我們今天了解一個字符串匹配算法-KMP算法,內容難度相對來說較高,建議先收藏再細品!!!

KMP算法的基本概念
KMP算法是一種高效的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,因此人們稱它為克努特—莫里斯—普拉特操作(簡稱KMP算法)。
該算法的主要使用場景就是在字符串(也叫主串)中的模式串(也叫字串)定位問題,常見的有“求子串出現的起始位置”、“求子串的出現次數”等。
解決什么問題
假設有兩個字符串,分別為文本串和模式串,如下:

求在文本串中是否出現過上面的模式串。
暴力解法
當出現不匹配的字符時,暴力算法會進行如下兩個操作:
- 向后移動模式串
- 目標串和模式串的指針都回溯
KMP優化解法
使用暴力算法的時間復雜度較高,如何去優化呢?
優化方向:防止或減少主串指針回溯
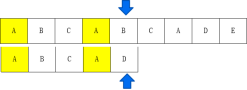
當出現不匹配的字符時,目標串指針不動,只移動模式串。
移動前,指針左邊的字符已經匹配了,所以要讓移動后的目標串的指針不會蘇,需要保證:模式串移動之后,在指針左邊的字符也是匹配的。
- 找相同字符必須是從模式串第一個位置開始
- 模式串移動方式由能找到的最長的相同字符決定,如果不是最長的,可能會漏掉能匹配的內容。
- 找到的最長的相同字符串長度必須小于已經匹配的內容長度,前后部分可以有交叉內容
KMP算法小結
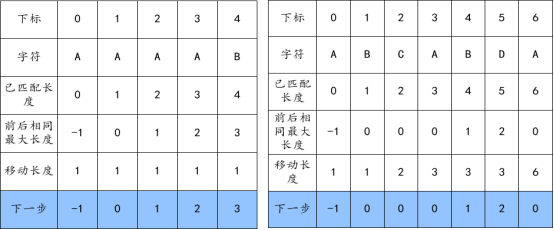
- 發生不匹配時,指針所指的下標等于已經匹配的長度
- 發生不匹配時,需要移動的長度 = 已經匹配的長度 - 前后相同的最大長度
- 前后相同的最大長度為空的地方用-1補齊
KMP算法中的next數組
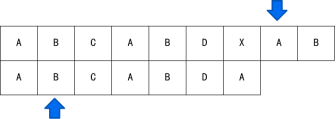
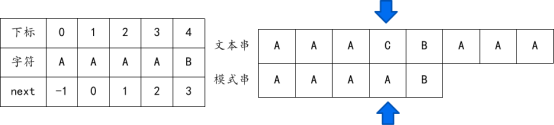
當目前的C和A不匹配時,由于A的前面也全都是A,所以前面也一定不匹配,對于這個模式串,可以直接將指針移動到-1的位置。
所以需要再對next數組進行改進,改進后的數組我們命名為nextval。
優化next數組
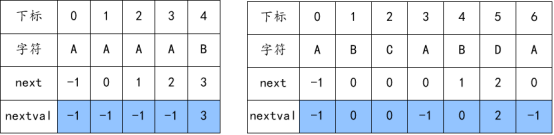
總結:若str[j] == str[next[j]],那么nextval[j] = nextval[next],否則nextval[j] = next[j]
判斷是否匹配
先給定兩個字符串,分別表示文本串和模式串,通過kmp(稍后寫這個函數)進行比較,找到第一次出現模式串的位置,如果沒有匹配上則給出提示。
char *text = "aaaaaabaaa",*pattern = "aaaab";
int index = kmp(text,pattern);
if(index == -1)
{cout << "沒有匹配上內容";
}
else{cout << "匹配上了,起始位置為:" << index;
}
輸出next數組
next指針用來動態獲取模式串的長度
int kmp(char *text,char *pattern){int index = -1;int txt_len = strlen(text),ptn_len = strlen(pattern);int *next = (int *)malloc(sizeof(int) * ptn_len);get_next(pattern,next,ptn_len);free(next);return index;
}
計算next數組
若str[j] == str[k]時,next[j+1] = k+1
若str[j] != str[k]時,k = next[k]
void get_next(char *str,int *next,int len){int j = 0,k = -1;next[0] = -1;while(j < len-1){if(k == -1 || str[j] == str[k]){k++;j++;next[j] = k;}else k = next[k];}
}
遍歷輸出next數組
從下標為0的位置到ptn_len依次輸出next數組內的元素
int kmp(char *text,char *pattern)
{int index = -1;int txt_len = strlen(text),ptn_len = strlen(pattern);int *next = (int *)malloc(sizeof(int) * ptn_len);get_next(pattern,next,ptn_len);for(int i=0;i<ptn_len;i++){printf("%d ",next[i]);}free(next);return index;
}
輸出nextval數組
將next數組變為nextval數組(此處的next數組實際上是nextval數組)
if(k == -1 || str[j] == str[k]){k++;j++;if(str[j] == str[k]){next[j] = next[k];}else{next[j] = k;}
}
else{k = next[k];
}
輸出匹配位置
int index = -1,txt_idx = 0,ptn_idx = 0;
... ...
get_next(pattern,next,ptn_len);while((txt_idx < txt_len) && (ptn_idx < ptn_len))
{if(text[txt_idx] == pattern[ptn_idx] || ptn_idx == -1){txt_idx++;ptn_idx++;}else{ptn_idx = next[ptn_idx];}
}if(ptn_idx >= ptn_len){index = txt_idx - ptn_len;
}
利用KMP算法解決字符串匹配問題,能極大節約時間復雜度。關于KMP算法還有什么問題的話,歡迎各位留言交流~


)














![JavaScript里方括號[]的使用](http://pic.xiahunao.cn/JavaScript里方括號[]的使用)

)