接上篇《58、Pandas庫中Series對象的操作(一)》
上一篇我們講解了Pandas庫中Series對象的基本概念、對象創建和操作,本篇我們來繼續學習Series對象的運算、函數應用、時間序列操作,以及Series的案例實踐。
一、Series對象的運算
1. 數值型數據的算術運算
Pandas的Series對象支持基本的算術運算,包括加法、減法、乘法和除法。這些運算可以在Series對象之間進行,也可以與標量(即單一數值)進行。在進行算術運算時,Pandas會嘗試進行元素級別的對齊(element-wise alignment),如果Series對象的索引不同,Pandas會嘗試基于索引進行匹配,或者在某些情況下使用NaN(Not a Number)來填充缺失的位置。
加法:通過+運算符或add()方法實現。
減法:通過-運算符或sub()方法實現。
乘法:通過*運算符或mul()方法實現。
除法:通過/運算符或div()方法實現。
代碼示例:
import pandas as pd# 創建Series對象
s1 = pd.Series([1, 2, 3, 4])
s2 = pd.Series([10, 20, 30, 40])# 加法
s_add = s1 + s2
print("加法:", s_add)# 減法
s_sub = s1 - s2
print("減法:", s_sub)# 乘法
s_mul = s1 * s2
print("乘法:", s_mul)# 除法
s_div = s1 / s2
print("除法:", s_div)2. 布爾索引與數據篩選
Pandas的Series對象支持基于布爾索引(Boolean Indexing)的數據篩選。布爾索引允許你根據條件表達式的結果來選取Series中的元素。當條件表達式作用于Series對象時,會返回一個與原始Series具有相同索引的布爾型Series,其中True表示滿足條件的元素,False表示不滿足條件的元素。然后,你可以使用這個布爾型Series來索引原始Series,從而選取滿足條件的元素。
條件表達式:使用比較運算符(如==、<、>等)創建條件表達式。
布爾索引:將條件表達式的結果用作索引,選取滿足條件的元素。
代碼示例:
import pandas as pd# 創建Series對象
s = pd.Series(['apple','banana','cherry','date'])# 布爾索引選以'a'開頭的元素
filtered_s = s[s.str.startswith('a')]
print("篩選結果:", filtered_s)3. 排序操作
Pandas的Series對象提供了兩種排序方法:sort_values()和sort_index()。
sort_values():根據Series中的值進行排序。默認情況下,數據按升序排序,但也可以指定ascending=False進行降序排序。
sort_index():根據Series的索引進行排序。同樣地,也可以指定ascending參數來控制排序順序。
這兩種方法都會返回一個新的已排序的Series對象,原始Series對象保持不變。
代碼示例:
import pandas as pd# 創建帶有索引的Series對象
s = pd.Series([3, 1, 4, 1, 5], index=['d', 'b', 'a', 'c', 'e'])# 根據值排序
s_sorted_values = s.sort_values()
print("按值排序:", s_sorted_values)# 根據索引排序
s_sorted_index = s.sort_index()
print("按索引排序:", s_sorted_index)4. 統計信息
Pandas的Series對象提供了許多統計方法,用于計算數據的描述性統計量。這些統計方法包括:
mean():計算Series中元素的均值(平均值)。
std():計算Series中元素的標準差。
max():返回Series中的最大值。
min():返回Series中的最小值。
此外,還有其他一些常用的統計方法,如median()(中位數)、mode()(眾數)、quantile()(分位數)等。這些方法可以幫助你快速了解數據的分布情況和特征。
代碼示例:
import pandas as pd ?# 創建Series對象 ?
s = pd.Series([1, 2, 3, 4, 5, 6, 7, 8, 9]) ?# 計算統計信息 ?
mean_value = s.mean() ?
std_value = s.std() ?
max_value = s.max() ?
min_value = s.min() ?print("均值:", mean_value) ?
print("標準差:", std_value) ?
print("最大值:", max_value) ?
print("最小值:", min_value)二、Series對象的函數應用
1. 使用apply()方法應用自定義函數
apply()方法是Pandas中Series對象的一個強大工具,它允許用戶應用自定義函數到Series中的每個元素。通過apply()方法,用戶可以輕松地執行復雜的元素級操作,這些操作可能無法通過內置的Pandas函數直接實現。
示例:定義一個函數,該函數將Series中的每個元素平方,并使用apply()方法將其應用到Series對象上。
import pandas as pd ?# 自定義函數,計算平方 ?
def square(x): ?return x ** 2 ?# 創建Series對象 ?
s = pd.Series([1, 2, 3, 4, 5]) ?# 使用apply()方法應用自定義函數 ?
s_squared = s.apply(square) ?
print(s_squared)2. 使用map()方法應用字典映射
map()方法允許用戶將一個字典中的鍵-值對映射到Series中的元素。當Series中的元素是字典的鍵時,這些元素將被替換為對應的值。這對于數據轉換和分類特別有用。
示例:創建一個字典,將一組數字映射到它們的字符串表示形式,并使用map()方法將其應用到Series對象上。
import pandas as pd ?# 創建字典映射 ?
mapping = {1: 'one', 2: 'two', 3: 'three', 4: 'four', 5: 'five'} ?# 創建Series對象 ?
s = pd.Series([1, 2, 3, 4, 5]) ?# 使用map()方法應用字典映射 ?
s_mapped = s.map(mapping) ?
print(s_mapped)3. 使用str屬性進行字符串操作
對于包含字符串的Series對象,Pandas提供了str屬性,該屬性包含了一系列用于字符串操作的方法。這些方法與Python內置的字符串方法類似,但可以在整個Series對象上高效地應用。
示例:使用str.upper()方法將Series中的字符串轉換為大寫,并使用str.contains()方法檢查字符串是否包含特定的子字符串。
import pandas as pd ?# 創建包含字符串的Series對象 ?
s = pd.Series(['apple', 'banana', 'cherry', 'Date', 'apple pie']) ?# 使用str.upper()方法轉換為大寫 ?
s_upper = s.str.upper() ?
print(s_upper) ?# 使用str.contains()方法檢查是否包含'apple' ?
contains_apple = s.str.contains('apple') ?
print(contains_apple)4.pct_change()函數
pct_change()函數是Pandas庫中Series和DataFrame對象的一個方法,用于計算當前元素與前一元素之間的百分比變化。它對于時間序列數據特別有用,因為它可以幫助你快速了解數據是如何隨時間變化的。
具體來說,pct_change()方法計算的是當前元素與前一個元素之間的差異,然后將其除以前一個元素(得到的結果是一個比率),再乘以100(將結果轉換為百分比)。第一個元素的百分比變化通常是NaN(不是數字),因為沒有前一個元素可以與之比較。下面是一個簡單的例子來說明pct_change()是如何工作的:
import pandas as pd ?# 創建一個簡單的 Series ?
s = pd.Series([100, 105, 102, 110, 108]) ?# 計算百分比變化 ?
change = s.pct_change() ?print(change)輸出是這樣的:
0 ? ? ? ? NaN ?
1 ? ?0.050000 ?
2 ? -0.028571 ?
3 ? ?0.078431 ?
4 ? -0.018182 ?
dtype: float64解釋:
第一個元素的百分比變化是 NaN,因為沒有前一個元素可以與之比較。
第二個元素的百分比變化是 (105 - 100) / 100 * 100 = 5%。
第三個元素的百分比變化是 (102 - 105) / 105 * 100 = -2.8571%。
以此類推...
默認情況下,pct_change() 會計算與前一個元素的百分比變化,但你也可以通過傳遞一個整數參數來計算與前面多個元素的百分比變化。例如,s.pct_change(2)會計算當前元素與兩個前面的元素的百分比變化。
三、Series對象的時間序列操作
1. 轉換為日期時間格式
Pandas 提供了一個非常方便的函數 to_datetime(),可以將 Series 對象中的字符串或其他格式的數據轉換為日期時間格式。這在進行時間序列分析時非常重要。
示例:將一個包含日期字符串的 Series 轉換為日期時間格式。
import pandas as pd ?# 創建一個包含日期字符串的 Series ?
dates_str = pd.Series(['2023-01-01', '2023-01-02', '2023-01-03']) ?# 使用 to_datetime() 轉換為日期時間格式 ?
dates_dt = pd.to_datetime(dates_str) ?
print(dates_dt)2. 時間序列的日期組件提取
對于日期時間格式的 Series,Pandas 提供了 .dt 訪問器,它允許你提取日期時間對象的各個組件,如年、月、日、小時等。
示例:從日期時間格式的 Series 中提取年份和月份。
# 假設 dates_dt 已經是日期時間格式的 Series ?# 提取年份 ?
years = dates_dt.dt.year ?
print(years) ?# 提取月份 ?
months = dates_dt.dt.month ?
print(months)3. 時間序列的位移
shift() 方法允許你沿著索引軸(通常是時間軸)移動數據。這對于時間序列分析中的滯后或領先分析非常有用。示例:將時間序列數據向前移動一個單位(例如,一天)。
# 假設 dates_dt 及其對應的值 series 是我們的時間序列數據
values = pd.Series([56, 44, 79], index=dates_dt)# 值向前移動一個單位(日期)
shifted_values = values.shift(1)
print(shifted_values)# 計算數據的變動情況(當前數據 - 前一天數據)
value_changes = values - shifted_values# 打印數據變動情況
print("數據變動情況:")
print(value_changes)注意:位移后的第一個值將會是 NaN,因為沒有前一天的數據可供參考。
4. 時間序列的重采樣
resample() 方法允許你根據指定的頻率重新采樣時間序列數據。這對于將高頻數據轉換為低頻數據(如每日數據轉換為每月數據)或將低頻數據轉換為高頻數據(通過插值或填充)非常有用。示例:將每日數據重采樣為每月數據,并計算每月的平均值。
# 假設 values 是每日數據的時間序列# 重采樣為每月數據,并計算平均值
monthly_mean = values.resample('ME').mean()
# 這里應該是前面56, 44, 79這一月份書所有數據的平均值
# (56+44+79)/3 = 59.666667
print(monthly_mean)在這個例子中,'M' 表示月份,'MS' 通常用來表示月份的開始,'MD' 通常用來表示月份的結束。Pandas 支持多種頻率代碼,如 'D'(天)、'H'(小時)等。重采樣后,你會得到一個具有新頻率的時間序列數據。
四、Series案例實踐:股票數據分析
在本案例實踐中,我們將展示如何使用Pandas的Series對象對股票數據進行分析和處理。我們將分析一個假設的股票數據集,該數據集包含了某只股票在一段時間內的每日收盤價。
1. 數據準備
假設我們已經有了一個簡單的字典,它包含了某只股票幾天的收盤價。
import pandas as pd ?# 假設的收盤價數據 ?
stock_data = { ?'2023-01-01': 100, ?'2023-01-02': 102, ?'2023-01-03': 101, ?'2023-01-04': 103, ?'2023-01-05': 105 ?
} ?# 將字典轉換為Pandas Series對象,并設置日期為索引 ?
stock_prices = pd.Series(stock_data) ?
stock_prices.index = pd.to_datetime(stock_prices.index)2. 數據可視化
使用Matplotlib庫來繪制收盤價的時間序列圖。
import matplotlib.pyplot as plt ?# 繪制收盤價的時間序列圖 ?
# 調用matplotlib.pyplot模塊的figure函數創建一個新的圖形窗口,并設置其大小 ?
plt.figure(figsize=(10, 5)) ?# 調用Series對象的plot方法繪制時間序列圖 ?
# 這里的title參數設置了圖形的標題 ?
stock_prices.plot(title='Stock Price Over Time', grid=True) ?# 設置x軸的標簽,即日期 ?
plt.xlabel('Date') ?# 設置y軸的標簽,即收盤價 ?
plt.ylabel('Close Price') ?# 調用plt.show()函數顯示圖形 ?
plt.show()這段代碼的主要目的是使用matplotlib庫來繪制一個表示股票收盤價的時間序列圖。通過plt.figure()創建一個新的圖形窗口,并設置其大小。然后,通過stock_prices.plot()調用Series對象的plot方法,繪制出時間序列圖,并設置圖形的標題為“Stock Price Over Time”。接著,使用plt.xlabel()和plt.ylabel()分別設置x軸和y軸的標簽。最后,調用plt.show()來顯示圖形。
3. 數據分析
計算每日的收益率(即相對于前一日的百分比變化)。
# 計算每日收益率 ?
returns = stock_prices.pct_change() ?# 顯示前幾日的收益率 ?
print("Daily Returns:") ?
print(returns.head())效果: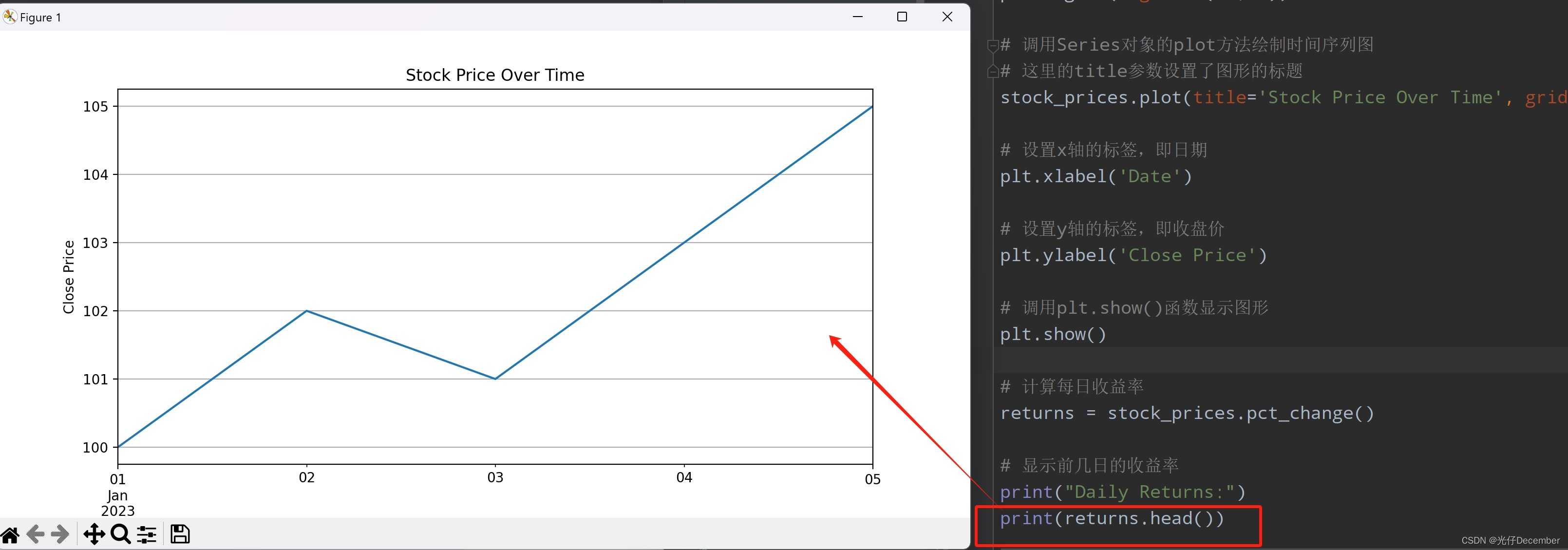
4. 結論
通過上面的代碼,我們展示了如何使用Pandas Series對象來表示和分析簡單的股票數據。我們首先創建了一個包含收盤價的Series對象,并使用Matplotlib繪制了時間序列圖。接著,我們計算了每日的收益率,并打印了前幾日的收益率。這個案例簡潔明了,展示了Series對象在數據分析中的基本用法。
至此,我們完成了Series對象的所有講解。下一篇我們來講解Pandas庫中DataFrame對象的操作。
轉載請注明出處:https://guangzai.blog.csdn.net/article/details/140084333






)

)
)



考試題庫,高效備考!!!)



)

