Lift, Splat, Shoot
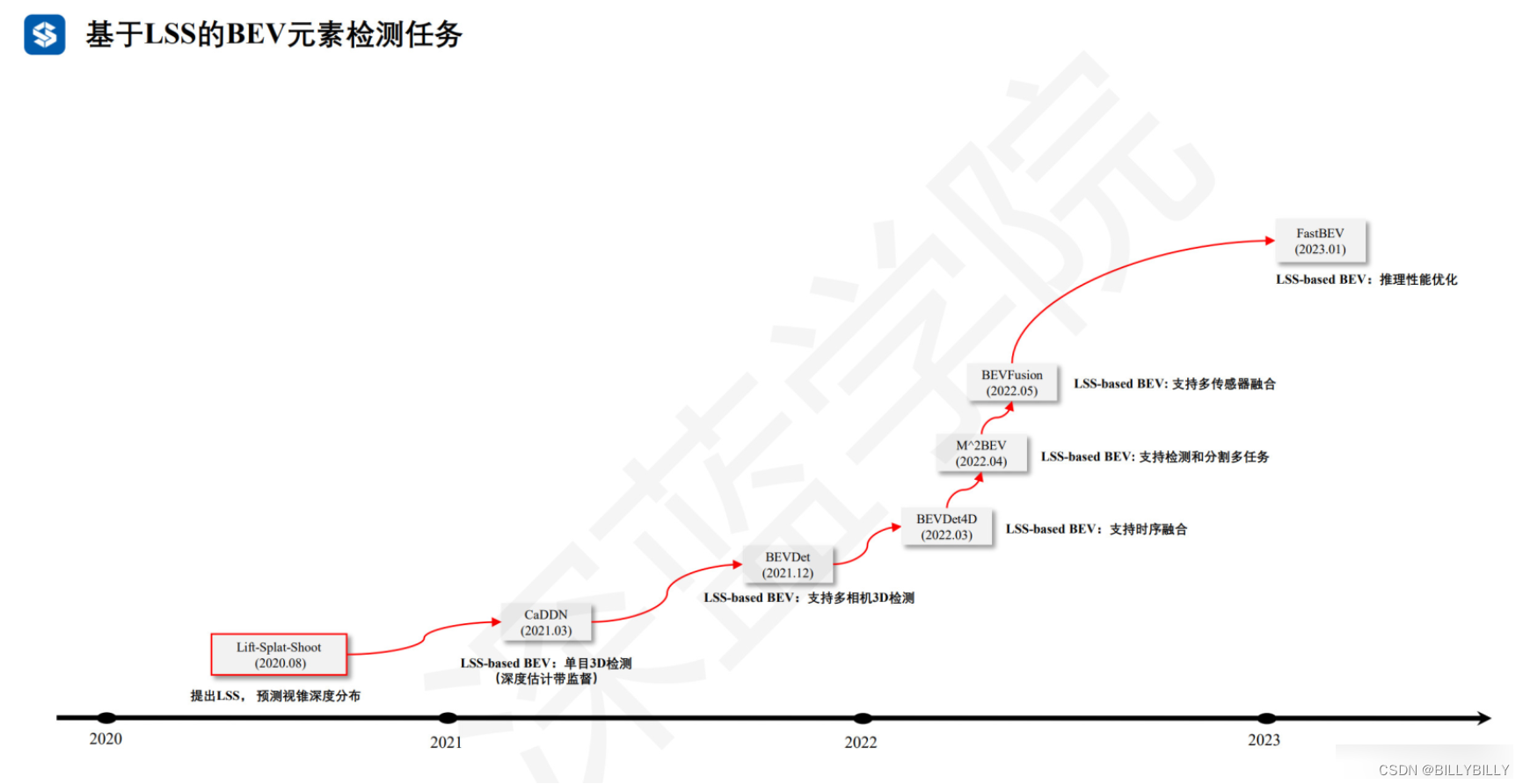
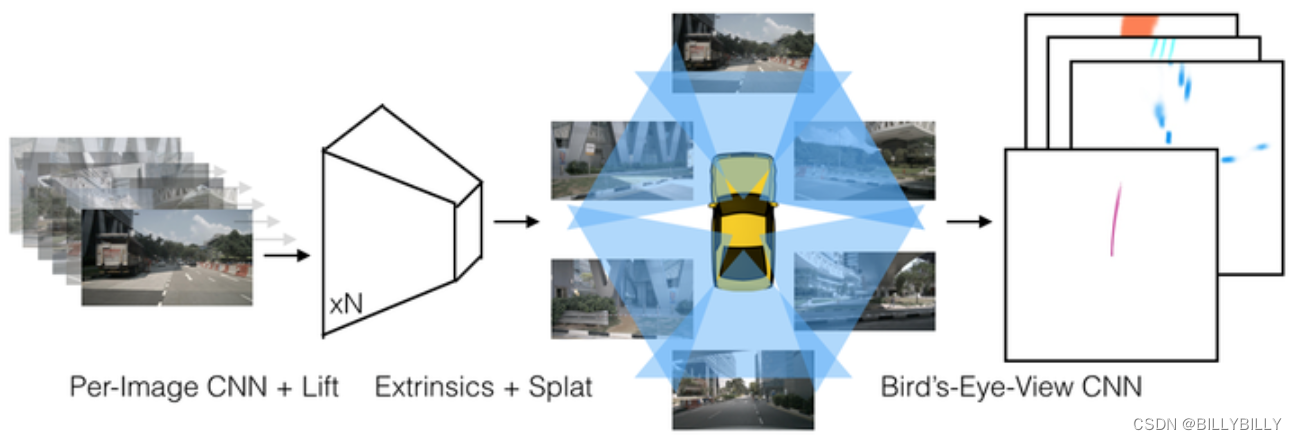
這是一個端到端架構,直接從任意數量的攝像頭數據提取給定圖像場景的鳥瞰圖表示。將每個圖像分別“提升(lift)”到每個攝像頭的視錐(frustum),然后將所有視錐“投放(splat)”到光柵化的鳥瞰圖網格中。這里要學習的是,如何表示圖像以及如何將所有攝像機的預測融合到場景的單個拼接表示,同時又能抵抗標定誤差。為學習運動規劃的密集表示,這里模型推斷的表示,“捕捉(shoot)”模板軌跡到網絡輸出的鳥瞰損失圖,從而實現可解釋的端到端運動規劃。
本文采用像素級深度分布,將圖像特征映射到BEV上。輸入圖像HW3 ,D代表離散深度維度,對于每個像素都有 (h,w,d) ,這樣我們模型預測結果 HWD 。同時對每個像素都會提取出長度為c的向量,和一個深度分布 的向量( 為歸一化的),c維度的特征,在D維度上進行重復,并乘上對應的 值,得到下圖。
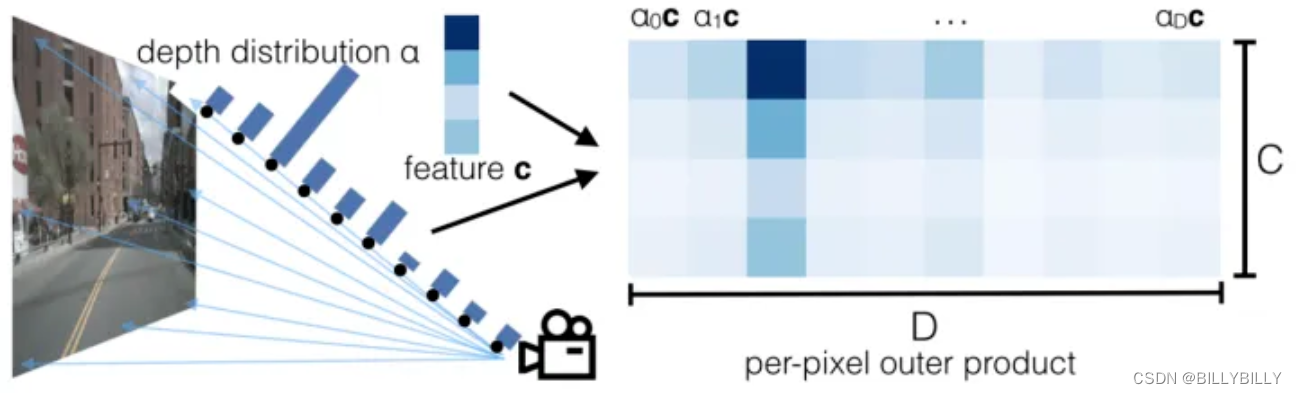
每個像素+深度值,得到一個 (x,y,z) 點,再像pointpillar一樣處理,每個點落在最近的pillar上,在高程上求sum pooling。整個過程,可以通過像OFT中的積分表來進行加速。不同相機之間,通過外參+depth來對齊。
lift是提升,即像pointpillar中特征通過pointnet來提升維度;splat為投放,即將特征放在BEV上。





A~F)



)
)








