文章目錄
- 引言
- 復習
- 二維背包問題——寵物小精靈之收服
- 個人實現
- 重大問題
- 滾動數組優化實現
- 新作
- 串聯所有單詞的字串
- 個人實現
- 參考實現
- 總結
引言
- 今天應該是舟車勞頓的一天,頭一次在機場刷題,不學習新的東西了,就復習一些之前學習的算法了。
復習
二維背包問題——寵物小精靈之收服
以往的分析鏈接
- 第一次分析
- 第二次分析

個人實現
- 這是第二次在做這道題,這是一個單純的二維背包問題,需要理清楚最后是要你輸出什么類型,先給20分鐘在開發網站上嘗試一下,然后在來具體分析。
#include <iostream>
#include <cstring>
#include <limits.h>using namespace std;const int N = 1010,M = 550,K = 110;// 其中的N表示的精靈球的數量,M是體力值,K是野生精靈的數量int nt[K],mt[K];
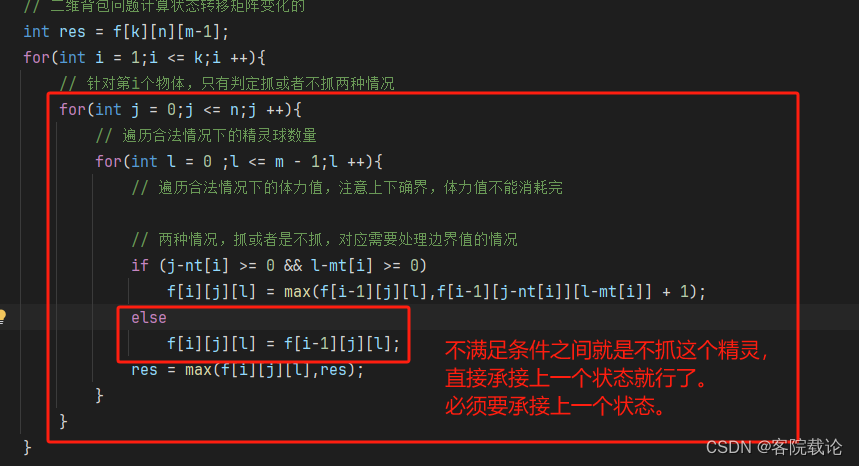
int f[K][N][M];int n,m,k;int main(){cin>>n>>m>>k;for(int i = 1;i <= k;i ++){cin>>nt[i]>>mt[i];}// 二維背包問題計算狀態轉移矩陣變化的int res = f[k][n][m-1];for(int i = 1;i <= k;i ++){// 針對第i個物體,只有判定抓或者不抓兩種情況for(int j = 0;j <= n;j ++){// 遍歷合法情況下的精靈球數量for(int l = 0 ;l <= m - 1;l ++){// 遍歷合法情況下的體力值,注意上下確界,體力值不能消耗完// 兩種情況,抓或者是不抓,對應需要處理邊界值的情況if (j-nt[i] >= 0 && l-mt[i] >= 0)f[i][j][l] = max(f[i-1][j][l],f[i-1][j-nt[i]][l-mt[i]] + 1);elsef[i][j][l] = f[i-1][j][l];res = max(f[i][j][l],res);}}}cout<<res<<" ";// 第二個維度進行判定for(int i = 1;i <= k;i ++) {// 針對第i個物體,只有判定抓或者不抓兩種情況for (int j = 1; j <= n; j++) {// 遍歷合法情況下的精靈球數量for (int l = 1; l <= m - 1; l++) {if (f[i][j][l] == 2)cout<<"("<<i<<","<<j<<","<<l<<"): "<<f[i][j][l]<<" "<<endl;}}}int cost_health = m;for(int i = 0;i < m;i ++){if(f[k][n][i] == res)cost_health = min(cost_health,i);}cout<<m - cost_health;
}重大問題
- 這里有一個重要的發現,就是就是如果使用原始的,不加滾動數組優化的,就得保證每一層之間都能夠將信息傳遞下來,不能因為不滿足條件,就直接跳過。
- 這個bug看了好久,才發現,中間是斷層的,之前的決策信息是沒有傳遞下來的,所以最后一行都是空的。
滾動數組優化實現
- 這里可以使用滾動數組進行優化實現,因為每一次都是從前往后遍歷,然后用的是之前的數據。如果使用從后往前遍歷,就不需要修改上一個數組了,這里講的有點模糊,有點混亂。這里直接看我之前的分析吧,具體如下
- 背包模板——采藥問題
- 設計公式推導,不過不重要,很好記:完全背包問題——買書
- 這個是公式推導的第二部分:完全背包問題——買書2
最終實現代碼如下
- 實現起來真簡單,不得不說,確實厲害!
#include <iostream>
#include <cstring>
#include <limits.h>using namespace std;const int N = 1010,M = 550,K = 110;// 其中的N表示的精靈球的數量,M是體力值,K是野生精靈的數量int nt[K],mt[K];
int f[N][M];int n,m,k;int main(){cin>>n>>m>>k;for(int i = 1;i <= k;i ++){cin>>nt[i]>>mt[i];}// 二維背包問題計算狀態轉移矩陣變化的for(int i = 1;i <= k;i ++){// 針對第i個物體,只有判定抓或者不抓兩種情況for(int j = n;j >= nt[i];j --){// 遍歷合法情況下的精靈球數量for(int l = m - 1 ;l >= mt[i];l --){f[j][l] = max(f[j][l],f[j-nt[i]][l-mt[i]] + 1);}}}int res = f[n][m-1];cout<<res<<" ";int cost_health = m;for(int i = 0;i < m;i ++){if(f[n][i] == res)cost_health = min(cost_health,i);}cout<<m - cost_health;
}
新作
串聯所有單詞的字串
- 題目鏈接


- 這題跳了好幾次,后面好幾題都做了,終于是他了,兩天做這道題。
重點
- words是由若干個子字符串構成的,然后可以按照任意順序進行拼接,形成n!個字符串,數量很大
- 每一個字符字串進行匹配查找拼接,這又是一個問題的。每個都是n平方的時間復雜度,根本做不了的。n平方 * n!,這個時間復雜度太高了。根本實現不了的!
- 可以在以下幾個地方做出精簡
- 掃描一次,然后記錄所有相同長度,但是起點不同但是長度相同的字符串,然后在按照集合進行比較?這樣確實能夠縮減時間復雜度。
- 嘗試使用不同的字符串進行優化?最長公共字串有用嗎?KMP算法?不得行!
- 這樣吧,匹配出每一個字符串在源字符串的位置,然后將源字符串標注為不同的序列,直接返回對應的序列即可。但是這里有一個問題的,就是這幾個 word之間會出現嵌套的問題嗎?如果出現嵌套問題就不好做了。
個人實現
- 字符串s重點長度為x的s.size() - x個子串中,和words中的每一個字符串進行匹配,然后進行標注。判定當前的字符串是相等的,過濾一遍的。記錄一下,每一個元素開始的位置,然后再向后進行遍歷,保證結果相同?
- 沒有辦法保證word和word之間是沒有重疊的,這種情況肯定會出現,這就不知道怎么處理了。
- 不想做了,今天好煩躁呀,還是直接看解說吧。
參考實現
-
這里參考的y總的代碼,基本思路還是很簡答的,關鍵是如何將問題進行拆解,和我的思路比較像,但是有兩個地方沒有想到
- 字符串的快速匹配可以使用hash實現,這里我并沒有考慮到,在我的設想里面只能使用遍歷實現
- 兩個字符字串的匹配使用兩個hash表配合滑動窗口實現的
-
具體思路分析圖如下
具體實現代碼如下
#include <iostream>
#include <unordered_map>
#include <vector>
using namespace std;vector<int> findSubstring(string s,vector<string >& words){vector<int> res;// 邊界條件判定為空if (words.empty()) return res;// 定義words的長度和word的長度,以及整個string的長度int n = s.size(),m = words.size(),w = words[0].size();// 定義目標子串中的對應的hash表unordered_map<string,int> tot;for (auto s:words) tot[s] ++;// 將待匹配的原始的字符串進行等距分割拼接for (int i = 0; i < w; ++i) {// 定義count記錄當前起點下的有效的字符子串的個數int cnt = 0;// 對每一個起點創建對應的字典字符串unordered_map<string,int> temp;for (int j = i; j < n; j += w) {// 如果長度大于滑動窗口的長度,需要彈出if (j >= i + m * w){// 已經超過了長度,需要彈出最初的元素auto st = s.substr(j - m * w,w);temp[st] --;// 判定彈出的元素是否有效if (temp[st] < tot[st]) cnt--;}// 需要往隊列中添加元素auto st = s.substr(j ,w);temp[st] ++;// 判定加入的元素是否有效if (temp[st] <= tot[st]) cnt ++;if (cnt == m) res.push_back(j - (m - 1)*w );}}return res;
}int main(){}
總結
-
剛到上海,總是有很多東西需要收拾,本來準備來實習的,結果的主管面還是把我拒了,確實沒有準備好呀,難受,現在就是單純來學習的了。心里悵然若失!不過無所謂了,先做著吧,盡力去做著吧。來了弄了蠻多家務的,昨天的都沒有交稿,脫了兩天,明天開始進入狀態了,調整一下,不能浪費時間!繼續卷吧!然后開始繼續弄的!
-
今天挫敗感還是滿足的,感覺坐立不安,怎么都不舒服。
- 換環境了?
- 沒找到實習
-
都有吧,好好干吧!
)











 - 可交換圖像文件)

this指針 常函數 常對象 靜態成員)
 函數來對圖像進行邊緣檢測,并顯示檢測到的邊緣特征)

是什么?2線,3線,4線原理)

