LLM現在能夠自動評估較長文本中的事實真實性
源碼地址:https://github.com/google-deepmind/long-form-factuality
論文地址:https://arxiv.org/pdf/2403.18802.pdf
這篇論文是關于谷歌DeepMind的,提出了新的數據集、評估方法和衡量標準,用于對 LLM 長式事實性(長式事實性)和信息準確性進行基準測試。
研究要點包括:
- 挑戰:沒有數據集、評估方法或指標來評估LLM長式產出的真實性
- 解決方法:數據集 “LongFact”、自動評估方法 "SAFE "和評估指標 “F1@K”。
- 第 1 點:上述方法可以量化 “法律碩士長式成果的事實性”。
- 第 2 點:模型越大,越長的陳述越符合事實。
換句話說,這項研究可用于自動評估 LLM 輸出的長式信息的準確性,并為 LLM 的未來發展提供參考。
LLM業績評估的現狀
近年來,法律碩士的成績有了顯著提高,但同時他們也存在"導致幻覺 "和 "說謊"的問題。特別是,"輸出長句時準確度的顯著降低 "是一個關鍵問題。其中一個原因是沒有數據集可以評估法律碩士長篇回答問題的真實性。這是因為現有的大多數數據集主要是要求人們回答簡短問題的問答,因此很難評估長式答案的真實性。此外,還沒有確定量化長刑期事實的方法或指標,因此無法對其進行成功評估。
本研究提出的方法。
如前所述,該研究提出了以下三種對長篇法律碩士論文事實性的自動評估方法。
- LongFact
- SAFE(搜索增強事實評估器)。
- F1@K
讓我們依次來詳細了解一下。
數據集: LongFact
LongFact 是本文提出的新問答數據集。
主要功能包括
- 包括 38 個主題的 2,280 個事實調查問題
- 主題分為四類:STEM(科學、技術、工程和數學)、社會科學、人文科學和其他。
- 包括需要長時間回答的問題
- 使用 GPT-4生成問題。
- 從生成的問題中刪除重復問題,并為每個主題隨機抽取 30 個問題
下圖左側顯示的是 “包含在 LongFact 中的問題主題百分比”,右側顯示的是 “現有數據集與 LongFact 的比較”。
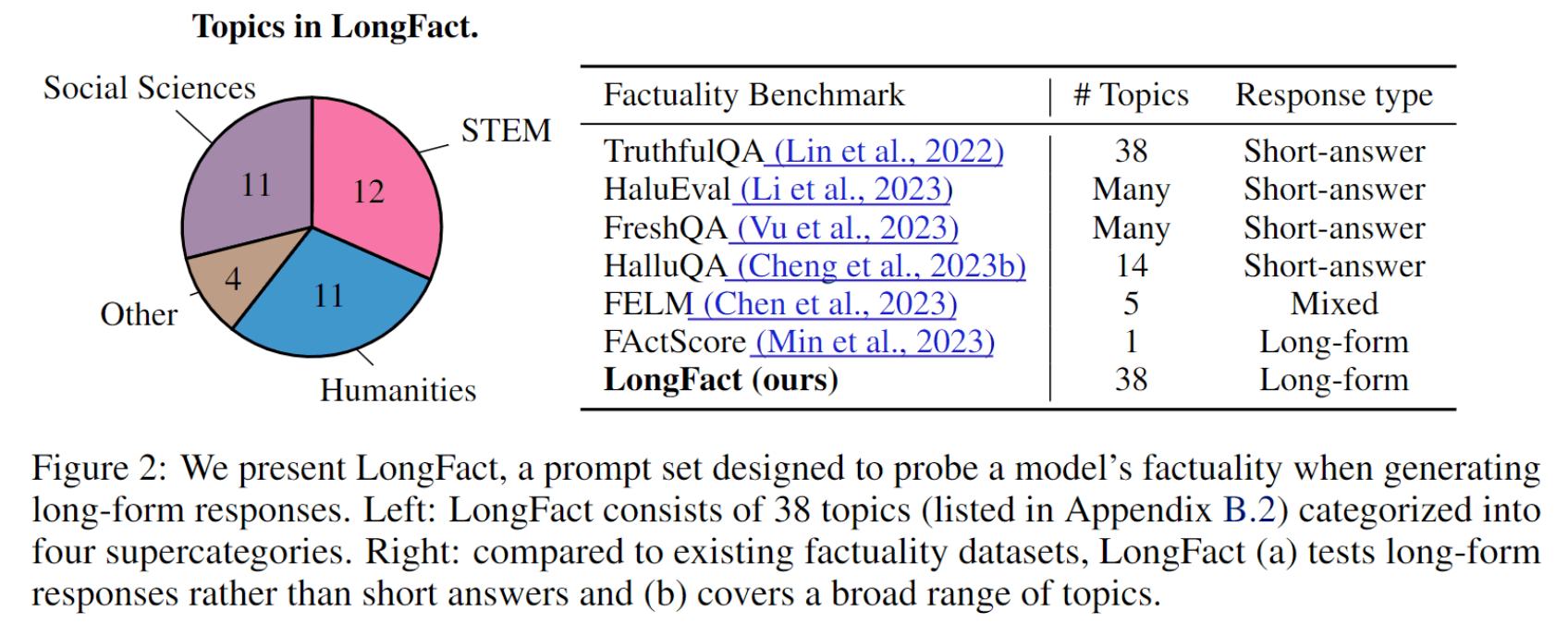
與現有的數據集相比,LongFact 是可用于評估長句事實性的數據集中主題數量最多的數據集。順便提一下,LongFact 在 GitHub 上公開發布,任何人都可以使用。因此,它有望成為未來 LLM 研究的基礎。
評估方法:SAFE(Search-Augmented Factuality Evaluator)
SAFE(Search-Augmented Factuality Evaluator)是本文提出的一種用于自動評估長格式事實性(LLM)的方法。
下圖是 SAFE 的概覽。
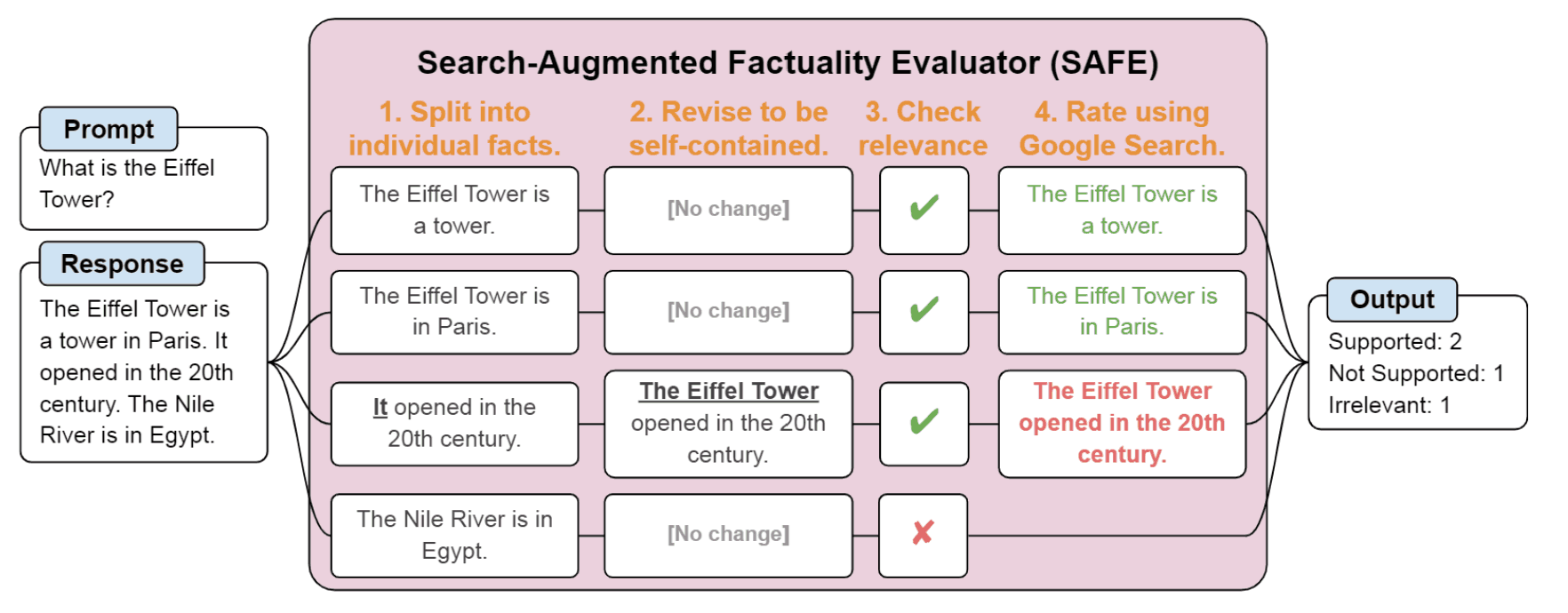
SAFE 的評估按以下順序進行
- 向 LLM 輸入 “提示”,并讓它輸出 “響應”。
- 使用 LLM 將回復文本分解為若干 “要素”。
- 使用 LLM 確定 “分解的各個元素是否與輸入的提示相關”。
- 使用已確定相關的 "單個元素 "的 LLM 生成 Google 搜索查詢。
- 使用生成的查詢進行谷歌搜索
- 確定谷歌搜索結果中的 "個別元素 "是否為正確信息(以及是否有充分依據)。
實質上,如下圖所示,輸出文本被分解為其元素、查詢生成和谷歌搜索,從搜索結果中尋找支持事實的信息。
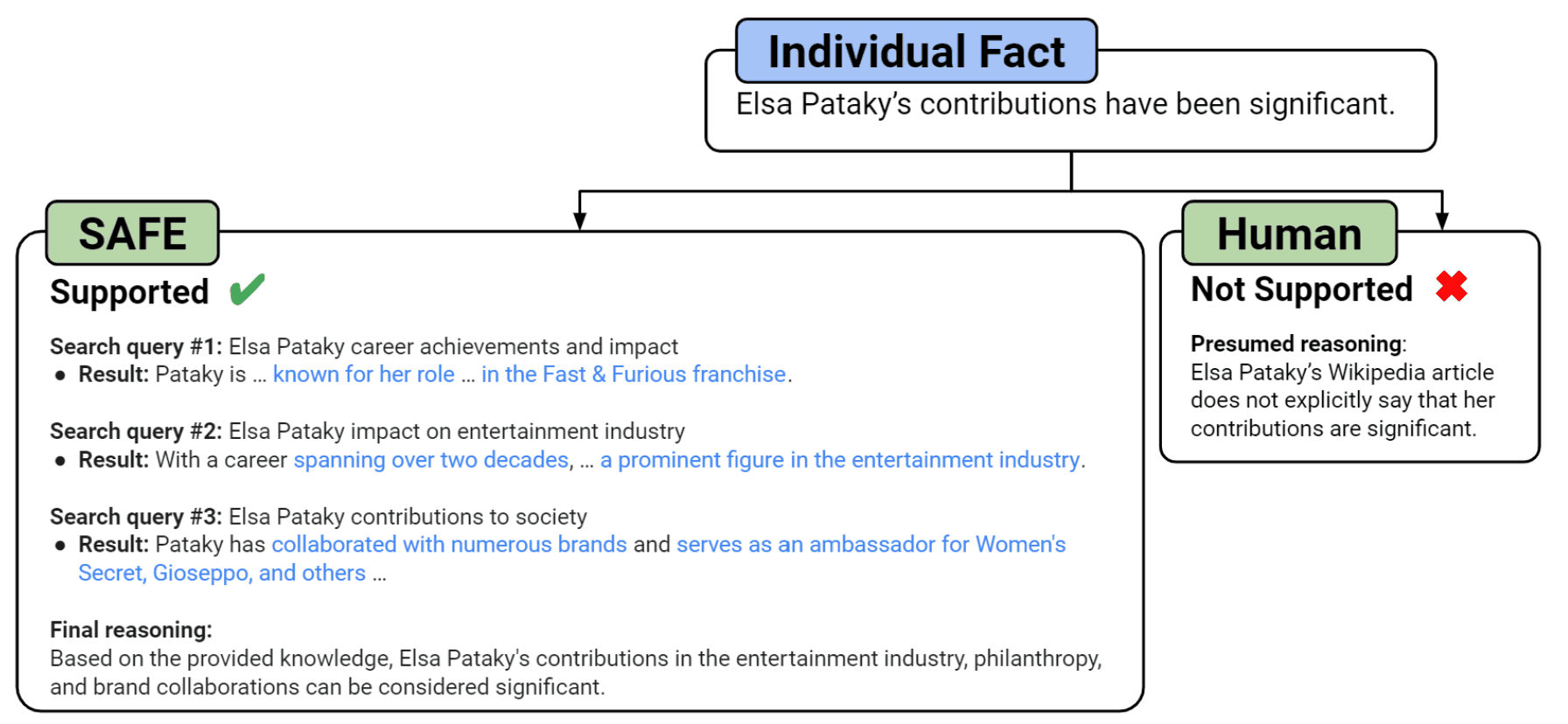
當然,"正確信息元素數量 "越多,LLM 輸出的響應就越可靠
當作者為 SAFE 與人類意見不一致的 100 個事實分配正確標簽時,他們發現 SAFE 的正確率為 76%,而人類的正確率僅為 19%。此外,SAFE 的表現優于人類,而成本卻不到人類評分者的二十分之一。
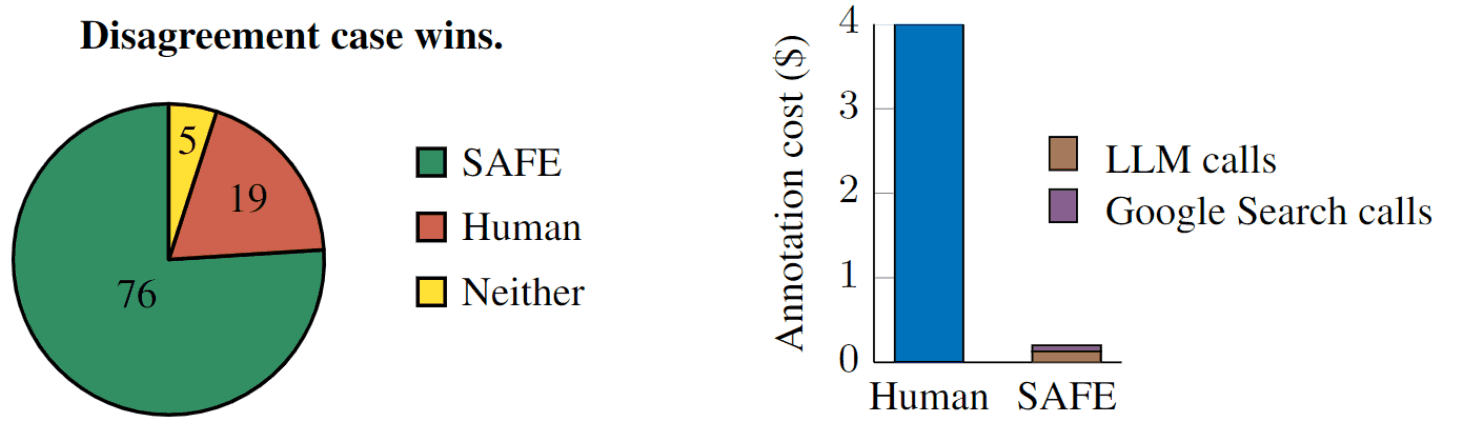
這意味著,SAFE 將被證明成本相對較低,準確性較高。
順便提一下,SAFE 的實施代碼也在GitHub 上以開源方式提供,任何人都可以使用。
評價指標:F1@K
F1@K 是一個同時考慮擬合率(精確度)和重復率(召回率)的指標。其具體定義如下
- 一致率 Prec(y):輸出 y 中 "正確信息要素 "的百分比
- 復制率 RK(y):輸出 y 中 "正確信息元素 "數量的最小值 S(y) 除以用戶預期偏好的輸出句子長度(正確信息元素數量)的數量 K min(S(y)/K,1)
而 F1@K 則將擬合度和可重復性與下式相結合。
如果 S(y)>0:.
F1@K(y)=2?Prec(y)?RK(y)Prec(y)+RK(y)
如果 S(y)=0:.
F1@K(y)=0。
換句話說,F1@K 的值介于 0 和 1 之間,越接近 1 表示長文本的事實性越強�
K 是一個超參數,代表用戶偏好的輸出文本長度(正確信息元素的數量)。假設用戶認為最多 K 個 "信息正確元素 "越多越好,但對超過 K 個的 "信息正確元素 "則漠不關心。
例如,如果 K=64,用戶認為 64 以內的 "正確信息要素 "越多越好,但對第 65 條及以后的信息則漠不關心。
K 值需要根據用戶的偏好來設置。
這樣不僅可以評估信息是否符合事實,還可以評估信息是否包含足夠的信息量。
事實上,本文使用 F1@K 對 13 個 LLM 進行了基準測試,并比較了這些模型在長句中的實際表現。
使用該數據集和評估指標及方法對 LLM 性能進行比較。
實驗細節
LongFact 對 13 個 LLM(Gemini、GPT、Claude 和 PaLM-2 系列)進行了基準測試,以研究LLM 中"模型大小 "與 "長文本事實性 "之間的關系。
具體來說,每個模型都會針對從 LongFact 中隨機抽取的 250 個問題生成輸出結果,并使用 SAFE 進行評估。
然后,他們對 F1@K(K=64 和 K=178)的性能進行了量化和比較。
結果
實驗結果表明,模型越大,越長的陳述越符合事實。
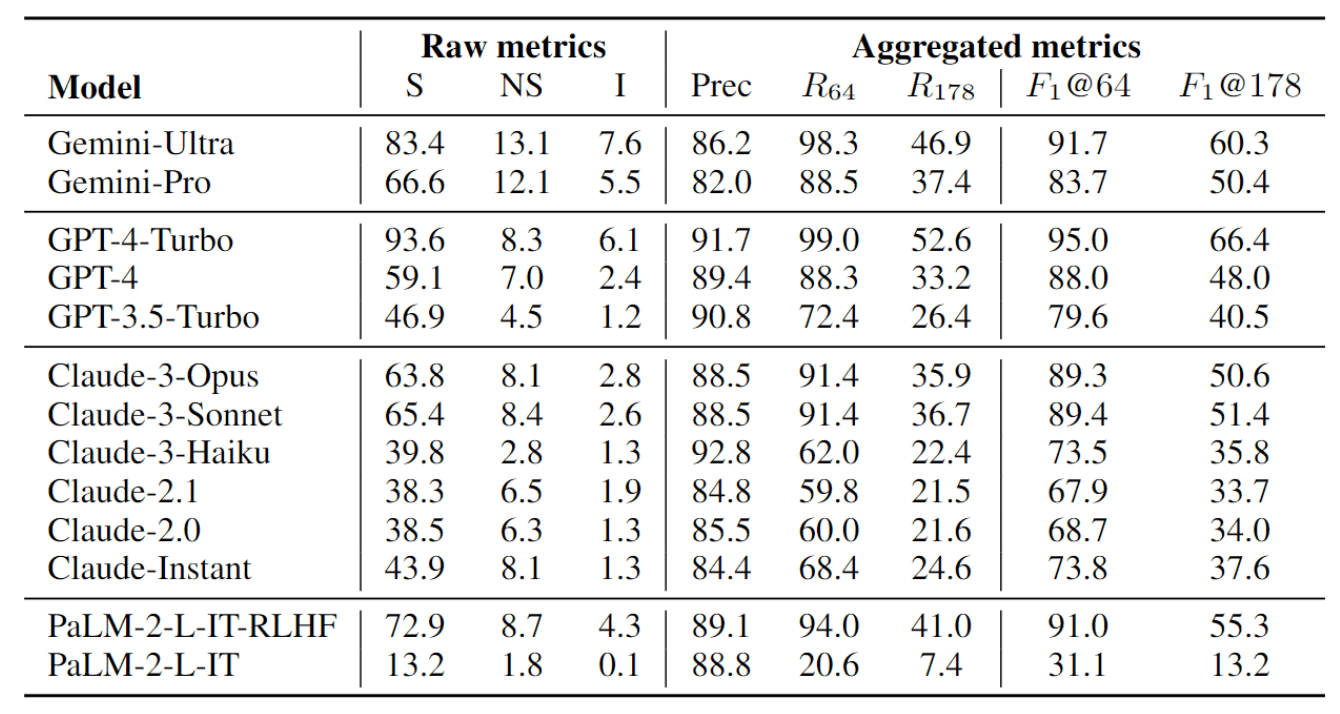
例如,GPT-4-Turbo 的事實性高于 GPT-4,GPT-4 的事實性高于 GPT-3.5-Turbo。我們還可以看到,Gemini-Ultra 的事實性高于 Gemini-Pro,PaLM-2-L-IT-RLHF 的事實性高于 PaLM-2-L-IT。
此外,無論 K 值如何,三個最符合事實的模型是 GPT-4-Turbo、Gemini-Ultra 和 PaLM-2-L-IT-RLHF。
期望這項研究將成為未來法律碩士發展的基礎
本文介紹了谷歌 DeepMind 關于 "正確評估長篇法律碩士論文中信息的事實性和準確性的方法 "的研究。本研究提出了 LongFact、自動評估方法 SAFE 和 F1@K 指標,用于評估長句中 LLM 的事實性。這些將有助于澄清長篇文本中大規模語言模型的事實性現狀,并為今后的研究提供基礎。
本研究的局限性如下:
- LongFact 和 SAFE 依賴于 LLM,因此直接受到所用 LLM 功能的影響
- SAFE 依靠谷歌搜索,可能無法正確評估某些事實
- 至于 SAFE 的性能是否與 "人類專家級評估員 "相當或更好,尚未進行測試。
因此,他們計劃今后開展有關學習、微調和使用外部工具的研究,以提高較長法律碩士課程的事實性。他還表示,SAFE "依賴語言模型 "的改進以及根據 LLM 內部知識評估較長文本中事實準確性的方法的開發也在計劃階段。


和ROW_NUMBER()函數的對比)
)








)






