長上下文大型語言模型(LCLLMs)確實引起了一些關注。這類模型可能使某些任務的解決更加高效。例如理論上可以用來對整本書進行總結。有人認為,LCLLMs不需要像RAG這樣的外部工具,這有助于優化并避免級聯錯誤。但是也有許多人對此持懷疑態度,并且后來的研究表明,這些模型并沒有真正利用長上下文。還有人聲稱,LCLLMs會產生幻覺錯誤,而其他研究則表明,較小的模型也能高效解決這些任務。
關于長上下文大型語言模型是否真正利用其巨大的上下文窗口,以及它們是否真的更優越,這些問題仍然沒有定論,因為目前還沒有能夠測試這些模型的基準數據集。
但是要充分發揮LCLLMs的潛力,需要對真正的長上下文任務進行嚴格評估,這些任務在現實世界應用中很有用。現有的基準測試在這方面表現不佳,它們依賴于像“大海撈針”這樣的合成任務或固定長度的數據集,這些數據集無法跟上“長上下文”的不斷發展的定義。
所以DeepMind最近構建了一個名為Long-Context Frontiers(LOFT)新基準數據集,試圖解決這一不足。這個新數據集包括六個任務,涵蓋了35個數據集,這些數據集跨越文本、視覺和音頻模態。

這些任務包括:
- 文本、視覺和音頻檢索:該數據集旨在測試模型在多跳推理、指令遵循和少量樣本任務適應等重要挑戰上的能力,你可以在文本、視覺和音頻模態中測試這些能力。
- 檢索增強生成(RAG):在整個語料庫上進行推理,并由于檢索遺漏而減少錯誤。
- SQL:將整個數據庫作為文本處理,從而避免進行SQL轉換。
- 多樣本ICL:擴大在上下文中學習的示例數量,以避免找到少量樣本的最佳數量。
這些新任務和數據集的引入,旨在為長上下文模型的開發和評估提供更全面和現實的測試場景,從而更好地理解和利用這些模型在多模態環境中的潛力。

在考慮新類型任務時,作者們創造了他們所稱的一種新提示方式:語料庫上下文提示(Corpus-in-Context Prompting)。換句話說,整個語料庫都在提示中。這個提示包括:
- 指令:一套指導模型的指令。
- 語料庫格式化:他們將整個語料庫插入到提示中,并為語料庫中的每個元素(例如,段落、圖像、音頻)添加一個唯一標識符(以便在需要時可以識別)。
- 格式化的重要性:對作者而言,格式化對于提高檢索精度尤為重要,特別是對于僅解碼器中的因果注意力。
- 少量樣本示例:提供有限數量的演示有助于讓大型語言模型(LLM)掌握所需的響應格式,并提高任務準確性。示例是從同一語料庫中選擇的,以便學習關于語料庫的細節。
- 查詢格式化:查詢格式化類似于少量樣本中的一個,以提高響應的相關性和準確性。
這種方法的設計旨在讓模型能夠更好地處理和理解大量、多模態的信息,同時減少處理錯誤或誤解的可能。通過這種結構化的提示方式,模型不僅能夠更有效地從語料庫中檢索信息,還能根據具體任務需求進行適當的響應。這種方法的引入可能會對未來的大型語言模型的開發和評估產生重要影響,尤其是在處理長上下文或復雜查詢的場景中。

編碼高達一百萬個令牌的上下文可能會很慢且計算成本高昂。語料庫上下文提示(CiC)的一個關鍵優勢在于它與自回歸語言模型中的前綴緩存兼容,因為查詢出現在提示的末尾。這意味著語料庫只需要被編碼一次,類似于傳統信息檢索中的索引過程。
盡管這種方法看起來復雜,但對于作者來說,這種提示與前綴緩存兼容,因此在模型中只需編碼一次。
作者決定使用以下模型來比較他們的方法:
- Google的Gemini 1.5 Pro(上下文長度超過2M)。
- GPT-4o(128K上下文長度)。
- Claude 3 Opus(200K上下文長度)。
- 為手頭任務開發的專門模型。例如,Gecko是一種最新的雙編碼器,作為檢索任務的專門模型。
這種比較的設定旨在展示不同模型處理長上下文任務的能力,并評估CiC提示策略在實際應用中的效果。通過這種方式,可以更清楚地理解各種模型在處理復雜查詢和長上下文信息時的性能差異。

對于作者來說,使用提示的Gemini模型的表現與專門模型一樣好。當上下文減少到100萬個令牌時,性能會有所下降,但在Gecko模型中這種下降不太明顯。
這表明Gemini模型在處理大量上下文時具有較強的能力,尤其是當利用語料庫上下文提示(CiC)策略時。然而,即使在上下文量減少時,專門為檢索任務設計的Gecko模型仍能保持較高的性能水平。這種差異可能源于Gecko模型特有的結構和優化,使其更適合處理大規模的信息檢索任務,即便在較長的上下文中也能有效地減少性能退化。
這些發現對于理解不同類型的語言模型在處理長上下文任務時的優勢和局限具有重要意義,也為未來模型的設計和優化提供了寶貴的參考。

如果需要找到的文檔位于上下文長度的末尾,性能會有所下降,這主要是因為在提示的后部分注意力減弱。這是自回歸模型處理長文本時常見的問題,尤其是在那些需要維持高度注意力跨度的任務中。
在自回歸語言模型中,由于解碼過程是按順序進行的,模型在處理長文本的后部時可能不如前部那樣敏感和精確。這種現象通常被稱為“注意力衰減”(attention decay),意味著模型在對長距離依賴進行編碼時的效果會隨著距離的增加而逐漸減弱。

作者指出:
- Gemini 1.5 Pro 在所有四個視覺基準測試中都優于 GPT-4o。Gemini 也優于 CLIP 的文本到圖像檢索。
- Gemini 1.5 Pro 在音頻檢索方面與專門模型 PaLM 2 DE 表現相當。
- 在多跳數據集上的檢索增強生成(RAG)流程中,Gemini 表現更為優越。這是因為長上下文大型語言模型(LCLLM)能夠進行多步驟推理(而簡單的 RAG 并不支持這一點)。
對于作者來說,這種性能主要源于長上下文的使用,而不是參數記憶,因為當移除上下文時,性能會顯著下降。這表明,Gemini 模型的高性能依賴于其能夠訪問和處理大量上下文信息的能力。當這些上下文被移除時,模型的性能會受到重大影響,這強調了長上下文在處理復雜問題和任務時的重要性。
長上下文的使用不僅提高了模型在特定任務上的性能,也使得模型在面對需要廣泛信息和多步推理的復雜場景時更加有效。但是這也暴露了模型在缺乏足夠上下文支持時的局限性,進一步表明改進模型的上下文管理和處理能力是未來發展的一個關鍵方向。

在文章中提到,雖然 Gemini 在SQL任務上相比于專門的處理流程表現落后(這并不令人意外,因為這些流程現在已經非常成熟,能夠處理復雜的分析),但它在多樣本上下文學習(Many-Shot ICL)任務中表現優于 GPT-4,在這種任務中,它實際上是在擴大上下文中的示例數量。Claude 似乎表現更好。增加示例數量似乎是有益的,并且性能呈單調增加。但是在更復雜的任務中,情況并非如此,更多的示例似乎并沒有帶來益處。

這些結果表明,在更復雜的任務中,模型從擴大上下文示例數量中學習的能力可能會更早地達到極限。這暗示了在處理高復雜度任務時,僅僅增加上下文中的示例數量并不能持續提升模型的性能,反而可能達到一個性能瓶頸。
這一發現強調了在設計和優化語言模型用于復雜任務處理時的挑戰。它提示我們,在這些情境下,可能需要探索更多的優化策略或者引入新的模型架構,而不是簡單地依賴增加上下文示例的數量。此外,這也表明了模型的泛化能力和適應復雜數據結構的能力在實際應用中的重要性。這種理解有助于未來在設計模型和訓練策略時做出更加明智的選擇,尤其是在面對多樣化和高復雜度任務的場景中。
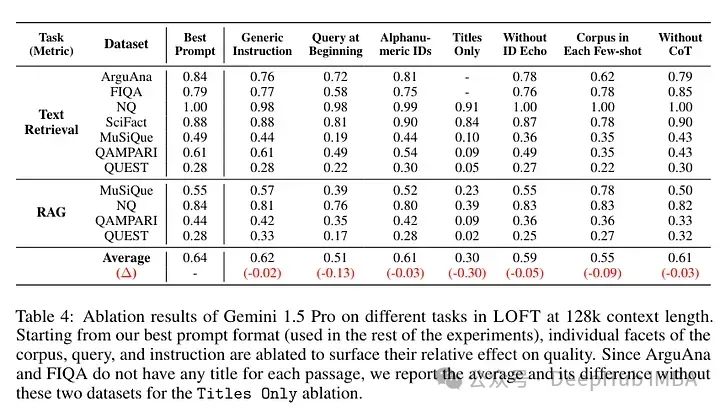
這項研究通過引入LOFT(Long Context Frontiers benchmark)來衡量長上下文大型語言模型(LCLLMs)的進展。LOFT是一組旨在為檢索、檢索增強生成、類SQL推理和上下文中學習等任務提供嚴格評估的任務套件,這些任務被認為是技術變革的成熟領域。
但是該數據集也存在一些局限性。首先是成本問題,如作者所述:
LOFT 128k 測試集包含大約35個數據集×100個提示×128k 令牌 = 448M 輸入令牌,根據當前的計算,對于Gemini 1.5 Pro的成本是$1,568,對于GPT-4o是$2,240,而對于Claude 3 Opus是$6,720。為了降低成本,論文還發布了開發集,這些開發集的大小是原來的十分之一,使用Gemini 1.5 Pro或GPT-4o評估的成本大約是$200。
這項研究并沒有顯示出使用長上下文的明顯優勢。Gemini似乎并不優于Gecko(由DeepMind發布的模型,因此討論的公平性有限)。在實際使用時 RAG的成本并不是高,因為RAG的檢索的成本與大量的令牌成本基本相似,并且對于大多數工業應用來說,2M個令牌還遠遠不夠。
并且,這項研究并沒有消除關于長上下文的疑慮。基準測試中所有模型的表現都非常高,而且可能并不需要使用LCLLM來解決問題,一個正確設置的小型模型就足夠了。Google給出的提示對于許多應用來說過于昂貴,而且需要有少量樣本(與人們通常使用的更動態、對話式的用法相比)。
最后,作者還表明,模型仍然存在位置問題(可能還包括粒度問題),性能在擴展到100萬時迅速下降(大約減半)。
總之,在使用新數據集的這項研究中,LCLLM似乎沒有這些所謂的優勢,或者至少在這項研究中并沒有表現出來。
論文:
Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
https://avoid.overfit.cn/post/8e48436858674be0a0b9306afecb13bc








——過濾器與監聽器)










