哈希表(Hash Table)是一種高效的數據結構,能夠在平均情況下實現常數時間的查找、插入和刪除操作。
????????哈希表的核心是哈希函數,哈希函數是一個將輸入數據(通常稱為“鍵”或“key”)轉換為固定長度的整數的函數。這個整數通常用作哈希表(Hash Table)中的索引,用于快速查找數據。本質上就是根據輸入的值確定值的位置。
例如,輸入除以10取余是位置編號:
int HashPosFind(int num) {return num % 10;
}如果有重復的情況呢,那么要在其他位置存儲,有不同的方法,這里采取的是鏈表法。
如圖所示,如果序號為1的地址處已經有值存在,那么我們就把新的數連接到鏈表上。
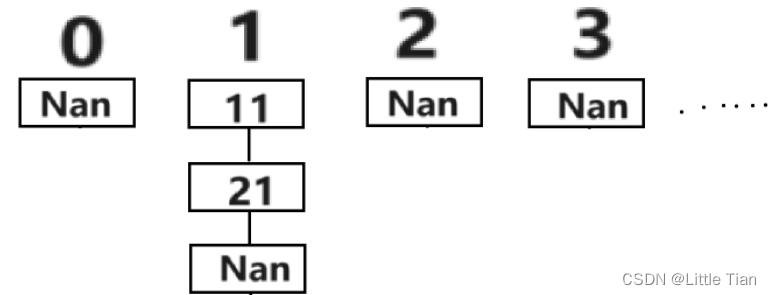
首先我們可以寫出類似于這樣的函數:
#define NUM 10
#define Nan -32767
typedef struct Seqlist {struct Seqlist* next;int val;
}Seqlist;typedef struct HashList {int num;Seqlist** list;
}HashList;
HashList* HashInit() {HashList* H = (HashList*)malloc(sizeof(HashList));H->num = 0;H->list = (Seqlist**)malloc(sizeof(Seqlist*) *NUM);for (int i = 0; i < NUM; i++) {H->list[i] = (Seqlist*)malloc(sizeof(Seqlist));H->list[i]->next = NULL;}for (int i = 0; i < NUM; i++) {H->list[i]->val = Nan;}return H;
}1.首先定義NUM表示一共有十個位置定義鏈表,定義Nan表示沒有數的時候的數值。
2.然后定義哈希表的結構,用二級指針的方法模擬二維數組,準確的說是二維鏈表。
3.接著為哈希表開辟空間,先為10個鏈表指針開辟二級指針(指針數組),接著在為每個序列號指針開辟空間并且初始化為Nan表示此時哈希表為空。
????????接著就是哈希表插入操作,這里要考慮兩種情況,第一是當取得地址序列號之后,此時的鏈表存儲的是Nan,那我們要先把鏈表的Nan賦值為插入的數據,然后新創建一個節點存儲Nan表示鏈表的結尾。
????????第二種情況的是第一個數值不是Nan,這時要一直找到鏈表的尾,然后同樣執行上一步的操作:先賦值為插入的數值,然后更新鏈表的尾。
代碼如下:
void HashPush(int val,HashList* H) {int pos = HashPosFind(val);if (H->list[pos]->val == Nan) {H->list[pos]->val = val;Seqlist* new_node = (Seqlist*)malloc(sizeof(Seqlist));new_node->val = Nan;new_node->next = NULL;H->list[pos]->next = new_node;}else {printf("重新插入中\n");int num = 1;Seqlist* cur = H->list[pos];while (cur->val != Nan) {cur = cur->next;}Seqlist* new_node = (Seqlist*)malloc(sizeof(Seqlist));new_node->val = Nan;new_node->next = NULL;cur->next = new_node;cur->val = val;}
}????????首先是第一種情況,因為是Nan所以說明此時的鏈表為空,所以直接存儲,然后開辟一個新的節點存儲Nan表示鏈表的結尾。
????????第二種情況說明已經有值存在,這時先找到鏈表的尾(找到節點值為Nan的節點),然后執行和第一步一樣的操作:先存儲值,然后新開辟一個節點存儲Nan。
????????最后是打印函數:思路比較簡單,一直打印到Nan為止。
void HashPrint(HashList* H) {for (int i = 0; i < NUM; i++) {printf("%d: ",i);Seqlist* cur = H->list[i];while (cur->val != Nan) {printf("%d ", cur->val);cur = cur->next;}printf("\n");}
}這就是文章的全部的內容了,希望對你有所幫助,如有錯誤歡迎指出。




)


)











