
?開篇
書接上文,在上文《談LORA微調與數據質量處理之爭》中我們詳細敘述了:LORA微調手段和數據清洗之分,以及如何平衡和組合使用LORA微調與數據清洗的手法。
文末我們提到了“下一篇我們講著重講述:在打造企業數據清洗工具、平臺和落地過程中又會遇到什么挑戰”。因此本篇就著重講企業數據清洗的架構與設計。
接著上文中這一個示意圖即:
理想中的AI RAG在召回企業原始數據、語義資料時的設想

實際我們面臨的問題和準備要采取的后續措施

在上文中我們提到了“補鏈”這個手段。
數據清洗就是“補鏈”
數據清洗就是“補”,的確,數據清洗不僅僅只是“去除重復的、無用的數據”,它主要包含著一堆的科學化、合理化的高科技組合手段。
手段很多,但是最最重要的手段有以下幾種,這些是在實際我們面臨企業原始數據通過embedding技術進入向量庫前必須要經歷的步驟,它們是:
- 原始段落折分(包括按行折、按段折);
- 語義合并(對于跨段落甚至跨頁同語義數據內容進行合并);
- 圖文組合(把圖和文組成一段進入向量庫);
- 重復內容去除(在合并或者折分時勢必遇到不少語句沖突或者重復的內容);
- 內容重寫(這塊逃不掉的,有些原始數據來自于一些非結構化數據很雜亂,你自己要重新組織);
- 內容擴寫(有些太簡單了,需要適當的加一些前綴、后綴);
- 翻譯(有些縮寫你肯定不能用或者是一些專用組織內用語);
- 糾錯(包括錯別字、有岐義的詞句甚至是原數據根本就寫錯了);
- 打標簽;
- 人工Review;
上述10步,必不可少,其實還有更多。
下面我們通過實例展開這10個點來看。
企業數據進入向量庫前的必備步驟詳細講解
原始段落折分
是按行折還是按段折?
為什么要按行?為什么要按段?
如果我說120個字一折分可以嗎?
我們就拿業界做的好的數據進向量庫以及可以召回的工具fastgpt的內部數據清洗工具來說,它提供了上述幾種折分手法。可是,我們仔細著想一下,這幾種折分方法哪一種最好呢?
都不好!
又
都好。
不好在哪
按行或者按段折,那下一段怎么辦?下一段內容和上一段是強關聯呢!你硬生生把它折開來后進向量庫時速度是快了,召回時體積也小了,可是語義上往往會造成嚴重的失真!
那按照120字、200字一折,那一句話正好有一個逗號甚至一句完整的語句正好被你來個“攔腰斬斷”,那這樣一折它造成的幻覺會更利害呢。
好在哪
簡單!直接PDF、ITEXT、PYTHON。。。等等等開發語言來了。。。好了,這又落進“Show技術”的坑里去了而忘記了技術的本質是為企業、為某一領域服務這一件事。
對,只有這個好處了!
什么是合理折分手法呢
按行、按段是沒錯。但是我們需要把一個語義歸攏在一段,再把這一段折出來,這樣就最好了。
帶來的問題
就拿歸攏成一段這件事來說甚至第一頁內容和第13頁內容是屬于一段的。那現在我假設給你一篇500頁的pdf文檔,作為進數據一環的數據清洗人員在面臨著這樣的工作量時豈不要瘋了?他要干活前還得看完全文呢?
但是呢,又必須這么干才合理,沒錯,你沒看錯,此時企業對數據清洗人員的素質、運營能力甚至是業務能力產生了很大的要求,這不又繞回了:這個東西門檻太高,不是一般企業可以玩得起的梗了嗎?
您別急,此處我們先放一放,后面我們會講解決辦法。
語義合并
它和段落折分很像,其中最大的一個問題在于需要數據清洗人員或者說是工具可以識別跨段、跨頁的語句屬于同一個語義,然后進行合并,對操作人員的要求很高。
比如說以下這個例子

它就不能作為兩段,而必須作為一段進行語義上的合并后才能進向量庫,它需要做成以下語義上的合并結果
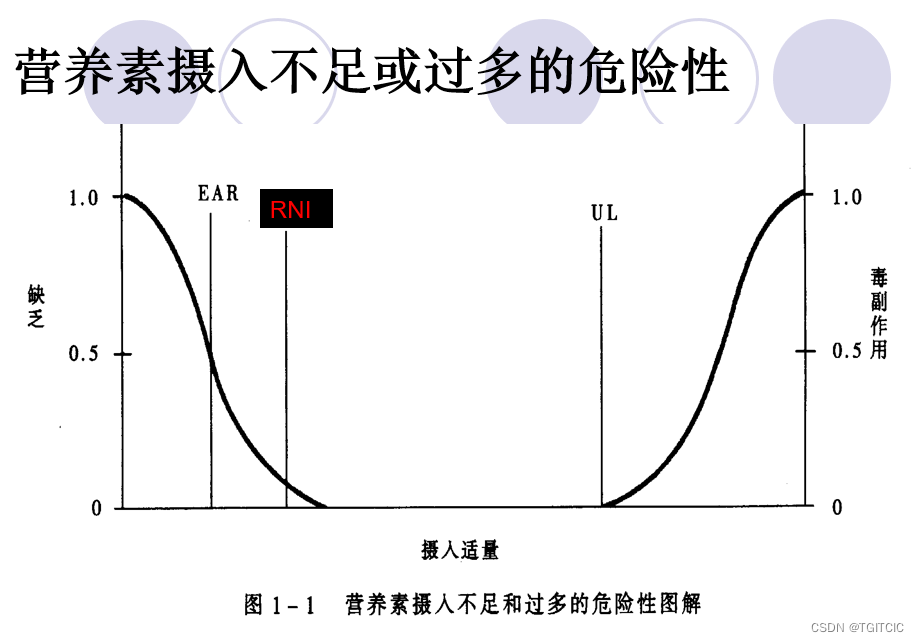
鉀在人體內/生理上的含量:鉀是體內重要陽離子之一;正常含量約250克,約占體重的0.2-0.3%。鉀主要存在于細胞內,約占總量的98%,其余在細胞外液。
我們看到了上述就是我們在語義上做的合并
圖文組合
看以下這個例子
?沒有經驗的人會告訴我這么做:
- 使用AI工具或者是截圖工具把圖片提取出來;
- 使用AI工具或者是截圖工具把文字提取出來;
- 然后把圖和文變成一段;
- 然后進向量庫;
沒錯,是這4步,你1步都少不了。但是這個工作量是很大的,一個500頁PDF的文檔,其中有277張圖文混排的,你怎么辦?你知道要操作幾步?你知道需要花費多少時間?
這還只是一個會使用AI工具的人能夠做的,如果碰到圖片有水印怎么辦?
能怎么辦呢?
打開PS。。。

下面就不多說了。。。
重復內容去除
有些文檔每一頁都有子標題,甚至是孫子標題,當跨頁合成一段內容時,你總得把這些“重復的段落標記”給去除掉吧?要不然到了召回后交由LLM這一步,出現幻覺的機率會更大。
這里面會涉及到一些手工的活。
內容重寫
比如說下面這一例子

沒經驗的人開動python、開動itext、開動ocr,3段內容。。。夸夸夸。。。進向量庫了。。。那叫一個爽啊。
可是進完數據后呢?這3段代表什么意思呢?
于是這時就需要重寫了,需要重寫成以下這樣
水缺乏分:1)高滲性脫水 2)低滲性脫水 3)等滲性脫水試想如果不加思索一味只靠“數據跑批”、“各種技術”把上述3句話喂入LLM然后在召回時AI會怎么回答?

內容擴寫
還是拿上例繼續說,“水缺乏分哪些”其中有一項叫“等滲性脫水”。
那么這個名詞給到有專業知識的醫生、護理人員是看得懂的。但如果你在做一個“家庭醫療百科”時,就這么一個“等滲性脫水”告訴使用者,這就叫完事了?
你必須要把它擴展開來
等滲性脫水是指體內水分和電解質(主要是鈉)按正常比例丟失,導致體液的滲透壓保持不變的一種脫水類型。等滲性脫水通常發生在急性腹瀉、嘔吐或大量出汗的情況下。由于水和鈉的丟失比例相同,血清鈉濃度通常保持在正常范圍內。
等滲性脫水的主要癥狀包括:
口渴
皮膚干燥
尿量減少
乏力
頭暈
治療等滲性脫水的關鍵是補充等滲液體,如口服補液鹽(ORS)或靜脈輸注生理鹽水,以恢復體內的水和電解質平衡。這就是擴寫。
翻譯
來看實例

兄弟,這一段你要是直接進入語料庫了后,這樂子就大了。
AI!
我們正在寫AI類的相關文章。。。AI!!!這。。。
其實它在整篇文章里的這個AI代表的是什么意思知道嗎?
Adequate Intake - 適意攝入量糾錯
任何企業的原始資料都存在錯誤,這里面如果只是錯別字還算好的。更重要的在于知識內容或者是信息因為數據收集、整理到進入向量庫時當中的這個時間差造成了信息上的誤解。
我們碰到過一個例子,就是一家連鎖超市,某一個重要區域的聯系電話因為有15天的時間差,電話號碼已經更換了。
而進數據的人員沒有注意到這個問題,結果導致了客戶打這個售后的電話回答他這個電話是一個廢品回收站電話。

這得造成多大的誤解呢!
打標簽
拿“減肥”這個事來作例子。
各年齡段、性別、身高、體重、目標體重、每日活動頻率都會決定著BMR或者是每天應該控制的攝入的卡路里的量不同。
現在假設有10條數據,涉及BMR、卡路里的。如果不分類的一股腦的進入了向量庫,那么這個AI產品在回答或者是計算BMR或者是每天攝入量時是偏差很大的,也是不準的,這將對企業自身的服務質量形成極不好的口碑呢。
因此,就需要在每一條記錄前打上類似這樣的標簽
0-3歲段-男性-飲食:正文
4-8歲段-學齡前-飲食:正文
9-14歲-飲食:正文
15-18歲-青少年段-飲食:正文
這樣的標簽。這就叫打標簽。
人工Review
這步逃不掉的,一般做企業AI類項目,這個語料在最后進入訓練(即:通過embedding技術進入向量庫的過程)都需要有業務專家做人工校正和Review,甚至在運營的過程中會比較高頻次的不斷的做校正和Review,這個過程會伴隨著這個項目的整個生命周期。
步驟之多、技術含量之高足以讓一般企業對AI類項目望而卻步
我們看看上面說的,這10步是必須步驟,少一步企業的數據在經過AI后會產生各種千奇百怪的問題。輕則被人當個笑話看、重則會造成企業的聲譽和口碑受到嚴重影響。
因此從企業角色出發,對于數據清洗充滿了挑戰,其中之一就是成本和人力資源問題。
我們可以注意到上述的過程我不是基于傳統的洗數據來論述這10點的,而是基于IT技術的輔助下才能做這10步的,可以這么說,一個高級運營+一個大數據團隊都不一定干得了上述10件事。
這又繞回了AI落地難啊難,光做數據清理就得付出很大的成本。
這的確是一個讓現在企業很頭疼的問題。
為了數據質量付出的成本一點不低,還挺高昂
這些步驟我們把它們平鋪在一個平面上,就可以發覺有多“累”了。
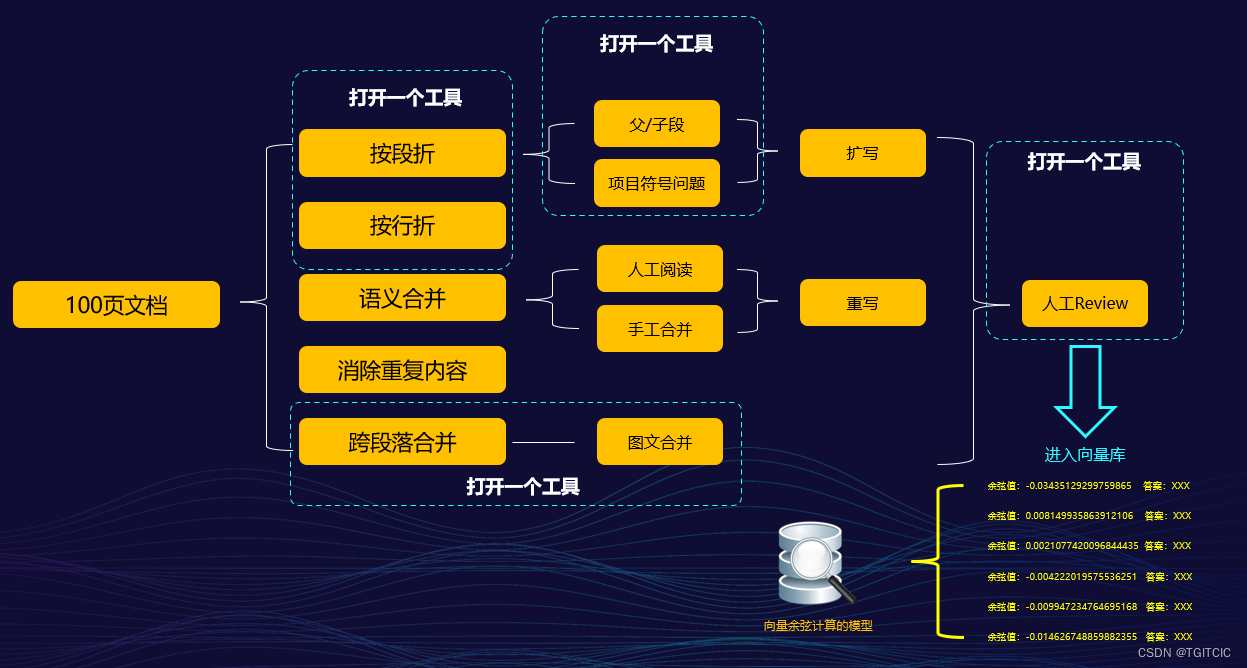
如果用AI工具來輔助數據清洗就一定可以解決嗎
答案是:不會,沒有這么簡單!
在進入AI時代后我們對一些步驟采用“AI時代的技術賦能運營”來做這件事。
我們可以看到,就算使用AI工具,一個人在完成上述100頁的原始數據清理時至少需要同時在4個工具間來回切換。
哪四個工具呀?
- word
- ps
- 一個OCR或者是讓IT團隊做一個小系統或者用AI識圖工具
- AI作文工具
嗯,的確有了AI工具后比原來效率是提高了不少,但是這還是沒有擺脫“要做此工種的人門檻太高,一般企業負擔不起”的這么一個坎。
而且實際企業運營時不止只有100頁,而是有上千*100頁的文檔時,大家一起來瞧,這件事會變成什么樣的工作量呢?

這是一件很恐怖的事!
到現在為止,大家都知道數據清洗肯定是可以產生可觀的結果的,但是它太累人了、對企業的運營團隊、IT團隊來說門檻還是太高。
提出解決方法
我記得我在前面的博客《AI落地不容樂觀-從神話到現實》這一篇中講到過:
即一個AI項目要成為剛需必須具備:
原來需要一群月薪老老高的大牛,在一個月里可以做出來的事。用了AI可以用一堆菜鳥在1周內就可以完成同樣質量的事。
于是,就有了這么一個公式,你的業務如果用AI去落地后可以滿足以下這個公式,這個AI項目就會變得極有價值即我們假設一個大牛的成本為X,一個菜鳥的成本為Y,原先不用AI一件工作的交付時間為A,質量為Q有以下公式:
??? 成本上:3*Y<X;
??? 交付時間:<=A;
??? 交付質量:=Q
如果你的企業做一個項目依舊沒有到達上述這個目標,我相信這個項目對企業來說只會變成這么樣的一件事:
我付了錢、多了事、沒有解決根本問題
變成這么一個“坑”。
這是企業的運營負責人或者是經營者們所不能接受的一件事。
必須使用超級個體的理念賦能企業
AI時代,如何賦能個體的,我們都知道了。但是“你只有一個人,你渾身是鐵能打幾個釘”?,我們把目光放到賦能個體變成超級個體來同樣轉換到企業身上如何賦能?
再說白了點,讓企業可以使用甚至比原來更低的成本、更高的效率獲得同等甚至高于(一般來說是高于的)人肉+工具取得的數據清洗質量呢?
真正為企業賦能,把超級個體的能力賦能企業業務部門
于是我和我現在的團隊想到了這么一個設計。
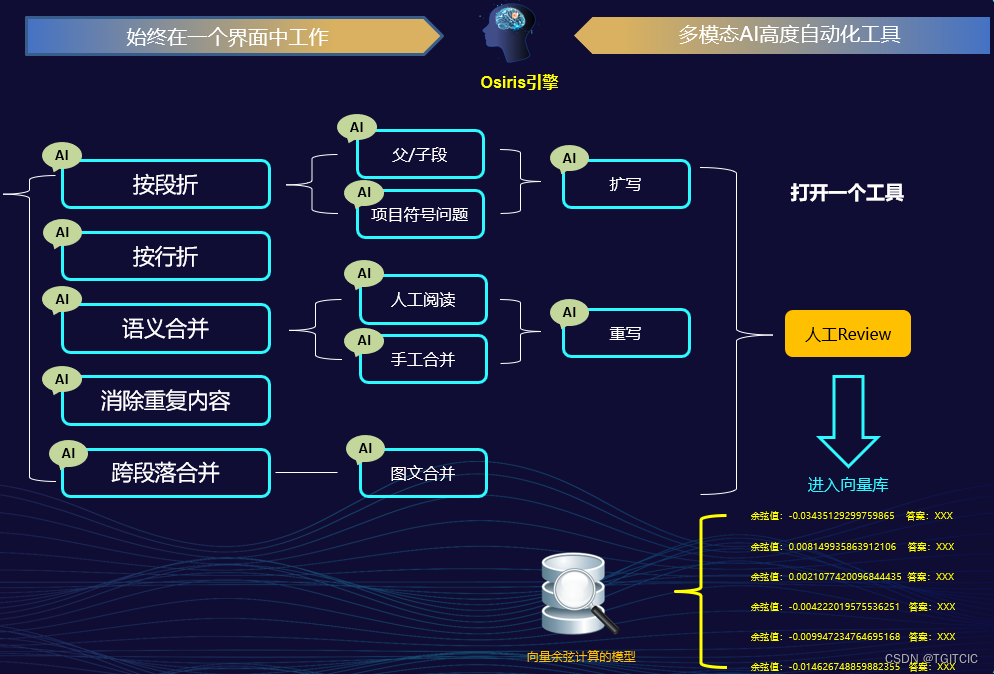
我們把來回切換工具(哪怕就在2個工具間切換)造成的工作上的“上下文不連貫”甚至失真全部用AI銜接起來,讓上述這10步在:一個工具、一個界面里完成。并且把上述這些折分、去重啦、翻譯啦、組合啦、擴寫啦的經驗內置成AI模板,到了企業業務部門的運營人員手中變成了:一個點擊、兩次點擊+一個ctrl c即可以完成的事。
這樣做可以把工作的效率極大的提升,同時可以極大程度降低企業清洗數據人員的門檻真正做到“打造超級體”的目的。
于是,在我們的手里誕生了這么一個東西:

我們內部給它定義名稱為:Osiris即:荷魯斯引擎。
- 注:Osiris是植物、農業和豐饒之神,赫里奧波里斯-九柱神之一 。
理念是美好的,但現實又如何。
超級工具的誕生和效果
這個工具我們把它做成了一體化工具,它打開后的界面不復雜,但是它可以讓一個運營人員在完成上述10大數據清洗必備步驟時完全在一個界面并且是連貫的操作。同時它蘊含著我們這1年多來總結的那些方法論化成了:簡單的一次點擊和ctrl + c 、ctrl + v操作中。
于是我們使用剛畢業的大學生來做實驗,我們給了他一份170頁左右的PDF文檔、醫療類的、高專業性。對這10個方法就像我寫博客一樣寫了這10步(還沒有我寫的博客這么詳細),以及需要注意什么。
然后他在2天不到的時間(并未有加班的現象)即完成了高質量的embedding數據了。
對比我自己,我們因為是工作室模式因此團隊不大每個人都是超級個體。我自己也經常要參與語料和數據清洗工作,如果換了我以前面對這種上百頁PDF、PPT我結合著AI自動化工具零零碎碎的使用(我手還挺快)也得要5個工作日(每個工作日8小時耗滿),這還只能處理100頁左右的文檔成高質量的語料。
而使用了我們自己開發的這個一體化工具后,一個基本沒有什么經驗的畢業生經過1小時培訓和2小時自我閱讀教程就完成了我一周的工作量。此時我們就知道這個工具有多好用了。
為什么用了一體化工具后效率會這么高呢?
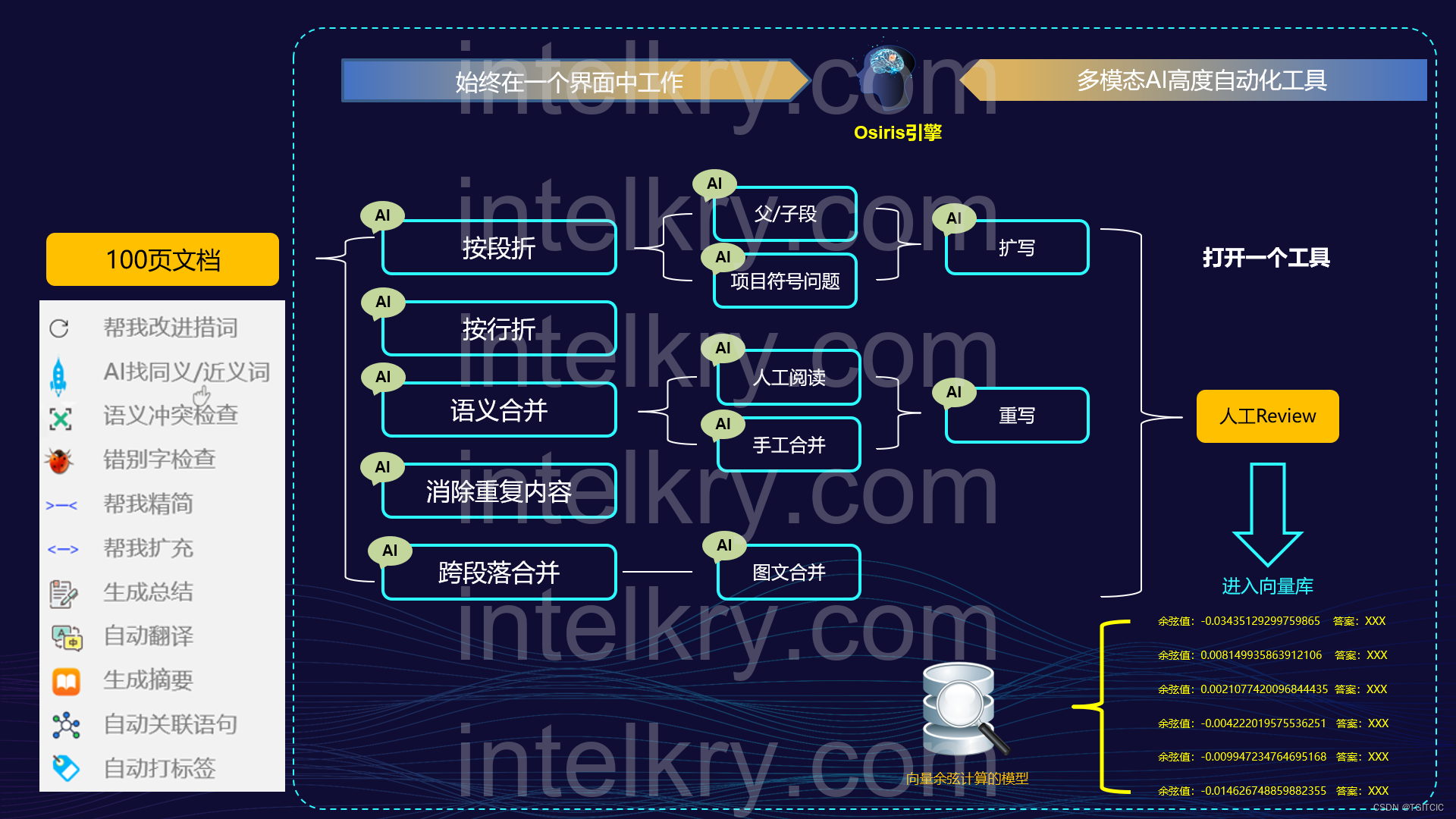
因為上述這些步驟在一體化工具使用時它變成了這么樣的一種工作流了。
我們可以看到,其實人肉在這里面只是起到了一個事后Review的工作。而這一步是無論你使用什么工具都逃不掉的一步。
所以我們通過不斷的使用這個工具采集到了一個指標,即:使用我們自己的這個Osiris引擎后它平均到達了我之前博客說到的:90%+提高AI回答精準性的要求,事實上是遠超這個指標了。
所以,這就是我在之前博客中所說的,要實現:
原來需要一群月薪老老高的大牛,在一個月里可以做出來的事。用了AI可以用一堆菜鳥在1周內就可以完成同樣質量的事。
于是,就有了這么一個公式,你的業務如果用AI去落地后可以滿足以下這個公式,這個AI項目就會變得極有價值即我們假設一個大牛的成本為X,一個菜鳥的成本為Y,原先不用AI一件工作的交付時間為A,質量為Q有以下公式:
??? 成本上:3*Y<X;
??? 交付時間:<=A;
??? 交付質量:=Q
這么一個公式,僅僅靠AIGC是不可能完成的,你必須依靠的是:使用AI在如何打造超級個體、賦能個體同樣的步驟、理念打包成一個工具然后用這個工具、平臺去賦能企業才能成功。
結語
數據清理非常重要,數據清理并非只是依靠單個工具。而它是一個體系化的理論+工具的組合。
技術的終極目標就是普惠大眾,如何把先進的理念、業務運營知識、工具的使用變成可以以“一鍵式”賦能大眾和企業,一旦我們在平時做事時以這樣的理念為目標時何愁做不出來好的AI產品呢?
朋友們,未來已到!讓我們動起手來,把心里那些美好的點子和理念化作持續的行動來為祖國的AI事業一起添磚加瓦吧。
后續篇章中我會深入介紹Osiris的引擎,并且以Osiris引擎實際操作來展示什么叫“超級智能體”。
好了,結束今天的篇章。








 熟悉ArkUI)







![[面試題]計算機網絡](http://pic.xiahunao.cn/[面試題]計算機網絡)



