本文來源公眾號“程序員學長”,僅用于學術分享,侵權刪,干貨滿滿。
原文鏈接:PyCaret,一個超強的 python 庫
今天給大家分享一個超強的 python 庫,PyCaret。
https://github.com/pycaret/pycaret
簡介
PyCaret 是一個開源的、低代碼的 Python 機器學習庫,可自動化機器學習工作流程。
它是一種端到端的機器學習和模型管理工具,可以成倍地加快實驗周期并提高你的工作效率。
與其他開源機器學習庫相比,PyCaret 是一個替代的低代碼庫,可以用幾行代碼替換數百行代碼。這使得實驗的速度和效率呈指數級增長。
PyCaret 本質上是多個機器學習庫和框架的 Python 包裝器,例如 scikit-learn、XGBoost、LightGBM、CatBoost、Optuna、Hyperopt、Ray 等。
PyCaret 的設計和簡單性受到了公民數據科學家這一新興角色的啟發,該術語由 Gartner 首次使用。
公民數據科學家是高級用戶,他們可以執行簡單和中等復雜的分析任務,而這些任務以前需要更多的技術專業知識。
初體驗
安裝
你可以使用 Python 的 pip 包管理器安裝 PyCaret。
pip?install?pycaret快速入門
PyCaret 具有?「函數式API和面向對象的API」兩種形式。
函數式API
#?Classification?Functional?API?Example#?loading?sample?dataset
from?pycaret.datasets?import?get_data
data?=?get_data('juice')#?init?setup
from?pycaret.classification?import?*
s?=?setup(data,?target?=?'Purchase',?session_id?=?123)#?model?training?and?selection
best?=?compare_models()#?evaluate?trained?model
evaluate_model(best)#?predict?on?hold-out/test?set
pred_holdout?=?predict_model(best)#?predict?on?new?data
new_data?=?data.copy().drop('Purchase',?axis?=?1)
predictions?=?predict_model(best,?data?=?new_data)#?save?model
save_model(best,?'best_pipeline')面向對象的API
#?Classification?OOP?API?Example#?loading?sample?dataset
from?pycaret.datasets?import?get_data
data?=?get_data('juice')#?init?setup
from?pycaret.classification?import?ClassificationExperiment
s?=?ClassificationExperiment()
s.setup(data,?target?=?'Purchase',?session_id?=?123)#?model?training?and?selection
best?=?s.compare_models()#?evaluate?trained?model
s.evaluate_model(best)#?predict?on?hold-out/test?set
pred_holdout?=?s.predict_model(best)#?predict?on?new?data
new_data?=?data.copy().drop('Purchase',?axis?=?1)
predictions?=?s.predict_model(best,?data?=?new_data)#?save?model
s.save_model(best,?'best_pipeline')使用面向對象API實現時間序列分析
這里使用的數據集是 pycaret 自帶的數據集 airline。
#?load?dataset
from?pycaret.datasets?import?get_data
data?=?get_data('airline')
data ?接著看:
?接著看:
#?init?setup
from?pycaret.time_series?import?TSForecastingExperiment
s?=?TSForecastingExperiment()
s.setup(data,fh?=?3,session_id?=?123,n_jobs=1)
best=s.compare_models()如下圖所示,可以看到 STLF 模型的效果最好,下面我們來看一下預測的效果。

s.plot_model(best,plot?=?'forecast')

#?forecast?plot?36?days?out?in?future
s.plot_model(best,?plot?=?'forecast',?data_kwargs?=?{'fh'?:?36})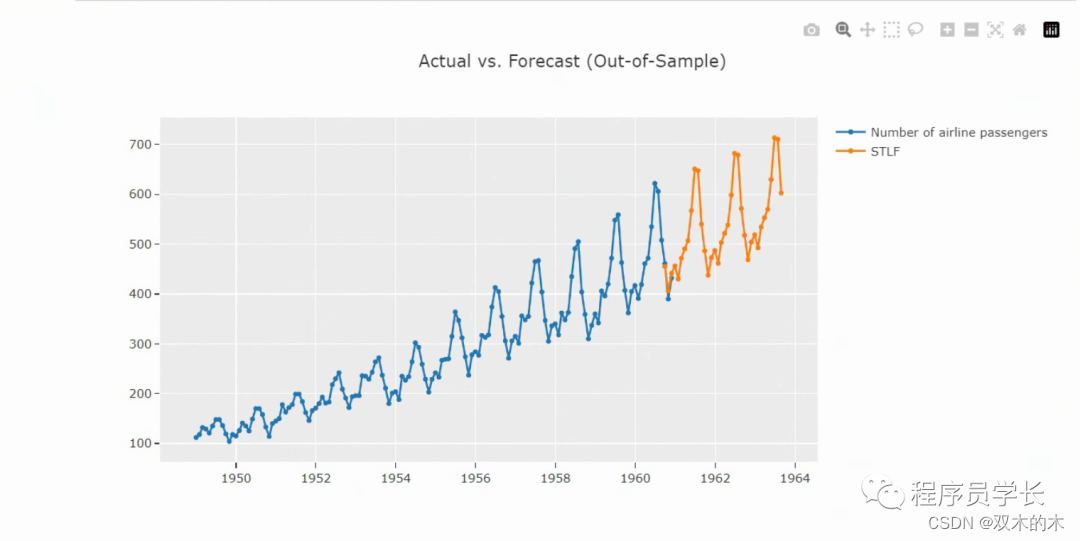
在 GPU 上訓練
要想在 GPU 上訓練模型,只需在 setup 函數中傳遞 use_gpu = True 即可。
API 的使用沒有發生變化;但是,在某些情況下,必須安裝額外的庫。
你可以在 GPU 上訓練以下模型:
-
Extreme Gradient Boosting
-
CatBoost
-
Logistic 回歸、嶺分類器、隨機森林、K 鄰域分類器、K 鄰域回歸器、支持向量機、線性回歸、嶺回歸、套索回歸。
-
Light Gradient Boosting Machine
THE END !
文章結束,感謝閱讀。您的點贊,收藏,評論是我繼續更新的動力。大家有推薦的公眾號可以評論區留言,共同學習,一起進步。
![[論文筆記]RAPTOR: RECURSIVE ABSTRACTIVE PROCESSING FOR TREE-ORGANIZED RETRIEVAL](http://pic.xiahunao.cn/[論文筆記]RAPTOR: RECURSIVE ABSTRACTIVE PROCESSING FOR TREE-ORGANIZED RETRIEVAL)










)







