使用 PCA 探索數據分類的效果(使用 Python 代碼)
「AI秘籍」系列課程:
- 人工智能應用數學基礎
- 人工智能Python基礎
- 人工智能基礎核心知識
- 人工智能BI核心知識
- 人工智能CV核心知識
主成分分析 (PCA) 是數據科學家使用的絕佳工具。它可用于降低特征空間維數并生成不相關的特征。正如我們將看到的,它還可以幫助你深入了解數據的分類能力。我們將帶你了解如何以這種方式使用 PCA。提供了 Python 代碼片段,完整項目可在GitHub1上找到。
什么是 PCA?
我們先從理論開始。我不會深入講解太多細節,因為如果你想了解 PCA 的工作原理,有很多很好的資源^2^3。重要的是要知道 PCA 是一種降維算法。這意味著它用于減少用于訓練模型的特征數量。它通過從許多特征中構建主成分 (PC) 來實現這一點。
PC 的構造方式是,第一個 PC(即 PC1)盡可能解釋特征中的大部分變化。然后 PC2 盡可能解釋剩余變化中的大部分變化,依此類推。PC1 和 PC2 通常可以解釋總特征變化的很大一部分。另一種思考方式是,前兩個 PC 可以很好地總結特征。這很重要,因為它使我們能夠在二維平面上直觀地看到數據的分類能力。

數據集
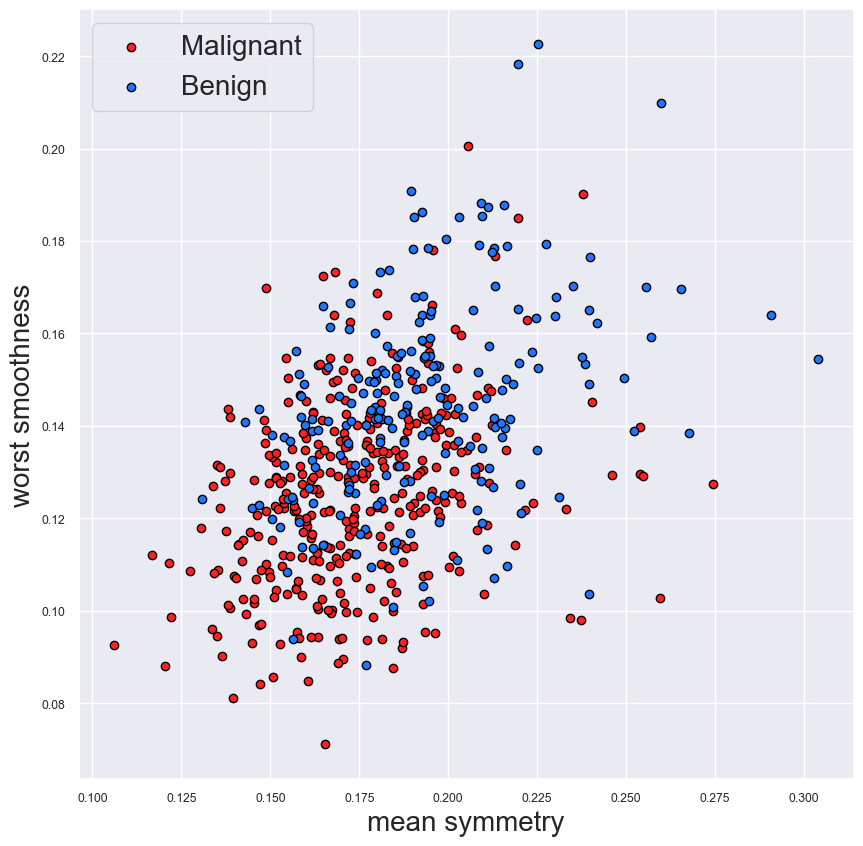
好的,讓我們深入研究一個實際的例子。我們將使用 PCA 來探索乳腺癌數據集^4,我們使用以下代碼導入該數據集。目標變量是乳腺癌測試的結果 - 惡性或良性。每次測試都會取出許多癌細胞。然后從每個癌細胞中采取 10 個不同的測量值。這些包括細胞半徑和細胞對稱性等測量值。為了獲得 30 個特征的最終列表,我們以 3 種方式匯總這些測量值。也就是說,我們計算每個測量值的平均值、標準誤差和最大值(“最差”值)。在圖 1 中,我們仔細研究了其中兩個特征 -細胞的平均對稱性和最差平滑度。
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()data = pd.DataFrame(cancer['data'],columns=cancer['feature_names'])
data['y'] = cancer['target']
在圖 1 中,我們可以看到這兩個特征有助于區分這兩個類別。也就是說,良性腫瘤往往更對稱、更光滑。重疊部分仍然很多,因此僅使用這些特征的模型效果不會很好。我們可以創建這樣的圖表來了解每個單獨特征的預測能力。盡管有 30 個特征,但需要分析的圖表還是很多。它們也沒有告訴我們整個數據集的預測能力。這就是 PCA 發揮作用的地方。
PCA——整個數據集
讓我們首先對整個數據集進行 PCA。我們使用下面的代碼來執行此操作。我們首先縮放特征,使它們都具有均值為 0 和方差為 1。這很重要,因為 PCA 通過最大化 PC 解釋的方差來工作。由于其規模,某些特征往往會具有更高的方差。例如,以厘米為單位測量的距離的方差將高于以公里為單位測量的相同距離。如果不進行縮放,PCA 將被那些方差較大的特征“壓倒”。
縮放完成后,我們擬合 PCA 模型并將特征轉換為 PC。由于我們有 30 個特征,因此最多可以有 30 個 PC。對于我們的可視化,我們只對前兩個感興趣。你可以在圖 2 中看到這一點,其中使用 PC1 和 PC2 創建了散點圖。我們現在可以看到兩個不同的集群,它們比圖 1 中更清晰。
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA#Scale the data
scaler = StandardScaler()
scaler.fit(data)
scaled = scaler.transform(data)#Obtain principal components
pca = PCA().fit(scaled)pc = pca.transform(scaled)
pc1 = pc[:,0]
pc2 = pc[:,1]#Plot principal components
plt.figure(figsize=(10,10))colour = ['#ff2121' if y == 1 else '#2176ff' for y in data['y']]
plt.scatter(pc1,pc2 ,c=colour,edgecolors='#000000')
plt.ylabel("Glucose",size=20)
plt.xlabel('Age',size=20)
plt.yticks(size=12)
plt.xticks(size=12)
plt.xlabel('PC1')
plt.ylabel('PC2')
該圖可用于直觀地了解數據的預測強度。在本例中,它表明使用整個數據集將使我們能夠區分惡性腫瘤和良性腫瘤。但是,仍然有一些異常值(即不明確位于群集中的點)。這并不意味著我們會對這些情況做出錯誤的預測。我們應該記住,并非所有特征方差都會在前兩個 PC 中捕獲。在完整特征集上訓練的模型可以產生更好的預測。
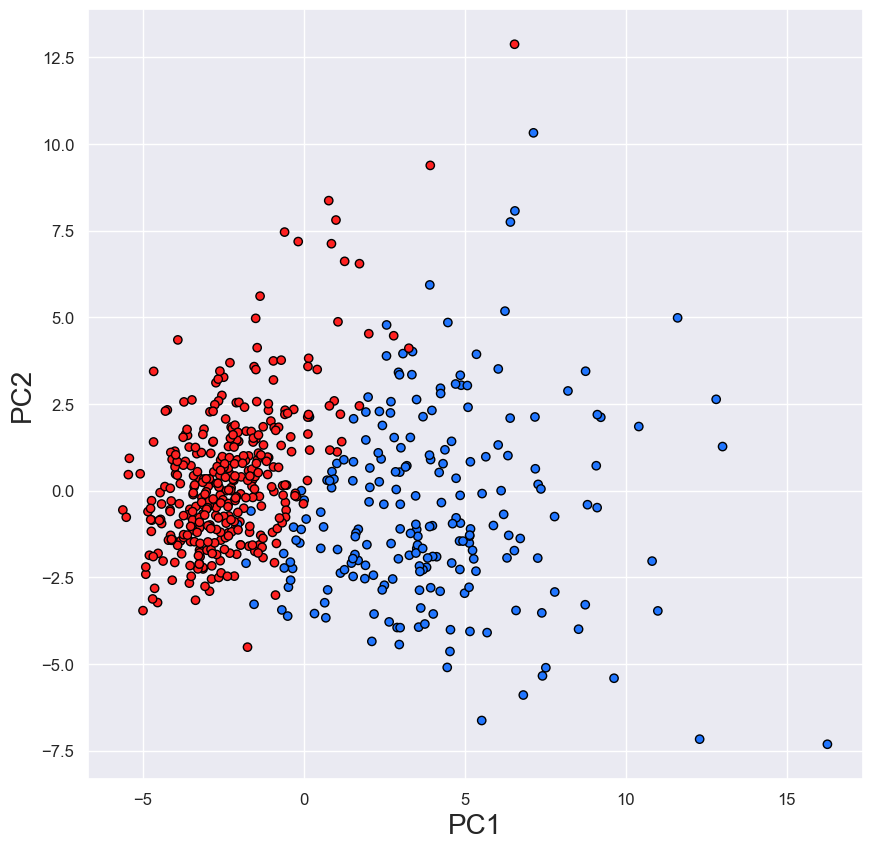
此時,我們應該提到這種方法的一個注意事項。PC1 和 PC2 可以解釋特征中很大一部分方差。然而,這并不總是正確的。在某些情況下,PC 可能被認為是特征的糟糕總結。這意味著,即使你的數據可以很好地分離類別,你也可能無法獲得清晰的聚類,如圖 2 所示。
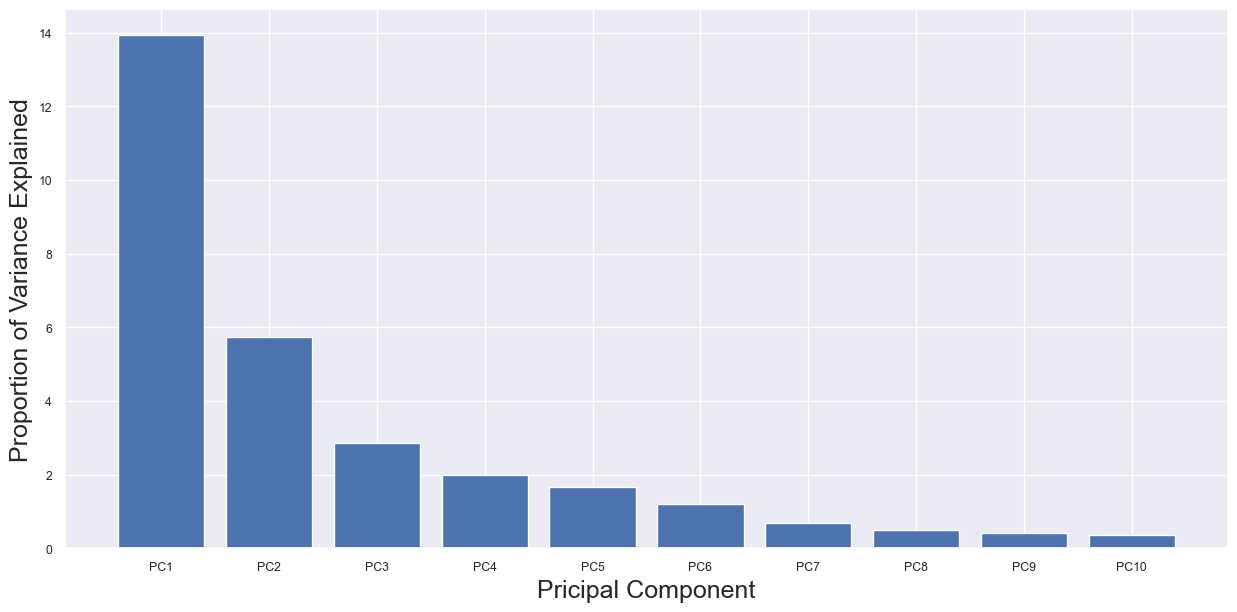
我們可以使用 PCA 碎石圖來確定這是否會是一個問題。我們使用下面的代碼創建了此分析的碎石圖,如圖 3 所示。這是一個條形圖,其中每個條形的高度是相關 PC 解釋的方差百分比。我們看到,PC1 和 PC2 總共只解釋了約 20% 的特征方差。即使只有 20% 的解釋,我們仍然得到兩個不同的聚類。這強調了數據的預測強度。
var = pca.explained_variance_[0:10] #percentage of variance explained
labels = ['PC1','PC2','PC3','PC4','PC5','PC6','PC7','PC8','PC9','PC10']plt.figure(figsize=(15,7))
plt.bar(labels,var,)
plt.xlabel('Pricipal Component')
plt.ylabel('Proportion of Variance Explained')

PCA——特征組
我們還可以使用此過程來比較不同的特征組。例如,假設我們有兩組特征。第 1 組具有基于細胞對稱性和平滑度特征的所有特征。而第 2 組具有基于周長和凹度的所有特征。我們可以使用 PCA 來直觀地了解哪組更適合進行預測。
group_1 = ['mean symmetry', 'symmetry error','worst symmetry',
'mean smoothness','smoothness error','worst smoothness']group_2 = ['mean perimeter','perimeter error','worst perimeter',
'mean concavity','concavity error','worst concavity']
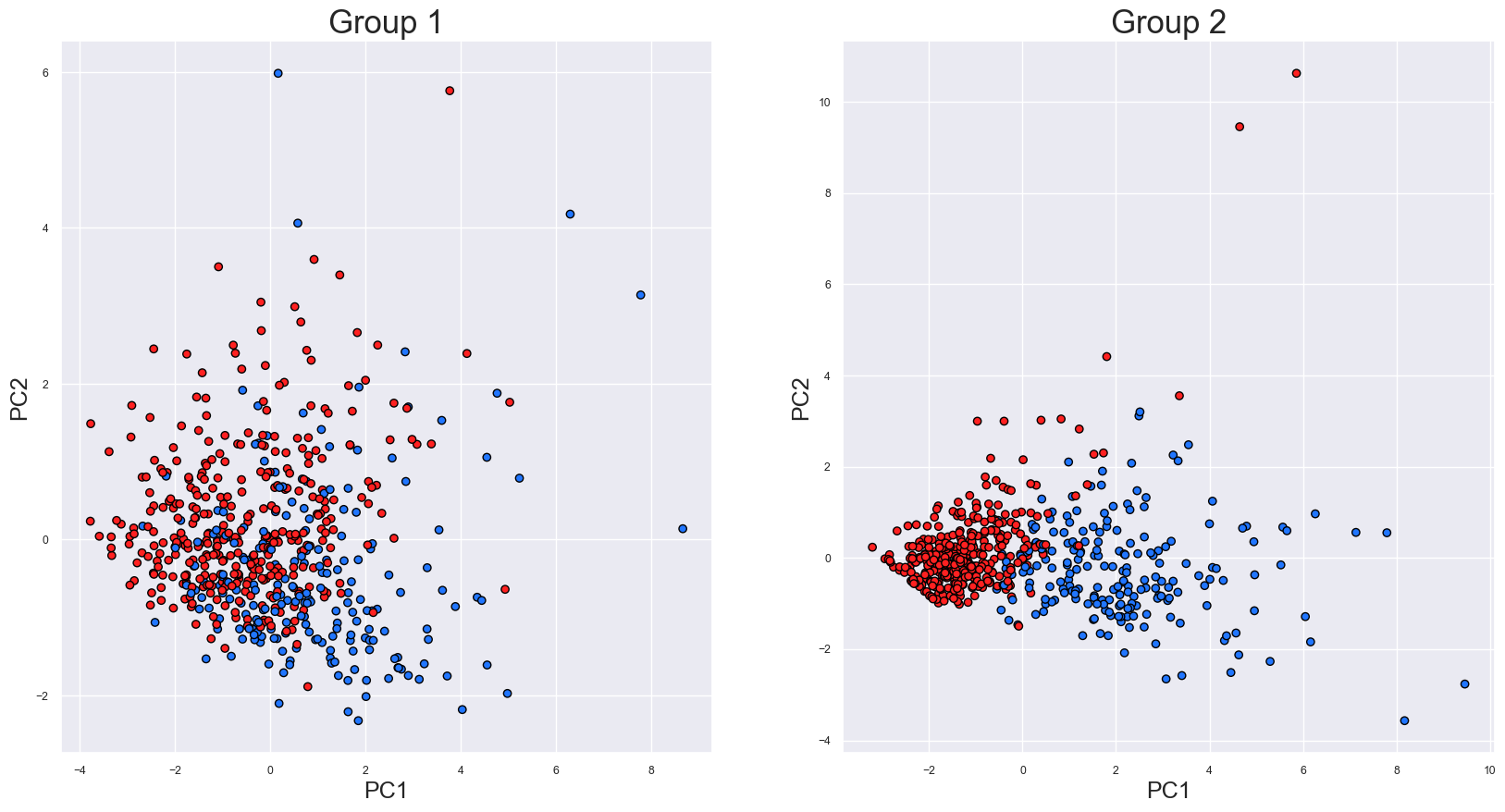
我們首先創建兩組特征。然后分別對每組進行 PCA。這將為我們提供兩組 PC,我們選擇 PC1 和 PC2 來代表每個特征組。該過程的結果可以在圖 4 中看到。
對于第 1 組,我們可以看到有一些分離,但仍然有很多重疊。相比之下,第 2 組有兩個不同的簇。因此,從這些圖中,我們預計第 2 組中的特征是更好的預測因子。使用第 2 組特征訓練的模型應該比使用第 1 組特征訓練的模型具有更高的準確率。現在,讓我們來測試一下這個假設。
我們使用下面的代碼來訓練使用兩組特征的邏輯回歸模型。在每種情況下,我們使用 70% 的數據來訓練模型,其余 30% 的數據來測試模型。第 1 組的測試集準確率為 74%,相比之下,第 2 組的準確率為 97%。因此,第 2 組中的特征是更好的預測因子,這正是我們從 PCA 結果中預期的。
from sklearn.model_selection import train_test_split
import sklearn.metrics as metric
import statsmodels.api as smfor i,g in enumerate(group):x = data[g]x = sm.add_constant(x)y = data['y']x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.3, random_state = 101)model = sm.Logit(y_train,x_train).fit() #fit logistic regression modelpredictions = np.around(model.predict(x_test)) accuracy = metric.accuracy_score(y_test,predictions)print("Accuracy of Group {}: {}".format(i+1,accuracy))---
Optimization terminated successfully.Current function value: 0.458884Iterations 7
Accuracy of Group 1: 0.7368421052631579
Optimization terminated successfully.Current function value: 0.103458Iterations 10
Accuracy of Group 2: 0.9707602339181286
最后,我們將了解如何在開始建模之前使用 PCA 來更深入地了解數據。它將讓你了解預期的分類準確度。你還將對哪些特征具有預測性建立直覺。這可以讓你在特征選擇方面占據優勢。
如上所述,這種方法并非萬無一失。它應該與其他數據探索圖和匯總統計數據一起使用。對于分類問題,這些可能包括信息值和箱線圖。一般來說,在開始建模之前,從盡可能多的不同角度查看數據是個好主意。
參考
https://github.com/hivandu/public_articles ??









-灰狼優化算法優化CNN-BiLSTM)




)




