學AI還能贏獎品?每天30分鐘,25天打通AI任督二脈 (qq.com)

MindNLP ChatGLM-6B StreamChat
本案例基于MindNLP和ChatGLM-6B實現一個聊天應用。
1 環境配置
%%capture captured_output
# 實驗環境已經預裝了mindspore==2.2.14,如需更換mindspore版本,可更改下面mindspore的版本號
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
!pip install mindnlp!pip install mdtex2html配置網絡線路
!export HF_ENDPOINT=https://hf-mirror.com2 代碼開發
下載權重大約需要10分鐘
from mindnlp.transformers import AutoModelForSeq2SeqLM, AutoTokenizer
import gradio as gr
import mdtex2htmlmodel = AutoModelForSeq2SeqLM.from_pretrained('ZhipuAI/ChatGLM-6B', mirror="modelscope").half()
model.set_train(False)
tokenizer = AutoTokenizer.from_pretrained('ZhipuAI/ChatGLM-6B', mirror="modelscope")
???model.chat?是 ChatGLM-6B 模型自帶的方法,用于生成對話。這個方法接受輸入的 prompt(即用戶輸入的初始文本)及其相關參數,并返回生成的響應。
???tokenizer?是一個文本標記器(tokenizer),用于將文本字符串轉換成模型可以處理的格式,并且將模型的輸出轉換回可讀文本。具體來說,tokenizer 會將輸入的 prompt 轉換成 token ids,并在生成響應后將生成的 token ids 轉換回文本。token ids 是一組數字,代表原始文本中的每個單詞或符號。比如,'你好' 可能會被轉換為?[12345, 67890]?這樣的 token 序列。?一旦模型生成了響應的 token 序列,`tokenizer` 會將這些 token ids 轉換回人類可讀的文本。這就是最終的響應。
可以修改下列參數和prompt體驗模型
prompt = '你好'
history = []
response, _ = model.chat(tokenizer, prompt, history=history, max_length=20)
response???prompt?是用戶提供的輸入文本,它是此次對話的起點。例如,在這段代碼中,prompt 是 '你好'。
???history?是一個列表,存儲了之前所有的對話記錄。有了這個歷史記錄,模型可以生成與上下文相關的響應。這在進行連續對話時特別有用。
???max_length?參數表示生成的響應的最大長度。這里的?20?指定響應最多包含 20 個 token。
response?會被賦值為模型生成的文本。這就是模型對當前 prompt 和 history 的回答。?_?表示另一個未使用的返回值,通常是生成過程中使用的一些調試信息或其他數據。

其他測試
def chat_with_bot(prompt, history=[]):response, history = model.chat(tokenizer, prompt, history=history, max_length=50)return response, history
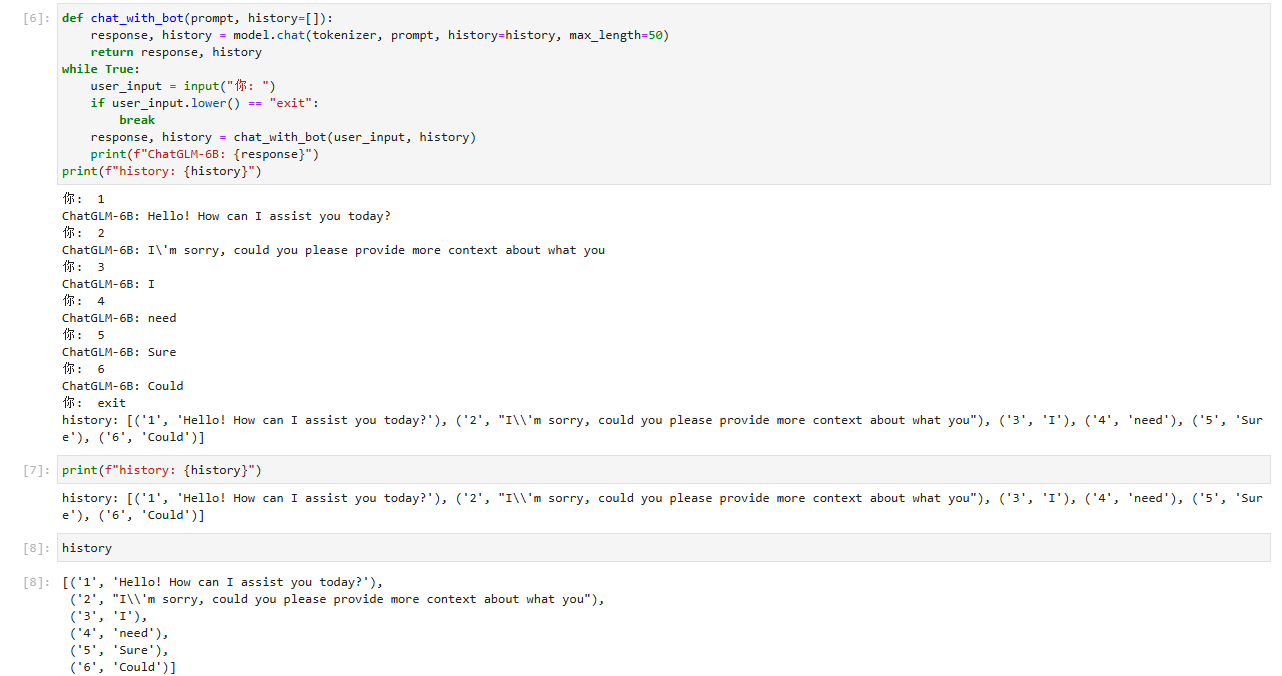
while True:user_input = input("你: ")if user_input.lower() == "exit":breakresponse, history = chat_with_bot(user_input, history)print(f"ChatGLM-6B: {response}")
print(f"history: {history}") 你: 1
ChatGLM-6B: Hello! How can I assist you today?
你: 2
ChatGLM-6B: I\'m sorry, could you please provide more context about what you
你: 3
ChatGLM-6B: I
你: 4
ChatGLM-6B: need
你: 5
ChatGLM-6B: Sure
你: 6
ChatGLM-6B: Could
你: exit
history: [('1', 'Hello! How can I assist you today?'), ('2', "I\\'m sorry, could you please provide more context about what you"), ('3', 'I'), ('4', 'need'), ('5', 'Sure'), ('6', 'Could')]

MAX_HISTORY_LENGTH = 5def prune_history(history, max_length):if len(history) > max_length:return history[-max_length:]return historydef chat_with_bot(prompt, history=[]):response, history = model.chat(tokenizer, prompt, history=history, max_length=50)history = prune_history(history, MAX_HISTORY_LENGTH)return response, history
while True:user_input = input("你: ")if user_input.lower() == "exit":breakresponse, history = chat_with_bot(user_input, history)print(f"ChatGLM-6B: {response}")
print(f"history: {history}")
你: 1
ChatGLM-6B: Hello! How can I assist you today?
你: 2
ChatGLM-6B: I'm sorry, could you please provide more context about what I
你: 3
ChatGLM-6B: need
你: 4
ChatGLM-6B: Thank
你: 5
ChatGLM-6B: You
你: 6
ChatGLM-6B: For
你: 今天天氣怎么樣?
ChatGLM-6B: I
你: 謝謝
ChatGLM-6B:
你: exit
history: [('4', 'Thank'), ('5', 'You'), ('6', 'For'), ('今天天氣怎么樣?', 'I'), ('謝謝', '')]

from mindnlp.transformers import AutoModelForSeq2SeqLM, AutoTokenizer
import mindspore
import gradio as gr
import mdtex2html# 加載模型和分詞器
model = AutoModelForSeq2SeqLM.from_pretrained('ZhipuAI/ChatGLM-6B', mirror="modelscope").half()
model.set_train(False)
tokenizer = AutoTokenizer.from_pretrained('ZhipuAI/ChatGLM-6B', mirror="modelscope")# 定義提示和歷史
prompt = '你好'
history = []# 分詞并處理 attention mask
inputs = tokenizer(prompt, return_tensors="ms", padding=True)
attention_mask = inputs["attention_mask"].astype(mindspore.bool_)try:# 與模型進行對話response, _ = model.chat(tokenizer, prompt, history=history, max_length=20, attention_mask=attention_mask)print(response)print(history)
except Exception as e:print(f"Error: {e}")Loading?checkpoint?shards:?100%?8/8?[00:49<00:00,??5.33s/it]
你好👋!我是人工智能助手 ChatGLM-6B []

![[知識點篇]《計算機組成原理》之數據信息的表示](http://pic.xiahunao.cn/[知識點篇]《計算機組成原理》之數據信息的表示)




——開發:數據轉換——技術方法、主要工具)





)
)






)