
論文地址:Enhancing Retrieval-Augmented Large Language Models with Iterative Retrieval-Generation Synergy
摘要
????????檢索增強生成由于有望解決包括過時知識和幻覺在內的大型語言模型的局限性而引起廣泛關注。然而,檢索器很難捕捉相關性,尤其是對于具有復雜信息需求的查詢。最近的工作提出通過讓大型語言模型積極參與檢索來改進相關性建模,即用生成來指導檢索。在本文中,我們證明了通過我們稱之為ITER-RETGEN的方法可以實現強大的性能,該方法以迭代的方式協同檢索和生成:模型對任務輸入的響應顯示了完成任務可能需要的內容,因此可以作為檢索更相關知識的信息上下文,從而有助于在另一次迭代中生成更好的響應。與最近在完成單個輸出時將檢索與生成交織在一起的工作相比,ITERRETGEN將所有檢索到的知識作為一個整體進行處理,并在很大程度上保持了生成的靈活性,而沒有結構約束。我們在多跳問答、事實驗證和常識推理方面對ITER-RETGEN進行了評估,并表明它可以靈活地利用參數知識和非參數知識,優于或與最先進的檢索增強基線競爭,同時減少了檢索和生成的開銷。我們可以通過生成增強檢索自適應來進一步提高性能。
1 引言
????????生成型大型語言模型(LLM)為許多應用程序提供了強大的功能。盡管LLM很強大,但它們缺乏在訓練數據中被低估的知識,并且容易產生幻覺,尤其是在開放領域環境中(OpenAI,2023)。
????????因此,檢索增強LLM引起了廣泛關注,因為LLM的輸出可能基于外部知識。
????????先前的檢索增強型LMs(Izacard等人,2022b;Shi等人,2023)通常采用一次性檢索,即僅使用任務輸入(例如,用于開放域問答的用戶問題)來檢索知識。如果原始輸入中明確說明了信息需求,則一次性檢索應足以滿足這些信息需求,這適用于事實問答(Kwiatkowski et al.,2019)和單跳事實驗證(Thorne et al.,2018),但不適用于具有復雜信息需求的任務,例如多跳推理(Yang et al,2018)和長形式問答(Fan et al。2019)。
????????為了滿足復雜的信息需求,最近的工作建議在整個生成過程中多次收集所需的知識,使用部分生成(Trivedi等人,2022a;Press等人,2022)或前瞻性句子(Jiang等人,2023)作為搜索查詢。然而,這種將檢索與生成交織在一起的結構化工作流具有以下局限性:(1)由于中間生成以之前檢索的知識為條件,而對之后檢索的知識沒有任何意識,因此在生成過程中,它們無法將所有檢索的知識作為一個整體進行處理;(2) 它們需要多輪檢索來收集一組全面的知識,并且可能通過更新新檢索的知識來頻繁地改變提示,從而增加了檢索和生成的開銷。
????????在本文中,我們發現通過迭代檢索生成協同作用來增強檢索增強LLM是簡單但有效的(ITER-RETGEN,圖1)。ITER-RETGEN迭代檢索增強生成和生成增強檢索:檢索增強生成基于所有檢索到的知識輸出對任務輸入的響應(最初使用任務輸入作為查詢)。該輸出顯示了完成任務可能需要的內容,因此可以作為檢索更多相關知識的信息上下文,即生成增強檢索。新檢索到的知識可以有利于檢索增強生成的另一次迭代。我們還可以利用模型生成來調整檢索,通過將知識從能夠訪問模型生成的重新排序器提取到僅能夠訪問任務輸入的密集檢索器,這在用戶輸入可以很容易地收集,但相關知識或期望輸出沒有注釋的情況下可能是有益的。

圖1:ITER-RETGEN迭代檢索和生成。在每次迭代中,ITER-RETGEN利用上一次迭代的模型輸出作為特定上下文,以幫助檢索更多相關知識,這可能有助于改進模型生成(例如,校正該圖中Hesse Hogan的高度)。為了簡潔起見,我們在此圖中只顯示了兩次迭代。實心箭頭將查詢連接到檢索到的知識,虛線箭頭表示檢索增強生成。
????????我們在三個任務上評估了我們的方法,包括多跳問題回答、事實驗證和常識推理。我們的方法提示LLM生成一系列推理步驟,然后在少樣本設置下得出最終答案。對于上下文演示,我們專注于解決問題,并遵循Wei等人(2022)對思想鏈進行注釋,而沒有明確考慮生成增強檢索可能受到的影響,這使得它在概念上簡單易實現。我們的方法在六個數據集中的四個數據集上實現了比以前最先進的檢索增強方法高達8.6%的絕對增益,同時在其余兩個數據集中具有競爭力。根據我們的實驗,生成通常受益于更多的迭代,兩次迭代可以獲得最大的性能增益。可以通過選擇適當數量的迭代來定制性能成本權衡。我們可以通過上述生成增強檢索自適應來進一步提高性能并減少迭代。
????????我們將研究結果總結如下:
-
諸如精確匹配(EM)之類的自動度量可能會大大低估LLM在問答任務中的性能。此外,精確匹配的改進并不總是反映出生成的改進。使用LLM的評估可能更可靠。
-
ITER-RETGEN優于或與最先進的檢索增強方法競爭,同時更簡單,檢索和生成的開銷更少。通過生成增強檢索自適應,我們可以進一步提高性能,還可以減少開銷(通過減少迭代)。
- LLM最好能有效利用參數知識和非參數知識。ITER-RETGEN在問答任務中始終優于Self Ask,無論非參數知識是否提及答案。
2 相關工作
????????最近幾個月,LLM驅動的應用程序激增,如ChatGPT、Bing Chat和CoPilot(Chen等人,2021)。LLM在表現出前所未有的性能水平的同時,也受到以下限制:(1)由于對計算和數據的高需求,持續高效地更新LLM仍然是一個懸而未決的研究問題(Scialom等人,2022);(2) LLM也傾向于產生幻覺(OpenAI,2023),即生成看似合理但非事實的文本。為了緩解這些問題,越來越多的趨勢是使用工具(Mialon等人,2023;Gou等人,2022),例如代碼解釋器(Gao等人,2022b;Shao等人,2020)或搜索引擎(Nakano等人,2021)來擴充LLM,試圖將子任務交給更合格的專家,或通過提供更相關的信息來豐富LLM的輸入上下文。
????????檢索增強是LLM與外部世界連接的主流方向。先前的檢索增強LMs(Izacard和Grave,2021;Shao和Huang,2022)通常以被動的方式接收檢索到的知識:在沒有LMs干預的情況下,基于任務輸入檢索知識。由于檢索器很難捕捉相關性,特別是在零樣本環境中,最近的工作表明,LLM積極參與檢索以改進相關性建模,例如,為模型生成的檢索提供特定上下文(例如,生成的搜索查詢(Nakano等人,2021;Press等人,2022;Yao等人,2022)、部分生成(Trivedi等人,2022a)或前瞻性句子(Jiang等人,2023))。Khattab等人(2022)提出了一種支持各種檢索增強方法的DSP編程框架。
????????最近的工作在完成單個輸出時將檢索與生成交織在一起。這種結構化的工作流程可能會降低生成的靈活性(Yao等人,2022)。ITER-RETGEN避免了用檢索來中斷生成,而是迭代檢索和生成,即利用上一次迭代的完整生成來檢索更多相關信息,有助于改進下一次迭代中的生成。ITER-RETGEN還具有在生成過程中將所有檢索到的知識作為一個整體進行處理的優勢,并且在概念上更簡單、更容易實現,同時在多跳問答、事實驗證和常識推理方面具有較強的經驗。
????????一項名為GAR的密切相關的工作(Mao等人,2021)用生成的背景信息增強了查詢。HyDE(Gao et al,2022a)也有類似的精神,但專注于零樣本信息檢索,并建議首先提示LLM生成涵蓋回答給定問題所需信息的“假設”段落,然后使用生成的段落來檢索真實段落。RepoCoder(Zhang et al,2023)專注于存儲庫級別的代碼完成,并提出了一種兩次迭代的檢索生成范式,其中第二次迭代利用中間代碼完成進行檢索。相比之下,我們建議在各種自然語言任務上與ITER-RETGEN協同進行檢索和生成,并探索如何進一步調整檢索與模型生成。
3?迭代檢索生成協同
3.1 概述
????????給定問題q和檢索語料庫={
},其中
是段落,ITER-RETGEN重復
次迭代的檢索生成;在迭代
中,我們(1)利用上一次迭代的生成
,與
連接,來檢索前k個段落,然后(2)提示LLM
生成輸出
,將檢索到的段落(表示為
)和
集成到提示中。因此,每次迭代可以公式化如下:
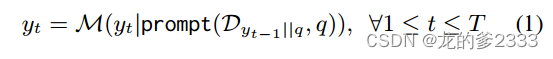
????????最后一個輸出將作為最終響應產生。
3.2?生成增強檢索
????????有許多自然語言任務具有復雜的信息需求。例如,在開放域多跳問答中,特定的信息需求只有在正確回答了一些先決條件的子問題后才能顯現出來。換言之,原始問題與其支持知識之間可能存在語義差距,這是具有表示瓶頸的檢索器無法有效解決的。在第一次迭代中,我們只能用問題
來檢索知識。在以后的迭代中,上一次迭代的LLM輸出雖然不能保證正確性,但顯示了回答問題可能需要什么,因此可以用來彌合語義差距;隨著檢索的改進,LLM可能會產生更好的輸出。
3.3 檢索增強生成
????????在每次迭代中,我們使用思想鏈提示生成一個輸出,除了我們還為問題準備檢索到的知識。盡管可能存在更先進的提示變體,例如,將前幾次生成整合到提示中以實現直接改進,但我們將探索留給未來的工作,并專注于以直接的方式研究檢索和生成之間的協同作用。
3.4 生成增強檢索自適應
????????模型生成不僅為檢索提供了特定的上下文,還可以用來優化檢索器,以便檢索器更好地捕捉問題中的信息需求。
????????密集檢索器我們在實驗中采用了密集檢索。給定由參數化的稠密檢索器,其中θq和θd分別表示查詢編碼器和段落編碼器的參數,查詢和段落之間的相似性得分計算為其編碼向量的內積:
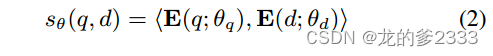
????????重新排序器?重新排序器,參數化為,輸出段落與查詢相關的概率;我們將概率表示為
。
????????蒸餾?重新排序器通常比檢索器更善于捕捉查詢和段落之間的相關性。因此,我們將知識從一個重新排序者提煉為一個檢索者。為了幫助檢索器更好地解決問題與其支持知識之間的語義差距,我們允許重新排序器訪問(其中
是第一次迭代的LLM輸出)。我們使用以下訓練目標僅優化檢索器的查詢編碼器:
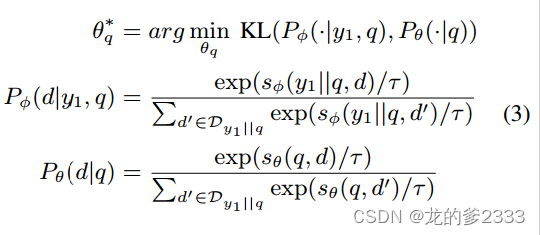
????????其中KL(·,·)表示兩個概率分布之間的KL散度。
4 實驗
4.1 數據集
????????我們在三個推理任務的六個數據集上進行了實驗:(1)多跳問答,包括HotPotQA(Yang等人,2018)、2WikiMultiHopQA(Ho等人,2020)、MuSiQue(Trivedi等人,2022b)和Bamboogle(Press等人,2022)。
????????關于MuSiQue,我們遵循Press等人(2022),僅使用2個問題;(2) 事實核查,包括Feverous(Aly等人,2021);(3) 常識推理,包括戰略QA(Geva等人,2021)。示例如表1所示。
????????我們分別使用2017年10月(Yang等人,2018)和2018年12月(Karpukhin等人,2020)的維基百科轉儲作為HotPotQA和2WikiMultiHopQA的檢索語料庫,并將2021年12月的維基百科轉儲(Izacard等人,2022b)用于其他數據集。
4.2 評估設置
????????我們對Bamboogle的所有125個問題、StrategyQA訓練集的前500個問題以及其他數據集開發集的前五百個問題進行了評估。
????????所有方法都是在3個熱點設置下進行評估的,在演示中共享相同的問題。
????????評估指標是多跳問答數據集的精確匹配(EM)和F1,以及事實驗證和常識推理數據集的準確性。為了進行更穩健的評估,我們還使用text-davinci-003評估模型輸出的正確性,所得度量表示為Acc?。用于評估的提示如下,其中{question}、{model output}和{answer}是占位符。

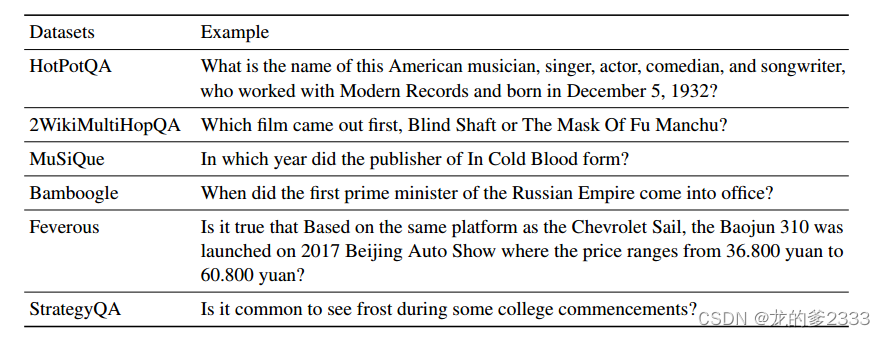
表1:來自六個數據集的示例問題。
4.3 基線
????????直接提示(Brown等人,2020) 提示LLM在沒有解釋的情況下直接生成最終答案。當用檢索來增強直接提示時,我們使用問題來檢索知識,這些知識將放在提示中的問題之前。
????????CoT提示(Wei等人,2022)提示LLM生成自然語言推理步驟,然后是最終答案。
????????ReAct(Yao et al,2022)將推理、行動和觀察步驟交織在一起,直到達到最終確定答案的行動。一個操作可以是生成查詢以搜索信息,也可以是最終確定答案。觀察是檢索到的段落的串聯。
????????Self-Ask(Press等人,2022)交錯(i)后續問題生成,(ii)使用后續進行檢索,以及(iii)以檢索到的知識為條件回答后續,直到不再生成后續問題,LLM給出原始問題的答案。我們遵循(Yoran等人,2023),在原始問題的前面加上新檢索到的段落。在我們評估的任務中,Self-Ask在概念上與ReAct相似,主要區別在于Self-Asc在提示中的原始問題之前積累檢索到的知識,而ReAct則將檢索到的信息放在其查詢之后。Self-Ask和IRCoT(Trivedi等人,2022a)也共享協同推理和檢索的精神。
????????DSP(Khattab等人,2022)包括多跳檢索階段和答案預測階段。對于檢索階段中的每一跳,都會提示模型生成搜索查詢并總結檢索知識以供后續使用。在預測階段,DSP根據總結的知識和檢索到的文檔使用CoT生成答案。
4.4 實現細節
????????我們使用了InstructGPT的text-davinci-003版本(歐陽等人,2022)作為后端LLM。
????????我們還在附錄A中介紹了使用開源Llama-2模型(Touvron等人,2023)的實驗。所有實驗都使用了貪婪解碼。
????????對照MSMARCO(Izacard等人,2022a)用于檢索。我們檢索了每個查詢的前5個段落。對于ReAct和Self Ask,我們最多允許5次與檢索交互。我們對DSP1的實現進行了調整,使其使用與其他方法相同的生成模型和檢索系統。
????????請注意,ITER-RETGEN的第一次迭代是CoT提示和檢索增強。因此,ITER-RETGEN和CoT提示共享相同的注釋上下文演示。所有提示均顯示在附錄中。
4.5 主要結果
????????如表2所示,ITER-RETGEN(T≥2)的Acc?顯著高于HotPotQA、2WikiMultiHopQA、Bamboogle和StrategyQA上的檢索改進基線,同時與MuSiQue和Feverous上的最佳方法(即Self -Ask)具有競爭力。
????????當增加ITER-RETGEN的迭代次數時,性能通常會提高,第二次迭代會帶來最大的提升。
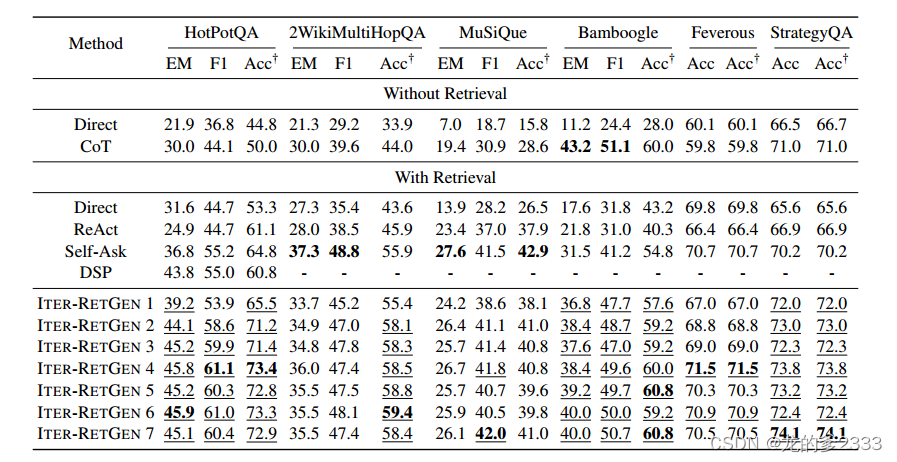
表2:多跳問答、事實驗證和常識推理數據集的評估結果。
Acc?是用text-davinci-003評估的模型輸出的準確性。對于ITER-RETGEN,我們評估了不同迭代(最多7次迭代)中的LLM輸出。帶下劃線的度量值高于Self-Ask的度量值。
????????值得注意的是,如表3所示,ITERRETGEN(T=2)優于ReAct和Self-Ask,或者與ReAct和Self-Mask競爭,使用更少的對LLM的API調用(即2)和更少的檢索段落(即每次迭代5個,總共10個)。ITER-RETGEN在概念上也很簡單,即迭代檢索遞增的CoT,而不需要復雜的處理。

表3:API調用text-davinci-003的平均次數,以及檢索到的ReAct和Self-Ask段落。
請注意,ITER-RETGEN(T=2)通過更少的API調用(即2)和更少的檢索段落(每次迭代5個,總共10個)實現了顯著更高或具有競爭力的Acc?。
????????我們還將ITER-RETGEN與DSP進行了比較,后者也基于檢索到的知識使用CoT生成答案,但在信息收集和處理方面有所不同。在每次迭代中,ITERRETGEN根據(1)問題和(2)先前的模型輸出檢索知識,該模型輸出顯示了回答問題可能需要的內容。隨著迭代次數的增加,我們傾向于獲得更全面、更相關的知識集。此外,與DSP不同,我們不匯總檢索到的文檔以生成答案,因此不會引入匯總錯誤。
????????如表2所示,ITER-RETGEN明顯優于DSP。我們手動調查了10個隨機問題,其中DSP失敗,但ITER-RETGEN提供了正確的答案。在其中40%的案例中,DSP未能檢索到包含正確答案的文件,而在其中50%的案例中所總結的知識具有誤導性,例如,對于“Chris Menges和Aram Avakian共享什么職業?”的問題,DSP生成了一個錯誤的摘要“Chris Mengs和Aram Avakian都是美國和英國電影攝影師協會的成員。”。
????????Acc?是一個可靠的度量??為了研究Acc?的可靠性,我們重點關注EM和Acc?不一致的模型輸出,并手動檢查哪個度量給出了更正確的標簽。在四個多跳問答數據集中的每一個數據集上,我們從ITER-RETGEN的第二次迭代中隨機采樣了20個模型輸出,總共產生了80個樣本。對于98.75%的樣本,EM為0,Acc?為1,而Acc?在97.5%的時間內給出了正確的標簽,這表明EM嚴重低估了模型性能。我們還對Self-Ask進行了同樣的評估,當Acc?與EM不一致時,98.75%的時間給出了正確的標簽。
????????Acc?提供了識別語義正確的模型輸出的優勢,即使它們的表面形式與注釋的答案不同。例如,對于“Jan Baptist Van Rensselaer的父親來自哪個國家?”這個問題,注釋的答案是荷蘭語,而模型預測是荷蘭,這在Acc?方面是正確的,但受到EM的懲罰。
????????值得注意的是,ITER-RETGEN(T≥2)在2WikiMultiHopQA上始終表現出比Self-Ask更低的EM,但更高的Acc?,這表明EM的增強并不一定反映生成答案質量的提高。
????????生成效益檢索自適應??為了研究LLM輸出如何用于檢索自適應,我們在HotPotQA和Feverous上進行了實驗。具體來說,在每個數據集上,我們從訓練集中隨機抽取9000個問題進行訓練,并抽取1000個問題進行驗證。我們將ITER-RETGEN應用于一次迭代,并使用模型輸出y1進行檢索自適應,如第3.4節所示。我們使用TART(Asai等人,2022)作為重新排序器,并在不超過1000步的時間內將知識從TART提取到密集檢索器。
????????批量大小為32,學習率為1e-5。我們使用了蒸餾損失最低的檢索器檢查點。
????????如表4所示,檢索自適應使ITER-RETGEN能夠用更少的迭代實現顯著更高的Acc?。我們還展示了使用進行適應的好處,展示了它對變體的改進,變體的不同之處在于重新排序者無法訪問
;該變體的訓練目標可以通過去除等式3中的所有
符號來獲得。

表4:使用LLM生成y1對優化密集檢索器的影響。我們根據Acc?在HotPotQA和Feverous上評估了ITER-RETGEN
4.6 消融實驗
4.6.1 生成增強檢索
????????表6顯示了不同迭代中檢索的答案回憶。第一次迭代只使用問題進行檢索,并且存在低回答回憶的問題。在第二次迭代中,用第一次迭代的LLM輸出擴充的檢索,實現了顯著更高的回憶,表明LLM生成可以幫助彌合復雜問題與其支持知識之間的語義差距。然而,之后的表現很快就達到了平穩期。
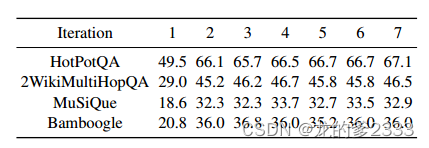
表6:ITER-RETGEN在不同迭代中檢索到的段落的答案回憶
4.6.2 ITER-RETGEN更好地利用參數和非參數知識
????????理想情況下,LLM應該靈活地利用非參數知識或參數知識,這取決于非參數知識在上下文中是否相關。表5列出了供調查的不同問題子集的績效細分。我們考慮了CoT在不進行檢索的情況下正確回答問題的能力,作為評估LLM使用其參數知識回答問題能力的代理。與Self-Ask相比,ITER-RETGEN往往在保留LLM在LLM可以使用CoT解決的問題上的性能方面明顯更好,而無需檢索,同時在互補子集上具有競爭力。這可能是因為Self-Ask的結構約束使LLM對后續問題生成和回答的準確性和全面性過于敏感,而且Self-Ask也無法整體處理所有檢索到的知識,從而降低了LLM解決問題的靈活性。此外,無論上下文中的非參數知識是否提到了答案,ITER-RETGEN都在很大程度上始終優于Self-Ask。這表明,當上下文中的非參數知識不相關或不完整時,ITER-RETGEN比Self-Ask更好地利用參數知識。

表5:Self-Ask和ITER-RETGEN(T=2)在不同子集上的比較,以Acc?為單位。CoT?是CoT×在沒有檢索的情況下正確回答的問題的子集;CoT%是補碼。w/Answer Retrieved是一種方法(Self-Ask或ITER-RETGEN)成功檢索提及答案的段落的問題子集;w/o Answer Retrieved是補碼。ITER-RETGEN往往更善于保持LLM在使用CoT無需檢索即可解決的問題上的性能,并且無論檢索到的知識是否提到了答案,都始終更準確
4.7 誤差分析
????????在HotPotQA上,我們手動分析了ITER-RETGEN(T=2)失敗的20個隨機案例。25%的預測是假陰性。在10%的情況下,ITER-RETGEN檢索所有必要的信息,但未能執行正確的推理。其余65%的錯誤案例與檢索有關,其中76.9%的案例中,檢索被第一次迭代的完全錯誤推理誤導,而在其他案例中,第一次迭代中的推理是部分正確的,但檢索器未能在第二次迭代中檢索到缺失的部分。我們還觀察到,在第一次迭代中,推理可能會受到僅使用問題作為查詢檢索到的嘈雜且可能分散注意力的知識的負面影響。
5 案例研究
????????表7分別用HotPotQA和StrategyQA的兩個例子展示了檢索生成的協同作用。在第一次迭代中,由于兩個問題都需要多跳推理,檢索器無法僅使用問題檢索所有支持知識。盡管在第一次迭代中受到分心的檢索知識(HotPotQA示例中不同領域的能力)的影響,并顯示出不完美的參數知識(StrategyQA示例中生成的Raclette不太可能在巴黎找到的語句),LLM在第二次迭代中生成有助于檢索相關知識的短語,并成功糾正其輸出。
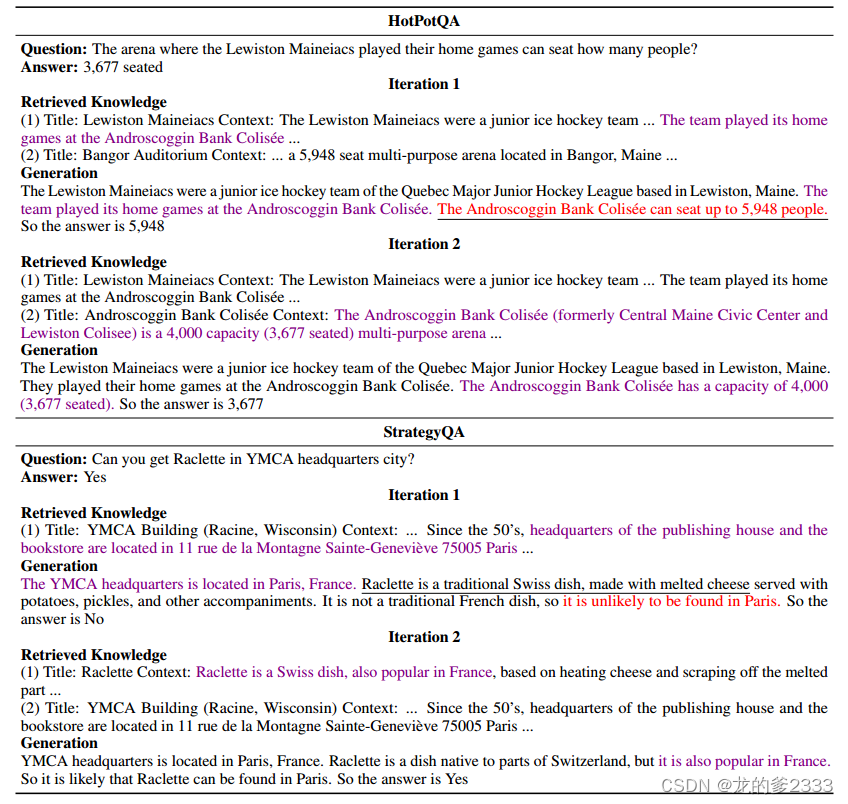
表7:展示檢索-生成協同作用的兩個例子。我們在生成的短語下劃線,這些短語有助于檢索相關知識,并在第二次迭代中成功糾正事實錯誤(紅色)。為簡潔起見,表中未顯示檢索到的無關段落。
6 結論
????????我們展示了ITER-RETGEN在回答具有復雜信息需求的問題方面的有效性。盡管簡單,ITER-RETGEN的性能優于具有更復雜工作流程的檢索增強方法,我們認為這可以作為未來檢索增強生成研究的有力基線。我們還表明,生成增強檢索自適應可以進一步提高ITER-RETGEN的性能,同時減少開銷。
局限性
????????在這項工作中,我們建議使用ITERRETGEN來增強檢索增強的大型語言模型,該模型以迭代的方式協同檢索和生成,并與更結構化的提示技術(如Self-Ask)相比表現出強大的性能。然而,值得注意的是,我們的實驗使用了一個固定的黑匣子大型語言模型,該模型可能沒有針對各種形式的提示進行同等優化。研究促進特定(基于梯度的)優化進一步突破極限的潛力將是一件有趣的事情。這可能涉及到使大型語言模型能夠更靈活有效地利用參數和非參數知識。通過探索這一途徑,我們可能會發現該領域的新見解和進步。此外,我們的實驗沒有涵蓋長格式生成,這可能會比ITERRETGEN在這項工作中受益于更細粒度的檢索。我們承認這一領域值得進一步探索,我們將其留給未來的工作。





安裝及規則查詢)













