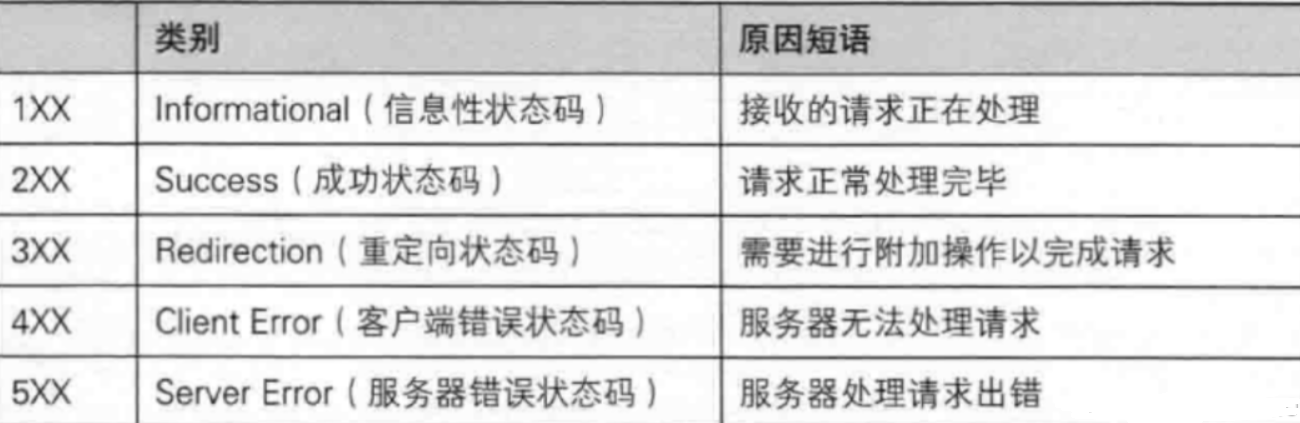
200 OK 表示一切順利
404 NOT FOUND 訪問的資源沒有找到
403 Forbidden 表示請求的資源沒有權限訪問
405 Method Not Allowed 服務器只支持GET,但是你發了個POST
500 Interal Server Error 服務器內部錯誤,可能是服務器掛了
504 Geteway Timeout 訪問服務器超時
302 Move temporarily 臨時重定向,如果一個網站更換了新的域名,但是老用戶并不知道,此時訪問原來的域名就可以跳轉到新的域名
301 永久重定向,瀏覽器會把重定向的結果記錄下來,后續再訪問就會直接訪問重定向的目標地址即可,不用跳轉
9. 構造HTTP請求
9.1 PostMan
PostMan是構造HTTP請求的第三方工具。
https://www.postman.com/web
9.2 通過代碼
package network;import jdk.internal.util.xml.impl.Input;import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.Socket;public class HttpClient {private Socket socket;private String ip;private int port;public HttpClient(String ip, int port) throws IOException {this.ip = ip;this.port = port;socket = new Socket(ip, port);}public String get(String url) throws IOException {StringBuilder request = new StringBuilder();//構造首行request.append("GET " + url + " HTTP/1.1\n");//構造headerrequest.append("Host: " + ip + ":" + port + "\n");//構造空行request.append("\n");//發送數據OutputStream outputStream = socket.getOutputStream();outputStream.write(request.toString().getBytes());//讀取響應數據InputStream inputStream = socket.getInputStream();byte[] buffer = new byte[1024 * 1024];int n = inputStream.read(buffer);return new String(buffer, 0, n, "utf-8");}public String post(String url, String body) throws IOException {StringBuilder request = new StringBuilder();//構造首行request.append("POST " + url + " HTTP/1.1\n");//構造headerrequest.append("Host: " + ip + ":" + port + "\n");request.append("Conternt-Length: " + body.getBytes().length + "\n");request.append("Content-Type: text/plain\n");//構造空行request.append("\n");//構造 bodyrequest.append(body);//發送數據OutputStream outputStream = socket.getOutputStream();outputStream.write(request.toString().getBytes());//讀取響應數據InputStream inputStream = socket.getInputStream();byte[] buffer = new byte[1024 * 1024];int n = inputStream.read(buffer);return new String(buffer, 0, n, "utf-8");}public static void main(String[] args) throws IOException {
// HttpClient httpClient = new HttpClient("42.192.83.143", 8080);
// String getResp = httpClient.get("/AjaxMockSever/info");
// System.out.println(getResp);
// String postResp = httpClient.post("/AjaxMockSever/info","this is body");
// System.out.println(postResp);HttpClient httpClient = new HttpClient("www.sogou.com", 80);System.out.println(httpClient.get("http://www.sogou.com"));}
}
10. HTTPS
HTTPS是在HTTP的基礎上,引入了一個加密層(SSL)。
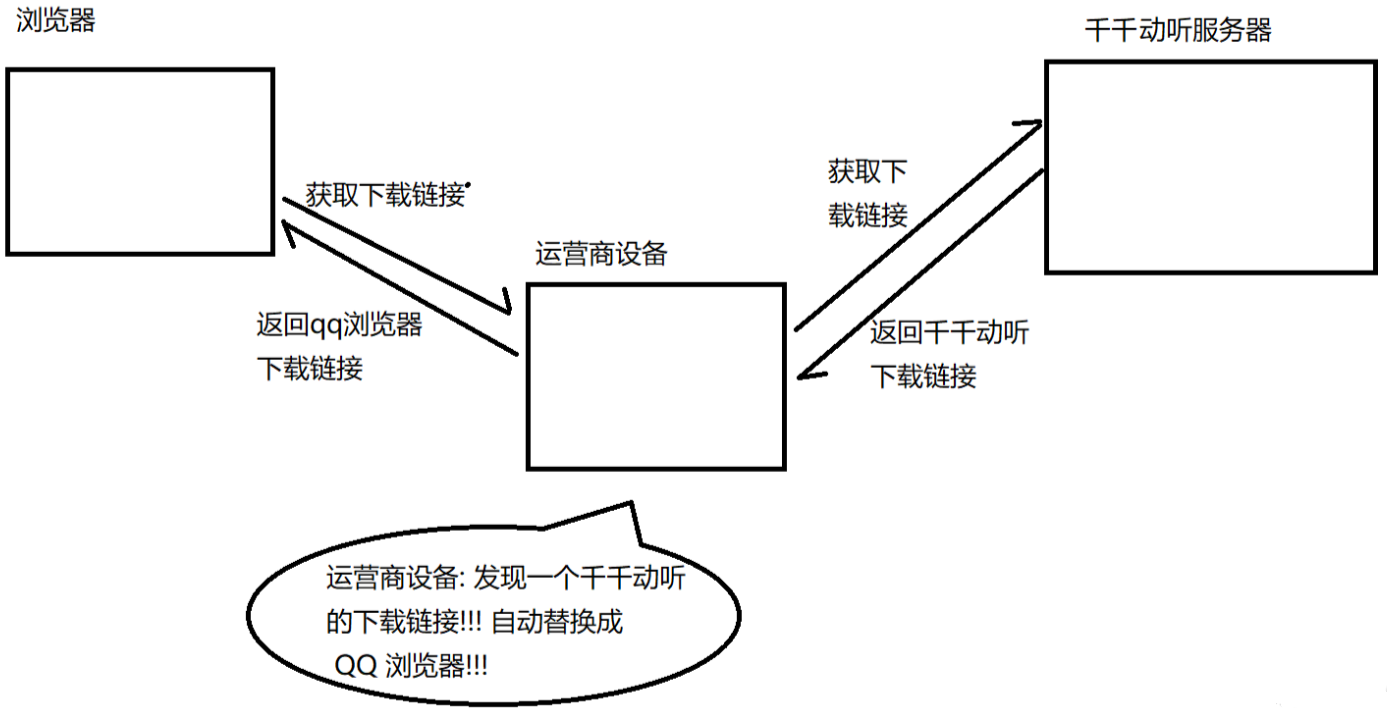
HTTP是明文傳輸的(不安全)
10.1 加密
解決安全問題,最核心的要點,就是"加密"。
介紹密碼學中的概念
明文:真正要傳輸的數據
密文:針對明文進行了加密,得到的結果往往不直觀
明文變成密文==>就是加密
密文變成明文==>就是解密
加密和解密的過程中,涉及到一個關鍵道具,稱為“秘鑰”
對稱加密:加密和解密,使用的是同一個密鑰
非對稱加密:加密和解密,使用的是兩個密鑰。這兩個密鑰k1、k2,是成對的。可以使用k1來加密,此時就是k2解密;也可以使用k2加密,此時就是k1解密。
兩個密鑰,就可以一個公開出去,稱為"公鑰",另一個自己保存好,稱為"私鑰"。
10.2 HTTPS工作流程
引入加密,對HTTP傳輸的數據進行保護,主要針對 header 和 body 進行加密。
HTTPS = HTTP + SSL(加密層)
對稱加密
通過對稱加密的方式對傳輸的數據進行加密的操作。
1.對稱加密的時候,客戶端和服務器使用的是同一個密鑰
2.不同的客戶端要使用不同的密鑰(如果所有的客戶端密鑰都相同,加密形同虛設,黑客很容易拿到密鑰)
每個客戶端連接到服務器的時候,都需要自己生成一個隨機的密鑰,并且把這個密鑰告知服務器。密鑰需要傳輸給對方的,一旦黑客拿到了這個密鑰,意味著加密操作就無意義。
非對稱加密
使用非對稱加密,主要是針對對稱密鑰加密,確保對稱密鑰的安全性。
非對稱加密系統開銷,遠遠大于對稱加密。不太適合使用非對稱加密針對大規模的數據進行加密。
服務器生成一對非對稱密鑰,私鑰服務器自己持有,公鑰則可以告知任何的客戶端。
客戶端在連上服務器之后,就需要先從服務器這邊拿到公鑰(公鑰本身就可以公開出去,不需要加密傳輸);然后客戶端生成對稱密鑰,拿著公鑰針對對稱密鑰進行加密。
此時就可以把加密之后的密文進行傳輸了,由于要想解密,必須通過私鑰,而私鑰只有服務器自己知道,此時這樣的加密的數據就可以比較安全的到達服務器了。
服務器通過私鑰解密之后得到了對稱密鑰,接下來和客戶端之間的通信就通過對稱加密來完成了。
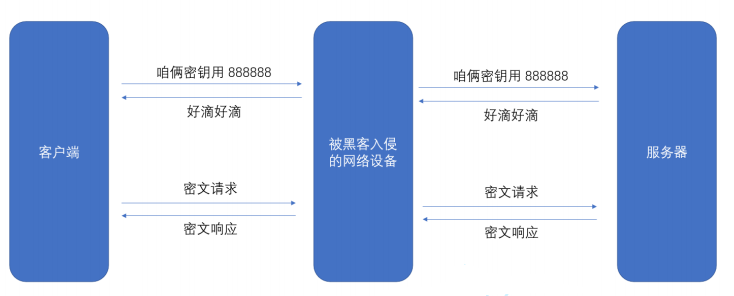
此時黑客拿到的是一個key加密后的結果,此時黑客要想解密,需要知道PRI,PRI私鑰只有服務器自己知道,黑客拿不到(黑客監聽中間的通信數據,要比黑入服務器這邊容易一些,如果都能黑進服務器了,大概率就可以直接拖數據庫了,用戶啥信息都被拿到了)。

SSL 內部完成的工作
使用HTTPS的時候,底層也是TCP先進行 TCP三次握手,TCP連接打通之后就要進行 SSL 的握手了(交換密鑰的過程),后面才是真正傳輸業務數據(完整的 HTTPS 的請求/響應了)。
黑客自己也能生成一對公鑰和私鑰設,公鑰為 pub2,私鑰為 pri2。黑客不關心服務器的公鑰私鑰是啥,自己生成一對就行了。生成公鑰和私鑰的算法都是開放的,服務器能生成,黑客也能生成。
黑客就可以使用 pri2 對上述數據進行解密,因此黑客就拿到了 key 。黑客繼續使用從服務器拿到的 pub1 重新對 key 進行加密并且傳輸給服務器。

證書
如何解決上述問題?
最關鍵的一點,客戶端拿到公鑰的時候,要能有辦法驗證,這個公鑰是否是真的,而不是黑客偽造的。
要求服務器這邊要提供一個**“證書”**
證書是一個結構化的數據(里面包含很多屬性,最終以字符串的形式提供)
證書中會包含一系列的信息,比如服務器的主域名、公鑰、證書有效期…
證書是搭建服務器的人,要從第三方的公正機構進行申請的。

一個關鍵問題:返回證書的時候,證書數據也是經過了黑客的設備,此時黑客是否能修改證書中的公鑰?公鑰替換成自己的公鑰呢?
不行,客戶端拿到證書之后,會先針對證書驗證真偽。
證書驗證的過程
證書中可能會包含這些信息
證書:服務器的域名:……
證書的有效時間:……
服務器的公鑰:……
公證機構信息:……
證書的簽名:……
其中最重要的就是證書的簽名。這個簽名并不是真正的簽名,而是根據算法將證書的數據算出他的校驗和,然后公證機構使用自己的私鑰(不是服務器的私鑰),針對校驗和進行加密,此時就得到了簽名。
客戶端拿到證書之后主要做兩件事:
1.按照同樣的校驗和算法將證書中的信息進行計算得到校驗和val1;
2.通過公證機構在系統中內置的公鑰來對證書進行解密,得到校驗和val2;
此時就對比看兩個校驗和是不是一致的
一致就是沒被修改過的
不一致就是被修改過的,如果黑客替換成了自己的公鑰,此時客戶端通過計算就會發現數據錯誤,此時客戶端就能發現錯誤。
這時候瀏覽器就會彈出一個告警界面,告訴用戶你訪問的網站有風險。
回答準確率)








![NSSCTF(MISC)—[justCTF 2020]pdf](http://pic.xiahunao.cn/NSSCTF(MISC)—[justCTF 2020]pdf)








)
