一. LightWeight概述
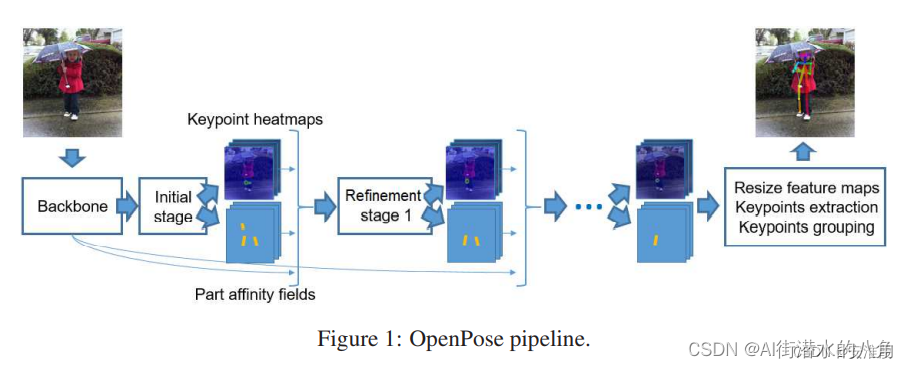
????????light weight openpose是openpose的簡化版本,使用了openpose的大體流程。
????????Light weight openpose和openpose的區別是:
????????a 前者使用的是Mobilenet V1(到conv5_5),后者使用的是Vgg19(前10層)。
????????b 前者部分層使用了空洞卷積(dilated convolution)來提升感受視野,后者使用一般的卷積。
????????c 前者卷積核大小為3*3,后者為7*7。
????????d 前者只有一個refine stage,后者有5個stage。
????????e 前者的initial stage和refine stage里面的兩個分支(hotmaps和pafs)使用權值共享,后者則是并行的兩個分支
二. LightWeight的網絡結構
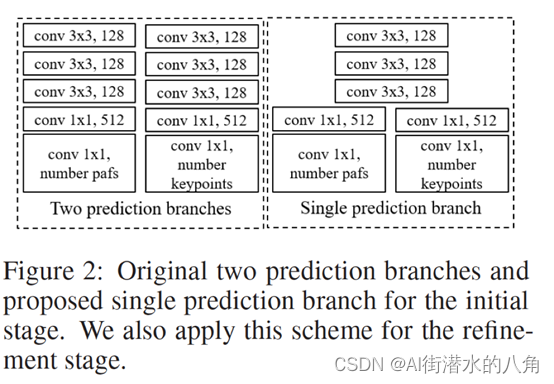
????????openpose的每個stage使用下圖中左側的兩個并行的分支,分別預測hotmaps和pafs,為了進一步降低計算量,light weight openpose中將前幾層進行權值共享,如下圖右側所示。
????????其網絡流程:
三. LightWeight的網絡結構代碼
import torch
from torch import nnfrom modules.conv import conv, conv_dw, conv_dw_no_bnclass Cpm(nn.Module):def __init__(self, in_channels, out_channels):super().__init__()self.align = conv(in_channels, out_channels, kernel_size=1, padding=0, bn=False)self.trunk = nn.Sequential(conv_dw_no_bn(out_channels, out_channels),conv_dw_no_bn(out_channels, out_channels),conv_dw_no_bn(out_channels, out_channels))self.conv = conv(out_channels, out_channels, bn=False)def forward(self, x):x = self.align(x)x = self.conv(x + self.trunk(x))return xclass InitialStage(nn.Module):def __init__(self, num_channels, num_heatmaps, num_pafs):super().__init__()self.trunk = nn.Sequential(conv(num_channels, num_channels, bn=False),conv(num_channels, num_channels, bn=False),conv(num_channels, num_channels, bn=False))self.heatmaps = nn.Sequential(conv(num_channels, 512, kernel_size=1, padding=0, bn=False),conv(512, num_heatmaps, kernel_size=1, padding=0, bn=False, relu=False))self.pafs = nn.Sequential(conv(num_channels, 512, kernel_size=1, padding=0, bn=False),conv(512, num_pafs, kernel_size=1, padding=0, bn=False, relu=False))def forward(self, x):trunk_features = self.trunk(x)heatmaps = self.heatmaps(trunk_features)pafs = self.pafs(trunk_features)return [heatmaps, pafs]class RefinementStageBlock(nn.Module):def __init__(self, in_channels, out_channels):super().__init__()self.initial = conv(in_channels, out_channels, kernel_size=1, padding=0, bn=False)self.trunk = nn.Sequential(conv(out_channels, out_channels),conv(out_channels, out_channels, dilation=2, padding=2))def forward(self, x):initial_features = self.initial(x)trunk_features = self.trunk(initial_features)return initial_features + trunk_featuresclass RefinementStage(nn.Module):def __init__(self, in_channels, out_channels, num_heatmaps, num_pafs):super().__init__()self.trunk = nn.Sequential(RefinementStageBlock(in_channels, out_channels),RefinementStageBlock(out_channels, out_channels),RefinementStageBlock(out_channels, out_channels),RefinementStageBlock(out_channels, out_channels),RefinementStageBlock(out_channels, out_channels))self.heatmaps = nn.Sequential(conv(out_channels, out_channels, kernel_size=1, padding=0, bn=False),conv(out_channels, num_heatmaps, kernel_size=1, padding=0, bn=False, relu=False))self.pafs = nn.Sequential(conv(out_channels, out_channels, kernel_size=1, padding=0, bn=False),conv(out_channels, num_pafs, kernel_size=1, padding=0, bn=False, relu=False))def forward(self, x):trunk_features = self.trunk(x)heatmaps = self.heatmaps(trunk_features)pafs = self.pafs(trunk_features)return [heatmaps, pafs]class PoseEstimationWithMobileNet(nn.Module):def __init__(self, num_refinement_stages=1, num_channels=128, num_heatmaps=19, num_pafs=38):super().__init__()self.model = nn.Sequential(conv( 3, 32, stride=2, bias=False),conv_dw( 32, 64),conv_dw( 64, 128, stride=2),conv_dw(128, 128),conv_dw(128, 256, stride=2),conv_dw(256, 256),conv_dw(256, 512), # conv4_2conv_dw(512, 512, dilation=2, padding=2),conv_dw(512, 512),conv_dw(512, 512),conv_dw(512, 512),conv_dw(512, 512) # conv5_5)self.cpm = Cpm(512, num_channels)self.initial_stage = InitialStage(num_channels, num_heatmaps, num_pafs)self.refinement_stages = nn.ModuleList()for idx in range(num_refinement_stages):self.refinement_stages.append(RefinementStage(num_channels + num_heatmaps + num_pafs, num_channels,num_heatmaps, num_pafs))def forward(self, x):backbone_features = self.model(x)backbone_features = self.cpm(backbone_features)stages_output = self.initial_stage(backbone_features)for refinement_stage in self.refinement_stages:stages_output.extend(refinement_stage(torch.cat([backbone_features, stages_output[-2], stages_output[-1]], dim=1)))return stages_output
四. LightWeight是怎么去識別行為呢
????????LightWeight可以檢測到人體的關鍵點,所以可以通過兩種方式來判斷行為,第一種方法是通過計算角度,第二種方式,是通過判斷整體的關鍵點(把摳出的關鍵點圖送入到分類網絡),本文的做法是第一種方式
# 計算姿態
def get_pos(keypoints):str_pose = ""# 計算左臂與水平方向的夾角keypoints = np.array(keypoints)v1 = keypoints[1] - keypoints[0]v2 = keypoints[2] - keypoints[0]angle_left_arm = get_angle(v1, v2)#計算右臂與水平方向的夾角v1 = keypoints[0] - keypoints[1]v2 = keypoints[3] - keypoints[1]angle_right_arm = get_angle(v1, v2)if angle_left_arm>0 and angle_right_arm>0:str_pose = "LEFT_UP"elif angle_left_arm<0 and angle_right_arm<0:str_pose = "RIGHT_UP"elif angle_left_arm>0 and angle_right_arm<0:str_pose = "ALL_HANDS_UP"elif angle_left_arm>0 and angle_right_arm<0:str_pose = "NORMAL"return str_pose五. LightWeight的演示效果




六. 整個工程的內容
提供源代碼,模型,提供GUI界面代碼

代碼的下載路徑(新窗口打開鏈接):基于深度學習LightWeight的人體姿態之行為識別系統源碼

有問題可以私信或者留言,有問必答





)


)










