目錄
1? 目標定位
2? 地標檢測
3? 目標檢測
4? 在卷積網絡上實現滑動窗口
5? 邊界框預測
6? 交并比
7? 非極大值抑制
8? 錨框
9? YOLO算法
10 用u-net進行語義分割
11? 轉置卷積
12? ?u-net 結構靈感
1? 目標定位
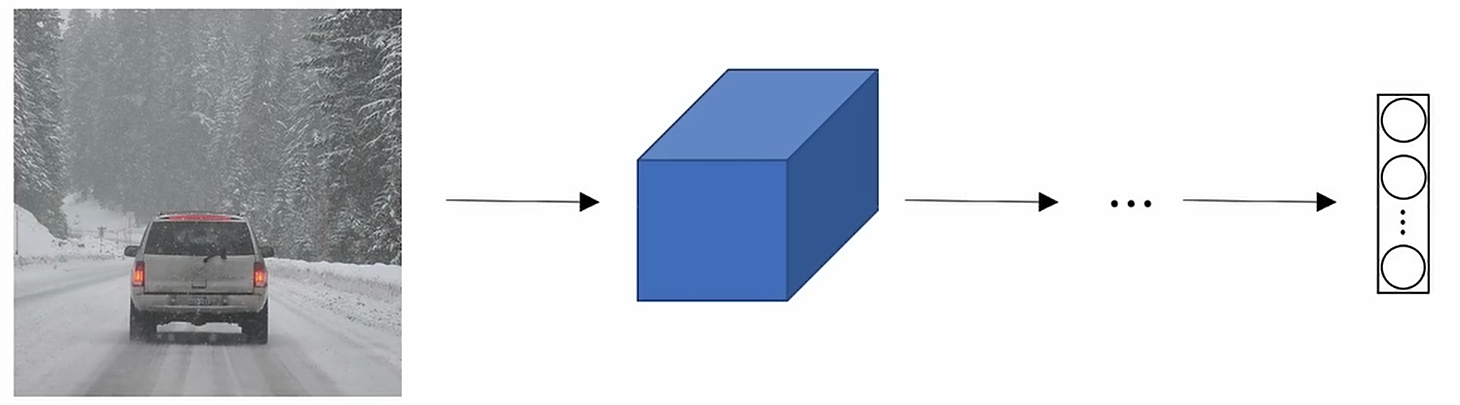
????????你已經對圖片分類有所了解。例如通過這張圖片可以識別出這是車。接下來我們要對一張圖片進行分類并定位,這意味著你不僅要識別出這是一輛車,還要知道這輛車在圖片中的位置。我們還會學習目標檢測,來檢測在一張圖片里的多個對象,把它們全部檢測出來,并且定位。

????????對于圖像分類和分類并定位問題。通常它們只有一個對象。在目標檢測問題中可能會有很多對象,他們可能是來自多個不同類別的多個對象。在圖像分類中學習的方法將會對分類定定位問題有幫助;學習道德定位的方法,對物體檢測有幫助。讓我們先來了解一下圖像分類并定位。
????????你可能在多層卷積網絡中輸入一張圖片,這會導致我們的卷積網絡有一個特征向量,然后將特征向量傳給softmax輸出預測的結果。如果你要制作一輛自動駕駛的車輛,那么你的目標類別可能會有行人、車輛、摩托車、一個背景環境。
????????如果你想定位圖中的汽車,你可以改變你的神經網絡,通過得到更多的輸出單元,使得這個神經網絡可以輸出一個邊框。具體的說你的神經網絡要輸出額外4個數字(),這4個數字是定位對象的邊框參數。
????????圖片左上角標為坐標(0,0),右下角標為(1,1)。所以為了指定圖中紅色長方形邊框,我們需要指定邊框的中心,需要,邊框的寬度
,邊框的長度
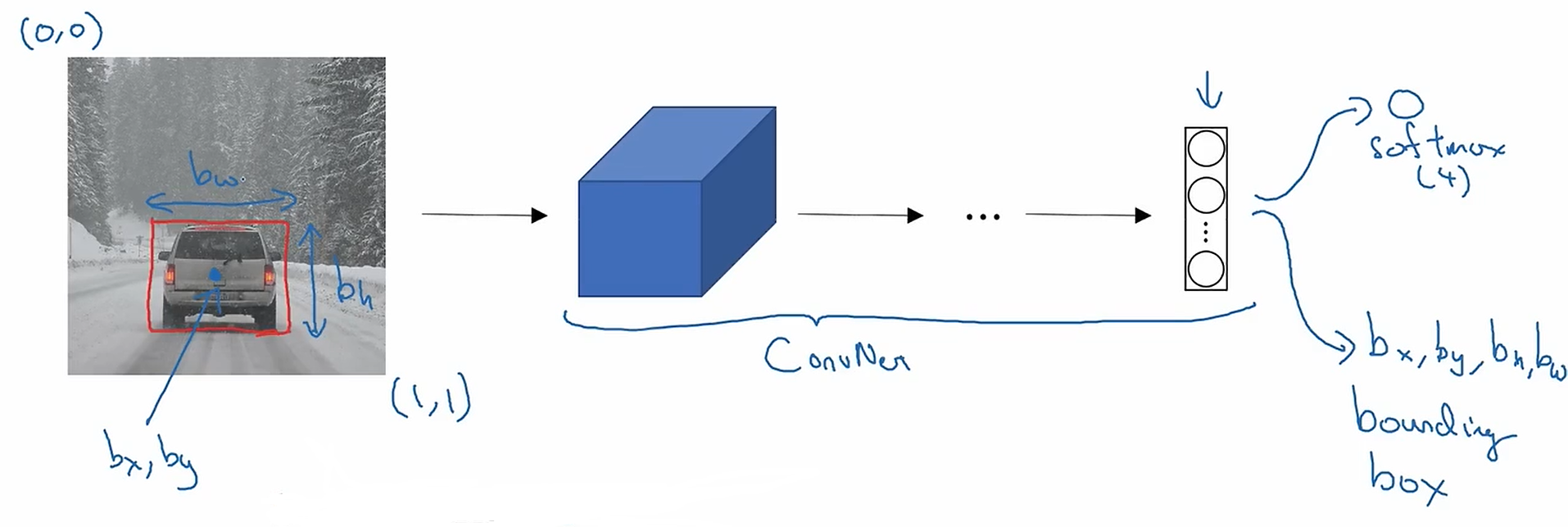
????????如果你的訓練集不僅僅是包含對象類別標簽,還包含4個額外的數字給出邊框。你可以用監督學習來讓你的算法輸出類別標簽和4個變量來告訴你所檢測到的對象的邊界框。
????????在上面這個例子中理想的,位于圖片的一半位置;
,大約距離圖片上方70%;
,因為這個紅色矩形的寬度,大約占到整個圖片的30%;
,紅色方框的寬度大約占整體圖片的40%。
? ? ? ? 目標標簽y的定義如下:如果是行人、車輛、摩托車,;如果是背景,也就是沒有任何你需要檢測的類別,
,你可以把
當做包含一個類別的概率。
是你所檢測對象的邊界框。如果
,你想知道是哪一個類別的對象。因此,
。這些定義的前提都是我們要處理圖像分類并定位問題,也就是圖片中最多只有一個對象,在
中,最多只有一個是1。
????????讓我們來看一個例子。
如果一個訓練集圖像 ,那么
,那么;如果x=
 ,那么
,那么,其中?表示對應的數字無關緊要,因為圖中沒有對象,那么你不需要關心神經網絡輸出的邊界框是什么,也不會關心
會是什么。
? ? ? ? 現在我們來看看怎么定義損失函數。如果你使用均方差作為損失函數,那么損失函數
2? 地標檢測
????????我們知道了神經網絡輸出4個變量邊界框去定位對象。對于更普遍的情況我們可以讓神經網絡只輸出重要的點和圖像的(x,y)坐標。
????????假設你要建立一個臉部識別算法。出于某些原因,你想要算法告訴你某人的眼角在哪里,那個點有(x,y)坐標。你可以建立一個神經網絡,它的輸出層只輸出兩個數字()來告訴你這個人眼角的坐標。
????????現在如果你想要神經網絡告訴你眼角的所有4個角,即兩只眼睛的左右兩個眼角。那么我們可以修改神經網絡讓它輸出(),(
),(
),(
)

????????現在神經網絡就輸出了人臉上的眼角這4個點的預估坐標位置。如果你想要的不僅僅是這4個點,你想要輸出眼周的點,你可以放置一些點。你也可以在嘴巴上放著一些點,這樣你就可以提取出嘴型,從而知道一個人在笑還是沒在笑。你也可以在鼻子上放置一些點。
????????為了討論方便,假設人臉上有64個地標,并把這些地標作為訓練集,你可以讓神經網絡告訴你:臉部重要的位置或者重要的地標在哪。

? ? ? ? 你可以把例如上圖這樣的圖當做輸入,讓它通過神經網絡,輸出1或者是0(1表示有人臉;0表示沒有人臉);同時輸出(),(
),...........,(
)

????????這個可以告訴你圖片中是否有人臉,并且所有關鍵特征是否在臉上。
????????為了訓練這樣一個神經網絡,你需要一個有標簽的訓練集(X,Y)。
????????最后一個例子。如果你對人體姿勢檢測感興趣的話。你也可以定義一些關鍵的位置,建立一個神經網絡去標識人的姿勢的關鍵位置,并輸出。

????????為了實現這個,你也需要指出這些關鍵特征。
3? 目標檢測
????????現在我們已經知道了目標定位和地標檢測。 現在讓我們來開始搭建一個目標檢測算法。在這一節中,我們將學會如何用一個卷積神經網絡和滑動窗口檢測的算法進行目標檢測。
????????假設你想搭建一個汽車檢測算法。你可以先創建一個有標記的訓練數據集x和對應的y。訓練集中包含緊密裁剪的汽車樣例,也就是說x基本上只包含車。

????????有了這個有標記的訓練數據集,你就可以訓練一個卷積神經網絡。輸入一張緊密裁剪的圖像,卷積神經網絡負責輸出y。當你訓練好這個卷積神經網絡之后,你就可以把它用在滑動窗口檢測中了。

????????具體做法是如果你有一張上圖這樣的測試圖像,你要做的是:先選擇一個窗口尺寸 。在圖像中取和滑動窗口一樣大小的圖像,把它輸入到神經網絡中做預測。
。在圖像中取和滑動窗口一樣大小的圖像,把它輸入到神經網絡中做預測。

? ? ? ? 再滑動窗口,取下一個圖像輸入到神經網絡中做預測。

? ? ? ? 按照這樣的方式,直到滑動窗口遍歷了圖片中的所有位置。
? ? ? ? 之前用滑動窗口,現在用更大的窗口 ,也就是取圖片中更大的窗口區域,輸入到神經網絡中作預測。
,也就是取圖片中更大的窗口區域,輸入到神經網絡中作預測。

? ? ? ? 依次遍歷完整個圖像后,用更大的滑動窗口 再執行一遍。
再執行一遍。

????????我們期望這么做:只要圖像做某處有一輛車就會有某個窗口能夠檢測到。
????????這個算法之所以被稱為滑動窗口檢測,是因為你把這些窗口,在一定步長下劃過整個圖像,然后判斷每個方框內的區域是否有車輛。
????????滑動窗口檢測有一個很大的缺點:計算成本大。因為你裁剪出了很多不同的正方形圖像,并讓每個圖像都單獨通過卷積神經網絡的運算。如果你使用了一個很大的步長,那么卷積神經網絡的窗口數量會減少,但是它會影響算法表現;如果你使用了很小的步長,那么這些小區域的數量會很多,將它們全部通過卷積神經網絡意味著很高的計算成本。
4? 在卷積網絡上實現滑動窗口
????????為了搭建一個用卷積實現的活動窗口,讓我們先來看一下如何將神經網絡中的全連接層轉換成卷積層。
????????假設你的目標檢測算法的輸入是14×14×3的圖像,使用16個5×5大小的過濾器,然后做一個2×2的最大池化,把它縮小到5×5×16,然后把它展平成400維向量,在和一個400維的向量做全連接,最后用softmax單元輸出一個y。
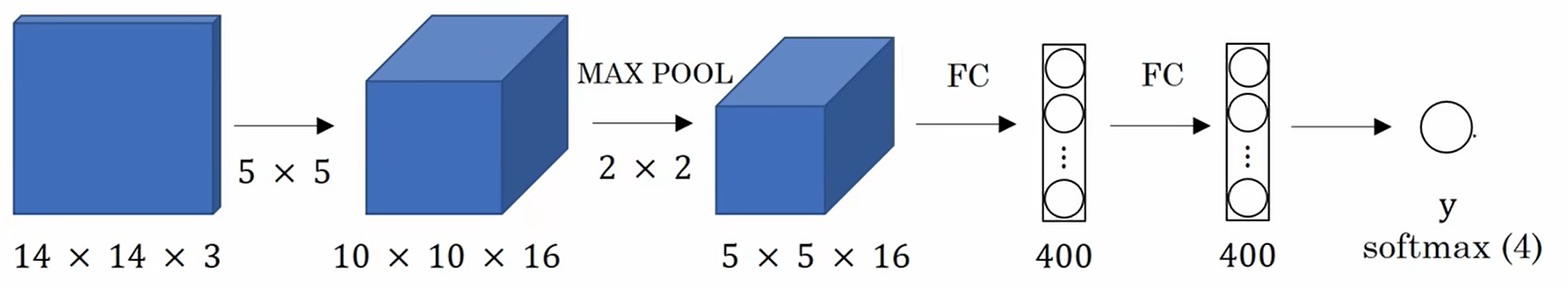
????????為了做我們馬上要做出的改變,將最后的輸出改成4個數字,代表softmax所區分的4個類別中每一類的概率,這4個類別是行人、汽車、摩托車和背景。
????????現在我想做的是展示如何將這些層轉化成卷積層?
? ? ? ? 前面這些層都和之前一樣,只不過要把后面的全連接層換成卷積層。
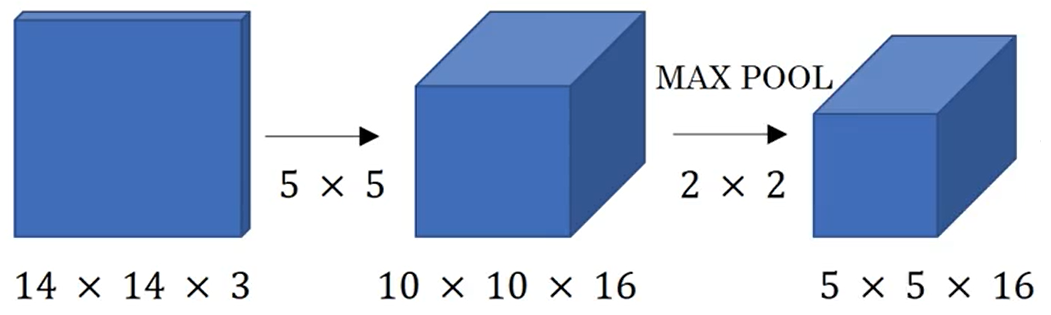
? ? ? ? 用400個5×5的過濾器把5×5×16轉換成1×1×400。從數學操作上來講,這和一個全連接層是一樣的。
????????因為這400個節點中的每一個都對應一個維度為5×5成左右的過濾器。也就是說這400個值中的每一個都是5×5×16個前一層的激活值輸入某個任意的線性方程的結果。
? ? ? ??利用這樣的方式,我們就把它變成了一個卷積神經網絡,如下:

????????在這一轉換之后,讓我們來看一下你怎樣用卷積的形式來實現滑動窗口目標檢測。
????????假設你的滑動窗口卷積神經網絡的輸入是14×14×3的圖像。

????????你的測試集里的圖像是16×16×3。如下圖:
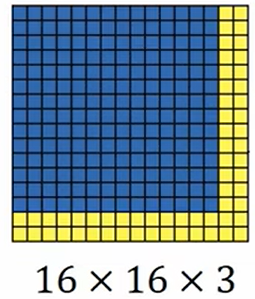
????????在原來的滑動窗口算法中,你可以把藍色區域輸入到卷積神經網絡中,運行一次來得到分類結果0或1,然后你可以向右移動滑動窗口(本例使用2個像素的步長),然后將窗口內的圖像輸入到卷積神經網絡中來得到標記0或1。用這樣的方式,在16×16×3的圖像上進行滑動窗口運算,分別得到了4個標簽。
????????不過事實上,這里面的很多運行卷積神經網絡的計算是重復的,所以對滑動窗口的卷積方式的實現,是讓這幾次卷積神經網絡的前向運算共享計算過程。
????????具體來說,你可以這么做。你可以運行之前卷積神經網絡,用同樣的參數,同樣的過濾器,如下圖:

????????我們可以發現最后輸出的這個藍色區域就是對輸入中藍色區域做卷積運算的結果。其他的區域也是如此。
????????這個卷積形式所做的,不是在輸入圖像的4個子圖像上分別做卷積運算,而是把4個合并成一個進行運算,從而利用這4個14×14圖像的共同區域共享了大量的運算。
????????為了實現滑動窗口,之前的方法是裁剪出一個區域,讓它通過卷積神經網絡,然后對旁邊下一個區域如法炮制,直到有可能這個區域識別出一輛車。

????????但是現在,我們根據之前的方式,可以實現對整張圖像以卷積操作的形式,進行一次大的卷積神經網絡的前向傳播,同時得到所有的預測,然后就有可能識別出這輛車的位置。
5? 邊界框預測
????????我們知道了如何使用卷積來實現滑動窗口,雖然這在計算上更有效率,但是它依然無法精確輸出邊界框。在這里我們將學習如何更精確的預測邊界框。
????????在使用滑動窗口的方法中,通過預先決定的窗口來掃過整個圖片,可能沒有一個邊框與車的位置恰好吻合,也許下圖這個邊框是最吻合的。

????????另一方面,看上去一個更為精確的邊界框實際上并不是一個正方形,它是一個較寬的長方形。所以是否有一個算法可以給出更精確的邊界框?YOLO就是一個比較好的能精確輸出邊界框的算法。
????????下面是具體的做法。假設你有一張輸入圖片是100×100,接著你要將其用網格劃分(這里使用3×3的網格劃分,但是在實際中你會使用更細分的網格,比如19×19的網格)。基本思路是你將圖片分類及定位的算法應用到這九個網格中的每一個。
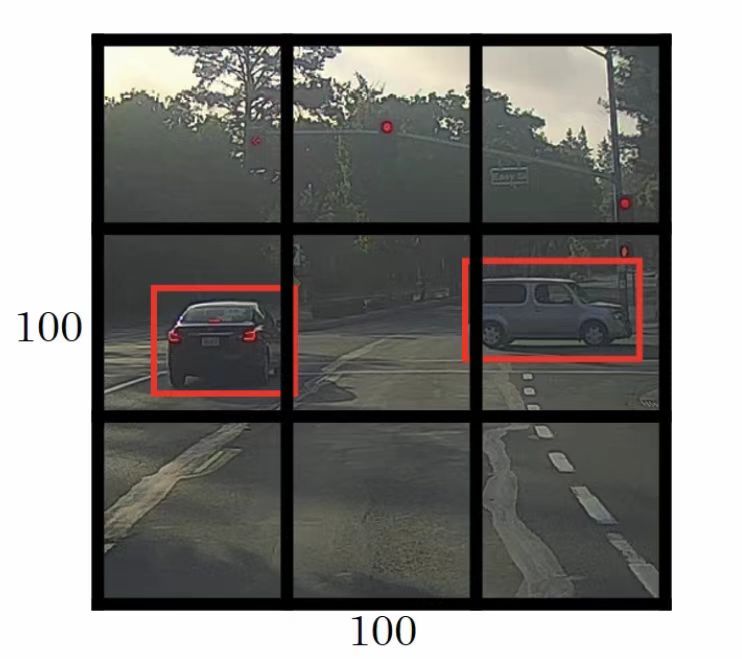
????????對于這九個網格中的每一個,你要給定一個標簽,這個標簽y是一個八維的向量,第一個輸出值 取決于那一個網格中是否有目標物,
指定邊界層的位置,最后
給出網格中的目標物體屬于哪一類。所以每一個網格中都有這樣的信息,即
????????讓我們從左上角的網格開始。左上角這個網格裝沒有目標物,所以這個單元格中的標簽y第一個維度,因此
。所有不包含目標物體的單元格的輸出標簽y都是如此。
????????圖片中有兩個目標物,YOLO算法會將這兩個目標物分別分配到包含它們的中心點的網格中。左邊汽車的預測框的中心點落在由綠色線描繪出的網格中;右邊汽車的預測框的中心點落在由黃色線描繪出的網格中,它們的標簽
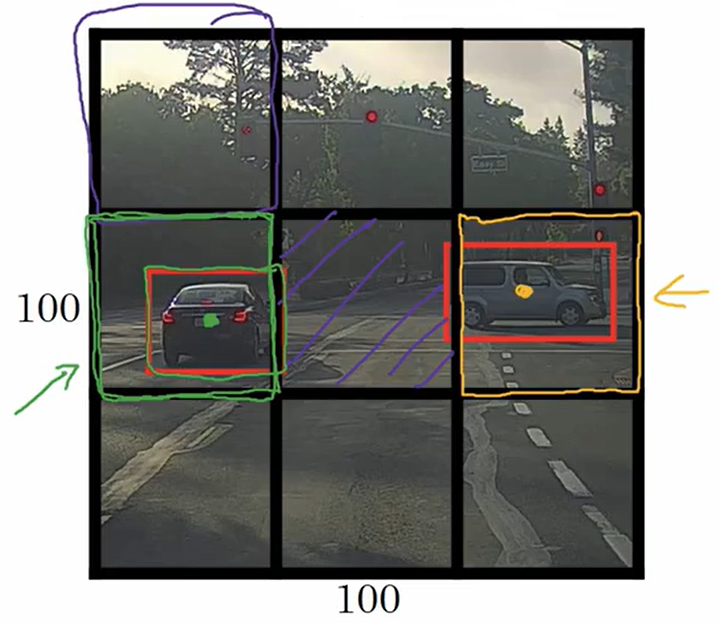
????????對于這9個網格中的每一個,都會有一個8維的輸出向量。由于有3×3個網格,輸出的總大小將會是3×3×8
????????將目標物分配到單元格中的方式,需要先找到目標物的中心點,然后再根據中心點的位置將它分配到包含該中心點的網格中。所以對于每一個目標物,即使它跨越了多個網格,他也只會被分配給這些網格中的一個。
????????我們該如何決定邊界框的參數(),在下圖用黃色線描出的網格中有一個目標物所以它的標簽
。在YOLO算法中,我們把網格左上角點的坐標定為(0,0),右下角的點定為(1,1),要指定目標物中心點的位置,也就是黃點的位置。
,因為它大概在距離左邊0.4左右的位置;
;邊界框的寬度、高度是通過它和整個網格寬度、高度的比例來指定的,
,
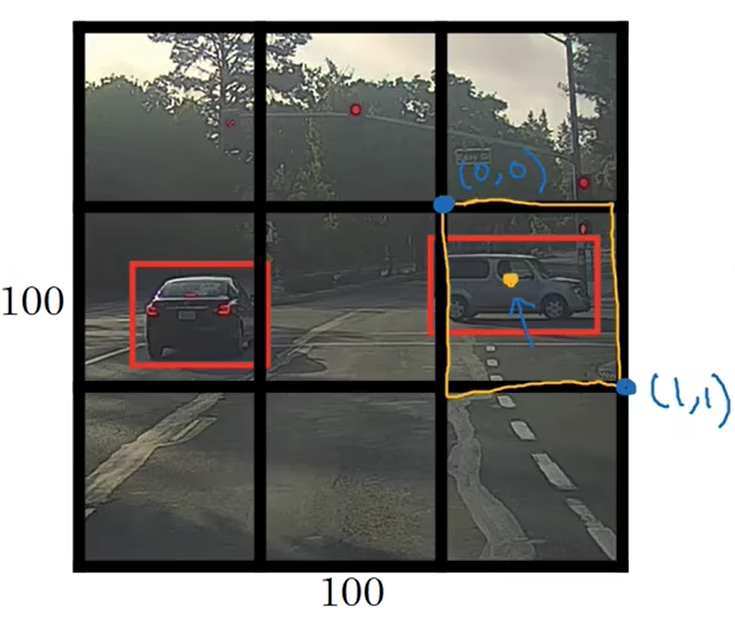
6? 交并比
????????交并比既可以用來評價目標檢測算法,也可以用于往目標檢測算法中加入其他特征,從而進一步改善算法。
????????在建立目標檢測時,你希望能夠進行定位目標。假如下圖的紅框是一個真實的邊界框,而你的算法輸出的是紫色這個邊界框,你不知道這個結果是好還是壞。

????????交并比或者說IoU函數,它計算了這兩個邊界框的交集除以并集的比率。下圖的黃色區域面積除以紫色和紅色區域面積的比值就是交并比。

????????計算機視覺領域的原則是,如果IoU>0.5,你的結果就會被判斷為正確;如果預測和真實的邊界框完美重合了,此時IoU=1。
????????0.5經常作為一個臨界值來判斷預測的邊界框是否準確。這只是一個常規值,如果你想更嚴格一點,你可以把準確的標準提高,IoU越高,邊界框就越準確。因此有一個衡量定位準確度的方法就是:數出算法準確檢測并定位一個目標的次數。
7? 非極大值抑制
????????目前所學到的目標檢測的問題之一是:算法可能會對同一目標進行多次檢測。非極大值抑制確保算法只對每個對象進行一次檢測。我們來舉一個例子。
????????假設你想在下圖中檢測行人、車、摩托車,你會在圖片上放著一個19×19的網格。右邊這輛車只有一個中心點,它應該會被分配到一個網格單元中;同樣的左邊這輛車也應該只有一個中心點,也應該只有一個單元格預測出有一輛車。

????????實際上算法對每一個網格都進行了目標分類和定位算法,那么將會有不止一個網格被認為是車的中心點。讓我們通過一個例子來看一看非極大值抑制是怎么工作的。

????????因為你對每個網格運行圖像分類和定位的算法。在這些網格上,有可能許多網格會舉手說:“我的值很大,有個目標極有可能在我的網格中”,因此對每個目標你可能會得到多個檢測結果。所以非極大值一直要做的是:清理這些檢測。這樣每輛車只會得到一個檢測結果,而不是多個結果。
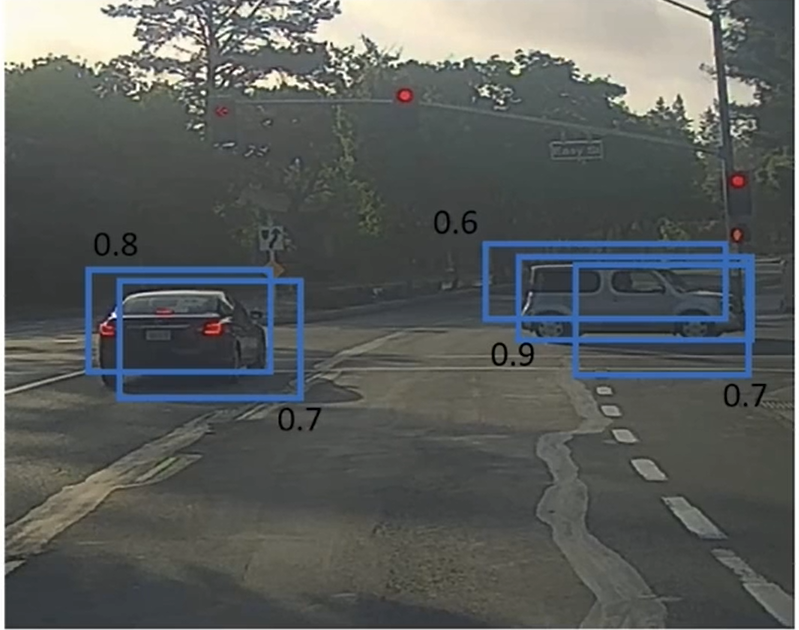
????????具體來說,它就是先看一看每個檢測結果的相關概率,選取其中概率最大的那一個框。接下來非極大值抑制再看剩下的所有方框以及所有和你選的框有著高IoU值的框,把它們抑制。接下來再從剩下所有的框找出概率最大的框,去掉任何有著高IoU值的框。
? ? ? ? 如果把下圖中暗的框都去掉,剩下的框就是這兩個物體的最終預測框。
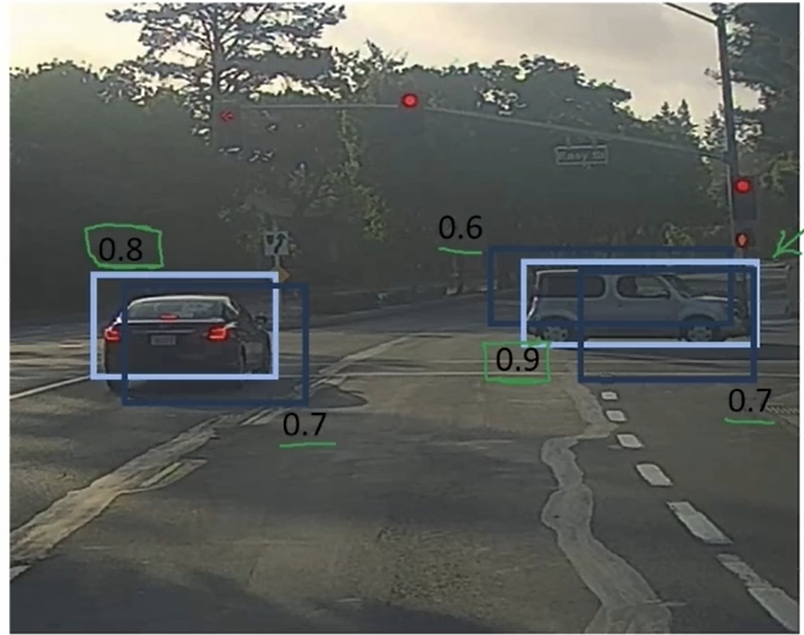
? ? ? ? 這就是非極大值抑制。非極大值意思是你將要輸出有著最大可能性的分類判斷,抑制那些非最大可能性的鄰近的方框。
????????現在我們來看一下這個算法的細節。首先在這個19×19的網格中,你會得到一個19×19×8的輸出量。為了運用非極大值抑制,首先要做的是丟掉所有值小于某個值的的方框,這樣我們就去掉了有著低概率的邊界框。
????????如果還有剩下的邊界框還沒有被處理掉,將重復的選出最大pc值的邊界框,將它作為一個預測結果,然后丟掉有著高IoU值的邊界框。
8? 錨框
????????目前,目標檢測的問題之一是:每個網格單元只能檢測一個對象,如果一個網格單元要檢測多個對象該怎么辦呢?我們可以利用錨框。讓我們從一個例子開始了說明。
????????假設你有這樣一張圖片:

?人的中點和車的中點幾乎處在相同的位置,也就是說它們的中心點都落在同一個網格單元里。
????????對于這種情況,輸出向量y沒法輸出兩個類別,如果利用錨框的話,你需要預先定義兩個不同的形狀,你需要將這兩個預測跟兩個錨框關聯起來(一般來說,你可以使用更多的錨框,但在這里只是用2個)
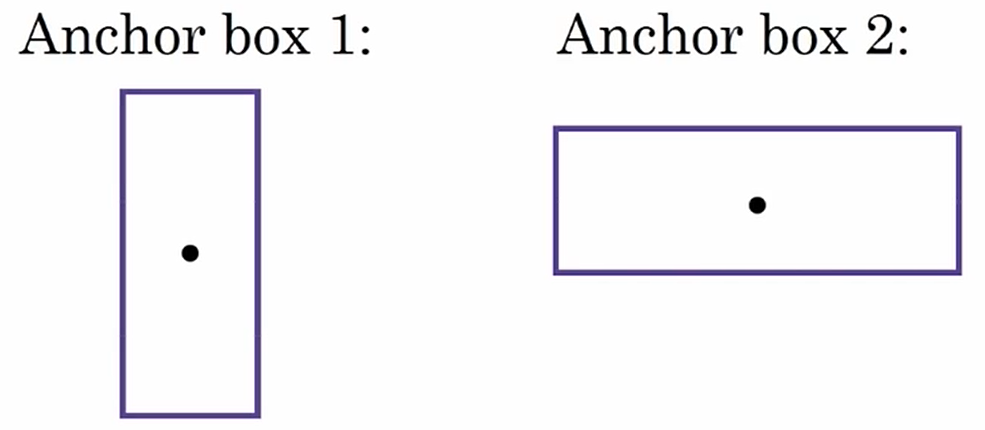
????????你要定義一個交叉標簽,其中前8個是跟1號錨框關聯的輸出值,后8個是跟2號錨框關聯的輸出值。
9? YOLO算法
????????讓我們來看看你該怎么構建訓練集。假設你想訓練一個算法來檢測三個目標:行人、汽車、摩托車。輸出y是3×3×2×8
????????以第1個網格為例,在這個網格中沒有目標,因此

????????第1個錨框的,因此沒有相關目標在第1個錨框;第2個錨框的
也是0,所以其他的值并不重要。
????????在這個圖像中,除了綠色框,絕大部分的網格中都沒有任何目標。對于綠色框而言,它的目標向量
????????遍歷這個3×3的框都會得到一個16維的向量,所以最終的輸出大小會是3×3×16。輸入的圖片也許是100×100×3,經過卷積神經網絡轉換后輸出3×3×16
????????這就是訓練,接下來我們看看算法如何進行預測。

????????輸入一張圖片,如果網格中沒有目標,你希望你的神經網絡輸出的值為0,其他值不能輸出一個“無所謂”的值,所以會給一些數值,但是這些數字都被無視,因為神經網絡告訴你這里沒有目標。
????????對于綠色框,你會希望輸出一些數值,它能非常準確的繪出車的邊界框。
????????如果你使用錨框,每個網格中都會得到兩個預測的錨框,某些可能會有很小的概率,非常小的,你得到的錨框可能如下圖所示:????????

????????如果你使用錨框,每個網格中都會得到兩個預測的錨框,某些可能會有很小的概率,非常小的pc,你得到的錨框可能如下圖所示:
????????當你去掉所有低概率的預測后,你需要單獨對被預測的類別執行非極大值抑制后產生最后的結果。
10 用u-net進行語義分割
????????語義分割的目標是:?繪制檢測到的對象周圍的輪廓,以便知道哪些像素屬于對象,哪些像素不屬于對象。
????????假如你正在建造一輛自動駕駛汽車,你看到像下圖這樣的輸入圖像,想要檢測其他汽車的位置。如果使用目標檢測算法,是繪制其他車輛周圍的邊界框。這對于自動駕駛汽車來說可能已經足夠了,但是如果你想讓你的學習算法弄清楚這張圖片中的每個像素是什么,那你可以使用語義分割算法。語義分割算法嘗試標記每一個像素。
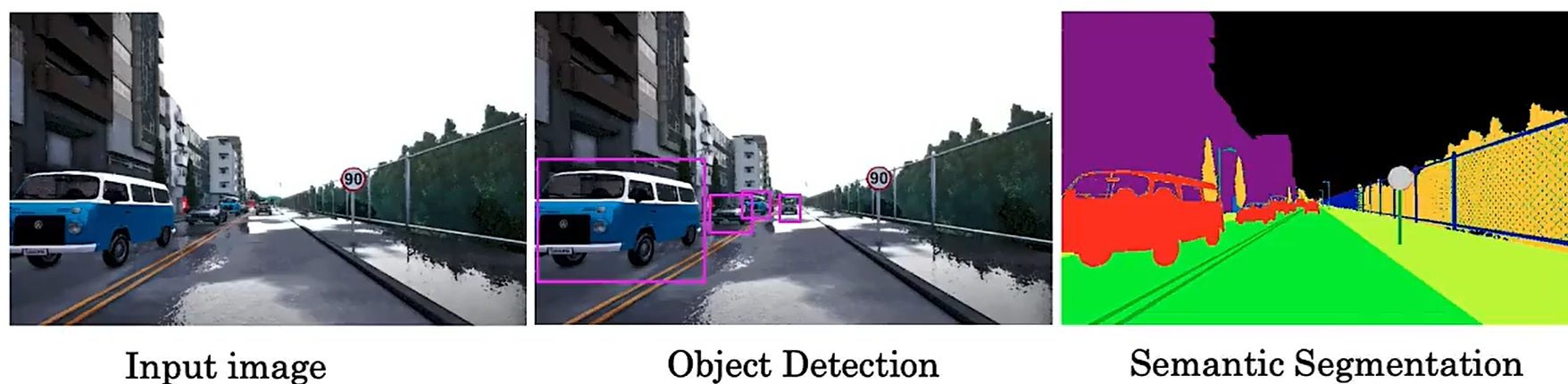
????????讓我們深入研究語義分割的作用。為了簡單起見,我們使用下面這個例子:從圖片中分割出汽車。在這種情況下,你可能會使用兩個標簽。

????????1代表是汽車,0代表不是汽車,在這種情況下分割算法會輸出此圖像中每個像素的1或0。

????????如果你想更精細的分割這張圖片,用1表示汽車,用2表示建筑物,3表示路面。
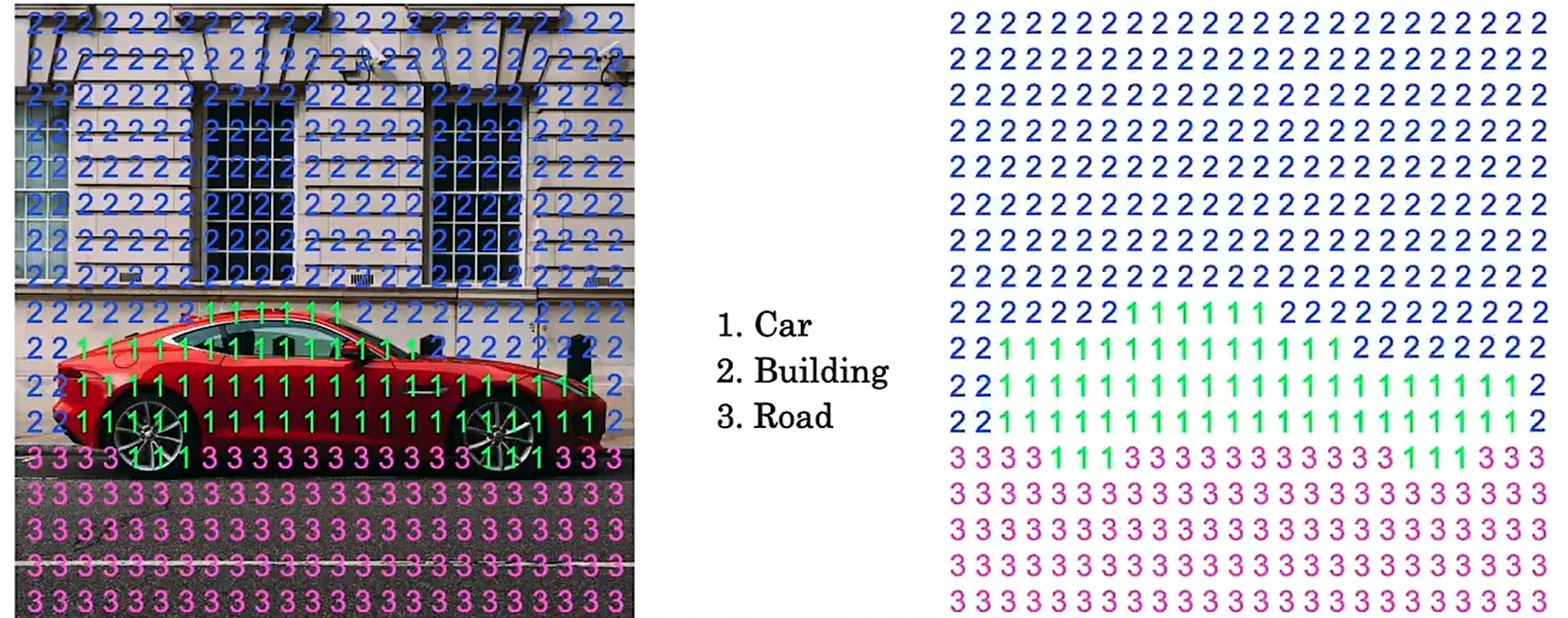
? ? ? ? 我們的應該網絡應該怎么做到這樣的輸出呢?
? ? ? ? 這是一個卷積神經網絡結構:

? ? ? ? 為了把這個網絡變成語義分割架構,我們把最后的全連接層去掉。
????????由于圖像經過神經網絡后,尺寸會越來越小,因此為了獲得全尺寸圖像,我們需要逐漸擴大該圖像。具體來說,當輸入圖像進入U-Net后,寬度要加大,通道數要減少,直到得到一個圖像分割圖。這就是U-Net架構的工作原理。

????????我們還沒有討論的一項操作是:把圖像變大。為了解釋這個過程,我們需要先了解如何使用反卷積(轉置卷積)。
11? 轉置卷積
????????轉置卷積是U-Net架構的關鍵部分。如何把2×2的輸入放大為4×4的輸出,這就是轉置卷積所要做的工作。讓我們來深入討論這個問題
????????普通卷積的工作原理是:可能會輸入一個6×6×3的圖像,和5個3×3×3的過濾器進行卷積,最終得到4×4×5的輸出。轉置卷積則有些不同。你的輸入可能是2×2,用一個3×3的過濾器進行卷積,最終得到的輸出是4×4。從這里可以看出輸出大于原始輸入。
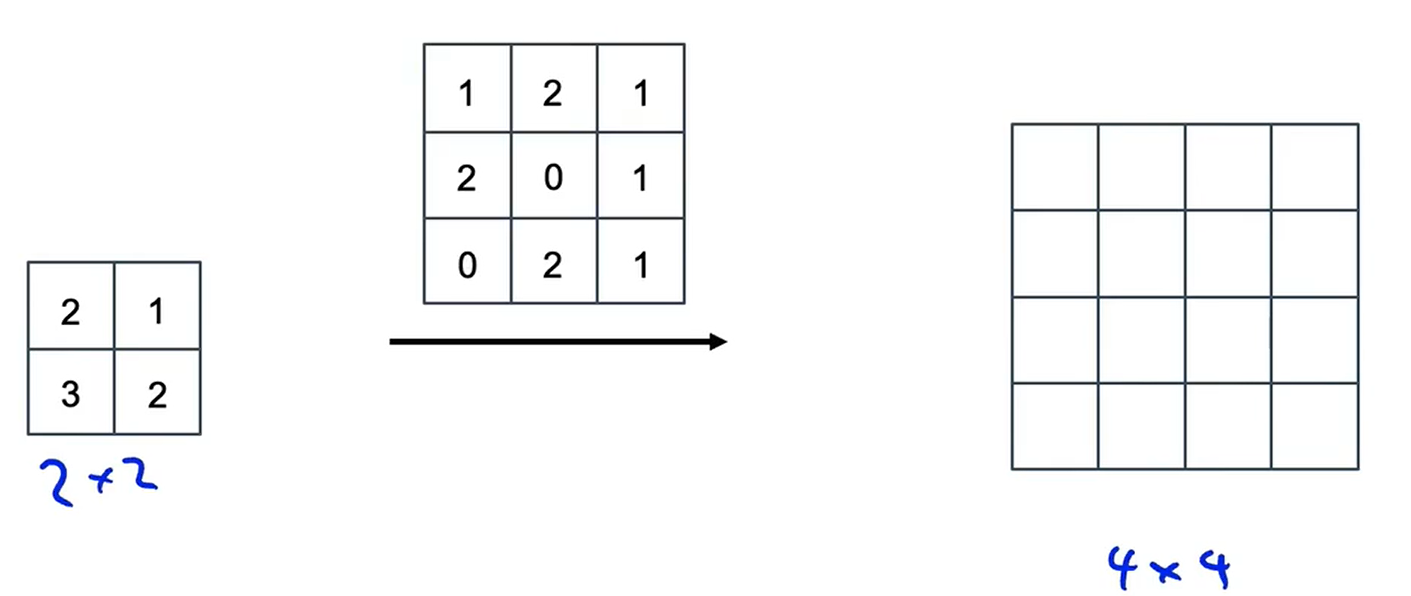
? ? ? ? 我們使用padding,它會作用在輸出上,假設p=1;步長s=2
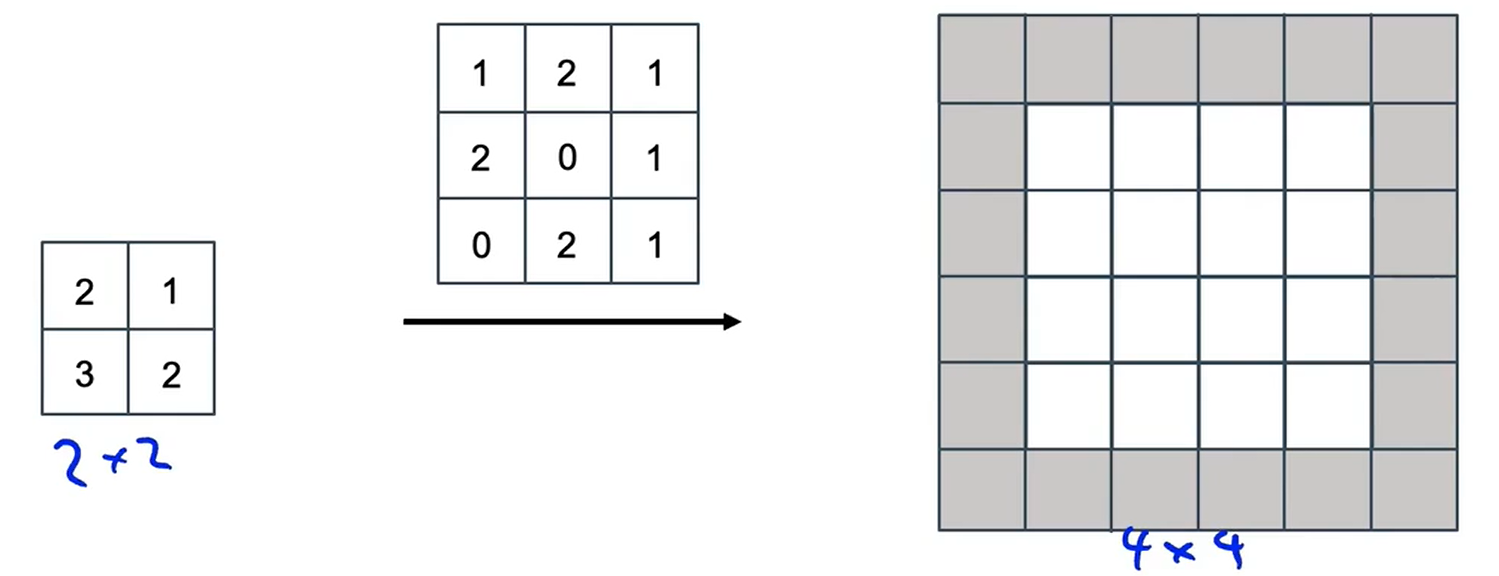
? ? ? ? 讓我們來看看轉置卷積的工作原理。
????????在普通的卷積中,通常要把過濾器放置在輸入上面,然后將其相乘再相加;在轉置卷積中是在輸出上放置過濾器。
????????首先輸入中的第1個元素2和過濾器中的每一個元素相乘,把這個3×3的值放在輸出中。填充區域不會包含任何數值,因此我們會忽略填充區域,并在輸出的紅色顯示區域中填入4個數值。
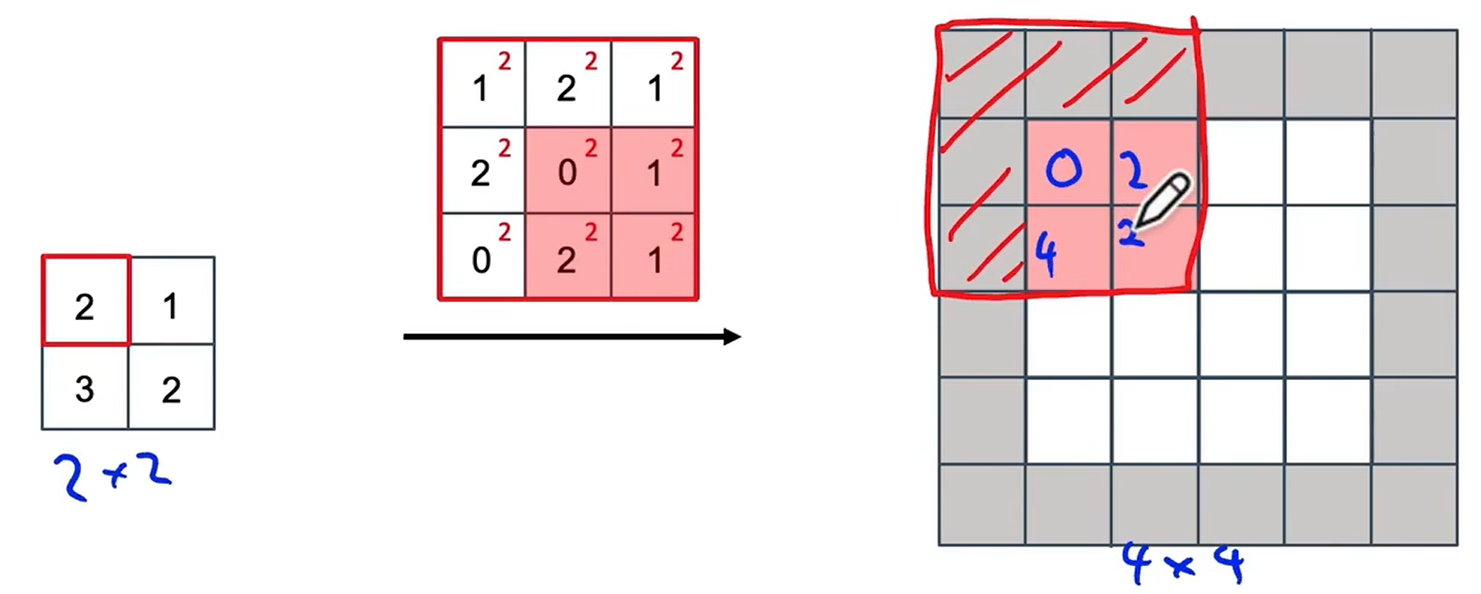
????????接下來我們來看第2個數值,也就是1,每個過濾器的元素乘1。因為我們使用了步長為2,因此輸出中的方格區域會向右移動兩格,同樣忽略填充區域,需要復制的數值區域只有這個綠色的陰影區域。你可能注意到在我們復制過濾器的紅色區域中,與綠色區域之間存在一些重疊,因此我們不能簡單的把綠色部分的紙復制到紅色部分的值上,而是把紅色區域的值和綠色區域的值相加。
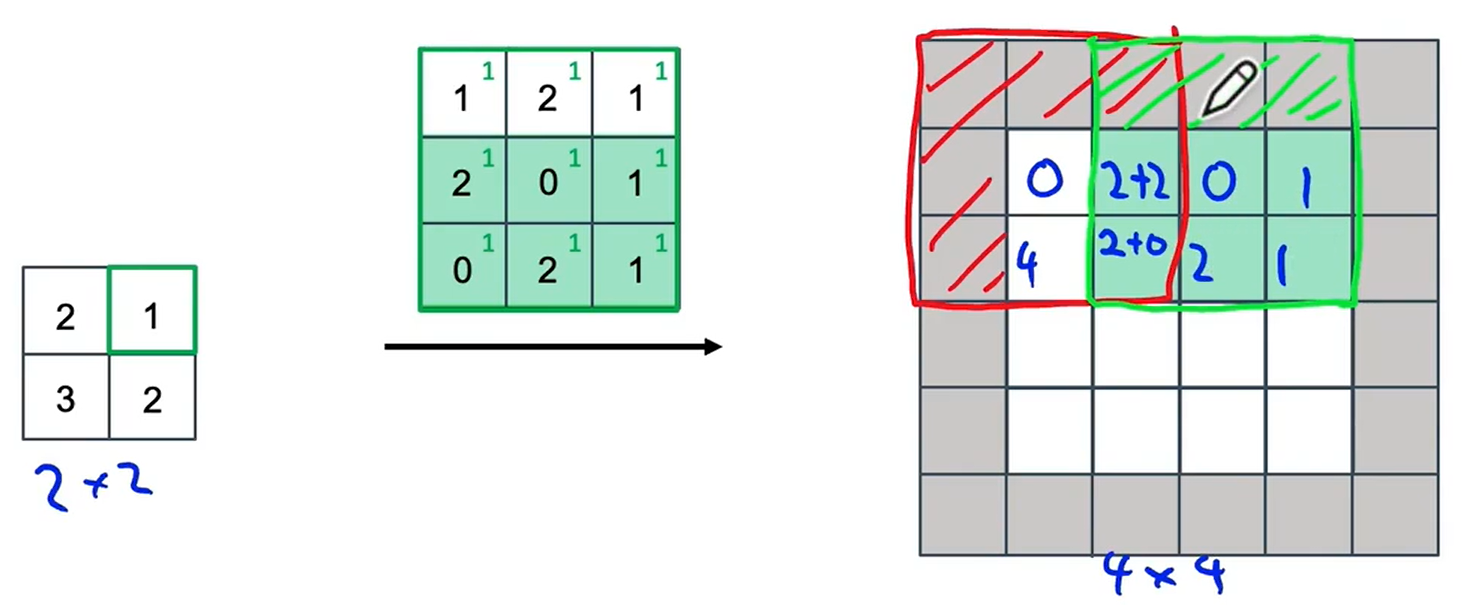
? ? ? ? 我們計算下一個:
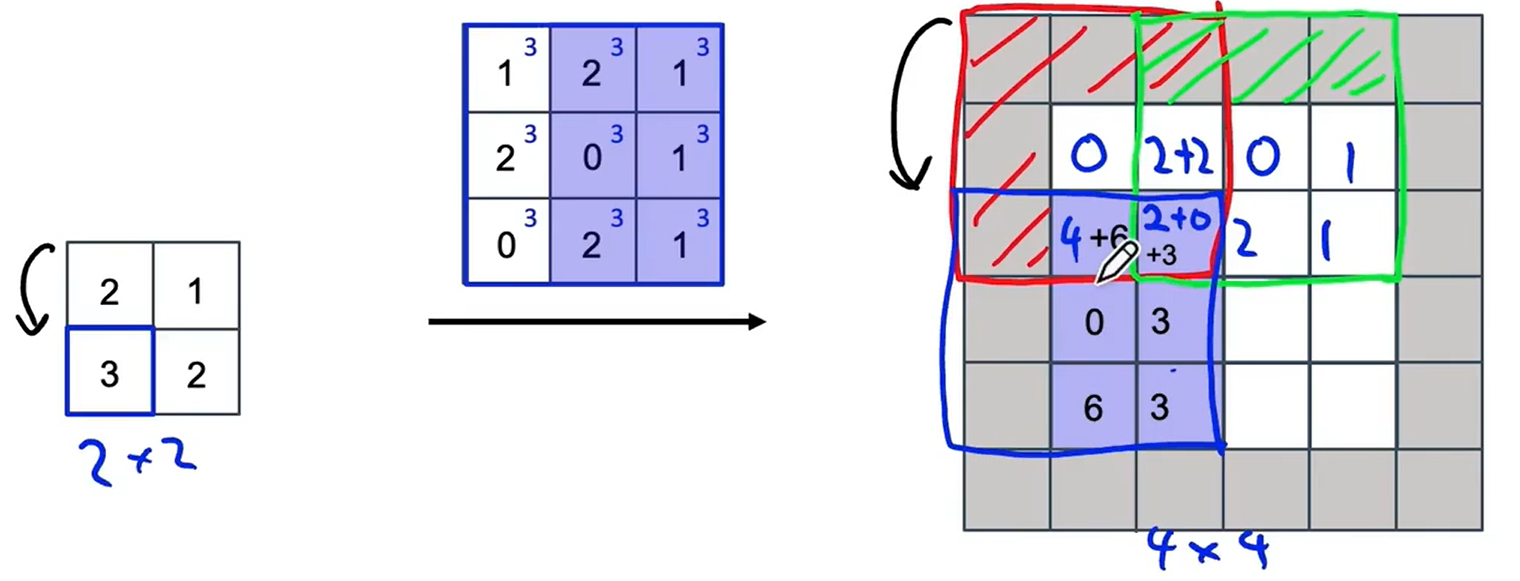
? ? ? ? 計算最后一個:
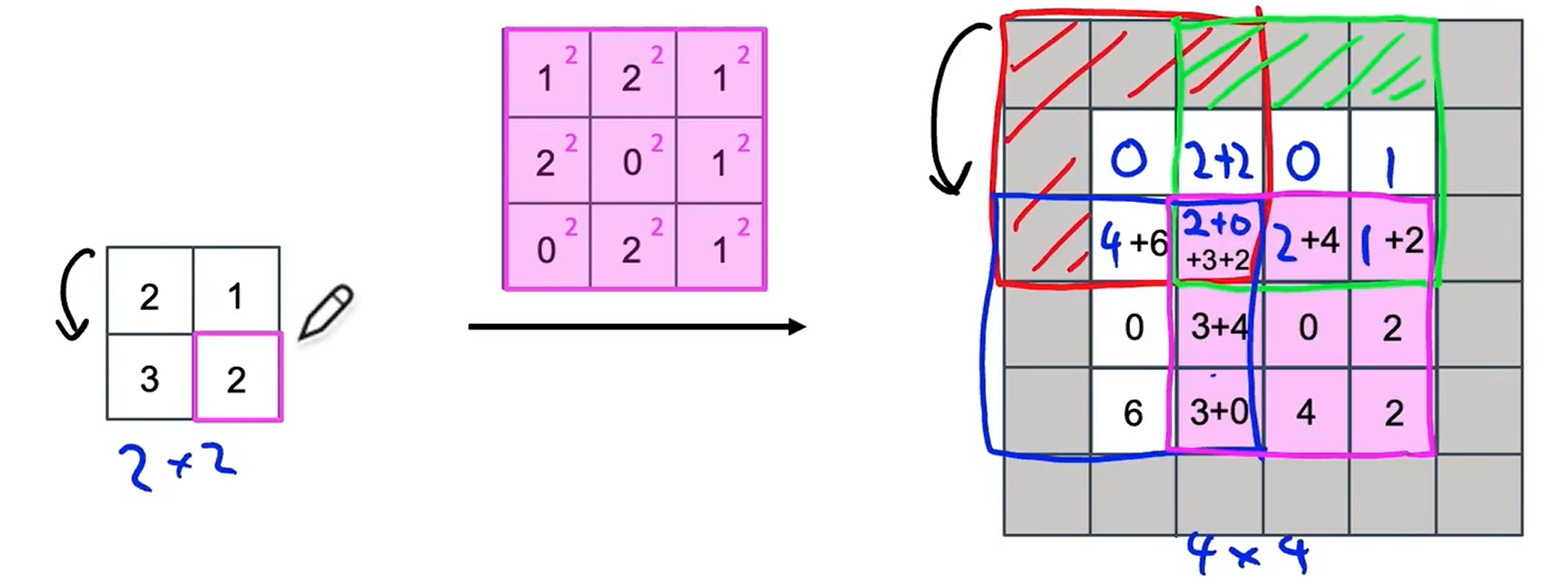
????????你可能想知道為什么要這么處理。雖然有很多方法都可以把小的輸入值變成較大的輸出值,轉置卷積是最有效的。
12? ?u-net 結構靈感
????????現在我們知道了轉置卷積的時限,我們可以深入探討一下U-Eet架構的細節了。
????????這是一張關于圖像分割神經網絡架構的粗略示意圖:

????????對于該神經網絡的前半部分,采用普通卷積。這部分神經網絡會對輸入圖像進行壓縮,經過這樣的作用后,可以演變成相當小的圖像,從而會喪失許多空間信息,因為維度變小了,但是卻更深了。在該神經網絡的后半部分,采用轉置卷積,把壓縮圖像再放大到原始輸入圖像的大小。
????????事實證明,對該神經網絡的架構進行修改是很有必要的,這樣可以使它工作得更好,這就是U-Net架構由來的原因。轉置卷積可以獲得上一層的高層次空間的復雜信息,而因為缺少了圖片的詳細空間信息,只有較低的空間分辨率。












—— Java安全SQL注入SSTISPELXXE)






)