在上一章中羅列了對RAG準確度的幾個重要關鍵點,主要包括2方面,這一章就針對其中一方面,來做詳細的講解以及其解決方案。
目錄
- 1 文檔解析
- 1.1 文檔解析工具
- 1.2 實戰經驗
- 1.3 代碼演示
- 2 文檔分塊
- 2.1 分塊算法
- 2.2 實戰經驗
- 2.3 代碼演示
- 3 文檔embedding
- 3.1 實戰經驗
- 3.2 代碼演示
- 4 向量數據庫
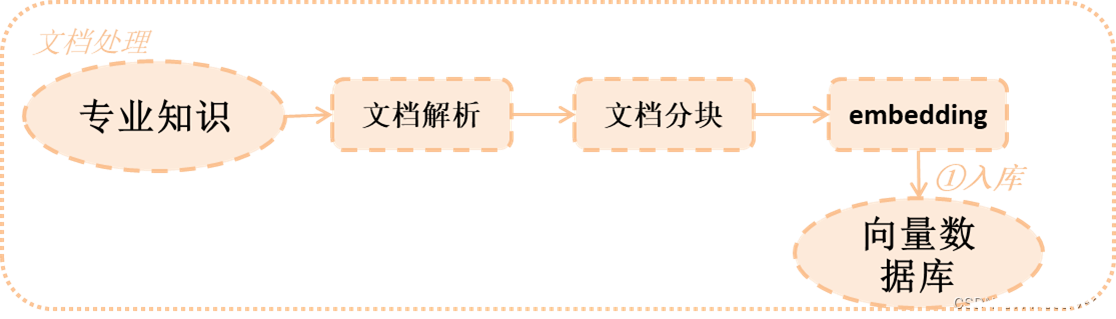
1 文檔解析
對于我們來說,查詢的文檔可能包括pdf、Excel、圖片等等各種各樣的內容,而這些內容中包括很多不同的格式,比如pdf中可能還包括表格和圖片,因此選擇哪些文檔解析工具非常重要。
1.1 文檔解析工具
在市面上有很多各種各樣的解析工具,不同解析工具有著不同的解析方法,在langchain中已經集成了很多針對不同類型文檔的解析,可供大家選擇。(注意:其中有(非)標志代表沒有集成在langchain中,另外還有其它的就沒有一一羅列了)
| 文檔類型 | 解析工具 |
|---|---|
| txt | TextLoader、unstructured |
| unstructured、pypdf、pdfplumer、pdfminer、Camelot(非)、pymupdf(非)、LlamaParse (非) | |
| word | unstructured |
| PPT | unstructured |
| html | unstructured、Firecrawl(非) |
| json | JSONLoader |
| 圖片 | unstructured |
| Excel | CSVLoader |
| markdown | unstructured |
| unstructured | |
| arxiv | ArxivLoader |
1.2 實戰經驗
其實不同文件的讀取無非就是想看看能否很好的將文件內容解析出來,而解析的好與壞其實跟你要解析的文檔息息相關。以下是常見幾個考察點:
- 文本不丟失
- 語言支持情況(中文、英文等)
- 段落信息是否能解析(段落其實是一個很重要卻容易被忽視的考察點,因為模型是理解文本,因此段落有助于更好的理解文檔的語義)
- 標題是否能識別
- 表格,圖片信息能否讀取
- 針對不同文檔類型的細節(比如pdf的頁頭、頁尾、分欄等細節)
下面以pdf為例,簡述一下pdf各類工具的優缺點:
| 工具 | 語言支持 | 段落信息 | 表格圖片 | 細節 |
|---|---|---|---|---|
| pypdf | 英文支持較好 | 段落支持一般 | 表格圖片差 | 分欄 |
| pdfplumer | 中文支持好 | 段落支持好 | 表格讀取好 | 分欄效果不好 |
| pdfminer | 中文支持好 | 段落支持好 | 表格圖片一般 | 分欄 |
| pymupdf(非) | 中午支持較好 | 段落支持好 | 表格圖片一般 | 分欄 |
| Camelot(非) | 中文支持好 | 段落支持一般 | 表格圖片好 | 分欄 |
| LlamaParse (非) | 中午支持較好 | 段落支持好 | 表格圖片好 | 分欄 |
1.3 代碼演示
以下以PyPDF和PDFMiner為例子給大家演示一下代碼
# 1 PyPDF演示,安裝pypdf:pip install pypdf
from langchain.document_loaders import PyPDFLoaderloader = PyPDFLoader("data/demo.pdf")
pages = loader.load()
# 讀取后pages長度=6,說明按照每一頁讀取的
print(len(pages))
# 段落,我們可以看到其中文本:ABSTRACT 的前面的換行與其它換行并不沒有不同,因此識別段落一般
print(pages[0].page_content[300:400])
# 表格,之所以選取第4頁,是該頁有表格,可以看到表格內容已經被解析出來
print(pages[3].page_content)
# 圖片,之所以選取第3頁,是該頁有圖片(可以看到圖片不能解析,需要配合rapidocr-onnxruntime,后續有例子)
print(pages[2].page_content)
# 讀取圖片,需要安裝rapidocr-onnxruntime:pip install rapidocr-onnxruntime
loader = PyPDFLoader("data/demo.pdf", extract_images=True)
pages = loader.load()
print(pages[2].page_content)# 2 演示PDFMiner,提前安裝pdfminer.six:pip install pdfminer.six
from langchain.document_loaders import PDFMinerLoaderloader = PDFMinerLoader("data/demo.pdf")
pages = loader.load()
# 讀取后pages長度=1,說明將文檔按照一頁讀取
print(len(pages))
# 段落,我們可以看到其中文本:ABSTRACT 的前面的換行與其它換行不同,因此很好的識別段落
print(pages[0].page_content[400:600])
# 表格和圖片,我們可以找一些大概第3頁的圖片能夠被解析出來,第4頁表格內容也能夠被解析出來
print(pages[0].page_content)從上面代碼可以看出,我們分析了幾個要素
- 段落:很明顯PDFMiner能夠識別更好的段落,即大標題這些可以有2個換行符合,而PyPDF并不能
- 圖片和表格:PyPDF增加插件也能識別
- 分頁:為什么要列分頁,因為這樣省的你去講每一頁都手動連接在一起
- 換行:這里還有一個細節,就是事實上pdf中的換行并不是內容真正換行,大家可以嘗試一下unstructured,實際上會將不是真正換行的拼接在一起,這樣可以讓模型理解語義更加容易
因此對于不同文件類型,選型非常重要,特別是對你的業務文檔類型以及文檔中包含的內容,都是一種考察需求。
2 文檔分塊
前文已經講了之所以要分塊是因為2個原因:
- 因為大模型有token長度限制
- 過長的token其實對于大模型的理解和推理會變慢或者不準確。
那么文檔分塊如何分,怎么分才是最佳的,下面通過2個方面講述一下
2.1 分塊算法
文本分塊的的分割流程如下:
- 1)將文本拆分為小的、語義上有意義的塊(通常是句子)。
- 2)將這些小塊組合成較大的塊,直到達到某個大小(即你設定的大小,通常有一個函數測量)。
- 3)一旦達到該大小,將該塊作為自己的文本片段,然后開始創建一個具有一定重疊的新文本塊(以保持塊之間的上下文)。
分塊流程如上,那么這意味著有3個方面將影響你的分塊:
- 文本如何拆分
- 塊大小如何測量
- 重疊塊大小
下表就是按照不同分塊邏輯,羅列出目前的分塊算法,其應用也在描述中體現出來,大家可以按照自身文檔的內容選取不同的分塊算法:
| 方法 | 分塊符號 | 是否加入metadata | 描述 |
|---|---|---|---|
| Character | 用戶自定義字符 | 基于用戶定義的字符拆分文本。一種更簡單的方法。 | |
| Recursive | 用戶自定義字符的列表 | 遞歸拆分文本。遞歸分割文本的目的是試圖將相關的文本片段保持在一起。這是開始拆分文本的推薦方式。 | |
| Markdown | Markdown 特定字符 | √ | 基于特定于Markdown的字符拆分文本。值得注意的是,這增加了關于該塊來自哪里的相關信息(基于降價) |
| HTML | HTML特定字符 | √ | 基于特定于HTML的字符拆分文本。值得注意的是,這添加了關于該塊來自何處的相關信息(基于HTML) |
| Code | Code (Python, JS) 特定字符 | 基于特定于編碼語言的字符拆分文本。有15種不同的語言可供選擇。 | |
| Token | Tokens | 拆分令牌上的文本。有幾種不同的方法來衡量token。 | |
| Semantic Chunker | 句子或語義 | 首先對句子進行拆分。然后,如果它們在語義上足夠相似,就將它們組合在一起。 |
2.2 實戰經驗
如何選擇符合自身業務的分塊,這里有一些準則可供大家參考:
- 分塊算法:不同業務類型,對應不同的分塊算法,在2.1中的表格可以供大家選擇。
- 塊的大小:這一部分可能沒有統一標準說到底多大合適,一般都需要通過實驗驗證。比如你使用什么模型,其token限制是多少,然后在此基礎上,可以按照128、256、512、1024等等不同分塊方式去測試比如:響應時間、正確率、關聯度等指標。
- 重疊部分:至于需要重疊多少,這個也是沒有統一標準,按照塊的大小的方式去測試。
2.3 代碼演示
下面例子,選擇Recursive分塊算法,來說明一下分塊時需要注意的問題:
from langchain.text_splitter import RecursiveCharacterTextSplittertext = '''ChatGLM-6B 是一個開源的、支持中英雙語的對話語言模型,基于 General Language Model (GLM) 架構,具有 62 億參數。結合模型量化技術,用戶可以在消費級的顯卡上進行本地部署(INT4 量化級別下最低只需 6GB 顯存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技術,針對中文問答和對話進行了優化。經過約 1T 標識符的中英雙語訓練,輔以監督微調、反饋自助、人類反饋強化學習等技術的加持,62 億參數的 ChatGLM-6B 已經能生成相當符合人類偏好的回答,更多信息請參考我們的博客。歡迎通過 chatglm.cn 體驗更大規模的 ChatGLM 模型。為了方便下游開發者針對自己的應用場景定制模型,我們同時實現了基于 P-Tuning v2 的高效參數微調方法 (使用指南) ,INT4 量化級別下最低只需 7GB 顯存即可啟動微調。ChatGLM-6B 權重對學術研究完全開放,在填寫問卷進行登記后亦允許免費商業使用。'''# 1.按照300進行分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=300,chunk_overlap=0,length_function=len
)
chunks = text_splitter.split_text(text)
print(len(chunks))
# 我們可以看到其分割為3段,長度分別是10、292、136.其實他默認的分隔符就是換行
for chunk in chunks:print(len(chunk))# 2.按照200進行分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200,chunk_overlap=0,length_function=len
)
chunks = text_splitter.split_text(text)
print(len(chunks))
# 我們可以看到其分割為4段,長度分別是10、169、122、136。其中第二段被分了2段。因為原來第二段不符合200.
for chunk in chunks:print(len(chunk))
# 但是這里有個問題,可以打印第二段,發現其分割有點隨機,把我們有語義關聯的一句話分開掉。
print(chunks[1])# 3.解決分割不符合語義,通過separators傳入分割符合,會按照分割符合順序進行分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200,chunk_overlap=0,length_function=len,separators=["\n", "。", ","],keep_separator=True
)
chunks = text_splitter.split_text(text)
print(len(chunks))
# 我們可以看到其分割為4段,長度分別是10、162、130、136。
for chunk in chunks:print(len(chunk))
# 這里就解決了分割
print(chunks[1])從上面代碼可以看到
- 分塊的邏輯:是先按照一個大的分隔符進行分割,默認是換行符,然后再將較小的合并到符合長度之下。也就是前面所說的分割流程
- 分塊分隔符:當默認的時,有可能沒有次級的分塊分隔符,那么會隨機切斷,所以使用separators參數傳入,可以更好分割
3 文檔embedding
文檔最終是通過embedding向量化后存入向量數據庫,而選擇不同embedding對于最終查詢來說非常重要(這里大家可以自行補一下embedding基礎,這里就不講embedding原理)。如果embedding做得不好,導致查詢的結果與答案不一致,那么如何選對embedding也是對于RAG的準確度至關重要。
這里需要注意的是embedding也是一個訓練好的模型,目前大部分開源的embedding模型都是使用Sentence Bert。這里不詳細講述,大家有興趣可以去了解其論文。這個主要給大家講述幾個重要選擇embedding模型的實戰參考。
3.1 實戰經驗
對于我們如何選擇一個embedding,我根據一些實戰中的經驗總結如下:
- 排行榜:首先要知道有哪些embedding模型,一般我們去hugging face的排行版上找:https://huggingface.co/spaces/mteb/leaderboard
- 語言:在排行榜中,你可以根據你的業務選擇語言
- embedding維度:這個需要根據你的業務,如果你業務語義豐富,那么選擇維度更高更好,如果語義不豐富,其實選擇維度更低會更好。
- sequence length:不同embedding模型支持不同sequence length,因此需要根據你的業務選擇不同的模型
- 模型大小:這個會根據實際你有多少資源作為選擇標準
- 業務效果:以上幾個標準可能只是基本維度,最終還是需要看看業務效果,因此你可能需要選擇幾個比較合適的模型,然后再逐一的去測試一下其效果相對于你的業務結果如何
3.2 代碼演示
下面通過m3e-base模型加上TSNE畫出相關性,可以直觀感受到你的模型是否準確理解句子的語義。
(注明:本例子來自大神的demo代碼:https://github.com/blackinkkkxi/RAG_langchain/blob/main/learn/embedding_model/embedd.ipynb)
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
from sentence_transformers import SentenceTransformermodel = SentenceTransformer('moka-ai/m3e-base')# 測試句子
sentences =['為什么良好的睡眠對健康至關重要?' ,'良好的睡眠有助于身體修復自身,增強免疫系統','在監督學習中,算法經常需要大量的標記數據來進行有效學習','睡眠不足可能導致長期健康問題,如心臟病和糖尿病','這種學習方法依賴于數據質量和數量','它幫助維持正常的新陳代謝和體重控制','睡眠對兒童和青少年的大腦發育和成長尤為重要','良好的睡眠有助于提高日間的工作效率和注意力','監督學習的成功取決于特征選擇和算法的選擇','量子計算機的發展仍處于早期階段,面臨技術和物理挑戰','量子計算機與傳統計算機不同,后者使用二進制位進行計算','機器學習使我睡不著覺',
]
# 通過調用model的encode進行embedding
embeddings = model.encode(sentences)
len(embeddings)
len(embeddings[0])
# 通過TSNE工具畫出圖表來直觀看看相關性
tsne = TSNE(n_components=2 , perplexity=5)
embeddings_2d = tsne.fit_transform(embeddings)
plt.rcParams['font.sans-serif'] = ['Kaitt', 'SimHei']
plt.rcParams['axes.unicode_minus'] = False
color_list = ['black'] * len(embeddings_2d[1:])
color_list.insert(0, 'red')
plt.scatter(embeddings_2d[:, 0], embeddings_2d[:, 1] , color=color_list )
for i in range(len(embeddings_2d)):plt.text(embeddings_2d[:,0][i], embeddings_2d[:,1][i]+2, sentences[i] ,color=color_list[i] )# 顯示圖表
plt.show()4 向量數據庫
向量數據庫需要存儲向量化后的數據,然后通過問題查詢相似度,得到最終相關的幾個答案,扔給大模型進行回答。那么向量數據庫的存儲和相似度查詢就可能會影響RAG最終的結果,因此,我們選擇哪一種向量數據庫,對于我們來說還是比較重要的。(注意:這里可能只從影響RAG準確度來說,真正選擇向量數據庫可能要考慮的方面還是比較多的,這里就不列舉了)
向量數據庫中,相似度是我們最看重的指標之一,因為它對于RAG最終的準確度有著很大的影響。以下表格列出幾種不同相似度算法及其應用場景(注意也還有不同的算法,這里就不再累述,只是作為說明相似度)
| 算法 | 原理 | 應用場景 | 對應數據庫 |
|---|---|---|---|
| 歐氏距離 | 歐幾里得空間中,兩個點之間的最短直線距離 | 機器學習:歐氏距離常用于 k 最近鄰算法 (KNN) 中,計算樣本之間的距離。圖像檢索:歐氏距離常用于圖像檢索中,計算圖像之間的相似度。推薦系統:歐氏距離常用于推薦系統中,計算用戶之間的相似度 | Chroma、Milvus、Faiss |
| 余弦相似度 | 在向量空間中,兩個向量夾角的余弦值 | 文本檢索:余弦相似度常用于文本檢索中,計算文本之間的相似度。自然語言處理:余弦相似度常用于自然語言處理中,計算詞語之間的相似度。信息檢索:余弦相似度常用于信息檢索中,計算文檔之間的相似度 | Chroma、Milvus |
| 點積相似度 | 兩個向量的點積除以它們的模長的乘積 | 文本檢索:點積相似度常用于文本檢索中,計算文本之間的相似度。自然語言處理:點積相似度常用于自然語言處理中,計算詞語之間的相似度。推薦系統:點積相似度常用于推薦系統中,計算用戶之間的相似度 | Chroma、Milvus 、Faiss |
| 曼哈頓距離 | 兩個向量對應分量差的絕對值的總和 | 圖像處理:曼哈頓距離常用于圖像處理中,計算圖像之間的差異。機器學習:曼哈頓距離常用于機器學習中,計算樣本之間的距離。數據挖掘:曼哈頓距離常用于數據挖掘中,計算數據點之間的相似度 | Faiss |






![[240701] 蘋果設備持久耐用,人工智能戰略成未來致勝關鍵](http://pic.xiahunao.cn/[240701] 蘋果設備持久耐用,人工智能戰略成未來致勝關鍵)










266)
:xpath和lxml類庫)
