論文鏈接:Side Adapter Network for Open-Vocabulary Semantic Segmentation
代碼鏈接:https://github.com/MendelXu/SAN
作者:Mengde Xu,Zheng Zhang,Fangyun Wei,Han Hu,Xiang Bai
發表單位:華中科技大學、微軟亞洲研究院
會議/期刊:CVPR2023 Highlight
一、研究背景

ImageNet 上的分割結果。對于每個圖像,將其類別與 coco 類別結合起來作為推理過程中的詞匯表,并且僅可視化注釋類別的掩碼
現代語義分割方法依賴于大量標注數據,但數據集通常只包含數十到數百個類別,數據收集和標注成本高昂。近年來,大規模視覺-語言模型(如CLIP)在圖像分類任務中取得了巨大成功,但在像素級別的語義分割中應用這些模型面臨挑戰,因為這些模型的訓練側重于圖像級別的對比學習,它學習到的表示缺乏語義分割所需的像素級識別能力。彌補表示粒度差距的一種解決方案是在分割數據集上微調模型。然而,分割數據集的數據量遠小于視覺語言預訓練數據集,因此微調模型在開放詞匯識別上的能力常常受到損害。
將語義分割建模為區域識別問題繞過了上述困難。早期嘗試采用兩階段訓練框架。
在第一階段,訓練一個獨立模型來生成一組蒙版圖像作物作為蒙版建議。
在第二階段,使用視覺語言預訓練模型(例如 CLIP)來識別蒙版圖像裁剪的類別。然而,由于掩模預測模型完全獨立于視覺語言預訓練模型,它錯過了利用視覺語言預訓練模型強大特征的機會,并且預測的掩模圖像裁剪可能不適合識別,這會導致模型笨重、緩慢且性能低下。
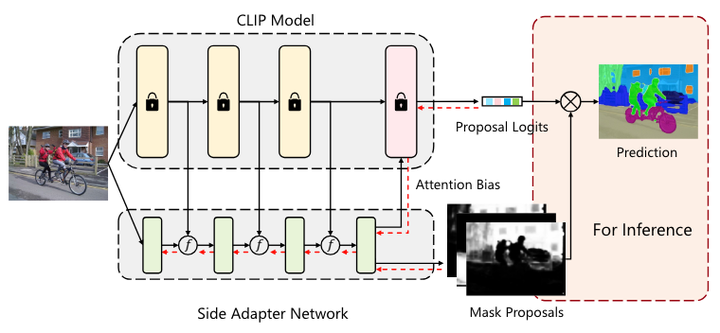
SAN 概述
為了實現這一目標,提出了一個新的框架(上圖所示),稱為側適配器網絡 (side adapter network, SAN)。由于端到端訓練,它的掩模預測和識別是 CLIP 感知的,并且由于利用了 CLIP 的特性,它可以是輕量級的。
紅色虛線表示訓練期間的梯度流。在框架中,凍結的 CLIP 模型仍然充當分類器,并且側適配器網絡生成掩碼提案和注意偏差,以指導 CLIP 模型的更深層來預測提案明智的分類邏輯。在推理過程中,將 mask proposal 和proposal logits 結合起來,通過 Matmul(矩陣乘法函數)得到最終的預測。
二、整體框架
本文提出了一種新的開放詞匯語義分割框架——Side Adapter Network (SAN)。該方法將語義分割任務建模為區域識別問題。SAN附加在凍結的CLIP模型上,具有兩個分支:一個用于預測掩碼提案,另一個用于預測應用在CLIP模型中的注意力偏差,以識別掩碼的類別。整個網絡可以端到端訓練,使附加的側網絡能夠適應凍結的CLIP模型,從而使預測的掩碼提案對CLIP感知。
作者證明這種解耦設計提高了分割性能,因為用于 CLIP 識別掩模的區域可能與掩模區域本身不同。為了最大限度地降低 CLIP 的成本,進一步提出了單前向設計:將淺層 CLIP 塊的特征融合到 SAN,并將其他更深的塊與注意力偏差相結合以進行掩模識別。
因為用于 CLIP 識別掩模的區域可能與掩模區域本身不同的理解:CLIP模型主要是通過對比學習在圖像級別進行訓練的,其學習到的特征更偏向于全局或大范圍的圖像特征,而不是具體的像素級別特征。當CLIP模型應用于掩模識別時,它的注意力機制可能會關注到一些與掩模區域有重疊但并不完全一致的區域。這種不完全一致性是因為CLIP的注意力機制可能會將注意力分散到整個圖像中一些相關的部分,而不僅僅是掩模的邊界或內部區域。
假設有一張圖像,其中有一只狗在草地上。CLIP模型可能會關注到整只狗以及周圍的草地作為特征進行分類,而語義分割任務僅需要標注出狗的具體輪廓區域。這時,CLIP的識別區域(整只狗和部分草地)與實際需要的掩模區域(狗的輪廓)并不完全一致。
出于公平性和可重復性的目的,該研究基于官方發布的 CLIP 模型。重點關注已發布的 ViT CLIP 模型,因為視覺 Transformer 事實上已經取代 ConvNet 成為計算機視覺社區的主導骨干網,并且為了概念的一致性和簡單性,側適配器網絡也由視覺 Transformer 實現。
準確的語義分割需要高分辨率圖像,但已發布的ViT CLIP模型是針對低分辨率圖像(例如224×224)設計的,直接應用于高分辨率圖像,性能較差。為了緩解輸入分辨率的沖突,在 CLIP 模型中使用低分辨率圖像,在側適配器網絡中使用高分辨率圖像。作者證明這種不對稱輸入分辨率非常有效。此外,還探索僅微調 ViT 模型的位置嵌入并注意改進。
三、核心方法 Side Adapter Network
3.1 架構介紹
Side Adapter Network (SAN) 是一個端到端的框架,旨在充分利用CLIP模型在開放詞匯語義分割中的能力。SAN由一個輕量級的視覺Transformer實現,可以利用CLIP的特征,并且有兩個輸出:掩碼提案和用于掩碼識別的注意力偏差。這些注意力偏差應用于CLIP的自注意力機制,以識別掩碼提案的類別。
在實踐中,將淺層 CLIP 層的特征融合到 SAN 中,并將注意力偏差應用于更深的 CLIP 層以進行識別。通過這種單前向設計,可以最大限度地降低 CLIP 模型的成本。
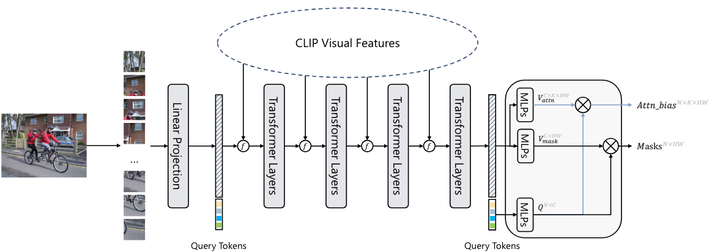
SAN的詳細架構
-
輸入圖像:輸入圖像被分割成16×16的圖像塊,每個塊通過線性嵌入層投射為視覺tokens。
-
視覺tokens與查詢tokens:這些視覺tokens與N個可學習的查詢tokens連接在一起,并輸入到隨后的Transformer層中。
-
輸出:SAN有兩個輸出:掩碼提案和用于掩碼識別的注意力偏差。查詢tokens和視覺tokens分別通過兩個獨立的3層MLP(多層感知器)投射為256維度的向量,用于生成掩碼提案和注意力偏差。
投影查詢標記可以表示為 ,其中N是查詢標記的數量,默認等于100。投影視覺標記可以表示為
,其中H和W是輸入的高度和寬度圖像。最后的預測mask由Q mask和V mask的內積生成:
其中, ,產生注意力偏差類似于掩模預測。查詢標記和視覺標記也由 3 層 MLP 投影,表示為
,其中 K 是 ViT CLIP 的注意力頭數量。通過內部生成Q attn和V attn,得到了注意力偏差:
其中, ,此外,如果需要,注意力偏差將進一步調整為
,其中h和w是 CLIP 中注意力圖的高度和寬度。在實踐中,Q mask和Q attn可以共享,并且注意力偏差將應用于CLIP的多個自注意力層中,即偏差用于不同的自注意力層中。
掩模預測和識別的解耦設計背后的動機很直觀:用于在 CLIP 中識別掩模的感興趣區域可能與掩模區域本身不同。
3.2 Feature fusion on visual tokens 視覺標記上的特征融合
在ViT模型中,視覺tokens和[CLS] token是主要的特征表示。為了充分利用CLIP模型的強大特征,SAN將CLIP模型的視覺tokens與SAN的視覺tokens進行特征融合。具體步驟如下:
-
特征重排:由于CLIP和SAN的視覺tokens數量和特征維度可能不同,首先將CLIP的視覺tokens重新排列為特征圖,經過1×1卷積和重尺寸操作來調整通道維度和特征圖大小。
-
特征融合:將調整后的CLIP特征圖與SAN的對應特征圖進行逐元素相加,從而實現特征融合。特征融合在多個層次上進行,例如在12層的ViT-B/16 CLIP模型和8層的SAN模型中,將CLIP的{stem,3,6,9}層的特征與SAN的{stem,1,2,3}層的特征融合。
3.3 Mask recognition with attention bias 帶有注意偏差的掩模識別
原始的CLIP模型只能通過[CLS] token進行圖像級的識別,為了在CLIP模型中實現精確的掩碼識別,SAN引入了注意力偏差,這些偏差用于指導CLIP模型的[CLS] token在感興趣區域進行識別。
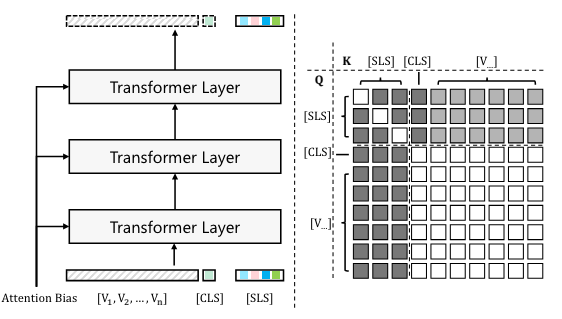
在 CLIP 中使用注意偏差來預測掩模的圖示
左圖創建一組 [SLS] 令牌(即影子 [CLS] 令牌副本)并將其應用于 CLIP。這些[SLS]令牌在注意力偏差的影響下更新。 右圖該圖顯示了不同類型的令牌如何相互作用。方塊的顏色表示query token和key token之間的關系:黑色表示query沒有被key更新,白色表示query可以正常被key更新,灰色表示在attention的作用下query可以被key更新偏見。
過程總結:
-
生成[SLS] tokens:創建一組[CLS] token的影子副本([SLS] tokens),這些副本在更新時僅受視覺tokens的影響,而不會反過來影響視覺tokens或[CLS] tokens。
-
添加注意力偏差:在計算注意力時,將預測的注意力偏差Bk添加到注意力矩陣中,從而引導[SLS] tokens的特征逐漸適應掩碼預測。
-
類別預測:通過比較[SLS] token與CLIP文本嵌入的類別名稱之間的距離或相似度,輕松獲得掩碼的類別預測。
在計算注意力時,預測的注意力偏差 Bk 被添加到注意力矩陣中,從而引導[SLS] tokens的特征逐漸適應掩碼預測。公式如下:
其中,l 表示層數,k表示第 k個注意力頭,Q[SLS]=Wq X[SLS]和 V[SLS]=Wv X[SLS] 是[SLS] tokens的查詢和value嵌入,Kvisua l=Wk Xvisual 是視覺tokens的鍵嵌入,Wq,Wk,Wv 是查詢、鍵、value嵌入層的權重。
在原始設計中,計算復雜度為:
Tvisual? 是視覺tokens的數量,T[CLS] 是[CLS] token的數量(通常為1),T[SLS]? 是[SLS] tokens的數量。
這個計算復雜度考慮了所有類型的tokens,并假設它們都通過屏蔽自注意力層(masked self-attention layer)進行更新。具體來說,每個token與所有其他token進行交互,導致了二次復雜度。
為了降低計算復雜度,作者提出使用交叉注意力(cross-attention)來更新[SLS] tokens。交叉注意力與自注意力共享嵌入權重,但只涉及特定類型的token之間的交互。這使得計算復雜度降低為:
隨著注意力偏差的應用,[SLS] tokens 的特征逐漸演化以適應掩碼預測。掩碼的類別預測通過比較[SLS] tokens和CLIP文本嵌入的類別名稱之間的距離或相似度來獲得:
其中 C 是類別數量,N 是查詢tokens的數量。
3.4 Segmentation map generation
最后,結合掩碼提案 和掩碼的類別預測
,通過矩陣乘法生成最終的分割圖 S:
其中, 。
為了訓練模型,mask生成通過dice損失L mask_dice和二元交叉熵損失L mask_bce進行監督。mask模識別通過交叉熵損L cls進行監督。總損失為:
損失權重𝜆1、𝜆2、𝜆3分別為 5.0、5.0 和 2.0。 通過端到端訓練,側適配器網絡可以最大限度地適應凍結的CLIP模型,因此掩模建議和注意偏差是CLIP感知的。
四、實驗結果
在 6 個數據集上進行了實驗:COCO Stuff、ADE20K-150、ADE20K-847、Pascal Context-59、Pascal Context-459 和 Pascal VOC。按照常見的做法,所有模型都在 COCO Stuff 的訓練集上進行訓練,并在其他數據集上進行評估。
-
COCO Stuff:它包含 164K 圖像和 171 個注釋類,分為訓練集、驗證集和測試集,分別包含 118K、5K 和 41K 圖像。在實驗中,默認使用完整的118K訓練集作為訓練數據。
-
ADE20K-150(ADE-150):它是一個大規模場景理解數據集,包含 20K 訓練圖像和 2K 驗證圖像,總共 150 個注釋類。
-
ADE20K-847(ADE-847):它具有與 ADE20K-150 相同的圖像,但有更多注釋的類(847 個類),這對于開放詞匯語義分割來說是一個具有挑戰性的數據集。
-
Pascal VOC(VOC) :Pascal VOC 包含 20 類語義分割注釋,其中訓練集和驗證集分別包含 1464 個和 1449 個圖像。
-
Pascal Context-59:它是一個用于語義理解的數據集,包含 5K 訓練圖像、5K 驗證圖像以及總共 59 個帶注釋的類。
-
Pascal Context-459:它具有與 Pascal Context-59 相同的圖像,但有更多注釋的類(459 個類),這也廣泛用于開放詞匯語義分割。
Dataset Analysis:為了澄清并有利于對開放詞匯能力的理解,作者通過計算其他數據集和訓練數據集 COCO Stuff 之間的類別相似度來進行簡單的分析,結果顯示在表1。
-
提取文本嵌入:使用預訓練的CLIP模型,將每個數據集的類別名稱轉換為文本嵌入向量。
-
計算余弦相似度:對于每一對數據集,計算其類別嵌入向量之間的余弦相似度。具體來說,對于兩個類別集合A和B中的每個類別對(a, b),計算它們的余弦相似度,然后利用這些相似度計算Hausdorff(豪斯多夫,對于點集 A 中的每個點 a,找到點集 B 中距離 a 最近的點,然后在這些最近距離中取最大值)距離,作為這兩個數據集之間的相似度度量。
-
生成相似度表:通過上述步驟,得到不同數據集之間的相似度,結果顯示在表1中。
在五個驗證數據集中,Pascal VOC和Pascal Context-59的相似度高達0.9,這意味著它們更擅長衡量視覺類別方面的域內開放詞匯能力。此外,Pascal Context-459、ADE20K-150和ADE20K-847的相似度得分較低,這使得它們能夠更好地評估跨領域開放詞匯能力。
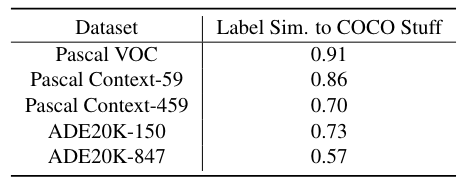
表 1:驗證數據集和訓練集(即 COCO Stuff)之間的標簽集相似度。基于CLIP文本編碼器通過Hausdorff距離和余弦相似度測量。
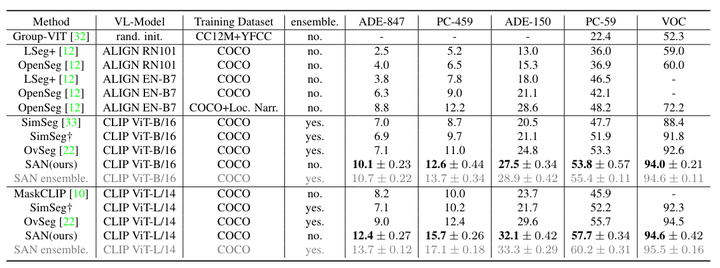
與最先進方法的性能比較。 ? SimSeg [33] 在其論文中使用 COCO Stuff 的子集進行訓練。為了公平比較,使用他們官方發布的代碼在完整的 COCO Stuff 上重現了他們的方法。 * RN101:ResNet-101 [14]; EN-B7:EfficientNet-B7 [29]; SAN 整體。ensemble是使用集成技巧的結果,而不是默認設置。
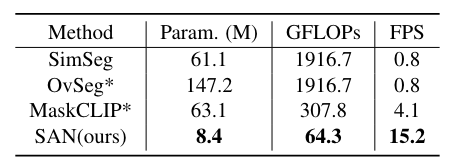
與其他方法的訓練和測試效率比較。
Param.代表方法中可訓練參數的總數(以百萬為單位)。輸入圖像的分辨率為640×640。CLIP型號為ViT-B/16。 * 目前還沒有可用的官方代碼,按照他們論文中的描述重新實現他們的方法。 OvSeg與 SimSeg具有相似的結構,但它對整個 CLIP 模型進行了微調,從而產生了更多的可訓練參數。
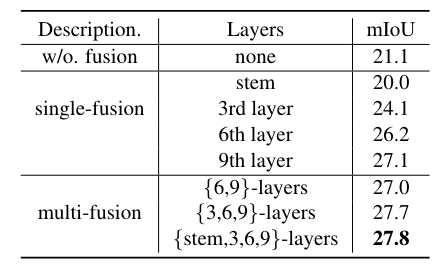
不同的特征融合策略。 ViT-B/16 的最后 3 層用于所有實驗中的掩模預測。

特征融合層數量和掩模預測層數量之間的權衡
SAN輕量級的關鍵是利用CLIP模型的強大功能。通過實驗說明了表中特征融合的重要性。 如果不融合 CLIP 功能,mIoU 將從 27.8 下降到 21.1。
此外,還注意到,融合較深層(例如第9層)的特征比融合較淺層(例如stem層)的特征要好,并且僅融合第9層的特征可以達到27.1 mIoU,比融合高+6.0 mIoU沒有特征融合的基線。這一觀察結果與更深層次的特征往往更具語義性的直覺是一致的。此外,與單層融合相比,融合多層特征可以進一步提高性能 +0.8 mIoU。
為了最小化 CLIP 的推理成本,采用單前向設計,即較淺的層用于特征融合,其他較深層用于mask識別,因此需要進行權衡,如上表所示。 當前9層用于特征融合,后3層用于掩模識別時,性能最佳。
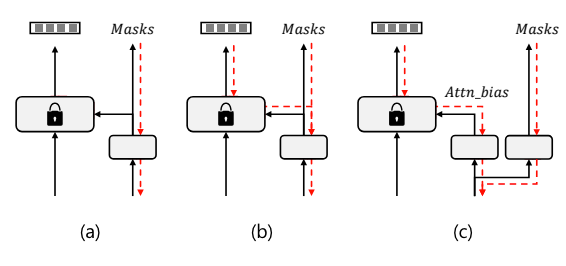
掩模預測頭的設計選擇。 (a) 單頭和來自 CLIP 的阻塞梯度的兩階段訓練; (b) 單頭端到端訓練; (c) 解耦頭端到端訓練。紅色虛線表示訓練期間的梯度流。
與其他兩階段框架不同,本文的方法是端到端的訓練框架。
作者研究了其他兩個框架之間的差異。由于注意力偏差分支必須通過 CLIP 進行訓練,為了進行比較,在 CLIP 的自注意力層中使用 mask proposal 代替注意力偏差。如果來自 CLIP 的梯度被阻止,則該方法退化為兩階段框架,即掩模預測與 CLIP 識別隔離。否則,該方法是單頭端到端訓練框架,并且掩模預測是 CLIP 感知的。
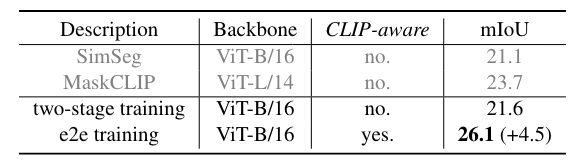
兩階段與端到端。這一顯著改進證明了 CLIP 感知掩模預測的重要性。
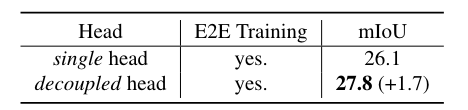
單頭和解耦頭的比較。只需很少的額外參數和觸發器,解耦頭就可以顯著提高性能。所有模型都經過端到端訓練。
單頭設計意味著模型只有一個注意力頭來處理掩碼預測和識別。解耦頭設計意味著模型在處理掩碼預測和識別時,使用了多個注意力頭,這些頭之間的計算是解耦的。
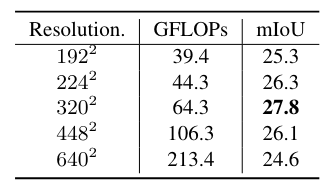
ViT-B/16 CLIP 模型輸入分辨率的影響。改變 CLIP 輸入分辨率,同時始終在側面適配器網絡中使用 640*640 圖像。
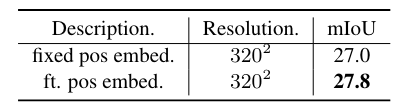
微調位置嵌入可以提高性能
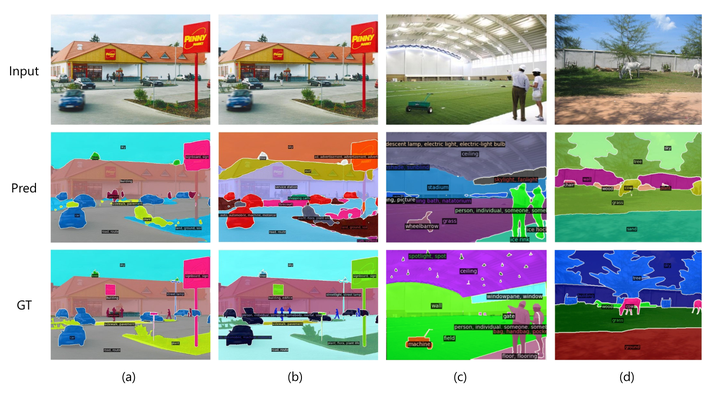
方法的定性結果。 (a) 和 (b) 是具有不同詞匯表(分別為 ADE-150 和 ADE-847)的相同輸入圖像的結果
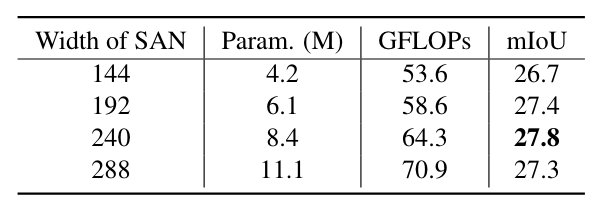
SAN容量的影響。代表模型中可訓練參數的總數(以百萬為單位)。
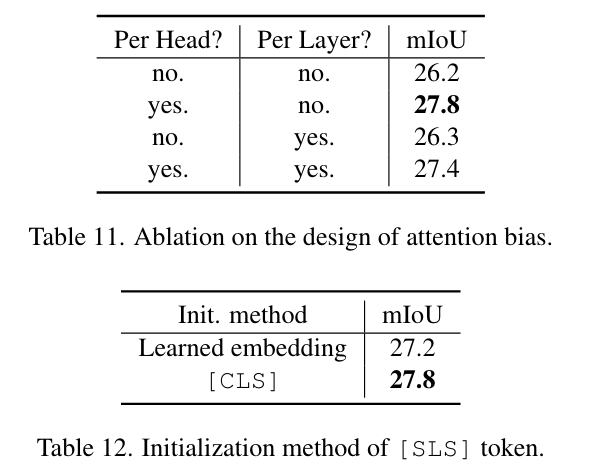
注意偏差設計的消融和[SLS]令牌的初始化方法
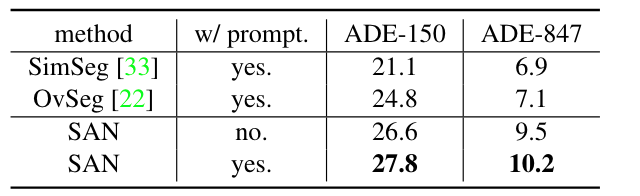
Prompt工程的效果。單個模板“{} 的照片”。用于不使用Prompt工程的模型。









266)
:xpath和lxml類庫)








