隱私計算實訓營第二期-第十課
- 第十課:基于SPU機器學習建模實踐
- 1 隱私保護機器學習背景
- 1.1 機器學習中隱私保護的需求
- 1.2 PPML提供的技術解決方案
- 2 SPU架構
- 2.1 SPU前端
- 2.2 SPU編譯器
- 2.3 SPU運行時
- 2.4 SPU目標
- 3 密態訓練與推理
- 3.1 四個基本問題
- 3.2 解決數據來源問題
- 3.3 解決數據安全問題
- 3.4 解決模型計算問題
- 3.5 解決密態計算問題
- 3.6 如何應對更復雜的模型
- 3.7 已有模型的復用
- 4 作業實踐
- 4.1 基礎NN模型作業
- 4.2 進階Transformer模型作業
第十課:基于SPU機器學習建模實踐
首先必須感謝螞蟻集團及隱語社區帶來的隱私計算實訓第二期的學習機會!
本節課由螞蟻隱私計算部算法工程師吳豪奇老師講解。

本節課主要內容為:
- 隱私保護機器學習背景
- SPU架構簡介
- NN密態訓練/推理示例
1 隱私保護機器學習背景
1.1 機器學習中隱私保護的需求
本節課前兩個小節的內容,我們這之前的課程中已有一些了解,
本節課可以回顧一下。
數據和模型的隱私保護需求是產生隱私保護機器學習的根因。

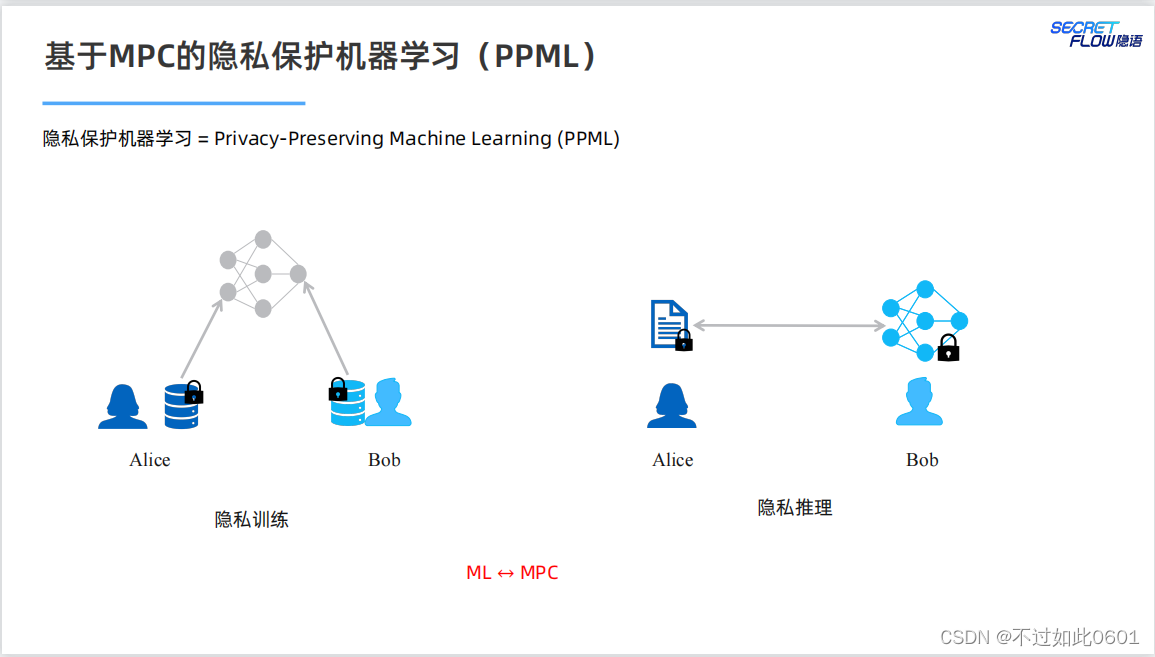
1.2 PPML提供的技術解決方案
MPC提供了隱私保護的技術解決方案。
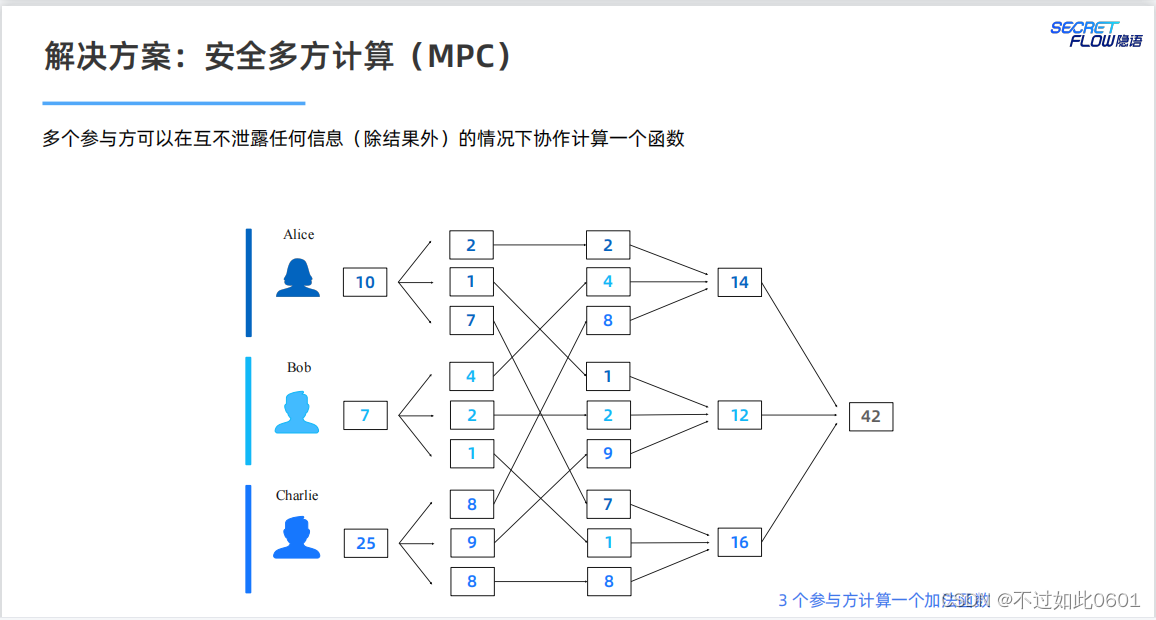
使用MPC結合機器學習,為模型訓練和推理提供隱私保護。
問題:
我們是否可以直接以 MPC 的方式高效地運行已有的機器學習程序?
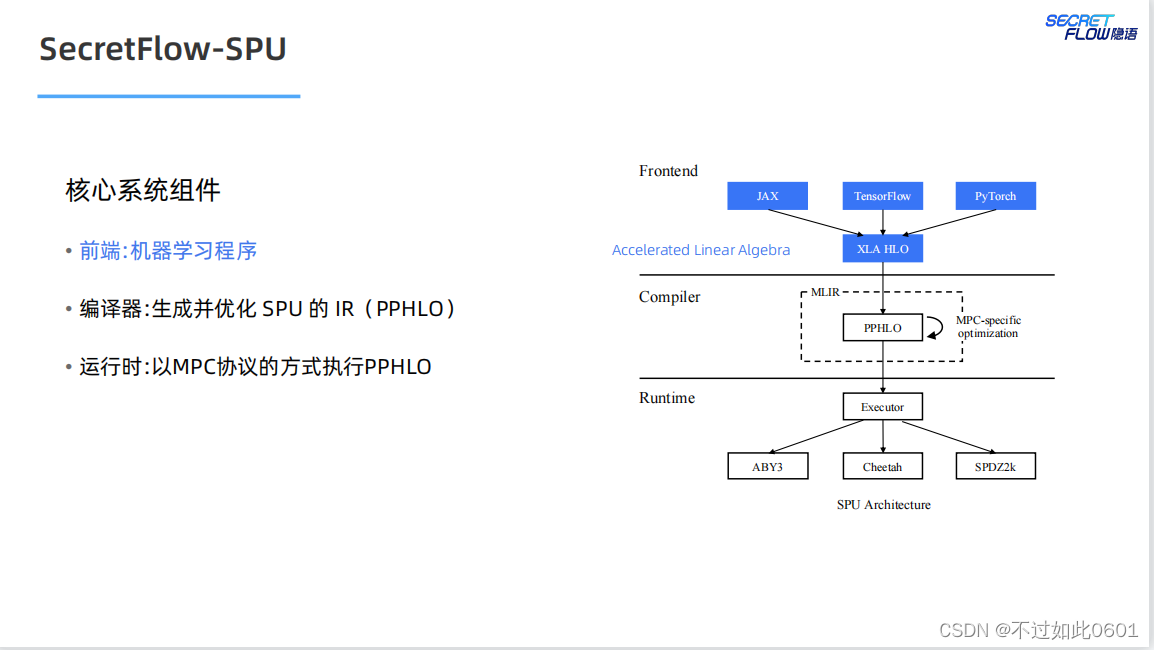
2 SPU架構
SPU架構我們在之前已經學習過,宏觀上主要分為三部分:
- 前端部分
- 編譯器
- 運行時
2.1 SPU前端
SPU前端盡量支持原生的AI編程方式,支持JAX、TensorFlow,Pytorch
等典型的AI編程框架。
2.2 SPU編譯器
SPU的編譯器以優化方式生成SPU的密態中間語言。
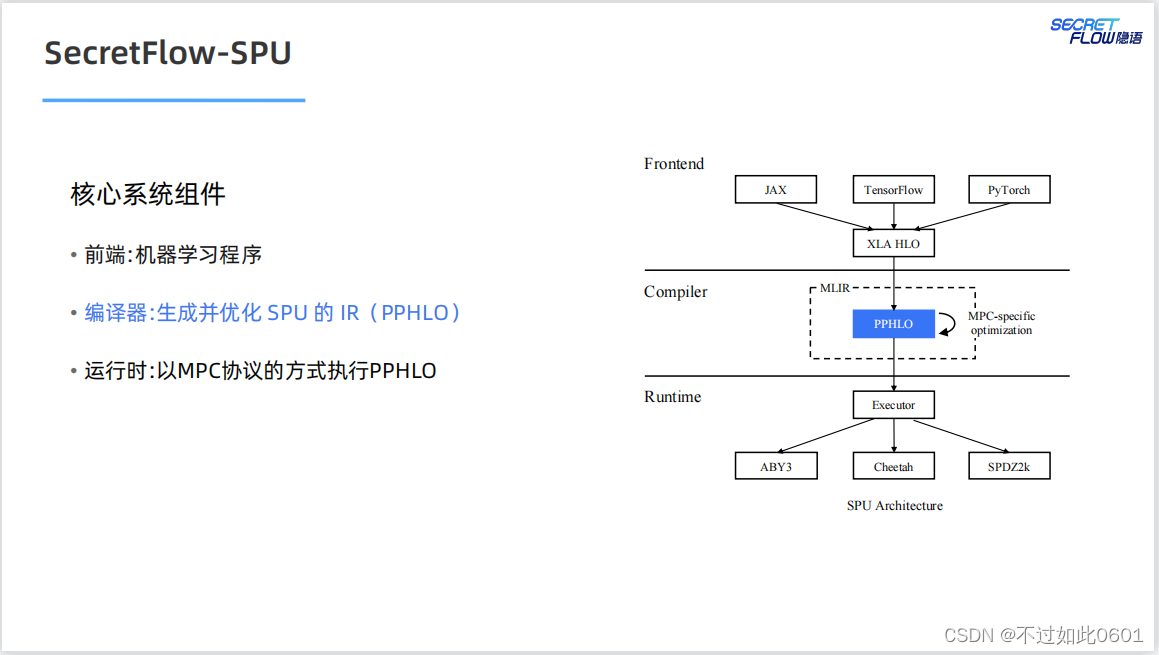
2.3 SPU運行時
SPU的運行時支持多種并行模式(數據并行+指令并行),多種MPC協議
以及多種部署模式。
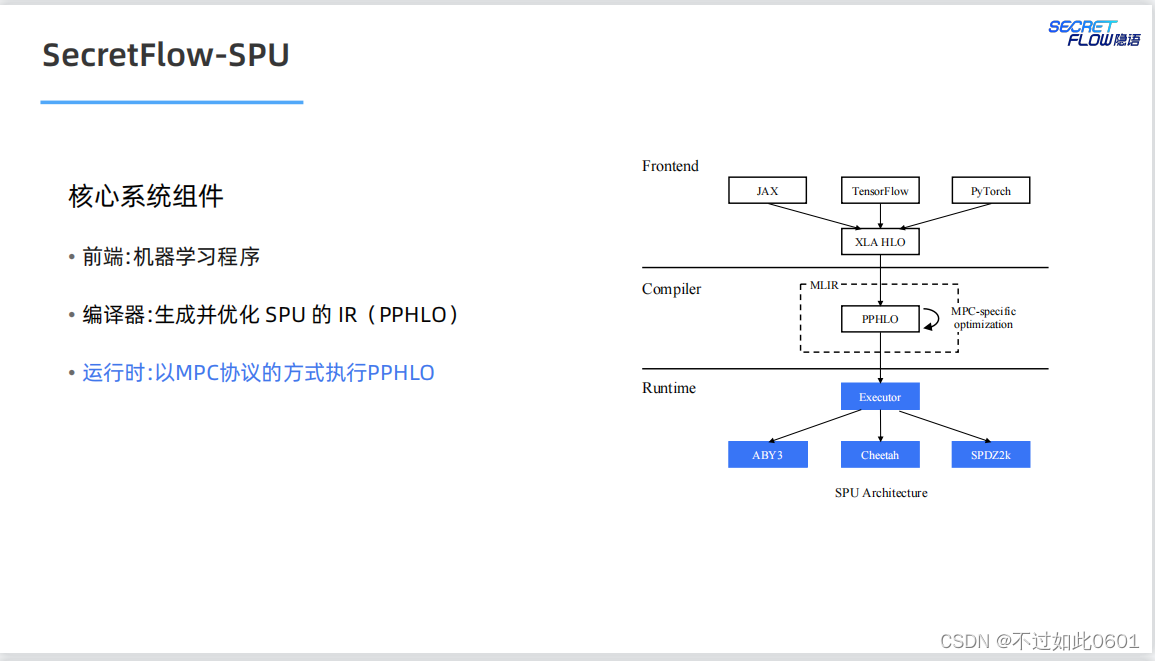
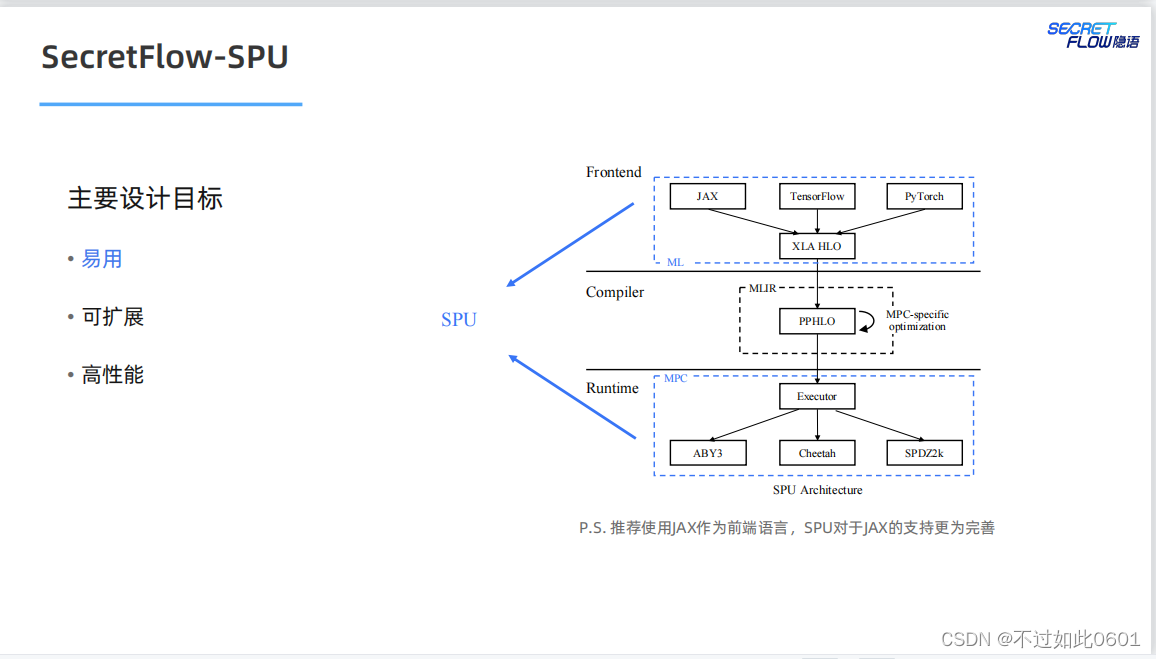
2.4 SPU目標
SPU的最終目標是實現易用、可擴展和高性能的密態計算虛擬設備。
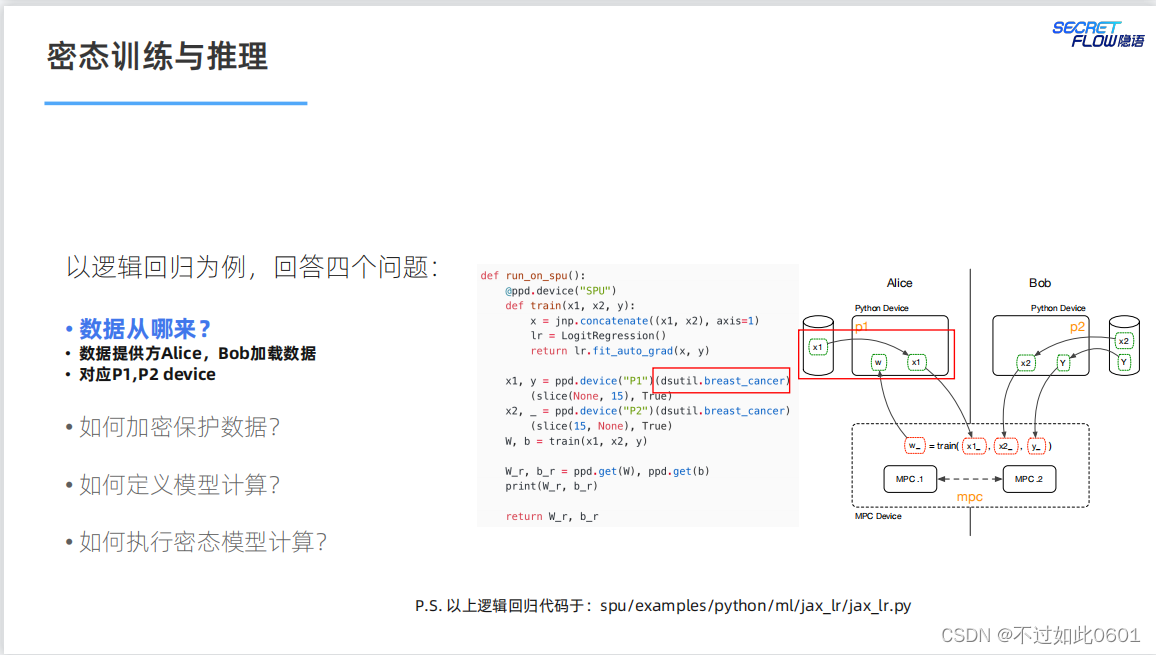
3 密態訓練與推理
3.1 四個基本問題
密態的訓練和推理需要解決的四個問題:
- 數據從哪來?
- 如何加密保護數據?
- 如何定義模型計算?
- 如何執行密態模型計算?

3.2 解決數據來源問題
數據由數據個參與方以密態的形式提供。
3.3 解決數據安全問題
數據安全通過MPC協議或者同態加密等外部模式解決。

3.4 解決模型計算問題
NN模型的計算問題通過JAX實現前向和反向傳播。

3.5 解決密態計算問題
NN模型的密態計算SPU的編譯器轉換為密態算子,然后按照MPC協議
進行計算。
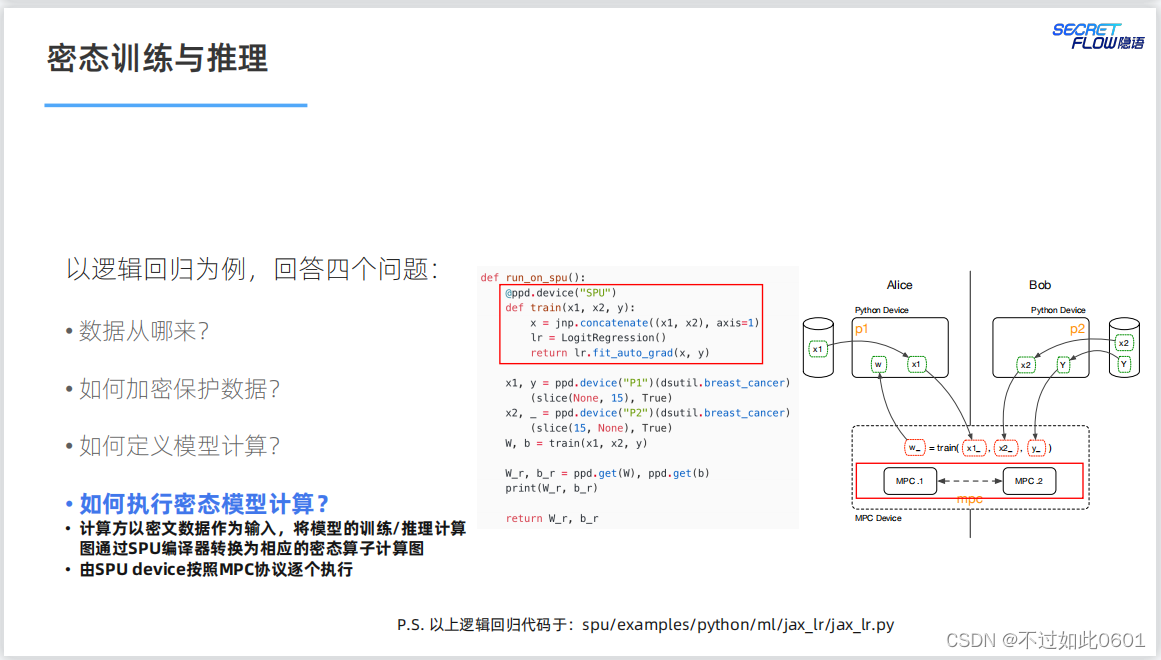
密態的計算過程與明文類似,通過SPU密態計算配置實現密態訓練。
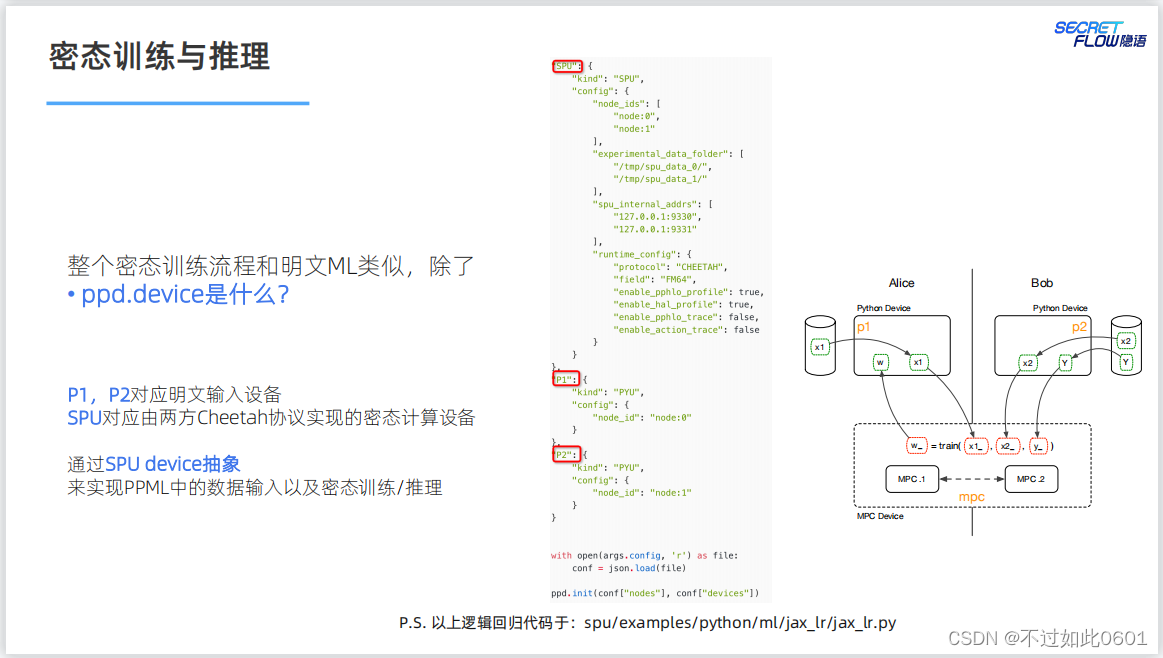
3.6 如何應對更復雜的模型
對于復雜模型,使用stax和flax來進行實現。

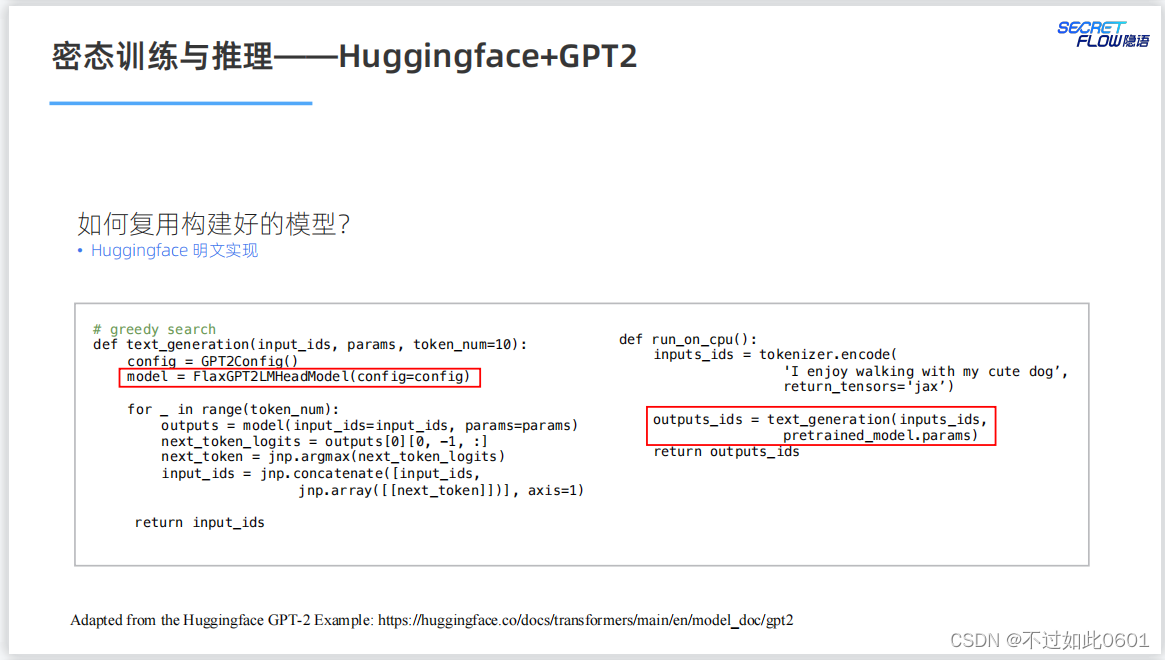
3.7 已有模型的復用
已有模型的復用問題,根據明文實現來進行密態計算的遷移。
比如,明文實現的GPT2模型。
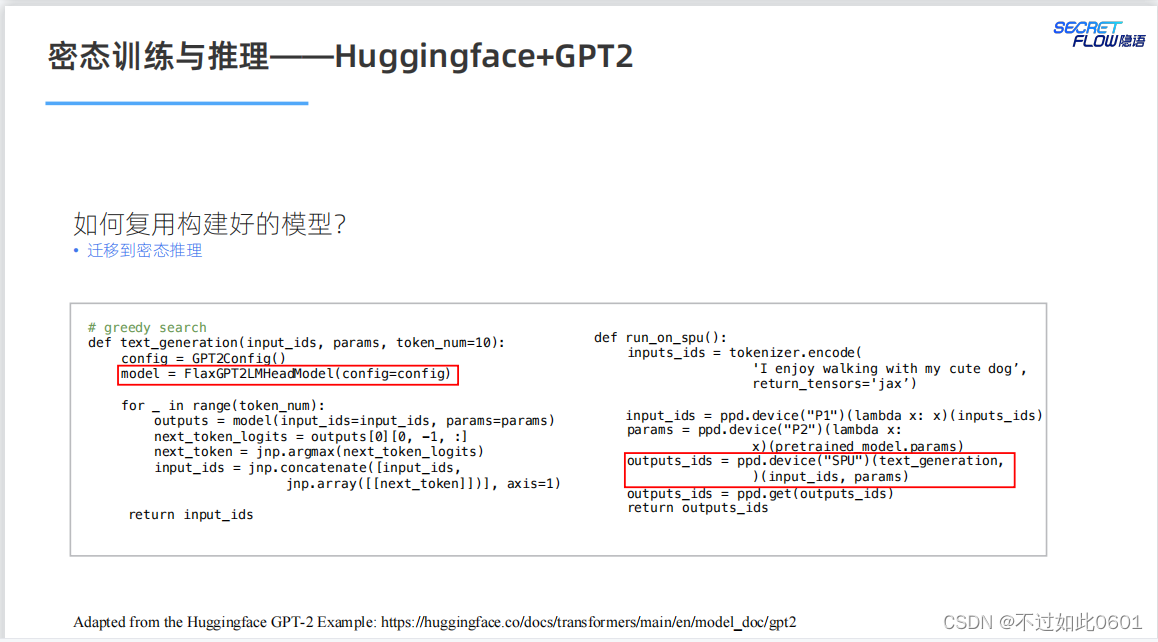
然后進行密態遷移:
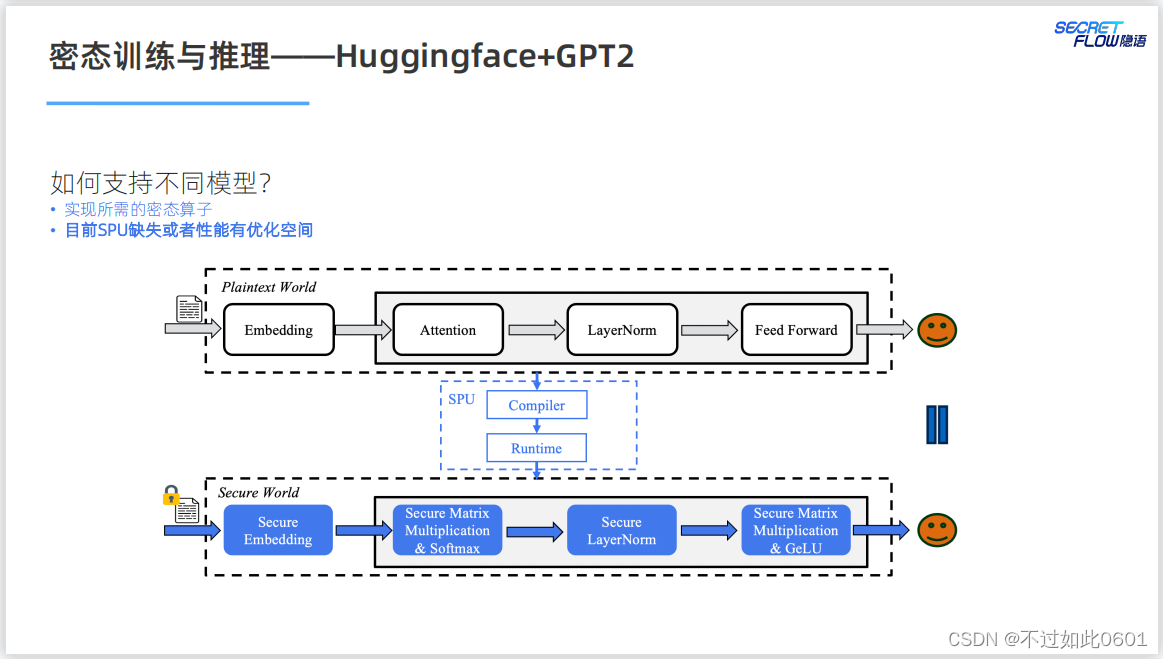
在支持不同的模型方面,SPU還需要更新和優化自己的實現以滿足不同
模型的需求。
4 作業實踐
4.1 基礎NN模型作業
本次課程有兩個作業,一個是基礎的NN模型。另一個是進階的Transformer
模型。
完成步驟如下:
1、加載數據集
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import Normalizerdef breast_cancer(party_id=None, train: bool = True) -> (np.ndarray, np.ndarray):x, y = load_breast_cancer(return_X_y=True)x = (x - np.min(x)) / (np.max(x) - np.min(x))x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)if train:if party_id:if party_id == 1:return x_train[:, :15], _else:return x_train[:, 15:], y_trainelse:return x_train, y_trainelse:return x_test, y_test
2、定義模型
from typing import Sequence
import flax.linen as nnFEATURES = [30, 15, 8, 1]class MLP(nn.Module):features: Sequence[int]@nn.compactdef __call__(self, x):for feat in self.features[:-1]:x = nn.relu(nn.Dense(feat)(x))x = nn.Dense(self.features[-1])(x)return x
3、定義訓練參數
import jax.numpy as jnpdef predict(params, x):# TODO(junfeng): investigate why need to have a duplicated definition in notebook,# which is not the case in a normal python program.from typing import Sequenceimport flax.linen as nnFEATURES = [30, 15, 8, 1]class MLP(nn.Module):features: Sequence[int]@nn.compactdef __call__(self, x):for feat in self.features[:-1]:x = nn.relu(nn.Dense(feat)(x))x = nn.Dense(self.features[-1])(x)return xreturn MLP(FEATURES).apply(params, x)def loss_func(params, x, y):pred = predict(params, x)def mse(y, pred):def squared_error(y, y_pred):return jnp.multiply(y - y_pred, y - y_pred) / 2.0return jnp.mean(squared_error(y, pred))return mse(y, pred)def train_auto_grad(x1, x2, y, params, n_batch=10, n_epochs=10, step_size=0.01):x = jnp.concatenate((x1, x2), axis=1)xs = jnp.array_split(x, len(x) / n_batch, axis=0)ys = jnp.array_split(y, len(y) / n_batch, axis=0)def body_fun(_, loop_carry):params = loop_carryfor x, y in zip(xs, ys):_, grads = jax.value_and_grad(loss_func)(params, x, y)params = jax.tree_util.tree_map(lambda p, g: p - step_size * g, params, grads)return paramsparams = jax.lax.fori_loop(0, n_epochs, body_fun, params)return paramsdef model_init(n_batch=10):model = MLP(FEATURES)return model.init(jax.random.PRNGKey(1), jnp.ones((n_batch, FEATURES[0])))
4、驗證參數
from sklearn.metrics import roc_auc_score
def validate_model(params, X_test, y_test):y_pred = predict(params, X_test)return roc_auc_score(y_test, y_pred)
5、開始明文訓練
import jax# Load the data
x1, _ = breast_cancer(party_id=1, train=True)
x2, y = breast_cancer(party_id=2, train=True)# Hyperparameter
n_batch = 10
n_epochs = 10
step_size = 0.01# Train the model
init_params = model_init(n_batch)
params = train_auto_grad(x1, x2, y, init_params, n_batch, n_epochs, step_size)# Test the model
X_test, y_test = breast_cancer(train=False)
auc = validate_model(params, X_test, y_test)
print(f'auc={auc}')
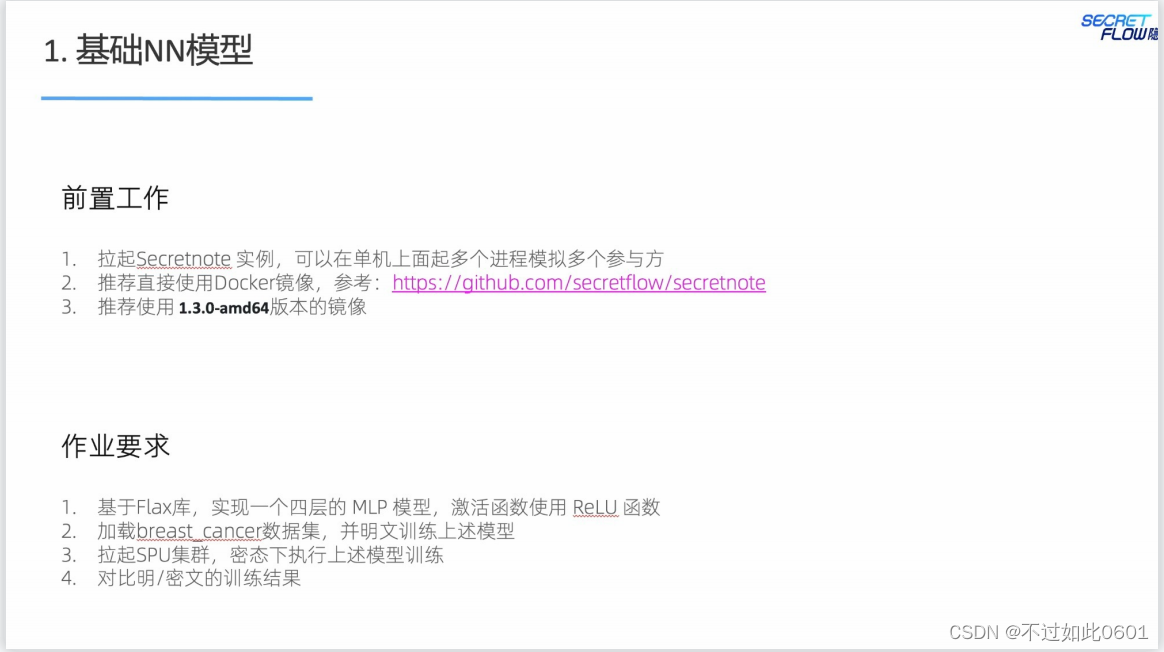
這里輸出的明文訓練結果為:
6、開始密文訓練
import secretflow as sf# Check the version of your SecretFlow
print('The version of SecretFlow: {}'.format(sf.__version__))# In case you have a running secretflow runtime already.
sf.shutdown()sf.init(['alice', 'bob'], address='local')alice, bob = sf.PYU('alice'), sf.PYU('bob')
spu = sf.SPU(sf.utils.testing.cluster_def(['alice', 'bob']))x1, _ = alice(breast_cancer)(party_id=1, train=True)
x2, y = bob(breast_cancer)(party_id=2, train=True)
init_params = model_init(n_batch)device = spu
x1_, x2_, y_ = x1.to(device), x2.to(device), y.to(device)
init_params_ = sf.to(alice, init_params).to(device)params_spu = spu(train_auto_grad, static_argnames=['n_batch', 'n_epochs', 'step_size'])(x1_, x2_, y_, init_params_, n_batch=n_batch, n_epochs=n_epochs, step_size=step_size
)
7、檢查參數
params_spu = spu(train_auto_grad)(x1_, x2_, y_, init_params)
params = sf.reveal(params_spu)
print(params)
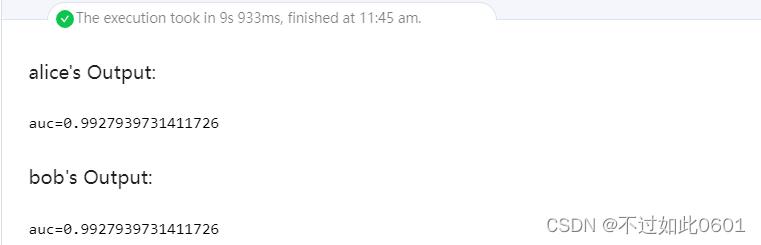
8、輸出訓練結果
X_test, y_test = breast_cancer(train=False)
auc = validate_model(params, X_test, y_test)
print(f'auc={auc}')
密文訓練輸出結果為:
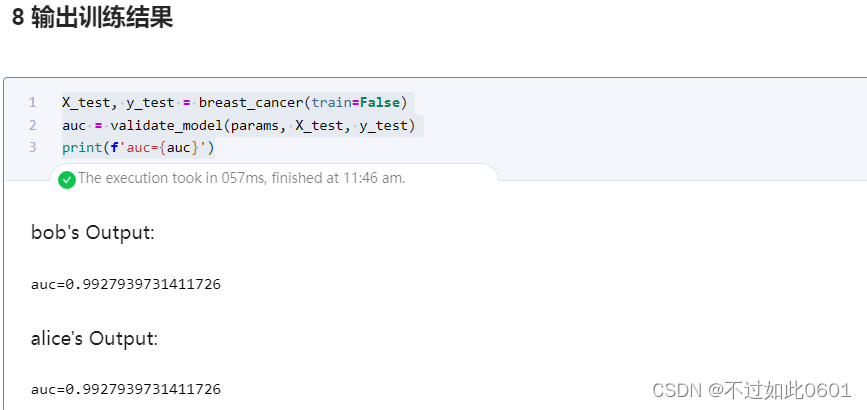
可以看出,密文訓練和明文訓練的效果相同,本作業結束,
4.2 進階Transformer模型作業
完成步驟如下:
1、安裝Transformer模型
import sys
!{sys.executable} -m pip install transformers[flax] -i https://pypi.tuna.tsinghua.edu.cn/simple
2、設置鏡像huggingface
import os
import sys
!{sys.executable} -m pip install huggingface_hub
os.environ['HF_ENDPOINT']='https://hf-mirror.com'
3、加載模型
from transformers import AutoTokenizer, FlaxGPT2LMHeadModel, GPT2Config
tokenizer = AutoTokenizer.from_pretrained("gpt2")
pretrained_model = FlaxGPT2LMHeadModel.from_pretrained("gpt2")
4、定義文本生成函數
def text_generation(input_ids, params):config = GPT2Config()model = FlaxGPT2LMHeadModel(config=config)for _ in range(10):outputs = model(input_ids=input_ids, params=params)next_token_logits = outputs[0][0, -1, :]next_token = jnp.argmax(next_token_logits)input_ids = jnp.concatenate([input_ids, jnp.array([[next_token]])], axis=1)return input_ids
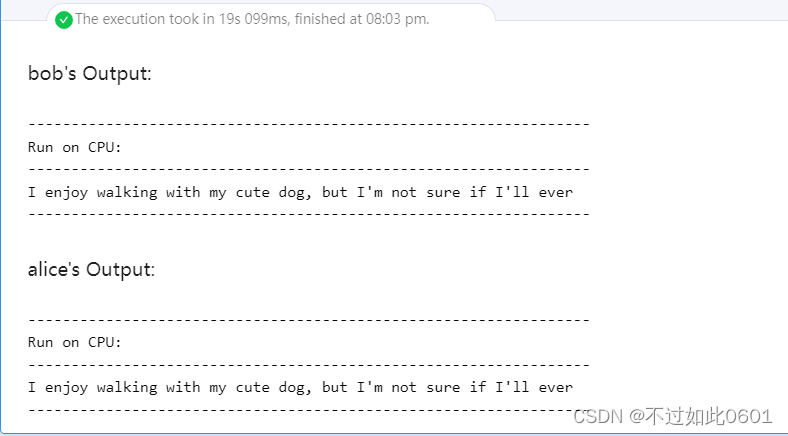
5、進行明文的文本生成
import jax.numpy as jnpinputs_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='jax')
outputs_ids = text_generation(inputs_ids, pretrained_model.params)print('-' * 65 + '\nRun on CPU:\n' + '-' * 65)
print(tokenizer.decode(outputs_ids[0], skip_special_tokens=True))
print('-' * 65)
生成的輸出結果為:
6、進行密文訓練
import secretflow as sf# In case you have a running secretflow runtime already.
sf.shutdown()sf.init(['alice', 'bob', 'carol'], address='local')alice, bob = sf.PYU('alice'), sf.PYU('bob')
conf = sf.utils.testing.cluster_def(['alice', 'bob', 'carol'])
conf['runtime_config']['fxp_exp_mode'] = 1
conf['runtime_config']['experimental_disable_mmul_split'] = True
spu = sf.SPU(conf)def get_model_params():pretrained_model = FlaxGPT2LMHeadModel.from_pretrained("gpt2")return pretrained_model.paramsdef get_token_ids():tokenizer = AutoTokenizer.from_pretrained("gpt2")return tokenizer.encode('I enjoy walking with my cute dog', return_tensors='jax')model_params = alice(get_model_params)()
input_token_ids = bob(get_token_ids)()device = spu
model_params_, input_token_ids_ = model_params.to(device), input_token_ids.to(device)output_token_ids = spu(text_generation)(input_token_ids_, model_params_)
這里由于機器配置不夠,內存不足,被系統kill進程,導致無法完成訓練。小伙伴們機器好的應該可以跑完。
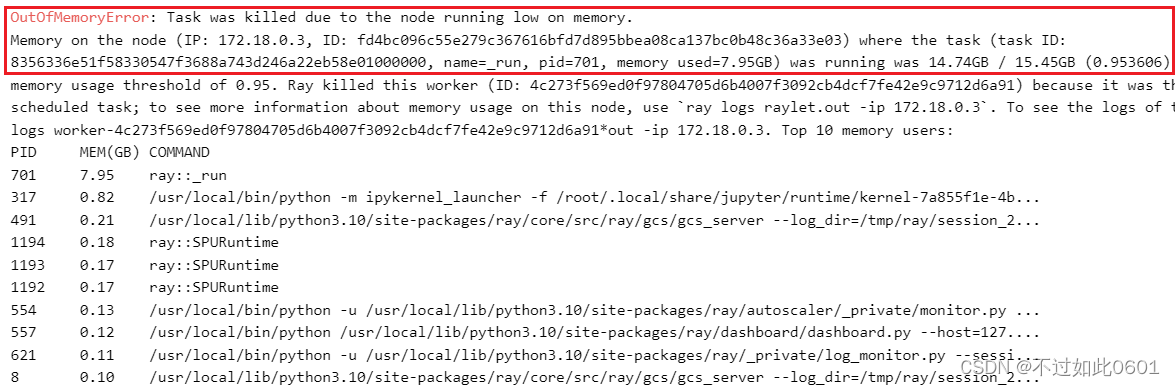
7、輸出密文訓練結果
outputs_ids = sf.reveal(output_token_ids)
print('-' * 65 + '\nRun on SPU:\n' + '-' * 65)
print(tokenizer.decode(outputs_ids[0], skip_special_tokens=True))
print('-' * 65)
至此,本次作業全部結束。






)
:JVM虛擬機調優分析與實戰)




)



)
-第9節(Java內存模型綜述))
)
