Towards Topic-Guided Conversational Recommender System 論文閱讀
- Abstract
- 1 Introduction
- 2 Related Work
- 2.1 Conversation System
- 2.2 Conversational Recommender System
- 2.3 Dataset for Conversational Recommendation
- 3 Dataset Construction
- 3.1 Collecting Movies for Recommendation
- 3.2 Creating Topic Threads
- 3.3 Generating the Conversation
- 3.4 The TG-ReDial Dataset
- 4 Our Approach
- 4.1 Problem Formulation
- 4.2 Recommendation Module
- 4.3 Dialog Module
- 5 Experiments
- 5.1 Evaluation on Item Recommendation
- 5.2 Evaluation on Topic Prediction
- 5.3 Evaluation on Response Generation
- 6 Conclusion
文章信息:

原文鏈接:https://arxiv.org/abs/2010.04125
源碼:https://github.com/RUCAIBox/TG-ReDial
Abstract
對話推薦系統(CRS)旨在通過交互式對話向用戶推薦高質量的項目。為了開發有效的CRS,高質量數據集的支持是必不可少的。現有的CRS數據集主要關注用戶的即時請求,而缺乏對推薦場景的主動引導。在本文中,我們貢獻了一個新的CRS數據集,名為TG-ReDial(通過主題引導的對話進行推薦)。我們的數據集具有兩個主要特點。首先,它結合了主題線索,以確保向推薦場景的自然語義轉換。其次,它是以半自動方式創建的,因此人類注釋更加合理和可控。基于TG-ReDial,我們提出了主題引導的對話推薦任務,并提出了一種有效的方法來解決這一任務。廣泛的實驗已經證明了我們的方法在三個子任務上的有效性,即主題預測、項目推薦和響應生成。TG-ReDial可在以下鏈接獲取:https://github.com/RUCAIBox/TG-ReDial。
1 Introduction

最近,對話推薦系統(CRS)(Chen等人,2019;Sun和Zhang,2018;Li等人,2018;Zhang等人,2018b;Liao等人,2019)已成為一個新興的研究課題,旨在通過自然語言對話為用戶提供高質量的推薦。通常,CRS由推薦組件和對話組件組成,分別負責提供合適的推薦和生成恰當的響應。為了開發有效的CRS,高質量的數據集對于學習模型參數至關重要。現有的CRS數據集大致可以分為兩類,即基于屬性的用戶模擬(Sun和Zhang,2018;Lei等人,2020;Zhang等人,2018b)和基于閑聊的目標完成(Li等人,2018;Chen等人,2019;Liu等人,2020)。
這些數據集通常假設用戶在與系統交互時有明確、即時的需求。它們缺乏從非推薦場景到所需推薦場景的主動引導(或過渡)。實際上,根據對話上下文自然觸發推薦變得越來越重要(Tang等人,2019;Kang等人,2019)。這個問題在DuRecDial數據集(Liu等人,2020)中得到了一定程度的探討。DuRecDial通過構建目標序列來描述目標規劃過程。然而,它主要關注對話子任務(例如,非推薦、推薦和問答)的類型切換或覆蓋。明確的語義過渡,即如何引導到推薦,尚未在DuRecDial數據集中得到充分研究或討論。此外,大多數現有的CRS數據集(Liu等人,2020;Li等人,2018)主要依賴人類標注者來創建用戶畫像或生成對話。由于生成的對話主要反映了標注者的特征(例如,興趣)或預定義的身份,因此很難通過有限數量的人類標注者捕捉到現實應用中的豐富、復雜的案例。
為了解決上述問題,我們構建了一個新的CRS數據集,名為通過主題引導的對話進行推薦(TG-ReDial)。該數據集包含10,000段在電影領域的兩方對話,對話雙方分別為尋求者和推薦者。我們的數據集有兩個新的特點。首先,我們明確創建了一個主題線索,以引導每段對話的整個內容流程。從非推薦主題開始,主題線索通過一系列演變主題自然地將用戶引導到推薦場景。我們的數據集通過閑聊對話強制實現了向推薦的自然過渡。其次,我們的數據集是以半自動方式創建的,涉及合理且可控的人類標注努力。關鍵思想是將對話中的用戶身份與來自一個流行電影評論網站的真實用戶對齊。通過這種方式,推薦的電影、創建的主題線索和推薦理由都是基于真實數據挖掘或生成的。人類標注者的主要任務是在必要時修訂、潤色或重寫對話數據。因此,我們不再依賴人類標注者來創建個性化的用戶畫像,如先前的研究(Li等人,2018;Liu等人,2020),使我們的對話數據更接近現實案例。圖1展示了我們TG-ReDial數據集的一個示例。
基于TG-ReDial數據集,我們研究了一個新的主題引導的對話推薦任務,該任務可以分解為三個子任務,即項目推薦、主題預測和響應生成。主題預測的目的是創建引導最終推薦的主題線索;項目推薦提供符合用戶需求的合適項目;響應生成則生成自然語言的適當回復。在我們的方法中,推薦模塊利用歷史交互和對話文本來推導準確的用戶偏好,分別通過順序推薦模型SASRec(Kang和McAuley,2018)和預訓練語言模型BERT(Devlin等人,2019)進行建模。對話模塊包括一個主題預測模型和一個響應生成模型。主題預測模型整合了三種有用的數據(即歷史發言、歷史主題和用戶畫像)來預測下一個主題。響應生成模型基于GPT-2(Radford等人,2019)實現,用于生成引導用戶或提供有說服力的推薦的回應。為了驗證我們方法的有效性,我們在TG-ReDial數據集上進行了廣泛的實驗,將我們的方法與競爭基線模型進行比較。我們的主要貢獻總結如下:
(1)我們發布了一個新的對話推薦系統數據集TG-ReDial。它強調了引導最終推薦的自然主題過渡。我們的數據集是以半自動方式創建的,因此人類標注更加合理和可控。
(2)基于TG-ReDial,我們提出了主題引導的對話推薦任務,包括項目推薦、主題預測和響應生成。我們進一步開發了一種有效的解決方案,基于Transformer及其變體BERT和GPT-2利用多種數據信號。
2 Related Work
2.1 Conversation System
對話系統(Shang等,2015;Li等,2016;Dhingra等,2017)研究如何在給定多輪上下文話語的情況下生成適當的回應。現有工作可分為任務導向系統(Dhingra等,2017;Young等,2007)和閑聊系統(Li等,2016;Shang等,2015;Zhou等,2019)。任務導向系統旨在完成特定目標(如訂票),而閑聊系統則提供通用對話。與我們的工作相關,話題信息在對話系統研究領域引起了廣泛關注(Xing等,2017;Tang等,2019;Xu等,2020),因為它能夠增強生成對話的語義。早期研究(Xing等,2017;Lian等,2019)側重于引導下一輪回應的話題,而近期研究(Tang等,2019;Xu等,2020)則開始強調整個對話中的多輪話題引導過程。例如,關鍵詞轉移(Tang等,2019)和知識圖譜(Xu等,2020)被引入以改進話題引導的對話系統。
2.2 Conversational Recommender System
對話推薦系統(Conversational Recommender System, CRS)(Chen等,2019;Sun和Zhang,2018;Li等,2018)旨在通過與用戶的對話提供高質量的推薦。通常,它由兩個部分組成:一個對話組件用于與用戶交互,另一個推薦組件用于根據用戶偏好選擇推薦項目。早期的對話推薦系統(Christakopoulou等,2016;Sun和Zhang,2018;Zhou等,2020c)主要通過詢問用戶對預定義槽位的偏好來進行推薦。近年來,一些研究(Li等,2018;Chen等,2019;Liu等,2020)開始通過自然語言對話與用戶交互,強調流暢的回應生成和精準的推薦。此外,后續研究(Chen等,2019;Kang等,2019;Zhou等,2020b)引入了知識圖譜或強化學習,通過增強的用戶模型或交互機制來提升對話推薦系統的性能。
2.3 Dataset for Conversational Recommendation
為了促進對話推薦系統的研究,近年來已發布了多個數據集(Li等,2018;Kang等,2019;Liu等,2020;Lei等,2020)。其中,Facebookrec(Dodge等,2016)和EAR(Lei等,2020)是基于經典推薦數據集通過自然語言模板構建的合成對話數據集。ReDial(Li等,2018)、GoReDial(Kang等,2019)和DuRecDial(Liu等,2020)則是通過人工標注創建的,具有預定義目標(如項目推薦和目標規劃)。這些目標導向的數據集結合了閑聊和任務導向(推薦任務)對話的元素。與這些數據集相比,我們的數據集強調話題引導的過程,自然地將會話引導至對話推薦系統的推薦場景中。值得注意的是,DuRecDial數據集(Liu等,2020)與TG-ReDial數據集類似,都利用目標序列來引導對話。然而,DuRecDial的目標序列由多種任務類型組成(例如推薦、問答等)。相比之下,TG-ReDial利用話題線索來表征內容流的演變,更容易融入開放域對話中。另一個顯著區別是,DuRecDial依賴人工標注生成用戶相關數據(如用戶畫像和話語),而TG-ReDial主要從電影評論網站挖掘合適的信息,更貼近真實場景。
3 Dataset Construction
借鑒(Sun和Zhang,2018;Li等,2018)的研究,我們采用了一種兩方設置的對話推薦系統,其中用戶和聊天機器人分別扮演信息尋求者和推薦者的角色。我們期望信息尋求者與推薦者之間的對話從非推薦場景開始。推薦者主動引導對話進入目標話題,然后根據尋求者的興趣進行合適的推薦。
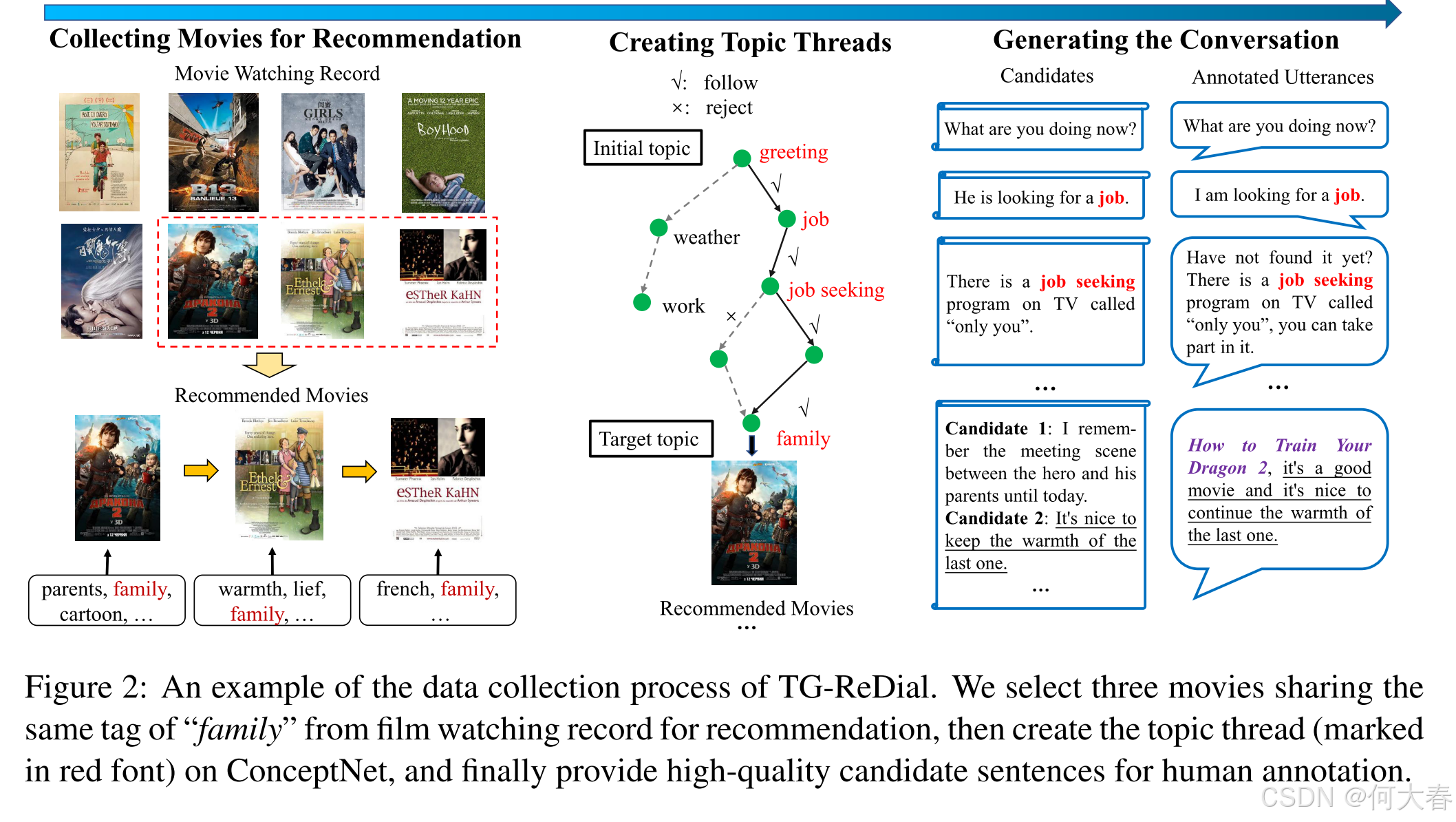
與以往的研究不同,我們以半自動化的方式構建了數據集。我們利用了中國熱門電影評論網站豆瓣電影的真實數據記錄。我們將每次對話與豆瓣電影的真實用戶關聯起來,從而可以結合用戶的觀看記錄(喜歡和不喜歡)進行推薦。對于推薦的電影,我們創建了一個從先前話題演變到電影目標話題的話題線索。最后,人工標注者將根據用戶畫像和檢索到的與電影相關的高質量候選內容生成合適的推薦回復。圖2展示了構建過程的示例。
接下來,我們首先描述TG-ReDial數據集的構建過程,然后展示該數據集的詳細統計信息。
](https://i-blog.csdnimg.cn/direct/7aada2e788294eccbd2d736c8867a74a.png)
3.1 Collecting Movies for Recommendation
為了模擬真實的推薦場景,我們首先收集了豆瓣上真實用戶的觀看記錄以用于推薦。為了使推薦與話題相關,我們為每部電影附加了若干有意義的標簽(例如類型、導演和主演)。我們保留了豆瓣電影中電影的原始標簽,并進一步挖掘其評論以提取高頻關鍵詞,然后手動選擇合適的標簽。每部電影的標簽數量設置為1到38個。整個觀看序列被分割成若干連貫的子序列,其中確保電影至少共享一個共同標簽。我們刪除了不連貫的子序列。每個保留的子序列對應一次獨特的對話,每個用戶平均參與四到五次對話。給定一個用戶,我們根據其對電影的評分標記接受/拒絕狀態(接受:五星評分≥4;拒絕:五星評分≤2)。與之前的研究(Li等,2018;Liu等,2020)相比,一個主要區別是我們重用了帶有評分偏好的現有觀看記錄(涵蓋喜歡和不喜歡的電影),使生成的對話更貼近真實情況。
3.2 Creating Topic Threads
給定一次對話中的電影,我們通過話題標簽以有序的方式將它們連接起來。每次對話的初始話題設置為問候語,目標話題則是下一部推薦電影的選定標簽。為了創建話題線索,我們從初始話題開始,遍歷常識知識圖譜ConceptNet(Speer等,2017)。通過深度優先搜索(DFS)算法識別的最短話題路徑被視為話題線索。我們多次重復上述過程,直到所有推薦電影都能通過話題線索連接起來。
為了增強信息尋求者的個性化特征,借鑒(Zhang等,2018a)的研究,我們生成了用戶畫像以更好地控制對話質量。我們首先從原始網站收集用戶畫像、自我描述及其評論文本中的關鍵詞,然后利用47個手寫模板生成句子來描述用戶畫像。通過用戶畫像,我們可以在生成話題線索時捕捉兩種選項,即跟隨和拒絕。在每一步中,跟隨選項會將當前話題納入話題線索,而拒絕選項則會考慮另一個話題進行擴展。選擇依據是話題關鍵詞是否出現在提取的畫像關鍵詞中。對于不在關鍵詞中的話題,我們以0.5的概率拒絕擴展該話題。這種采樣方式增加了對話數據的靈活性和多樣性。
3.3 Generating the Conversation
在獲得話題線索和推薦電影后,我們請眾包工作者完成對話。每次對話從閑聊話語開始,根據話題線索演變,并在目標話題上提供推薦。盡管上述信息(即電影序列、話題線索和用戶畫像)已經高度概括了對話的框架,但在有限的人工標注者數量下進行數據標注仍然具有挑戰性。受MultiWOZ(Budzianowski等,2018)的啟發,我們提出了一種基于開放域對話語料庫豆瓣(Wu等,2017)和爬取的電影評論的候選驅動標注方法,分別幫助生成與話題和推薦相關的話語。
給定一個話題線索,我們需要為其中的每個話題生成一句話語。給定一個話題,我們首先從豆瓣語料庫中隨機檢索20條包含該話題的話語。然后,我們利用基于RNN的匹配模型(Lowe等,2015)計算它們與上一條話語的相關性,并選擇最相關的句子作為候選話語。在這一步驟中,人工標注者的作用是修改檢索到的候選話語,以確保整個對話的語義一致性。
對于目標話題,我們需要生成一個有說服力的推薦理由。回想一下,用戶實際上已經觀看了這部電影并發表了相關評論。我們利用目標話題作為查詢,通過極端嵌入相似性(Liu等,2016a)檢索出最相關的三條評論句子。標注者將從這三條候選句子中選擇,并根據對話上下文在必要時進行修改或重寫。
我們的眾包工作者來自一家專業的數據標注公司。每條話語都分配給一名標注者(標注)和一名檢查員(檢查)。每位標注者都需要仔細閱讀用戶畫像并瀏覽原始網站上的詳細信息。為了保證人工生成數據的質量,我們進一步利用兩個自動指標來識別低質量案例以進行重新標注。具體來說,我們計算Distinct指標(Li等,2016)以過濾具有較小Distinct值的低信息量對話;我們還計算給定候選話語與人工標注話語之間的BLEU分數(Papineni等,2002),然后過濾幾乎沒有修改的對話。這些不良案例將被重新標注,直到通過自動評估為止。
3.4 The TG-ReDial Dataset

TG-ReDial的詳細統計數據如表1所示。TG-ReDial包含來自1,482名用戶的129,392條話語。我們的數據集以話題引導的方式構建,包含更多信息豐富的句子。平均而言,每次對話有7.9個話題,每條話語包含19.0個單詞,這些數字均大于現有對話推薦系統數據集(Li等,2018;Liu等,2020;Kang等,2019)的相應數值。此外,平均每位用戶有10條畫像句子和202.7條觀看記錄。
我們數據集的一個主要特點是通過話題線索組織對話,使得從閑聊到推薦的過渡更加自然。這樣的數據集特別有助于將推薦組件集成到通用聊天機器人中,因為我們的主題很容易與開放域對話對齊。此外,我們將對話與唯一的用戶身份相關聯,使其更貼近現實情況。特別是,我們可以獲取對話中用戶的畫像和觀看歷史。據我們所知,大多數現有數據集(Li等,2018;Liu等,2020)主要關注對話推薦系統的冷啟動場景,而對話推薦系統利用現有用戶的歷史交互數據也同樣重要。我們的數據集為利用歷史交互數據訓練對話推薦算法提供了可能性。由于我們的數據集中每個用戶參與了多次對話,研究其他個性化任務也是可行的。
需要注意的是,為了保護用戶隱私,我們僅采樣了具有大量觀看記錄的用戶。對于派生的用戶數據(例如畫像或觀看記錄),我們進行了匿名化處理并添加了隨機修改(例如刪除、替換或刪除)。我們還要求檢索到的評論句子必須通過改寫生成。最后,我們要求人工標注者手動追蹤數據集中用戶身份與相應用戶數據的對應關系。我們不包含最終數據集中可識別用戶的數據。
4 Our Approach
在本節中,我們首先形式化定義了話題引導的對話推薦任務。然后,我們介紹了針對該任務的解決方案。
4.1 Problem Formulation
給定用戶 u u u,我們假設她與一個畫像 P u P_u Pu?(一組與u感興趣的話題相關的描述性句子)和一個歷史交互序列 I u I_u Iu?(u按時間順序交互過的項目序列)相關聯。每次對話由一系列話語組成,表示為 d = { s k } k = 1 n d=\{s_k\}_{k=1}^n d={sk?}k=1n?,其中 s k s_k sk?是第 k k k輪的話語。我們以話題引導的方式考慮對話推薦系統,每條話語 s k s_k sk?與一個話題 t k t_k tk?相關聯。當 t k t_k tk?是目標話題時,系統將觸發對項目 i k i_k ik?的推薦,并提供有說服力的理由。
基于這些符號,話題引導的對話推薦任務定義為:給定用戶畫像 P u P_u Pu?、用戶交互序列 I u I_u Iu?、歷史話語 { s 1 , … , s k ? 1 } \{s_1,\ldots,s_{k-1}\} {s1?,…,sk?1?}以及相應的話題序列 { t 1 , … , t k ? 1 } \{t_1,\ldots,t_{k-1}\} {t1?,…,tk?1?},我們的目標是(1)預測下一個話題 t k t_k tk?以到達目標話題,或(2)推薦電影 i k i_k ik?,最后(3)生成關于該話題的適當回應 s k s_k sk?或帶有說服力的理由。這三個子任務分別稱為話題預測、項目推薦和回應生成。
4.2 Recommendation Module
推薦模塊的目標是根據對話上下文預測用戶喜歡的項目。關鍵點是如何推導出有效的用戶表示以進行推薦。我們為此任務考慮兩種數據信號。特別地,我們利用預訓練的語言模型BERT(Devlin等,2019)對歷史話語 { s 1 , … , s k ? 1 } \{s_1,\ldots,s_{k-1}\} {s1?,…,sk?1?}進行編碼,并使用自注意力序列推薦模型SASRec(Kang和McAuley,2018)對用戶交互序列 I u I_u Iu?進行編碼。
用戶 u u u的表示 v u v_u vu?如下獲得:

其中 v u ( 1 ) \boldsymbol{v}_u^{(1)} vu(1)?(從BERT獲得)和 v u ( 2 ) \boldsymbol{v}_u^{(2)} vu(2)?(從SASRec獲得)分別是表示歷史話語和交互序列的嵌入。給定用戶表示,我們可以計算從項目集中向用戶 u u u推薦項目 i i i的概率:

其中 e i e_i ei?是項目 i i i的學習項目嵌入。我們利用公式2對所有項目進行排序,并選擇概率最大的項目進行推薦。
4.3 Dialog Module
對話模塊旨在為用戶(尋求者)生成適當的回應,以進行話題引導或項目推薦。我們通過特定模型實現這兩個目的。
Topic Prediction Model.
它預測下一個話題,引導用戶u向目標話題發展。我們主要利用文本數據進行話題預測,并實現了三種不同的基于BERT的編碼器,即對話-BERT、話題-BERT和畫像-BERT,分別用于編碼歷史話語、歷史話題序列和用戶畫像。對于每個BERT變體,我們簡單地將所有可用的文本數據和目標話題(用[SEP]標記分隔)連接起來。目標話題的引入是為了增強話題語義。基于獲得的表示,我們通過以下公式計算話題 t t t作為下一個話題的概率:

其中 e t e_t et?是話題 t t t的學習嵌入, r ( 1 ) \boldsymbol{r}^{(1)} r(1)、 r ( 2 ) \boldsymbol{r}^{(2)} r(2)和 r ( 3 ) \boldsymbol{r}^{(3)} r(3)分別是歷史話語、話題和用戶畫像的嵌入,分別從對話-BERT、話題-BERT和畫像-BERT獲得。我們利用公式[3]對所有話題進行排序,并選擇概率最大的話題。
Response Generation Model.
它旨在為話題引導的對話生成適當的回應。我們利用預訓練的文本生成模型GPT-2(Radford等,2019)進行回應生成。GPT-2利用堆疊的掩碼多頭自注意力層,通過通用語言模型(Radford等,2019;Devlin等,2019)在大量網絡文本數據上進行訓練。我們在此模型中考慮兩種情況。對于非推薦情況,我們根據預測的話題生成回應,并將 t k t_k tk?與歷史話語 { s 1 , … , s k ? 1 } \{s_1,\ldots,s_{k-1}\} {s1?,…,sk?1?}(用[SEP]標記分隔)連接起來。對于推薦情況,我們根據推薦的項目生成有說服力的理由,并將推薦的電影 i k i_k ik?與歷史話語 { s 1 , … , s k ? 1 } \{s_1,\ldots,s_{k-1}\} {s1?,…,sk?1?}連接起來。對于這兩種情況,我們可以將輸入統一為一個長序列,該序列將被編碼并輸入GPT-2進行解碼。
5 Experiments
我們在TG-ReDial數據集上評估所提出的方法,該數據集按8:1:1的比例分為訓練集、驗證集和測試集。對于每次對話,我們從第一條話語開始,依次通過模型生成回復話語或推薦。我們對三個子任務進行評估,即項目推薦、話題預測和回應生成。
5.1 Evaluation on Item Recommendation
在本小節中,我們進行了一系列實驗,以驗證我們提出的模型在推薦任務中的有效性。借鑒(Kang和McAuley,2018;Liu等,2016b)的研究,我們采用NDCG@k和MRR@k(k = 10, 50)作為評估指標,對所有可能的項目進行排序。
Baselines.
我們考慮以下基線模型進行性能比較:(1)Popularity根據交互次數衡量項目的流行度進行排序。(2)ReDial(Li等,2018)專門為對話推薦系統提出,利用自動編碼器進行推薦。(3)KBRD(Chen等,2019)是最先進的對話推薦系統模型,使用知識圖譜增強上下文項目或實體的語義以進行推薦。(4)GRU4Rec(Liu等,2016b)應用GRU對用戶交互歷史進行建模,不使用對話數據。(5)SASRec(Kang和McAuley,2018)采用Transformer架構對用戶交互歷史進行編碼,不使用對話數據。(6)TextCNN(Kim,2014)采用基于CNN的模型從上下文話語中提取文本特征以進行推薦。(7)BERT(Devlin等,2019)是一種預訓練語言模型,直接對連接的歷史話語進行編碼。
Result and Analysis.
表2展示了不同方法在推薦任務中的表現。可以看出,Popularity的表現優于ReDial但不如KBRD。ReDial和KBRD利用歷史話語中的項目進行推薦。此外,KBRD結合了外部知識圖譜以增強項目的表示。其次,SASRec的表現優于GRU4Rec和兩個對話推薦系統模型(即KBRD和ReDial)。這表明自注意力架構特別適合對交互歷史進行建模。此外,基于文本的TextCNN(即TextCNN和BERT)表現優于其他基線模型,這表明利用歷史話語進行推薦是有用的。在這兩個基于文本的模型中,BERT的表現優于TextCNN,因為它采用了更強大的架構并利用大規模數據進行訓練。最后,我們提出的模型顯著優于所有基線模型。我們的模型能夠同時利用歷史話語和交互序列,結合了BERT和SASRec的優點。

5.2 Evaluation on Topic Prediction
我們繼續評估我們方法在話題預測任務中的表現。借鑒(Tang等,2019)的研究,我們采用Hit@k(k = 1, 3, 5)作為評估指標,對所有可能的話題進行排序。
Baselines.
我們考慮以下基線模型進行性能比較:(1)PMI通過計算與最后一個話題的點互信息進行排序。(2)MGCG(Liu等,2020)是最近提出的基于多類型GRU(使用特殊GRU編碼用戶畫像)的對話推薦系統模型。(3)Conversation/Topic/Profile-BERT分別利用對話/話題/畫像-BERT對歷史話語/話題/用戶畫像進行編碼以預測下一個話題。(4)Ours w/o target是我們提出的模型的消融模型,從輸入中移除目標話題。
Result and Analysis.
表3展示了不同方法在話題預測任務中的表現。可以看出,PMI表現不佳,因為它無法考慮目標話題。其次,Conversation/Topic-BERT的表現優于MGCG。這表明預訓練語言模型BERT特別適合捕捉話題語義。在基于BERT的模型中,ProfileBERT表現較差,因為在此任務中歷史話語和話題更為重要。此外,我們的模型優于所有基線模型,因為它聯合利用了由不同BERT模型編碼的歷史話語、話題和用戶畫像。最后,從BERT模型的輸入中移除目標話題后,性能顯著下降,表明目標話題的重要性。

5.3 Evaluation on Response Generation
最后,我們評估了我們方法在回應生成任務中的表現。借鑒(Chen等,2019;Qiu等,2019;Tao等,2018a)的研究,我們采用困惑度(PPL)和BLEU-1,2,3來評估生成回應與真實回應之間的相關性,并采用Distinct-1,2來評估生成話語的信息量。此外,我們邀請人工標注者對生成結果的相關性、流暢性和信息量進行評分,評分范圍為[0, 2]。
Baselines.
我們考慮以下基線模型進行性能比較:(1)ReDial(Li等,2018)采用分層RNN進行回應生成。(2)KBRD(Chen等,2019)應用Transformer并基于知識圖譜增強詞權重建模。(3)Transformer(Vaswani等,2017)應用基于Transformer的編碼器-解碼器框架生成適當的回應。(4)GPT-2(Radford等,2019)是一種預訓練文本生成模型,并在TG-ReDial數據集上進行了微調。
Result and Analysis.
表4展示了不同方法在回應生成任務中的表現。首先觀察到ReDial在我們的數據集上表現不佳。一個主要原因是ReDial采用分層RNN進行回應生成,這不適合編碼長話語(回想一下,我們數據集中的話語更長且信息量更大)。其次,Transformer在大多數指標上優于KBRD,因為KBRD利用知識圖譜信息提升實體和項目的預測概率,這可能對文本生成產生不利影響。此外,Transformer、GPT-2和我們的模型在BLEU分數上表現相似。對于PPL、Distinct和人工評估,Transformer表現最差,而我們的模型表現非常好。實際上,BLEU可能不適合評估對話推薦系統(Tao等,2018b),因為它更容易受到停用詞等無意義詞的影響。最后,我們的模型在大多數情況下優于所有基線模型,因為它可以利用預測的話題或項目來提升生成文本的質量。

6 Conclusion
我們為對話推薦系統引入了一個高質量的數據集TG-ReDial,該數據集基于真實用戶數據通過人工標注構建。基于TG-ReDial,我們提出了話題引導的對話推薦任務及其解決方案。大量實驗證明了所提出方法在三個子任務中的有效性。目前,TG-ReDial數據集的潛力尚未完全挖掘。它可以作為更多任務的測試平臺,例如個性化閑聊(Zhang等,2018a)、目標引導對話(Tang等,2019)和序列推薦(Zhou等,2020a)。作為未來工作,我們將在TG-ReDial數據集上研究這些任務。此外,我們還將考慮如何構建更有效的話題引導對話推薦方法。
——EFCore反向工程)






)
![[Web 安全] 反序列化漏洞 - 學習筆記](http://pic.xiahunao.cn/[Web 安全] 反序列化漏洞 - 學習筆記)

神經網絡模擬二階電機數學模型中的非線性干擾,以及使用WNN(小波神經網絡)預測模型中的非線性函數來抵消遲滯影響的功能)
詳解: Pytorch實現)


認知)

)


