2.1 輸入輸出流
流可以被看作一組有序的字節集合,即數據在兩個設備間的傳輸。
字節流:以字節作為單位,讀到一個字節就返回一個字節;InputStream & OutputStream。
字符流:使用字節流讀到一個到多個字節先查詢碼表再返回;Reader & Writer。會使用緩存。
Java IO 類設計時采用了 Decorator 模式(裝飾者)
2.1 補充 - 裝飾者模式
裝飾者模式的組成部分:
-
Component(抽象組件):定義了一個接口,描述了可以動態添加的責任。
-
ConcreteComponent(具體組件):定義了Component接口的具體實現。
-
Decorator(抽象裝飾者):抽象類,實現了Component接口,并持有Component接口的一個實例。
-
ConcreteDecorator(具體裝飾者):具體裝飾者類,實現Decorator的抽象方法,并添加額外的功能。
裝飾者模式的實現步驟:
-
定義組件接口(Component),它有一個方法,比如?
operation()。 -
創建具體組件類(ConcreteComponent),實現Component接口。
-
創建裝飾者抽象類(Decorator),實現Component接口,并包含一個Component接口的引用。
-
實現具體裝飾者類(ConcreteDecorator),繼承Decorator類,并添加額外的功能。
-
通過組合,Decorator可以動態地給Component添加功能。
裝飾者模式的好處主要包括:
-
動態擴展性:可以在運行時動態地給一個對象添加額外的職責,而不需要修改原有的代碼結構。
-
靈活性:裝飾者模式提供了一種靈活的替代方案,用于繼承,可以基于需要向對象添加任意數量的職責。
-
低耦合性:裝飾者模式允許系統在對象間保持較低的耦合度,因為對象不需要知道它是由哪些裝飾者組成的。
-
可維護性:當需要添加新的功能時,可以簡單地創建新的裝飾者類,而不是修改現有的類,這符合開閉原則(對擴展開放,對修改封閉)。
-
責任分離:裝飾者模式有助于將類的不同職責分離開來,使得各個職責可以獨立地變化和擴展。
使用裝飾者模式而不是繼承的理由:
-
避免類的爆炸式增長:如果使用繼承來擴展功能,每個類的新組合都會產生一個新的子類,這可能導致類的數量急劇增加。
-
減少繼承的缺陷:繼承是一種靜態的、靜態綁定的關系,它限制了靈活性。裝飾者模式使用組合和動態綁定,提供了更大的靈活性。
-
繼承是強耦合的:繼承關系使得基類和子類之間存在強耦合,基類的任何變化都可能影響到子類。裝飾者模式通過組合來實現,耦合度較低。
-
繼承層次結構可能很復雜:隨著功能的增加,基于繼承的層次結構可能變得復雜且難以管理。裝飾者模式提供了一種更扁平化和靈活的結構。
-
多重繼承問題:Java不支持多重類繼承,但可以有多多個接口。如果需要實現多個不相關的功能擴展,繼承可能無法滿足需求,裝飾者模式可以解決這個問題。
總之,裝飾者模式提供了一種更加靈活和動態的方式來擴展對象的功能,同時避免了繼承可能帶來的問題和限制。
2.1 Java Socket \ TCP & UDP
Socket 由IP地址和端口號唯一確定。
面向鏈接的 Socket (TCP)
面向無連接的 Socket (UDP)
TCP(傳輸控制協議)
-
連接導向:TCP 需要在數據傳輸之前建立連接,通過三次握手過程。
-
可靠的:TCP 提供可靠的數據傳輸服務,確保數據包正確、按順序地到達目的地。
-
面向字節流:TCP 沒有消息邊界,它將數據視為字節流。
-
錯誤恢復:TCP 有錯誤檢測和重傳機制,如果數據包丟失或損壞,TCP 會重新發送它們。
-
擁塞控制:TCP 有擁塞控制機制,可以在網絡擁塞時減慢數據傳輸速度。
-
有序傳輸:TCP 保證數據包的順序傳輸,如果出現亂序,接收方會緩存數據直到可以按順序重組。
-
帶寬消耗:由于 TCP 的可靠性和控制機制,它可能會消耗更多的帶寬。
UDP(用戶數據報協議)
-
無連接:UDP 是無連接的,它在數據傳輸前不需要建立連接。
-
不可靠的:UDP 不保證數據包的到達、順序或完整性,它只是盡可能快地發送數據。
-
面向消息:UDP 面向消息,發送的數據被分割成數據報,每個數據報都是獨立的。
-
錯誤檢測有限:UDP 只提供了最基本的錯誤檢測,不負責重傳丟失的數據包。
-
無擁塞控制:UDP 沒有擁塞控制,即使網絡擁堵,它也會繼續以全速發送數據。
-
有序性不保證:UDP 不保證數據包的順序,如果數據包亂序到達,接收方需要自己處理。
-
帶寬消耗較少:UDP 由于其簡單性,通常消耗較少的帶寬。
TCP(傳輸控制協議)的三次握手是建立一個可靠的連接所必須的過程。這個過程確保了兩個端點(客戶端和服務器)都能夠接收和發送數據。以下是三次握手的步驟:
-
SYN(同步序列編號):
- 客戶端選擇一個初始序列號(ISN,Initial Sequence Number)并發送一個帶有 SYN 標志位設置為 1 的數據包給服務器,以請求建立連接。這表示客戶端準備好發送數據了。
-
SYN-ACK(同步-確認):
- 服務器接收到客戶端的 SYN 數據包后,會用自己的初始序列號響應一個 SYN-ACK 數據包。這個響應中 SYN 標志位和 ACK(確認)標志位都被設置為 1。服務器的序列號是它選擇的 ISN,而 ACK 值是客戶端的 ISN 加 1。
-
ACK(確認):
- 客戶端接收到服務器的 SYN-ACK 數據包后,會發送一個帶有 ACK 標志位設置為 1 的數據包給服務器,以完成連接建立。客戶端的 ACK 值是服務器的 ISN 加 1。此時,連接建立完成,客戶端和服務器都可以開始發送數據。
2.1 Java 序列化
- 序列化:實現序列化的類需要實現Serializable 接口(標記接口),調用方法為:使用一個輸出流構造一個 ObjectOutputStream 對象,使用其 writeObject 方法來寫出對象。被聲明為 static 和 transient 的數據成員不可以被序列化。
-
對于 static 數據成員:
- 由于
static字段是類級別的,通常不需要序列化。如果你需要保存類的狀態,可以考慮將static字段的值存儲在某個地方,然后在對象反序列化后恢復它們。 - 例如,你可以使用一個靜態方法來獲取和設置
static字段的值,然后在序列化和反序列化過程中手動調用這個方法。
- 由于
-
對于 transient 數據成員:
- 如果你需要在反序列化后恢復
transient字段的狀態,你可以在反序列化過程中顯式地重新賦值。 - 一種常見的做法是在類的構造函數或一個單獨的初始化方法中重新設置
transient字段的值。
- 如果你需要在反序列化后恢復
- 外部序列化:自定義讀寫接口
2.2 同步 \ 異步 \ 阻塞 \ 非阻塞
多線程語境下:
- 同步 & 異步:關注任務是否可以被多個線程同時調用,同步是僅可以被一個線程訪問。
- 阻塞 & 非阻塞:關注線程的狀態,阻塞代表線程掛起。
IO語境下:
- 同步 & 異步:關注消息發起和接受的機制,同步是發起一個IO操作后得到返回才進行后續操作,異步是指發起IO操作后不等待返回。通過輪詢、回調等方式等待結果。
- 阻塞 & 非阻塞:關注等待結果的狀態:阻塞指需要等待IO操作結束。
并發 & 并行:并發在同一時刻只有一條指令執行;并行同一時刻多條指令同時執行。
2.3 BIO \ NIO \ AIO
BIO :阻塞式IO;
NIO:基于Selector 的異步網絡 IO( Selector 輪詢所有被注冊的 channel ,一旦發現 Channel 上被注冊的事件發生就可以進行處理)
AIO:基于 Proactor 實現基于事件和回調機制的 I/O 操作方式,允許應用程序在執行 I/O 操作時不被阻塞,從而可以處理其他任務。
1. 每個 socket 鏈接在事件分離器注冊IO完成事件和回調處理;
2. 應用程序需要進行IO時,向分離器發出IO請求,分離器通知系統處理;
3. 系統嘗試IO操作,完成后通知分離器;
4. 分離器檢測到IO完成事件后,激活回調。
2.3 補充 Channel?
在 Java NIO(New Input/Output)庫中,"Channel" 是指可以用于執行 I/O 操作的通道。Java NIO 中的通道類似于傳統的"流",但有一些重要的區別:
- 通道可以非阻塞,允許單線程處理多個輸入/輸出通道。
- 通道總是基于緩沖區的,數據從通道讀取到緩沖區,或從緩沖區寫入到通道。
3.1 Collections
Java 中的容器可以分為兩類
Collection:存儲獨立的元素,包括
- List:按插入順序保存元素;eg:LinkedList & ArrayList & Vector;
- Set:不可有重復元素,通過equals 方法來保證唯一;eg:HashSet & TreeSet;
- Queue: 隊列
- Stack:堆棧
Map:存儲鍵值對;eg: HashMap、TreeMap、LinkedHashMap;
3.2?LinkedList & ArrayList & Vector
ArrayList: 數組實現。讀取快,擴容慢。
LinkedList:雙向鏈表;非線程安全。注意:Java標準庫并沒有直接提供一個現成的線程安全的雙向鏈表實現。
Vector:與 ArrayList 相比是線程安全的。
3.3 Map
HashMap: 鍵值與下標的關系由 hashcode 決定,即 hash 桶。僅當 hashcode 和 equals 相同才被認為是一個對象。
Java 8 之前的實現是數組加鏈表
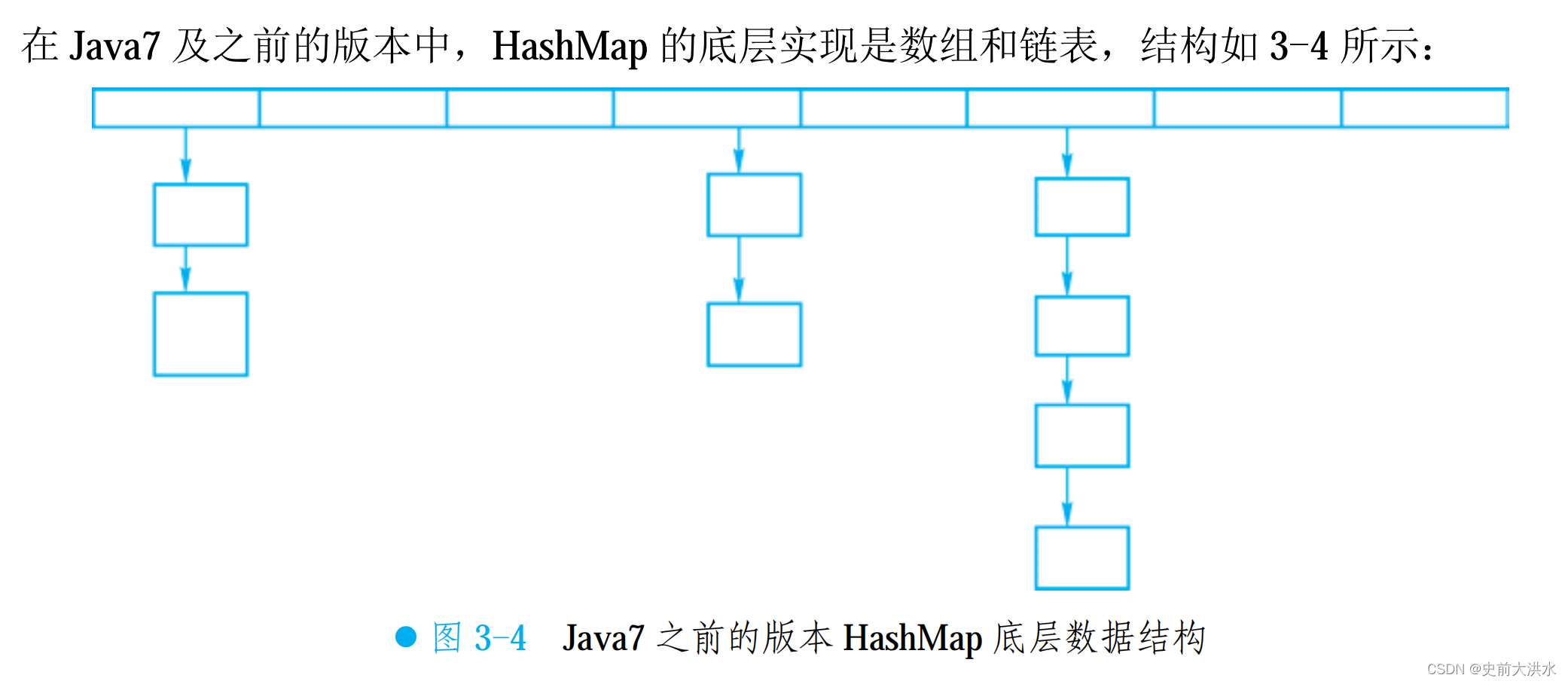
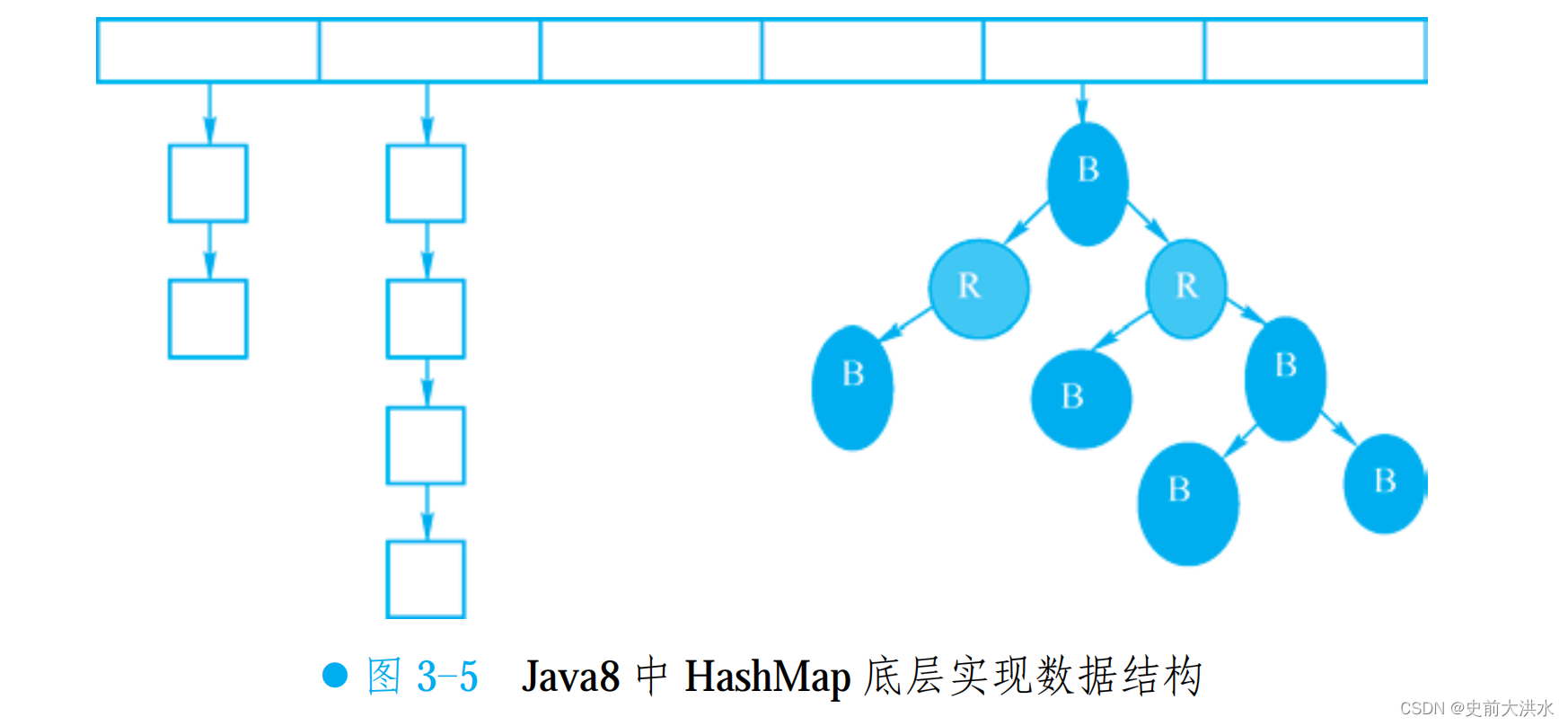
Java 8 之后:采用了數組+樹+鏈表的結構,當鏈表達到最大深度時,重構為紅黑樹。
TreeMap:完全由紅黑樹實現,元素有序。
LinkedHashMap:?
Java 8 之前:為每個數據節點的引用多維護了一份鏈表。
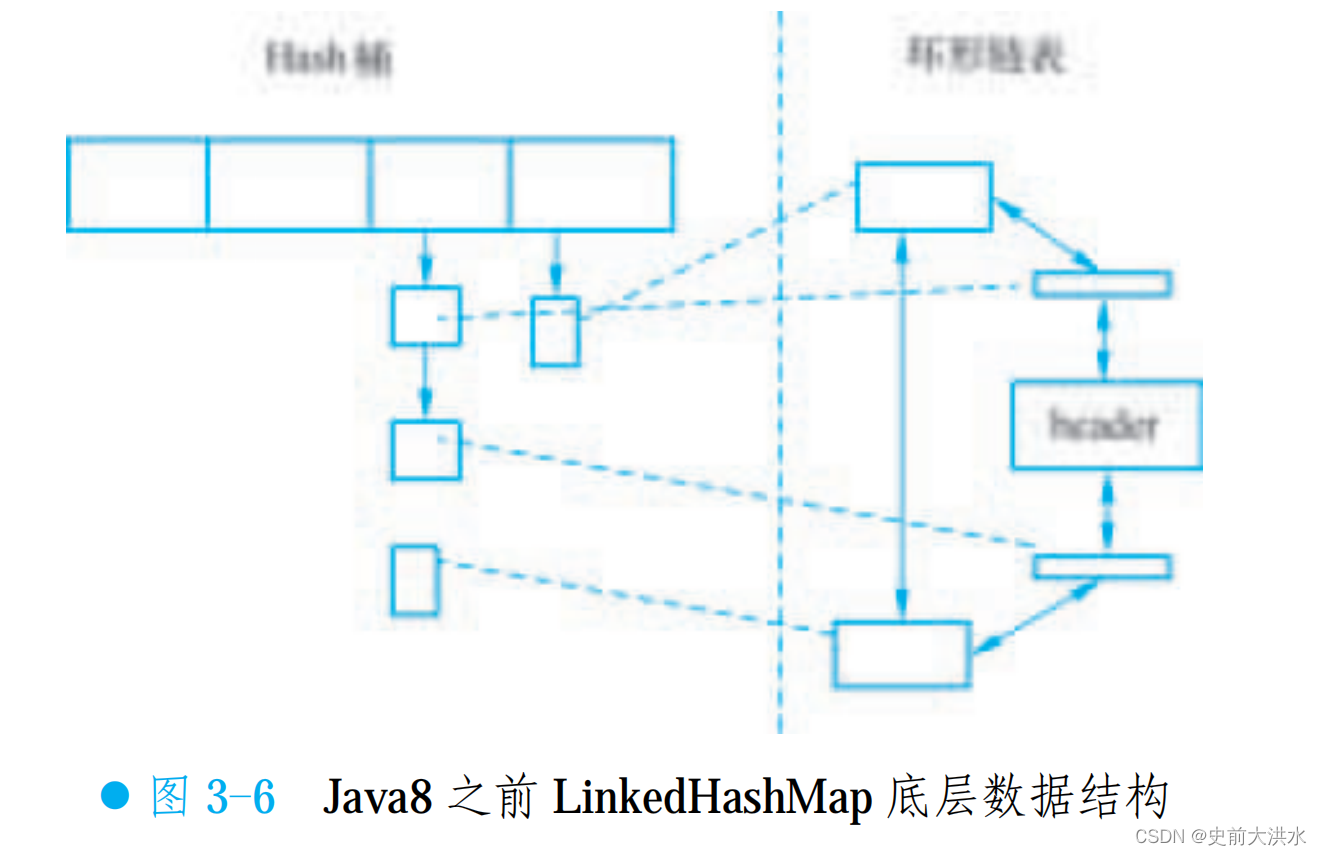
Java 8 中

HashTable : hashtable 為線程安全的,不可存儲 null 值;
WeakHashTable: key值如果沒有外部強引用,垃圾回收時,對應內容也會被移除掉。
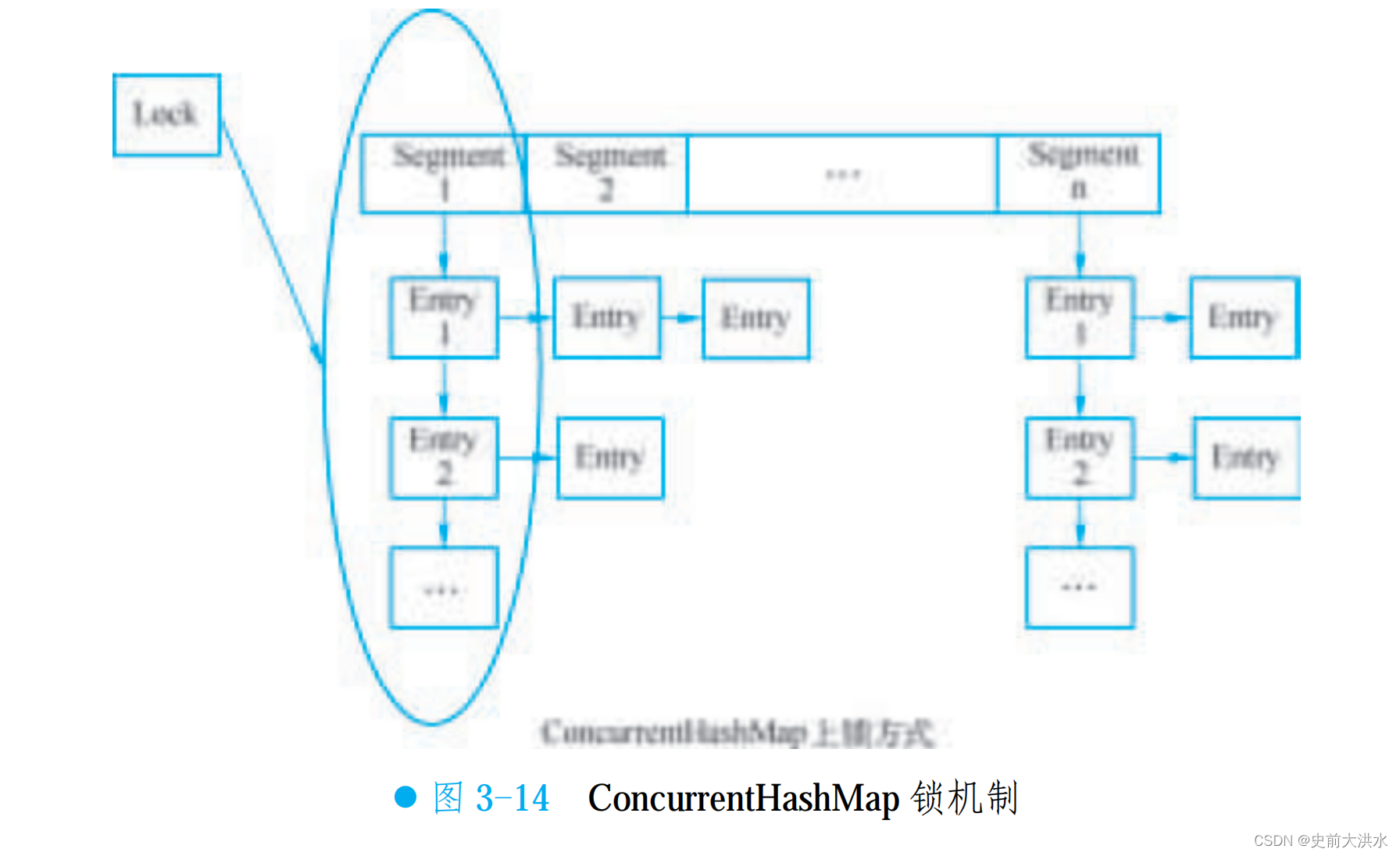
ConcurrentHashMap: HashMap 中支持高并發、高吞吐的線程安全版本。包含一個 Segment 數組,結構和 HashMap類似,每個Segment 守護著一個 HashEntry 里的元素,對 HashEntry 數組進行修改時需要先獲得 Segment 鎖。注意,在某些情況下還是存在線程不安全的可能,例如?map.pub 方法不是一個原子操作。所以在進行操作時最好在線程里對操作加鎖。
3.4 Set
HashSet:HashSet 內部通過 HashMap 實現,所有的值使用相同的 value。同樣,其不是線程安全的。
LinkedHashSet:可維護插入數據的順序。底層是 LinedHashMap。
TreeSet:底層使用 TreeMap 來存儲數據
3.5 BlockingQueue
生產者線程在倉庫裝滿之后會被阻塞,消費者線程則實在倉庫清空后阻塞。
ArrayBlockingQueue:基于數組實現的有界 BlockingQueue,陷入先出。線程安全。
LinkedBlockingQueue:使用了雙鎖隊列算法。線程安全。
PriorityBlockingQueue:隊頭元素是隊列的最小元素。使用的最小堆結構。
ConcurrentLinkedQueue: 非阻塞的線程安全隊列。采用的CAS 方式保證。
DelayQueue:阻塞的優先隊列,管理的對象必須要實現util.concurrent.delayed接口,其線程安全由重入鎖實現。
3.5 - 補充 CAS 算法
CAS(Compare-And-Swap,比較并交換)算法是一種用于并發控制的技術,主要用于多處理器系統中實現原子操作。CAS操作通常由三個參數組成:內存位置(V),預期值(A)和新值(B)。基本思想是,如果內存位置的當前值與預期值相匹配,那么將內存位置的值更新為新值。如果不相匹配,操作則不執行任何操作或回滾。
3.7?迭代器
使用 Iterator 遍歷容器時,如果對容器增加或者刪除操作操作就會改變容器數量,導致拋出異常。解決方法:使用線程安全的容器來做迭代器。eg: ConcurrentHashMap 等。
3.8 并行數組操作
例如 parallexXXX 方法,使用多線程進行操作。











)


中切換到當前項目所在的虛擬環境)




