目錄
序列化(Serialization)
反序列化(Deserialization)
事例操作?
UserSale
??重寫序列化方法
重寫反序列化
?重寫toString方法
SaleMapper
SaleReducer
SaleDriver
序列化(Serialization)
????????序列化是將Java對象轉換成字節流的過程,使得對象可以被存儲到磁盤上或通過網絡進行傳輸。在Hadoop中,這個過程特別關鍵,因為數據經常需要在網絡間傳遞(例如,從Map任務到Reduce任務),或者存儲到HDFS上。Hadoop自定義了一套序列化機制——Writable接口,任何需要進行序列化的類都必須實現這個接口。實現Writable接口的類需要重寫兩個方法:write(DataOutput out)和readFields(DataInput in)。前者負責將對象的狀態(即成員變量的值)寫入到DataOutput流中;后者則從DataInput流中讀取字節并恢復對象狀態。
反序列化(Deserialization)
????????反序列化則是序列化的逆過程,即將字節流轉換回Java對象。在Hadoop中,當數據從網絡接收或從HDFS讀取后,需要通過反序列化恢復成原始的Java對象,以便程序能夠進一步處理這些數據。利用前面提到的readFields(DataInput in)方法,Hadoop可以從輸入流中重建對象實例。
?Hadoop選擇了自定義Writable接口,主要出于以下考慮:
- 性能:Hadoop的Writable接口設計得更加輕量級和高效,特別適合大規模數據處理,減少序列化和反序列化過程中的開銷。
- 緊湊性:Writable接口能夠生成更緊湊的二進制格式,節省存儲空間和網絡帶寬。
- 可移植性:Hadoop集群可能包含不同版本的Java或運行在不同的操作系統上,自定義序列化機制保證了跨平臺的一致性。
事例操作?
使用自定義對象,實現對用戶購買商品總額的計算
入口文件示例
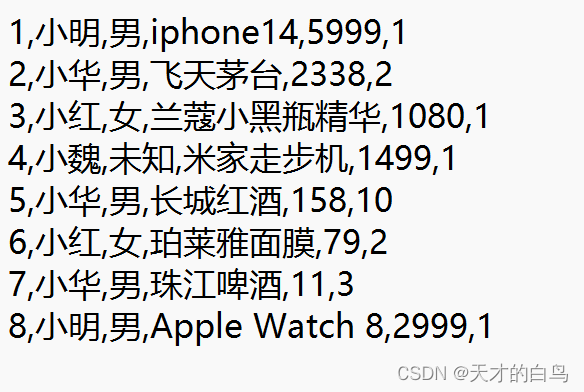
UserSale
實現Hadoop的Writable接口
public class UserSale implements Writable {//銷售idprivate int saleId;//用戶名稱private String username;//用戶性別private String sex;//商品名稱private String goodsName;//商品單價private int price;//購買數量private int saleCount;//購買總價private int totalPrice;?記得得有空參構造
public UserSale() {}??重寫序列化方法
//重寫序列化方法@Overridepublic void write(DataOutput out) throws IOException {out.writeInt(saleId);out.writeUTF(username);out.writeUTF(sex);out.writeUTF(goodsName);out.writeInt(price);out.writeInt(saleCount);out.writeInt(totalPrice);}重寫反序列化
順序和序列化的順序一樣
@Overridepublic void readFields(DataInput in) throws IOException {this.saleId = in.readInt();this.username = in.readUTF();this.sex = in.readUTF();this.goodsName = in.readUTF();this.price = in.readInt();this.saleCount = in.readInt();this.totalPrice = in.readInt();}?重寫toString方法
reduce階段的輸出的格式
//重寫toString方法//最終輸出到文件的value@Overridepublic String toString() {return " " + totalPrice;}?get,set方法,以及定義totalPrice的構造方法
public void setTotalPrice(int totalPrice) {this.totalPrice = totalPrice;}public void setTotalPrice(){this.totalPrice = this.price*this.saleCount;}SaleMapper
package com.igeekhome.mapreduce.sale;import com.igeekhome.mapreduce.model.UserSale;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class SaleMapper extends Mapper<LongWritable, Text, Text, UserSale>{//創建輸出key對象private Text keyOut = new Text();//創建輸出valueUserSale valueOut = new UserSale();@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, UserSale>.Context context) throws IOException, InterruptedException {//獲取一行數據String line = value.toString();//根據分隔符拆解數據String[] saleDetails = line.split(",");//封裝對象valueOut.setSaleId(Integer.parseInt(saleDetails[0]));valueOut.setUsername(saleDetails[1]);valueOut.setSex(saleDetails[2]);valueOut.setGoodsName(saleDetails[3]);valueOut.setPrice(Integer.parseInt(saleDetails[4]));valueOut.setSaleCount(Integer.parseInt(saleDetails[5]));//賦值keyOut.set(valueOut.getUsername());//計算總價valueOut.setTotalPrice();System.out.println(keyOut+"+"+valueOut);//map階段的輸出context.write(keyOut,valueOut);}
}?其中
Mapper<LongWritable, Text, Text, UserSale>
分別表示
LongWritable:map階段輸入的key類型,一行文本的偏移量
Text:map階段輸入的value類型,表示一行文本中的內容
Text: map階段輸出的key類型 ,表示一個單詞
UserSale?:map階段輸出的value類型,這里是UserSale對象
SaleReducer
新建reduce階段輸出的alue
reduce()方法的調用次數 是由kv鍵值對中有多少不同的key決定的
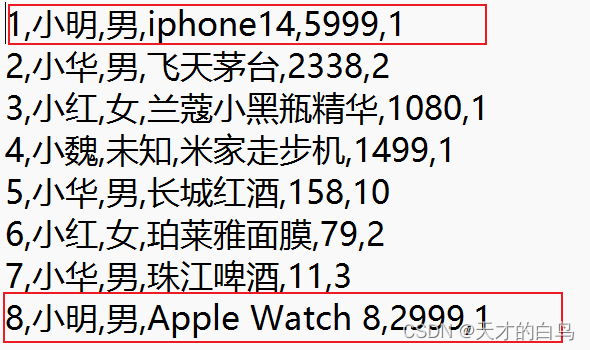
比如此時小明的兩條數據進入Reducer,for循環執行的是這兩條數據里的總價相加
package com.igeekhome.mapreduce.sale;import com.igeekhome.mapreduce.model.UserSale;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class SaleReducer extends Reducer<Text, UserSale,Text, UserSale> {//新建reduce階段輸出的alue//reduce()方法的調用次數 是由kv鍵值對中有多少不同的key決定的private UserSale valueOut = new UserSale();@Overrideprotected void reduce(Text key, Iterable<UserSale> values, Reducer<Text, UserSale, Text, UserSale>.Context context) throws IOException, InterruptedException {//定義一個用戶的訂單int sumTotalPrice = 0;for (UserSale userSale : values) {//獲取一個訂單中的總價int totalPrice = userSale.getTotalPrice();valueOut.setSex(userSale.getSex());//進行累加sumTotalPrice +=totalPrice;}//設置在結果文件終端輸出valueOut.setTotalPrice(sumTotalPrice);System.out.println("reduce" +valueOut);//reduce階段的輸出context.write(key,valueOut);}
}
Reducer<Text, UserSale,Text, UserSale>
Text:reduce階段的輸入key類型, 即map階段輸出key類型,表示用戶名
UserSale:reduce階段的輸入value類型,即map階段輸出value類型,表示用戶對象
Text:reduce階段的輸出key類型,表示用戶名
UserSale:reduce階段的輸出value類型,表示用戶對象,實際上輸出的是totalPrice(因為toString方法的重寫)
SaleDriver
package com.igeekhome.mapreduce.sale;import com.igeekhome.mapreduce.model.UserSale;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class SaleDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {//1.獲取配置對象和job對象Configuration conf = new Configuration();Job job = Job.getInstance(conf);//2.設置Driver類對象job.setJarByClass(SaleDriver.class);//3.設置mapper和reducer類對象job.setMapperClass(SaleMapper.class);job.setReducerClass(SaleReducer.class);//4.設置map階段輸出的kv對象job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(UserSale.class);//5.設置最終輸出的kv類對象job.setOutputKeyClass(Text.class);job.setOutputValueClass(UserSale.class);//6.設置讀取文件的路徑 和 輸出文件的路徑FileInputFormat.setInputPaths(job,new Path("D:\\code\\sale_details (1).txt"));FileOutputFormat.setOutputPath(job,new Path("D:\\code\\output"));//7.提交jobboolean result = job.waitForCompletion(true);System.out.println(result?"計算成功":"計算失敗");}}
之后的分區操作mapreduce分區![]() https://blog.csdn.net/m0_74934794/article/details/139991018?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22139991018%22%2C%22source%22%3A%22m0_74934794%22%7D
https://blog.csdn.net/m0_74934794/article/details/139991018?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22139991018%22%2C%22source%22%3A%22m0_74934794%22%7D





)



方法——分割字符串為元組)
:條件語句)

)



原理)
![[教程]Gitee保姆級圖文使用教程](http://pic.xiahunao.cn/[教程]Gitee保姆級圖文使用教程)

