引言
關于數據庫設計與優化的前幾篇文章中,我們提到了數據庫設計優化應該遵守的指導原則、數據庫底層的索引組織結構、數據庫的核心功能組件以及SQL的解析、編譯等。這些其實都是在為SQL的優化、執行的理解打基礎。
今天這篇文章,我們以MySQL中InnoDB存儲引擎中的數據索引組織及一條SQL的物理執行過程,來更直觀的理解數據庫中我們提交一條SQL后,數據庫默默幫我們做的事情。
準備工作
我們依然以前一篇文章中的t_customer表為例,建表語句如下:
create table t_customer(id int not null auto_increment comment '會員id',name varchar(32) comment '會員姓名',gender tinyint not null default 0 comment '會員性別:0未知,1男,2女',city varchar(32) comment '會員所在城市',primary key(`id`),key `idx_city` (`city`)
) comment '會員信息表';
然后我們編寫一個Python腳本,利用Faker框架,來生成測試數據:
import random
from faker import Faker
from faker.providers import BaseProvider
import pymysql
import db_config as db_cfgprint(db_cfg.host)conn = pymysql.connect(host=db_cfg.host, port=db_cfg.port, user=db_cfg.user, password=db_cfg.password,database=db_cfg.database)
cursor = conn.cursor()
sql = "insert into t_customer(name, gender, city) values('{}', {}, '{}')"class GenderProvider(BaseProvider):def gender(self):return random.sample([1, 2, 0], counts=[100, 100, 1], k=1)[0]# 指定語言環境為中文環境,創建Faker生成器
fk = Faker('zh_CN')
fk.add_provider(GenderProvider)
for i in range(10000):cursor.execute(sql.format(fk.name(), fk.gender(), fk.city()))
conn.commit()
cursor.close()
conn.close()測試數據大概如下:

其實這里我們只是從數據組織結構上展開SQL的執行,沒有測試數據也沒啥影響。不過,還是強烈建議感興趣的了解下Python,很好用,很好玩。這里不再展開,需要理解的可以看下筆者關于Python的相關系列文章。
B+樹的索引組織結構
簡單說下B+樹索引
B+樹索引,就是傳統意義上的索引,也是目前關系型數據庫系統中查找最為常用和最有效的索引。
需要注意的是,從使用的角度來看,B+樹索引的構造類似于二叉樹,根據鍵值(key value)能夠快速找到相應的數據。但是,有幾個細節需要提一下:
- B+樹中的B不是表示二叉(binary),而是代表平衡(balance),因為B+樹是從最早的平衡二叉樹演化而來的,但是B+樹不是一個二叉樹
- 樹結構的索引,只有是平衡樹,才能降低樹的高度,從而降低基于索引檢索的磁盤IO的次數
- B+樹索引,實際上并不能通過一個給定的鍵值查到具體的某一行數據,而是只能找到被查找符合鍵值的數據所在的頁,這些數據按照鍵值順序進行組織存儲。然后數據庫通過把頁讀入內存,然后在內存中執行進一步的查找操作,最終得到要查找的數據。后續我們簡化一下操作,假設每個頁都只存儲一條數據,以便更好地進行表述、理解
- 關于數據以頁為單位進行讀取,前面的文章中已經提到,可以更好地利用程序的局部性原理,從而提高檢索的效率
t_customer的索引結構
引言中已經提到,我們這里以MySQL的InnoDB存儲引擎為例進行介紹,其他數據庫中的底層原理也基本類似。
從前面的建表語句中,可以看出t_customer有兩個索引:
- 主鍵索引 id,是聚簇索引(Clustered Index)
- idx_city,是輔助索引(Secondary Index)
索引的示意圖大概如下:
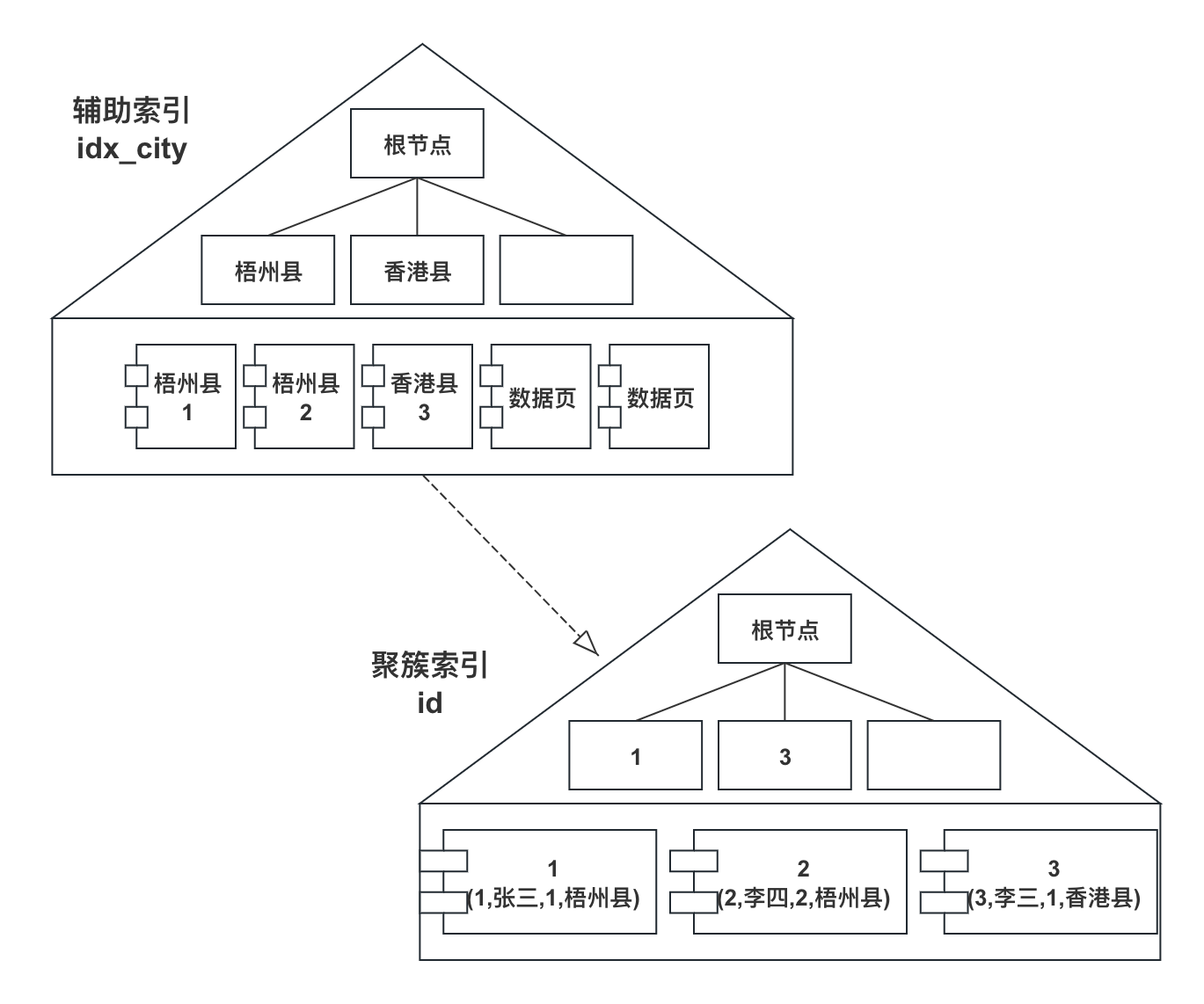
前面已經提到,我們簡化一下,一個頁只存儲一條數據。
輔助索引的葉子結點,存儲的都是該索引的鍵值及對應的主鍵的值;
聚簇索引的葉子節點,存儲的都是一行行完整的數據。
SQL執行過程
接下來,我們將要執行的是這樣一條SQL語句:
select id,name
from t_customer
where city = '合肥' and gender = 1
假設數據庫的優化器最終決定要走idx_city這個索引,進行SQL的執行,主要的執行過程大概如下:
- 從索引idx_city中找到第一個滿足city = '合肥'的主鍵id;
- 到主鍵id索引中取出整行,將id, name, gender取出,如果gender = 1 則將id, name的值放入內存緩沖區;
- 重復前兩個步驟,直到在idx_city索引中找到的city值不滿足查詢條件為止
- 將內存緩沖區的數據返回給用戶
上面的這條SQL,首先從idx_city索引中找到主鍵id,然后再到聚簇索引中找到整行記錄,然后還要判斷是否符合條件,再決定是否返回改行數據。這種查詢場景,叫做”回表“。
回表的操作,會增加磁盤IO的次數,如果輔助索引結構中已經包含了用戶需要的所有字段,則可以避免回表的操作,這時候的索引叫做”覆蓋索引“。
下面,我們對這條SQL稍微修改一下:
select id,name
from t_customer
where city = '合肥' and gender = 1
order byname
limit 100現在這條要執行的SQL中,添加了排序及limit操作,執行的過程會發生相應的調整,假設優化器還是選擇了要走idx_city這個索引:
- 從索引idx_city中找到第一個滿足city = '合肥'的主鍵id;
- 到主鍵id索引中取出整行,將id, name, gender取出,如果gender = 1 則將id, name的值放入排序緩沖區sor_buffer中;
- 重復前兩個步驟,直到在idx_city索引中找到的city值不滿足查詢條件為止
- 對sort_buffer中的數據按照字段name進行快速排序;
- 按照排序結果的數據取出前100條,返回給用戶
其實,涉及到排序的話,問題會突然變得復雜起來,這里簡單描述下,可能的情況:
1、符合條件的行數很多,sort_buffer中放不下,這時候就不能直接基于內存的排序算法進行了,就需要我們前面文章提到的TPMMS的算法了,進行基于磁盤的多路歸并排序;
2、加入最終返回的字段比較多,執行引擎在執行的過程中,可能決定不將所有字段都放入sort_buffer,可能只放主鍵id和參與排序的字段,然后排序完成之后,需要再按序進行一次回表的操作,獲取用戶需要的所有字段,然后再返回給用戶。基于是否將所有字段放入sort_buffer中,排序的操作符可以簡單分為全字段排序和rowid排序。
實際上SQL的執行要考慮的真實場景比較復雜,本文為了便于描述與理解,做了相應的簡化,感興趣的可以自行研究。




——XML文件操作sql)















![ESP8266[ 關于-巴發云MQTT/TCP:arduino 設置回調函數 ] 日志2024/6/29](http://pic.xiahunao.cn/ESP8266[ 關于-巴發云MQTT/TCP:arduino 設置回調函數 ] 日志2024/6/29)