目錄
01 學習目標
02 概念
2.1 強化學習
2.2?深度Q學習(Deep Q-Learning )
03 問題描述
04 算法中的概念及原理?
05?月球著陸器自動著陸的算法實現
?06 拓展:基于pytorch實現月球著陸器著陸
07 總結
寫在最前:關于強化學習及lunar lander問題有很多技術貼,作者尚未理解透徹,不作全面深入的原理講解,本文僅作吳恩達老師課程的課后代碼實現之用途!
01 學習目標
? ? ?(1)理解什么強化學習
? ? ?(2)利用深度Q學習(Deep Q-Learning)算法實現月球著陸器自動著陸
02 概念
2.1 強化學習
? ? ? ?強化學習(Reinforcement Learning,簡稱RL)是一種機器學習方法,主要研究智能體(agent)如何在環境中采取行動以最大化某種累積獎勵。在強化學習中,智能體通過與環境的交互來學習,即通過嘗試不同的動作并觀察結果,逐步優化其行為策略。
? ? ? ?強化學習的基本要素包括:
? ? ? ? ? ?1. 狀態(State):描述環境當前情況的信息。
? ? ? ? ? ?2. 動作(Action):智能體可以執行的操作。
? ? ? ? ? ?3. 獎勵(Reward):環境對智能體執行動作后的反饋,用于指導智能體的學習過程。
? ? ? ? ? ?4. 策略(Policy):智能體選擇動作的規則或策略,可以是確定性的或概率性的。
? ? ? ? ? ?5. 價值函數(Value Function):評估狀態或狀態-動作對的好壞,通常用于指導策略的改進。
? ? ? ? ? ?6. 模型(Model):可選,表示環境的狀態轉移和獎勵函數。
? ? ? ? 強化學習的目標是找到一個最優策略,使得智能體在長期運行中獲得的累積獎勵最大化。常見的強化學習算法有Q-Learning、Deep Q-Networks (DQN)、Policy Gradients、SARSA、DDPG、PPO(近端策略優化算法)等。強化學習在游戲、機器人控制、自動駕駛、推薦系統等多個領域都有廣泛的應用。例如,在AlphaGo中,深度強化學習被用來訓練圍棋AI,使其能夠戰勝世界頂級棋手。
2.2?深度Q學習(Deep Q-Learning )
? ? ? ?Deep Q-Learning 是一種強化學習方法,它將傳統的 Q-Learning 的概念擴展到了使用深度神經網絡來近似 Q 函數。在傳統的 Q-Learning 中,Q 值通常是在一個表格中存儲和更新的,這種方法在狀態空間有限且較小的情況下效果很好。然而,對于高維狀態空間或連續狀態空間,表格方法不再可行,因為所需的存儲量會變得非常龐大。而Deep Q-Learning 通過使用深度神經網絡,也就是Deep Q-Network作為函數逼近器來克服這一限制。
DQN 有以下2個關鍵技術點:
? ? (1)經驗回放(Experience Replay):DQN 使用經驗回放緩沖區存儲過去的經驗(狀態、動作、獎勵、下一個狀態),然后從中隨機抽取一批數據來訓練網絡,這有助于打破數據的相關性,避免過度擬合最近的數據。
? ? (2)目標網絡(Target Network):DQN 使用兩個神經網絡,一個是主網絡(或在線網絡),用于決策;另一個是目標網絡,用于計算目標 Q 值。目標網絡的參數定期從主網絡同步過來,這樣做是為了讓目標 Q 值的計算更加穩定,避免訓練過程中的振蕩。
03 問題描述
? ? ? ?這是一個經典的強化學習案例,旨在讓月球著陸器(Lunar Lander)通過算法自己學會如何安全地著陸到兩面小旗中間的平臺上。如下圖所示:

04 算法中的概念及原理?
? ? 先了解下動作空間(action space)和觀察空間(obersevation space)的概念:什么是 Gym 中的觀察空間(Observation Space)和動作空間(Action Space)?![]() https://zhuanlan.zhihu.com/p/658889348
https://zhuanlan.zhihu.com/p/658889348
? ? 著陸器的動作空間包括4個動作:
| 0:什么都不做 | 2:點火主引擎 |
| 1:點火左定向引擎 | 3:點火右定向引擎 |
? ? 著陸器的觀察空間包括8個狀態:
| x:著陸器的?x 坐標 | θ:著陸器的角度 |
| y:著陸器的?y坐標 | θ':著陸器的角速度 |
| x':著陸器在 x 方向的線速度 | l:著陸器的左腿是否與地面接觸(布爾值) |
| y':著陸器在 y 方向的線速度 | r:著陸器的右腿是否與地面接觸(布爾值) |
? ? 獎勵 Rewards的設計:
? ? ? ?每一步都會獲得一個獎勵。一個 episode(回合)總獎勵是該 episode 中所有步驟的獎勵之和。對于每一步,獎勵如下:
? ? ? 著陸器離著陸點越近/遠,獎勵增加/減少;
? ? ? 著陸器移動越慢/快,獎勵增加/減少;
? ? ? 著陸器傾斜度越大,獎勵減少;
? ? ??每個與地面接觸的腿獎勵增加10分;
? ? ? 每幀側引擎點火,獎勵減少0.03分;
? ? ? 每幀主引擎點火,獎勵減少0.3分;
? ? ? episode 因墜毀或安全著陸而額外獲得-100或+100分的獎勵。
如果一個 episode 得分至少為200分,則訓練停止。
? ? ? ?貝爾曼方程:
式中為動作-價值函數(action-value,Q函數),?Q函數表示在給定狀態?
下,采取動作?
后獲得的期望累積回報。R為當前狀態的獎勵,γ為折扣因子,s'、a'表示下一個狀態和動作。上式表示了agent在環境中總會選擇獎勵最大的動作,當執行動作次數足夠多時(i→∞),Q就是最優解"Q(s,a;w)"。根據Q函數建立的神經網絡稱為“Q-network”,Q網絡。
? ? ? ?算法的核心:
? ? ? ?算法中包含兩個神經網絡:一個是目標Q網絡(target Q network)、另一個是Q網絡(Q network)。兩個神經網絡結構一樣而參數不同,為“一前一后”關系,Q網絡更新快而目標Q網絡更新慢。不斷地訓練“目標Q網絡”與“Q網絡”,并通過控制兩者間損失來可達到降低更新速度、增強穩定性的目的。每個回合結束計算兩個Q之間的誤差,如下:
? ? ? ?每個回合結束agent會自動更新兩個Q網絡的參數,算法中為了agent表現穩定采用的“軟更新”技術,如下式:
? ? ? ?式中,為學習率,一般設置為非常小的值。
是目標Q網絡的參數,
是Q網絡的參數。這樣子,agent的目標Q網絡的新參數
、也就是新經驗中,有一大部分是基于之前回合的舊經驗
而僅小部分來自最近一個回合學到的新經驗
。
05?月球著陸器自動著陸的算法實現
? ? ? ?(1)導包
import time
from collections import deque, namedtupleimport gymnasium as gym
#import gym
import numpy as np
import PIL.Image
import tensorflow as tf
import utilsfrom pyvirtualdisplay import Display
from pyglet.gl import gl
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Input
from tensorflow.keras.losses import MSE
from tensorflow.keras.optimizers import Adam? ? (utils是吳恩達老師編寫的計算模塊,包括get_experiences、check_update_conditions、get_new_eps、get_action、update_target_network和plot_history等函數)
? ? ?(2)設置超參數
# 為TensorFlow設置隨機種子
tf.random.set_seed(utils.SEED)
# 設置超參數
MEMORY_SIZE = 100_000 # 設置經驗緩沖區的大小
GAMMA = 0.995 # 折扣因子
ALPHA = 1e-3 # 學習率
NUM_STEPS_FOR_UPDATE = 4 # 每4步執行一次學習更新? ? ?(3)模擬環境
# 加載月球模擬環境
env = gym.make('LunarLander-v2', render_mode='rgb_array')# 設置初始狀態
env.reset()
PIL.Image.fromarray(env.render())? ? ? LunarLander-v2是gym中模擬月球表面的虛擬環境。初始狀態為agent位于顯示窗口的中心頂部位置。運行以上代碼,結果如下:

? ? ? ?(4)設置狀態和動作
# 設置觀察和動作變量
state_size = env.observation_space.shape
num_actions = env.action_space.n# 獲取初始狀態
initial_state = env.reset()
# 選擇第1個動作
action = 0# step函數返回當前動作下的四個變量
next_state, reward, done, info, _= env.step(action)print('State Shape:', state_size)
print('Number of actions:', num_actions)
with np.printoptions(formatter={'float': '{:.3f}'.format}):print("Initial State:",initial_state)print("Action:",action)print("Next State:", next_state)print("Reward Received:", reward)print("Episode Terminated:", done)print("Info:", info)? ? ? ? 運行以上代碼,結果如下:
? ? ?
? ? ? ?在Open AI的Gym環境中,使用.step()方法來運行環境動態的單個時間步。在我們使用的gym版本中,.step()方法接受一個動作并返回五個值(最后1個為空):
? ? ? observation(object):在月球著陸器環境中,對應于包含著陸器位置和速度的numpy數組,即前面所說的觀測空間的狀態。
? ? ? reward (float):采取特定行動所獲得的獎勵。在月球著陸器環境中,對應于前面描述的獎勵。
? ? ? done (bool):當done為True時,它表示回合結束,可以重置環境進行下一回合了。
? ? ? Info (dictionary):用于調試的診斷信息。算法中并沒有使用這個變量。
? ? ?(5)神經網絡
# 創建 Q網絡
q_network = Sequential([ Input(shape=state_size),Dense(units=64,activation='relu', name='qL1'),Dense(units=64,activation='relu', name='qL2'),Dense(units=num_actions, name='qL3') ])# 創建目標 Q網絡
target_q_network = Sequential([Input(shape=state_size),Dense(units=64,activation='relu', name='tqL1'),Dense(units=64,activation='relu', name='tqL2'),Dense(units=num_actions, name='tqL3')])optimizer = Adam(learning_rate=ALPHA)? ? ? (6)經驗回放
# 將經驗存儲為命名元組
experience = namedtuple("Experience", field_names=["state", "action", "reward", "next_state", "done"])(在Python中,namedtuple是collections模塊中的一個函數,用于創建具有命名字段的小而簡單的類。它非常適合用來創建只讀的、輕量級的對象集合。Experience在這里被定義為一個namedtuple,用來存儲智能體在環境中的經歷,它有五個字段:state, action, reward, next_state, 和 done)
? ? ? ?定義損失函數:
def compute_loss(experiences, gamma, q_network, target_q_network):""" 損失函數Args:experiences: (tuple) 元組 ["state", "action", "reward", "next_state", "done"]gamma: (float) 折扣因子.q_network: (tf.keras.Sequential) Q網絡,用于預測q_valuestarget_q_network: (tf.keras.Sequential) 目標Q網絡,用于預測y_targetsReturns:loss: (TensorFlow Tensor(shape=(0,), dtype=int32)) 返回目標Q網絡和Q網絡之間的均方誤差."""# 返回經驗states, actions, rewards, next_states, done_vals = experiences# 計算目標Q網絡的最大值 max Q^(s,a)max_qsa = tf.reduce_max(target_q_network(next_states), axis=-1)# 貝爾曼方程計算目標Q網絡的值y_targets = rewards + gamma * max_qsa * (1 - done_vals)# 獲得Q網絡估計值 q_valuesq_values = q_network(states)q_values = tf.gather_nd(q_values, tf.stack([tf.range(q_values.shape[0]),tf.cast(actions, tf.int32)], axis=1))# 計算loss loss = MSE(y_targets, q_values)return loss? ? ? (7)更新網絡參數
@tf.function # 裝飾器,可以將Python函數轉換為TensorFlow圖結構,函數中的所有操作都會在TensorFlow圖中執行
def agent_learn(experiences, gamma):"""更新Q網絡的權重參數.Args:experiences: (tuple) 元組["state", "action", "reward", "next_state", "done"]gamma: (float) 折扣因子."""# 計算損失函數with tf.GradientTape() as tape:loss = compute_loss(experiences, gamma, q_network, target_q_network)# 計算梯度gradients = tape.gradient(loss, q_network.trainable_variables)# 更新Q網絡的權重參數optimizer.apply_gradients(zip(gradients, q_network.trainable_variables))# 更新目標Q網絡的權重參數utils.update_target_network(q_network, target_q_network)? ? ? ?(8)訓練智能體(agent)
start = time.time() # 開始計時num_episodes = 2000 # 訓練回合總數
max_num_timesteps = 1000 # 每個回合訓練步數total_point_history = []num_p_av = 100 # number of total points to use for averaging
epsilon = 1.0 # ε-greedy策略的初始值# 創建經驗緩沖區
memory_buffer = deque(maxlen=MEMORY_SIZE)# target Q network的初始權重參數設置為與Q-Network相同
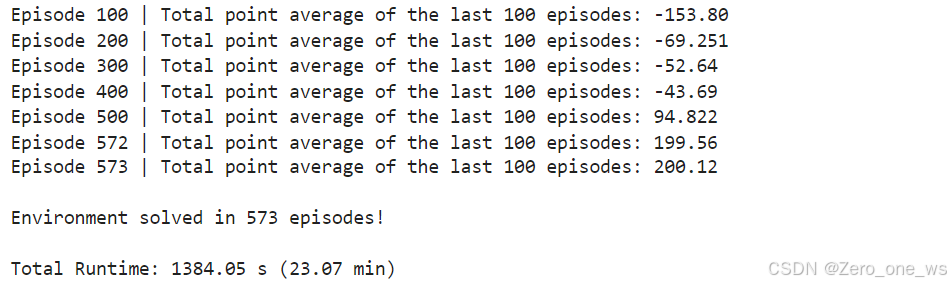
target_q_network.set_weights(q_network.get_weights())for i in range(num_episodes):# 每個回合開始時,重設環境得到初始狀態state = env.reset()[0]total_points = 0for t in range(max_num_timesteps):# 使用ε-greedy策略,在當前狀態s選擇一個動作astate_qn = np.expand_dims(state, axis=0)q_values = q_network(state_qn)action = utils.get_action(q_values, epsilon)# 計算采取當前動作a可得到的獎勵r,及下個狀態s'next_state, reward, done, info, _ = env.step(action)# 儲存經驗元組 (S,A,R,S')至經驗緩沖區memory_buffer.append(experience(state, action, reward, next_state, done))# 通過當前步數和緩沖區數據量判別是否達到更新條件update = utils.check_update_conditions(t, NUM_STEPS_FOR_UPDATE, memory_buffer)if update:# 隨機選取經驗樣本experiences = utils.get_experiences(memory_buffer)# 梯度下降法更新網絡參數agent_learn(experiences, GAMMA)state = next_state.copy()total_points += rewardif done:breaktotal_point_history.append(total_points)av_latest_points = np.mean(total_point_history[-num_p_av:])# 更新εepsilon = utils.get_new_eps(epsilon)print(f"\rEpisode {i+1} | Total point average of the last {num_p_av} episodes: {av_latest_points:.2f}", end="")if (i+1) % num_p_av == 0:print(f"\rEpisode {i+1} | Total point average of the last {num_p_av} episodes: {av_latest_points:.2f}")# 如果最近100個回合的平均分超過200分,停止訓練if av_latest_points >= 200.0:print(f"\n\nEnvironment solved in {i+1} episodes!")q_network.save('lunar_lander_model.keras')breaktot_time = time.time() - startprint(f"\nTotal Runtime: {tot_time:.2f} s ({(tot_time/60):.2f} min)")# Plot the point history
utils.plot_history(total_point_history)? ? ? ? 運行以上代碼,結果如下:
? ? ?

? ? ? ? (9)訓練過程保存為視頻
import logging
import imageio
import base64
import IPythonlogging.getLogger().setLevel(logging.ERROR)def create_video(filename, env, q_network, fps=30):with imageio.get_writer(filename) as video:done = Falsestate = env.reset()[0]frame = env.render()#frame = env.render(mode="rgb_array")video.append_data(frame)while not done: state = np.expand_dims(state, axis=0)q_values = q_network(state)action = np.argmax(q_values.numpy()[0])state, _, done, _, _ = env.step(action)frame = env.render()frame = PIL.Image.fromarray(frame)video.append_data(frame)def embed_mp4(filename):"""Embeds an mp4 file in the notebook."""video = open(filename,'rb').read()b64 = base64.b64encode(video)tag = '''<video width="840" height="480" controls><source src="data:video/mp4;base64,{0}" type="video/mp4">Your browser does not support the video tag.</video>'''.format(b64.decode())return IPython.display.HTML(tag)filename = "./videos/lunar_lander.mp4"
create_video(filename, env, q_network)
embed_mp4(filename)最后一步,我這里保存視頻失敗,生成的視頻打不開,哪位大佬知道原因的可以在評論區解答下!
?06 拓展:基于pytorch實現月球著陸器著陸
? ? ? ? 由于拿到吳恩達老師課程的代碼后,折騰幾天都跑不通,終于能跑了又不能生成視頻,就先找了個大神的pytorch代碼跑了下,可以正常訓練和保存視頻,基于tensorflow和pytorch的步驟都是一樣的。鏈接放在下面:
【機器學習】強化學習(六)-DQN(Deep Q-Learning)訓練月球著陸器示例-CSDN博客![]() https://blog.csdn.net/cxyhjl/article/details/135812771
https://blog.csdn.net/cxyhjl/article/details/135812771
07 總結
? ? (1)強化學習的高級之處在于:只需給定目標、設置好獎勵機制,agent就可以自主學習完成任務,特斯拉最新的Optimus機器人身上就采用了強化學習。
? ? (2)強化學習實現著陸器著陸月球的主要內容包括:超參數、虛擬環境、兩個Q神經網絡、經驗重放緩沖區、epsilon貪婪策略、軟更新、訓練agent,前6塊內容柔和進了最后一步“訓練agent”中,強化學習中很重要的獎勵設置本文沒有涉及,因為lunar lander的獎勵機制在采用的env.step()方法中.。








: Gradle 插件開發與發布)


)


(11.8排列活動順序))




