提到 “SaaS 出海”這個詞大家肯定并不陌生,SaaS 企業將業務拓展到海外市場已經成為許多 SaaS 公司的重要戰略方向。隨著企業對于靈活性、可擴展性以及成本效益需求的不斷增長, SaaS 模式提供了理想的解決方案。對于尋求出海機會的 SaaS 企業來說,全球化市場的巨大潛力尤為吸引人。在許多地區,尤其是發展中市場, SaaS 服務的普及率還遠遠沒有飽和,這也為企業提供了非常廣闊的成長空間。
隨著全球數字化轉型的不斷加速, SaaS 服務需求也在持續增長。上周,GTC 2024 全球流量大會在深圳成功召開,Databend 作為新一代云原生數據倉庫服務商,也攜帶領先的出海大數據解決方案亮相本次大會。大會圍繞著“角逐技術力,把握 SaaS 出海新姿勢”這個話題產生出許多精彩的碰撞火花。Databend 聯合創始人吳炳錫出席了本次大會,并帶來 《SaaS 出海:Databend Cloud 的定位與實踐》分享。Databend 成立至今已有三年,這三年里 Databend 是如何定位產品?怎么做出海?以及如何獲取出海用戶的?通過以下的分享將為大家一一揭秘。

Databend 創建于 2021 年 3 月,核心團隊成員來自 ClickHouse 社區、谷歌 Anthos、阿里云等國內外知名互聯網和云計算公司,團隊在云原生數據庫領域有著豐富的工程經驗,研發人員分布在中、美兩地,同時也是數據庫開源社區活躍貢獻者。我們創立的開源云原生數倉項目 Databend,是一個使用 Rust 研發、基于對象存儲設計的新一代云原生數據倉庫產品,提供極速的彈性擴展能力和按需、按量的 Data Cloud 產品體驗,致力于打造開源版的 Snowflake。目前,Databend 在 GitHub 上獲得超過 7400 個Star ,擁有 180 多位貢獻者,總 PR 數量達到 9700+ ,累計已解決 Issue 接近 4400 個。我們以 Databend 作為內核,打造了商業化產品 Databend 企業版和 Databend Cloud。
目前,Databend Cloud 在 AWS、阿里云、騰訊云、華為云新加坡區都提供了相應的服務。在 AWS 上,我們在美國東一區、西一區以及歐洲區都提供了云服務。未來,我們也會隨著用戶的需求繼續開拓新的可用區。基于我們成熟的部署經驗,開一個新區大概只用 2- 3 天,能夠極快滿足用戶的業務需求。
Databend 的適用場景包括實時 OLAP、海量日志/數據歸檔、財務數據的離線分析等,服務的用戶包含多點、微盟、茄子快傳、海外的區塊鏈公司,以及南北醫藥集團、尼泊爾電信、蘋果中國、國內汽車廠商等等。
Databend Cloud 產品定位
Databend 團隊在數據庫領域都工作了十年以上,對數據庫行業的痛點非常熟悉。所以當時為 Databend 做產品定位的時候,我們就在想怎么才能幫助企業解決行業里的數據痛點。
出海企業在做海外業務時,很多人都想利用 AWS 穩定的網絡和硬礎架構去做底層基礎設施支撐。看起來一切都是美好的,但隨著業務增長,他們不得不面對復雜的產品和架構,數據分析成本越來越高。一方面,可供選擇的產品非常多,企業也跟著很迷茫,另一方面,這些產品本身也非常昂貴,除了計算存儲費用外,還有網絡、備份恢復、跨 VPC 傳輸等等。
Databend Cloud 的設計目標
Databend 致力于簡化這一切,我們的 Databend Cloud 很早就定位在 Snowflake、Redshift、BigQuery 的替換上。用戶從這些技術棧遷移到 Databend 上面,基本上 2- 3 周都能完成,而且過程非常順利。
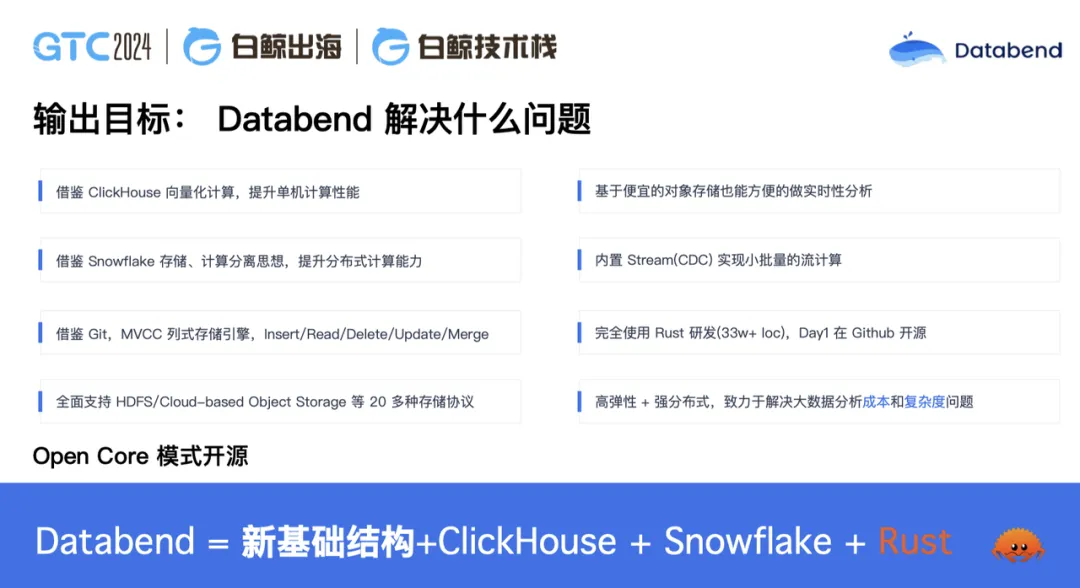
我們為什么能解決這些問題?
首先,Databend 的內核團隊非常熟悉 ClickHouse,ClickHouse 在中國 TOP5 的貢獻者我們團隊占了三個,所以我們基于 ClickHouse 的向量化計算和 Rust 大幅提升了產品性能。同時,我們基于 Snowflake 的存算分離思想,提升了分布式計算能力,借助 Git 實現 MVCC 列式存儲引擎,支持事務操作。支持事務也是我們對大數據的一項突破。目前,所有大數據產品其實都不講究事物,這也造成了金融領域、公司財務報表、公司訂單對賬經常會丟失數據,或者數據對不齊。我們把數據庫的事務理念帶到了大數據里面,并用 SQL 的理念解決了這個問題,支持了事務。所以 Databend 在數據對賬場景中表現非常完美,支持這個場景完全沒有問題。
此外,我們還開源了一個 OpenDAL 項目。2023 年 3 月, OpenDAL 正式移交到 Apache 軟件基金會孵化器中進行孵化,將會在今年畢業。它已經成為 Rust 生態以及數據庫開發生態里大量使用的組件。
另外,我們把大數據里面大家最痛苦的——任務編排、stream 流計算,還有內部的一些增量獲取,全都內置到 Databend Cloud 里,對外提供統一的 SQL 入口。從此,你不用去想什么任務編排了,也不用去搞外置 GPT,只用這一套 SQL 就可以全部搞定。
我們今年剛剛支撐了一個游戲用戶,他們原來有一個 30 多人的大數據團隊,近半年都在支持一個游戲上線。 據他們介紹,這個游戲上線后需要半年回本,如果回不了本,這個游戲可能就廢了。之前,30 多人的團隊支撐一個游戲上線其實是很困難的。在使用 Databend Cloud 后,現在一個游戲只需要 2- 3 人就可以支撐住了。
Databend Cloud——基于 Databend 的 SaaS 產品
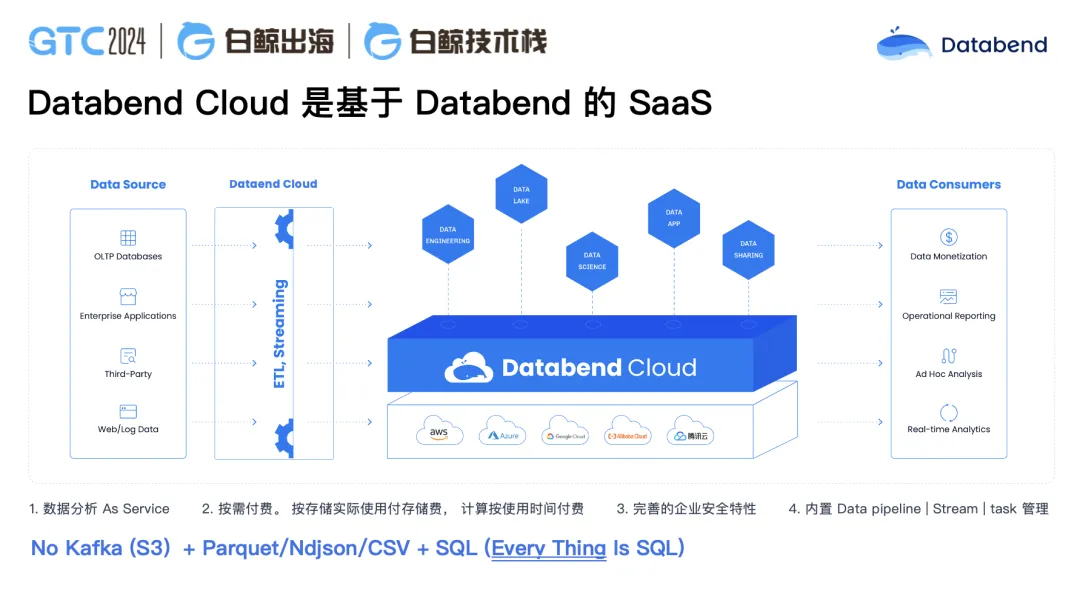
與其他大數據產品不太一樣,Databend 是構建在對象存儲之上的一個數據倉庫,在對象存儲之上你可以用 SQL 去做數據操作。在 Databend 里,你的存儲不用搞多副本,不用搞數據分片,也沒有分區分表,分庫分表,上層就一個表,通過 SQL 來計算就可以了。
這樣做的好處是你使用的資源減少了非常多。比如說原來我們做大數據,做數據中轉,可能 ClickHouse 要 40 臺機器,Kafka 和做數據清洗 ETL 占 100 多臺機器,甚至 200 臺都可能是正常的。使用 Databend 后,可能就變成了 30 臺左右,不用再使用 Kafka 和 ClickHouse。你的數據直接用 S3 接住,然后再往 Databend Cloud 里做數據的清洗、加載、處理,整個過程全是使用 SQL 以及 Python 處理。
我們設計的這個產品,平替了整個大數據技術棧,SQL 使用體驗與使用 Snowflake 非常接近。而我們比 Snowflake 更有優勢的一點在于我們可以進行私有化部署。如果用戶對數據審核要求極為嚴格的話,甚至還可以把數據放在用戶自己的對象存儲 Bucket 里面,只把計算放在 Databend。
Databend Cloud 的創新點

Databend 與傳統的數倉產品也有非常大的區別。傳統數倉基本都會強調分庫分表以及分區的概念,它不敢讓你把集群擴展得非常大,同時數倉需要保持 always on。數倉產品有個特點,凌晨會做大量數據清洗、報表的工作,所以你會發現凌晨到早上 8 點之間數倉都會非常繁忙。反而到了白天,數倉由于在進行大量的數據加載,并不繁忙。白天它的 CPU 利用率可能只到 5% 左右,非常低。但高的時候 CPU 利用率又會到 100%,又扛不住。
Databend 的做法是,如果說你需要非常大的計算資源,可以讓它動態擴展到一個指定的 size。如果你發現實際上并沒有那么大的計算需求怎么辦?還可以讓它動態收縮,甚至收縮到零,這樣就沒有計算資源,只有存儲了。這將為用戶實現比較好的成本控制,計算資源是彈性的,存儲成本實現本地盤的 1/ 8。
同時,對象存儲本身就搞定了副本,所以你也不用搞備份。Databend 的存儲引擎從底層設計就支持備份,你所有的操作都可以回滾到上個操作。比如你正在做一個 table,只需一個命令,undo table 就可以回來。再比如 update table,把 table update 錯了,可以很方便地回到上一個時間位置。Databend Cloud 在云上默認給用戶保留了一天的恢復周期,更長的恢復周期則需要平臺恢復。
Databend Cloud 內置了 Task、Stream、insert multi table。其中,insert multi table 是一個非常有意思的功能。在一個征信項目里,數據本身是一個 json 文件,分成了 40 多個 section,是一種半結構化數據,我們的目標是將其清洗成結構化數據去使用。這時候就可以用 insert multi,將每一個部分插到不同的表里面,然后就可以直接使用了。我們可以把一個復雜的 JSON,甚至是不同的 JSON,按不同的位置用 insert multi 插到不同的表里面,這樣的話它就變成一種結構化數據去使用。在這個過程里,我們也支持復雜 SQL 的一些大屏,寬表等類型。
另外,我們現在最成功的一點是支持了 Python 的 UDF,我們也支持 Python 的外置 UDF。數據科學家可以用 Python 去寫一些數據邏輯,然后用 SQL 來調取。甚至你這個 Python 如果需要 AI 的能力,在特別復雜情況下你可以外掛到外面,直接調機器學習的能力去使用。同時,Databend 提供了 SQL 為統一接口,所有操作都以 SQL 為接口,這讓大多數數據開發人員無需再學習就可以掌握。
現在,我們還在實現一個探索功能,在 Databend 內置 CPU 的 AI embedding。如果你的計算過程中沒有 GPU 資源的話,通過這個能力可以直接用 CPU 做 AI embedding,會節省大量成本。
幫用戶解決問題,Databend Cloud 云上最佳實踐
我在創業的這幾年里,最大的一個感受是你做的事情別人其實不一定感興趣。如何讓別人對你感興趣呢?首先你要發現別人的痛點,然后解決了他什么樣的問題,在這個問題里面如何輔助他真的能走向成功。
Databend 現在已在游戲、社交、金融、廣告、電商等多個行業領域中成功替代 Snowflake、Redshift、BigQuery、GreenPlum、ClickHouse、CDH 等產品,為客戶提供了降本增效的大數據解決方案。

比如上圖這個客戶是做海外游戲的,大概每秒鐘會產生十幾萬條數據的入庫,這些數據再去做分析。原先,從數據到可見都在 Snowflake 上,可以實現分鐘級可見。現在遷移到 Databend Cloud 后,它做到了秒級可見,整個數據從可見到使用非常快,同時我們的語法跟 Snowflake 基本一致。數據先寫 S3,從 S3 加載到 Databend Cloud 里,做數據的打平,數據的加工,最終對外提供服務。這時候他的數據科學家也可以直接介入進來,進行更多深入的數據分析工作。
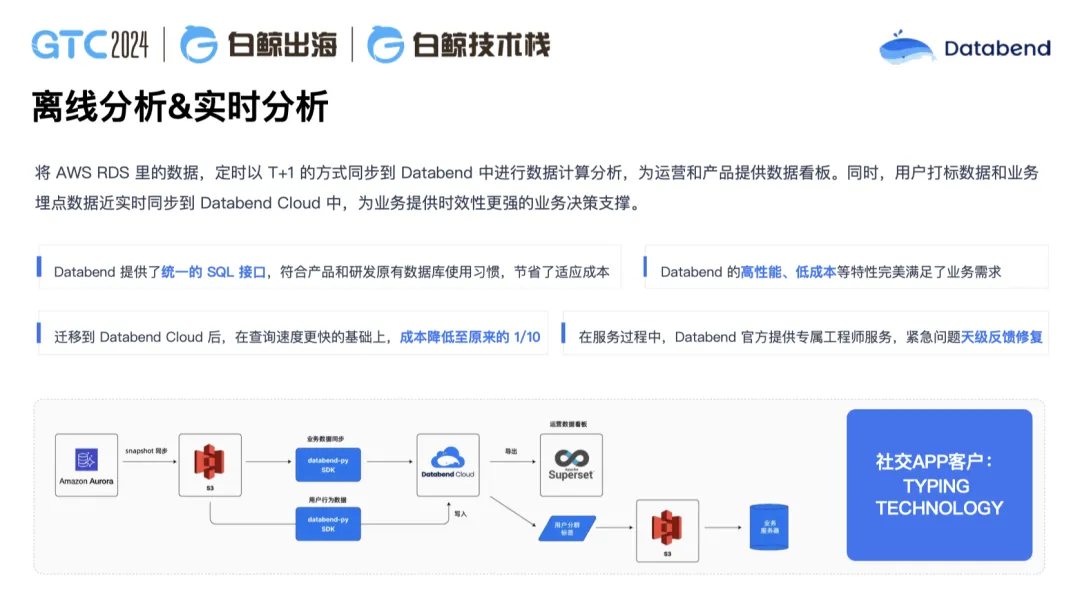
Typing 是我們做過的一個社交用戶,原來用的是 Redshift,每個月的消費在 3, 000 美金左右,遷移到 Databend Cloud 后,每個月消費下降到大概 300 美金左右,成本降低了 90%。為什么可以降低這么多?很大的一個原因是他在計算節點不使用情況下,可以直接關閉自動休眠掉,節省了大量的計算資源費用。此外,他的存儲從原來的本地盤變成 S3,同時我們在 S3 還引入了壓縮,如果你在本地盤的數據是 100G,壓完之后就只有 10G。在這個案例中,成本下降非常顯著。
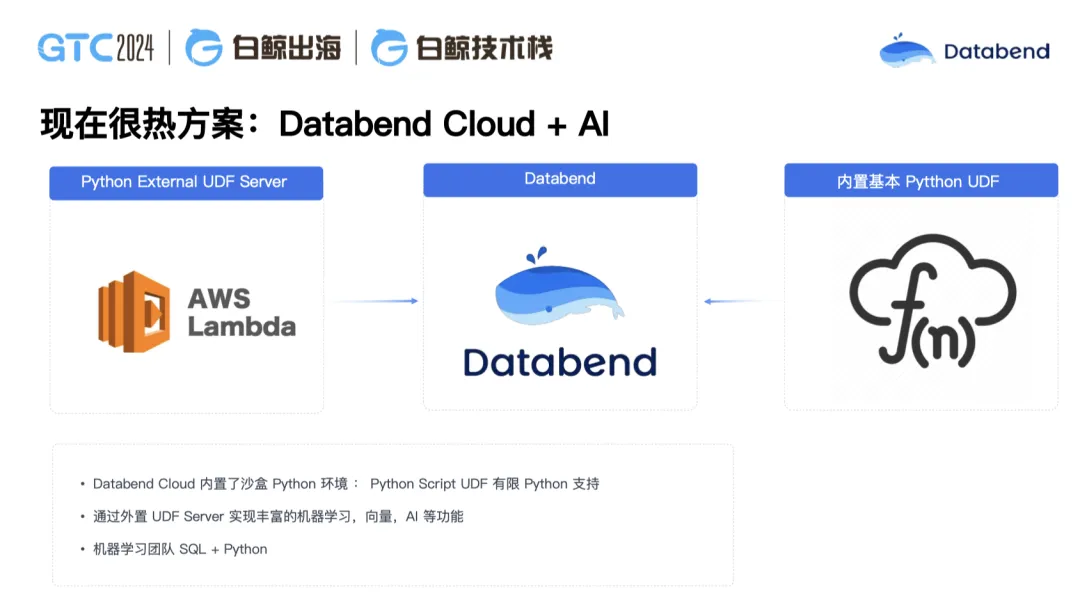
AI 大模型是現在一個非常熱的方案,用戶也經常問我們如何跟 AI 進行整合。最近,我們在一個醫藥場景落地了一個應用。當醫生在醫院里開藥,只用把病人的癥狀輸進去,這套方案就會自動把對應的藥品說明返還出來。這是怎么做到的呢?首先,我們借助了 AWS Lambda 計算函數,把一些藥品的數據進行訓練,訓練完之后只要輸入癥狀我們就可以把藥品對應出來,然后動態選擇。這解決了很多醫生的煩惱,以前他可能知道這個癥狀,但不知道還有哪個藥能治這個病,我們正在探索的這個 AI+Databend 的方案可以很好地解決這個痛點。此外,我們也正在和金融行業做一些探索,繼續拓展更多的落地場景。
在上述場景里,你可以理解為 AI 學習可以借助外部的 Python UDF 去做機器學習訓練,訓練好的結果集可以供 Databend 使用。在這種情況下,如果說涉及到特別復雜的邏輯,SQL 已經沒辦法表達了,你就可以用 Python 來定義 UDF 來去使用。我們用 Databend 存儲了數據, 使用外部的 GPU 來做向量化計算和機器學習,繼續 AI 的一些訓練,然后內部整合到 Databend,把數據和機器學習完全打通了。
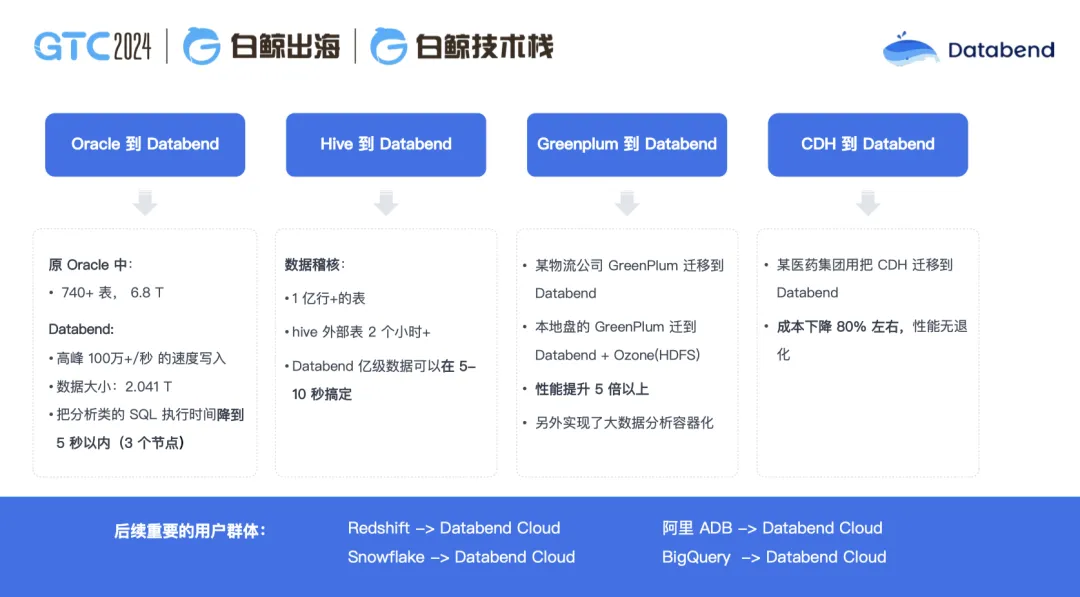
這是我們做的一些案例總結,如果你留意我們社區的話,可能看到過這些分享。比如在 Oracle 的遷移里,原來 700 多張表, 6.8T 的數據,遷移到 Databend 里只有 2T 多的數據,高峰時間達到 100 萬+每秒的速度寫入,原來一個 80 多秒的 SQL 在 Databend 能穩定跑在 5 秒以內,只要三個節點;從 Hive 到 Databend 的案例,1 億行+的情況下,做數據比對,在 Hive 里面需要兩個小時,在 Databend 里面十幾秒就能可以搞定;在 GreenPlum 到 Databend 的遷移場景里,從 HDFS 本地盤遷到 Databend 里,性能得到了 5 倍以上的提升,并且管理更簡單,計算也更好擴展;某醫藥集團把 CDH 遷移到 Databend,成本下降 80% 左右,性能無退化。
今年,我們還在陸續替換阿里 ADB,Redshift,Snowflake,Bigquery 等產品。以前沒做大數據前,我其實很少接觸到幾萬億的表,做了大數據行業之后,我發現萬億級別的表,甚至 PP 級單表都很正常。Databend 集群在萬億級或者 PB 級表的場景下,只需 30 多臺機器就可以運行得很好,是應對海量數據分析的完美解決方案。
關于 Databend
Databend 是一款開源、彈性、低成本,基于對象存儲也可以做實時分析的新式數倉。期待您的關注,一起探索云原生數倉解決方案,打造新一代開源 Data Cloud。
Databend Cloud:https://databend.cn
Databend 文檔:Databend
Wechat:Databend
GitHub:GitHub - datafuselabs/databend: 𝗗𝗮𝘁𝗮, 𝗔𝗻𝗮𝗹𝘆𝘁𝗶𝗰𝘀 & 𝗔𝗜. Modern alternative to Snowflake. Cost-effective and simple for massive-scale analytics. https://databend.com
)




詳細安裝和使用教程)







)
)




