在接觸過大量的傳統關系型數據庫后你可能會有一些新的問題: 無法整理成表格的海量數據該如何儲存? 在數據非常稀疏的情況下也必須將數據存儲成關系型數據庫嗎? 除了關系型數據庫我們是否還有別的選擇以應對Web2.0時代的海量數據?
如果你也曾經想到過這些問題, 那么HBase將是其中的一個答案, 它是非常經典的列式存儲數據庫. 本文首先介紹HBase的由來以及其與關系數據庫的區別, 其次介紹其訪問接口、數據模型、實現原理和運行機制. 即便之前沒有接觸過HBase的相關知識也不影響閱讀該文章.

如果想了解其他的非關系型數據庫也可以查看我的博客文章:NoSQL數據庫
概述
HBase是谷歌公司BigTable的開源實現. 而BigTable是一個分布式存儲系統, 使用谷歌分布式文件系統GFS作為底層存儲, 主要用來存儲非結構化和半結構化的松散數據. HBase的目標是處理非常龐大的表, 可以通過水平擴展的方式利用廉價計算機集群處理超過10億行數據和百萬列元素組成的數據表.
GFS、HDFS、BigTable、HBase的關系:
HDFS是GFS的開源實現. HBase是BigTable的開源實現.
GFS是BigTable的底層文件系統, BigTable的數據存儲在GFS上.
HDFS是HBase的底層存儲方式. 雖然HBase可以使用本地文件系統, 但是為了提高數據可靠性一般還是會選擇HDFS作為底層存儲.
HBase和BigTable底層技術對應關系
| 項目 | BigTable | HBase |
|---|---|---|
| 文件存儲系統 | GFS | HDFS |
| 海量數據處理系統 | MapReduce | Hadoop MapReduce |
| 協同服務系統 | Chubby | Zookeeper |
與傳統的數據庫相比主要區別在于:
- 數據類型: 關系數據庫采用關系模型, HBase則采用更加簡單的數據模型–將數據存儲為未經解釋的字符串.
- 數據操作: 關系數據庫通常包括豐富的操作, 涉及復雜的多表連接. HBase則不存在復雜的多表關系, 只有簡單的增刪查改.
- 存儲模式: 關系數據庫是基于行模式存儲的, 元組或行被連續地存儲在磁盤中. HBase是基于列存儲的.
- 數據索引: 關系數據庫可以針對不同列構建復雜的多個索引以提高訪問效率. HBase則只有一個索引–行鍵.
- 數據維護: 關系數據庫中更新操作會用新值替換舊值. HBase則會保留舊數據, 僅僅生成一個新的版本.
- 可伸縮性: 關系數據庫很難進行橫向擴展, 縱向擴展的空間也比較有限. HBase作為分布式數據庫可以輕易地通過增加集群中的機器數量來達到性能的伸縮.
訪問接口
HBase提供了多種訪問方式, 不同的方式適用于不同的場景.
| 類型 | 特點 | 場合 |
|---|---|---|
| Native Java API | 最常規高效的訪問方式 | 適合Hadoop MapReduce作業并行批處理HBase表數據 |
| HBase Shell | HBase的命令行工具, 最簡單的接口 | 適合HBase管理 |
| Thrift Gateway | 利用Thrift序列化技術, 支持C++, PHP, Python等多種語言 | 適合其他異構系統訪問HBase |
| REST Gateway | 解除語言限制 | 支持REST風格的HTTP API訪問HBase |
| Pig | 使用Pig Latin流式編程語言來處理HBase的數據 | 適合做數據統計 |
| Hive | 簡單 | 可以用類似SQL語言的方式來訪問 |
數據模型
數據模型是一個數據庫產品的核心, 接下來將介紹HBase列族數據模型并闡述HBase數據庫的概念視圖和物理視圖的差異.
相關概念
HBase實際上是一個稀疏、多維、持久化存儲的映射表, 采用行鍵、列族、列限定符和時間戳進行索引, 每個值都是未經解釋的字節數組byte[].
表
表由行和列組成, 列被分為若干個列族
行
每個HBase表都由若干行組成, 每個行由行鍵(Row Key)進行標識.
訪問表中的行有3種方式:
- 通過單個行鍵訪問
- 通過行鍵區間訪問
- 全表掃描
行鍵可以是任意字符串(最大長度64KB, 實際應用中一般為10-100字節). 在HBase內部將行鍵保存為 字節數組, 按照行鍵的 字典序 排序. 所以在設計行鍵時可以充分考慮該特性, 將需要一起讀的行存儲在一起.
列族
HBase中一個表被分為多個列族, 列族是最基本的訪問控制單元. 表中的每個列都必須屬于一個列族, 我們可以將其理解為 把列按照需求分到不同的組中, 就如同整理文件到不同的文件夾中去.
為什么要這么做?
- 控制權限. 我們通過列族可以實現權限的控制, 例如某些應用只可以修改某些數據.
- 獲得更高的壓縮率. 同一個列族中的所有數據都屬于同一種數據類型, 著通常意味著更高的壓縮率.
缺點
- 列族數量不可太多. HBase的一些缺陷導致列族只能有幾十個.
- 不能頻繁修改.
列限定符
列族中的數據是通過列限定符來定位的. 列限定符無需事先定義, 也沒有數據類型, 總被視為字節數組byte[].
單元格
在HBase的表中, 通過行、列和列限定符可以確定一個"單元格(Cell)". 單元格中存儲的數據沒有數據類型, 總被視為字節數組byte[].
每個單元格中可以保留一個數據的多個版本, 每個版本對應一個不同的時間戳.
時間戳
每個單元格都保留了同一個數據的多個版本, 這些版本采用時間戳進行索引. 事實上每一次對于一個單元格執行的操作(增刪改)時, HBase都會自動生成并存儲一個時間戳, 通常這個時間戳是64位整型. 當然, 這個時間戳也可以由用戶自己賦值, 用以避免應用程序中出現數據版本沖突.
一個單元格中的不同版本的數據是以時間戳降序排序的, 以便于讀到最新的數據版本.
我認為下面的一張圖可以很好地表述上面的5個概念. 類比于關系數據庫, 行鍵就是主鍵行號, 列限定符就是列名, 列族就是列名組成小組的組名, 單元格就是具體存儲數據的格子, 時間戳則標識了一個單元格中不同時間的數據版本.
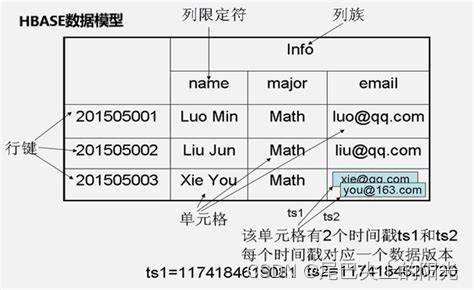
一個HBase數據模型的實例
數據坐標
相較于我們所熟悉的關系數據庫, HBase無法僅使用行號和列號確定一個數據. 在HBase中, 我們需要: 行鍵、列族、列限定符和時間戳 這4個東西來確定一個數據.
[行鍵, 列族, 列限定符, 時間戳]被稱為是HBase的坐標, 可以通過這個坐標來直接訪問數據. 在這種層面上講, HBase也可以被視為一個鍵值數據庫.
概念視圖
在HBase的概念視圖中, 一個表是一個稀疏、多維的映射關系.
| 時間戳 | 列族 contents | 列族 anchor | |
|---|---|---|---|
| com.cnn.www | t5 | anchor:cnnsi.com="CNN" | |
| t4 | anchor:my.look.ca="CNN.com" | ||
| com.cnn.www | t3 | contents:html="xxxx" | |
| t2 | contents:html="xxxx" | ||
| t1 | contents:html="xxxx" |
上表存儲了一個網頁的頁面內容(html代碼)和一些反向連接. contents中存儲的是網頁內容, anchor中存儲的是反向連接. 不過有幾個地方需要額外注意:
- 行鍵. 行鍵采用的是url的倒序, 因為HBase的行鍵采用字典倒序排列, 這樣可以使得相同的網頁都保存在相鄰的位置
- 每個行都包含了相同的列族, 即便有些列族不需要存儲數據(為空)
物理視圖
列族 contents
| 時間戳 | 列族 contents | |
|---|---|---|
| com.cnn.www | t3 | contents:html="xxxx" |
| t2 | contents:html="xxxx" | |
| t1 | contents:html="xxxx" |
列族 anchor
| 時間戳 | 列族 anchor | |
|---|---|---|
| com.cnn.www | t5 | anchor:cnnsi.com="CNN" |
| t4 | anchor:my.look.ca="CNN.com" |
我們可以輕易發現, 在物理的存儲層面上來看HBase采用了基于列的存儲方式, 而不是傳統關系數據庫那樣基于行來存儲. 這也是HBase與傳統關系數據庫間的重要區別.
與概念視圖的不同
- 列族的分開存放. 可以看到contents和anchor兩個列族被分開存放.
- 不存在空值. 在概念視圖中有些列是空的, 但是在物理視圖中這些值根本不會被存儲.
總結
行式數據庫使用 NSM(N-ary Storage Model) 存儲模型, 將一個元組(或行)連續地存儲在磁盤頁中. 數據被一行一行地儲存, 寫完第一行再寫第二行. 在讀取數據時需要從磁盤中順序掃描每個元組的完整內容. 顯然, 如果每個元組只有少量屬性的值對查詢有用時, NSM模型會浪費許多磁盤空間.
列式數據庫采用 DSM(Decomposition Storage Model) 存儲模型, 將關系進行垂直分解, 以列為單位存儲, 每個列單獨存儲. 該方法最小化了無用的I/O.
行式存儲主要適合于小批量的數據處理, 比如聯機事務處理. 列式數據庫主要適用于批量數據處理和即席查詢(Ad-Hoc Query). 列式數據庫的優點是: 降低I/O開銷, 支持大量用戶并發查詢, 數據處理速度比傳統方法快100倍, 并且具有更高的數據壓縮比.
如果嚴格從關系數據庫的角度來看, HBase并不是一個列式存儲的數據庫, 畢竟它是以列族為單位進行分解的, 而不是每個列都單獨存儲. 但是HBase借鑒和利用了磁盤上這種列存的格式, 所以某種角度上來說它可以被視為列式數據庫. 常用的商業化列式數據庫有: Sybase IQ, Verticad等.
如果想要更深入地了解HBase的實現原理, 架構以及運行機制, 可以閱讀我的博客: 分布式數據庫HBase











)
)






