前沿重器
欄目主要給大家分享各種大廠、頂會的論文和分享,從中抽取關鍵精華的部分和大家分享,和大家一起把握前沿技術。具體介紹:倉頡專項:飛機大炮我都會,利器心法我還有。(算起來,專項啟動已經是20年的事了!)
2023年文章合集發布了!在這里:又添十萬字-CS的陋室2023年文章合集來襲
往期回顧
前沿重器[48] | 聊聊搜索系統1:開篇語
前沿重器[49] | 聊聊搜索系統2:常見架構
前沿重器[50] | 聊聊搜索系統3:文檔內容處理
前沿重器[51] | 聊聊搜索系統4:query理解
前沿重器[52] | 聊聊搜索系統5:召回:檢索、粗排、多路召回
RAG在整個大模型技術棧里的重要性毋庸置疑,而在RAG中,除了大模型之外,另一個不可或缺的部分,就是搜索系統,大模型的正確、穩定、可控生成,離不開精準可靠的搜索系統,大量的實驗中都有發現,在搜索系統足夠準確的前提下,大模型的犯錯情況會驟然下降,因此,更全面、系統地了解搜索系統將很重要。
聽讀者建議,像之前的對話系統一樣(前沿重器[21-25] | 合集:兩萬字聊對話系統),我也會拆開揉碎地給大家講解搜索系統目前業界比較常用的架構、技術方案,目前的計劃是分為這幾個模塊講解:
開篇語(前沿重器[48] | 聊聊搜索系統1:開篇語):給大家簡單介紹一下搜索系統的概況,以及現在大家比較關注在大模型領域的發展情況。
搜索系統的常見架構(前沿重器[49] | 聊聊搜索系統2:常見架構):經過多代人的探索,目前探索出相對成熟可靠,適配多個場景、人力、生產迭代等因素的綜合性方案。
文檔內容處理(前沿重器[50] | 聊聊搜索系統3:文檔內容處理):對原始文檔內容、知識的多種處理方案。
Query理解(前沿重器[51] | 聊聊搜索系統4:query理解):對query內容進行解析,方便后續檢索使用。
召回:檢索、粗排、多路召回(前沿重器[52] | 聊聊搜索系統5:召回:檢索、粗排、多路召回):使用query理解的結果,從海量數據中找到所需的信息。
精排(本期):對檢索的內容進行進一步的精篩,提升返回的準確性。
其他搜索的附加模塊:補充說明一些和搜索有關的模塊。
本期的內容是精排,即對召回的內容進行進一步篩選,從而得到更好的結果。
目錄:
精排的意義
精排需要考慮的因素
精排方案設計的框架
案例分析
補充講重排
大模型精排
小結
這個可以說是最百花齊放的模塊了,在實踐過程中,搜索發展到后期這部分的花活就會變得異常多,無論是論文還是各種分享,但我發現論文和各種分享多半是從自身面對的場景出發的,因地制宜的成分很多,因此這次我換個說法,先從思路下手,先把這部分的整體邏輯講明白,然后再用一些案例來進行講解。
精排的意義
首先,還是要重申一下精排的概念。所謂的精排,在整個搜索里,核心功能是在獲得召回結果的基礎上,整理出精準的結果。這里有一個前提,那就是在召回結果的基礎上,沒有召回的精排是沒有意義的。
這里就要引出一個問題,就是兩者會有什么區別。這個問題談清楚了,大家就會明白精排在整個搜索過程中的作用。
最直接的,召回和精排的對象是不一樣的。召回面對的是整個數據庫里的所有數據,而精排面對的是召回已經找回來的少量數據,這是兩者處理思路不同的核心原因。
召回是大海撈針,精排是百里挑一。召回的過程類似篩簡歷,用一些比較粗暴的方式快速過濾很多“一定不對的內容”,從而得到相對不那么離譜的答案。類似向量召回之類的,要通過把句子向量化才能進行快速匹配和篩選,其本質就是在空間中以query為中心畫個圈,只把圈內的內容拿出來;精排則像是面試,對幾個簡歷還算不錯的人進行進一步的篩選,這一步因為是進行深入面試和理解,盡管精排的準確性高但是速度慢,所以需要召回來進行配合。
精排的性質是優中選優。繼續從對象觸發,精排面對的是召回已經找出的數據,這些數據從某個角度而言,已經被判為和query存在一定關系,但是隨著物料的增加,“有一點關系”并不足夠滿足用戶需求,所以要進行更精確的比對,因此此處要做的是進一步提升召回物料之間的差距。
另外,精排的綜合性要求更高。召回層是可以基于很多不同的依據來分別做的,而精排則不然,需要盡可能把多個因素放一起綜合地來做。
精排需要考慮的因素
前文有提到,精排的綜合性要求很高,我們就需要考慮很多因素,相比召回,我們在這一步就要求考慮的很全面,現在我先把需要考慮的因素用比較籠統的方式列舉出來,然后我們再逐個剖析他們如何表征以及怎么放入模型中。
和query的相關性。這點毫無疑問應該排在前列,畢竟用戶進行搜索的核心目標就是要解決query描述的問題,不相關的話搜索無從談起。
物料質量。在物料已經比較多的情況下,就要開始考慮把質量比較高的物料放到前面。
用戶偏好。在有用戶信息的搜索系統下,或者因為業務需求,就需要將結合考慮到用戶的偏好,比較典型的像音樂、電商等搜索場景,對個性化的要求就會比較高。
和query的相關性,主要可以從這幾個角度來去看。
語義相似度。這個大家應該都比較容易想到,早年比較流行的方式就是類似ESIM之類的方案來做(前沿重器[9] | ESIM:語義相似度領域小模型的尊嚴),效果確實比非交互的相似度效果好,后續基于bert的句子對相似度也是不錯的,而且訓練的模式會比較簡單,直接用‘q-d-label’的模式就能訓練一個還可以的結果,在后續的版本中,迭代到learning to rank方案也比較絲滑。
用戶行為體現的相似度。這個思路和推薦中用的點擊率預估是非常相似的,用戶搜Q點D,本質就是對內容一定程度的認可,甚至是更為直接的相似度信息,畢竟用戶是對這個結果認可的。當然了,有些內容,即使不相關用戶也可能點進去,例如某些獵奇或者不合規的內容。
至于物料的質量,這個可以從兩個角度出發。
物料本身的質量。如話題、文案的合規性、豐富度、新鮮度等,這個會比較簡單。
用戶群體對物料的評價。如點擊率、單位時間點擊量、命中query豐富度、停留時間、點擊離開率等,這些是基于用戶行為對物料的評價。
最后就是用戶偏好,應該也是后期需要花費時間比較多的一部分。
多個維度的協同過濾的方式。例如搜索這個query的用戶更傾向于點擊的內容、某個畫像的用戶更傾向于點擊的內容(群體特征)、該用戶平時的點擊偏好(個人直接特征)等。
盡管上述的因素在生產實踐中并不是按照這個來應用的,但因為特征來源廣泛,往往還充斥著很多無效的信息。我所提出的上述思路更多是為了讓大家更加結構化地理解整個精排內部所需要的信息,不容易錯漏,相比一個一個比對,根據特定結構化思維來整理效率會更高。
當然,這只是我們常說的考慮因素,而在實踐過程,我們需要把上面考慮的因素,結合信息來源和使用方法,構造成適合應用的模式,即特征,從而應用在精排模型中,于是我們就能推導出精排方案的框架。
精排方案的框架
常規的算法建模,不外乎要考慮的就是三點:數據、特征、模型。早期數據可以通過語義相似度或者是人工標注數據快速構造baseline,后續則逐步切換為在線用戶的行為數據,此處不贅述,本章重點講解后面兩種。
在前面一章節講到了需要考慮的因素,在實際應用情況,我們會把內容根據信息來源以及后續使用方法進行有機組合構建。
一般地,從數據來源來看,會把所有特征按照4個維度來構造。
Query側:通過query理解來獲取,常見的意圖、實體包括某些關鍵詞等。
Doc側:即文檔信息,一般通過內容理解,即在文檔內容處理模塊處理構造(前沿重器[50] | 聊聊搜索系統3:文檔內容處理),這里包括一些類似物料質量、文檔摘要等的內容。
用戶側:用戶偏好信息,這個一般是在用戶出現行為的過程就能記錄,在推理過程一般只需要讀取。
交互特征:Query和Doc之間的匹配度特征,注意這里是一些小特征,如某些計算得到的相似度,語義相似度、字面相似度等,還有一些統計得到的特征,如如歷史的曝光點擊率等,再者還有一些召回層帶下來的信息,多種粗排的相似度特征,召回鏈路及其個數等。
有了這些特征就可以開始構造模型把他們融合起來了。合并的鏈路我喜歡分為3個流派。
規則加分模式。在前期數據不足不好訓練的情況下,直接對幾個特征用規則進行簡單組合即可使用,別小看這個方法,這個方案在很長一段時間都可以拿來使用。
機器學習組合模式。通過機器學習模型,例如比較有名的xgboost,可以快速把這些特征進行組合構造。
深度學習及其變體。因為特別的特征需要用特別的結構來吸納,所以出現了多種魔改的特征,但效果確實在對應場景有所提升。
于是,便有了我們所期待的模型。
這便是我想聊的框架,數據、特征、模型的基礎框架,構成搜索精排在實踐過程的重要組成部分。在這個框架下,我們可以結合搜索當前的狀態以及目前可獲得的資源,來靈活設計自己目前需要的方案。
數據是模型學習的基礎,是特征的原料。借助數據能發現可解釋的規律,各種突出區分度的特征則是從數據篩選、分析而來。
特征是數據依據的表達,是query和doc匹配的信息來源。只有構造合理的特征,模型才會生效,所以他是數據依據的表達,同時q和d所謂的是否匹配,
模型是數據的通用表示,是特征有機組合完成推理的橋梁。
案例分析
相比列舉方法,案例在這里可能會更合適,通過案例分析,尤其對他們面對的問題分析,讓大家進一步理解“因地制宜”的重要性。
美團
美團的分享一直都維持的很好,在搜索方面也涌現了很多優秀的文章,具體可以在這里翻閱:https://www.zhihu.com/org/mei-tuan-dian-ping-ji-shu-tuan-dui。本次要講的精排,并非作為一個專題來講,而是分布在很多文章內部,通過多篇文章的閱讀才梳理出內部的一些細節。涉及這些關鍵文章:
搜索廣告召回技術在美團的實踐:https://zhuanlan.zhihu.com/p/707169501
大眾點評內容搜索算法優化的探索與實踐:https://zhuanlan.zhihu.com/p/688404734
多業務建模在美團搜索排序中的實踐:https://zhuanlan.zhihu.com/p/388211657
Transformer 在美團搜索排序中的實踐:https://zhuanlan.zhihu.com/p/131590390
美團搜索毫無疑問是一個非常具有特點的場景,我的理解結合眾多技術文章的分析來看,美團搜索在場景上,具有如下的特點:
特殊的多業務場景。美食、電影、機票、酒店等個典型場景聚合,顯然這種聚合和一般地百度開放域搜索還不太一樣,業務場景各異,且各自之間存在高低頻的差異,再者不同業務還可能有不同的子目標。
和電商類似,用戶在輸入習慣上,可能有大量的內容聚焦在特定的專有名詞或者tag上,如“燒烤”、“麥當勞”等。
檢索需要很大程度以來用戶畫像信息。典型的例子——地點,美團是一個高度依賴地點的場景,美團的幾乎所有場景在用戶檢索時都很大程度依賴地點信息,用戶搜索的“燒烤”就需要很大程度地參考地點信息,當然還有別的類似用戶個人偏好等也有結合實際場景的依賴,例如美食對口味有依賴等。
結合上面特點,美團也進行了大量的特別設計。
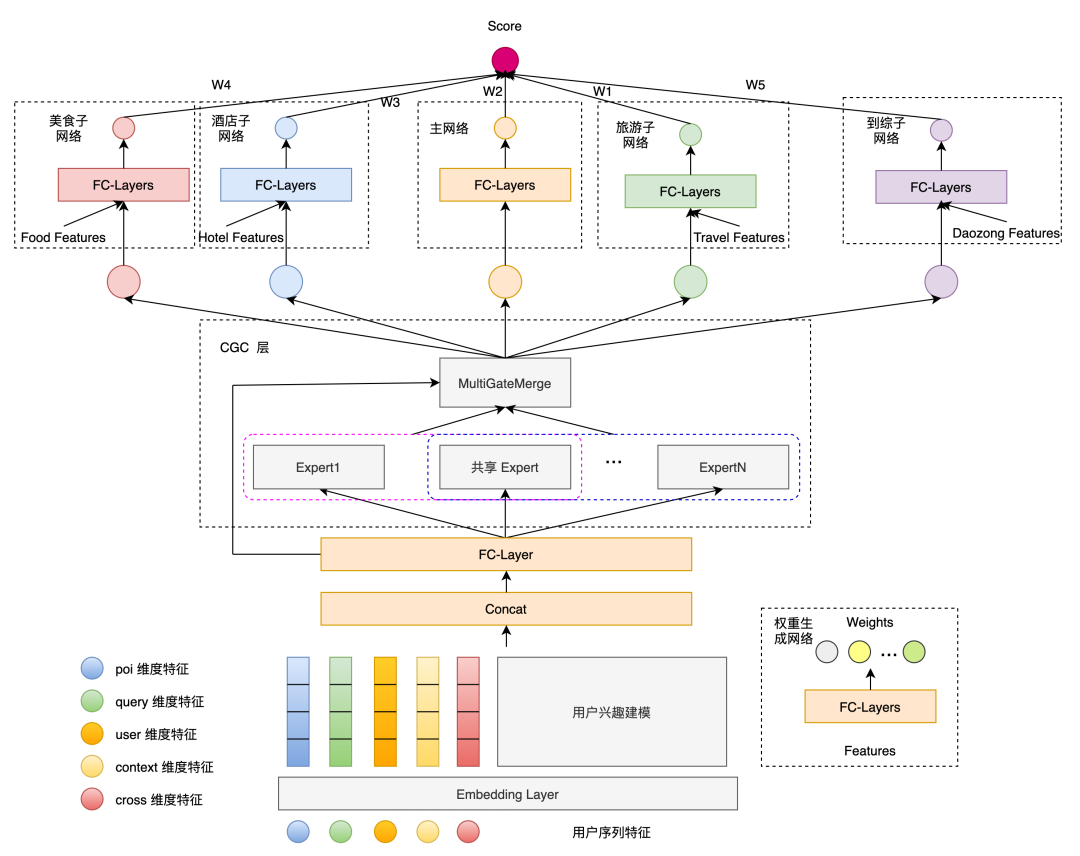
首先是特殊的多業務場景,構造了多業務配額模型(Multi-Business Quota Model,MQM)以確認綜合搜索下各個業務的配額,有利于他們的有機組合。下面提供了MQM-V2的結構圖,從圖中可以看到:
采用多目標的建模方式,以每一路召回是否被點擊為目標進行建模,并計算他們整體的聯合概率。
引入了按業務拆分的召回方式,同時這些召回方式在精排內存在一定冷啟動需求,所以構造了二維目標應對這種冷啟動問題。
此處的特征考慮了query、user、context、cross等特征。
用戶行為建模上,使用的是transformers結構。
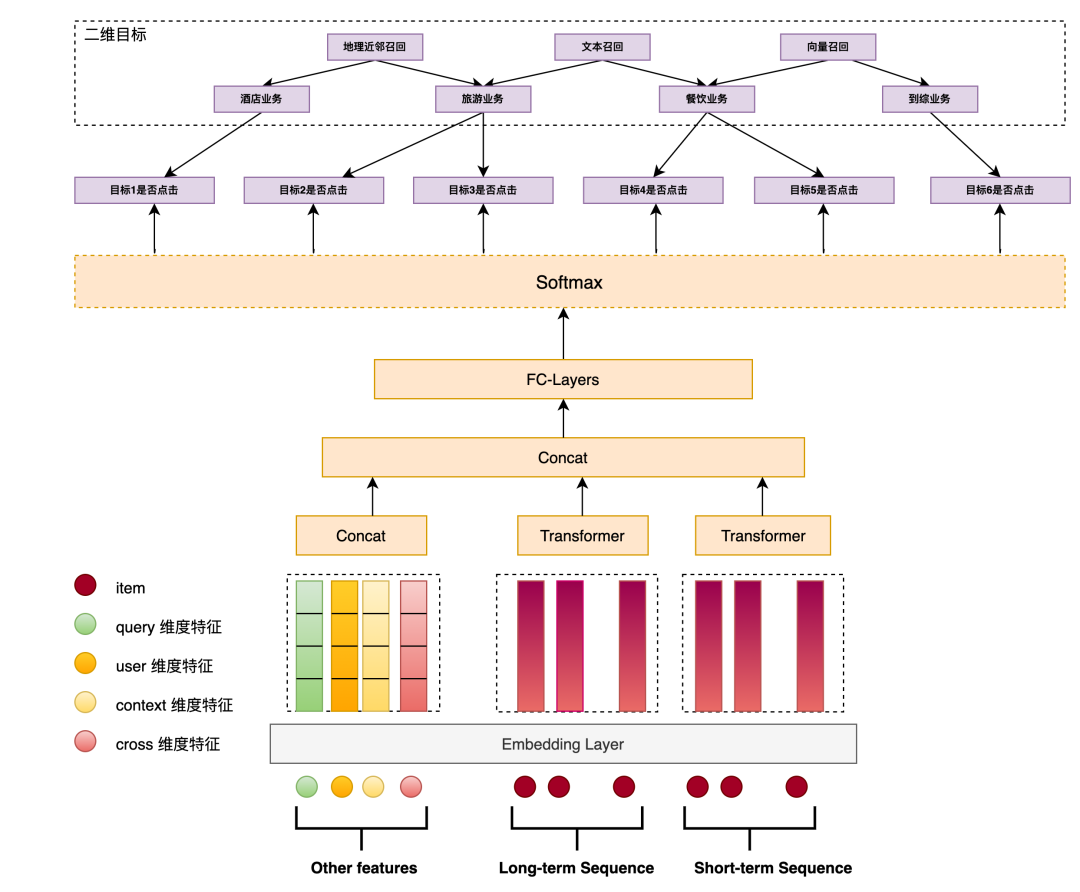
另外,多業務的精排模型(Multi-Business Network,MBN)也根據這個場景問題進行了特別的優化,下面給出的是精排模型V4的結構。可以看到有如下特點:
最下游子模塊各自建模,應對不同的業務需求,形成快速、獨立迭代能力。
此處特殊的是CGC層,這是一種多任務學習下的思路,來源于騰訊提出的PLE(Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations),考慮多個專家的模式應對不同場景的問題。(補充,在V3版本中有考慮過MMOE(Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts))(再補充,注意這篇文章的時間線是21年7月,即3年前)
值得注意的是,這里單獨把POI特征給單獨拿了出來做表征。
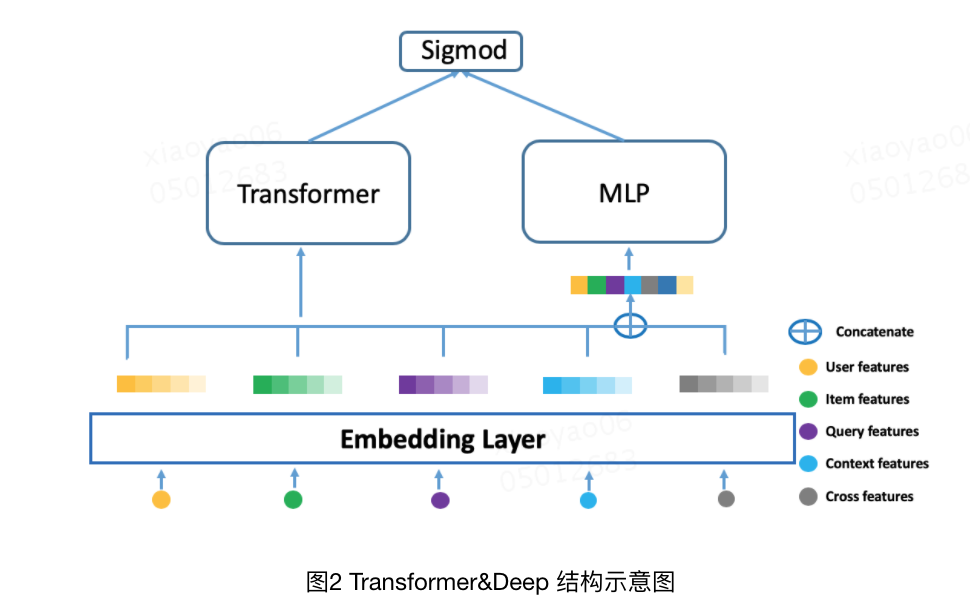
至于第二點,就是用戶比較喜歡輸入tag、專名的問題,其實在特征工程上就能發現,在query特征之外,還考慮到了大量其他的特征,尤其是user、poi等特征,特別地針對用戶興趣建模,也是有專門的設計。這里比較有特點的是考慮了transformers結構,此處給出一個美團曾經使用過的一種結構(Transformer&Deep),這篇一定程度參考了AutoInt(Automatic Feature Interaction Learning via Self-Attentive Neural Networks)
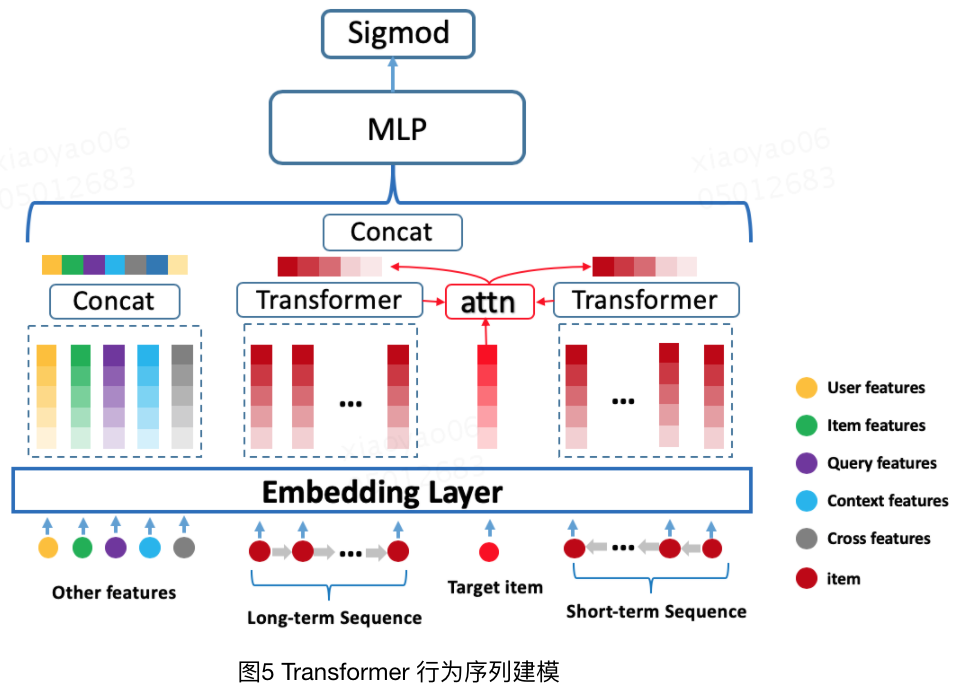
至于最后一點,就是用戶畫像信息的使用,這點承接第二點,從上述模型來看,美團在用戶信息表征上做了很多研究工作,尤其是用戶的個人行為,畢竟用戶行為很大程度反映了用戶的偏好,這里給出第三版本的用戶行為建模網絡。同時友好的是,作者在文章里講述了很多transformer應用的經驗。
實驗表明Transformer能更好地對用戶行為(item序列)進行有效建模,甚至由于相對簡單的Attention-pooling。
長序列下Transformer對比GRU優勢會更明顯,短序列盡管會縮小但仍舊優秀。
位置編碼對長序列有一定效果,但如果已經切分,則效果會被大幅度削弱。
Transformer編碼層不需要太多。
“頭”的個數影響不大。
知乎
相比美團,知乎更像是傳統意義的搜索,其主要的物料基本是用戶UGC的問答和博客文章,知乎在搜索精排上的迭代發展,也表現出這一特點,而且這個過程會更加純粹,對用戶的參考會更少一些,通過分析可以看到比較純粹的搜索精排優化,我們來看一起看看。https://mp.weixin.qq.com/s/DZZ_BCiNw0EZg7V0KvhXVw
我們直接從整個優化歷程來逐個分析。
GBDT。GBDT具備比較基礎的特征融合能力,也是比較高的baseline。這應該是很多搜索系統常見的基礎工作了。
TF-Ranking。考慮特征容量和技術迭代,以及多目標排序原因,而升級DNN,同時形成了比較規范的特征輸入模塊、特征轉化模塊和主網絡部分。
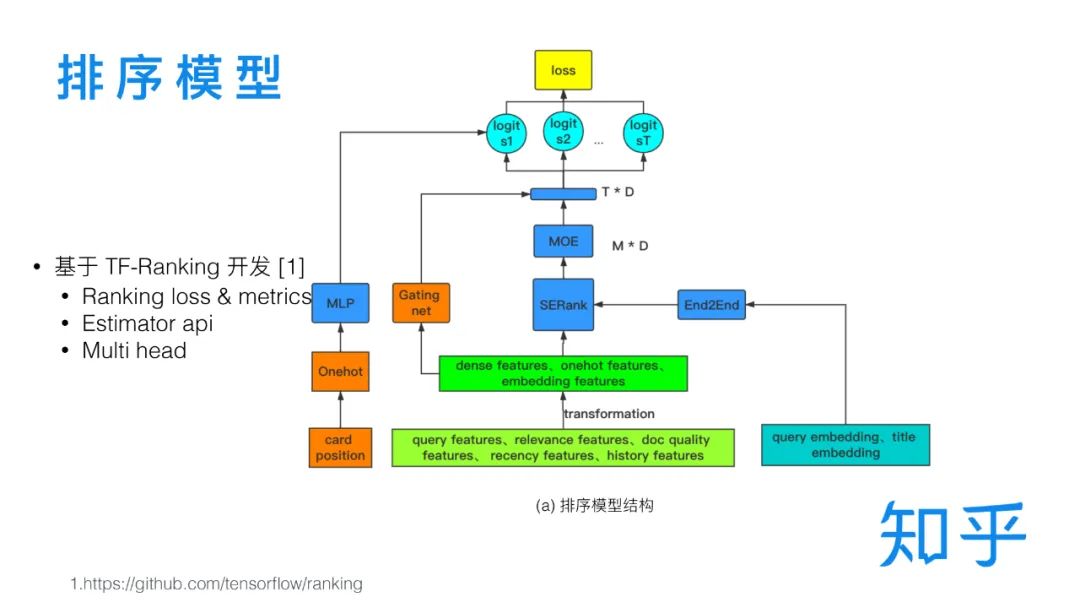
主網絡下,開始考慮多目標排序,權衡閱讀時長、點贊、收藏、分享、評論等反饋行為,簡單的考慮共享參數層+任務獨立參數層的結構來完成(文章中使用Hard sharing來表示)(類似前面美團提到的多業務配額模型),該方式需要通過實驗的方式來權衡多目標之間的關系,后面則優化升級為MMOE(Modeling task relationships in multi-task learning with multi-gate mixture-of-experts.),即多個expert加權的方式,權重任務間共享又讓任務之間存在獨立性。
考慮搜索中常見的位置偏差(用戶瀏覽行為是從上到下,因此靠前的更容易得到點擊),這方面推薦中也是有的,因此優化方案上也存在一些推薦系統的影子,此處考慮兩個策略:
降低頭部樣本權重,如硬編碼位置權重、自學習位置權重等。該方案收益不高。
通過一個獨立的 shallow tower 對 Position Bias 進行建模(Recommending what video to watch next: a multitask ranking system)。如前面的TF-Ranking的圖中提到的(Card position)部分。
學習排序問題。前面一再強調,精排是一個優中選優的對比問題,而這類型的問題,在學術界也有專門的研究,即learning to rank(LTR,之前我竟然還寫過點簡單的入門,很早之前了R&S[19] | 學習排序入門級概述),此處考慮使用List wise loss方案(綜合效果最優),在推理階段同樣要考慮到list wise,即在對單條打分的同時也要考慮其他被召回的文檔,此處使用的是SE Block的結構(Squeeze-and-excitation networks.)。
文本特征也是需要考慮的。比較簡單的方式就是先計算一個語義相似度然后把語義相似度當做特征放入模型,而比較詳細的方案就是直接把語義模型(如bert)放入到LTR中進行訓練,甚至是整體模型中進行訓練。
另外還有一些諸如個性化、GBDT編碼特征、生成對抗模型、在線學習等思路在文中也有簡單提到,不贅述。
補充講重排
重排是基于業務的一個特殊排序階段,和推薦類似,很多時候精排考慮的更多的還是query+用戶畫像和doc之間的匹配度,但在重排階段還需要考慮實際的業務需求,如多樣性、內容連貫性等,例如常規的相似度的排序結果在搜索里面很可能會出現同質化,此時就需要通過重排來一定程度實現更符合業務目標的排序。
這里提3個比較常用的重排策略(https://www.zhihu.com/question/462539445/answer/3079023802)。
全局排序——listwise策略,這個同樣是LTR的內容,采用諸如序列生成的方式,輸出一個用戶體驗最好的內容序列。
流量調控——在重排層,借助流量的調控,把熱門、新品等有利因素的物料往前傾斜。
打散策略——在一定窗口下,通過懲罰的方式把某些過于同質的內容往后調整。
當然,這里的策略都有提到一個點,這些重排策略或多或少都有提到目標,從目標出發解決問題才更直接,不能因為的新穎性或者自己新學到而迫切考慮使用。
大模型精排
有關大模型的精排部分,我是有在閱讀一些論文并進行一些常識。不過在實踐上收益其實并不高,初步結論是“用處不大沒必要硬用”,當然這個也有待進一步探索。目前是發現在精排層會有如下問題。
由于特征的稀疏性、表征連續性、上下文信息等問題,這些特征很難通過prompt的形式有效輸入,尤其是后期比較完善的系統。
實驗表現上,輸入大模型的數據順序對最終決策的影響還是比較大。
上限很難打過現有比較完善的精排模型。
老生常談了,大模型的成本和更新敏捷度問題。
但值得注意的是,在比較早期,特征不多也不復雜的情況下,可以暫時充當精排模塊,但也只是暫時,在同一時期只要有比較好的語義相似度模型(甚至粗排的語義表征相似度),也有可能超過簡單基于prompt的大模型。
小結
精排是搜索后期優化的重點部分了,結合大廠走在前面的先決條件,精排方面的分享、論文都很多,所以本文聊下來挺容易剎不住車的,但我還是聚焦于精排研發的常用思路,方便大家把零散的內容給串起來,同時,精排以及重排是最接近用戶的一部分了,因此和用戶習慣、業務需求關系最為緊密,我們在進行分析的過程,還是需要多看case,多剖析用戶習慣,從而實現更優秀的精排效果。








)






![[Java]Swing版坦克大戰小游戲項目開發(1)——new出一個窗口](http://pic.xiahunao.cn/[Java]Swing版坦克大戰小游戲項目開發(1)——new出一個窗口)




