寫在前面
- 博文內容涉及 基于 Deepseek LLM 的本地知識庫搭建
- 使用 ollama 部署 Deepseek-R1 LLM
- 知識庫能力通過 Ragflow、Dify 、AnythingLLM、Cherry 提供
- 理解不足小伙伴幫忙指正 😃,生活加油
我站在人潮中央,思考這日日重復的生活。我突然想,如果有一天,垂老和年輕都難以驚起心中漣漪,一潭死水的沉悶,鮮花和蛋糕也撼動不了。如果人開始不能為微小事物而感動,那么地震山洪的噩耗想必也驚聞不了。如果活著和死亡的本質無異,那便沒有了存在的意義。我沒有快樂,也沒有痛苦,只是麻木的置身于平靜的絕望之中,和世界一起下沉。我甚至病態的渴望,心中掀起一場風暴或是海嘯,將我席卷撕裂。可那片黑洞里什么也沒有,它吞噬萬物,它帶走了我的生命 情緒 活力,我眼睜睜的看著,我對此無能為力。 這一刻我明白了我看遠山,遠山悲憫。遠山知道我的苦悶,卻改變不了什么,只能悲憫,悲憫我的麻木,悲憫我的無奈
持續分享技術干貨,感興趣小伙伴可以關注下 _
本地 LLM 部署
LLM 本身只是一些 神經網絡參數, 就拿 DeepSeek-R1 來講,模型本身存儲了 權重矩陣,以及 混合專家(MoE)架構, 實際運行起來需要行業級別的服務器配置, 消費級別的個人電腦不能直接運行,實際還涉及到硬件適配,需手動配置 CUDA/PyTorch 環境,編寫分布式推理代碼,處理量化與內存溢出問題
現在通過 ollama 可以在消費級別電腦部署,上面涉及到的問題 ollama 幫我們完成,同時還涉及模型的管理,推理服務構建
ollama 開源項目地址: https://github.com/ollama/ollama
它在項目中這樣介紹自己:Get up and running with large language models.
ollama安裝
下載 ollama:之后直接安裝就可以,下載地址, https://ollama.com/download
ollama 專注于在本地設備(如個人電腦或服務器)快速部署和運行開源大語言模型(如 DeepSeek-R1),支持模型下載、環境配置及基礎推理服務。
適用需本地化運行 LLM 的場景,強調數據隱私與低成本(無需高性能服務器),但是不提供知識庫管理、RAG 或應用開發功能,需配合其他工具使用
安裝成功會自動配置環境變量
PS C:\Users\Administrator> ollama -h
Large language model runnerUsage:ollama [flags]ollama [command]Available Commands:serve Start ollamacreate Create a model from a Modelfileshow Show information for a modelrun Run a modelstop Stop a running modelpull Pull a model from a registrypush Push a model to a registrylist List modelsps List running modelscp Copy a modelrm Remove a modelhelp Help about any command
。。。。。。
Ollama 采用 Client-Server(C/S)架構,C 端通過命令行(CLI)或桌面應用與用戶交互,發起模型請求。S 端負責處理客戶端請求,管理模型下載與元數據,推理引擎,負責加載模型并執行計算
Ollama 資源優化技術:
權重量化:支持 INT8/INT4 量化,顯存占用降低至原始模型的 1/2 至 1/4,使 65B 參數模型可在 16GB 內存設備運行分塊加載:長文本分塊處理,避免顯存溢出GPU/CPU 調度:優先調用 NVIDIA/AMD GPU 加速,無 GPU 時通過 Metal 或分布式計算優化 CPU 模式
模型管理機制:
本地存儲:模型文件(如 blobs 數據)和元數據(如 manifests)默認存儲在 $HOME/.ollama,支持離線使用,數據無需上傳云端,適合醫療、金融等隱私敏感場景。模型拉取:客戶端通過 ollama run <模型名> 觸發服務端從遠程倉庫下載并緩存模型
通過下面的地址選擇對應的參數的模型即可:
https://ollama.com/library/deepseek-r1
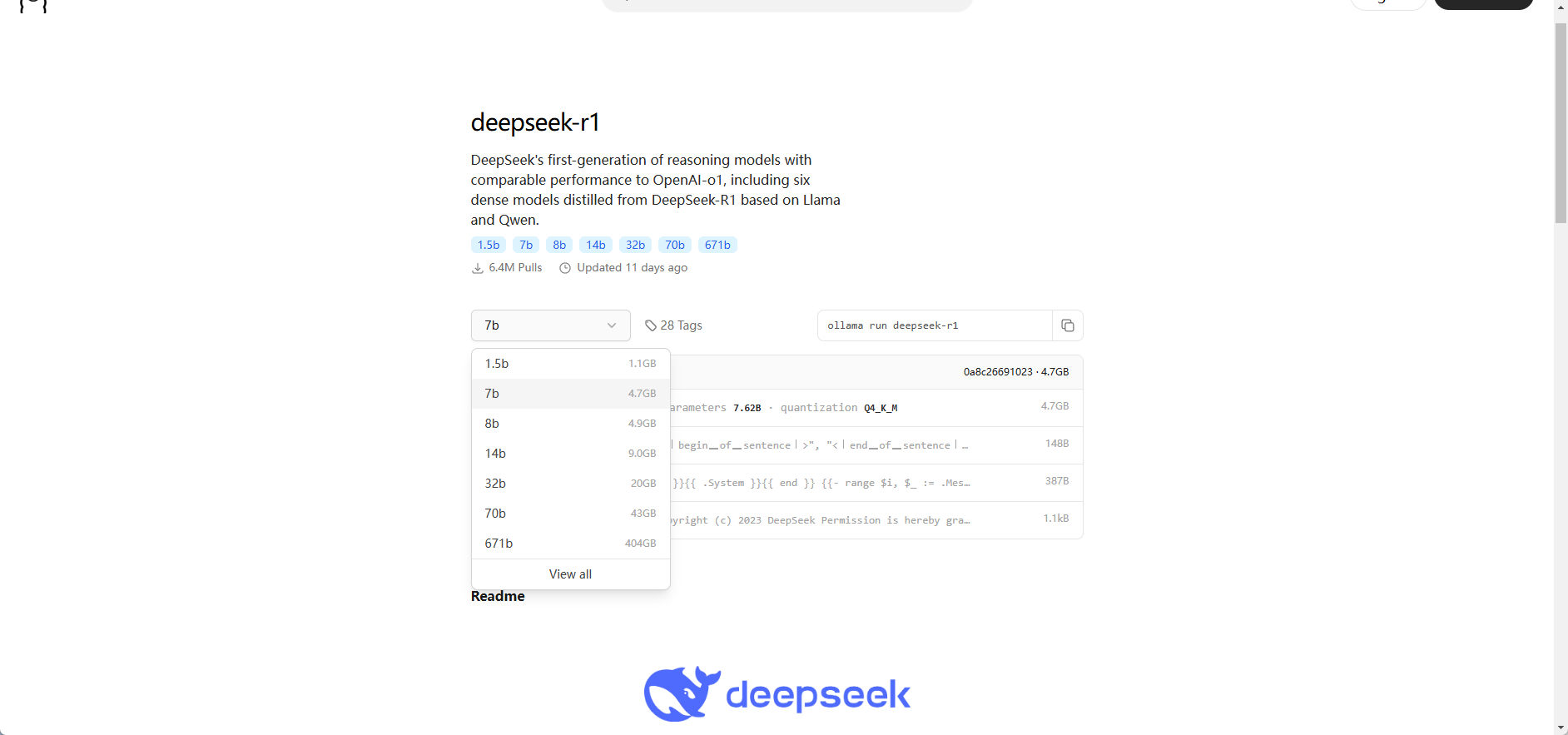
deepseek R1 蒸餾模型部署
關于什么是蒸餾模型,小伙伴可以看我之前的文章
模型下載成功就可以用了,默認會自動下載 DeepSeek-R1-Distill-Qwen-7B 模型
PS C:\Users\Administrator> ollama run deepseek-r1
pulling manifest
pulling 96c415656d37... 100% ▕████████████████████████████████████████████████████████▏ 4.7 GB
pulling 369ca498f347... 100% ▕████████████████████████████████████████████████████████▏ 387 B
pulling 6e4c38e1172f... 100% ▕████████████████████████████████████████████████████████▏ 1.1 KB
pulling f4d24e9138dd... 100% ▕████████████████████████████████████████████████████████▏ 148 B
pulling 40fb844194b2... 100% ▕████████████████████████████████████████████████████████▏ 487 B
verifying sha256 digest
writing manifest
success
直接命令行就可以交互了,算一道數學題
PS C:\Users\Administrator> ollama run deepseek-r1
>>> 1+2+3+4+54654+213=?
<think>
To solve the equation \(1 + 2 + 3 + 4 + 54654 + 213\), I will follow these steps:First, add the numbers from 1 to 4.Next, add the result to 54654.Finally, add this sum to 213 to get the final answer.
</think>To solve the equation \(1 + 2 + 3 + 4 + 54654 + 213\), follow these steps:1. **Add the numbers from 1 to 4:**\[1 + 2 + 3 + 4 = 10\]2. **Add this sum to 54654:**\[10 + 54654 = 54664\]3. **Finally, add the result to 213:**\[54664 + 213 = 54877\]**Final Answer:**\boxed{54877}>>> Send a message
這里通過命令行的方式啟動服務端,配置,$env:OLLAMA_HOST="0.0.0.0" 的作用是 將 Ollama 服務綁定到所有網絡接口,因為后面涉及到和其他工具交互。
PS C:\Users\Administrator> $env:OLLAMA_HOST="0.0.0.0" # 設置環境變量
服務啟動涉及到的環境變量在項目中位置:
https://github.com/ollama/ollama/blob/main/envconfig/config.go
PS C:\Users\Administrator> ollama serve # 啟動服務
2025/02/20 08:47:44 routes.go:1187: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://0.0.0.0:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:C:\\Users\\Administrator\\.ollama\\models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:0 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://*] OLLAMA_SCHED_SPREAD:false ROCR_VISIBLE_DEVICES:]"
time=2025-02-20T08:47:44.747+08:00 level=INFO source=images.go:432 msg="total blobs: 14"
time=2025-02-20T08:47:44.748+08:00 level=INFO source=images.go:439 msg="total unused blobs removed: 0"
time=2025-02-20T08:47:44.748+08:00 level=INFO source=routes.go:1238 msg="Listening on [::]:11434 (version 0.5.7)"
time=2025-02-20T08:47:44.749+08:00 level=INFO source=routes.go:1267 msg="Dynamic LLM libraries" runners="[cpu_avx cpu_avx2 cuda_v11_avx cuda_v12_avx rocm_avx cpu]"
time=2025-02-20T08:47:44.749+08:00 level=INFO source=gpu.go:226 msg="looking for compatible GPUs"
time=2025-02-20T08:47:44.749+08:00 level=INFO source=gpu_windows.go:167 msg=packages count=1
time=2025-02-20T08:47:44.749+08:00 level=INFO source=gpu_windows.go:183 msg="efficiency cores detected" maxEfficiencyClass=1
time=2025-02-20T08:47:44.749+08:00 level=INFO source=gpu_windows.go:214 msg="" package=0 cores=12 efficiency=4 threads=20
time=2025-02-20T08:47:44.872+08:00 level=INFO source=types.go:131 msg="inference compute" id=GPU-e65029a6-c2f9-44b1-bd76-c12e4083fa4c library=cuda variant=v12 compute=8.6 driver=12.8 name="NVIDIA GeForce RTX 3060" total="12.0 GiB" available="11.0 GiB"
[GIN] 2025/02/20 - 08:47:57 | 200 | 0s | 172.19.16.1 | GET "/"
[GIN] 2025/02/20 - 08:47:57 | 404 | 0s | 172.19.16.1 | GET "/favicon.ico"
同時項目啟動之后會輸出當前推理服務的環境變量
2025/02/20 08:47:44 routes.go:1187: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://0.0.0.0:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:C:\\Users\\Administrator\\.ollama\\models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:0 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://*] OLLAMA_SCHED_SPREAD:false ROCR_VISIBLE_DEVICES:]"
如果有需要部署生產級別的小伙伴需要詳細了解,這里簡單看幾個常用的:
OLLAMA_HOST
- 作用:指定服務器監聽的 IP 地址和端口。它定義了客戶端可以訪問服務器的地址。
- 當前值:http://0.0.0.0:11434,表示服務器將監聽所有可用的網絡接口,端口為 11434,使用 HTTP 協議。
OLLAMA_KEEP_ALIVE
- 作用:設置模型在內存中保持加載的時間。如果在這個時間內沒有新的請求,模型可能會被卸載以釋放內存。
- 當前值:5m0s,即 5 分鐘,意味著模型在 5 分鐘內沒有被使用就可能會被卸載。
OLLAMA_LOAD_TIMEOUT
- 作用:設置模型加載的超時時間。如果模型在這個時間內沒有加載完成,服務器可能會放棄加載操作。
- 當前值:5m0s,表示模型加載的最長時間為 5 分鐘。
OLLAMA_MAX_LOADED_MODELS
- 作用:限制每個 GPU 上最多可以加載的模型數量。這有助于控制 GPU 的資源使用。
- 當前值:0,表示沒有對每個 GPU 加載的模型數量進行限制。
OLLAMA_MAX_QUEUE
- 作用:設置請
求隊列的最大長度。當請求數量超過這個值時,新的請求可能會被拒絕。 - 當前值:512,表示請求隊列最多可以容納 512 個請求。
OLLAMA_MODELS
- 作用:指定模型文件存儲的目錄。服務器會從這個目錄中加載模型。
- 當前值:C:\Users\Administrator.ollama\models,表示模型文件存儲在該 Windows 用戶目錄下的 .
ollama\models 文件夾中。
OLLAMA_NUM_PARALLEL
- 作用:設置服務器
可以同時處理的并行模型請求數量。 - 當前值:0,表示沒有對并行請求數量進行限制。
知識庫搭建
在知識庫搭建的時候,我們還需要一個基本的嵌入模型,用于理解分析已有的知識庫內容
嵌入模型
這里我們使用的是 BGE-M3 ,嵌入模型是什么,通俗的話講,它把文本信息翻譯成計算機能夠理解和處理的數字形式,也就是向量。它就像是給每一段文本生成了一個獨一無二的 “數字指紋”,憑借這個 “指紋”,計算機就能對文本進行各種分析和操作。
有了嵌入模型分析知識庫的文本內容,那么是如何和問答結合的,這就需要 RAG
RAG
檢索增強生成(RAG)是一種將外部知識檢索與大語言模型(LLM)相結合的技術。傳統的大語言模型雖然擁有豐富的知識,但知識更新可能不及時,或者在特定領域的知識儲備不足。RAG 通過在生成回答之前,先從外部知識源(如文檔數據庫、網頁等)中檢索相關信息,然后將這些信息與用戶的問題一起輸入到大語言模型中,從而生成更準確、更具時效性的回答。
需要注意的事項
知識庫的搭建部分使用的是容器的方式,所以調用 ollama 提供的推理能力的時候,通過 127.0.0.0:11434 訪問是訪問不通的,所以需要一個能代表宿主機但是IP地址或者域名不是 127.0.0.0或localhost 的地址。
在windos 上面會有這個一個虛擬交換設備, 在其他服務調用 ollama 的時候,需要本地ID:11434 的方式訪問,這里我們選用這個 IP , 172.29.176.1:11434,至于這個 設備如何創建的,一般開啟虛擬化 Hyper - V 的時候會自動創建
以太網適配器 vEthernet (Default Switch):連接特定的 DNS 后綴 . . . . . . . :本地鏈接 IPv6 地址. . . . . . . . : fe80::c872:92b3:b00a:6ce0%25IPv4 地址 . . . . . . . . . . . . : 172.29.176.1子網掩碼 . . . . . . . . . . . . : 255.255.240.0默認網關. . . . . . . . . . . . . :
對于通過客戶端的方式直接部署的,我們可以之間使用 127.0.0.0:11434 或者 localhost 來訪問推理服務
Ragflow + DeepSeek
RAGFlow 是一款基于深度文檔理解構建的開源 RAG(Retrieval-Augmented Generation,檢索增強生成)引擎。RAGFlow 可以為各種規模的企業及個人提供一套精簡的 RAG 工作流程,結合大語言模型(LLM)針對用戶各類不同的復雜格式數據提供可靠的問答以及有理有據的引用。
官網地址:https://ragflow.io
項目地址: https://github.com/infiniflow/ragflow
這里需要使用 docker 來部署,安裝dockr, 克隆項目,執行 docker-compose 就可以了
git clone https://github.com/infiniflow/ragflow.git
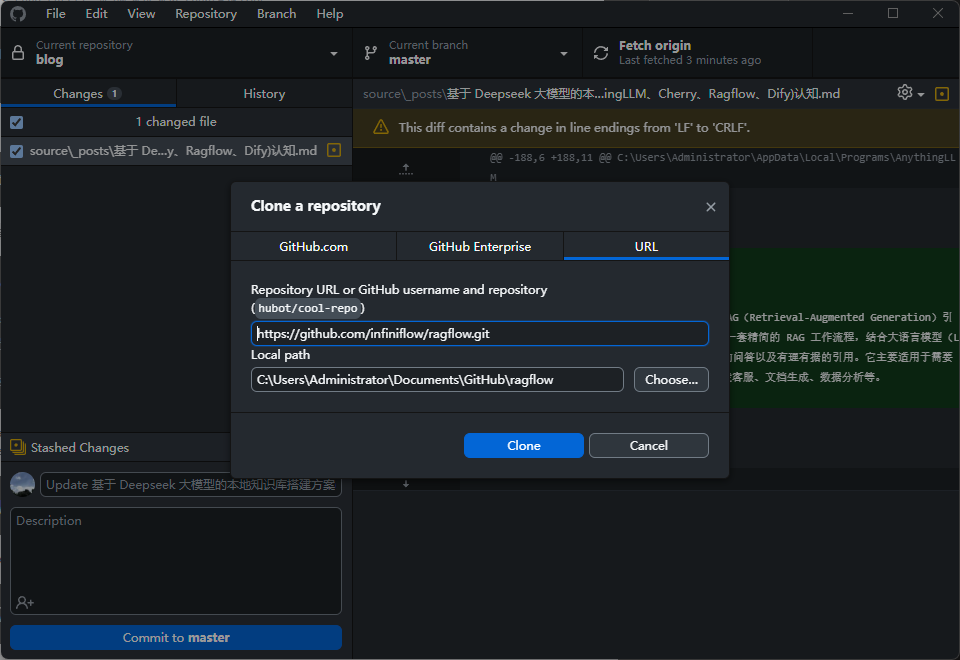
然后參考 readme 部署即可
$ cd ragflow/docker
$ docker compose -f docker-compose.yml up -d
這里需要說明一下,有些 docker-compose 維護不及時,可能部署有問題,所以我們用 readme 推薦的方式
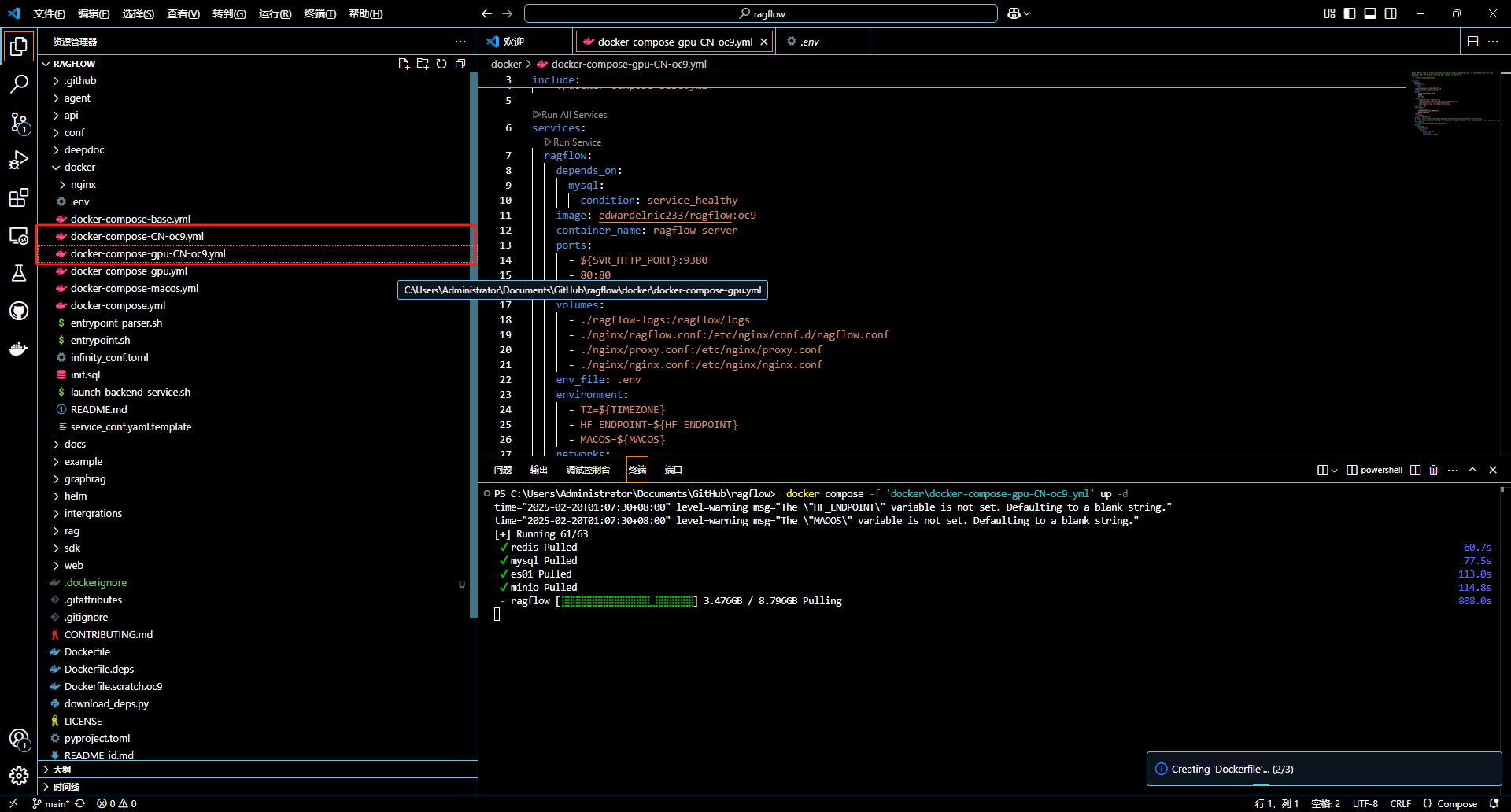
上面截圖中 GPU 版本的 我嘗試了好久,server 啟動鏈接 es 報錯,未果,用了默認的 compose。
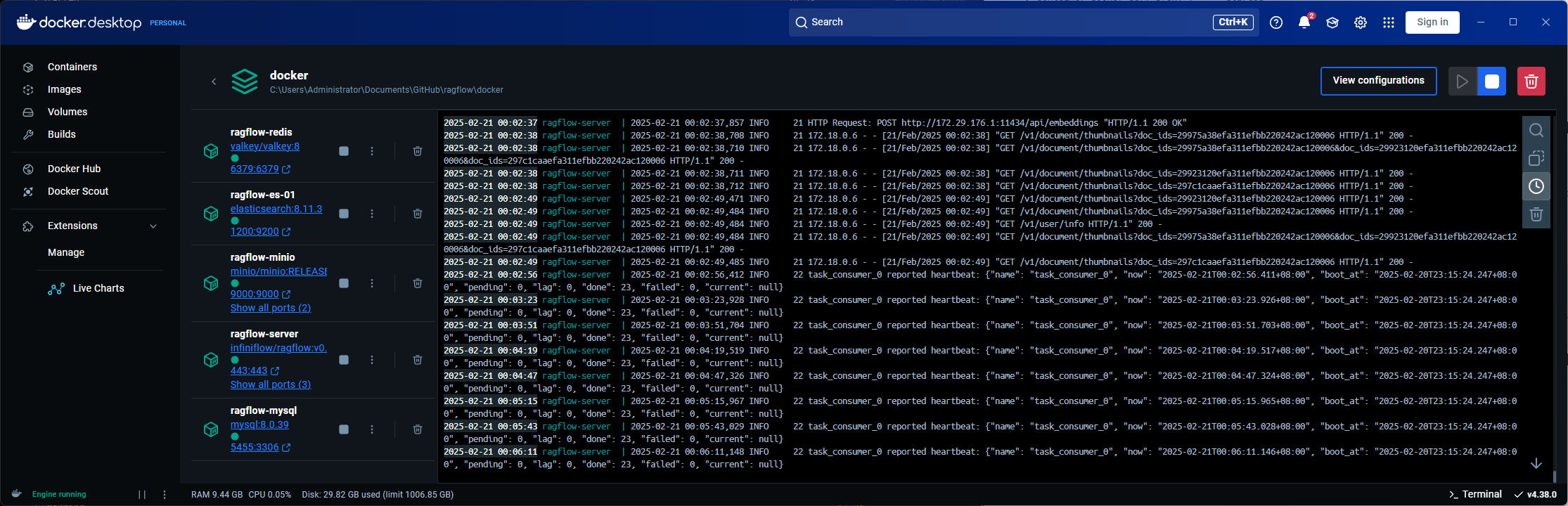
部署成功之后可以在docker 桌面版中看到容器,核心服務是一個 server
默認 80 端口,需要注冊賬號登陸
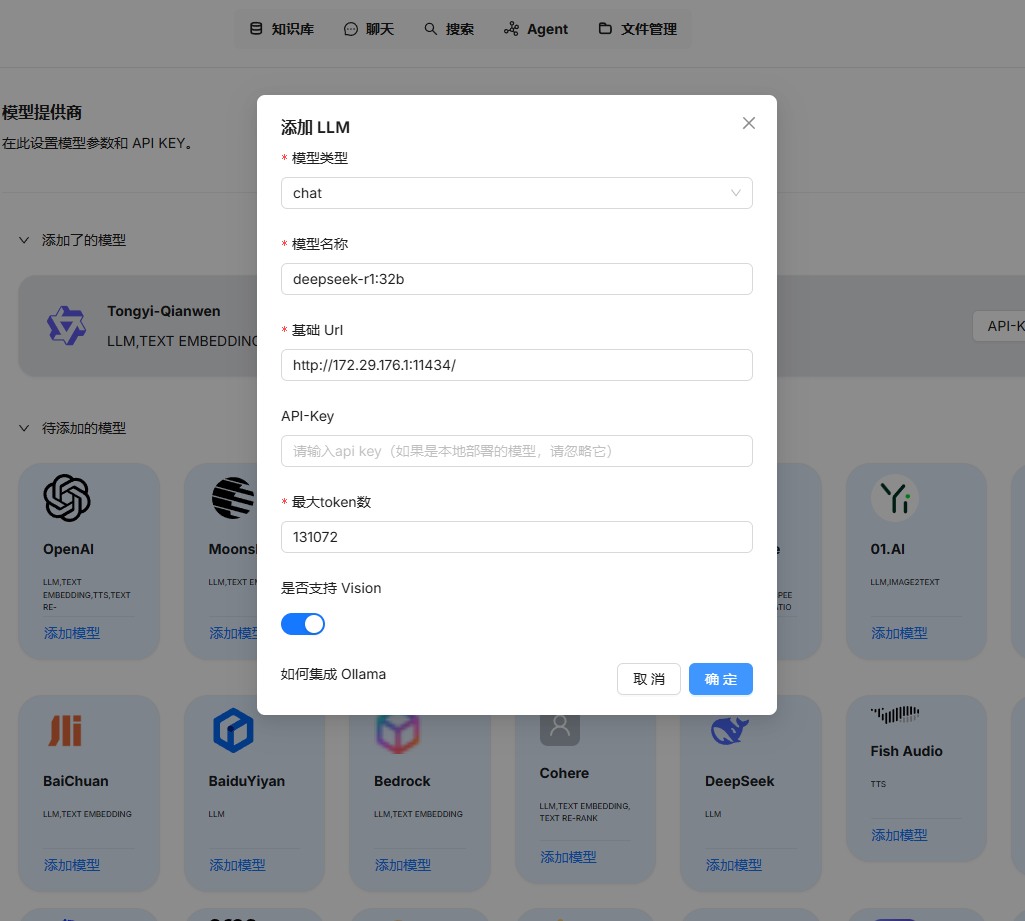
需要先配置基礎模型,需要注意這里的地址不能寫 127.0.0.1

選擇本地模型 LLM 模型
選擇嵌入模型

在系統模型設置添加對應的模型
選擇知識庫
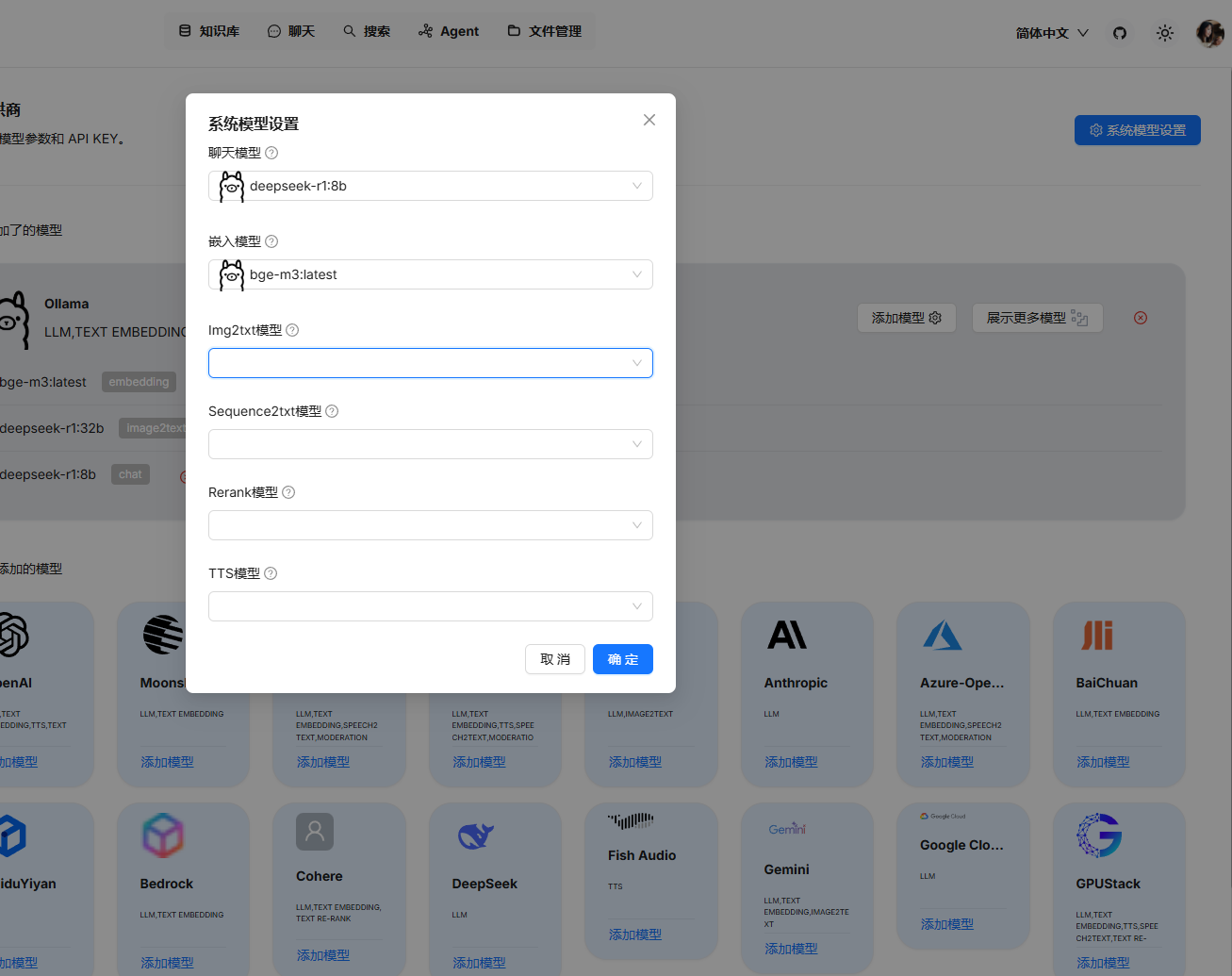
創建知識庫
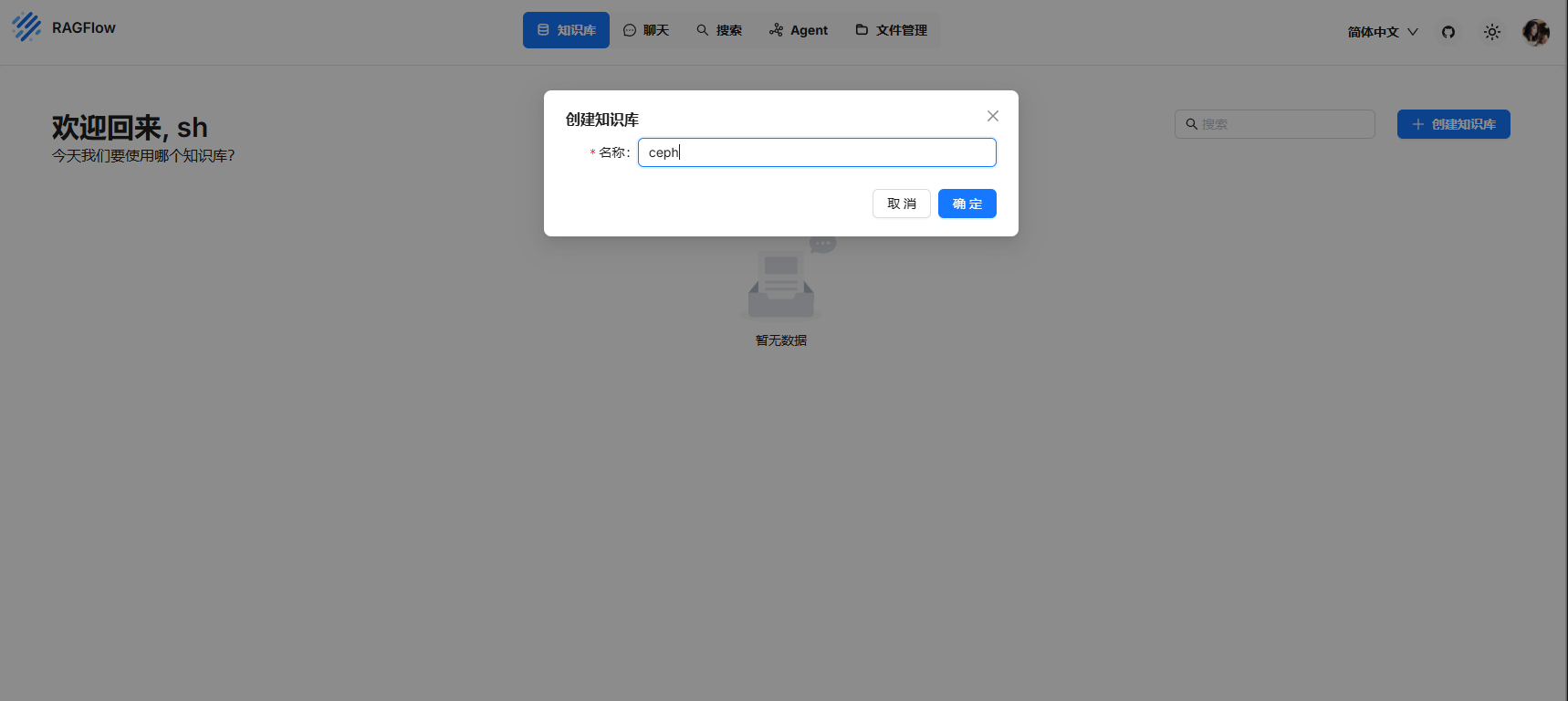
在配置中配置需要的數據
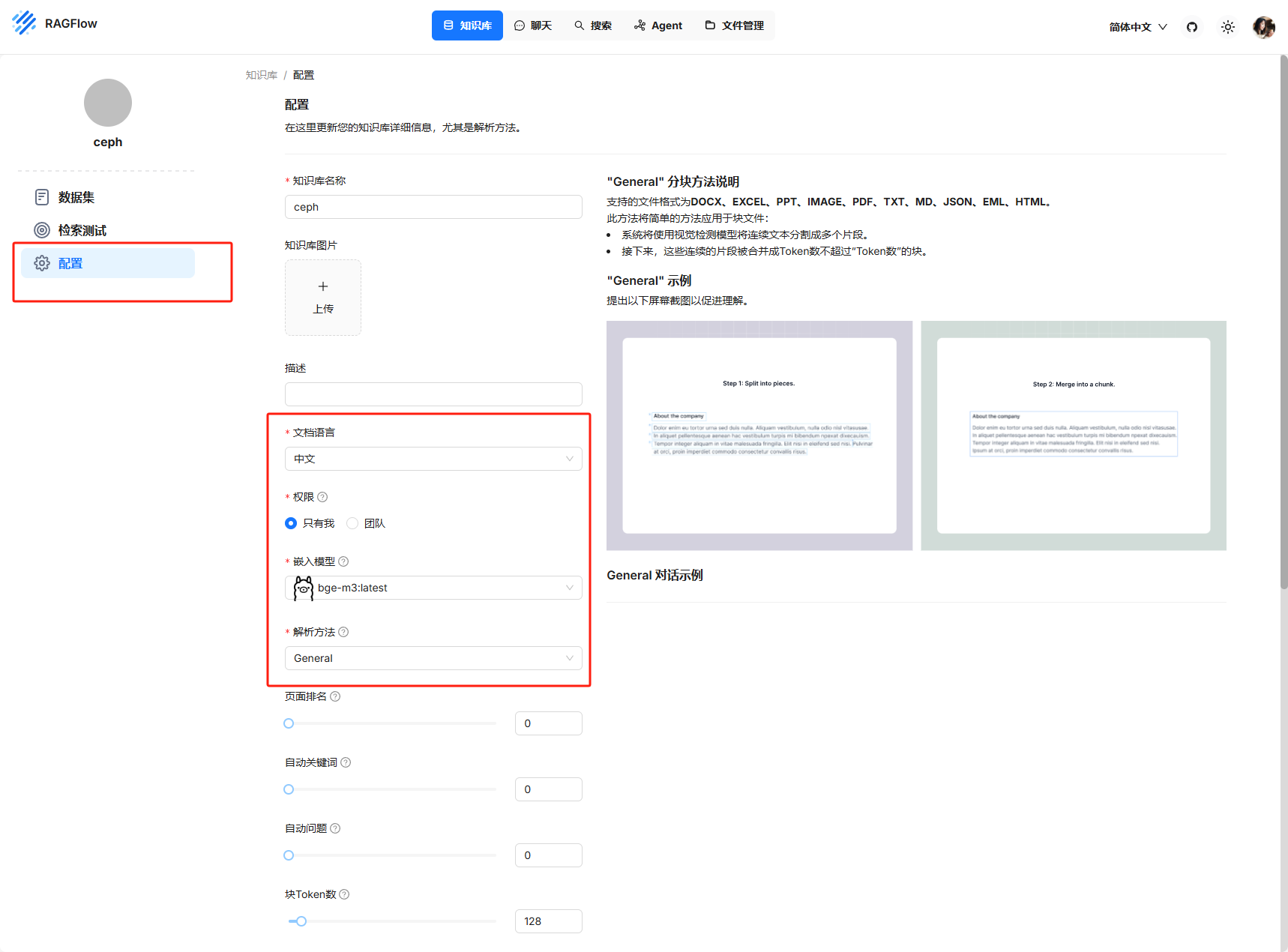
上傳本地的知識庫內容
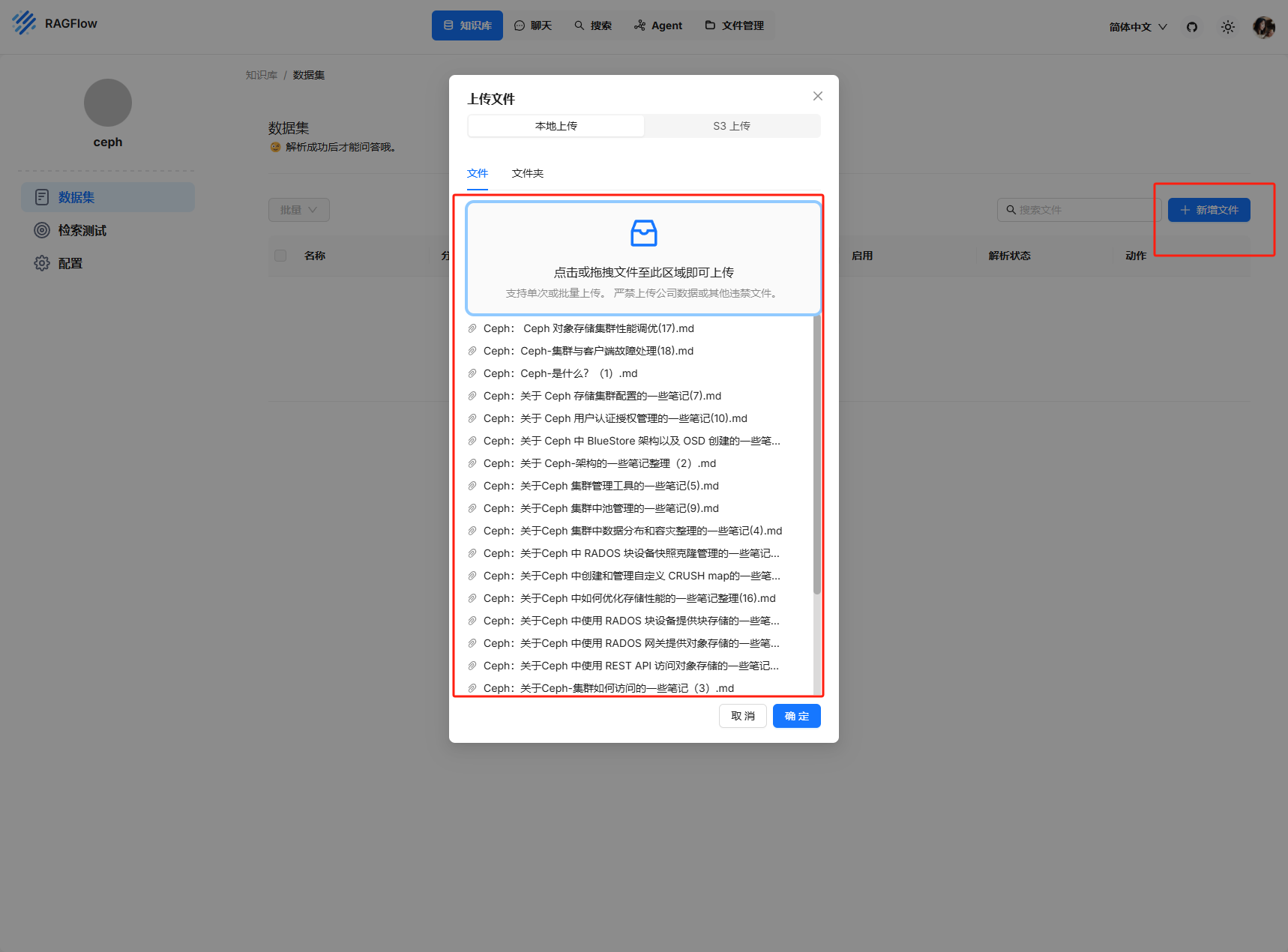
全選,解析啟用
之后在聊天配置中選擇對應的知識庫
模型參數調整
簡單測試
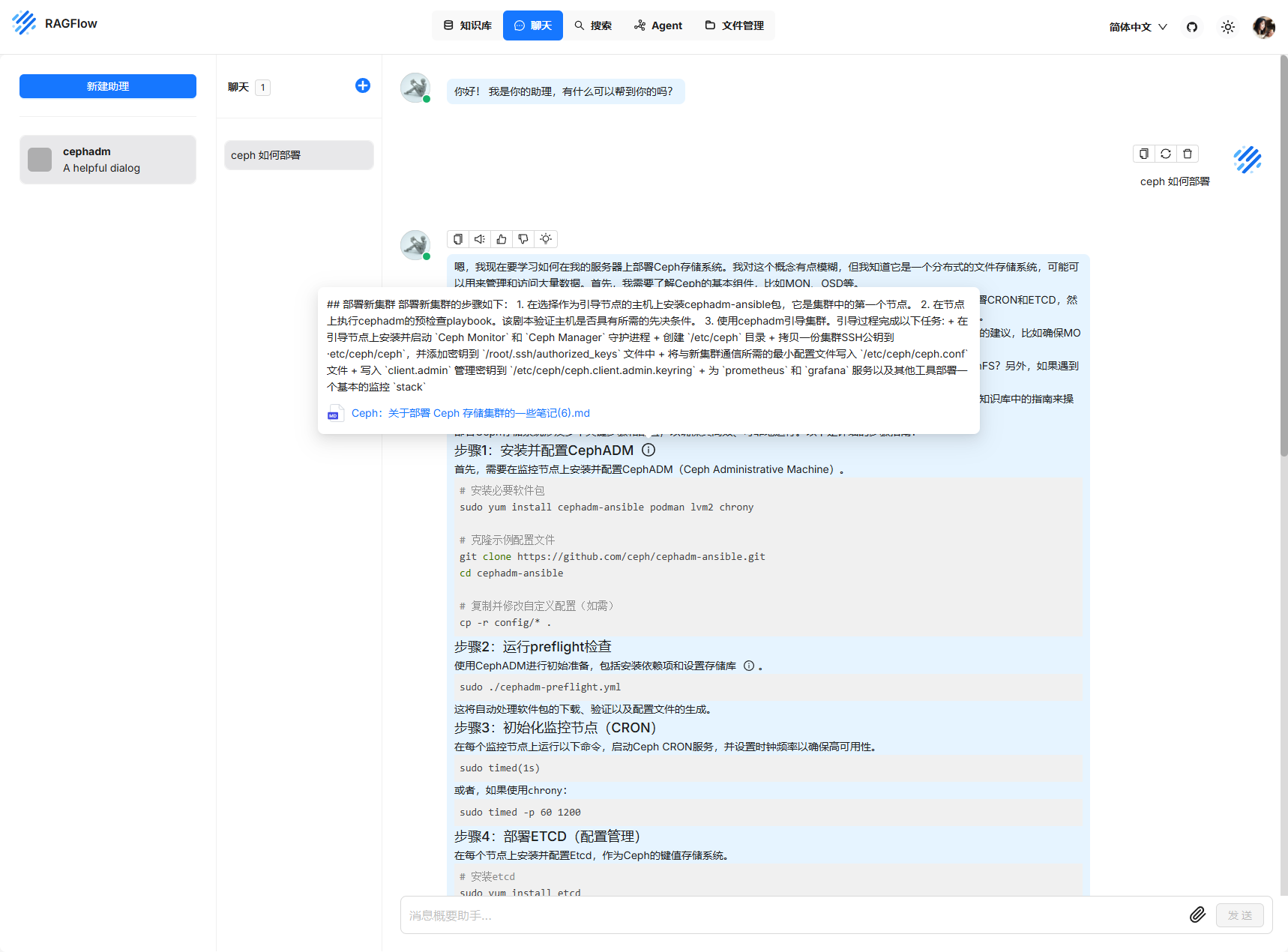
每次提問會顯示對應的文本內容
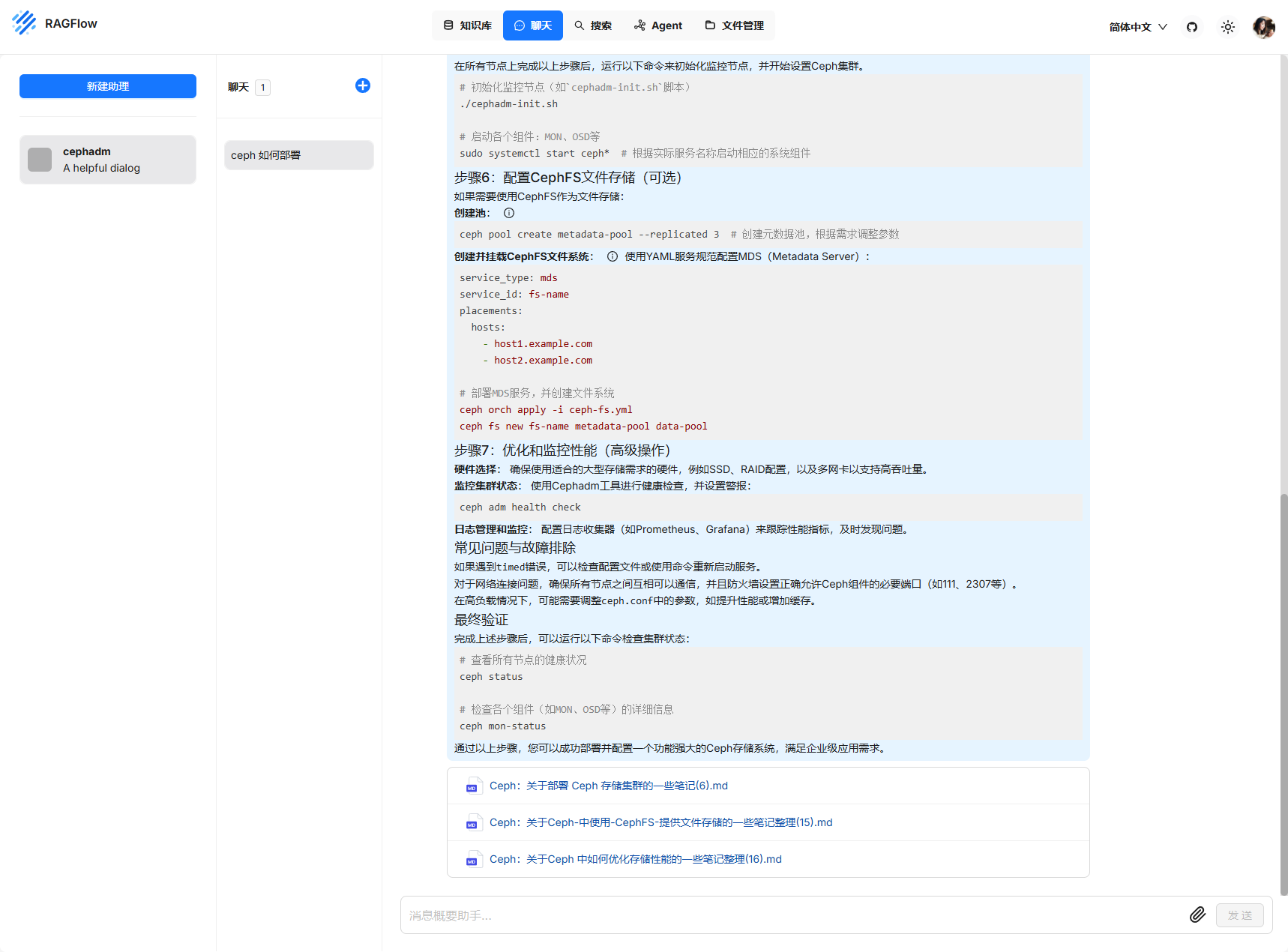
Dify + DeepSeek
Dify 是一個開源的 LLM 應用開發平臺。其直觀的界面結合了 AI 工作流、RAG 管道、Agent、模型管理、可觀測性功能等,可以快速從原型到生產。
官網地址: https://dify.ai/zh
項目地址: https://github.com/langgenius/dify/blob/main/README_CN.md
和上面的部署一眼,克隆項目,然后通過 docker 部署
git clone https://github.com/langgenius/dify.git
運行項目中的 docker-compose.yml
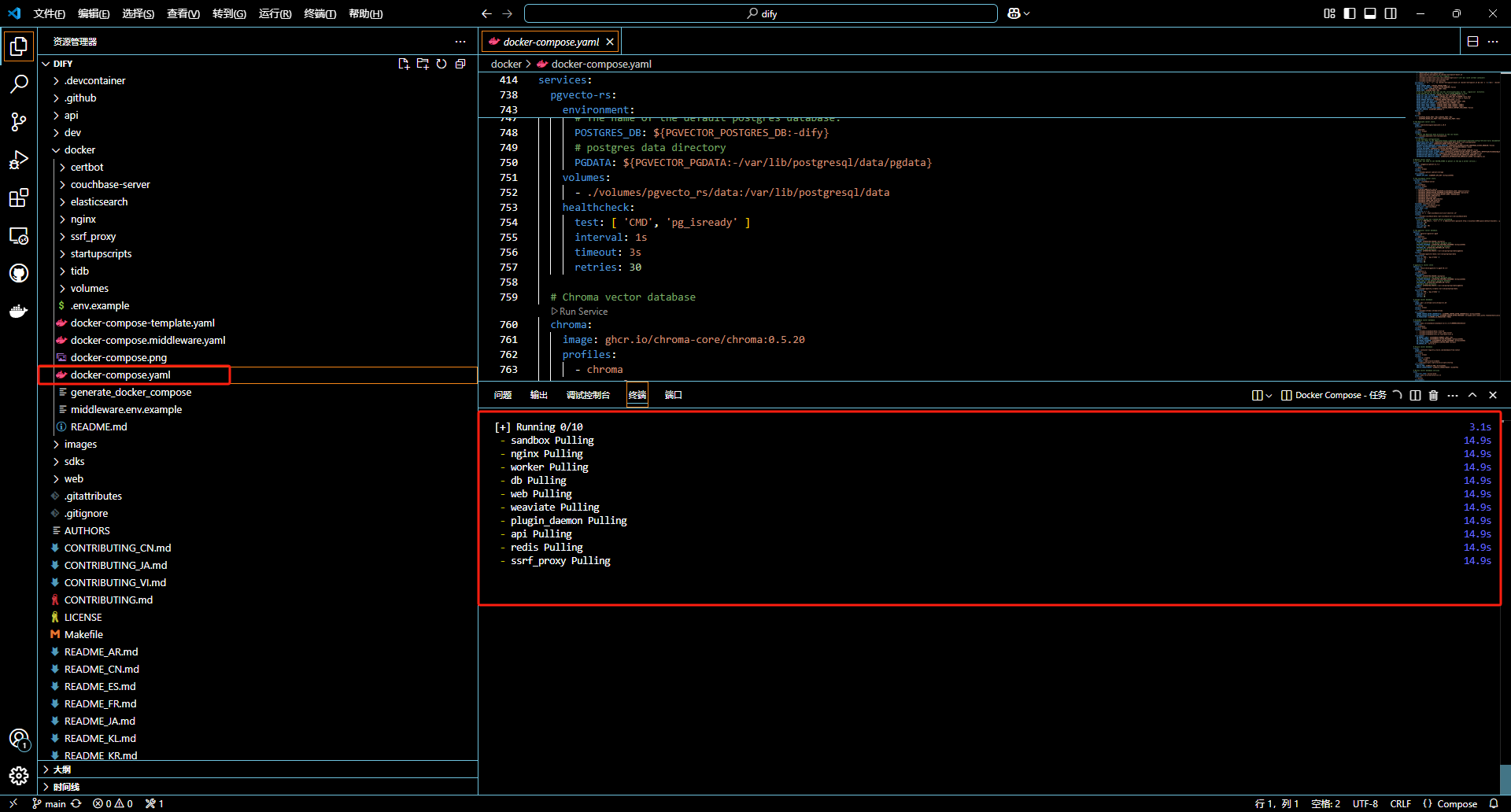
這里直接通過 vs code 運行
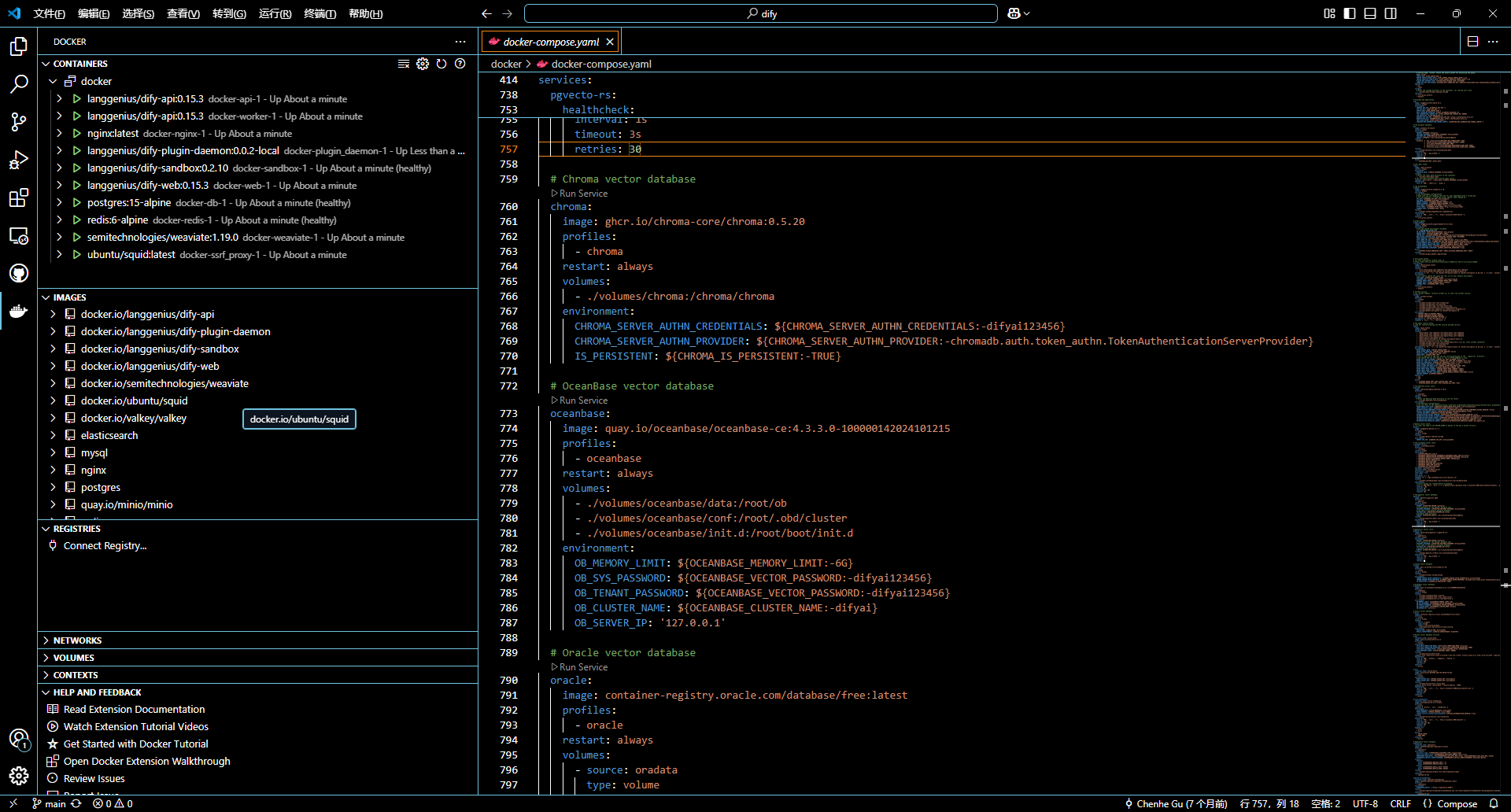
docker 中觀察容器運行情況
同樣是 80 端口,需要注冊一個賬號
用注冊的賬號登陸即可
選擇知識庫
在用戶中心設置中配置模型相關配置
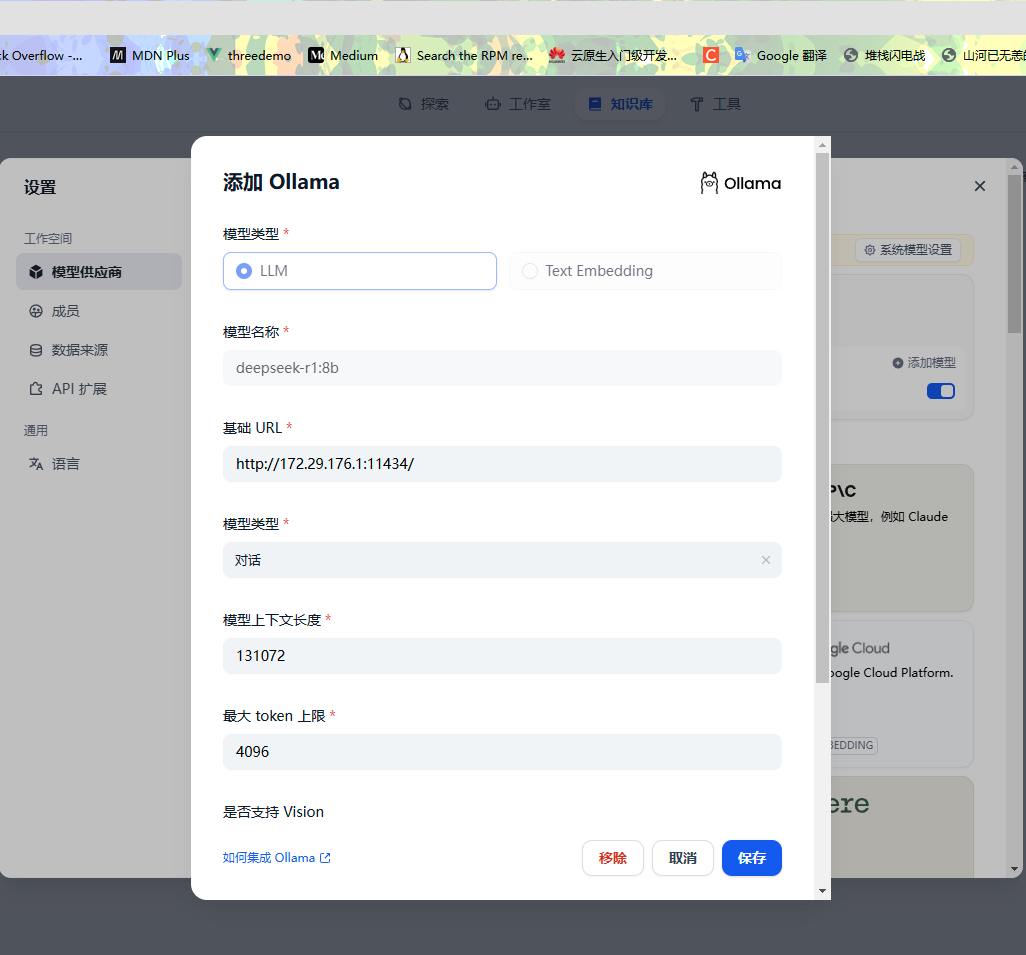
配置本地模型,需要注意這里的地址
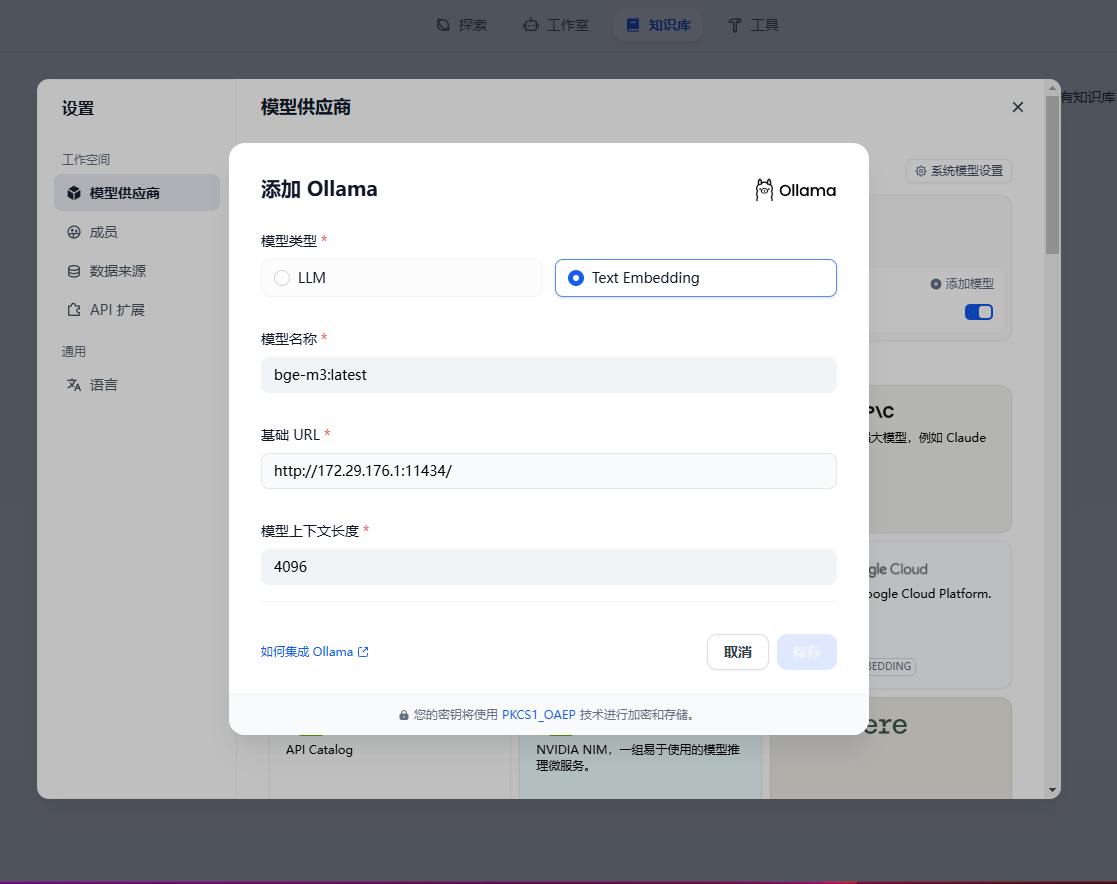
配置嵌入模型
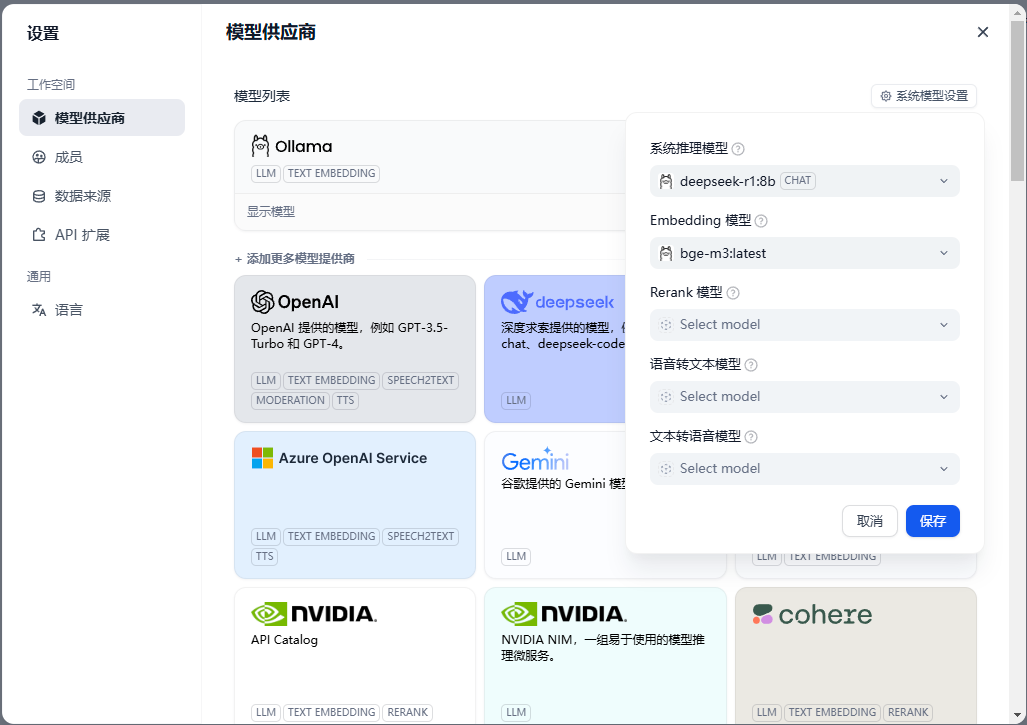
然后中模型配置中添加
選擇創建知識庫
導入本地知識庫
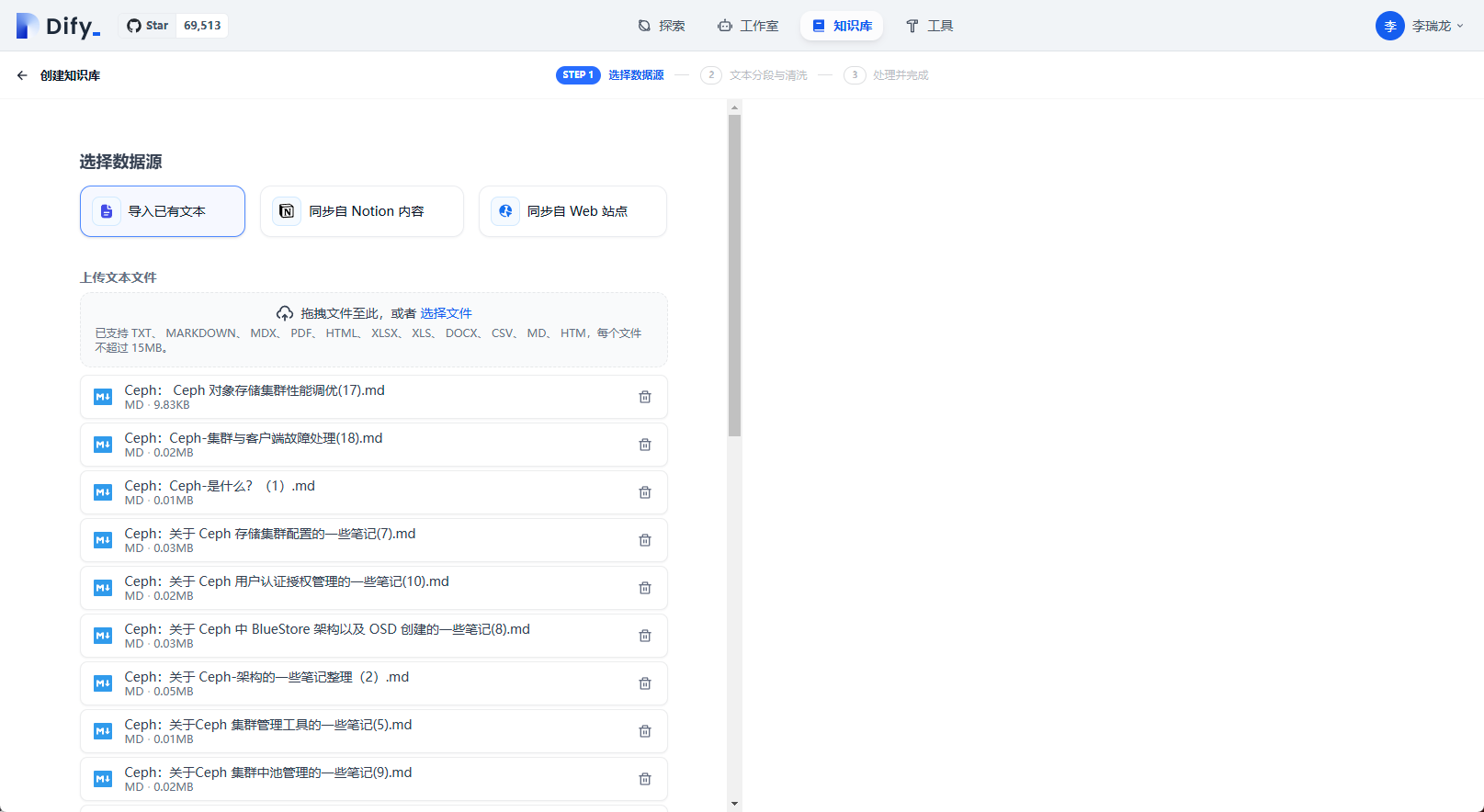
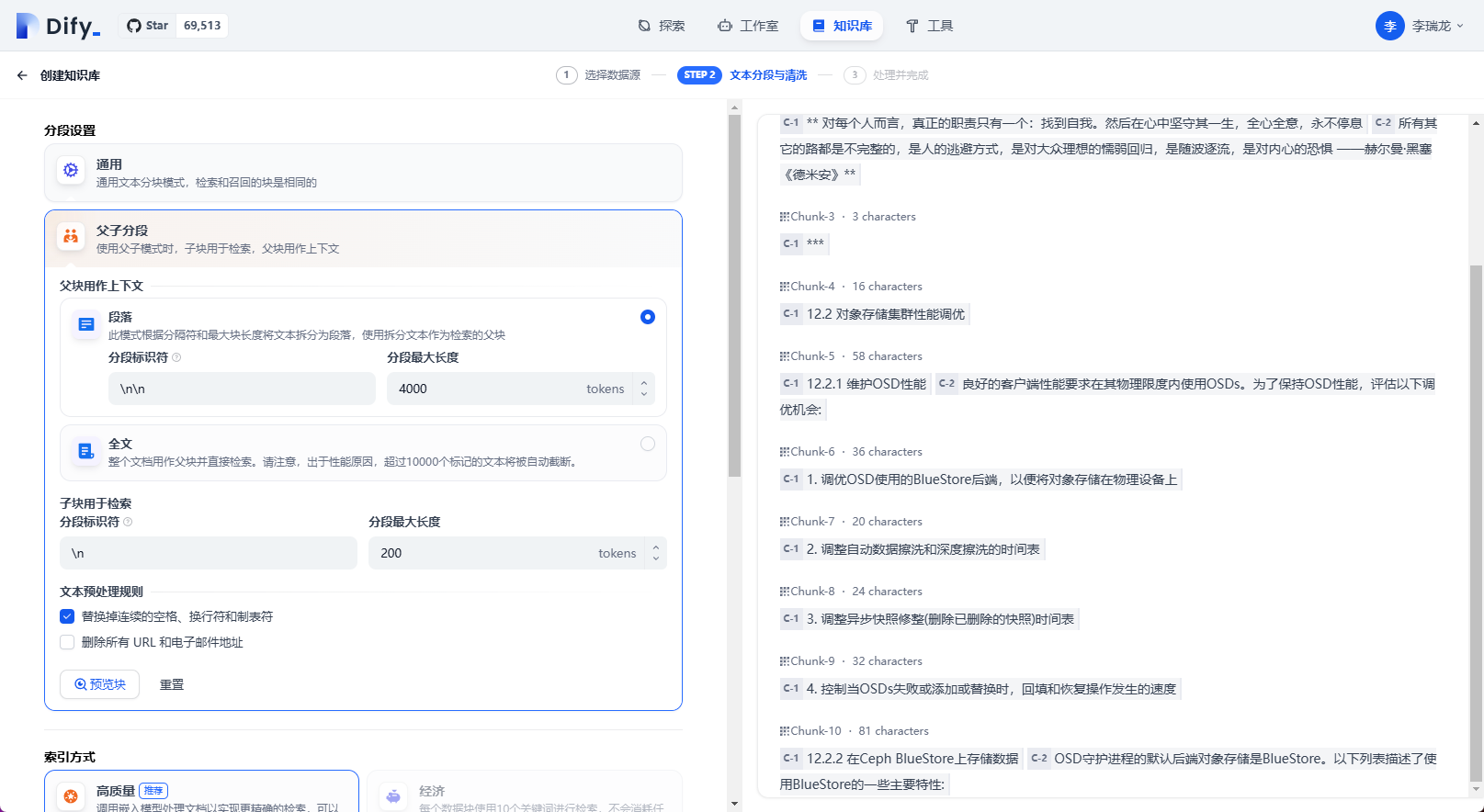
分段相關配置
保存設置
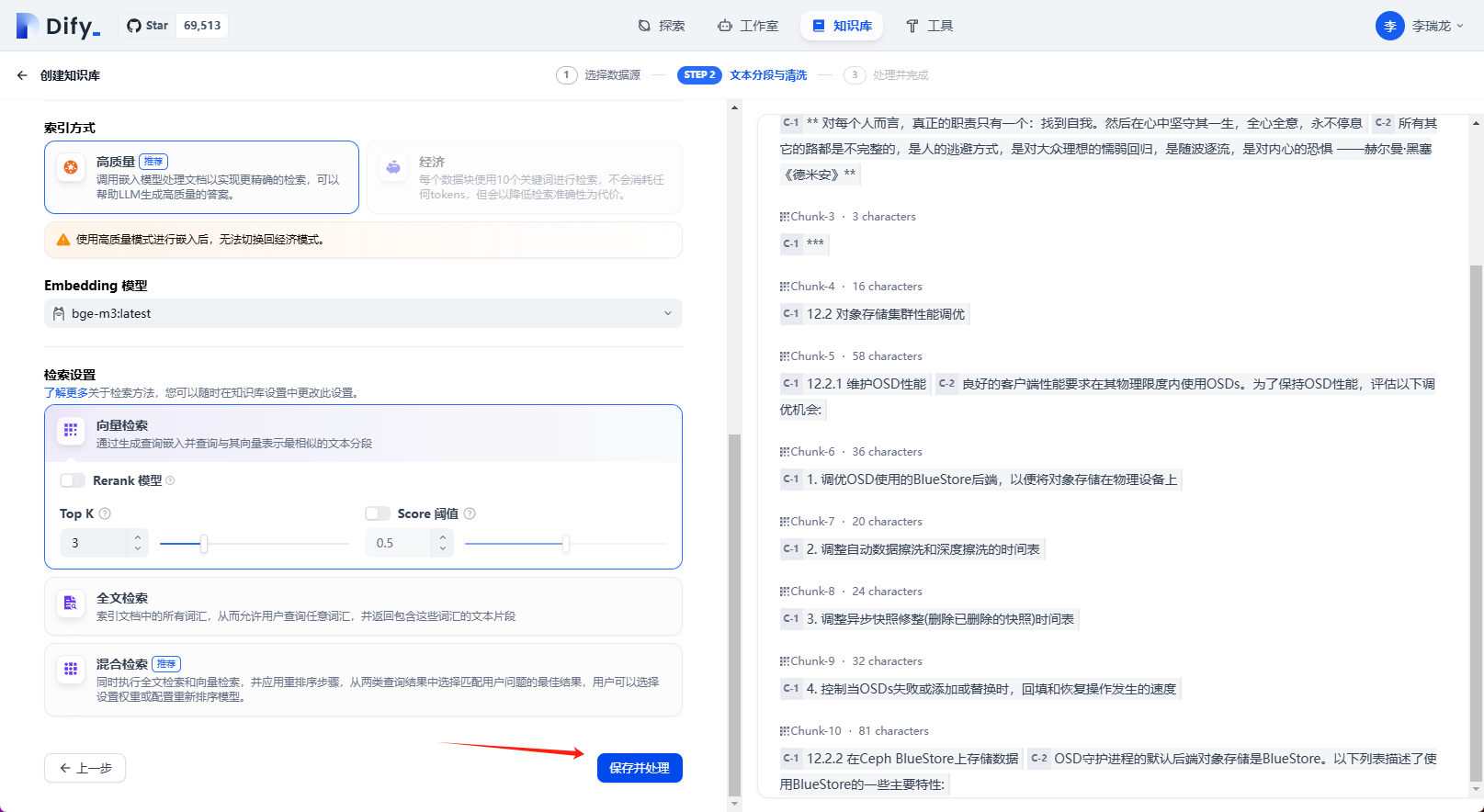
等待文檔解析完成
知識庫創建完成
創建聊天助手
上下文選擇之前創建的知識庫
做簡單的問答測試,可以看到最下面引用的文檔
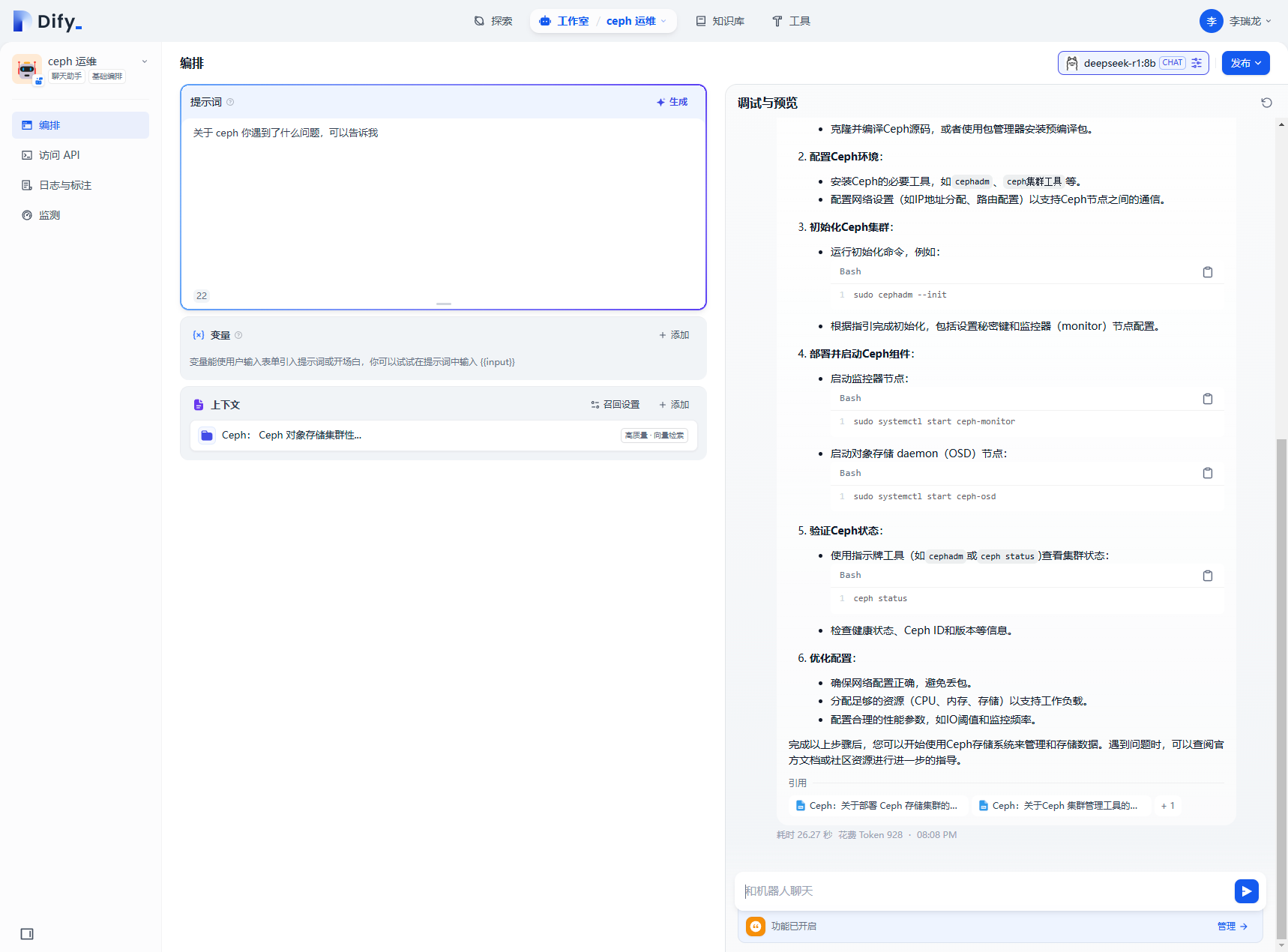
點擊發布,知識庫機器人創建完成
Cherry Studio + DeepSeek
Cherry Studio 是一款開源、跨平臺(支持 Windows/macOS/Linux)的 AI 桌面客戶端,專注于聚合多模型服務并提供本地化 AI 應用開發支持。
官網地址: https://cherry-ai.com/
下載地址: https://cherry-ai.com/download
項目地址: https://github.com/CherryHQ/cherry-studio
它的這樣介紹自己: Cherry Studio 是一款支持多個大語言模型(LLM)服務商的桌面客戶端,兼容 Windows、Mac 和 Linux 系統。

以下是其核心功能與使用要點:
多模型集成:支持 300+ 主流大語言模型,包括 DeepSeek、OpenAI、Gemini、Claude 等,通過 API 密鑰接入云端服務,也支持本地部署模型(如 Ollama)知識庫管理:可上傳 PDF、Word、Excel、網頁鏈接等文件,構建本地結構化數據庫,通過 RAG 技術實現智能檢索,支持向量化處理和來源標注預置智能體: 內置 300+ 行業助手(如翻譯、編程、營銷),支持自定義提示詞(Prompt)創建專屬 AI 應用多模態處理: 支持文本生成、圖像生成(集成硅基流動等平臺)、代碼高亮、Markdown 渲染及文件格式轉換
下面我們看看如何搭建
下載安裝
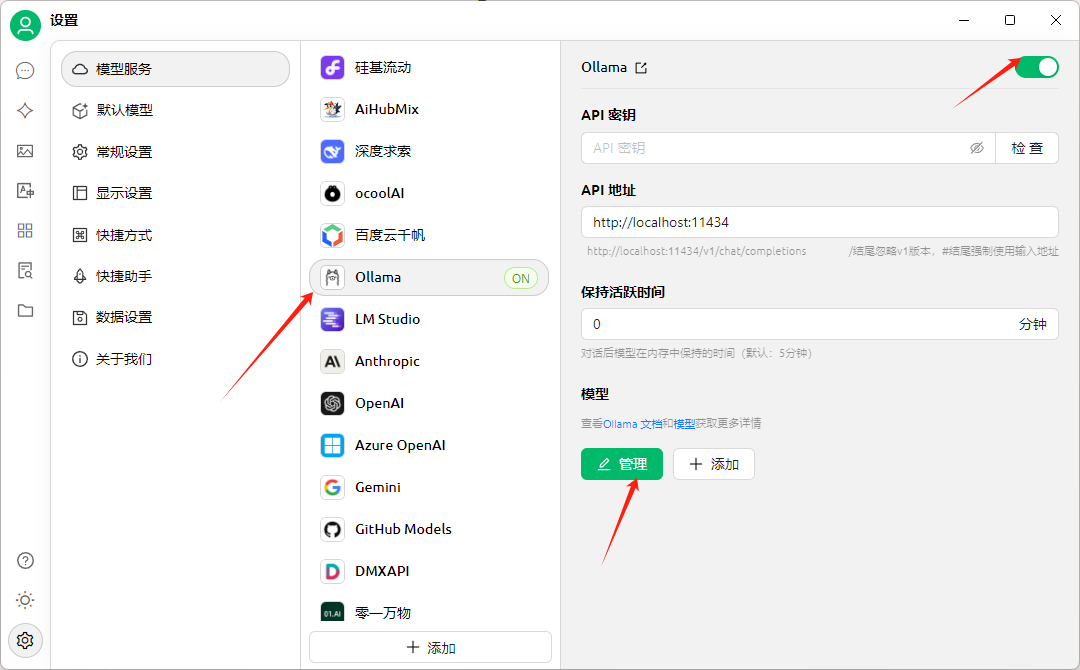
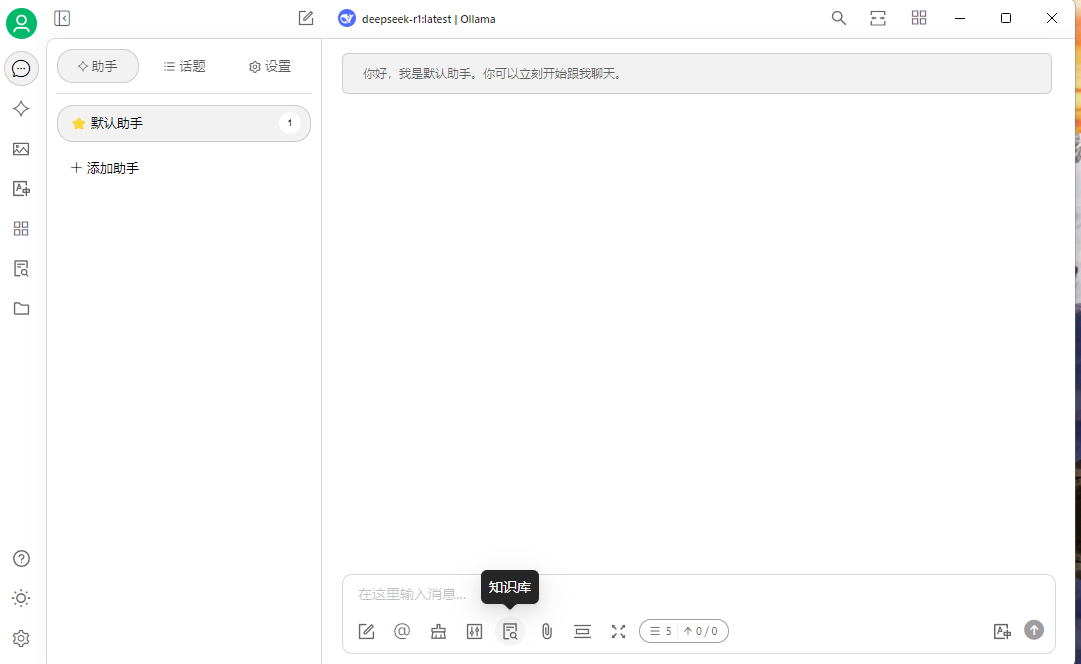
設置圖標選擇模型服務,選擇本地的 ollama 服務,
模型配置
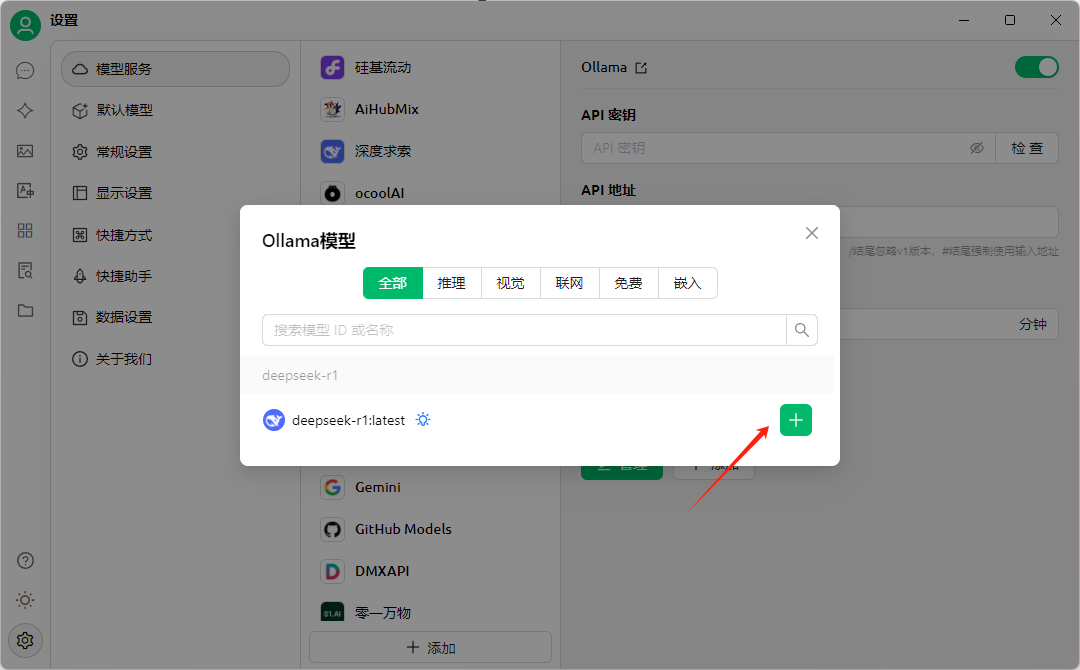
選擇我們之前 pull 的模型
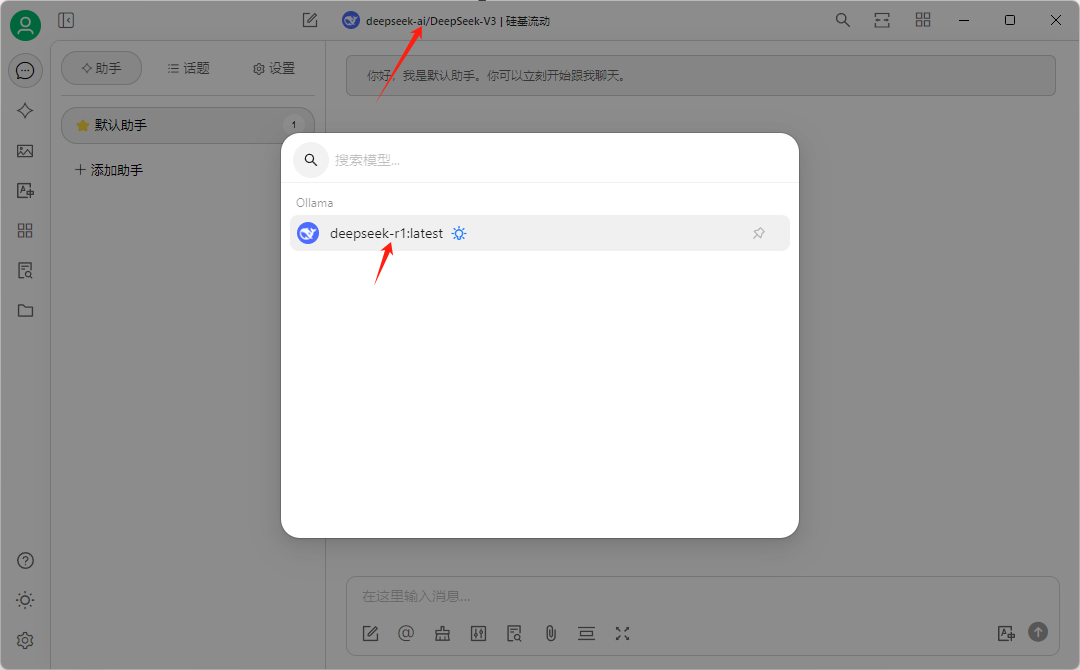
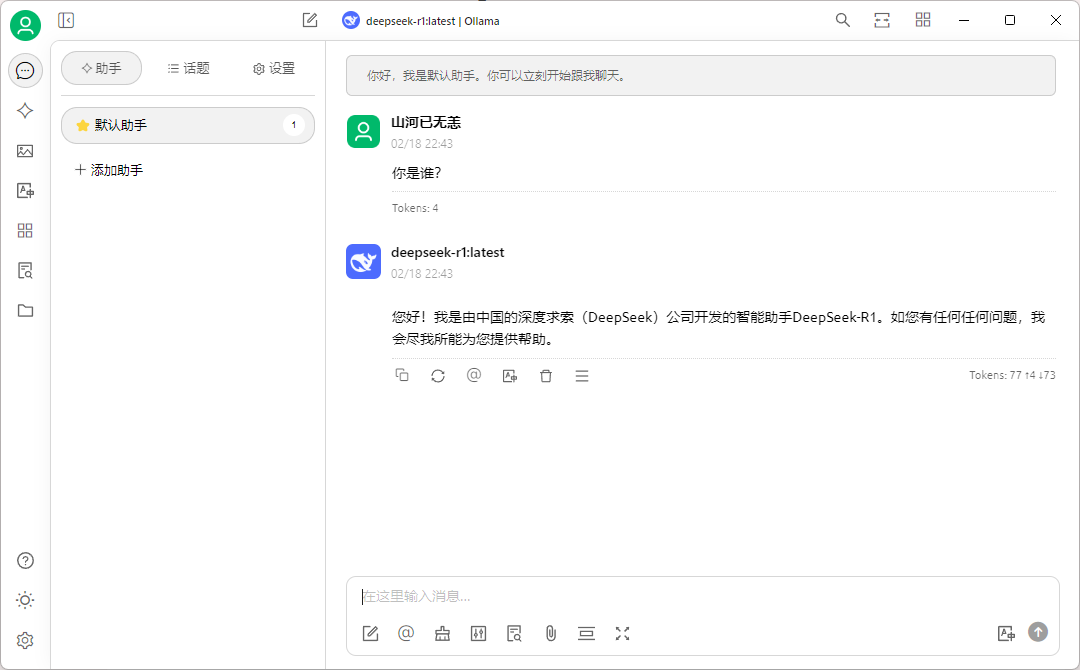
然后在默認助手中作簡單測試
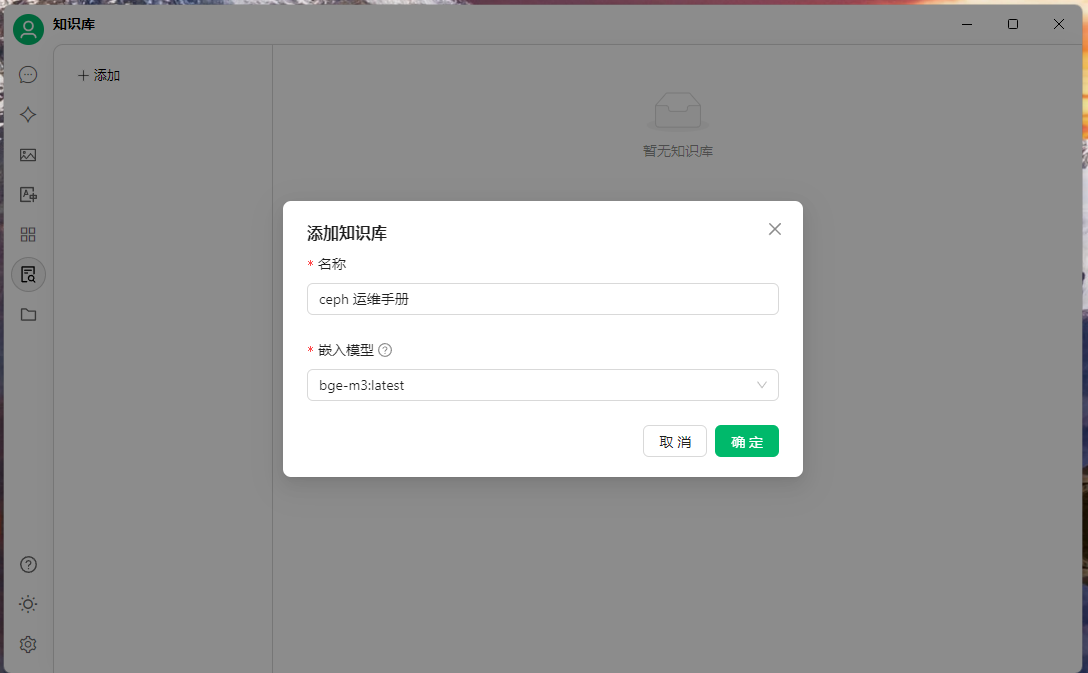
選擇知識庫圖標,創建知識庫,添加嵌入模型
然后上傳要創建知識庫的文件,可以通過搜索知識庫簡單測試
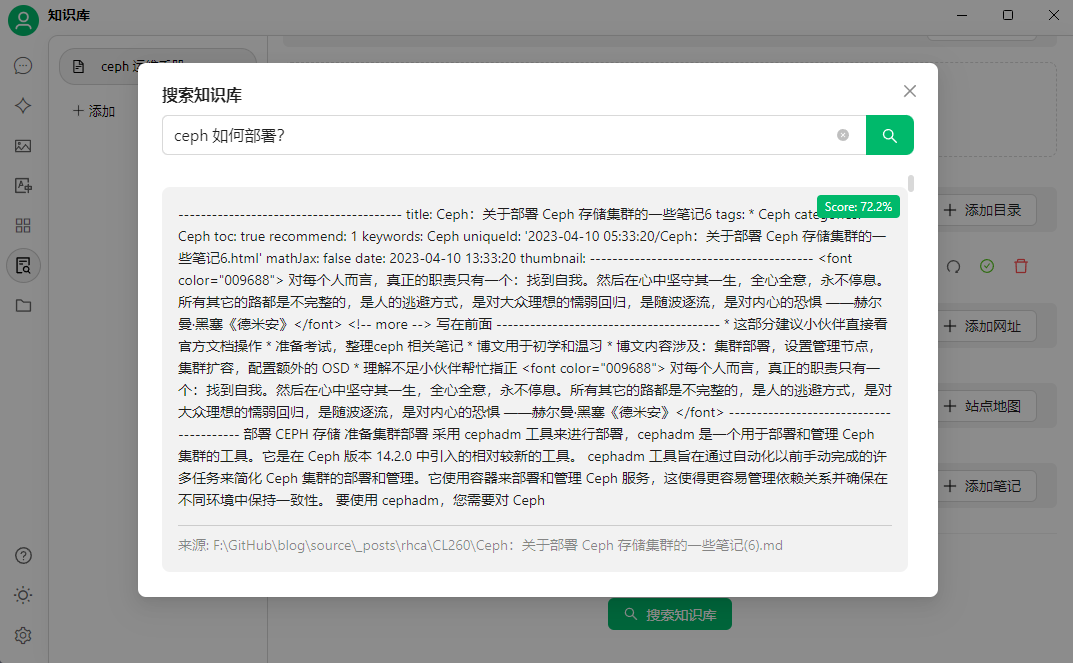
然后就可以提問了,選擇一開始添加的本地模型,提問的時候選擇知識庫
文檔中的內容做簡單問答測試
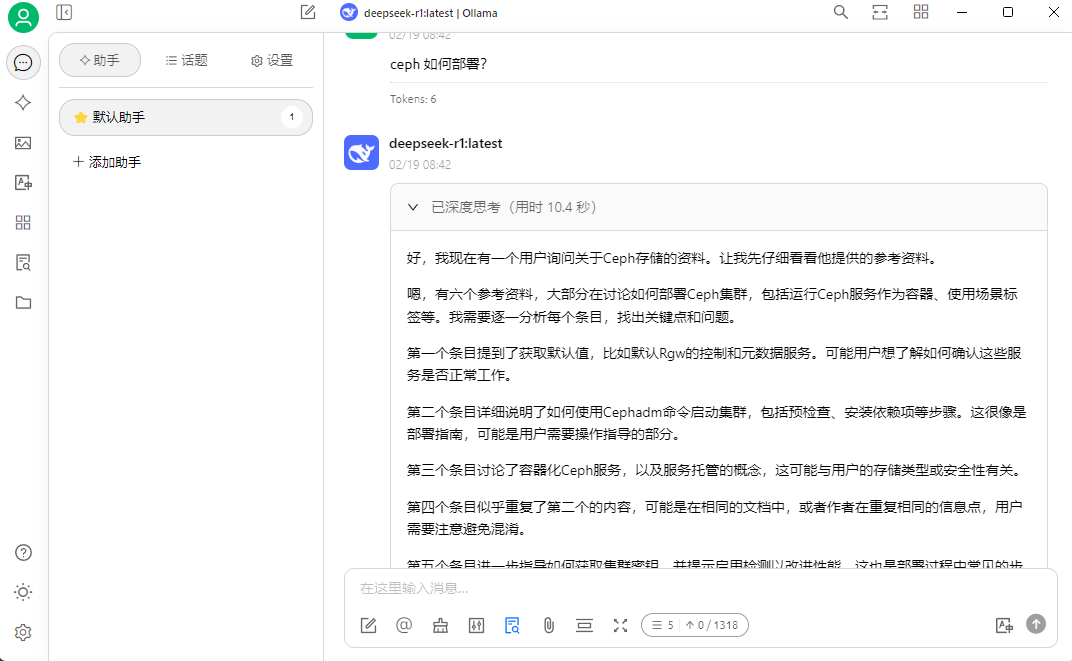
引用知識庫中的內容
AnythingLLM + DeepSeek
AnythingLLM 同樣是一個全棧應用程序,可以使用現成的商業大語言模型或流行的開源大語言模型,再結合向量數據庫解決方案構建一個私有ChatGPT,不再受制于人:您可以本地運行,也可以遠程托管,并能夠與您提供的任何文檔智能聊天。
官網下載地址: https://anythingllm.com/
文檔地址: https://docs.anythingllm.com/
項目地址: https://github.com/Mintplex-Labs/anything-llm/blob/master/locales/README.zh-CN.md
下載安裝包:
直接安裝即可,安裝完后會有如下的界面

選擇本地的模型
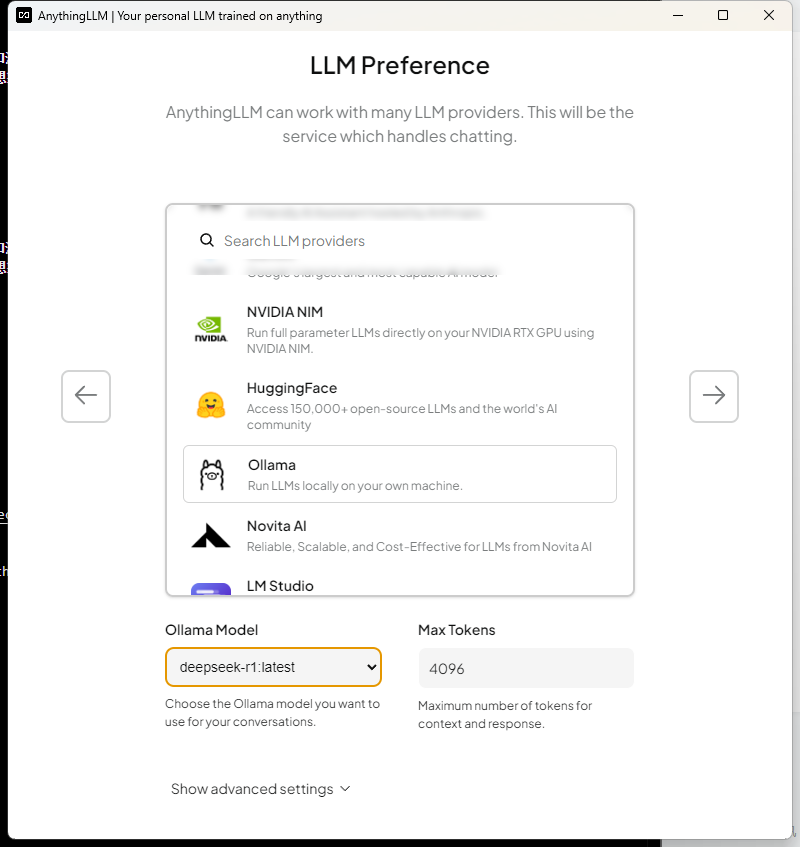
之后一直下一步,創建工作區
然后在新工作區,選擇下面的箭頭
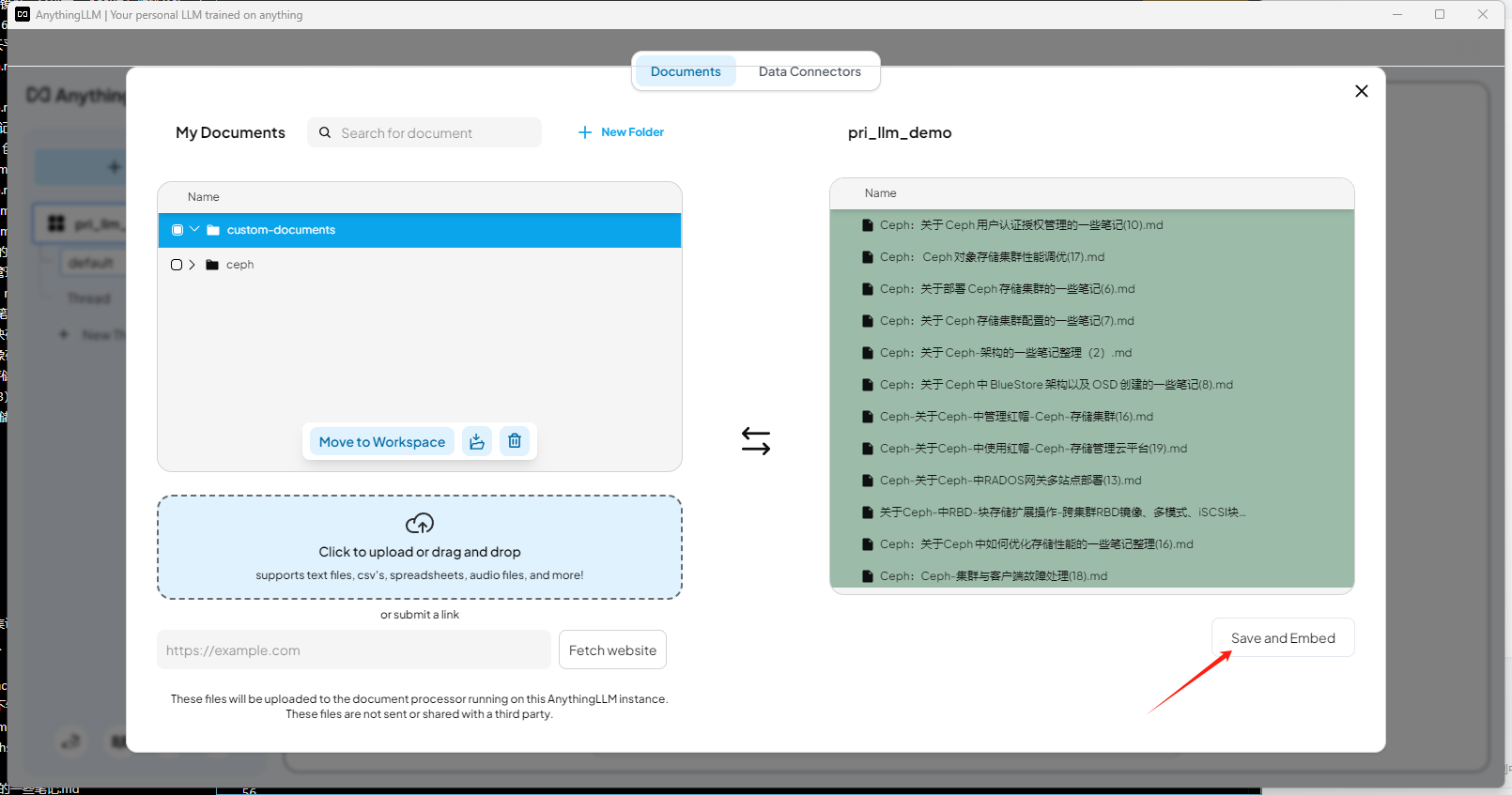
導入知識庫文檔
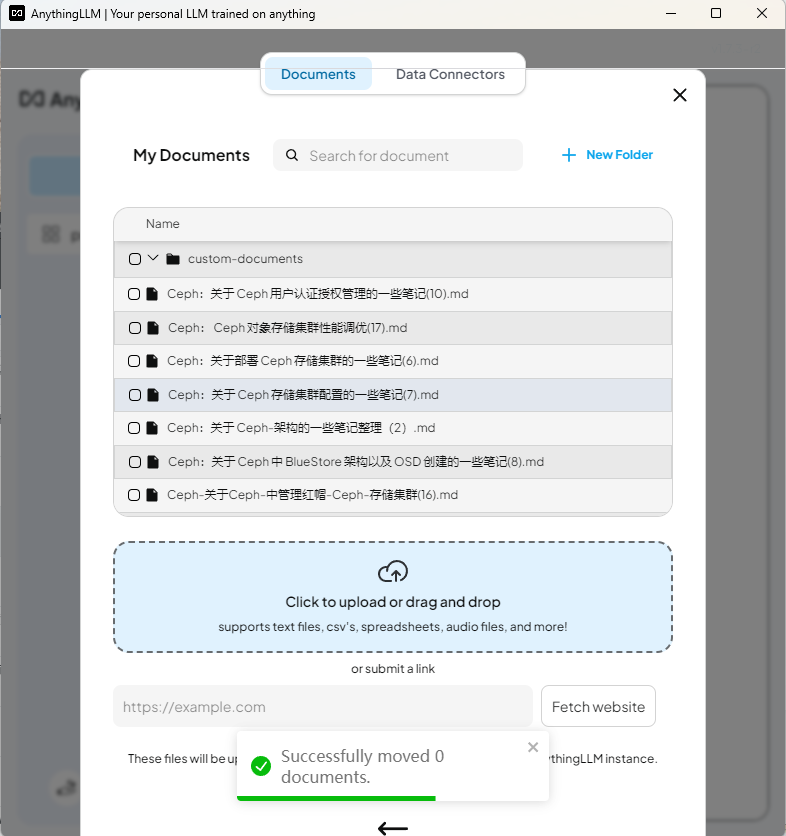
添加到工作區
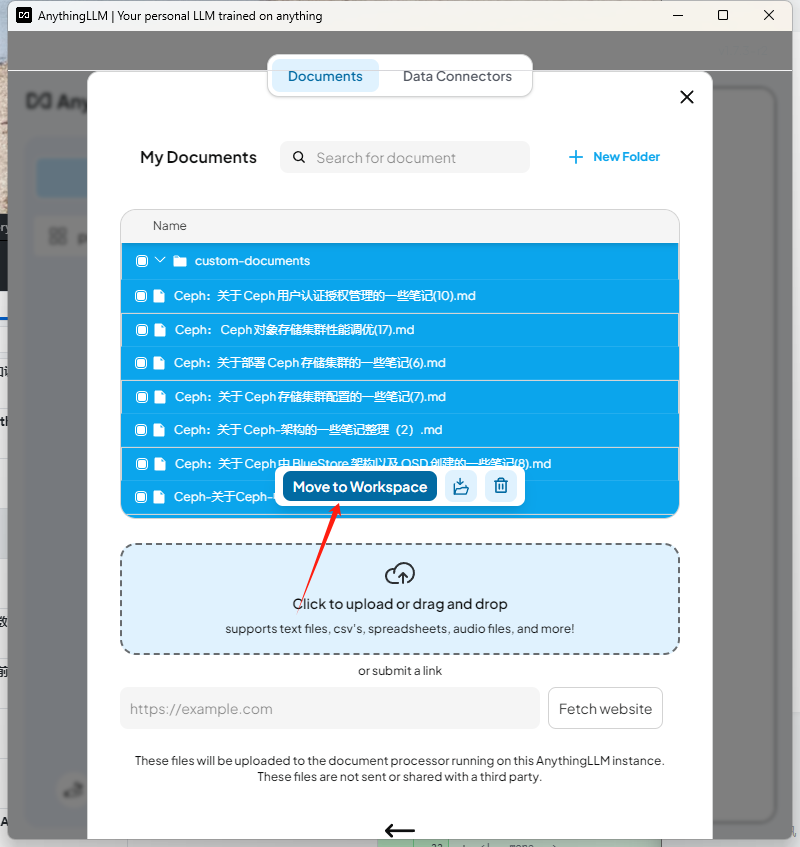
選擇啟用
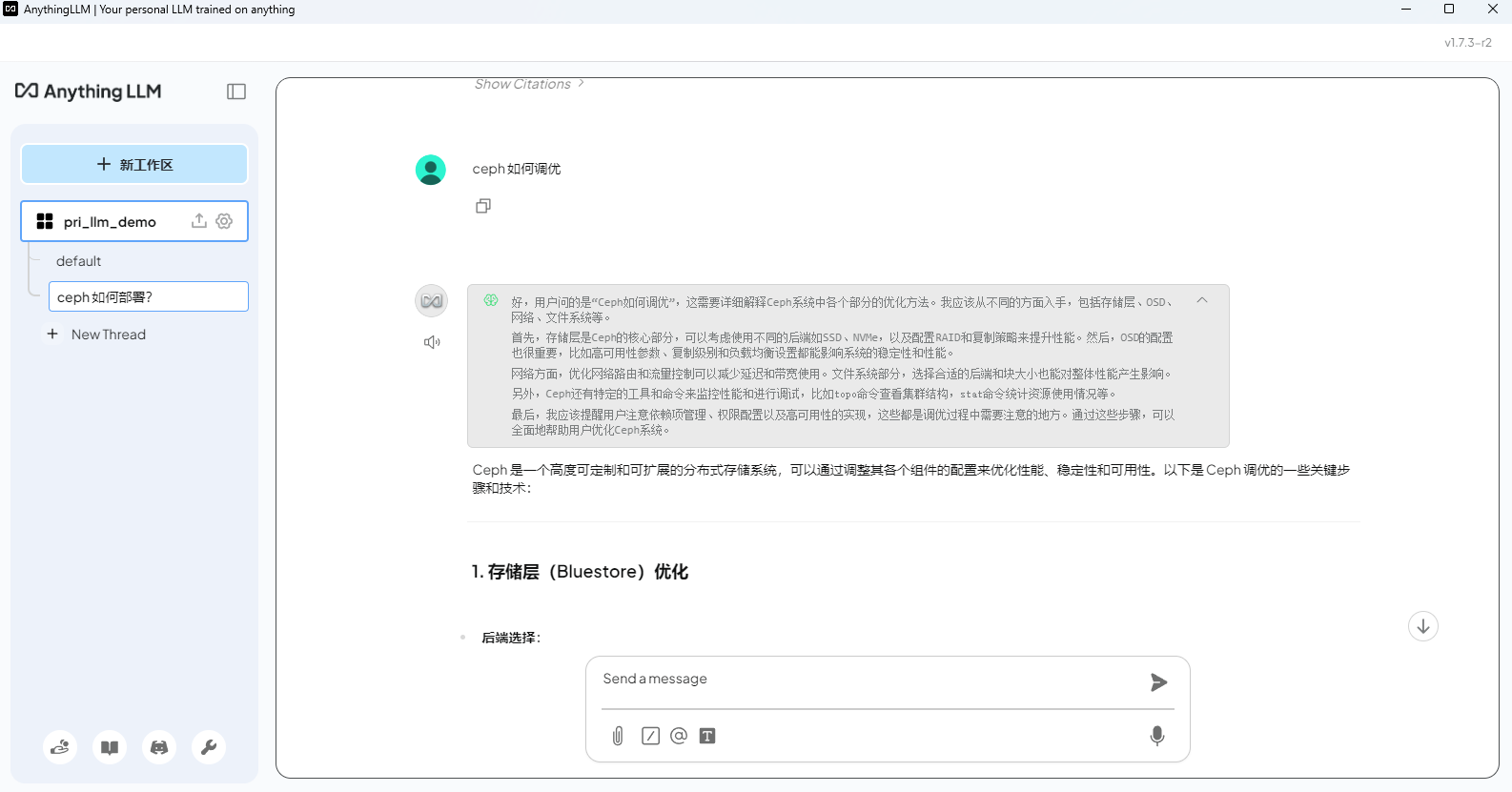
問一個知識庫相關的問題測試
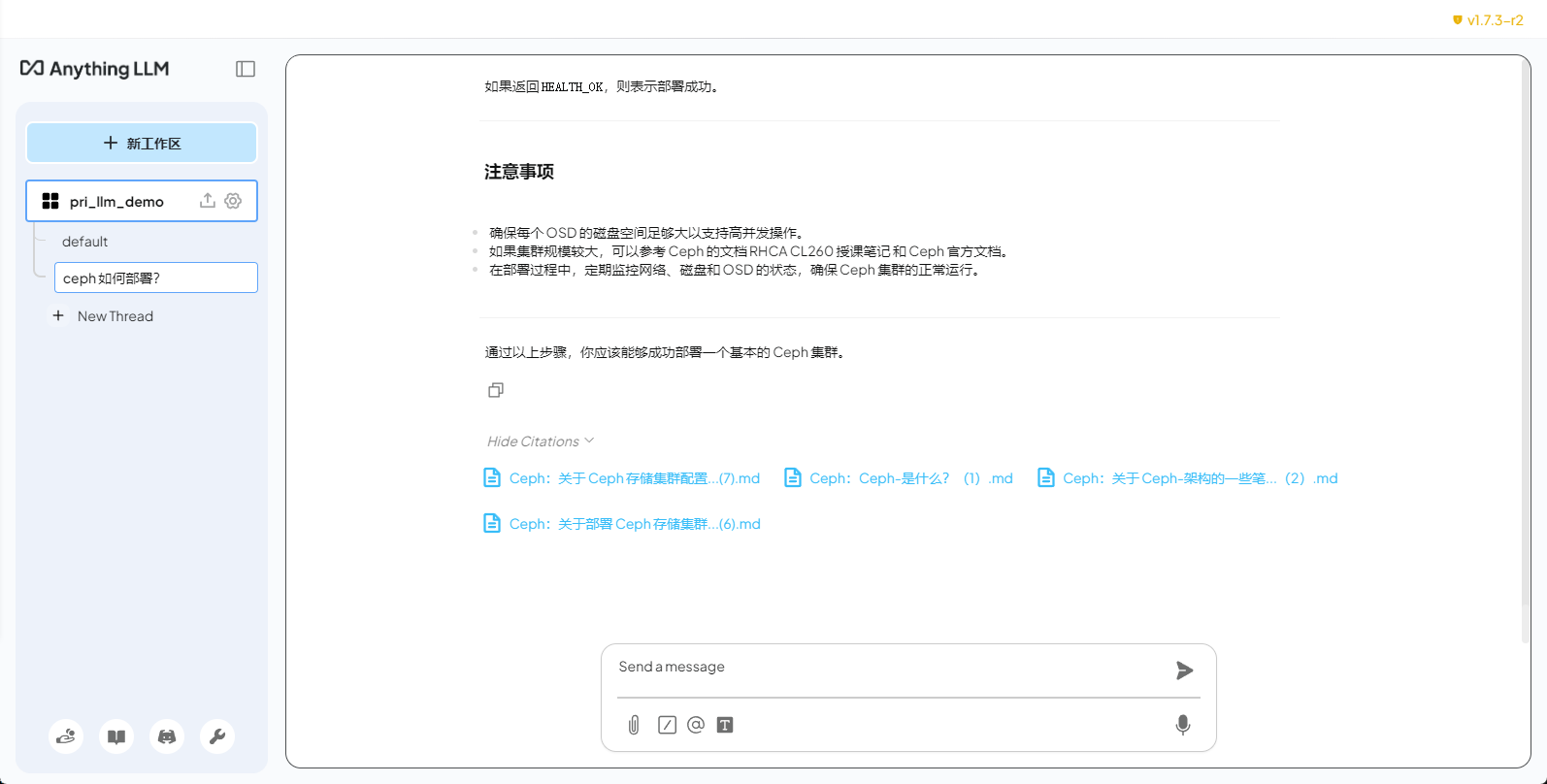
最下面會列出引用的文檔
LLM 相關配置可以在設置中設置
AnythingLLM 和 Cherry Studio 都是客戶端,所以 ollama 的推理模型直接設置 本地回環地址就可以
整體來看,Ragflow 相對專業一點,其次是 Dify ,Cherry Studio ,AnythingLLM ,但是前兩個相對部署較重,后兩個客戶端,可以直接客戶端部署。
博文部分內容參考
? 文中涉及參考鏈接內容版權歸原作者所有,如有侵權請告知 😃
https://ragflow.io
https://dify.ai/zh
https://cherry-ai.com/
https://anythingllm.com/
? 2018-至今 liruilonger@gmail.com, 保持署名-非商用-相同方式共享(CC BY-NC-SA 4.0)

)




)












二刷第三十七天 | *300. 最長遞增子序列、674. 最長連續遞增序列、*718. 最長重復子數組)