模型可解釋性
這是一個關于錯誤解釋機器學習模型的危險以及正確解釋它的價值的故事。如果您發現諸如梯度提升機或隨機森林之類的集成樹模型的魯棒準確性很有吸引力,但也需要解釋它們,那么我希望您發現這些信息有用且有幫助。
試想一下,我們的任務是預測個人?為n行的財務狀況。我們的模型越準確,銀行賺的錢就越多,但由于此預測用于貸款申請,因此法律上也要求我們解釋為什么做出預測。在對多種模型類型進行試驗后,我們發現 XGBoost 中實現的梯度提升樹提供了最佳準確度。不幸的是,解釋 XGBoost 做出預測的原因似乎很難,所以我們只能選擇退回到線性模型,或者弄清楚如何解釋我們的 XGBoost 模型。沒有數據科學家愿意放棄準確性……所以我們決定嘗試后者,并解釋復雜的 XGBoost 模型(它恰好有 1,247 個深度為 6 的樹)。

經典的全局特征重要性度量
第一個明顯的選擇是使用 Python XGBoost 接口中的 plot_importance() 方法。它提供了一個非常吸引人的簡單條形圖,表示我們數據集中每個特征的重要性:(重現本文的代碼在Jupyter notebook 中)
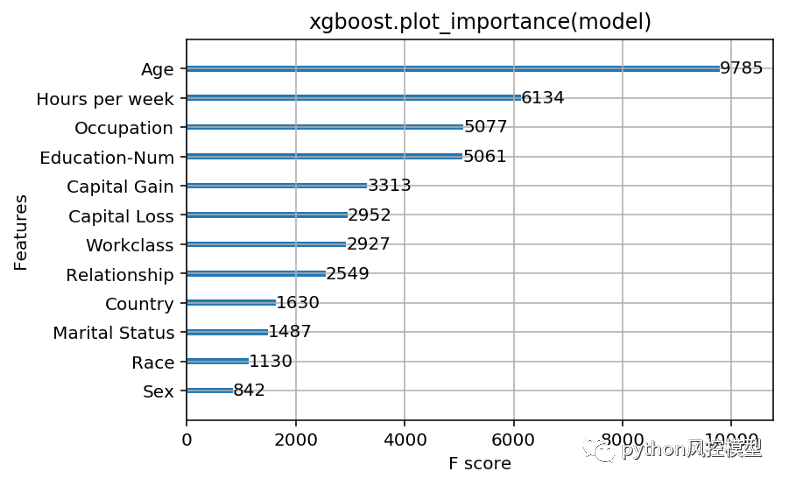
為一個訓練模型運行 xgboost.plot_importance(model) 的結果,用于預測人們是否會報告來自經典“成人”人口普查數據集的超過 5 萬美元的收入(使用邏輯損失)。
如果我們查看 XGBoost 返回的特征重要性,我們會發現年齡在其他特征中占主導地位,顯然是最重要的收入預測指標。我們可以停在這里,向我們的經理報告直觀令人滿意的答案,即年齡是最重要的特征,其次是每周工作時間和教育水平。但是作為優秀的數據科學家……我們查看了文檔,發現在 XGBoost 中測量特征重要性有三個選項:
-
重量。使用特征在所有樹中拆分數據的次數。
-
覆蓋。使用特征在所有樹中拆分數據的次數,權重由經過這些拆分的訓練數據點的數量決定。
-
獲得。?使用特征進行拆分時獲得的平均訓練損失減少量。
這些是我們可以在任何基于樹的建模包中找到的典型重要性度量。權重是默認選項,因此我們決定嘗試其他兩種方法,看看它們是否有所不同:
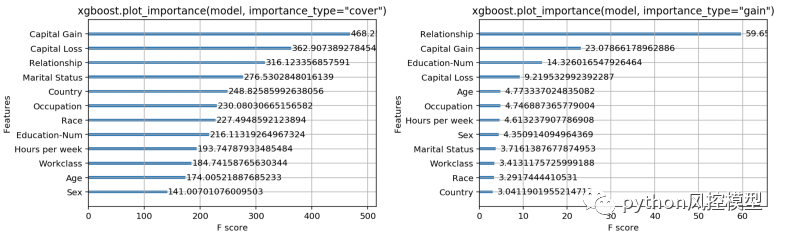
運行 xgboost.plot_importance 的結果同時具有 important_type=”cover” 和 important_type=”gain”。
令我們沮喪的是,我們看到 XGBoost 提供的三個選項中的每一個的特征重要性排序都非常不同!對于cover方法,似乎資本收益特征最能預測收入,而對于收益方法,關系狀態特征主導所有其他特征。這應該讓我們在不知道哪種方法最好的情況下,依賴這些度量來報告特征重要性會非常不舒服。
是什么讓衡量特征重要性的好壞?
如何將一種特征歸因方法與另一種進行比較并不明顯。我們可以衡量每種方法在數據清理、偏差檢測等任務上的最終用戶性能。但這些任務只是對特征歸因方法質量的間接衡量。在這里,我們將改為定義我們認為任何好的特征歸因方法都應該遵循的兩個屬性:
-
一致性。每當我們更改模型以使其更多地依賴于某個特征時,該特征的歸因重要性不應降低。
-
準確性。所有特征重要性的總和應該等于模型的總重要性。(例如,如果重要性是由 R2 值衡量的,那么每個特征的屬性應與完整模型的 R2 相加)
如果一致性不成立,那么我們不能比較任意兩個模型之間的歸因功能重要性有關,因為那么?具有較高分配的歸屬并不意味著模型實際上更多地依賴于該功能。
如果準確性無法保持,那么我們不知道每個特征的屬性如何結合起來代表整個模型的輸出。我們不能在方法完成后對屬性進行標準化,因為這可能會破壞方法的一致性。
當前的歸因方法是否一致且準確?
回到我們作為銀行數據科學家的工作……我們意識到一致性和準確性對我們很重要。事實上,如果一個方法不一致,我們不能保證具有最高屬性的特征實際上是最重要的。因此,我們決定使用兩個與我們在銀行的任務無關的非常簡單的樹模型來檢查每種方法的一致性:
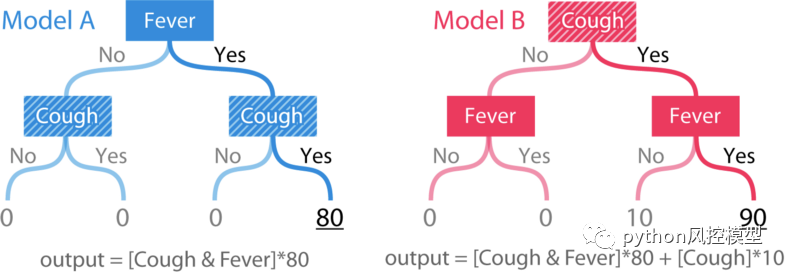
兩個特征的簡單樹模型。咳嗽在模型 B 中顯然比模型 A 更重要。
模型的輸出是基于人的癥狀的風險評分。模型 A 只是一個簡單的“與”函數,用于發燒和咳嗽的二元特征。模型 B 具有相同的功能,但只要咳嗽是肯定的,就 +10 。為了檢查一致性,我們必須定義“重要性”。在這里,我們將通過兩種方式定義重要性:1)作為我們刪除一組特征時模型預期準確率的變化。2)作為我們刪除一組特征時模型預期輸出的變化。
重要性的第一個定義衡量特征對模型的全局影響。而第二個定義衡量特征對單個預測的個性化影響。在我們的簡單樹模型中,咳嗽特征在模型 B 中顯然更重要,無論是對于全局重要性還是對于發燒和咳嗽都是肯定的個體預測的重要性。
上面的weight、cover和gain方法都是全局特征歸因方法。但是當我們在銀行中部署我們的模型時,我們還需要為每個客戶提供個性化的解釋。為了檢查一致性,我們在簡單的樹模型上運行了五種不同的特征歸因方法:
-
樹形狀。我們提出了一種新的個性化方法。
-
薩巴斯。一種個性化的啟發式特征歸因方法。
-
平均值(|樹形狀|)。基于個性化 Tree SHAP 歸因的平均幅度的全局歸因方法。
-
獲得。與上面 XGBoost 中使用的方法相同,也等效于 scikit-learn 樹模型中使用的 Gini 重要性度量。
-
拆分計數。代表 XGBoost 中密切相關的“權重”和“覆蓋”方法,但使用“權重”方法計算。
-
排列。當在測試數據集中隨機排列單個特征時,導致模型準確度下降。
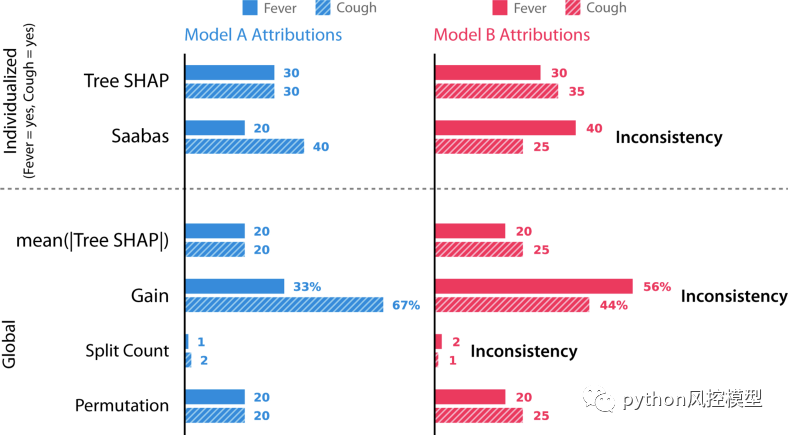
使用六種不同方法的模型 A 和模型 B 的特征屬性。據我們所知,這些方法代表了文獻中所有特定于樹的特征歸因方法。
之前除了特征排列以外的所有方法都是不一致的!這是因為它們在模型 B 中對咳嗽的重要性低于模型 A。不能相信不一致的方法可以正確地為最有影響的特征分配更多的重要性。精明的讀者會注意到,當我們研究的經典特征歸因方法在同一模型上相互矛盾時,這種不一致就已經在早些時候表現出來了。那么精度屬性呢?事實證明,Tree SHAP、Sabaas 和 Gain 都如之前定義的那樣準確,而特征排列和拆分計數則不然。
也許令人驚訝的是,像增益(基尼重要性)這樣廣泛使用的方法會導致如此明顯的不一致結果。為了更好地理解為什么會發生這種情況,讓我們檢查一下模型 A 和模型 B 的增益是如何計算的。為了簡單起見,我們假設我們的數據集的 25% 落在每個葉子上,并且每個模型的數據集都有完全匹配的標簽模型的輸出。
如果我們將均方誤差 (MSE) 視為我們的損失函數,那么在對模型 A 進行任何拆分之前,我們從 1200 的 MSE 開始。這是來自 20 的常數平均預測的誤差。在模型 A 中對發燒進行拆分后, MSE 下降到 800,因此增益方法將 400 的下降歸因于發燒特征。然后在咳嗽特征上再次拆分導致 MSE 為 0,并且增益方法將這個 800 的下降歸因于咳嗽特征。在模型 B 中,相同的過程導致分配給發燒特征的重要性為 800,分配給咳嗽特征的重要性為 625 :
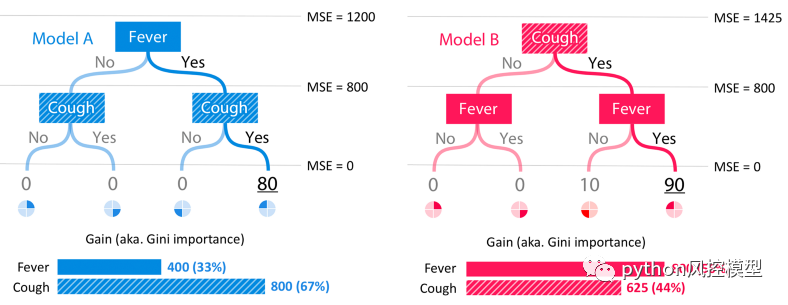
計算模型 A 和模型 B 的增益(又名基尼重要性)分數。
通常我們期望樹根附近的特征比葉子附近分裂的特征更重要(因為樹是貪婪地構造的)。然而,增益方法傾向于將更多的重要性歸因于較低的分裂。這種偏見會導致不一致,當咳嗽變得更加重要時(因此從根本上分開),其歸因重要性實際上下降了。個性化的 Saabas 方法(由treeinterpreter 使用package) 在我們下降樹時計算預測的差異,因此它也遭受相同的偏向于樹中較低的分裂。隨著樹變得更深,這種偏差只會增加。相比之下,Tree SHAP 方法在數學上等效于對特征的所有可能排序的預測差異進行平均,而不僅僅是由它們在樹中的位置指定的排序。
只有 Tree SHAP 既一致又準確,這并非巧合。鑒于我們想要一種既一致又準確的方法,結果證明只有一種方法可以分配特征重要性。詳細信息在我們最近的NIPS 論文中,但總結是博弈論關于利潤公平分配的證明導致機器學習中特征歸因方法的唯一性結果。這些獨特的值被稱為 Shapley 值,以 1950 年代導出它們的 Lloyd Shapley 的名字命名。我們在此使用的 SHAP 值來自與 Shapley 值相關的幾種個性化模型解釋方法的統一。Tree SHAP 是一種快速算法,可以在多項式時間內準確計算樹的 SHAP 值,而不是經典的指數運行時(參見arXiv)。
自信地解釋我們的模型
堅實的理論論證和快速實用的算法相結合,使 SHAP 值成為自信地解釋樹模型(例如 XGBoost 的梯度提升機)的強大工具。有了這種新方法,我們又回到了解釋銀行 XGBoost 模型的任務上:
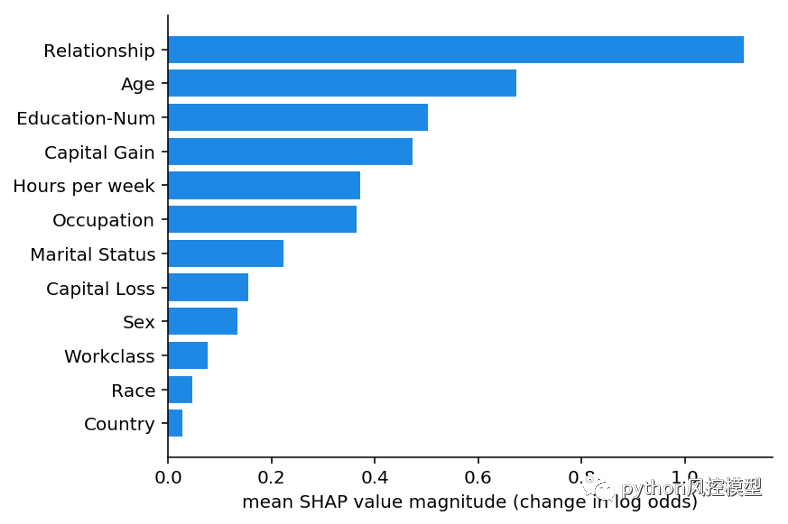
應用于收入預測模型的全局均值(|Tree SHAP|)方法。x 軸本質上是當特征從模型中“隱藏”時模型輸出的平均幅度變化(對于該模型,輸出具有對數幾率單位)。有關詳細信息,請參閱論文,但“隱藏”意味著將變量整合到模型之外。由于隱藏特征的影響會根據還隱藏的其他特征而變化,因此使用 Shapley 值來確保一致性和準確性。
我們可以看到,關系特征實際上是最重要的,其次是年齡特征。由于 SHAP 值保證了一致性,因此我們無需擔心在使用增益或拆分計數方法之前發現的各種矛盾。但是,由于我們現在對每個人都有個性化的解釋,因此我們可以做的不僅僅是制作條形圖。我們可以繪制數據集中每個客戶的特征重要性。在十八Python包讓一切變得簡單。我們首先調用 shap.TreeExplainer(model).shap_values(X) 來解釋每個預測,然后調用 shap.summary_plot(shap_values, X) 來繪制這些解釋:
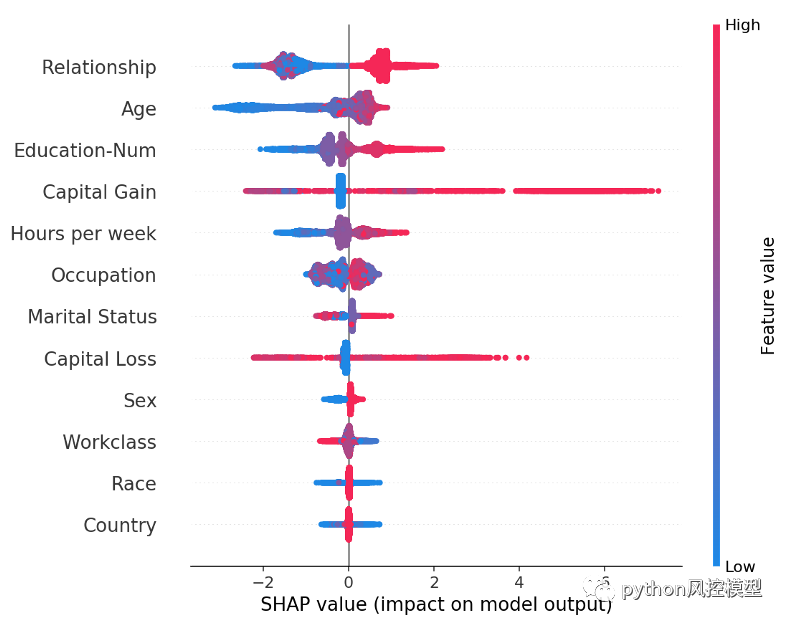
每個客戶的每一行都有一個點。點的 x 位置是該特征對模型對客戶的預測的影響,點的顏色代表該特征對客戶的價值。不適合行的點堆積起來以顯示密度(在此示例中有 32,561 個客戶)。由于 XGBoost 模型具有邏輯損失,因此 x 軸具有對數賠率單位(Tree SHAP 解釋了模型邊際輸出的變化)。
這些特征按均值(|Tree SHAP|)排序,因此我們再次將關系特征視為年收入超過 5 萬美元的最強預測因子。通過繪制特征對每個樣本的影響,我們還可以看到重要的異常值效應。例如,雖然資本收益在全球范圍內并不是最重要的特征,但對于部分客戶而言,這是迄今為止最重要的特征。按特征值著色的模式向我們展示了諸如年輕如何降低您賺取超過 5 萬美元的機會,而高等教育增加您賺取超過 5 萬美元的機會。
我們可以停在這里向我們的老板展示這個情節,但讓我們更深入地研究其中的一些功能。我們可以通過繪制年齡 SHAP 值(對數幾率的變化)與年齡特征值來為年齡特征做到這一點:
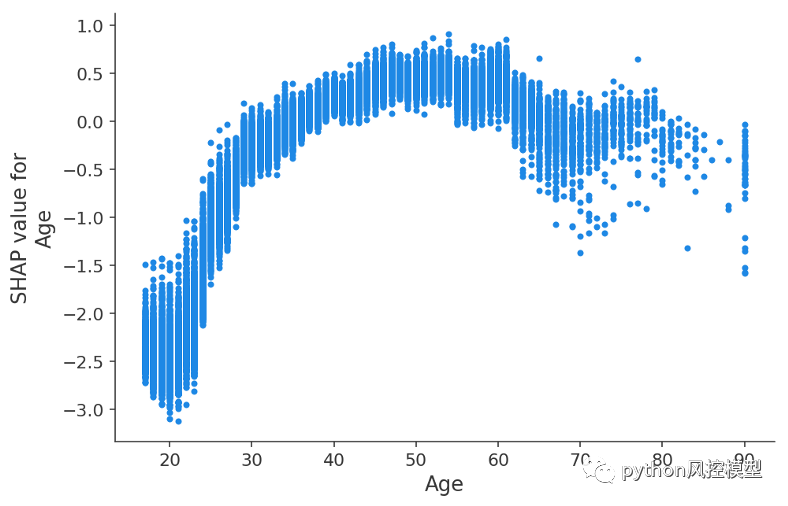
y 軸是年齡特征對年收入超過 5 萬美元的對數幾率的改變程度。x 軸是客戶的年齡。每個點代表數據集中的一個客戶。
在這里,我們看到了 XGBoost 模型捕捉到的年齡對收入潛力的明顯影響。請注意,與傳統的部分依賴圖(顯示更改特征值時的平均模型輸出)不同,這些 SHAP 依賴圖顯示交互效應。盡管數據集中的許多人都 20 歲,但他們的年齡對他們的預測的影響程度有所不同,如 20 歲點的垂直離散所示。這意味著其他特征正在影響年齡的重要性。為了了解哪些特征可能是這種效應的一部分,我們根據受教育年限對點進行著色,并看到高水平的教育在 20 多歲時降低了年齡的影響,但在 30 多歲時提高了它:
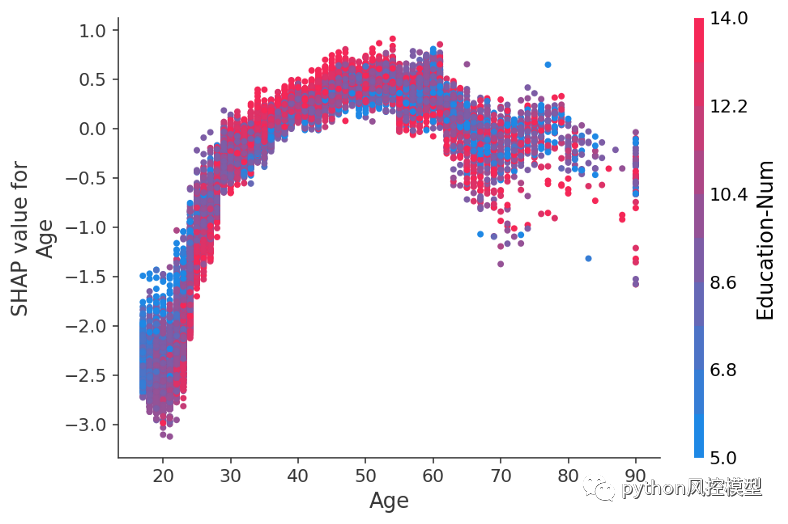
y 軸是年齡特征對年收入超過 5 萬美元的對數幾率的改變程度。x 軸是客戶的年齡。Education-Num 是客戶完成的教育年數。
如果我們為每周工作的小時數制作另一個依賴圖,我們會看到工作更多的好處在大約 50 小時/周時穩定下來,如果您已婚,額外工作不太可能表明高收入:
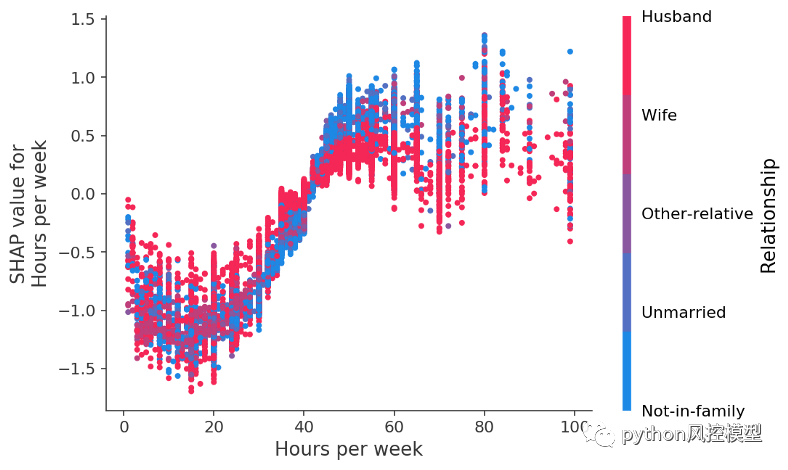
每周工作小時數與工作小時數對收入潛力的影響。
解釋你自己的模型
這個簡單的演練旨在反映您在設計和部署自己的模型時可能經歷的過程。在十八包很容易通過PIP安裝,我們希望它可以幫助你有信心開拓您的模型。它包含的不僅僅是本文所涉及的內容,包括 SHAP 交互值、模型不可知的 SHAP 值估計和其他可視化。筆記本可以在各種有趣的數據集上說明所有這些功能。例如,您可以在解釋 XGBoost 死亡率模型的筆記本中根據您的健康檢查查看您死亡的主要原因。對于 Python 以外的語言,Tree SHAP 也已直接合并到核心 XGBoost 和 LightGBM 包中。
版權聲明:文章來自公眾號(python風控模型),未經許可,不得抄襲。遵循CC 4.0 BY-SA版權協議,轉載請附上原文出處鏈接及本聲明。






如何檢測DeFi協議中的價格操縱漏洞)




)
)






