在使用Apache SeaTunnel時,我遇到了一個寫入S3文件的報錯問題。通過深入調試和分析,找到了問題所在,并提出了相應的解決方案。 
本文將詳細介紹報錯情況、參考資料、解決思路以及后續研究方向,希望對大家有幫助!
一、詳細報錯
2024-04-12 20:44:18,647 ERROR [.c.FileSinkAggregatedCommitter] [hz.main.generic-operation.thread-43] - commit aggregatedCommitInfo error, aggregatedCommitInfo = FileAggregatedCommitInfo(transactionMap={/xugurtp/seatunnel/tmp/seatunnel/831147703474847745/476b6a6fc7/T_831147703474847745_476b6a6fc7_0_1={/xugurtp/seatunnel/tmp/seatunnel/831147703474847745/476b6a6fc7/T_831147703474847745_476b6a6fc7_0_1/NON_PARTITION/output_params_0.json=/xugurtp/seatunnel/tmp/6af80b38f3434aceb573cc65b9cd12216a/39111/output_params_0.json}}, partitionDirAndValuesMap={}) java.lang.IllegalStateException: Connection pool shut down
二、參考資料
- HADOOP-16027:https://issues.apache.org/jira/browse/HADOOP-16027
- CSDN Blog:https://blog.csdn.net/a18262285324/article/details/112470363
- AWS SDK Java Issue #2337:https://github.com/aws/aws-sdk-java/issues/2337
- Amazon SQS Java Messaging Lib Issue #96:https://github.com/awslabs/amazon-sqs-java-messaging-lib/issues/96
- 博客園:https://www.cnblogs.com/xhy-shine/p/10772736.html
三、解決思路
1. 遠程調試
在本地IDEA中進行debug未發現報錯,但在服務器上執行時卻報錯,因此決定進行遠程debug。執行以下命令添加JVM參數:
-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005實際命令是:
java -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005 -Dhazelcast.client.config=/opt/module/seatunnel-2.3.4/config/hazelcast-client.yaml -Dseatunnel.config=/opt/module/seatunnel-2.3.4/config/seatunnel.yaml -Dhazelcast.config=/opt/module/seatunnel-2.3.4/config/hazelcast.yaml -Dlog4j2.configurationFile=/opt/module/seatunnel-2.3.4/config/log4j2_client.properties -Dseatunnel.logs.path=/opt/module/seatunnel-2.3.4/logs -Dseatunnel.logs.file_name=seatunnel-starter-client -Xms1024m -Xmx1024m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/seatunnel/dump/zeta-client -XX:MaxMetaspaceSize=1g -XX:+UseG1GC -cp /opt/module/seatunnel-2.3.4/lib/*:/opt/module/seatunnel-2.3.4/starter/seatunnel-starter.jar org.apache.seatunnel.core.starter.seatunnel.SeaTunnelClient -e local --config job/s3_sink.conf -cn xxx2. 定位問題
通過調試發現問題出在hadoop-aws使用的緩存連接池對象。關鍵在于if判斷部分,如果上游傳遞了fs.s3a.impl.disable.cache=true,則不使用緩存。深入debug發現:有時hadoopConf.getSchema獲取的不是s3a而是s3n。
s3和s3n / s3a的區別
- s3:基于塊的文件系統
- s3n:基于對象存儲的文件系統,支持高達5GB的對象
- s3a:基于對象存儲的文件系統,支持高達5TB的對象,并具有更高的性能
在配置文件中設置的是s3a,但實際獲取到的是s3n,這顯然不合理。
3. 深入挖掘
我仔細看了一下報錯的截圖發現:

確實是commit期間報的錯:那么也就是說commit初始化s3conf并沒有走buildWithConfig方法,而是用的默認值,而且我根本沒找到commit里面有new s3Conf的代碼,再次debug看看誰去重新初始化了S3Conf:

定位到這里就很頭疼了,已經涉及到引擎層而非插件層面了,涉及到classloader的使用以及反序列化操作:

反序列化代碼:
logicalDag =CustomClassLoadedObject.deserializeWithCustomClassLoader(nodeEngine.getSerializationService(),classLoader,jobImmutableInformation.getLogicalDag());很明顯可以看出,S3Conf(靜態類)被重新初始化了,導致SHEMA被重新賦值成s3n了
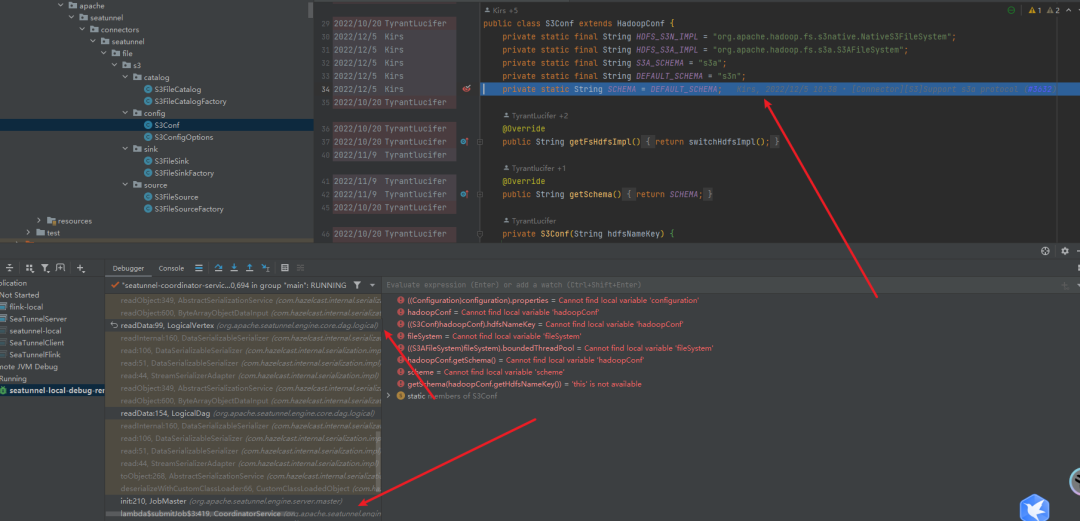
因為s3conf它本身的屬性都是靜態的,而對classloader反序列化是時會重新加載靜態屬性的,所以導致shema被重新賦值為默認s3n了
綜上所述
除了source和sink階段,AggregatedCommit操作也會寫入s3File。錯誤發生在commit期間,說明初始化S3Conf時并沒有走buildWithConfig方法,而是使用了默認值。
由于S3Conf類的屬性是靜態的,反序列化時會重新加載靜態屬性,導致SCHEMA被重新賦值為默認的s3n。
資料參考:https://wiki.apache.org/hadoop/AmazonS3
s3:基于Block塊的文件系統
S3 Block FileSystem(URI scheme:s3)由S3支持的基于塊的文件系統。 文件存儲為塊,就像HDFS一樣。 這樣可以有效地實現重命名。 此文件系統需要您為文件系統專用一個存儲桶 - 您不應使用包含文件的現有存儲桶,或將其他文件寫入同一存儲區。 此文件系統存儲的文件大于5GB,但不能與其他S3工具進行互操作。
s3n:基于對象存儲的文件系統
S3 Native FileSystem(URI scheme:s3n)用于在S3上讀取和寫入常規文件的本機文件系統。 這個文件系統的優點是您可以訪問使用其他工具編寫的S3上的文件。 相反,其他工具可以訪問使用Hadoop編寫的文件。 缺點是S3的文件大小限制為5GB。
s3a:基于對象存儲的文件系統
S3A(URI方案:s3a)是S3 Native,s3n fs的繼承者,S3a:系統使用Amazon的庫與S3進行交互。 這允許S3A支持較大的文件(不超過5GB的限制),更高的性能操作等等。 文件系統旨在替代S3 Native:從s3n:// URL可訪問的所有對象也應該通過替換URL模式從s3a訪問。
public class S3Conf extends HadoopConf {private static final String HDFS_S3N_IMPL = "org.apache.hadoop.fs.s3native.NativeS3FileSystem";private static final String HDFS_S3A_IMPL = "org.apache.hadoop.fs.s3a.S3AFileSystem";private static final String S3A_SCHEMA = "s3a";private static final String DEFAULT_SCHEMA = "s3n";private static String SCHEMA = DEFAULT_SCHEMA;@Overridepublic String getFsHdfsImpl() {return switchHdfsImpl();}@Overridepublic String getSchema() {return SCHEMA;}private S3Conf(String hdfsNameKey) {super(hdfsNameKey);}public static HadoopConf buildWithConfig(Config config) {HadoopConf hadoopConf = new S3Conf(config.getString(S3ConfigOptions.S3_BUCKET.key()));String bucketName = config.getString(S3ConfigOptions.S3_BUCKET.key());if (bucketName.startsWith(S3A_SCHEMA)) {SCHEMA = S3A_SCHEMA;}HashMap<String, String> s3Options = new HashMap<>();putS3SK(s3Options, config);if (CheckConfigUtil.isValidParam(config, S3ConfigOptions.S3_PROPERTIES.key())) {config.getObject(S3ConfigOptions.S3_PROPERTIES.key()).forEach((key, value) -> s3Options.put(key, String.valueOf(value.unwrapped())));}s3Options.put(S3ConfigOptions.S3A_AWS_CREDENTIALS_PROVIDER.key(),config.getString(S3ConfigOptions.S3A_AWS_CREDENTIALS_PROVIDER.key()));s3Options.put(S3ConfigOptions.FS_S3A_ENDPOINT.key(),config.getString(S3ConfigOptions.FS_S3A_ENDPOINT.key()));hadoopConf.setExtraOptions(s3Options);return hadoopConf;}public static HadoopConf buildWithReadOnlyConfig(ReadonlyConfig readonlyConfig) {Config config = readonlyConfig.toConfig();HadoopConf hadoopConf = new S3Conf(readonlyConfig.get(S3ConfigOptions.S3_BUCKET));String bucketName = readonlyConfig.get(S3ConfigOptions.S3_BUCKET);if (bucketName.startsWith(S3A_SCHEMA)) {SCHEMA = S3A_SCHEMA;}HashMap<String, String> s3Options = new HashMap<>();putS3SK(s3Options, config);if (CheckConfigUtil.isValidParam(config, S3ConfigOptions.S3_PROPERTIES.key())) {config.getObject(S3ConfigOptions.S3_PROPERTIES.key()).forEach((key, value) -> s3Options.put(key, String.valueOf(value.unwrapped())));}s3Options.put(S3ConfigOptions.S3A_AWS_CREDENTIALS_PROVIDER.key(),readonlyConfig.get(S3ConfigOptions.S3A_AWS_CREDENTIALS_PROVIDER).getProvider());s3Options.put(S3ConfigOptions.FS_S3A_ENDPOINT.key(),readonlyConfig.get(S3ConfigOptions.FS_S3A_ENDPOINT));hadoopConf.setExtraOptions(s3Options);return hadoopConf;}private String switchHdfsImpl() {switch (SCHEMA) {case S3A_SCHEMA:return HDFS_S3A_IMPL;default:return HDFS_S3N_IMPL;}}private static void putS3SK(Map<String, String> s3Options, Config config) {if (!CheckConfigUtil.isValidParam(config, S3ConfigOptions.S3_ACCESS_KEY.key())&& !CheckConfigUtil.isValidParam(config, S3ConfigOptions.S3_SECRET_KEY.key())) {return;}String accessKey = config.getString(S3ConfigOptions.S3_ACCESS_KEY.key());String secretKey = config.getString(S3ConfigOptions.S3_SECRET_KEY.key());if (S3A_SCHEMA.equals(SCHEMA)) {s3Options.put("fs.s3a.access.key", accessKey);s3Options.put("fs.s3a.secret.key", secretKey);return;}// default s3ns3Options.put("fs.s3n.awsAccessKeyId", accessKey);s3Options.put("fs.s3n.awsSecretAccessKey", secretKey);}
}參考了反序列的知識才了解到這個情況:
當對一個包含靜態成員的類進行反序列化時,靜態成員不會恢復為之前的狀態,而是保持在其初始狀態。任何靜態變量的值都是與該類本身相關的,
4. 解決方案
1.去掉
stastic修飾,把有參構造換成無參構造和靜態工廠方法:2.保留
stastic靜態方法,使用getSchema方法代替靜態屬性調用:
由此可見,代碼中的細節問題,即使看似微不足道,也可能引發嚴重的后果。一個簡單的靜態修飾符的誤用,不僅能導致程序行為異常,更可能導致系統穩定性和安全性的大問題。
相關的issues已提交,大家有興趣可以查看:
[bigfix][S3 File]:Change the [SCHEMA] attribute of the [S3CONF class] to be non-static to avoid being reassigned after deserialization by LeonYoah · Pull Request #6717 · apache/seatunnel (github.com)
[Bug] [S3File] [zeta-local] Error writing to S3File in version 2.3.4:: Java lang. An IllegalStateException: Connection pool shut down · Issue #6678 · apache/seatunnel (github.com)
四、有待研究
1.為什么只有local模式會報錯:
推測可能是cluster模式是分布式的,每個算子分布在不同的機器上,所以本地緩存不會被使用,類似于沒有走緩存。
2.為什么本地IDEA執行local模式卻沒問題
可能是Windows和Linux的線程調度機制不同導致的。
結論
通過這次對Apache SeaTunnel S3 File寫入報錯問題的分析與解決,希望這些經驗能幫助到遇到類似問題的開發者,同時也提醒大家在處理分布式系統時注意細節問題,以免引發不必要的故障。
本文由 白鯨開源科技 提供發布支持!





:堆排序)













