????????基于殘差卷積網絡和多層感知器變壓器編碼器(MLP)的優勢,提出了一種新型的混合深度學習乳腺病變計算機輔助診斷(CAD)系統。利用骨干殘差深度學習網絡創建深度特征,利用Transformer根據自注意力機制對乳腺癌進行分類。所提出的CAD系統具有識別兩種情況乳腺癌的能力:情景A(二元分類)和情景B(多重分類)。數據收集和預處理、斑塊圖像創建和分割以及基于人工智能的乳房病變識別都是執行框架的組成部分,在這兩種情況下都得到了一致的應用。提出的人工智能模型的有效性與三個獨立的深度學習模型進行了比較:自定義CNN, VGG16和ResNet50。
????????利用CBIS-DDSM和DDSM兩個數據集來構建和測試所提出的CAD系統。測試數據的五重交叉驗證用于評估性能結果的準確性。所建議的混合CAD系統取得了令人鼓舞的評估結果,在二元和多類別預測挑戰中,總體準確率分別為100%和95.80%。
????????乳房x線攝影技術是診斷早期乳腺癌的最佳方式。在乳腺癌早期,將癌細胞組織與乳腺組織區分開來并不是一件簡單的工作,特別是對于乳腺致密的女性。例如,圖1顯示了6例個體病例的乳房x線照片。良性和惡性病例均取自乳腺造影篩查數字數據庫(CBIS-DDSM)數據集的拓展乳腺成像子集,而正常病例取自乳腺造影篩查數據庫(DDSM)數據集。
????????一些乳腺病例的組織強度高,特征多樣,放射科醫生很難用肉眼區分正常組織和異常組織。在這種情況下,假陽性率會增加,導致乳房圖像的錯誤分類。
????????在之前的工作[4]中,利用一階和高階放射學特征構建了基于CAD的基于乳腺x光片的深度信念網絡(DBN)。結果表明,這些特征對疾病預測是有用和可信的。一些有趣的研究如[6-8]顯示了影像學放射學特征與復發風險、預后和分子表型之間的關系的重要性,這有助于預測乳腺圖像中的惡性概率。
1. 文章貢獻
????????提出了一種新的混合ResNet與變壓器編碼器(Transformer Encoder)框架,用于從x射線乳房x線攝影數據集自動預測乳腺癌。采用深度學習的ResNet作為骨干網絡進行深度特征提取,采用帶多層感知器(MLP)的TE對乳腺癌進行分類。
????????提出一種全面的計算機輔助診斷(CAD)系統,將乳腺癌分為兩種情況:二元分類(正常與異常)和多重分類(正常與良性與惡性)。
????????使用自定義CNN、VGG16和ResNet50三種AI模型與所提出的AI模型在二元和多類分類場景下的性能對比研究。
????????提出了一種自適應自動圖像處理分割三角形算法,用于創建自適應閾值,從整個乳房x光片中提取感興趣區域(roi)。與傳統的二值閾值分割算法相比,該算法能更好地分割邊界區域。
????????增強處理應用于增加圖像補丁的數量,以克服過擬合問題,并創建一個足夠大的數據集來訓練和測試所提出的模型。
????????創建4個不同補丁大小的異常數據集:256 × 256、400 × 400和512 × 512。當使用較大的貼片尺寸時,所提出的模型記錄了最好的結果。
2. 相關工作
2.1 深度學習分類
????????近年來,深度學習在乳腺癌的醫學應用在病灶分割、檢測和分類等領域得到了廣泛關注[9]。為了提高基于二元或多重分類情況的乳腺癌診斷率,已經探索和開發了幾種深度學習模型。與以往的研究一樣,使用深度學習YOLO預測器來區分乳房x線照片上的良惡性病例[9-13]。al - antari等[9]提出了一種基于YOLO預測器的深度學習識別框架,用于乳腺圖像的檢測和分類,以區分良惡性病例。YOLO主要用于從整個乳房x光片中檢測乳房腫瘤,分類時使用了三種分類器,分別是Regular前饋CNN、ResNet-50和InceptionResNet-V2。
????????InceptionResNet-V2分類器的性能最好,DDSM數據集的準確率為97.50%,INbreast數據集的準確率為95.32%。然而,由于微鈣化是一種不同的現象,需要不同的檢測技術,作者只關注了乳房腫塊的檢測,而沒有關注微鈣化問題[14]。
????????Hamed等[10]使用YOLO分類器通過提出三種檢測和分類乳腺癌的過程來識別乳腺圖像的良惡性。總體分類性能達到了總體準確率的89.5%。Hamed等[11]也利用基于yolov4的CAD系統識別良性和惡性病變,同時使用Inception、ResNet、VGG等不同的特征提取器將局部病變分類為良性或惡性。基于YOLO-V4模型提出的模型優于其他分類器,在質量位置檢測上準確率達到98%,而ResNet的最佳分類準確率為95%。
????????Aly等[12]使用YOLOv3分類器檢測良性腫塊和癌性腫塊,使用ResNet和Inception模型提取重要特征。所提出的模型能夠檢測出89.4%的腫塊,其中良惡性腫塊的識別準確率分別達到94.2%和84.6%。盡管YOLO檢測器可以有效地對輸入圖像進行預測,但很難檢測到微鈣化物體的小聚類[15]。
????????CNN技術也被用于乳腺癌的檢測和分類[16-25]。Kooi等[16]將基于CNN的CADe系統與依賴手工圖像特征的傳統CADe系統進行了比較。最終結果表明,基于cnn的CADe系統在低靈敏度下優于傳統的CADe系統,而在高靈敏度下兩種系統的結果相同。基于cnn的CADe系統的AUC為0.929,參考CADe系統的AUC為0.91。
????????Xi等人[17]提出了CNN模型,利用計算機輔助檢測對乳房x線攝影圖像中的鈣化和腫塊進行分類和定位。根據作者的研究結果,VGGNet具有最好的總體分類準確率,得分為92.53%。Hou等人[18]提出了一項研究,使用基于一類半監督模型的深度卷積自編碼器檢測乳房x線攝影中的鈣化。在驗證階段,該模型的AUROC達到0.959%,AUPRC達到0.676%。該模型檢測鈣化病變的靈敏度為75%,每張圖像的假陽性率為2.5%。根據作者的發現,更先進的模型或更大的數據集并沒有提高檢測性能。
????????[19]應用圖像紋理屬性提取方法和CNN分類器開發了乳腺癌自主識別系統。采用均勻流形逼近和投影(UMAP)對提取的特征進行最小化。該模型在乳腺圖像分析學會(MIAS)數據集采集的圖像上能夠區分正常和異常圖像,特異性和準確性分別達到97.8%和98%,在DDSM數據集的圖像上,特異性和準確性分別達到98.3%和97.9%。
????????Pillai等[20]使用VGG16深度學習模型在乳房x光檢查中診斷乳腺癌。該模型優于AlexNet、EfficientNet和GoogleNet模型,準確率為75.46%。Mahmood等[21]開發了一種新的基于深度學習的卷積神經網絡(ConvNet),大大減少了診斷乳腺癌組織的人為錯誤。在乳腺腫塊分類中,該模型的訓練準確率為0.98%,測試準確率為0.97%,靈敏度為0.99,AUC為0.99。
????????另一項研究使用CNN模型進行特征提取,使用支持向量機(SVM)進行分類階段[22]。采用了多種深度特征步長融合和主成分分析(PCA)。使用MIAS和INbreast兩個數據集,所提出的模型在兩個數據集上的分類準確率分別達到97.93%和96.646%。采用主成分分析法,減少了計算量和執行時間;然而,分類性能并沒有得到提高。
????????Gaona和Lakshminarayanan[23]使用了一種CNN模型,該模型利用DenseNet架構對乳房x線攝影圖像中的乳腺腫瘤進行檢測、分割和分類。??本工作獲得的性能矩陣靈敏度為99%,特異性為94%,AUC為97%,準確度為97.7%。
????????Shen等[24]研究了一組基于CBIS-DDSM數據集乳房x線照片的乳腺癌檢測深度學習算法,涉及單個模型和四個模型。在獨立檢測中,最佳單模型的AUC為88%,而四模型平均的AUC為91%,特異性為80.1%,敏感性為86.1%。此外,還使用了另一個數據集INbreast,其中最佳的單一模型在獨立測試中每張圖像的AUC為95%,而四模型平均將AUC提高到98%,靈敏度為86.7%,特異性為96.1%。
????????相比之下,為了避免早期圖像質量下降,Roy等[25]使用卷積神經網絡(CNN)和連接分量分析(CCA)進行惡性乳腺分割,沒有進行任何預處理。采用k均值(KM)和模糊c均值(FCM)對采集到的圖像進行分割。采用所建議的混合方法,獲得的最佳準確率為90%。最后,[26]中的作者提出了一個基于AlexNet、VGG和GoogleNet的框架,利用單變量技術降低提取特征的維數,提取INbreast數據集上乳房x光片的基本特征。該模型的精密度為98.98%,特異度為98.99%,靈敏度為98.06%,準確度為98.50%。
2.2 Vision Transformer進行圖像分類
????????視覺轉換器(vision transformer, ViT)原理被用作一種分類系統,通過將圖像劃分為固定大小的小塊,將其線性拼接為矢量序列,在傳統的轉換編碼器中進行處理[27]。最近,一組研究人員使用該技術來識別良性和惡性病例,即Gheflati等人基于兩個乳腺超聲數據集檢測了純預訓練視覺變壓器模型和混合預訓練視覺變壓器模型的性能[28],證明了使用視覺變壓器技術在超聲檢查中自動檢測乳腺腫塊的重要性。
????????另一項工作使用CNN模塊提取局部特征,而使用ViT模塊識別多個區域之間的全局特征并改進相關的局部特征[29]。混合模型的準確率為90.77%,召回率為90.73%,特異性為85.58%,F1評分為90.73%。
????????[30]的作者提出了一種基于vit的半監督學習模型,利用超聲和組織病理學數據集,其結果優于CNN基線模型(VGG19, ResNet101, DenseNet201)。該模型達到了96.29%的高精度,f1得分為96.15%,準確率達到95.29%。?
3. 材料和方法
????????本文提出了一種基于殘差卷積網絡和帶多層感知器的變壓器編碼器的混合計算機輔助診斷方法。殘差卷積網絡作為主干網絡用于深度特征生成,TE基于自關注機制用于分類。所提出的深度學習模型需要完成幾個步驟,以提高乳房x光照片中乳腺癌檢測的準確性,如圖2所示。首先,采集到的醫學圖像采用DICOM格式;為了簡單起見,使用內部MATLAB (Mathworks Inc., Boston, MA, USA)代碼將這些圖像轉換為TIFF。然后進行預處理,去除不需要的偽影,增強分割后的乳房圖像的邊界。然后,進行標記、補丁圖像和增強處理。最后,使用生成的patch圖像對所提出的AI模型進行訓練和測試。

3.1 數據獲取和圖像收集
????????使用兩個標準的乳房圖像數據集來開發和評估所提出的深度學習CAD系統。本研究使用了乳腺篩查數字數據庫(DDSM)[31]和DDSM的乳腺成像子集(CBISDDSM)數據集[32]。CBIS-DDSM數據集由放射科醫師修訂;因此,在CBIS-DDSM中刪除了DDSM中一些錯誤或可疑的診斷圖像,使得該數據集適合用于良性或惡性圖像。兩個數據集都有左右乳房圖像的顱尾側(CC)和中外側斜位(MLO)視圖,這意味著每個病例(即患者)有四個視圖:左右乳房序列的兩個MLO視圖和兩個CC視圖。
????????CBIS-DDSM數據集包含1566名患者的6671張乳房圖像。實際上,CBIS-DDSM數據集是DDSM原始數據集的修改和標準化版本,僅包含異常病例(即良性和惡性),而原始DDSM數據集包含2620張掃描乳房x光片圖像,包括正常、良性和惡性病例。在這項工作中,最終創建的數據集共有4091張乳房圖像,包括從DDSM收集的正常病例和從CBIS-DDSM收集的異常病例。每個類別的圖像總數定義為998個正常圖像,461個良性圖像和431個惡性圖像。隨機將生成的數據集分成80%用于訓練,10%用于驗證,10%用于測試。這些分割是分層的,以確保訓練組、驗證組和測試組在每個類中所占的比例相同。來自同一患者的不同MLO和CC視圖保存在相同的訓練、驗證或測試集中,以避免任何準確性偏差并建立可靠的CAD系統。
????????兩個數據集中的所有乳房x光照片都由放射科專家注釋,因為它們是公開的[31,32]。與文獻一樣,領域研究人員總是將原始注釋乳腺圖像的標簽分配到其從該圖像提取的patch roi中[4,9,33]。因此,從數據集元數據中獲取圖像的標簽,并為創建的補丁保留標簽。例如,如果原始圖像具有惡性標簽,則提取的補丁圖像具有相同的惡性標簽,以此類推。此外,這兩個數據集都有每個患者的一些信息,包括乳房密度、左乳或右乳、圖像視圖、異常、異常類型、鈣質類型、鈣質分布、評估、病理和細微信息[31,32,34]。
3.2 數據準備和預處理
????????乳房x光照片是DICOM格式的。在使用乳房x線照片之前,使用MIRCODICOM軟件[35]將收集到的所有圖像轉換為TIFF格式。
????????之所以選擇TIFF格式,是因為它能夠以無損格式保存DICOM圖像,并且可以用于高質量的存檔目的[36,37]。將DICOM圖像轉換為TIFF格式后,進行預處理步驟。在預處理步驟中,去除不需要的偽影特征,然后對乳房圖像的邊界進行平滑處理。為了從每張乳房x射線照片中去除不需要的偽影,使用了圖像閾值分割技術[38,39],這是一種圖像處理分割技術,用于將乳房x射線衰減像素與背景像素分離。事實上,這樣的過程被用來將彩色或灰度圖像轉換為二值格式,以便在整個乳房x光片中輕松區分不同的區域。在閾值處理過程中,將每個圖像像素值與閾值進行比較;如果像素值小于閾值,則變為0(黑色區域或背景);否則,它將變為最大值(白色區域)。
???閾值技術有不同的操作類型,如THRESH_BINARY、THRESH_OTSU和THRESH_TRIANGLE,這些操作類型可以由OpenCV庫提供[38,39]。THRESH_BINARY是一種簡單的閾值分割技術,它依賴于定義的自適應閾值對圖像進行相應的分割,而THRESH_OTSU是基于Ostu的閾值分割技術,自動計算閾值對乳房和背景區域進行分割[38,39]。為了達到消除乳房x光檢查中不需要的信息的目標,進行了一項全面的調查研究。實驗中,發現THRESH_TRIANGLE是最好的[38-40]。三角形算法檢查直方圖的形狀,例如尋找谷、峰和其他直方圖形狀方面[40]。該算法取決于三個步驟來執行。首先,定義并繪制直方圖的最大值bmax和最小值bmin在灰度軸上的直線。其次,估計繪制的直線與直方圖中和
之間的所有點之間的垂直歐氏距離d。最后,根據直方圖與定義線之間的最大距離選擇閾值,生成二值或掩碼圖像,如圖3b-d所示。

數據預處理,提取整個乳房感興趣區域(ROI),并使用自定義內置圖像處理技術去除不需要的信息。(a)原始乳房x線照片,(b)使用THRESH_OTSU算子生成的圖像二值掩碼,(c)使用THRESH_BINARY算子生成的圖像二值掩碼,(d)使用THRESH_TRIANGLE算子生成的圖像二值掩碼,以及(e)應用處理技術后對應的乳房圖像??
????????在將胸部圖像與黑色背景分離方面,THRESH_TRIANGLE算子優于其他算子,如圖3d所示。雖然THRESH_TRIANGLE算子的分割面積比THRESH_BINARY大,但在對Mask圖像進行平滑處理后,在不損失乳房圖像邊界的情況下,可以得到一個很好的分割區域。在獲得乳房圖像的掩模后,利用形態學圖像處理技術,通過“morphologyEx”函數對乳房的邊界進行平滑處理,平滑去除乳房x線照片的噪聲[38]。通過“connectedComponentsWithStats”函數[38],使用連接分量分析(CCA)技術選擇最大的對象,該方法通常可以使用連接分量標記對二值圖像中的blobs進行更詳細的過濾。最后,為了構建沒有不良偽影的乳房圖像的ROI,應用“bitwise and”函數將原始圖像與其關聯的最終二值掩模圖像相乘,如圖3e所示。
3.3 創建補丁
????????為了獲得更準確的學習過程,深度學習模型是基于乳房病變區域而不是使用整個乳房x光片進行訓練的。眾所周知,與乳腺腫瘤大小相比,乳腺圖像的尺寸非常大,因此訓練期間的權值微調過程必須只關注腫瘤區域,以獲得更準確的深度學習參數(即網絡權值和偏差)[33]。在之前的研究中,由于缺乏這樣一個精確的基于補丁的CBIS-DDSM數據集[9,13,33],因此采用了先前的乳房病變檢測程序,從輸入的整張乳房x光片中自動提取乳房病變。然而,在此過程中,為了從整個乳房x光片中生成補丁圖像,采用了補丁提取和增強兩種方法。第一種方法從DDSM數據集中提取正常補丁,第二種方法從CBIS-DDSM數據集中提取異常良性和惡性補丁。
對于正常的補丁提取,需要依次進行如下步驟:
- 對從DDSM收集的每張圖像進行數據預處理后,最終分割后的圖像(或稱為“分割圖像”)準備好了,可以進行下一步操作,即創建一組塊。
- 從每個圖像創建一組256 × 256的補丁。計算所創建補丁的上閾值、下閾值、平均值和方差。這些tiles是從分割圖像中選取的,可能覆蓋了圖像中的不同區域,包括乳腺組織、異常區域(如腫塊、鈣化點等)以及可能的背景區域。
對于不正常的補丁提取,需要依次進行如下步驟:
Step 1: 圖像預處理
- 在從CBIS-DDSM數據集中收集的每個圖像上應用數據預處理步驟。
- 經過預處理后,分割的圖像準備用于創建一組塊。
Step 2: 使用已裁剪的補丁圖像
- CBIS-DDSM數據集中的原始乳腺X光圖像包含由放射科醫生審查過的良性和惡性腫塊的已裁剪補丁圖像。
- 這些已裁剪的補丁圖像被直接使用來創建512 × 512像素大小的切片。
- 選擇512 × 512像素大小是因為已裁剪的補丁圖像的大小各不相同,有的小于這個大小,有的大于這個大小。
Step 3: 對小于512 × 512像素的補丁進行零填充
- 如果已裁剪的補丁圖像小于512 × 512像素,這個補丁會被放在一個512 × 512像素的切片中,起始位置為(0,0)。
- 接著,自動應用零填充(zero padding)過程,以維持所需的固定大小512 × 512像素。
Step 4: 對大于512 × 512像素的補丁進行分割
- 如果已裁剪的補丁圖像大于512 × 512像素,會創建多個切片。
- 切片從左上角開始,沿著水平方向從左到右,以及沿著垂直方向從上到下創建。
- 這個過程是為了避免對生成的異常補丁進行下采樣(down-sampling)。
Step 5: 將每個切片分割成256 × 256像素的tiles
- 經過上述步驟后得到的每個512 × 512像素的切片會被進一步分割成兩個256 × 256像素的tiles。
????????應用這兩個程序后,共創建了15790個補丁圖像,其中正常補丁8860個,異常補丁6930個,其中惡性補丁3348個,良性補丁3582個。該數據集用于訓練和測試所提出的深度學習CAD系統。所有正常的斑塊存放在一個文件夾中,異常的斑塊也存放在另外兩個文件夾中:一個文件夾為良性,一個文件夾為惡性。所有生成的補丁文件名對于正常文件使用' PatientID_View_Side_Tile_Tile-Number.tif '格式,對于異常文件使用' PatientID_View_Side_Cropped_CroppedNumber.tif '格式。?
 ?3.4 數據分割
?3.4 數據分割
????????本研究考慮了所有在CBIS-DDSM數據集中有乳腺腫塊的患者,而正常病例則從DDSM數據集中收集。針對場景A(二元分類問題)和場景B(多類分類問題),采用兩種策略對生成的補丁進行分割。對于場景A(二元分類),生成的數據集如表1所示。
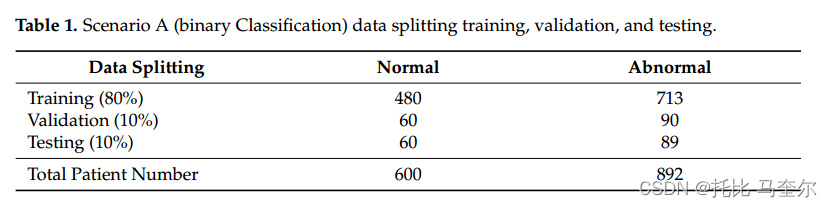 遵循第二種策略為場景B(多類分類)準備數據集。表2顯示了每一組的數據分布:訓練、測試和驗證。
遵循第二種策略為場景B(多類分類)準備數據集。表2顯示了每一組的數據分布:訓練、測試和驗證。

3.5 遷移補丁
????????應用補丁創建過程后,生成的兩個文件夾(命名為“X”和“Y”)保存所有補丁。還使用已創建的具有患者id的CSV文件指導此過程,以便將每個補丁傳輸到目標文件夾:train、val或test文件夾。為了使用第一種策略創建數據集,創建了三個文件夾:train、val和test文件夾,它們分別被命名為“Tr”、“Va”和“Te”。在每個文件夾中,創建了兩個名為“Normal”和“Abnormal”的文件夾。
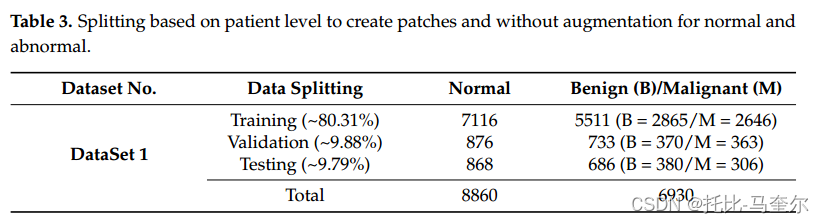
????????為了將“X”和“Y”中的所有補丁轉移到“Tr”、“Va”和“Te”文件夾的子文件夾中,讀取每個補丁的文件名;如果表1中的患者id列表中存在此名稱,則使用行名(“Training”名稱表示將文件傳輸到“Tr”文件夾)和列名將該文件傳輸到正確的子文件夾(“Normal”,“Abnormal”)來復制該補丁。第一個數據集是在沒有應用增強過程的情況下創建的,如表3所示。
?3.6 數據增強
????????數據增強的過程僅在基于患者水平分割數據集后應用于訓練集。在訓練和測試過程中,增強過程對于創建平衡數據集和消除過擬合非常重要。增強補丁的標簽必須與原始補丁圖像保持一致。依賴以下步驟來創建兩個數據集:
????????步驟1:為了擴大訓練集的數量,必須通過基于NumPy函數“flip”應用flip來創建新的補丁。根據兩個返回值,分別在垂直和水平方向上進行兩次翻轉[41](1:執行翻轉;0:取消翻轉)來自一個名為binomial的NumPy函數,該函數負責根據二項分布繪制樣本[42]。二項分布(BD)由
?

步驟二:在原點周圍使用不同角度進行旋轉:[5?,10?,15?,20?]。
????????表3中正常斑塊數量為7116個,惡性斑塊2646個,良性斑塊2865個。首先,為了增加具有額外補丁的良性案例,該過程依賴于從第一個補丁文件開始到最后一個補丁文件,為良性文件夾中的每個補丁創建新的類似補丁來增加原始補丁。這個步驟重復了幾次,直到良性文件夾中的文件總數達到7116。每個補片在補片過程中,應用步驟1和補片步驟2的角度[5?,10?,15?,20?],其中每個補片應用第一圈5?角度,第二圈10?角度,以此類推。同樣的程序也適用于為惡性病例制作額外的貼片。
????????具體來說,對于每個補丁,首先應用步驟1,然后在步驟2中使用了[5°, 10°, 15°, 20°]這四個角度。這意味著每個補丁首先被旋轉5°,然后再次應用相同的增強過程但這次旋轉10°,依此類推,直到所有四個角度都被應用。
????????表4展示了在增強過程后的最終數據集。

????????256 × 256的patch圖像不足以區分良性和惡性病例,因為一些重要的特征在patch之間被劃分。因此,對patch的創建進行了修改,創建了新的patch圖像(400 × 400和512 × 512),而沒有進行增強,增強會取到更大尺寸的良性和惡性特征,不同的是,可疑區域的ROI被分割成400 × 400或512 × 512的切片,而不是將每個區域分割成更小的補丁。表5總結了使用400 × 400和512 × 512補丁大小時新創建的數據集。提高了整體精度,特別是512 × 512補丁大小。
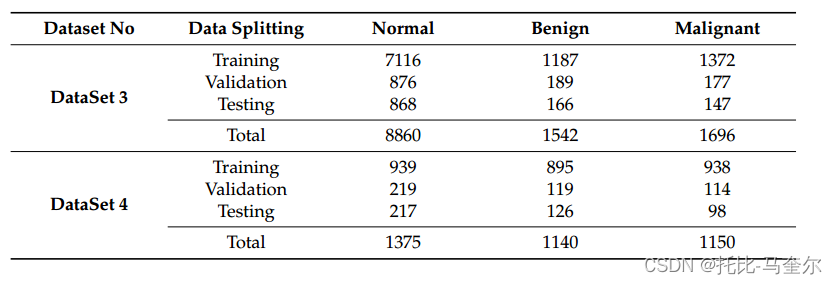
根據患者水平進行分割,創建(400 × 400, 512 × 512)塊,對正常、良性和惡性病例進行增強
3.7 推薦的深度學習模型
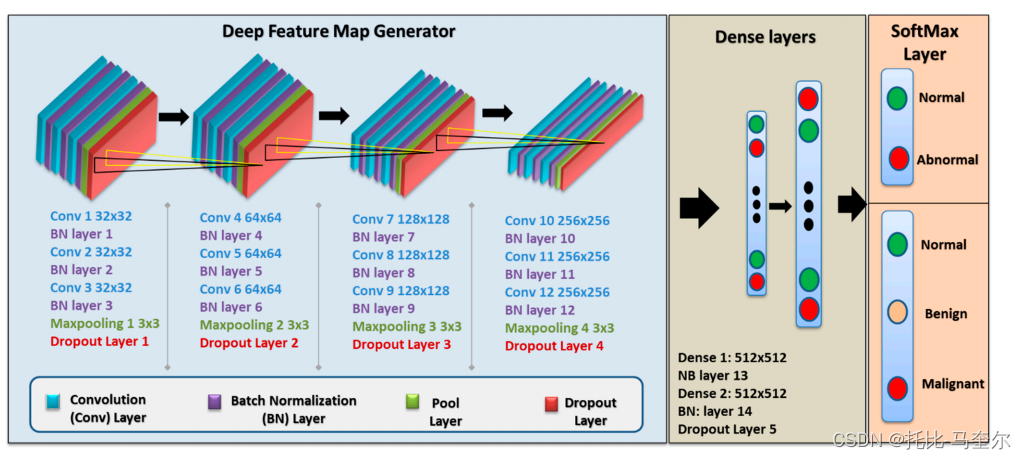
????????首先,一個深度學習模型是由使用改進的深度卷積神經網絡(CNN)模型,而第二個模型主要依賴于基于遷移學習原理的預訓練VGG16。在遷移學習的基礎上,利用預訓練的ResNet50模型。最后,基于這些模型應用Vision Transformer (ViT),因此,一些實驗是單獨基于這三個模型進行的,另一些實驗是使用ViT技術與ResNet50模型一起進行的。
3.8 自定義CNN模型
????????本文的改進模型是通過使用改進的深度卷積神經網絡(CNN)模型來實現的,該模型在一組乳房x光片斑塊上進行訓練,將其分類為正常或異常病例。
????????最終的自定義CNN模型包括一個VGG (Visual Geometry Group)序列型結構,該結構有五個塊,每個塊包含三個帶有小3 × 3濾波器的卷積層,一個最大池化層,最后是一個dropout層。該模型在每一層之后都進行了批歸一化處理,具有正則化效果,加快了收斂速度。應用于每個卷積層的濾波器為3 × 3,激活函數為ReLU, ' same '用于填充,' he_uniform '用于內核初始化,保證輸出的特征映射具有相同的寬度和高度。該模型在所有層中實現的stride和padding值分別為1和0, dropout率為25%。采用隨機梯度下降法,即Adam優化器,這是一種依賴于一階和二階矩自適應估計的方法[43]。
常用的 padding 方式有“valid”和“same”。其中,“valid”意味著不進行任何 padding,而“same”意味著進行足夠的 padding,使得輸出特征圖的空間維度與輸入特征圖相同(不考慮深度或通道數)
“He uniform”是一種常用的初始化方法,基于ReLU(或類似的)激活函數,并根據輸入和輸出神經元的數量來設置權重的初始值。使用“He uniform”或其他合適的初始化方法可以幫助神經網絡在訓練過程中更快地收斂,并可能提高最終的性能。
3.9?基于人工智能的VGG16模型
????????VGG16是一個廣泛參與計算機視覺和機器學習領域分類任務的CNN。實現了基于ImageNet數據集的預訓練VGG16模型,但去除了該模型中的分類層。因此,對于達到最佳性能的二元分類和多重分類,增加了兩個新的分類層。對于二值分類,該模型的分類層分為兩個塊:每個塊由一個具有512個神經元的常規層組成,然后分別添加Batch Normalization層和dropout層,dropout率為50%。最后,多重分類中的分類層有三個塊:每個塊有一個4090個神經元的常規層,然后分別添加Batch Normalization層和dropout層,dropout層的dropout率為50%
3.10 基于人工智能的ResNet50模型
????????ResNet-50是一個50層深度卷積神經網絡,已經應用于圖像識別任務。與預訓練的VGG16模型一樣,本文基于ImageNet數據集對ResNet50模型進行訓練,并刪除了分類層;因此,使用與VGG16模型相同的配置,在該模型中添加了兩個用于二元分類的塊和三個用于多重分類的塊。VGG16包含1.38億個參數,而ResNet50有2550萬個參數,加上ResNet50中應用的配置,使其運行速度更快。?
3.10?基于人工智能的混合ResNet和Transformer Encoder
????????ViT-b16模型將輸入圖像的16 × 16個二維塊線性組合成一維向量,送入由多頭自注意(MSA)和多層感知器(MLP)塊組成的變壓器編碼器,如圖2所示。MSA用于尋找單個輸入序列中每個patch與所有其他patch之間的關系,它采用縮放后的點積注意力,可由式(2)計算:
 ?
?
表示乘積
的方差,其均值為零。此外,乘積可以通過除以標準差
進行歸一化。通過SoftMax函數將縮放后的點積轉換為注意力分數。?
?
????????多層感知器層(MLP)塊被設計為三個塊:每個塊由高斯誤差線性單元(GELU) 40、90個神經元的非線性層、批處理歸一化和dropout層組成,其中所有dropout層的丟棄率為50%。?
4. 實驗結果及討論
4.1?場景A:二元分類:正常與異常
????????對于二值分類,采用自定義CNN、VGG16、ResNet50和混合(ResNet50 + ViT)模型進行比較。使用ImageNet對VGG16和ResNet50的深度學習模型進行預訓練。基于遷移學習策略,研究使用了預訓練的權重。除了VGG16模型中從17開始的層(' block5_conv3 ')到輸出層是可訓練的,其他所有層都是不可訓練的,而ResNet50模型中從143開始的層(' conv5_block1_1_conv ')到最后一層是只能訓練的。為了比較四種模型的最終結果,所有模型上的分類層都是相同的,使用的優化器是Adam。此外,輸出層或分類層使用了不同的單元,但當單元數為512時,準確率最高。學習速率為0.0001,每個模型的epoch數為25。在這種情況下,進行了兩種類型的實驗來比較四種模型的整體性能:一種依賴于單一測試而不應用k-fold交叉驗證技術,而第二種實驗主要依賴于5-fold交叉驗證技術。
????????首先,混合模型的總體準確率達到100%,優于所有其他模型,而VGG16記錄的數值最低,如表7所示。此外,ResNet50錯誤地將一個異常斑塊預測為正常,而VGG16有6個錯誤預測,自定義CNN模型只有4個錯誤預測,混合模型實現了最優值,基于混淆矩陣如圖6所示。?
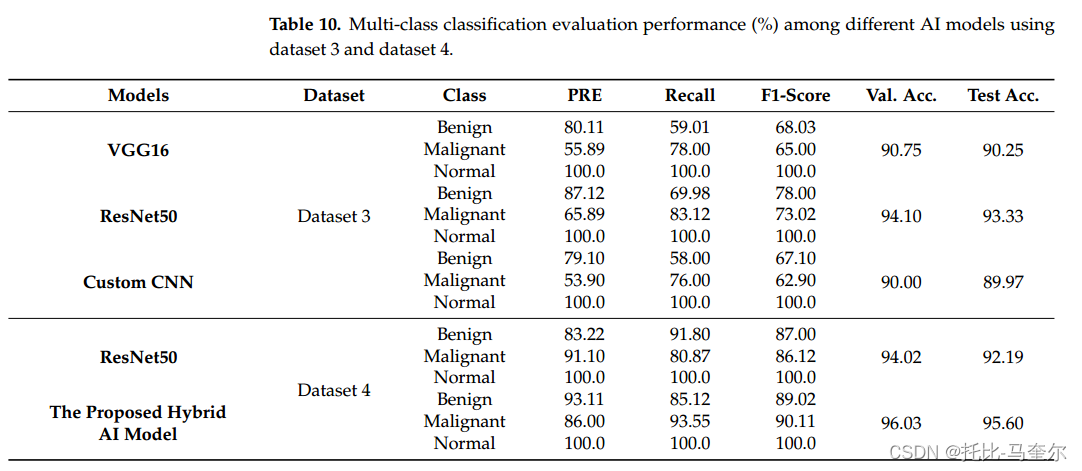
 ?4.2?場景B:多分類:正常、良性、惡性
?4.2?場景B:多分類:正常、良性、惡性
)


——項目介紹)






利用pyqt5實現yolov8目標檢測GUI界面)








