3.5? HDFS存儲原理
?3.5.1 冗余數據保存
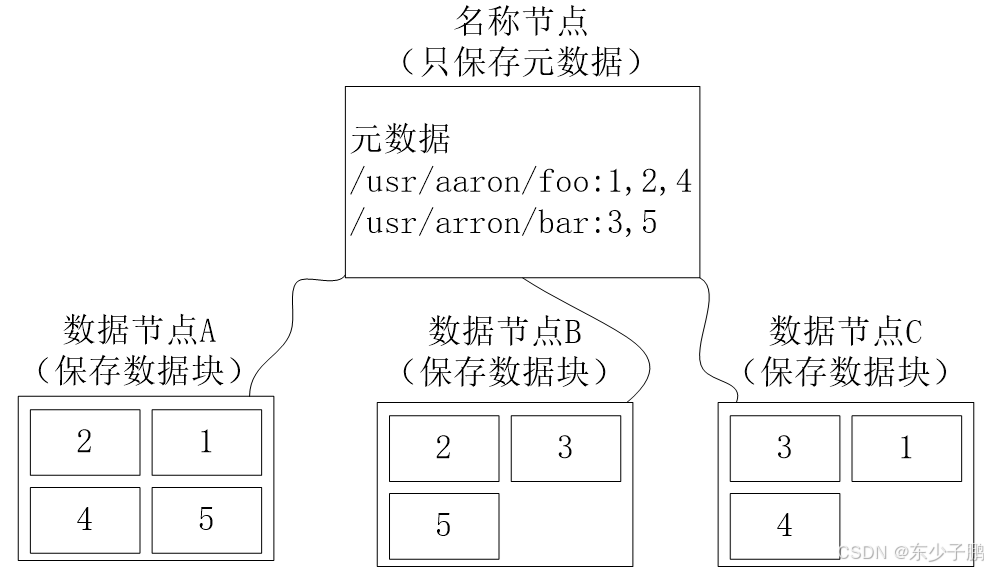
作為一個分布式文件系統,為了保證系統的容錯性和可用性,HDFS采用了多副本方式對數據進行冗余存儲,通常一個數據塊的多個副本會被分布到不同的數據節點上。
?
如圖所示,數據塊1被分別存放到數據節點A和C上,數據塊2被存放在數據節點A和B上。
這種多副本方式具有以下幾個優點:
(1)加快數據傳輸速度
(2)容易檢查數據錯誤
(3)保證數據可靠性
?3.5.2 數據存取策略
?1.數據存放
?第一個副本:放置在上傳文件的數據節點;如果是集群外提交,則隨機挑選一臺磁盤不太滿、CPU不太忙的節點
?第二個副本:放置在與第一個副本不同的機架的節點上
?第三個副本:與第一個副本相同機架的其他節點上
?更多副本:隨機節點
2. 數據讀取
?HDFS提供了一個API可以確定一個數據節點所屬的機架ID,客戶端也可以調用API獲取自己所屬的機架ID
?當客戶端讀取數據時,從名稱節點獲得數據塊不同副本的存放位置列表,列表中包含了副本所在的數據節點,可以調用API來確定客戶端和這些數據節點所屬的機架ID,當發現某個數據塊副本對應的機架ID和客戶端對應的機架ID相同時,就優先選擇該副本讀取數據,如果沒有發現,就隨機選擇一個副本讀取數據
3. 數據復制(采用流水線策略)
當客戶端需要向HDFS中寫入一個文件時,文件首先被寫入本地計算機。
(1)按照HDFS的設置被切分成一定大小的塊,具體大小由HDFS設置。
(2)每個塊都會向HDFS的NameNode節點發起寫請求。
(3)NameNode節點會根據系統中各個DataNode節點的使用情況,選擇一個合適的DataNode節點列表返回給客戶端。
(4)客戶端隨后會將數據首先寫入列表中的第一個DataNode節點,同時將列表傳給該節點。
3 數據復制(采用流水線策略)
(5)第一個DataNode節點在接收到一定數量的數據后,會向列表中的第二個DataNode節點發起連接請求,并把自己已經接收到的數據和列表傳給第二個節點。
(6)第二個節點在接收到數據后,也會向列表中的第三個節點發起連接請求。依此類推。這樣,列表中的多個DataNode節點形成了一條數據復制的流水線。
?3.5.3 數據錯誤與恢復
HDFS具有較高的容錯性,可以兼容廉價的硬件,它把硬件出錯看作一種常態,而不是異常,并設計了相應的機制檢測數據錯誤和進行自動恢復,主要包括以下幾種情形:
名稱節點保存了所有的元數據信息,其中,最核心的兩大數據結構是FsImage和Editlog,如果這兩個文件發生損壞,那么整個HDFS實例將失效。解決方案:
2. 數據節點出錯
3. 數據出錯

代碼實踐 -計算機視覺-47轉置卷積)

)



 框架)
首屏加載速度慢)





》)


神魔大陸|v0.51.0|冰火榮耀)
![[數據集][目標檢測]電力場景下電柜箱門把手檢測數據集VOC+YOLO格式1167張1類別](http://pic.xiahunao.cn/[數據集][目標檢測]電力場景下電柜箱門把手檢測數據集VOC+YOLO格式1167張1類別)
