在numpy中,最基本的數據結構是數組,因此我們首先需要了解如何創建一個數組。numpy提供了多種數組創建方法,包括從列表或元組創建、從文件中讀取數據、使用特定函數創建等。下面是一些常用的創建方法:
一、創建數組
1. 從列表或元組創建
使用numpy.array()函數可以從列表或元組創建一個數組,例如:
import numpy as np
a = np.array([1, 2, 3])
b = np.array((4, 5, 6))
print(a) # [1 2 3]
print(b) # [4 5 6]
2. 從文件中讀取數據
當我們需要從文件中讀取數據時,可以使用numpy.loadtxt()函數,例如:
import numpy as np
data = np.loadtxt('data.txt')
print(data)
其中data.txt是一個包含數據的文本文件,loadtxt()函數會自動將其讀取為一個numpy數組。
3. 使用特定函數創建
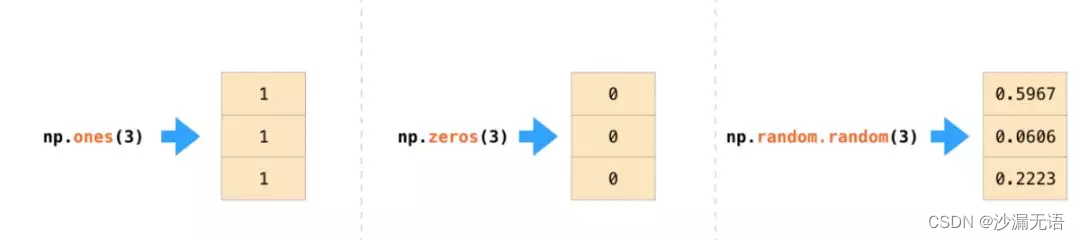
numpy提供了多種特定的函數來創建數組,例如:
import numpy as np
a = np.zeros((3, 4)) # 創建一個3行4列的全0數組
b = np.ones((2, 3)) # 創建一個2行3列的全1數組
c = np.random.rand(2, 4) # 創建一個2行4列的隨機數數組
print(a)
print(b)
print(c)
?
二、數組的算術運算
讓我們創建兩個NumPy數組,分別稱作data和ones:

若要計算兩個數組的加法,只需簡單地敲入data + ones,就可以實現對應位置上的數據相加的操作(即每行數據進行相加),這種操作比循環讀取數組的方法代碼實現更加簡潔。
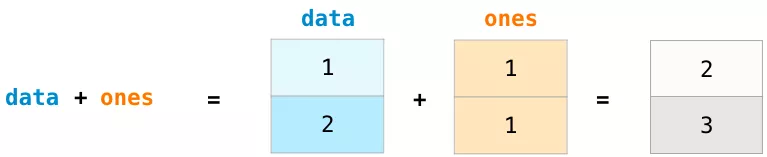
當然,在此基礎上舉一反三,也可以實現減法、乘法和除法等操作:

許多情況下,我們希望進行數組和單個數值的操作(也稱作向量和標量之間的操作)。比如:如果數組表示的是以英里為單位的距離,我們的目標是將其轉換為公里數。可以簡單的寫作data * 1.6:

NumPy通過數組廣播(broadcasting)知道這種操作需要和數組的每個元素相乘。
三、數組的切片操作
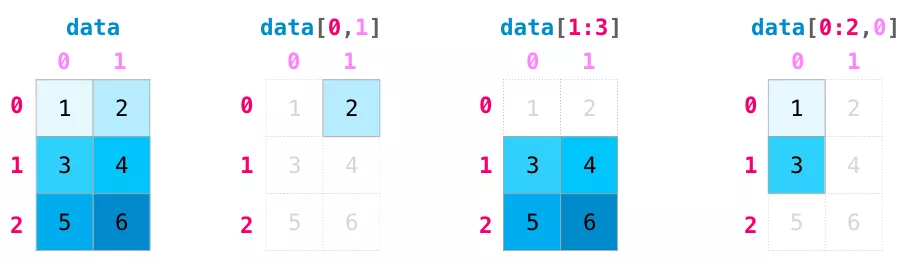
我們可以像python列表操作那樣對NumPy數組進行索引和切片,如下圖所示:

四、聚合函數
NumPy為我們帶來的便利還有聚合函數,聚合函數可以將數據進行壓縮,統計數組中的一些特征值:

除了min,max和sum等函數,還有mean(均值),prod(數據乘法)計算所有元素的乘積,std(標準差),等等。上面的所有例子都在一個維度上處理向量。除此之外,NumPy之美的一個關鍵之處是它能夠將之前所看到的所有函數應用到任意維度上。
五、NumPy中的矩陣操作
創建矩陣
我們可以通過將二維列表傳給Numpy來創建矩陣。
np.array([[1,2],[3,4]])

除此外,也可以使用上文提到的ones()、zeros()和random.random()來創建矩陣,只需傳入一個元組來描述矩陣的維度:

六、矩陣的算術運算
對于大小相同的兩個矩陣,我們可以使用算術運算符(+-*/)將其相加或者相乘。NumPy對這類運算采用對應位置(position-wise)操作處理:
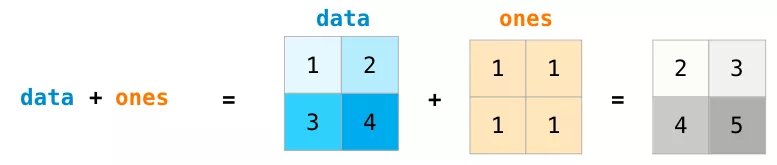
對于不同大小的矩陣,只有兩個矩陣的維度同為1時(例如矩陣只有一列或一行),我們才能進行這些算術運算,在這種情況下,NumPy使用廣播規則(broadcast)進行操作處理:

與算術運算有很大區別是使用點積的矩陣乘法。NumPy提供了dot()方法,可用于矩陣之間進行點積運算:
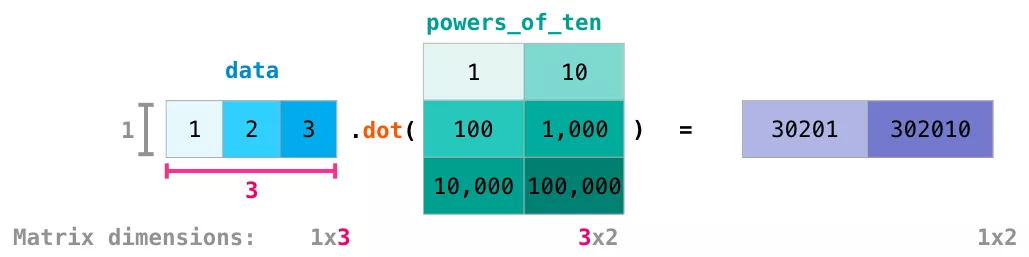
上圖的底部添加了矩陣尺寸,以強調運算的兩個矩陣在列和行必須相等。可以將此操作圖解為如下所示:

七、矩陣的切片和聚合
索引和切片功能在操作矩陣時變得更加有用。可以在不同維度上使用索引操作來對數據進行切片。
我們可以像聚合向量一樣聚合矩陣:

不僅可以聚合矩陣中的所有值,還可以使用axis參數指定行和列的聚合:

八、矩陣的轉置和重構
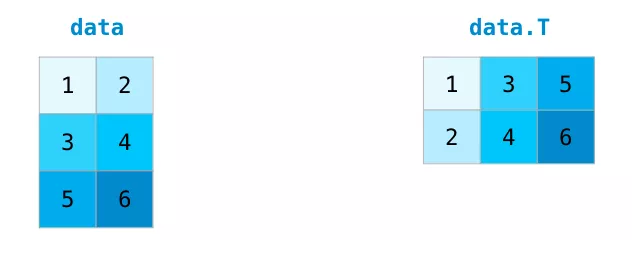
處理矩陣時經常需要對矩陣進行轉置操作,常見的情況如計算兩個矩陣的點積。NumPy數組的屬性T可用于獲取矩陣的轉置。
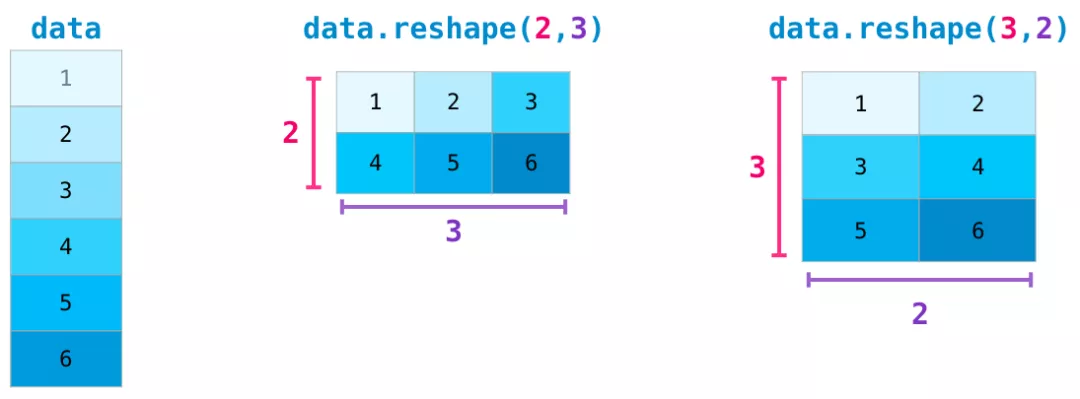
在較為復雜的用例中,你可能會發現自己需要改變某個矩陣的維度。這在機器學習應用中很常見,例如模型的輸入矩陣形狀與數據集不同,可以使用NumPy的reshape()方法。只需將矩陣所需的新維度傳入即可。也可以傳入-1,NumPy可以根據你的矩陣推斷出正確的維度:
上文中的所有功能都適用于多維數據,其中心數據結構稱為ndarray(N維數組)。
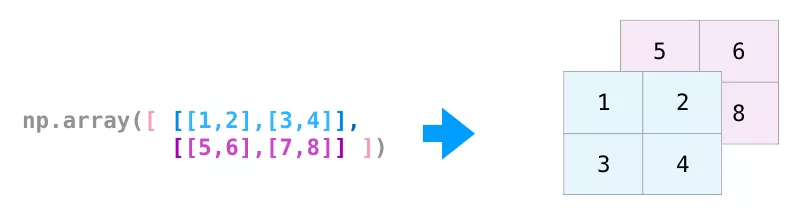
很多時候,改變維度只需在NumPy函數的參數中添加一個逗號,如下圖所示:
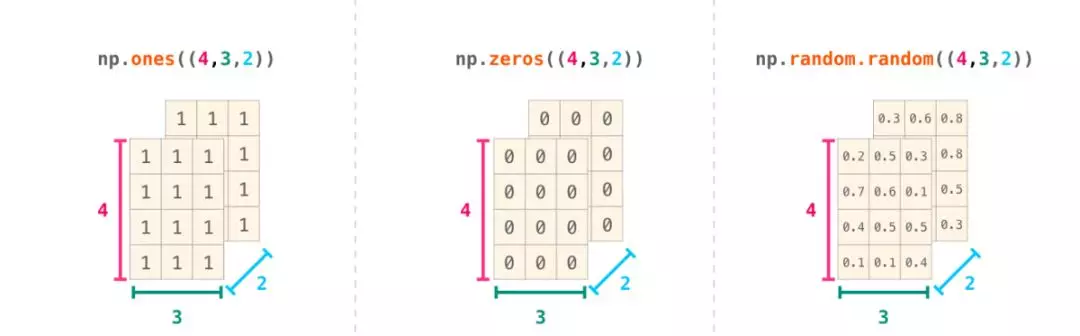
九、NumPy中的公式應用示例
NumPy的關鍵用例是實現適用于矩陣和向量的數學公式。這也Python中常用NumPy的原因。例如,均方誤差是監督機器學習模型處理回歸問題的核心:
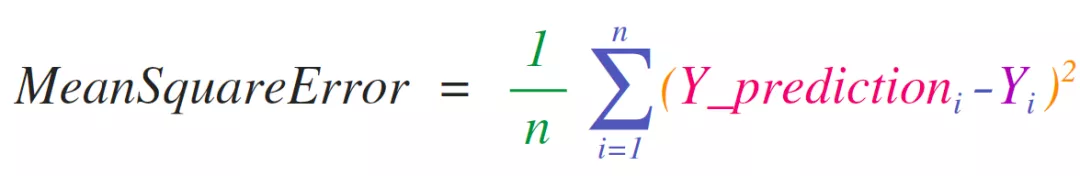
在NumPy中可以很容易地實現均方誤差:

這樣做的好處是,numpy無需考慮predictions與labels具體包含的值。文摘菌將通過一個示例來逐步執行上面代碼行中的四個操作:

預測(predictions)和標簽(labels)向量都包含三個值。這意味著n的值為3。在我們執行減法后,我們最終得到如下值:

然后我們可以計算向量中各值的平方:

現在我們對這些值求和:

最終得到該預測的誤差值和模型質量分數。
十、用NumPy表示日常數據
日常接觸到的數據類型,如電子表格,圖像,音頻……等,如何表示呢?Numpy可以解決這個問題。
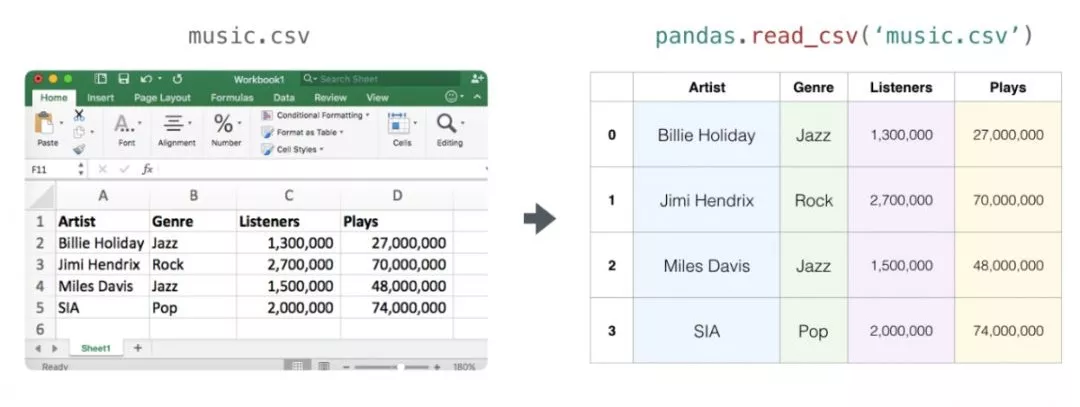
1、表和電子表格
電子表格或數據表都是二維矩陣。電子表格中的每個工作表都可以是自己的變量。python中類似的結構是pandas數據幀(dataframe),它實際上使用NumPy來構建的。
2、音頻和時間序列
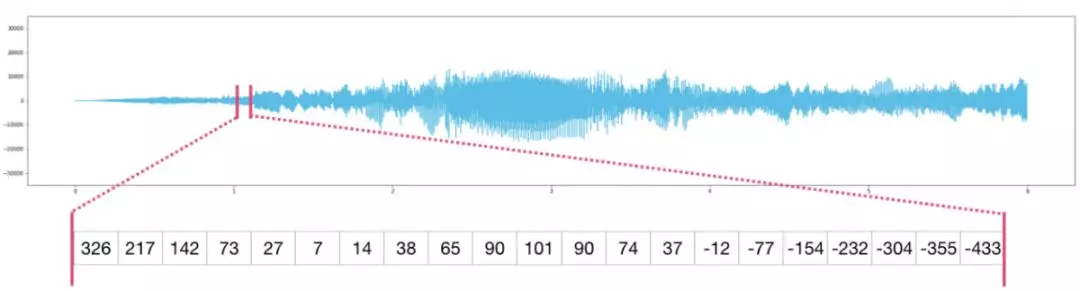
音頻文件是一維樣本數組。每個樣本都是代表一小段音頻信號的數字。CD質量的音頻每秒可能有44,100個采樣樣本,每個樣本是一個-65535到65536之間的整數。這意味著如果你有一個10秒的CD質量的WAVE文件,你可以將它加載到長度為10 * 44,100 = 441,000個樣本的NumPy數組中。想要提取音頻的第一秒?只需將文件加載到我們稱之為audio的NumPy數組中,然后截取audio[:44100]。
以下是一段音頻文件:
時間序列數據也是如此(例如,股票價格隨時間變化的序列)。
3、圖像
圖像是大小為(高度×寬度)的像素矩陣。如果圖像是黑白圖像(也稱為灰度圖像),則每個像素可以由單個數字表示(通常在0(黑色)和255(白色)之間)。如果對圖像做處理,裁剪圖像的左上角10 x 10大小的一塊像素區域,用NumPy中的image[:10,:10]就可以實現。
這是一個圖像文件的片段:

如果圖像是彩色的,則每個像素由三個數字表示 :紅色,綠色和藍色。在這種情況下,我們需要第三維(因為每個單元格只能包含一個數字)。因此彩色圖像由尺寸為(高x寬x 3)的ndarray表示。

4、語言
如果我們處理文本,情況就會有所不同。用數字表示文本需要兩個步驟,構建詞匯表(模型知道的所有唯一單詞的清單)和嵌入(embedding)。讓我們看看用數字表示這個(翻譯的)古語引用的步驟:“Have the bards who preceded me left any theme unsung?”
模型需要先訓練大量文本才能用數字表示這位戰場詩人的詩句。我們可以讓模型處理一個小數據集,并使用這個數據集來構建一個詞匯表(71,290個單詞):

然后可以將句子劃分成一系列“詞”token(基于通用規則的單詞或單詞部分):

然后我們用詞匯表中的id替換每個單詞:

這些ID仍然不能為模型提供有價值的信息。因此,在將一系列單詞送入模型之前,需要使用嵌入(embedding)來替換token/單詞(在本例子中使用50維度的word2vec嵌入):


![[leetcode]max-consecutive-ones 最大連續1的個數](http://pic.xiahunao.cn/[leetcode]max-consecutive-ones 最大連續1的個數)
)



 - HRP Conjugated)







![[240701] 蘋果設備持久耐用,人工智能戰略成未來致勝關鍵](http://pic.xiahunao.cn/[240701] 蘋果設備持久耐用,人工智能戰略成未來致勝關鍵)




