周末聽了一場關于Open Search的技術分析,整理如下,供大家參考。OpenSearch,作為ElasticSearch的一個分支,不僅繼承了其強大的搜索和分析能力,更在開源社區的驅動下,不斷演進和創新。本文將介紹OpenSearch的最新進展,特別是其在語義檢索技術方面的突破。
OpenSearch簡介
OpenSearch是一個開源的搜索與分析套件,起源于ElasticSearch 7.10.2版本,堅持Apache-2.0開源協議,以開源優先和社區驅動為原則。OpenSearch項目不僅提供了強大的搜索功能,還包括了DataPrepper、Dashboard等組件,廣泛應用于搜索、可觀測性、安全分析、數據可視化和機器學習等領域。
向量搜索引擎從原始向量做寫入、查詢,OpenSearch做了很多運行速度、壓縮量化方面的優化。到NeuralSearch語義搜索引擎,做的易用性升級,純文本端到端的寫入查詢,做了其他的功能優化,比如Hybrid query.多模態、文本切分、rerank。現在:稀疏編碼的語義搜索引擎,knn之外又多了一種選擇,各自具備自己的優勢,適配不同的應用場景
OpenSearch社區
OpenSearch的社區活躍度極高,擁有超過5億的總下載量,版本更新頻繁,合作伙伴和外部貢獻者眾多。在SlackWorkspace和OpenSearchForum上,有超過7000名成員參與討論,月瀏覽量達到30萬以上。這種活躍的社區氛圍為OpenSearch的持續發展和創新提供了堅實的基礎。
OpenSearch使用場景
OpenSearch平臺的優勢在于其檢索功能的沉淀、分布式架構、安全性和數據分析能力。特別是k-NN索引的橫向擴展能力,可以在集群中任意擴展數據節點,支持高達16K維度的向量,滿足大規模數據集的搜索需求。
1.結合OpenSearch豐富的檢索功能,與OpenSearch DSL結合完成復雜的查詢過程
- a. 比如加入復雜的過濾條件;
- b. 與其他查詢結合,e.g.BM25
2.基于OpenSearch分布式平臺,高可靠性、高擴展性、高性能,平臺確保分布式查詢和寫入 的負載均衡。
3.安全性:基于OpenSearch的安全插件,實現api級別鑒權,多用戶訪問控制,安全審計日志
4.數據分析:OpenSearch dashboards擁有豐富的數據可視化工具,數據進行可視化分析。dashboards上的搜索比較工具進行可視化的搜索效果比較,進行case
研究分析
使用場景:

OpenSearch向量數據庫
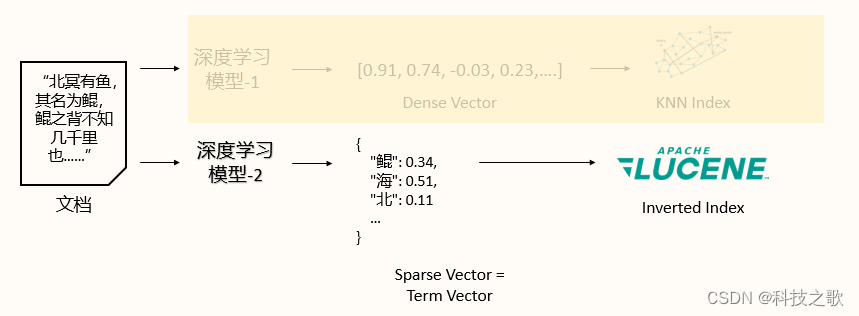
在深度學習時代,萬物皆可Embedding,無論是圖像、文本、視頻還是音樂,都可以通過向量化的方式進行高效的索引和檢索。OpenSearch通過k-NN插件,實現了向量引擎的適配,支持NMSLiB、Faiss、Lucene等多種向量庫,以及HNSW和IVF等索引結構,為用戶提供了強大的向量搜索能力。
k-NN插件
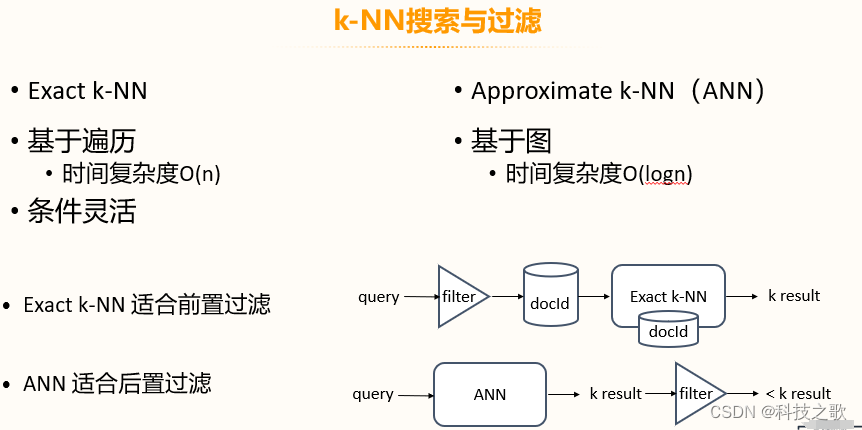
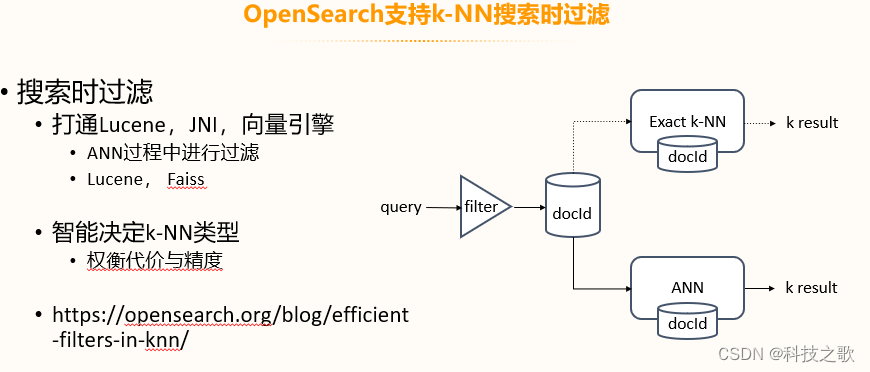
OpenSearch支持Exact k-NN和Approximate k-NN (ANN)搜索,以及基于遍歷和基于圖的過濾方式。Exact k-NN適合前置過濾,而ANN適合后置過濾。OpenSearch還能夠在搜索時進行過濾,打通了Lucene、JNI和向量引擎,智能決定k-NN類型,權衡代價與精度。
數據評測:性能與召回率的平衡
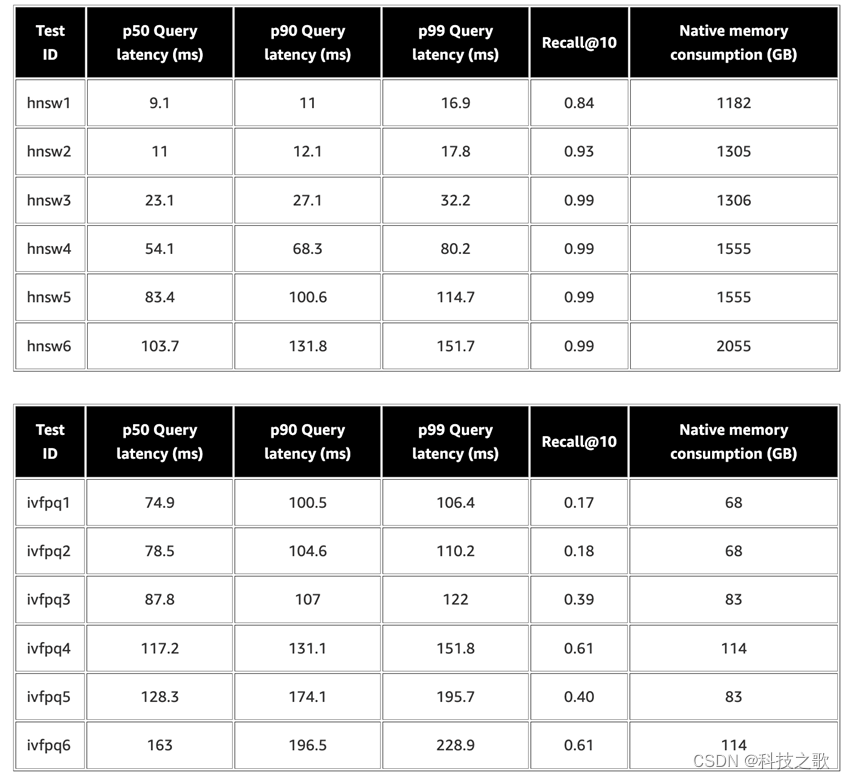
在1億數據集的評測中,OpenSearch展現出了穩定支持10億數據的能力,以及優秀的召回率和低延遲。例如,在r5.12xlarge實例上,p90查詢延遲僅為16.9毫秒,召回率達到0.99。這表明OpenSearch在處理大規模數據集時,能夠保持良好的性能和高準確度。
端到端的文本語義檢索
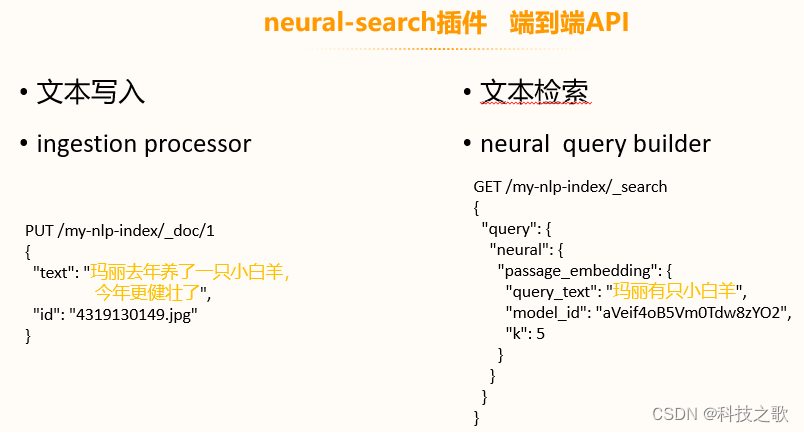
對于期望實現語義檢索的用戶,OpenSearch提供了neural-search插件,這是一個端到端的API,支持文本寫入和檢索。通過ingestion processor和neural query builder,用戶可以輕松實現文本的語義檢索。
ml-commons插件:模型全流程托管
ml-commons插件為語義檢索提供了強大的支持,實現了模型的全流程托管,包括一鍵部署、節點級部署、負載均衡和GPU支持。此外,它還支持遠程連接到SageMaker、Bedrock、Cohere、OpenAI等服務,以及通過AgentFramework連接大模型,助力RAG。
OpenSearch提供了可視化查詢比較工具,允許用戶使用相同的搜索測試不同的查詢,比較結果的差異。這有助于用戶更好地理解不同查詢方式的效果,優化搜索策略。
k-NN算法中的性能取舍
在k-NN算法中,性能和召回率往往需要權衡。例如,HNSW算法雖然召回率高達99%,但延時和內存占用相對較高;而IVF+PQ算法雖然召回率較低,但延時和內存占用更優。OpenSearch通過智能選擇算法,幫助用戶在性能和精度之間找到最佳平衡。

稀疏編碼:魚和熊掌兼得
稀疏編碼(neural sparse)是一種既能保證高相關性,又能節省存儲空間、保證速度的語義檢索方法。通過深度學習模型,稀疏編碼能夠將文檔和查詢轉換為稀疏向量,實現高效的語義匹配。
稀疏編碼的魯棒性
稀疏編碼在真實數據服從訓練數據分布時表現出色,模型能夠使用稀疏準確的向量表征,產出精確的結果。即使在支持論據不足的情況下,稀疏編碼也能保持較高的搜索相關性。
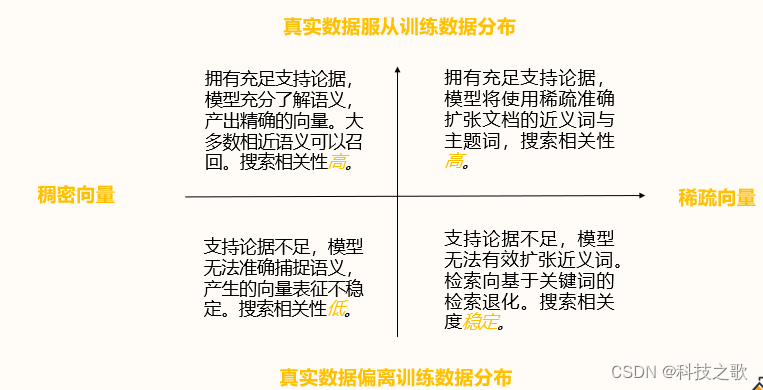
稀疏編碼語義檢索的計算方法
稀疏編碼通過點積計算查詢和文檔之間的分數,結合權重和語義模型,實現高效的語義匹配。

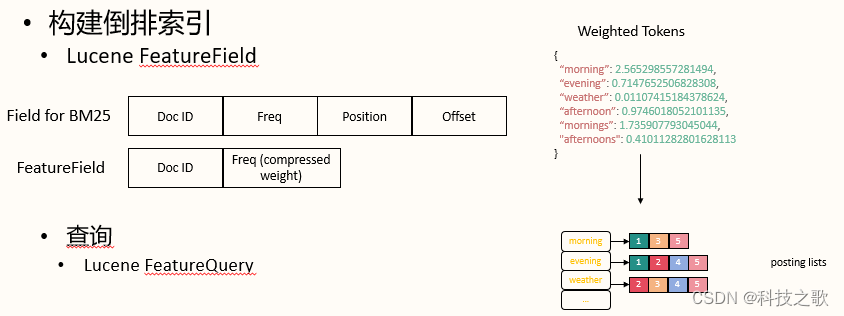
稀疏編碼與Lucene的結合
OpenSearch將稀疏編碼與Lucene結合,構建了倒排索引和FeatureField,實現了高效的檢索。
Doc-only模式:極致速度
OpenSearch的Doc-only模式通過減少模型推理和索引遍歷,實現了極致的搜索速度,同時保持了較高的搜索精度。

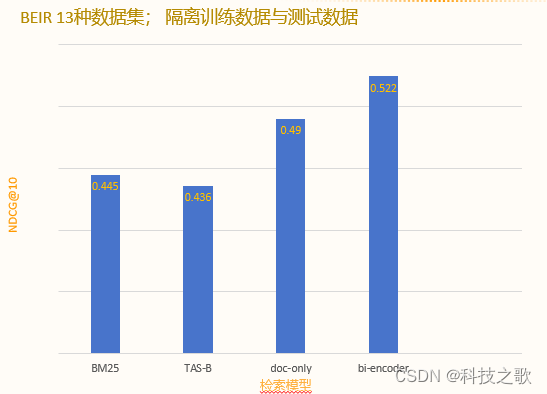
稀疏編碼性能測試結果
OpenSearch的稀疏編碼模型在性能測試中表現出色,無論是搜索精度還是速度,都遠超傳統的BM25模型。
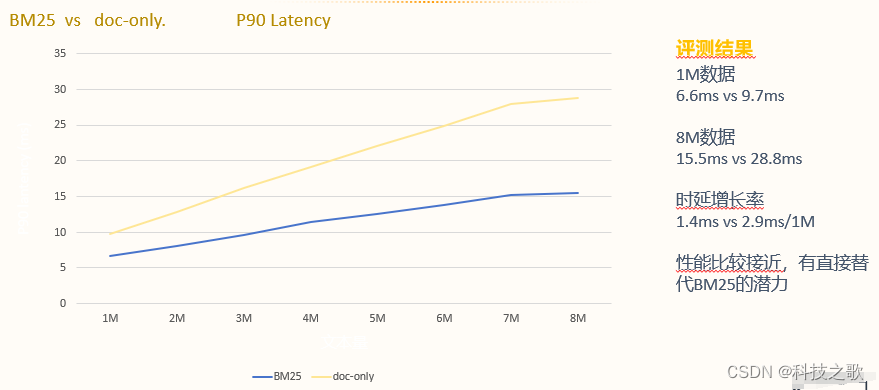
稀疏編碼資源消耗
稀疏編碼模型在資源消耗方面也具有優勢,索引大小和峰值內存占用都遠低于稠密索引模型。

稀疏編碼持續優化
OpenSearch團隊持續優化稀疏編碼模型,通過預訓練和知識蒸餾,減小模型尺寸,提高搜索精度,降低ingestion代價。
集成多路召回
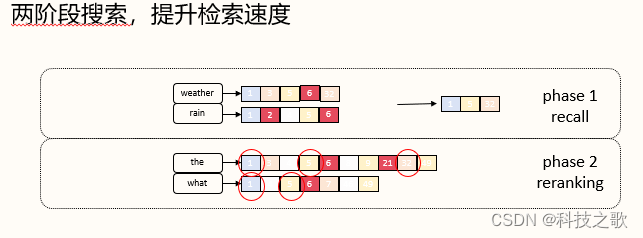
OpenSearch還支持集成多路召回,通過BM25與k-NN的集成,以及更復雜的查詢組合,進一步提升搜索精度。
結語
OpenSearch作為一個活躍的開源項目,其在語義檢索技術方面的創新和優化,提供了一個高效、準確、可擴展的搜索平臺。








)










