Java web應用性能分析之【系統監控工具prometheus】_javaweb服務器性能監控工具-CSDN博客
Java web應用性能分析之【prometheus+Grafana監控springboot服務和服務器監控】_grafana 導入 prometheus-CSDN博客
????????因為篇幅原因,前面沒有詳細說明Prometheus的監控指標,這里就拿出來單獨說明。主要是從Exporter對linux服務器、k8s節點、以及常用的exporter、node進行說明,這些都是通用的監控。后面會單獨說明自定義監控指標,自定義的主要是結合業務特色進行監控。
Prometheus組件構成簡介
????????Prometheus是一個開源的監控和告警工具包,其常用的組件主要包括以下幾個部分:
- Prometheus Server
- 功能:Prometheus Server是Prometheus的核心組件,負責定時從被監控組件(如Kubernetes、Docker、主機等)中拉取(pull)數據,并將其存儲在本地的時間序列數據庫中。它還提供了靈活的查詢語言(PromQL)來查詢和分析這些數據。
- 數據存儲:Prometheus Server本身就是一個時序數據庫,將采集到的監控數據按照時間序列的方式存儲在本地磁盤當中。
- 服務發現:Prometheus Server支持多種服務發現機制,如文件、DNS、Consul、Kubernetes等,可以動態地管理監控目標。
- Web UI:Prometheus Server內置了一個Web UI,通過這個UI可以直接通過PromQL實現數據的查詢以及可視化。
- Exporters
- 功能:Exporters是一組工具,用于將那些本身不支持直接暴露監控指標的應用程序或服務的指標數據轉換為Prometheus可以抓取的格式。
- 常見類型:例如,Node Exporter用于收集機器級別的指標(如CPU、內存、磁盤使用情況等),而MySQL Exporter則用于收集MySQL數據庫的指標數據。其他常見的Exporter還包括Blackbox Exporter(用于網絡探測)、Process Exporter(用于監控進程狀態)等。
- Client Libraries
- 功能:Client Libraries提供了在應用程序中實現自定義指標的方式。這些庫支持多種編程語言(如Go、Java、Python等),使得開發者可以輕松地在自己的應用中添加和暴露自定義的Prometheus指標。
- 使用場景:當開發者需要在自己的應用程序中實現更細粒度的監控時,可以使用Client Libraries來定義和暴露自定義的監控指標。
- Pushgateway(生產環境必須組件)
- 功能:Pushgateway是一個可選的組件(生產環境必須組件,很多時候服務器上監控網絡),用于接收由短期作業或批處理作業生成的指標數據,并允許Prometheus Server從Pushgateway中拉取這些數據。
- 使用場景:當某些作業或服務由于網絡限制或其他原因無法直接被Prometd heus Server訪問時,可以使用Pushgateway作為中間緩存he 層來收集和轉發這些指標數據。
- Alertmanager
- 功能:Alertmanager是Prometheus的告警管理工具,負責處理由Prometheus規則生成的警報,并將其發送給指定的接收者(如郵件、PagerDuty等)。
- 告警處理:Alertmanager支持對告警進行去重、分組和路由配置,以便將不同類型的告警發送給不同的接收者。此外,它還支持告警的沉默和抑制功能,以減少不必要的告警噪音。
- Grafana(可選組件)
- 功能:Grafana是一個開源的數據可視化和監控平臺,可以與Prometheus無縫集成,提供豐富的圖表和儀表盤來展示Prometheus存儲的監控數據。
- 使用場景:當用戶需要更直觀地查看和分析監控數據時,可以使用Grafana來創建自定義的圖表和儀表盤。Grafana支持多種數據源和插件擴展,可以滿足各種復雜的監控需求。
????????這些組件共同構成了Prometheus的完整監控和告警解決方案,使得用戶可以方便地收集、存儲、查詢和處理各種監控數據。
Prometheus指標類型
????????對于由許多組件組成的現代動態系統,云原生基金會(CNCF)中的項目Prometheus已經成為最受歡迎的開源監控軟件,并有效地成為指標監控的行業標準。Prometheus定義了一個度量說明格式和一個遠程寫入協議,社區和許多供應商都采用這個協議來說明和收集度量成為事實上的標準。OpenMetrics是另一個CNCF項目,它建立在Prometheus導出格式的基礎上,為收集度量標準提供了一個與廠商無關的標準化模型,旨在成為互聯網工程任務組(IEFT)的一部分。
????????Prometheus四種主要的指標類型包括Counter、Gauge、Histogram和Summary,以及相應的PromQL實例如下:(需要注意的是,以上PromQL實例僅供參考,實際使用時需要根據具體的指標名稱、標簽和查詢需求進行調整。同時,由于Prometheus查詢語言的復雜性和多樣性,還有很多其他的查詢方式和技巧可以探索和學習。)
????????Prometheus使用拉取模型來收集這些指標;也就是說,Prometheus主動抓取暴露指標的HTTP端點。這些端點可以是由被監控的組件自然暴露,也可以通過社區建立的數百個Prometheus導出器之一暴露出來。Prometheus提供了不同編程語言的客戶端庫,你可以用它來監控你的代碼。
????????由于服務發現機制和集群內的共享網絡訪問,拉取模型在監控Kubernetes集群時效果很好,但用Prometheus監控動態的虛擬機集群、AWS Fargate容器或Lambda函數就比較困難了。
????????為什么呢?主要原因是交易確定要抓取的指標端點,而且對這些端點的訪問可能受到網絡安全策略的限制。為了解決其中的一些問題,社區在2021年底發布了Prometheus Agent Mode,它只收集指標并使用遠程寫入協議將其發送到監控后端。
????????Prometheus可以抓取Prometheus暴露格式和OpenMetrics格式的指標。在這兩種情況下,指標通過HTTP接口暴露,使用簡單的基于文本的格式(更常用和廣泛支持)或更有效和強大的Protobuf格式。文本格式的一大優勢是它的可讀性,這意味著你可以在瀏覽器中打開它或使用像curl這樣的工具來檢索當前暴露的指標集。
????????Prometheus使用一個非常簡單的指標模型,有四種指標類型,只在客戶端SDK中支持。所有的指標類型都是用一種數據類型或由多個單一數據類型的組合在暴露格式中表示。這個數據類型包括一個指標名稱、一組標簽和一個浮點數。時間戳是由監控后端(例如Prometheus)或代理在抓取指標時添加的。
????????指標名稱和標簽集的每個唯一組合定義了一條時間序列,而每個時間戳和浮點數定義了一個系列中的樣本(即一個數據點)。
-
Counter(計數器)
- 作用:只增不減的計數器,常用于記錄請求次數、任務完成數、錯誤發生次數等。重啟進程后,計數會被重置。
- PromQL實例:假設我們有一個HTTP請求次數的Counter類型指標
http_requests_total,我們想要查詢最近一小時內增長最快的10個HTTP請求路徑:
-
promql`topk(10, delta(http_requests_total[1h]))`
????????Counter類型指標被用于單調增加的測量結果。因此它們總是累積的數值,值只能上升。唯一的例外是Counter重啟,在這種情況下,它的值會被重置為零。
????????Counter的實際值通常本身并不十分有用。一個計數器的值經常被用來計算兩個時間戳之間的delta或者隨時間變化的速率。
????????例如,Counter的一個典型用例是記錄API調用次數,這是一個總是會增加的測量值。
#?HELP?http_requests_total?Total?number?of?http?api?requests# TYPE http_requests_total counterhttp_requests_total{api="add_product"} 4633433
????????指標名稱是http_requests_total,它有一個名為api的標簽,值為add_product,Counter的值為4633433。這意味著自從上次服務啟動或Counter重置以來,add_product的API已經被調用了4633433次。按照慣例,Counter類型的指標通常以_total為后綴。
????????這個絕對數字并沒有給我們提供多少信息,但當與PromQL的rate函數(或其他監控后端的類似函數)一起使用時,它可以幫助我們了解該API每秒收到的請求數。下面的PromQL查詢計算了過去5分鐘內每秒的平均請求數。
rate(http_requests_total{api="add_product"}[5m])????????為了計算一段時期內的絕對變化,我們將使用delta函數,在PromQL中稱為increate():
increase(http_requests_total{api="add_product"}[5m])????????這將返回過去5分鐘內的總請求數,這相當于用每秒的速率乘以間隔時間的秒數(在我們的例子中是5分鐘):
rate(http_requests_total{api="add_product"}[5m]) * 5 * 60????????其他你可能會使用Counter類型指標的例子:測量電子商務網站的訂單數量,在網絡接口上發送和接收的字節數,或者應用程序中的錯誤數量。如果它是一個會一直上升的指標,那么就使用一個Counter。
????????下面是一個例子,說明如何使用Prometheus客戶端庫在Python中創建和增加一個計數器指標:
from?prometheus_client?import?Counterapi_requests_counter = Counter('http_requests_total','Total number of http api requests',['api'])api_requests_counter.labels(api='add_product').inc()
????????需要注意的是,由于Counter可以被重置為零,你要確保你用來存儲和查詢指標的后端能夠支持這種情況,并且在Counter重啟的情況下仍然提供準確的結果。Prometheus和兼容PromQL的Prometheus遠程存儲系統,如Promscale,可以正確處理Counter重啟。
-
Gauge(儀表)
- 作用:反映系統的當前狀態,樣本數據可增可減。常用于表示CPU使用率、內存使用率、磁盤空間使用率等。
- PromQL實例:如果我們想要查詢當前系統中CPU使用率最高的前三個節點:
promql`topk(3, 100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100))`
????????Gauge指標用于可以任意增加或減少的測量。這是你可能更熟悉的指標類型,因為即使沒有經過額外處理的實際值也是有意義的,它們經常被使用到。例如,測量溫度、CPU和內存使用的指標,或者隊列的大小都是Gauge。
????????例如,為了測量一臺主機的內存使用情況,我們可以使用一個Gauge指標,比如:
#?HELP?node_memory_used_bytes?Total?memory?used?in?the?node?in?bytes# TYPE node_memory_used_bytes gaugenode_memory_used_bytes{hostname="host1.domain.com"} 943348382
????????上面的指標表明,在測量時,節點host1.domain.com使用的內存約為900 MB。該指標的值是有意義的,不需要任何額外的計算,因為它告訴我們該節點上消耗了多少內存。
????????與使用Counter指標時不同,rate和delta函數對Gauge沒有意義。然而,計算特定時間序列的平均數、最大值、最小值或百分比的函數經常與Gauge一起使用。在Prometheus中,這些函數的名稱是avg_over_time、max_over_time、min_over_time和quantile_over_time。要計算過去10分鐘內在host1.domain.com上使用的平均內存,你可以這樣做:
avg_over_time(node_memory_used_bytes{hostname="host1.domain.com"}[10m])????????要使用Prometheus客戶端庫在Python中創建一個Gauge指標,你可以這樣做:
from?prometheus_client?import?Gaugememory_used = Gauge('node_memory_used_bytes','Total memory used in the node in bytes',['hostname'])memory_used.labels(hostname='host1.domain.com').set(943348382)
-
Histogram(直方圖)
- 作用:表示樣本數據的分布情況,通常用于統計請求的耗時、大小等。它提供了多個時間序列,包括_sum(總和)、_count(總數)以及多個_bucket(分桶統計)。
- PromQL實例:假設我們有一個請求耗時的Histogram類型指標
http_request_duration_seconds,我們想要查詢請求耗時在0.5秒到1秒之間的請求次數:
promql`histogram_quantile(0.95, sum(rate(http_request_duration_seconds_bucket{le="1"}[5m])) by (le)) - histogram_quantile(0.95, sum(rate(http_request_duration_seconds_bucket{le="0.5"}[5m])) by (le))`注意:這個查詢可能并不準確,因為Histogram類型不直接提供區間內的計數,而是通過累計的方式來表示分布。在實際應用中,我們更常用的是查詢某個分位數的請求耗時,如95%的請求耗時在多少以內。
????????Histogram指標對于表示測量的分布很有用。它們經常被用來測量請求持續時間或響應大小。
????????直方圖將整個測量范圍劃分為一組區間,稱為桶,并計算每個桶中有多少測量值。
????????一個直方圖指標包括幾個項目:
-
????????一個包含測量次數的Counter。指標名稱使用_count后綴。
-
????????一個包含所有測量值之和的Counter。指標名稱使用_sum后綴。
-
????????直方圖桶被暴露為一系列的Counter,使用指標名稱的后綴_bucket和表示桶的上限的le label。Prometheus中的桶是包含桶的邊界的,即一個上限為N的桶(即le label)包括所有數值小于或等于N的數據點。
????????例如,測量運行在host1.domain.com實例上的add_productAPI端點實例的響應時間的Histogram指標可以表示為:
#?HELP?http_request_duration_seconds?Api?requests?response?time?in?seconds# TYPE http_request_duration_seconds histogramhttp_request_duration_seconds_sum{api="add_product" instance="host1.domain.com"} 8953.332http_request_duration_seconds_count{api="add_product" instance="host1.domain.com"} 27892http_request_duration_seconds_bucket{api="add_product" instance="host1.domain.com" le="0"}http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.01"} 0http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.025"} 8http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.05"} 1672http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.1"} 8954http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.25"} 14251http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.5"} 24101http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="1"} 26351http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="2.5"} 27534http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="5"} 27814http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="10"} 27881http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="25"} 27890http_request_duration_seconds_bucket{api="add_product",?instance="host1.domain.com",?le="+Inf"}?27892
????????上面的例子包括sum、counter和12個桶。sum和counter可以用來計算一個測量值隨時間變化的平均值。在PromQL中,過去5分鐘的平均請求響應時間可以通過如下方式計算得到。
rate(http_request_duration_seconds_sum{api="add_product", instance="host1.domain.com"}[5m]) / rate(http_request_duration_seconds_count{api="add_product", instance="host1.domain.com"}[5m])????????它也可以被用來計算各時間序列的平均數。下面的PromQL查詢將計算出所有API和實例在過去5分鐘內的平均請求響應時間。
sum(rate(http_request_duration_seconds_sum[5m])) / sum(rate(http_request_duration_seconds_count[5m]))????????利用Histogram,你可以在查詢時計算單個時間序列以及多個時間序列的百分位。在PromQL中,我們將使用histogram_quantile函數。Prometheus使用分位數而不是百分位數。它們本質上是一樣的,但是以0到1的比例表示的,而百分位數是以0到100的比例表示的。要計算在host1.domain.com上運行的add_product API響應時間的第99百分位數(0.99四分位數),你可以使用以下查詢。
histogram_quantile(0.99,?rate(http_request_duration_seconds_bucket{api="add_product",?instance="host1.domain.com"}[5m]))????????Histograms的一大優勢是可以進行匯總。下面的查詢返回所有API和實例的響應時間的第99個百分點?:
histogram_quantile(0.99,?sum?by?(le)?(rate(http_request_duration_seconds_bucket[5m])))????????在云原生環境中,通常有許多相同組件的多個實例在運行,能否跨實例匯總數據是關鍵。
????????Histograms有三個主要的缺點:
-
????????首先,桶必須是預定義的,這需要一些前期的設計。
????????如果你的桶沒有被很好地定義,你可能無法計算出你需要的百分比,或者會消耗不必要的資源。例如,如果你有一個總是需要超過一秒鐘的API,那么擁有上限(le label)小于一秒鐘的桶將是無用的,只會消耗監控后端服務器的計算和存儲資源。另一方面,如果99.9%的API請求耗時少于50毫秒,那么擁有一個上限為100毫秒的初始桶將無法讓你準確測量API的性能。
-
????????第二,他們提供的是近似的百分位數,而不是精確的百分位數。
????????這通常沒什么問題,只要你的桶被設計為提供具有合理準確性的結果。
-
????????第三,由于百分位數需要在服務器端計算,當有大量數據需要處理時,它們的計算成本會非常高。
????????在Prometheus中減輕這種情況的一個方法是使用錄制規則來預先計算所需的百分位數。
????????下面的例子顯示了如何使用Prometheus的Python客戶端庫創建一個帶有自定義桶的直方圖指標。
from?prometheus_client?import?Histogramapi_request_duration = Histogram(name='http_request_duration_seconds',documentation='Api requests response time in seconds',labelnames=['api', 'instance'],buckets=(0.01, 0.025, 0.05, 0.1, 0.25, 0.5, 1, 2.5, 5, 10, 25 ))api_request_duration.labels(api='add_product',instance='host1.domain.com').observe(0.3672)
-
Summary(摘要)
- 作用:類似于Histogram,但更注重于分位數的計算。它同樣提供了_sum、_count以及多個quantile(分位數)。
- PromQL實例:假設我們有一個請求耗時的Summary類型指標
http_request_duration_seconds,我們想要查詢95%分位數的請求耗時:
promql`http_request_duration_seconds{quantile="0.95"}`
????????像直方圖一樣,Summary指標對于測量請求持續時間和響應體大小很有用。
????????像直方圖一樣,匯總度量對于測量請求持續時間和響應大小很有用。
????????一個Summary指標包括這些指標:
-
????????一個包含總測量次數的Counter。指標名稱使用_count后綴。
-
????????一個包含所有測量值之和的Counter。指標名稱使用_sum后綴。可以選擇使用帶有分位數標簽的指標名稱,來暴露一些測量值的分位數指標。由于你不希望這些量值是從應用程序運行的整個時間內測得的,Prometheus客戶端庫通常會使用流式的分位值,這些分位值是在一個滑動的(通常是可配置的)時間窗口上計算得到的。
????????例如,測量在host1.domain.com上運行的add_productAPI端點實例的響應時間的Summary指標可以表示為:
#?HELP?http_request_duration_seconds?Api?requests?response?time?in?seconds# TYPE http_request_duration_seconds summaryhttp_request_duration_seconds_sum{api="add_product" instance="host1.domain.com"} 8953.332http_request_duration_seconds_count{api="add_product" instance="host1.domain.com"} 27892http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0"}http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0.5"} 0.232227334http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0.90"} 0.821139321http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0.95"} 1.528948804http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0.99"} 2.829188272http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="1"} 34.283829292
????????上面這個例子包括總和和計數以及五個分位數。分位數0相當于最小值,分位數1相當于最大值。分位數0.5是中位數,分位數0.90、0.95和0.99相當于在host1.domain.com上運行的add_product API端點響應時間的第90、95和99個百分位。
????????像直方圖一樣,Summary指標包括總和和計數,可用于計算隨時間的平均值以及不同時間序列的平均值。
????????Summary提供了比Histogram更精確的百分位計算結果,但這些百分位有三個主要缺點:
-
????????首先,客戶端計算百分位是很昂貴的。這是因為客戶端庫必須保持一個有序的數據點列表,以進行這種計算。在Prometheus SDK中的實現限制了內存中保留和排序的數據點的數量,這降低了準確性以換取效率的提高。注意,并非所有的Prometheus客戶端庫都支持匯總指標中的量值。例如,Python SDK就不支持。
-
????????第二,你要查詢的量值必須由客戶端預先定義。只有那些已經提供了指標的量值才能通過查詢返回。沒有辦法在查詢時計算其他百分位。增加一個新的百分位指標需要修改代碼,該指標才可以被使用。
-
????????第三,也是最重要的一點,不可能把多個Summary指標進行聚合計算。這使得它們對動態現代系統中的大多數用例毫無用處,在這些用例中,通常我們對一個特定的組件感興趣,這個視角是全局的,它不與特定的實例關聯。
????????因此,想象一下,在我們的例子中,add_product的API端點運行在10個主機上,在這些服務之前有一個負載均衡器。我們沒有任何聚合函數可以用來計算add_product API接口在所有請求中響應時間的第99百分位數,無論這些請求被發送到哪個后端實例上。我們只能看到每個主機的第99個百分點。同樣地,我們也只能知道某個接口,比如add_productAPI端點的(在某個實例上的)第99百分位數,而不能對不同的接口進行聚合。
????????下面的代碼使用Prometheus的Python客戶端庫創建了一個Summary指標。
from prometheus_client import Summaryapi_request_duration = Summary('http_request_duration_seconds','Api requests response time in seconds',['api', 'instance'])api_request_duration.labels(api='add_product', instance='host1.domain.com').observe(0.3672)
????????上面的代碼沒有定義任何量化指標,只會產生總和和計數指標。Prometheus的Python SDK不支持Summary指標中的分位數計算。
Histogram還是Summary?
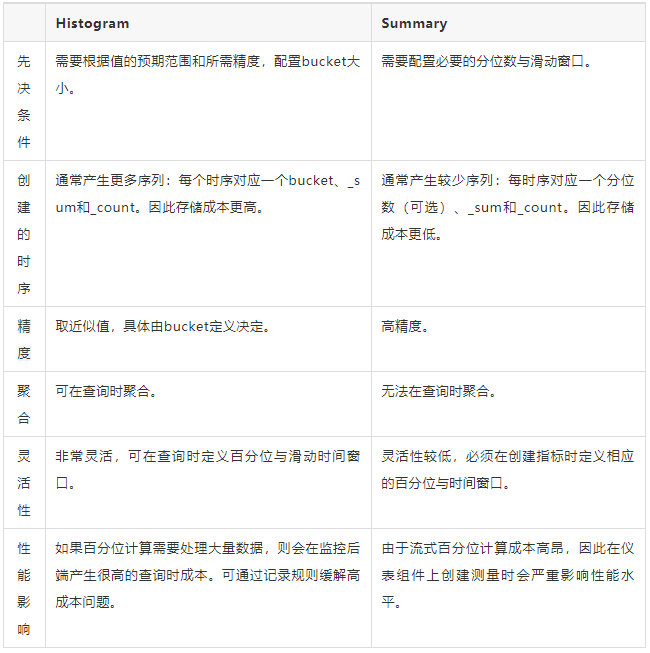
????????在大多數情況下,直方圖是首選,因為它更靈活,并允許匯總百分位數。
????????在不需要百分位數而只需要平均數的情況下,或者在需要非常精確的百分位數的情況下,匯總是有用的。例如,在履行關鍵系統的合約責任的情況下。
????????下表總結了直方圖和匯總表的優點和缺點。
Prometheus常用監控指標Exporter
????????廣義上講所有可以向Prometheus提供監控樣本數據的程序都可以被稱為一個Exporter。而Exporter的一個實例稱為target,Prometheus通過輪詢的方式定期從這些target中獲取樣本數據。
Exporter分類
????????從Exporter的來源上來講,主要分為兩類:
-
社區提供的
Prometheus社區提供了豐富的Exporter實現,涵蓋了從基礎設施,中間件以及網絡等各個方面的監控功能。這些Exporter可以實現大部分通用的監控需求。下表列舉一些社區中常用的Exporter:
| 范圍 | 常用Exporter |
| 數據庫 | MySQL Exporter, Redis Exporter, MongoDB Exporter, MSSQL Exporter等 |
| 硬件 | Apcupsd Exporter,IoT Edison Exporter, IPMI Exporter, Node Exporter等 |
| 消息隊列 | Beanstalkd Exporter, Kafka Exporter, NSQ Exporter, RabbitMQ Exporter等 |
| 存儲 | Ceph Exporter, Gluster Exporter, HDFS Exporter, ScaleIO Exporter等 |
| HTTP服務 | Apache Exporter, HAProxy Exporter, Nginx Exporter等 |
| API服務 | AWS ECS Exporter, Docker Cloud Exporter, Docker Hub Exporter, GitHub Exporter等 |
| 日志 | Fluentd Exporter, Grok Exporter等 |
| 監控系統 | Collectd Exporter, Graphite Exporter, InfluxDB Exporter, Nagios Exporter, SNMP Exporter等 |
| 其它 | Blockbox Exporter, JIRA Exporter, Jenkins Exporter, Confluence Exporter等 |
-
用戶自定義的
除了直接使用社區提供的Exporter程序以外,用戶還可以基于Prometheus提供的Client Library創建自己的Exporter程序,目前Promthues社區官方提供了對以下編程語言的支持:Go、Java/Scala、Python、Ruby。同時還有第三方實現的如:Bash、C++、Common Lisp、Erlang,、Haskeel、Lua、Node.js、PHP、Rust等。
Exporter的運行方式
從Exporter的運行方式上來講,又可以分為:
獨立使用的
以我們已經使用過的Node Exporter為例,由于操作系統本身并不直接支持Prometheus,同時用戶也無法通過直接從操作系統層面上提供對Prometheus的支持。因此,用戶只能通過獨立運行一個程序的方式,通過操作系統提供的相關接口,將系統的運行狀態數據轉換為可供Prometheus讀取的監控數據。 除了Node Exporter以外,比如MySQL Exporter、Redis Exporter等都是通過這種方式實現的。 這些Exporter程序扮演了一個中間代理人的角色。
集成到應用中的
為了能夠更好的監控系統的內部運行狀態,有些開源項目如Kubernetes,ETCD等直接在代碼中使用了Prometheus的Client Library,提供了對Prometheus的直接支持。這種方式打破的監控的界限,讓應用程序可以直接將內部的運行狀態暴露給Prometheus,適合于一些需要更多自定義監控指標需求的項目。
node-exporter常用監控指標
- CPU相關指標:
node_cpu_seconds_total{mode="idle"}:CPU空閑時間(秒)的總和。這是評估CPU使用率的重要指標之一。node_cpu_seconds_total{mode="system"}、node_cpu_seconds_total{mode="user"}等:分別表示CPU在內核態和用戶態的運行時間。
- 內存相關指標:
node_memory_MemTotal_bytes:內存總量(以字節為單位)。node_memory_MemFree_bytes:空閑內存大小(以字節為單位)。node_memory_Buffers_bytes和node_memory_Cached_bytes:分別表示被內核用作緩沖和緩存的內存大小。node_memory_SwapTotal_bytes和node_memory_SwapFree_bytes:分別表示交換空間的總大小和空閑大小。
- 磁盤相關指標:
node_filesystem_size_bytes:文件系統的大小(以字節為單位)。node_filesystem_free_bytes和node_filesystem_avail_bytes:分別表示文件系統的空閑空間和非root用戶可用的空間大小。node_disk_io_now、node_disk_io_time_seconds_total等:與磁盤I/O操作相關的指標,如當前正在進行的I/O操作數以及花費在I/O操作上的總時間。
- 網絡相關指標:
node_network_receive_bytes_total和node_network_transmit_bytes_total:分別表示網絡接口接收和發送的總字節數。這些指標對于評估網絡流量和帶寬使用情況非常重要。
- 系統負載相關指標:
node_load1、node_load5、node_load15:分別表示系統在過去1分鐘、5分鐘和15分鐘的平均負載。這些指標有助于了解系統的整體忙碌程度和性能表現。
????????要獲取完整的指標列表,可以訪問?node-exporter?的 metrics 端點(通常是?/metrics)。
mysql-exporter常用監控指標:
- MySQL 全局狀態指標:
mysql_global_status_uptime:MySQL 服務器的運行時間(以秒為單位)。mysql_global_status_threads_connected:當前打開的連接數。mysql_global_status_threads_running:當前正在運行的線程數。mysql_global_status_queries:從服務器啟動開始執行的查詢總數。mysql_global_status_questions:從服務器啟動開始接收的客戶端查詢總數。
- MySQL 復制指標(如果配置了復制):
mysql_slave_status_slave_io_running:表示 IO 線程是否正在運行(1 為運行,0 為停止)。mysql_slave_status_slave_sql_running:表示 SQL 線程是否正在運行(1 為運行,0 為停止)。mysql_slave_status_seconds_behind_master:從服務器相對于主服務器的延遲時間(以秒為單位)。
- InnoDB 存儲引擎指標:
mysql_global_status_innodb_buffer_pool_read_requests:InnoDB 緩沖池執行的邏輯讀請求數。mysql_global_status_innodb_buffer_pool_reads:不能滿足 InnoDB 緩沖池而直接從磁盤讀取的請求數。mysql_global_status_innodb_row_lock_time_avg:平均行鎖定時間(以毫秒為單位)。mysql_global_status_innodb_row_lock_time_max:最大行鎖定時間(以毫秒為單位)。
- 連接和資源使用指標:
mysql_global_variables_max_connections:MySQL 配置的最大連接數。mysql_global_status_aborted_connects:嘗試連接到 MySQL 服務器但失敗的連接數。mysql_global_status_connection_errors_total:由于各種原因導致的連接錯誤總數。
- 查詢緩存指標(如果啟用了查詢緩存):
mysql_global_status_qcache_hits:查詢緩存命中次數。mysql_global_status_qcache_inserts:插入到查詢緩存中的查詢次數。mysql_global_status_qcache_not_cached:由于查詢類型或其他原因而無法緩存的查詢次數。
- 其他常用指標:
mysql_exporter_last_scrape_duration_seconds:mysql-exporter?上次抓取指標所花費的時間。mysql_exporter_scrape_errors_total:mysql-exporter?在抓取過程中遇到的錯誤總數。
????????要獲取完整的指標列表,可以訪問?mysql-exporter?的 metrics 端點(通常是?/metrics)。此外,對于特定的監控需求,可能還需要結合 MySQL 的性能和配置進行進一步的定制和選擇。
redis-exporter?常用監控指標
- Redis 連接相關指標:
redis_connected_clients:當前連接的 Redis 客戶端數量。redis_connected_slaves:當前連接的 Redis 從節點數量。redis_blocked_clients:正在等待 Redis 的客戶端數量(通常因為 BLPOP、BRPOP、BRPOPLPUSH 等命令阻塞)。
- Redis 性能相關指標:
redis_instantaneous_ops_per_sec:每秒執行的操作數,反映 Redis 的處理速度。redis_latency_spike_duration_seconds:最近一次延遲峰值持續了多長時間(秒),這是檢測性能問題的一個標志。
- 內存使用相關指標:
redis_mem_used_bytes:Redis 使用的內存大小(字節)。redis_mem_fragmentation_ratio:內存碎片率,當該值遠大于 1 時,表示存在較多的內存碎片。redis_evicted_keys_total:由于 maxmemory 限制而被淘汰的 key 的總數量。redis_expired_keys_total:已過期的 key 的總數量。
- 持久性相關指標:
redis_rdb_last_save_time_seconds:自從 Redis 服務器啟動以來,最后一次 RDB 持久化的 UNIX 時間戳。redis_rdb_changes_since_last_save:自從最后一次 RDB 持久化以來,數據庫發生的改變次數。redis_aof_current_size_bytes:當前 AOF 文件的大小(字節)。redis_aof_last_rewrite_time_seconds:上一次 AOF 重寫操作的耗時(秒)。
- 其他常用指標:
blackbox-exporter?常用監控指標
- HTTP指標:
http_status_code:HTTP響應狀態碼,如200、404、500等。http_content_length:HTTP響應內容長度。http_request_duration_seconds:HTTP請求延遲。http_ssl_expiry_seconds:HTTPS證書過期時間。
- DNS指標:
dns_lookup_time_seconds:DNS查詢時間。dns_lookup_error:DNS查詢是否出錯。
- TCP指標:
tcp_connect_time_seconds:TCP連接時間。tcp_connection_refused:TCP連接是否被拒絕。
- ICMP指標:
icmp_response:ICMP響應是否正常,通常用于檢測遠程主機是否在線(存活狀態)。
kafka-exporter常用監控指標
Kafka集群和Broker相關指標
kafka_cluster_id:Kafka集群的唯一標識符。kafka_broker_id:Broker的唯一標識符。kafka_broker_version:Kafka Broker的版本號。kafka_controller_count:集群中控制器的數量。kafka_broker_requests_total:Broker接收到的請求總數。
主題和分區相關指標
kafka_topic_partitions_count:每個主題的分區數量。kafka_topic_partition_current_offset:每個分區的當前偏移量。kafka_topic_partition_leader_replica_count:每個分區的Leader副本數量。kafka_topic_partition_isr_replica_count:每個分區的ISR(In-Sync Replicas)副本數量。kafka_topic_partition_replica_count:每個分區的副本總數。kafka_topic_partition_under_replicated_partitions:分區副本數量少于期望值的分區數。
生產者相關指標
kafka_producer_request_rate:生產者發送請求的速率。kafka_producer_request_size_max:生產者發送的最大請求大小。kafka_producer_record_send_rate:生產者發送記錄的速率。kafka_producer_record_errors_total:生產者發送失敗的消息數量。kafka_producer_batch_size_avg:生產者批處理大小的平均值。
消費者相關指標
kafka_consumer_group_current_offset:消費者組在每個分區上的當前偏移量。kafka_consumer_group_lag:消費者組在每個分區上的滯后量(即當前偏移量與最后一條消息的偏移量之差)。kafka_consumer_group_membership_count:每個消費者組中的消費者成員數量。kafka_consumer_fetch_rate:消費者從Broker拉取消息的速率。kafka_consumer_fetch_size_bytes:消費者從Broker拉取消息的大小(以字節為單位)。
復制和同步相關指標
kafka_replica_fetch_manager_max_lag:每個副本的最大滯后量。kafka_replica_fetch_manager_min_fetch_rate:副本拉取的最小速率。kafka_replica_leader_elections_per_sec:每秒發生的Leader選舉次數。
????????請注意,以上指標列表并不完整,Kafka Exporter可能還提供了其他更詳細的監控指標。你可以根據實際需求選擇關注哪些指標,并在Prometheus中進行相應的配置和查詢。同時,確保Kafka Exporter已經正確配置并運行,以便能夠收集到這些指標數據。
Spring Boot Actuator常用監控指標
????????Spring Boot Actuator是一個用于暴露應用程序自身信息的模塊,它可以提供一系列生產就緒的端點,這些端點可以用于監視和管理Spring Boot應用程序。通過Actuator,您可以輕松地獲取應用程序的運行時信息,如健康狀態、性能指標、環境屬性、系統屬性等。
????????以下是一些常見的可以通過?/actuator/prometheus?監控的指標類型:
- 系統指標:
- CPU 使用率
- 內存使用情況(堆內存、非堆內存、JVM內存池等)
- 系統負載
- 磁盤空間和使用情況
- 網絡I/O
- 文件描述符使用
- 線程狀態和數量
- 垃圾回收活動
- 應用指標:
- HTTP 請求的計數、速率、延遲和百分位數
- 數據庫連接的池使用情況、查詢次數和性能
- 消息隊列的消費和生產速率
- 緩存命中率、大小和驅逐次數
- 調度任務的執行情況和延遲
- 外部API調用的次數、失敗率和延遲
- 業務指標:
- 用戶注冊、登錄和會話數
- 訂單處理速率和失敗率
- 購物車放棄率
- 頁面瀏覽量和跳出率
- 任何與你的業務邏輯直接相關的自定義指標
- 健康指標:
- 數據庫連接健康狀態
- 外部服務可達性(如API網關、認證服務等)
- 磁盤空間不足警告
- 應用程序內部特定組件的健康檢查(如緩存服務、消息隊列等)
- 自定義指標:
- 你可以定義自己的度量來監控應用程序中任何重要的方面。
????????Prometheus監控Spring Boot應用的方式主要有以下幾種:
- 使用Spring Boot Actuator提供的監控功能:首先,在Spring Boot程序中加入
spring-boot-starter-actuator依賴。這樣,Spring Boot在運行時就會自動放開/actuator/health和/actuator/info這兩個endpoint,我們就可以通過這兩個endpoint查看當前Spring Boot運行的情況。然后,Prometheus可以通過這些endpoint來拉取Spring Boot應用的指標數據。 - 集成micrometer-registry-prometheus:這是一種更為專業和詳細的監控方式。你需要確保你的Spring Boot和micrometer的版本號相互兼容。然后,你可以使用micrometer提供的各種監控功能來收集Spring Boot應用的指標數據,并通過Prometheus的pull機制來獲取這些數據。
- 使用Prometheus的push gateway:雖然Prometheus主要是基于pull模型來獲取數據的,但你也可以通過Prometheus的push gateway來實現push效果。這在你需要主動推送數據到Prometheus時非常有用。
????????spring-boot-starter-actuator主要提供了基本的監控和管理功能,包括暴露應用程序的各種信息;
????????micrometer-registry-prometheus則是更具體的一個實現,它將Micrometer的指標暴露給Prometheus,以實現與Prometheus的集成和更深入的監控。
????????在實際項目中,通常會根據具體需求來決定是否需要同時引入這兩個模塊。如果只需要基本的監控功能,那么引入spring-boot-starter-actuator可能就足夠了;如果需要與Prometheus進行集成以實現更深入的監控,那么還需要引入micrometer-registry-prometheus。
????????總的來說,Prometheus監控Spring Boot應用的方式主要取決于你的具體需求和你的應用環境。你可以根據自己的情況選擇最適合你的方式來進行監控。同時,Prometheus還提供了豐富的查詢語言和圖形化界面,可以幫助你更好地分析和展示監控數據。
Prometheus的k8s監控指標
????????針對于K8s集群,主要是對三方面進行監控,分別是Node、Namespace、Pod。
一、 Node監控
????????針對于節點的維度,主要監控內存、CPU使用率、磁盤和索引的使用率,過高告警。還要監控NodeNotReady的情況。
1、NodeMemorySpaceFillingUp
????????監控Node內存使用率,如果大于80%則報警。
1 2 3 4 5 6 7 8 9 | alert:NodeMemorySpaceFillingUp
expr:((1 - (node_memory_MemAvailable_bytes{job="node-exporter"} / node_memory_MemTotal_bytes{job="node-exporter"}) * on(instance) group_left(nodename) (node_uname_info) > 0.8) * 100)
for: 5m
labels:cluster: criticaltype: node
annotations:description: Memory usage on `{{$labels.nodename}}`({{ $labels.instance }}) up to {{ printf "%.2f" $value }}%.summary: Node memory will be exhausted.
|
2、NodeCpuUtilisationHigh
????????監控Node CPU使用率,如果大于80%則報警。
1 2 3 4 5 6 7 8 9 | alert:NodeFilesystemAlmostOutOfSpace
expr:((node_filesystem_avail_bytes{fstype!="",job="node-exporter"} / node_filesystem_size_bytes{fstype!="",job="node-exporter"} * 100 < 20 and node_filesystem_readonly{fstype!="",job="node-exporter"} == 0) * on(instance) group_left(nodename) (node_uname_info))
for: 5m
labels:cluster: criticaltype: node
annotations:description: Filesystem on `{{ $labels.device }}` at `{{$labels.nodename}}`({{ $labels.instance }}) has only {{ printf "%.2f" $value }}% available space left.summary: Node filesystem has less than 20% space left.
|
3、NodeFilesystemAlmostOutOfSpace
????????監控Node磁盤使用率,剩余空間<10%則報警。
1 2 3 4 5 6 7 8 9 | alert:NodeFilesystemAlmostOutOfSpace
expr:((node_filesystem_avail_bytes{fstype!="",job="node-exporter"} / node_filesystem_size_bytes{fstype!="",job="node-exporter"} * 100 < 10 and node_filesystem_readonly{fstype!="",job="node-exporter"} == 0) * on(instance) group_left(nodename) (node_uname_info))
for: 5m
labels:cluster: criticaltype: node
annotations:description: Filesystem on `{{ $labels.device }}` at `{{$labels.nodename}}`({{ $labels.instance }}) has only {{ printf "%.2f" $value }}% available space left.summary: Node filesystem has less than 10% space left.
|
4、NodeFilesystemAlmostOutOfFiles
????????監控Node索引節點使用率,剩余空間<10%則報警。
1 2 3 4 5 6 7 8 9 | alert:NodeFilesystemAlmostOutOfFiles
expr:((node_filesystem_files_free{fstype!="",job="node-exporter"} / node_filesystem_files{fstype!="",job="node-exporter"} * 100 < 10 and node_filesystem_readonly{fstype!="",job="node-exporter"} == 0) * on(instance) group_left(nodename) (node_uname_info))
for: 5m
labels:cluster: criticaltype: node
annotations:description: Filesystem on `{{ $labels.device }}` at `{{$labels.nodename}}`({{ $labels.instance }}) has only {{ printf "%.2f" $value }}% available inodes left.summary: Node filesystem has less than 10% inodes left.
|
5、KubeNodeNotReady
????????監控Node狀態,如果有Node Not Ready則報警。
1 2 3 4 5 6 7 8 9 | alert:KubeNodeNotReady
expr:(kube_node_status_condition{condition="Ready",job="kube-state-metrics",status="true"} == 0)
for: 5m
labels:cluster: criticaltype: node
annotations:description: {{ $labels.node }} has been unready for more than 15 minutes.summary: Node is not ready.
|
6、KubeNodePodsTooMuch
????????監控Node上pod數量,我們設置的最大每個Node上最多運行110個Pod,如果使用率>80%則報警。
1 2 3 4 5 6 7 8 9 | alert:KubeNodePodsTooMuch
expr:(sum by(node) (kube_pod_info) * 100 / 110 > 80)
for: 5m
labels:cluster: criticaltype: node
annotations:description: Pods usage on `{{$labels.node}}` up to {{ printf "%.2f" $value }}%.summary: Node pods too much.
|
二、Namespace監控
????????Namespace關于CPU和內存有三個值,分別是limit、request和usage。
我的理解是:
-
limit 最多可以申請多少資源(Pod 維度))
cpu:namespace_cpu:kube_pod_container_resource_limits:sum
memory:namespace_memory:kube_pod_container_resource_requests:sum
-
request 申請了多少資源(Pod 維度))
cpu:namespace_cpu:kube_pod_container_resource_requests:sum
memory:namespace_memory:kube_pod_container_resource_limits:sum
-
usage 實際使用了多少資源(Pod 維度))
cpu:sum(node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate) by (namespace)
memory:sum(node_namespace_pod_container:container_memory_working_set_bytes) by (namespace)
????????我們在kubord里面可以設置namespace的limit內存和cpu,這個暫時不知道如何從Prometheus獲取,后續會持續關注。
????????當request/limit > 80%則說明Namespace資源可能不夠,需要擴大namespace資源。
1、NamespaceCpuUtilisationHigh
????????監控namespace cpu使用率,高于90%則報警。
1 2 3 4 5 6 7 8 9 | alert:NamespaceCpuUtilisationHigh
expr:(sum(node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate) by (namespace) / sum(namespace_cpu:kube_pod_container_resource_limits:sum) by (namespace) * 100 > 90)
for: 5m
labels:cluster: criticaltype: namespace
annotations:description: CPU utilisation on `{{$labels.namespace}}` up to {{ printf "%.2f" $value }}%.summary: Namespace CPU utilisation high.
|
2、NamespaceCpuUtilisationLow
????????監控namespace cpu使用率,低于10%則報警。
1 2 3 4 5 6 7 8 9 | alert:NamespaceCpuUtilisationLow
expr:(sum(node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate) by (namespace) / sum(namespace_cpu:kube_pod_container_resource_limits:sum) by (namespace) * 100 < 10)
for: 5m
labels:cluster: criticaltype: namespace
annotations:description: CPU utilisation on `{{$labels.namespace}}` as low as {{ printf "%.2f" $value }}%.summary: Namespace CPU underutilization.
|
3、NamespaceMemorySpaceFillingUp
????????監控namespace 內存使用率,高于90%則報警。
1 2 3 4 5 6 7 8 9 | alert:NamespaceMemorySpaceFillingUp
expr:(sum(node_namespace_pod_container:container_memory_working_set_bytes) by (namespace) / sum(namespace_memory:kube_pod_container_resource_limits:sum) by (namespace) * 100 > 90)
for: 5m
labels:cluster: criticaltype: namespace
annotations:description: Memory usage on `{{$labels.namespace}}` up to {{ printf "%.2f" $value }}%.summary: Namespace memory will be exhausted.
|
4、NamespaceMemorySpaceLow
????????監控namespace 內存使用率,低于10%則報警。
1 2 3 4 5 6 7 8 9 | alert:NamespaceMemorySpaceLow
expr:(sum(node_namespace_pod_container:container_memory_working_set_bytes) by (namespace) / sum(namespace_memory:kube_pod_container_resource_limits:sum) by (namespace) * 100 < 10)
for: 5m
labels:cluster: criticaltype: namespace
annotations:description: Memory usage on `{{$labels.namespace}}` as low as {{ printf "%.2f" $value }}%.summary: Under-utilized namespace memory.
|
5、KubePodNotReady
????????監控pod狀態,如果存在pod持續not-ready達到十五分鐘則報警。
1 2 3 4 5 6 7 8 9 | alert:KubePodNotReady
expr:(sum by(namespace, pod) (max by(namespace, pod) (kube_pod_status_phase{job="kube-state-metrics",namespace=~".*",phase=~"Pending|Unknown"}) * on(namespace, pod) group_left(owner_kind) topk by(namespace, pod) (1, max by(namespace, pod, owner_kind) (kube_pod_owner{owner_kind!="Job"}))) > 0)
for: 5m
labels:cluster: criticaltype: namespace
annotations:description: Pod {{ $labels.namespace }}/{{ $labels.pod }} has been in a non-ready state for longer than 15 minutes.summary: Pod has been in a non-ready state for more than 15 minutes.
|
6、KubeContainerWaiting
????????監控pod狀態,如果存在pod持續waiting達到十五分鐘則報警。
1 2 3 4 5 6 7 8 9 | alert:KubeContainerWaiting
expr:(sum by(namespace, pod, container) (kube_pod_container_status_waiting_reason{job="kube-state-metrics",namespace=~".*"}) > 0)
for: 5m
labels:cluster: criticaltype: namespace
annotations:description:Pod {{ $labels.namespace }}/{{ $labels.pod }} container {{$labels.container}} has been in waiting state for longer than 15 minutes.summary: Pod container waiting longer than 15 minutes.
|
7、PodRestart
????????這個告警配置的就是如果kube-system這個namespace下面存在某個pod重啟了則發送告警。
????????因為在kube-system這個namespace下面,存在很多集群相關的pod,比如我們的日志收集組件Fluentd和corends等,所以如果這個namespace下面有容器重啟,那么需要警惕一下是否集群出現了問題。
1 2 3 4 5 6 7 8 9 | alert:PodRestart
expr:(floor(increase(kube_pod_container_status_restarts_total{namespace="kube-system"}[1m])) > 0)
for: 5m
labels:cluster: criticaltype: namespace
annotations:description:Pod {{ $labels.namespace }}/{{ $labels.pod }} restart {{ $value }} times in last 1 minutes.summary: Pod restart in last 1 minutes.
|
8、PrometheusOom
????????Prometheus自己也是存在宕機的風險,所以我們加了一個監控來檢測Prometheus,如果內存使用率達到90%則可能出現異常,所以發送告警。
1 2 3 4 5 6 7 8 9 | alert:PrometheusOom
expr:(container_memory_working_set_bytes{container="prometheus"} / container_spec_memory_limit_bytes{container="prometheus"} > 0.9)
for: 5m
labels:cluster: criticaltype: namespace
annotations:description:Memory usage on `Prometheus` up to {{ printf "%.2f" $value }}%.summary: Prometheus will be oom. |
三、Pod監控
1.1 pod性能指標(k8s集群組件自動集成)
????????k8s組件本身提供組件自身運行的監控指標以及容器相關的監控指標。通過cAdvisor 是一個開源的分析容器資源使用率和性能特性的代理工具,集成到 Kubelet中,當Kubelet啟動時會同時啟動cAdvisor,且一個cAdvisor只監控一個Node節點的信息。cAdvisor 自動查找所有在其所在節點上的容器,自動采集 CPU、內存、文件系統和網絡使用的統計信息。cAdvisor 通過它所在節點機的 Root 容器,采集并分析該節點機的全面使用情況。
????????當然kubelet也會輸出一些監控指標數據,因此pod的監控數據有kubelet和cadvisor,監控url分別為
https://NodeIP:10250/metrics
https://NodeIP:10250/metrics/cadvisor
1.2 K8S資源監控(k8s集群內部署)
????????kube-state-metrics是一個簡單的服務,它監聽Kubernetes API服務器并生成關聯對象的指標。它不關注單個Kubernetes組件的運行狀況,而是關注內部各種對象(如deployment、node、pod等)的運行狀況。
注:先手動檢查下集群,是否已經安裝kube-state-metrics

????????如果集群沒有安裝,可參考如下步驟進行部署:
| 1 2 3 4 5 |
|
1.3 編輯kube-state-metrics.yml文件
| 1 |
|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 |
|
1.4 啟動yaml文件
| 1 |
|

1.5 查看pod信息
| 1 |
|

1.6 查看service信息
| 1 |
|

????????這里可以看到k8s集群對外暴露的端口為 62177
1.7 查看集群信息
| 1 |
|

????????然后查看metrics信息
可以手動
| 1 |
|
????????正常,數據metrics就會出現
二、創建token供集群外部訪問
????????集群外部監控K8s集群,通過訪問kube-apiserver來訪問集群資源。通過這種方式集群外部prometheus也能自動發現k8s集群服務
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
|
三、集成Prometheus配置
| 1 |
|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
|
注意:bearer_token_file: /prometheus/data/k8s_token
這里的token為上面生成的token信息,請根據目錄進行配置即可
然后重啟prometheus
????????如果是容器部署的prometheus,需要考慮映射token,可docker cp到/prometheus/data/ 即可
即可
| 1 |
|
3、進入prometheus界面,查看相關指標
????????默認情況下 prometheus url: http://IP:9090

4、集成grafana
????????導入grafana JSON ID, 747


![[面試題]計算機網絡](http://pic.xiahunao.cn/[面試題]計算機網絡)
















