
Temporal Summary Images: An Approach to Narrative Visualization via Interactive Annotation Generation and Placement
- 摘要
- 1 引言
- 2 背景及相關工作
- 2.1 敘事可視化和講故事
- 2.2 顯示面向時間的數據
- 2.3 小倍數和漫畫
- 2.4 注釋可視化
- 3 設計要求和工作流程
- 3.1 工作流程
- 3.2 TSI 示例:1830-2010 年美國移民
- 4 時間布局和數據快照
- 4.1 時間布局
- 4.2 數據快照
- 5 注釋
- 5.1 數據興趣點(POI)
- 5.1.1 POI 類型
- 5.1.2 手動查詢和添加POI
- 5.2 自動創建注釋
- 5.2.1 數據屬性評分
- 5.2.2 確定 POI 分數
- 5.3 注釋放置
- 5.3.1 Top-n排名放置算法
- 5.3.2 基于密度的放置算法
- 6 實施與評估
- 6.1 評估
- 6.1.1 案例一:EpiSimS 仿真
- 6.1.2 案例二:千年宇宙學模擬
- 7 討論
- 7.1 TSI 框架的優點
- 7.2 自動評分數據屬性
- 7.3 更深入、更廣泛地研究快照注釋
- 7.4 當前設計的限制
- 8 結論
- 致謝
- 參考文獻
期刊: IEEE Trans. Vis. Comput. Graph.(發表日期: 2017)
作者: Chris Bryan; Kwan-Liu Ma; Jonathan Woodring

摘要
可視化是一種用于分析和交流復雜、多維和時變數據的強大技術。然而,由于可視化屬性的數量、各種顯著特征以及解釋興趣點 (POI) 所需的意識,在圖表或圖形中手動合成連貫的敘述可能很困難。我們提出時間摘要圖像(TSI)作為探索這些數據并從中創建故事的方法。作為一種可視化,TSI 由三個常見組件組成:(1) 時間布局、(2) 漫畫風格的數據快照和 (3) 文本注釋。為了增強用戶分析和探索,我們開發了許多交互式技術來推薦相關的數據特征和設計選擇,包括自動注釋工作流程。隨著分析和視覺設計過程的融合,生成的圖像變得適合用數據講述故事。為了進行驗證,我們使用 TSI 的原型實現來利用大規模科學模擬數據集進行兩個案例研究。
關鍵詞:敘事可視化、講故事、注釋、漫畫可視化、時變數據。
1 引言
對于那些經常需要從數據集中分析和提取基本信息,然后與其他人交流發現的人來說,可視化可以用作探索性和解釋性工具。盡管已經開發了許多視覺分析方法,但對創建敘事可視化的支持較少。特別是,隨著數據變得龐大、復雜、多維,有時甚至是異構的,手動篩選、識別和突出顯示圖表或圖形的基本方面就成為一項艱巨的任務。如果在探索和分析的過程中,可視化系統建議選擇和標記重要的區域和特征,以便導出在后續任務或演示中使用的數據故事,那將是令人期望的。
為了幫助解決這個問題,我們提出了時間摘要圖像(TSIs),這是一個用于創建多元時變數據集的敘事可視化的框架。從視覺上看,TSI 由三個常見組件組成:(1) 時間布局視圖,例如折線圖或故事情節,(2) 在相關時間步附加的數據快照,以及 (3) 錨定文本注釋。圖 1 顯示了一個 TSI 示例。它簡潔地講述了一個關于美國移民的故事,使用堆疊圖作為時間布局,五張地圖作為數據快照集,以及六個描述性注釋。
本文的重點不僅僅是 TSI 設計師可以制作的最終確定的“演示風格”圖像。相反,我們強調分析和設計過程的融合。為了增強探索,我們貢獻了許多交互式“幕后”技術。它們通過執行兩項任務來協助數據交互和可視化創建:(1) 選擇數據快照的相關時間步長;(2) 提供用戶循環的自動注釋工作流程,以推薦數據興趣點 (POI)展示。本文的大部分內容都集中在這種新穎的注釋支持上,它會自動創建、評分、排名并將數據驅動的注釋附加到顯示器上。在分析過程中,它們會提醒用戶注意顯著的視覺區域和重要的數據特征。如果需要,可以保存推薦的注釋,并隨后在將 TSI 呈現給一般受眾時用于傳達有關數據的關鍵數據觀察結果。
此外,隨著整個探索和構建過程的發生,設計人員會搜索、過濾和編輯要顯示的數據,同時調整其整體視覺外觀。當這兩項任務綜合在一起時,就會有效地出現一個統一的匯總數據故事,強調基礎數據集的重要方面和趨勢。根據作者的目的,進一步風格化組件會產生適合演示或公開展示的圖像。
我們基于本文描述的框架和技術創建了一個原型 TSI 應用程序。為了進行驗證,我們使用大規模科學模擬數據集(分別是疾病模型和宇宙學模型)進行了兩個案例研究。根據領域參與者的反饋,我們的方法對于分析和總結數據集都是有效的。
2 背景及相關工作
相關的先前工作分為兩大類:(1)敘事可視化和講故事作為數據交流的方法,以及(2)TSI 的三個特定視覺組成部分:時變技術、小倍數(也稱為漫畫)和注釋。
2.1 敘事可視化和講故事
Segel 和 Heer 在 [35] 中對敘事可視化進行了分類和評論。他們為此描述了七種特定類型,包括帶注釋的圖表/圖表和漫畫可視化。可以通過優先考慮數據的特定解釋或感知來構建敘事可視化來講述數據故事[19]。
數據講故事的概念本身已在 InfoVis、SciVis 和商業社區中得到強調 [15,23,25,28]。這里的重點是如何利用電影、文學和戲劇敘事慣例來調整可視化效果,以便與廣大受眾進行交流。在[26]中,Lee 等人。主張明確定義數據故事的范圍,并提出基于以下任務的視覺故事講述的三步流程:(1)找到見解,(2)創建一個故事,(3)講述故事。我們將 TSI 流程重點關注前兩點:探索數據和創建演示質量的可視化。
在更廣泛的通信可視化設計背景下,Moere 和 Leuven 在 [32] 中認為,美學構成了可視化的第三個重要約束(除了合理性和實用性之外)。最近的論文重點關注創建信息圖表或演示風格可視化的工作流程方面 [7,34,39,46],盡管大多數論文需要完全手動設計,而不考慮分析任務。雖然某些工具結合了這兩個目標 [16, 36],但它們的設計是針對 TSI 框架所解決的一組不同的任務。
2.2 顯示面向時間的數據
TSI 中最大的視覺組件是用于顯示時變數據的時間布局。選擇的布局取決于作者的判斷力;我們在當前框架中討論的四個選項是用于純數字數據的折線圖和流圖[10],以及用于基于流的分類數據的故事情節[40]和沖積圖[33]。雖然這些是眾所周知的傳統技術(我們因此選擇它們),但還有更多潛在的方法來顯示隨時間變化的數據 [5],這些方法是根據特定數據集或美學設計的。
除了簡單的視覺繪圖之外,多組件系統還可以通過鏈接的顯示或附加的視覺組件來增強時間視圖,通常是為了實現數據分析。例如,STAC [42] 和 PieceStack [43] 系統專注于堆疊圖的分析。 ChronoLenses [44] 是一個基于透鏡的折線圖數據轉換管道。 SemanticTimeZoom 系統 [6] 通過在圖表中結合定性和定量視覺效果來支持數據分析。這些技術支持與底層數據的詳細交互和理解,但這樣做的代價是必須專注于特定的視覺布局(即僅流圖),并且不考慮數據故事講述或呈現。相比之下,TSI 可以顯示多種類型的時間視圖,并使用文本注釋作為傳達定性數據觀察的方式,而不需要 TSI 作者/查看者進行培訓來解釋其含義。
2.3 小倍數和漫畫
小倍數使用一組離散數據增量的視圖(或框架)來顯示一個或多個維度的變化[41]。當這種變化傾向于遵循嚴格的線性數據路徑(即使涉及縮放和過濾)時,該技術可以被定義為敘事可視化的漫畫風格[35]。
之前的工作使用漫畫可視化作為總結或呈現數據的方式[12,45,46]。相反,VizPattern 系統使用漫畫作為創建可視化查詢的界面,以生成數據圖表[21]。最近一篇名為 Graph Comics [7] 的論文使用漫畫來總結網絡隨時間的變化。通過附加文本標題、標簽和注釋來突出顯示時態數據演變的特定方面,從而對框架進行風格化。然而,所有的設計和構建都是由系統用戶手動執行的。
TSI 數據快照組件采用漫畫技術。為了幫助選擇要顯示的快照,我們提出了三種時間步長選擇算法,請參見第 4.2 節。這類似于一些先前的系統(例如[45]),因為時間步長是使用距離和聚類啟發式選擇的。 TSI 作者選擇所需的時間步長選擇技術和所需的數據屬性來進行分段,并且可以手動調整結果或選擇不同的算法,直到找到可接受的結果。
2.4 注釋可視化
對顯著特征的感知理解對于圖形和圖表的理解很重要[18]。基于文本的注釋通過“以圖形方式將”觀看者的注意力指向感興趣的區域來幫助這一過程,并且可用于提出結論并提供數據上下文[35]。
在[20]中,作者定義了專門將可視化數據引用為觀察數據的注釋,而附加注釋提供了視圖本身中未顯示的額外信息。通過草圖創建的注釋被定義為自由格式,在異步、協作環境和新聞/信息圖表設計中尤其重要 [11, 17]。或者,通過查詢底層數據集并引用視覺布局來生成和放置數據驅動的注釋 [20, 22]。
自動創建的數據驅動注釋嘗試識別和標記數據集/可視化最有趣的功能或整體主題。 Google Drive 最近為其電子表格應用程序推出了“語言化”[1],該應用程序創建帶有描述性標題的數據圖表。在[22]中,Kandogan 引入了一個系統來注釋基于點的數據可視化中的集群、異常值和趨勢。 Kong 和 Agrawala 在 [24] 中創建了一種觀察注釋方法,該方法可以標記已創建的圖表的特征和維度,而不引用底層的原始數據值。
與本文特別相關的工作是 Hullman 等人的工作。 [20]。他們通過將價格極值與從數據庫中檢索到的時間相關的新聞報道相匹配來注釋股票市場的時間線。這使他們能夠創建上下文感知的附加注釋。 [14]中使用了類似的方法來注釋地理地圖。相比之下,TSI 框架可以創建附加和觀察類型的注釋,重點是放置。注釋還可以應用于不同類型的時變視覺技術(不僅僅是折線圖)。
3 設計要求和工作流程
TSI 的動機來自與 EpiSimS 疾病模擬團隊的討論(案例研究請參見第 6.1.1 節)。該小組的成員雖然精通流行病研究,但不是可視化專家,并且在使用復雜的視覺分析和設計工具方面經驗有限。根據他們通常的分析需求以及創建圖像供審核所采取的步驟,我們為團隊定義了以下一組特定任務:
T1 沿時空維度的結果。 EpiSimS 仿真輸出數據有兩個主要維度軸。 (1) 疾病傳播發生在流行病增長、高峰和衰退的一段時間內。 (2) 這種傳播發生在一個地理區域內,通常最初通過熱點,然后完全擴散。
T2 通過查詢特征進行數據分析。 EpiSimS 科學家對其領域數據非常熟悉,這指導了他們的探索。他們的主要重點是了解模擬輸入參數和緩解策略如何影響特定興趣點 (POI) 的流行病生命周期行為,例如疫情爆發的高峰或其在人口統計中的分布。這是通過 SQL 或基于表的電子表格函數查詢基礎數據集來完成的。
T3 使用傳統工具進行演示。為了向合作者或一般受眾(例如在會議或論文中)展示結果,需要使用靜態圖(折線圖、地圖等),這些圖是通過 R 或 Python 的 matplotlib 庫等工具創建的。使用圖像編輯軟件將它們組合起來并添加標題。
盡管這些任務是 EpiSimS 團隊特有的,但它們很容易被推廣。從廣義上講,研究人員和圖表設計者可能首先希望快速查看、分析和探索他們的數據以獲取相關特征或 POI。然后,他們用一組視覺元素總結結果以進行演示或講故事。與在沒有指導的情況下手動執行這些任務相反,TSI 框架將它們組合到單個工作流程中,并提供增強分析和圖像構建過程的技術。為了正式證明本文其余部分討論的設計組件和交互技術的合理性,我們首先定義 TSI 框架應遵循的一組準則:
DG1 Temporal-plus 數據視圖。數據集應該在(至少)兩個主要維度軸上可視化:時變域加上一個或多個“其他”維度。從 EpiSimS 特定任務的概括中,空間域被抽象出來;現在它只需要與時間軸正交。
DG2 突出顯示重要元素。應突出顯示重要的數據集特征和 POI,以首先引起創建 TSI 的作者的注意,然后引起觀察完整 TSI 的查看者的注意。
DG3 簡潔的演示視圖。完整或“構建”的 TSI 應適合作為單個、相互連接的靜態圖形進行數據呈現或講故事。在創建過程中,這意味著強調根據作者的喜好設計和配置 TSI 的圖形組件,然后將圖像導出為適合顯示的格式。在可視化理論的背景下,這表明可以使用傳統的或廣泛理解的視覺技術,因為它們更容易被普通觀眾理解。
選擇了三個視覺組件來滿足這些要求。對于 DG1,作者選擇的時間布局顯示隨時間變化的數據視圖。考慮到 DG3,我們使用傳統的時變技術。一組或多組漫畫數據快照顯示了“其他”正交維度。使用漫畫(相對于動畫或類似技術)的原因是 DG3 的靜態圖像方面。為了確保組件鏈接在一起(形成單個、連接的整體圖像),快照會沿著相應時間步長的軌道附加在時間布局上方。為了幫助 TSI 作者選擇要顯示的“最佳”快照,我們貢獻了一組自動時間步長選擇技術。
為了解決 DG2,我們使用文本注釋對時間布局上的重要元素進行圖形指向。數據驅動的注釋會自動創建并附加到新穎的工作流程中的顯示中;它們作為 TSI 設計師的一種引導探索形式,提醒他/她重要的數據特征或視圖中的顯著區域。熟悉數據后,作者可以快速與創建的注釋列表進行交互,以搜索相關屬性、極值和 POI,或者手動查詢數據以創建新注釋。為了在內置 TSI 中向查看者傳達關鍵觀察結果,可以固定并保存選定的注釋。通過這種方式,注釋工作流程具有雙重目的:豐富作者的分析和探索,以及向觀眾傳達發現。由于注釋是基于文本的,因此它們比更抽象的視覺技術(例如[6])具有優勢,不需要解釋培訓,因為相關的 POI 或特征是由注釋的文本明確描述的。
3.1 工作流程
除了簡單地定義一組視覺組件之外,設計指南還暗示必須有一個 TSI 探索和圖像構建的過程。我們在圖 2 中展示了此工作流程,其中記錄了 TSI 作者執行的具體步驟和交互。
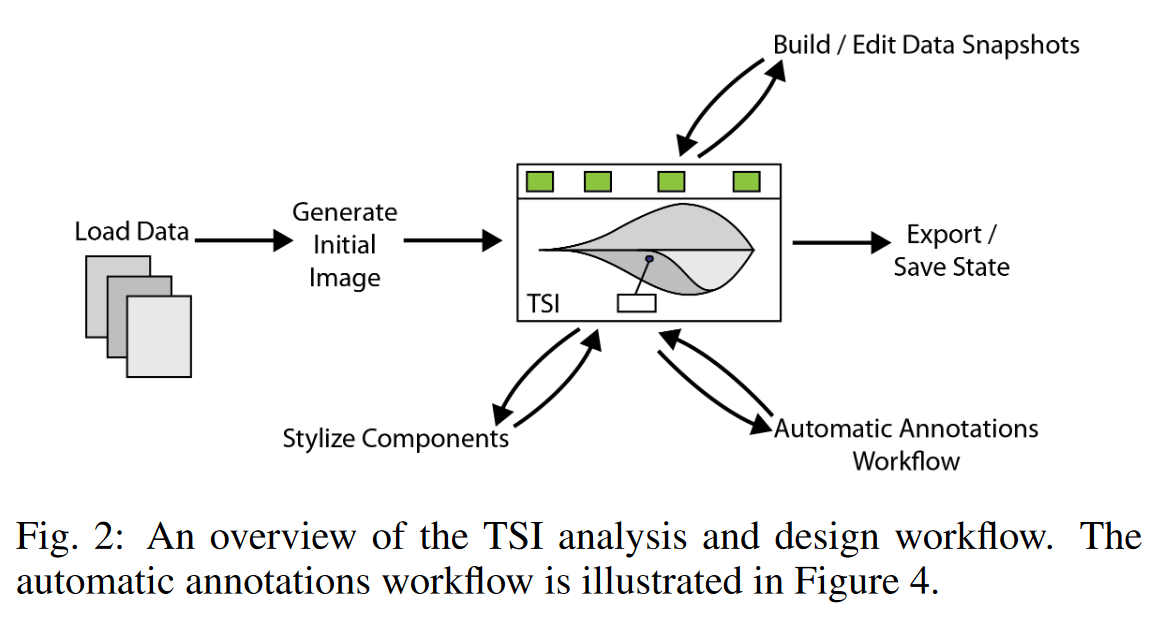
用戶首先加載一組文件。在我們的實現中,除了原始數據之外,這些還可以包括配置選項,例如時間布局、調色板和預先保存的注釋的選擇。這將通過創建時間布局、根據默認(或用戶指定的)時間步長選擇選項選擇一組數據快照以及加載任何已保存的注釋來生成 TSI 的初始視圖。
用戶現在可以執行許多交互。可以通過選擇一組不同的時間步長(為時間步選擇選擇新的啟發式、更改要顯示的數字等)或將它們沿著軌道拖動到不同的時間步來編輯數據快照。還可以加載第二組數據快照并將其附加到第一組數據快照之上(參見圖 10)。
關于注釋,作者可以選擇對他/她重要的屬性和POI類型,并啟動自動注釋工作流程。這將創建一組數據驅動的注釋,并嘗試根據相關性排名將最重要的注釋放置在顯示上。我們貢獻了兩種注釋放置算法。注釋可以單獨進行交互:拖動、編輯、刪除和過濾,或者用戶可以編輯基礎屬性/POI 分數以批量重新排序、過濾、選擇注釋并將其放置在顯示上。
除此之外,我們的系統還提供了手動數據查詢(通過 SQL)和注釋創建的接口。我們還讓設計師對視覺組件進行風格化和調整:設置顏色、字體樣式、編輯默認文本和標簽、調整組件大小等。當作者對視覺輸出感到滿意時,他/她可以將完成的 TSI 導出或保存為圖像文件或保存其當前狀態以供以后重用。導出的 TSI 旨在作為數據集的匯總,因為它包括沿重要維度軸的視圖(通過時間布局和數據快照)。保存的注釋集可幫助向 TSI 觀眾講述趨勢或亮點。
3.2 TSI 示例:1830-2010 年美國移民
我們通過示例用例說明了構建的 TSI,如圖 1 所示。該 TSI 講述了 1830 年至 2010 年美國移民趨勢的故事(數據來自 [3, 4])。時間布局顯示了每個十年基于原籍國(或地區)的移民百分比。每個時間步長總計為 100%,這是通過使用堆疊圖直觀地傳達的。愛爾蘭、俄羅斯和墨西哥的圖層已用明亮的顏色突出顯示。在此之上,數據快照是地圖;每個州根據其主要移民人口進行顏色劃分。
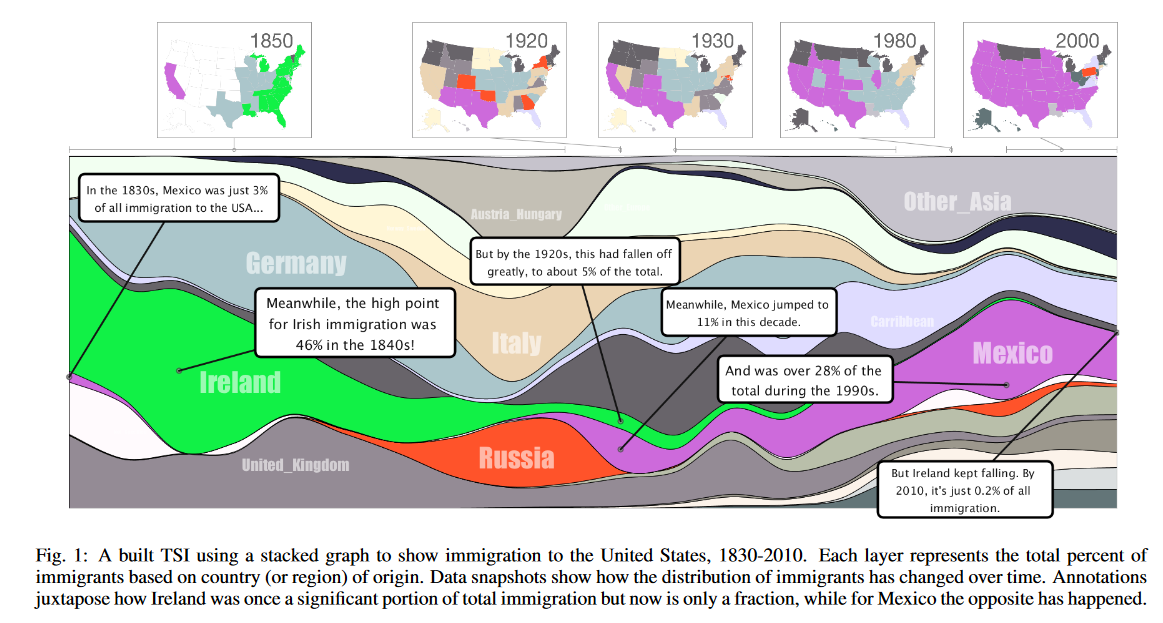
堆疊圖和地圖快照的結合顯示移民在兩個方面發生了巨大的演變:人們來自的國家和他們要移居的國家。為了強調愛爾蘭和墨西哥的趨勢相互鏡像,選定的注釋用有趣的文本描述了這兩個數據層。它們吸引了觀眾的注意力:愛爾蘭移民曾經幾乎占美國移民總數的一半,但目前已減少到只有一小部分。與此同時,墨西哥移民卻走向了相反的方向。
4 時間布局和數據快照
現在,我們對 TSI 的前兩個可視化組件進行高級概述:時間布局和數據快照。
4.1 時間布局
時間布局顯示數據隨時間變化的視圖;它位于中央并從左到右水平定向。這里可視化的選擇取決于 TSI 作者的判斷力,因此應該仔細考慮。對于獨立的數字時間序列(例如股票價格),折線圖是一個簡單的選擇。如果顯示時間數據大小是一個重要的考慮因素,例如在移民示例中(圖 1),則可以使用流圖。對于分類或流數據,應使用故事情節或沖積圖等技術。
我們當前的實現使用這四種技術作為時間布局的選項。由于它們是眾所周知的傳統技術,因此在向普通觀眾演示時應該是有效的。然而,從理論上講,任何與時間相關的可視化技術都可以用于該組件,盡管更復雜或抽象的視圖會引入潛在的解釋問題。
4.2 數據快照
數據快照是一組視覺框架的漫畫,顯示與時間布局正交的數據集視圖。在移民示例中,這是數據的制圖視圖。快照附加到時間布局上方的軌道,其位置與其關聯的時間步長相對應。它們旨在提供對數據集時間演變的額外見解,并幫助提供數據的整體摘要。與時間布局一樣,幀中使用的可視化技術的選擇由作者決定。我們當前的 TSI 原型將數據快照存儲為圖像文件集;檢索相關的內容并將其附加到顯示中。在案例研究(第 6.1 節)中,使用了空間和體積渲染,但根據上下文,更抽象或投影映射可能更合適。這些可以包括散點圖、條形圖、熱圖、視頻劇照和其他降維技術。
顯示的數據快照集取決于一組選定的時間步長。為了幫助 TSI 作者選擇合適的快照,我們提供了三種自動時間步長選擇技術:模時間步長索引、熵閾值選擇和分層分段。要使用其中之一,用戶首先在數據集中選擇一個或多個時間屬性。啟發式應用于屬性集并返回一組時間步長。圖 3 顯示了這些技術如何為示例屬性選擇時間步長:折線圖中的數值數據向量。對于每個選定的時間步長,都會檢索相關快照圖像并將其附加到 TSI。
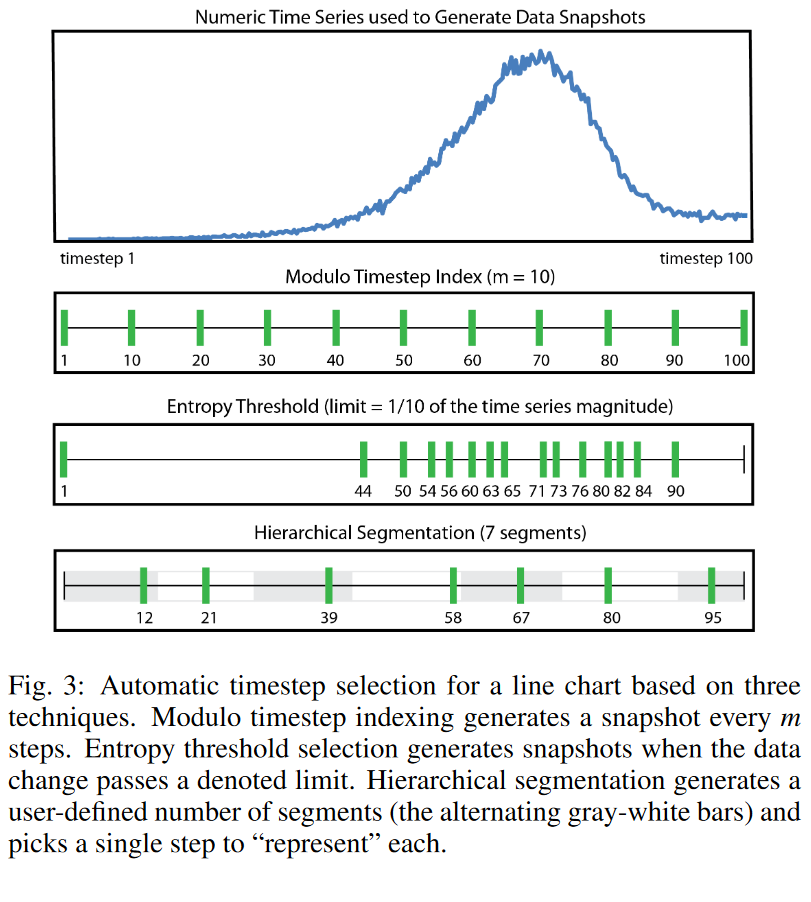
模時間步長索引 這是模擬中采用的典型時間步長選擇過程,其中數據定期保存;即,每 m 個步驟選擇一個快照。這將返回具有恒定步長的線性離散數據快照選擇。
熵閾值 熵是在每個連續時間步長(或時間步長集)之間計算的。當總體熵超過定義的限制時,選擇該時間步長。該技術強調基于大規模數據變化的時間步長選擇,而不是一般平坦或穩定的數據。
分層分段 計算每個時間步的增量(變化)。將分層聚類應用于增量以在所有時間步上生成分層分段,然后對要返回的所需分段數量進行切割。根據所需的統計指標(例如平均增量值或標準差)為每個片段選擇“代表性”時間步長。我們目前使用平均增量值來確定這一點。
我們在這里注意到這三種技術都是基于數據抽象的;也就是說,快照選擇不鏈接到所選的時間布局技術或當前顯示的注釋集。這樣做的原因是,作者可能會根據與這些組件無關(獨立)的屬性來選擇快照時間步長。使用的數據屬性可能不會顯示在時間布局中,并且僅包含在專門用于快照選擇的數據集中。
加載后,可以根據設計者的偏好以交互方式拖動、刪除或重置附加的快照。如果啟發式給出的結果不足,則可以嘗試另一個啟發式,或者可以完全手動選擇時間步長。
5 注釋
注釋直觀地指向顯著的數據特征和/或元素。它們是 TSI 的第三個組成部分,覆蓋并錨定到時間布局上。
TSI 框架的一個主要方面是其自動注釋支持的工作流程,如圖 4 所示。本節介紹此工作流程。我們首先解釋什么是數據 POI 以及如何利用它們來創建注釋。創建后,將對注釋進行評分和排名。在展示之前,它們必須正確定位。這需要過濾并僅選擇排名最高且相關的注釋,為此我們引入了兩種放置算法。與系統交互(例如縮放、平移、刪除不需要的注釋或更新屬性的分數)會觸發注釋工作流程中的先前步驟,強制注釋重新排名,并可能導致顯示新注釋并刪除舊注釋。這形成了一個用戶循環,可以審查排名注釋并用于指導分析和探索。所需的注釋可以固定在顯示屏上,以解釋相關結果或突出顯示數據的各個方面。
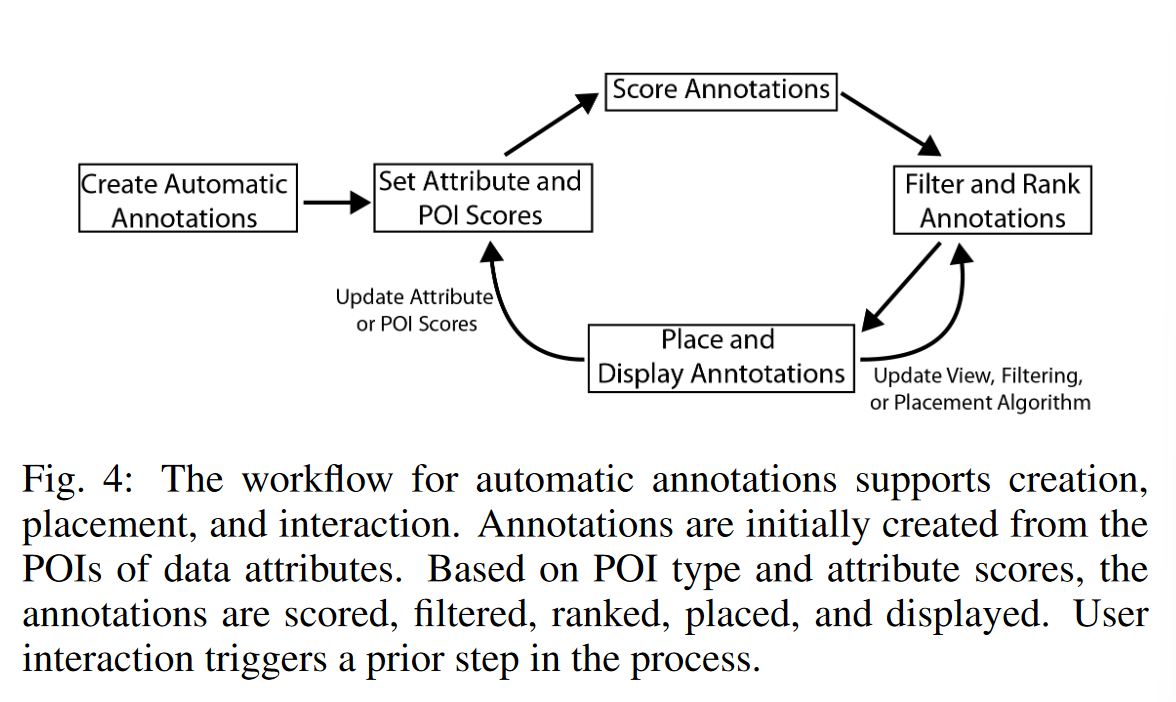
5.1 數據興趣點(POI)
注釋描述了底層數據集的一個方面,我們將其稱為興趣點 (POI)。相反,POI 可以使用單個注釋來描述。 POI 是數據屬性的特性,例如值極值或變化、開始和停止、分類、狀態或流變化、穩定區域等。盡管單個 POI 可以應用于數據屬性的多個元素(例如,平坦區域可能跨越多個時間步長),但它仍然指的是數據的單個特征。因此,我們僅使用術語 POI 而不是 ROI(感興趣區域)進行描述。
如第 2.4 節所述,注釋可以是附加的,也可以是觀察性的,具體取決于它們是否引用可視化數據或向視圖添加附加信息。我們的系統允許手動創建附加注釋或針對時間布局中未顯示的背景數據屬性進行查詢;它們還可以加載到用于構建 TSI 的初始數據集中。
5.1.1 POI 類型
圖 5 顯示了可從三種類型的數據屬性中提取的觀測 POI 的示例:數值向量、故事情節和沖積圖。每個顯示的 POI 對應一個注釋。

數值向量 POI 時間序列可以使用折線圖(如圖 5a 所示)或堆積圖來顯示。用于顯示圖表中每條線(或堆積圖層)的數據是獨立的數字數組(也稱為數值向量)。通過檢查向量的值特征,可以提取數值 POI:數字的第一個和最后一個實例、最小值和最大值、平坦區域和斜率變化(在一組時間步長上增加和減少)。
故事情節 POI 圖 5b 顯示了故事情節中 POI 的示例。特定于線路的 POI 是分類的,因為它們描述了一條線路(或一組線路)的當前狀態。例如,線路 L1 從 A 組的步驟 1 開始,在步驟 5 更改為 B 組,并在步驟 6 結束。或者,數字 POI 描述線路進入和離開的組。 A 組從步驟 1 開始,大小為 2(包含兩條線),在步驟 2 和 3 處最多為 3,依此類推。因此,A 組的數值大小向量將為 [2, 3, 3, 1, null, null]。
沖積圖 POI 圖 5c 標注了沖積圖中的示例 POI,這些示例顯示了組之間隨時間變化的數據流。通過將流的一部分分離并轉到另一個組,或者通過將來自另一個組的流合并到當前流中,可以改變流的大小。這些 POI 表明該群組的規模已發生變化。它們都是數字的和分類的,因為流量會改變數值量,并且流量所經過的組在質量上是不同的。當步驟之間的流量恒定時,它要么處于穩定區域(即,不會分裂或合并到其他組),要么因為整個流量會一起更改組。還可以提取基于組大小的數字 POI,就像對故事情節組所做的那樣。
來自組合屬性的 POI 對于每個示例可視化,我們注意到可以從“組合屬性”中提取 POI。組合屬性是兩個或多個數據屬性通過邏輯運算符組合在一起的情況。在故事情節示例中,組[B AND C]的最大大小在步驟5處為3。行[L1 AND L3]首先在步驟5處進入組B; line [L1 OR L3] 在步驟 4 中執行此操作。行還可以與組組合以形成組合屬性,例如,當行 L1 屬于組 A 的一部分時,行 [L1 AND A] 是行 L1 的子集。
5.1.2 手動查詢和添加POI
由于數據屬性是數值向量或分類向量,因此可以以允許 SQL 查詢的方式存儲它們。我們的 TSI 實現使用 HSQLDB 緩存 [2] 存儲數據屬性,并包含一個查詢接口。這允許搜索未自動提取的更復雜的 POI,以及訪問時間顯示中未顯示的背景數據屬性。在宇宙學案例研究(第 6.1.2 節)中,一位參與者在他的數據集中指出,他將使用此功能來識別數據屬性為其最大值的 50% 的時間步長。運行查詢時,它會根據其應用的時間步長和屬性創建單個注釋。
如果手動查詢僅引用背景數據,則會創建附加注釋。這種類型的注釋錨定到它所引用的時間步長。附加注釋也可以在 TSI 初始化時加載,并用于引用超出直接數據集范圍的“外部”或上下文信息。有關示例,請參閱附錄。
5.2 自動創建注釋
在圖 4 中,注釋工作流程的第一步是“創建注釋”。只需解析每個數據屬性(和組合屬性)并識別其 POI,即可完成一次。每個 POI 都會創建一個注釋。然而,存在一個問題,即這會生成大量注釋。可能數量太多,無法簡單地附加到 TSI。我們的解決方案只是顯示最相關或最重要的內容。
為了確定哪些注釋是“重要的”,我們使用每個創建的注釋都有一個分數的概念,以單個數值表示。不僅如此,POI 和數據屬性都有自己的分數。為了計算注釋的總體分數,將其相關屬性和 POI 的分數相乘:
s c o r e a n n o t a t i o n = s c o r e a t t r i b u t e ? s c o r e P O I score_{annotation}=score_{attribute}\cdot score_{POI} scoreannotation?=scoreattribute??scorePOI?
這樣,每個注釋都有自己的分數。一旦對創建的全套注釋進行評分,就可以將它們簡單地排序到列表中。排名最高的注釋被認為是最重要的。 (我們給予手動查詢和加載的附加注釋盡可能高的分數/排名,因為它們被認為對用戶來說是重要的,因為它們是手動創建/加載的。)
作為對兩個自動注釋進行評分和排名的示例,請考慮得分為 50 (scoreA = 50) 的數據屬性 A 和得分為 25 (scoreB = 25) 的屬性 B。表示屬性全局最大值的 POI 得分為 10 (scoremax=10)。有了這些值,表示 A 最大值的注釋的分數將為 500,而 B 的分數將為 250。排名按總體分數進行,因此注釋 MaxA 將排在 MaxB 之上。
在顯示之前,對排名的注釋列表進行過濾。一些注釋被丟棄,因為它們當前無法顯示在視圖上。如果用戶放大了部分顯示,則無法顯示當前窗口之外的注釋。或者,應用的過濾器可以隱藏某些 POI 類型而不顯示。當注釋作為顯示候選被刪除時,列表中排名較低的注釋會向上移動。根據剩余列表選擇注釋并將其放置在時間布局上。然而,首先,我們討論如何確定自動注釋分數。
5.2.1 數據屬性評分
我們實施的系統包括一個界面,用戶可以在其中設置數據屬性和 POI 類型的分數。可以通過組合兩個當前選定的屬性在此對話框中創建組合屬性。屬性分數還可以保存到配置文件中,以便在加載時應用,然后根據需要進行調整。雖然我們當前的系統僅支持手動屬性評分,但可以自動導出屬性分數并根據數據集屬性創建組合屬性。對此的討論請參見第 7.2 節。
5.2.2 確定 POI 分數
與數據屬性一樣,POI 類型可以由用戶手動評分。在第 5.2 節開頭的評分示例中,POI 類型“最大”的得分為 10(scoremax = 10)。該 POI 被視為“全局”,因為每個屬性只有一個最大值。 (即使最大值發生在多個時間步上也是如此。值是相同的。)全局 POI 包括“最大值”、“最小值”、“第一個”和“最后一個”等特征。
但是,局部最大值又如何呢?對于數字屬性,這些可能會出現多次;每個實例都是一個 POI。直觀上,較小的極值應該比較大的極值給予較小的權重,并且它們的特定 POI 和后續注釋分數應該較低。一些時間序列壓縮算法使用這種假設來對極值進行加權。使用距離函數(例如其他極值之間的絕對距離)確定局部極值權重;然后從壓縮線上丟棄非常低權重的點。為了對本地 POI 進行加權,我們使用[13]中壓縮算法的修改版本,該算法已擴展到對斜坡和平坦區域進行加權(其中較大的斜坡和平坦區域具有更高的權重)。
為了將本地 POI 權重轉換為 POI 分數,我們對該屬性的本地 POI 權重的整體集合進行歸一化。例如,如果局部最大值的 POI 分數設置為 5 (scorelocal max = 5),并且某個屬性具有三個壓縮權重分別為 28、120 和 200 的局部最大值,則相應的 POI 分數為 0.7、3 和 5 。
本地 POI 也存在于分類數據屬性中。作為故事情節中本地 POI 的示例,首先考慮一條線可以在組內停留多個時間步長。在圖 5b 中,線路 L1 在步驟 5 處從組 A 轉到 B,即“組變更”POI。其權重基于 L1 在離開之前在 A 組中停留的時間;時間越長意味著重量越高。沖積圖 POI 可以進行類似的加權,只不過權重還必須根據 POI 相關時間步長的組整體流量進行縮放。
5.3 注釋放置
創建注釋、評分、過濾和排名后,可以將它們放置到時間布局上。根據注釋的類型(無論是附加注釋還是觀察注釋),可以通過五種方式將其錨定到視圖(圖 6)。這些由注釋映射到的時間步長和屬性以及時間布局的選擇決定。觀察注釋可以映射到單個 (x,y) 點、固定在一個方向但在另一個方向上具有一系列位置的點,或者在兩個維度上都有一定范圍的點。附加注釋直接引用一個時間步長(或一組時間步長)。
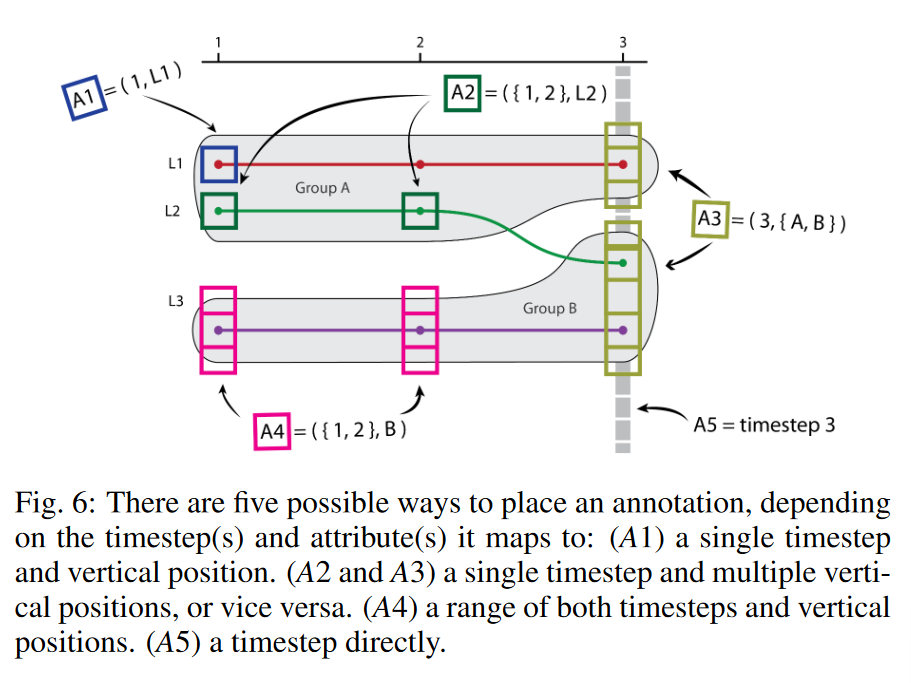
為了確定注釋如何在時間布局上定位,我們提供了兩種放置算法(附錄中提供了偽代碼)。第一種稱為 top-n 排名放置算法,僅根據排名選擇要顯示的注釋。如果用戶只關心查看得分最高的注釋(也許將他/她的分析集中在特定屬性或 POI 類型上),則該算法通過始終將它們附加到顯示來很好地發揮作用。
第二種算法稱為基于密度的放置算法,旨在在顯示器上分布注釋,同時防止顯示器變得混亂。它通過在時間布局上方應用權重字段并使用貪婪放置策略來嘗試放置注釋來實現此目的。先前放置的注釋會對字段施加權重,因此如果排名較低的注釋低于其可能錨點的閾值,則可能無法放置它們。
5.3.1 Top-n排名放置算法
該算法將注釋的排序列表和數字 n 作為輸入。它在第 n 個位置進行剪切,然后將剩余的注釋集放置在最“突出的位置”。
注釋最突出的位置由以下邏輯確定:對于僅映射到時間步的附加注釋,注釋錨定在該時間步的 x 位置以及時間布局頂部和視圖窗口頂部之間的中間位置。如果注釋映射到單個 (x,y) 位置,則使用該點。如果它映射到多個時間步長,則選擇中間的時間步長作為 x 位置。確定 y 點取決于注釋映射到的數據屬性。如果是單條線(例如折線圖或故事情節),則使用該線的 y 位置。對于一組線,使用中間位置的線。如果注釋映射到具有垂直高度的圖層或組(例如流圖圖層或故事情節組),則選擇在該時間步具有最大垂直高度的組并使用其中間 y 位置。如果屬性映射到包含線和組的組合屬性,則使用線最中間的 y 位置。
排名前 n 的放置算法的優點是僅顯示得分最高(即“最重要”)的注釋,并在其最顯著的位置進行顯示。但是,當多個注釋錨定到同一 (x,y) 位置時,這有時會導致遮擋。如果用戶對此感到困擾,他/她可以將注釋錨點拖動到其他可用位置來解決此問題。
5.3.2 基于密度的放置算法
在密度算法中,放置在視圖上的每個注釋都會對其周圍區域應用權重。更重要的注釋(得分更高的注釋)對其直接區域有更大的影響。如果某個區域附近沒有注釋,并且其得分高于該區域中字段的密度權重,則可以附加得分較低的注釋。具有多個高分注釋的區域將對周圍區域施加很大的權重,從而防止顯示的該部分顯示附近的低分注釋并變得混亂。圖 7 顯示了使用此算法嘗試放置四個注釋的示例。
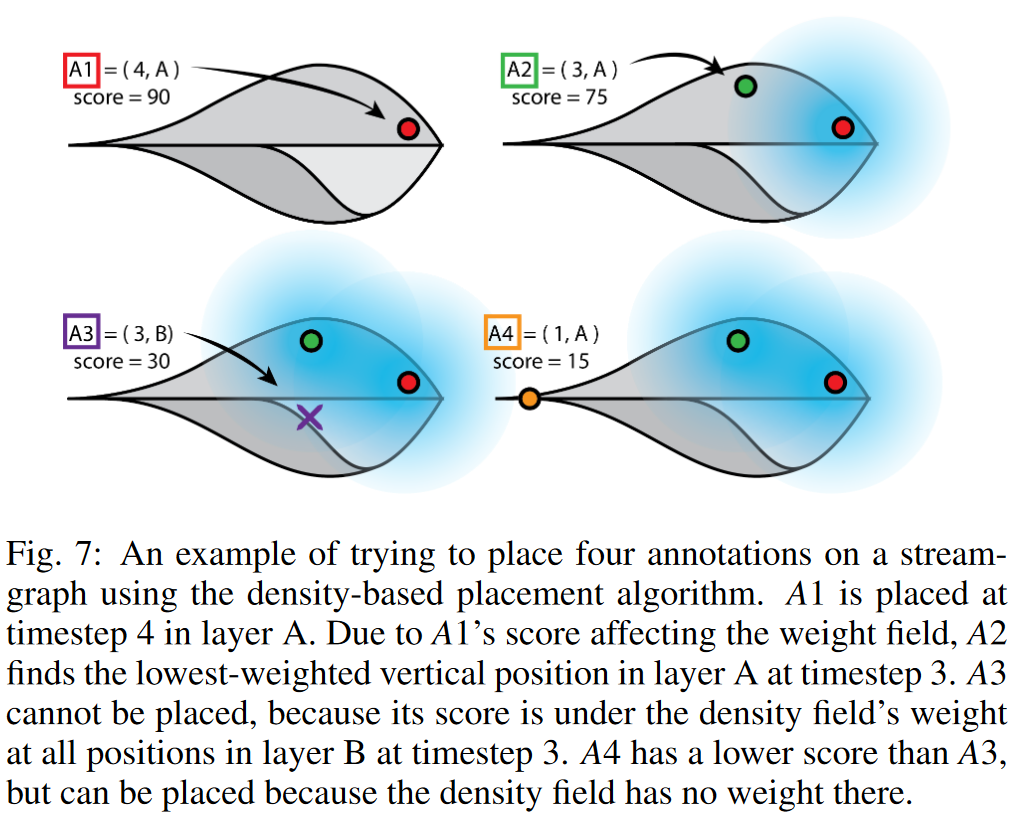
該算法的工作原理如下:從排名最高的注釋開始,根據其“突出位置”放置它。使用其得分對周圍區域應用核密度估計[37]。分布函數可以是用戶定義的,但我們發現正態分布和線性分布都效果很好。接下來,開始迭代注釋列表。對于允許放置的每個潛在 (x,y) 點,選擇密度場中權重最低的點。如果它的分數大于該位置的字段權重,則將注釋放置在視圖上并將其分數應用于密度字段。如果注釋可以均勻地放置在多個 (x,y) 位置,請選擇最接近其“突出位置”的一個。繼續迭代,直到到達列表末尾或直到所有剩余注釋都低于字段的最低閾值分數(用戶定義的數字)。
當用戶更新視圖窗口時,可能顯示的注釋列表將被重置并重新過濾,因此之前由于另一個注釋的權重而被刪除的注釋現在可能會顯示。當用戶縮放和平移時間布局時,這允許注釋“彈出”并填充新區域。該技術的另一個特點是,當交互發生時,未固定到單個 (x,y) 位置的注釋可以“滑動”到 TSI 的權重較小的部分。如果用戶不喜歡某個注釋,則刪除它可以讓排名較低的注釋出現在其空出的空間中。
6 實施與評估
我們已經實現了一個 TSI 原型應用程序,用 Java 和Processing 編寫。對于時間布局,它允許顯示折線圖、流圖和故事情節。數據快照存儲為圖像文件,并根據選定的時間步長進行檢索。
注釋顯示為通過彈簧連接到其錨點的文本框。力導向布局可確保文本框實現良好的分布并且不會相互遮擋。為了風格化 TSI,可以禁用力方向并將文本框拖動到首選位置。對于每種 POI 類型,我們在生成注釋時使用默認的“漂亮打印”句子,但這些句子可以進行編輯。
手動創建的注釋默認為最高等級,因此始終放置它們(除非在當前視圖窗口之外)。注釋也可以“固定”到顯示屏上。我們的系統允許用戶在可用的 (x,y) 位置之間拖動注釋的錨點。基于密度的放置算法的權重參數可以調整,包括權重分布半徑和字段的最低閾值分數。用戶認為不重要的 POI 和屬性可以被刪除或將其分數設置為零。這可確保任何引用注釋將在排序列表中排在最后,并且首先顯示得分較高的注釋。
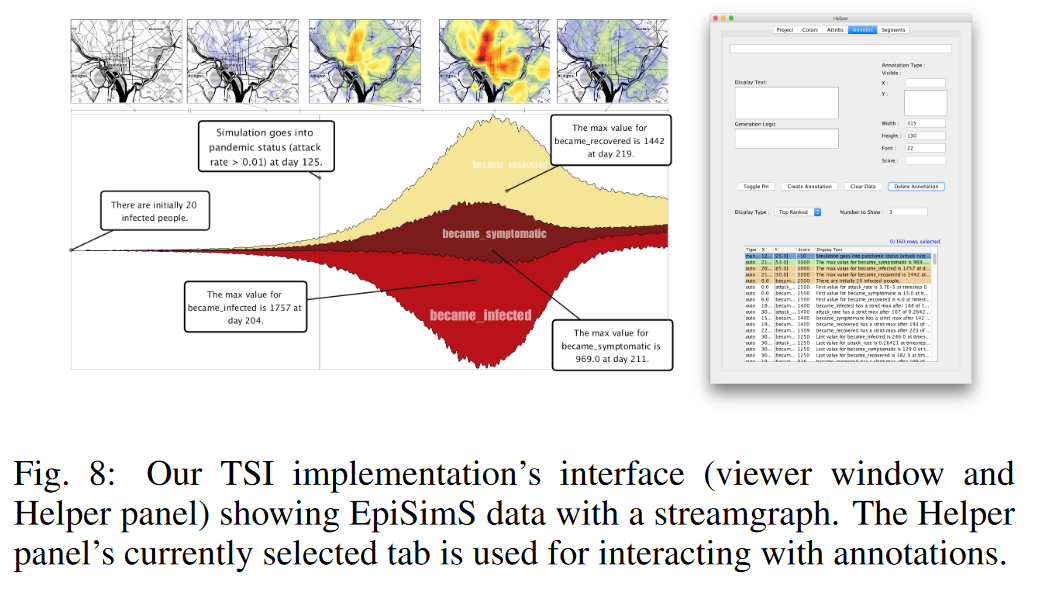
除了主 TSI 視圖之外,我們的原型還包括一個單獨的 Helper 面板(如圖 8 所示)。該面板處理大多數系統交互,例如選擇放置算法或編輯數據快照邏輯。它還顯示所有創建的注釋的列表(甚至是未顯示在顯示屏上的注釋),以允許檢查和搜索可以固定查看的特定注釋類型。
6.1 評估
為了驗證我們的框架并演示如何“在野外”使用 TSI,我們使用科學數據集進行了兩個案例研究。第一個是由 EpiSimS 團隊的三名成員通過兩次會議完成的:一名擁有 20 多年經驗的程序員和統計學家,以及一名三年級博士后物理學家。第二個案例研究是由六名宇宙學研究人員進行的:與三名研究生和一名博士后學者進行一次會議,并對研究生進行兩次單獨的在線訪談。在這兩項研究中,參與者與我們的系統進行交互并構建了 TSI(盡管在線會議只是演示)。根據反饋和觀察,我們認為 TSI 可以有效地幫助領域用戶分析數據并創建簡潔的敘述性可視化。
6.1.1 案例一:EpiSimS 仿真
EpiSimS 是一個可擴展、隨機、基于代理的美國傳染病模型[30]。根據傳播率、潛伏期、蚊子數量和反應機制等輸入參數,將疾病引入易感人群,并通過媒介之間的相互作用進行傳播。在正常(非 TSI)工作流程中,團隊成員選擇一組輸入參數并運行模擬實例。為了檢查輸出數據屬性,他們通常使用 R 或 matplotlib 等傳統工具創建折線圖和/或空間視圖。
通過 TSI,這些觀點被結合在一起。圖 8 顯示了該研究第一階段構建的 TSI(數據來自 [31])。流圖顯示了三個重要的時間疾病屬性。數據快照顯示疾病的空間演變。通過排名前 n 的放置算法,該團隊確定了三個時間屬性的最大極值,并將它們的注釋固定到視圖上,同時注釋還注明了初始感染播種值(被感染的 POI 類型為“First”)屬性)。最后,手動查詢的注釋標志著該模擬轉變為“流行病”狀態。
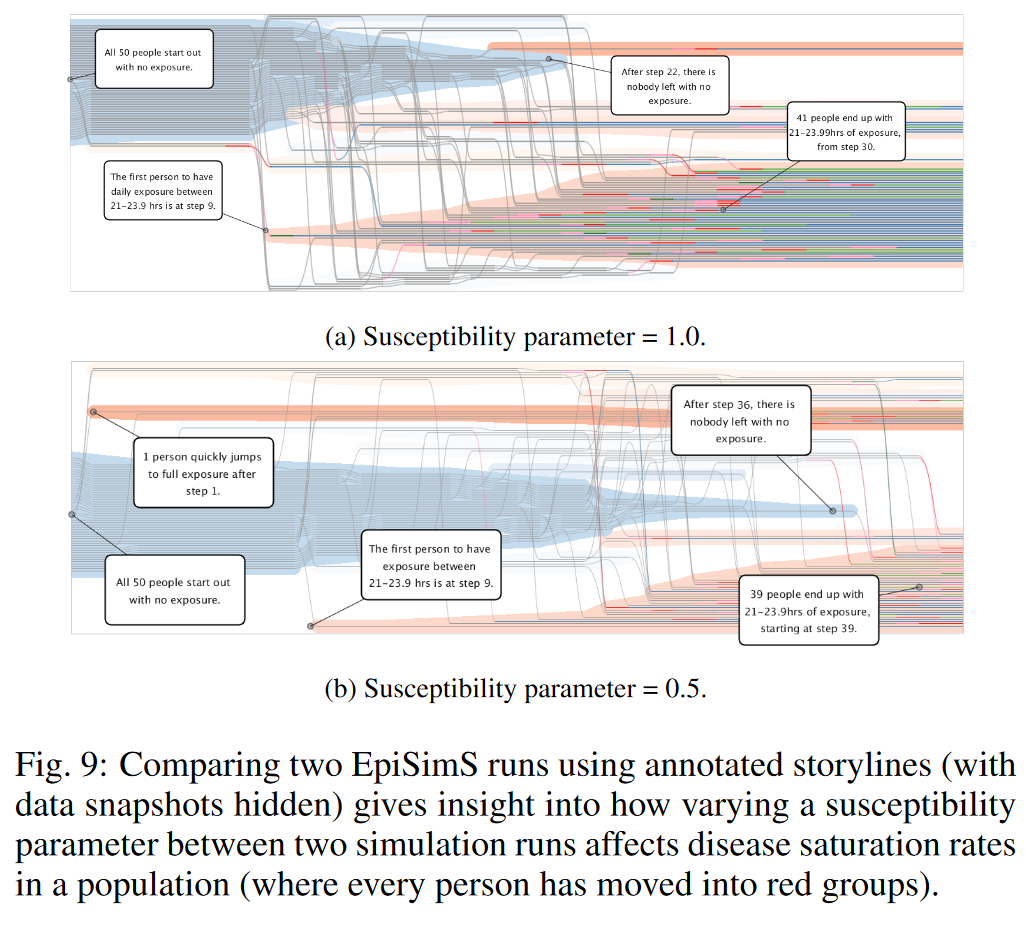
在圖 9 中,我們展示了兩個基于故事情節的 TSI。創建這些是為了展示如何使用密度放置算法來幫助解釋復雜繪圖中的視覺特征。在這種情況下,兩個模擬輸出會相互比較。由于篇幅限制,對這些 TSI 的討論可以在附錄中找到。
根據在構建 TSI 和使用系統的兩次會議期間與 EpiSimS 團隊成員的討論,我們收到了有關 TSI 工作流程許多方面的反饋,總結如下:
對于數據匯總和演示:“我喜歡這些時間匯總圖像。他們很容易獲得反饋。對于流感,我們可能對一組產品線感興趣,但對于蚊媒疾病,我們可能對其他產品感興趣。將快照放在頂部可以讓您了解地理情況以及疾病的發展方向。” “這有很多好處。這些是我想放在出版物中的照片。”
對于注釋工作流程:“注釋有助于指出我關心的內容。我需要知道,目前有多少人被感染?死了多少人?” “自動生成注釋對于快速查看何時發生重大變化非常有幫助。”
對于基于流圖的 TSI,團隊使用 top-n 排名放置算法來探索數據。 “快速看到亮點是件好事,因為你可以縮小想要進一步探索的范圍。真是個好主意,非常有用。”由于疾病相對一致的傾斜行為,密度放置算法對于流圖示例(圖 8)沒有被視為有用。 “對于其他[密度]放置技術來說太簡單了。”相反,它的實用性是針對故事情節人物,因為故事情節人物在視覺上更加復雜。 “很高興看到何時以及發生了什么重大變化,并記錄行為何時發生。這樣探索起來更容易。”
6.1.2 案例二:千年宇宙學模擬
ΛCDM 宇宙學模型,例如千年模擬 [27, 38] 涉及宇宙的結構和形成。對于第二個案例研究,我們分析了發生的星系特性 [8]。對于數據集,我們檢索了附加到六個最大合并樹的主要祖先分支節點的星系。對于這些星系,我們觀察兩個重要的屬性:恒星質量(SM)和恒星形成率(SFR),它們可用于顯示結構和形成行為趨勢。它們發生在一個重要的全宇宙“天文 POI”的背景下,標志著從物質主導時代到紅移約為 2 的暗能量主導時代的轉變。
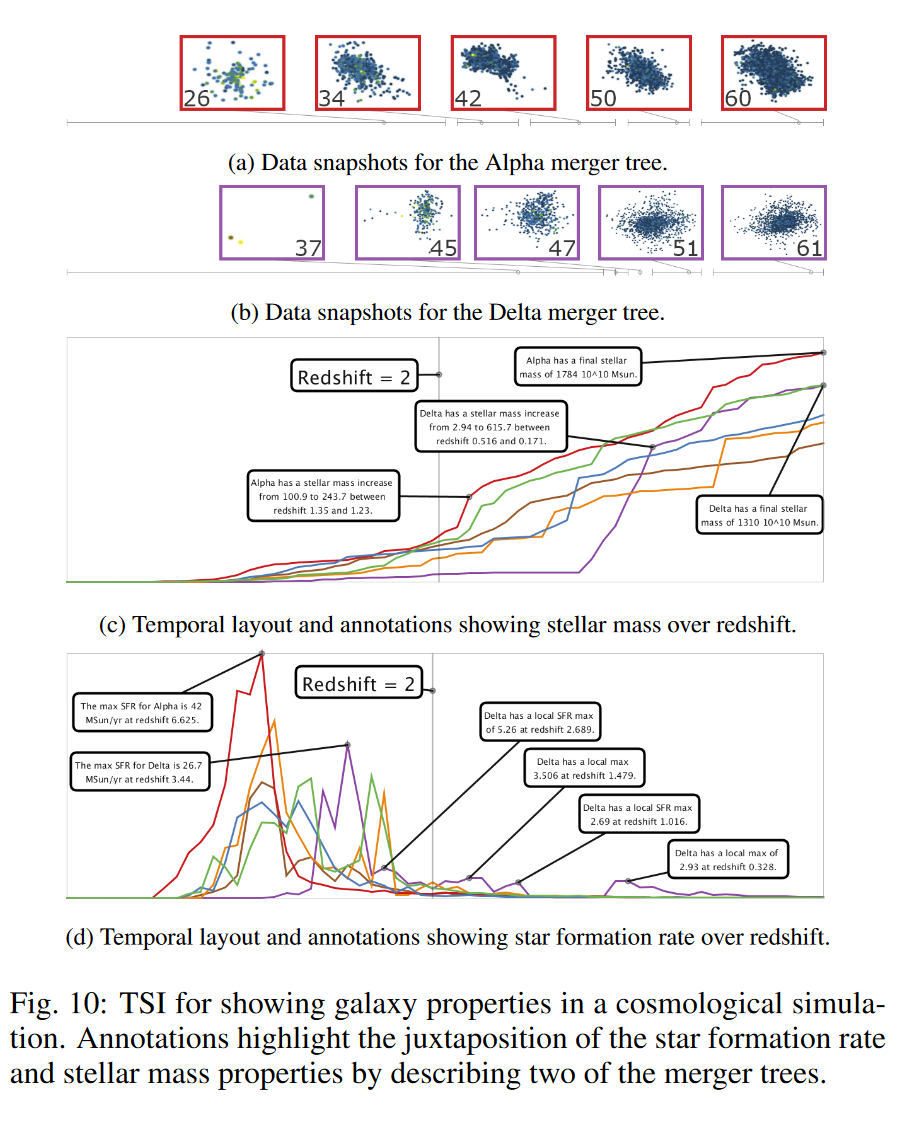
圖 10 顯示了本研究的 TSI。折線圖顯示了六個選定合并樹的紅移上的 SM 和 SFR。兩組數據快照突出顯示了 Alpha 和 Delta 合并樹的空間形成。對于這兩個折線圖,redshift = 2 處的附加注釋標記了“天文 POI”。其他注釋突出顯示了 Alpha 樹和 Delta 樹的顯著極值(紅色和紫色線)。
并置 SM 和 SFR 折線圖突出顯示了星系特性如何在紅移 = 2 注釋的兩側表現出重要的行為變化。對于 SM 來說,大部分增長發生在暗能量主導的時代(紅移 = 2 的右側)。注釋標記了 Alpha 樹和 Delta 樹的快速增加和最大值。 Delta 樹顯示出特別有趣的 SM 斜率快速增長(即斜率變化),從紅移 0.516 到 0.171。在 SFR 圖表中,大多數活動發生在紅移 = 2 的左側。Alpha 樹上的注釋強調它有一個大峰值,但隨后在模擬的其余部分下降。 Delta 的最大峰值也出現在紅移 = 2 的左側,但注釋指出其右側有多個局部峰值,其中一個進入暗能量主導時代。這發生在紅移 0.171 處,這與 SM 快速增加的時間段一致。這種奇怪的行為可能需要對達美航空的原始合并樹數據進行進一步調查(正如研究參與者所指出的)。
宇宙學參與者的反饋和討論比 EpiSimS 團隊更加復雜。雖然大多數人喜歡 TSI 框架,并將其技術視為對正常工作流程的改進,但一位在線會議參與者表示,他不相信 TSI 方法能夠滿足他的需求。談到觀察注釋,他認為“標記這些只會使圖像變得混亂。”但其他用戶卻有不同的感受;他們的評論整理如下:
自動注釋能夠給出數據的初步感覺:“這些注釋非常適合提供快速的順序,例如數量級估計。”對于更微妙或派生的興趣點,一名參與者會轉而進行查詢。 “[那么]手動查詢非常有用。我根據圖表尋找的東西變化很大,單個系統涵蓋所有標準可能是不合理的。”這得到了另外兩名用戶的響應,他們認為注釋可能難以顯示數據 POI 的潛在意義或推理:
一位參與者喜歡能夠在兩種放置算法之間切換:“所以我喜歡注釋放置的靈活性。我認為,如果您想要及時標記某個事件,并評估其中的數字或特征,那么排名靠前的注釋尤其有用。”
在將 TSI 與其領域工具(主要是 R 和 Python)進行比較時:“社區中我們很難找到顯示事物演化圖表的好方法。這對于在論文中顯示數據肯定有用,而不是我們通常使用的數據。”特別是,TSI 提供的一個優勢是他們專注于講故事:“我喜歡創造性地添加快照和/或圖中注釋的想法。這些東西可以幫助講述一個故事,具體取決于你想要展示或理解的具體內容。”
7 討論
根據設計過程和案例研究的反饋,關于 TSI 框架的當前狀態和我們的原型實現,有很多可以討論的要點。
7.1 TSI 框架的優點
TSI 旨在匯總至少具有兩個強維度軸的數據,其中一個始終假定為時間軸。雖然這將框架限制為時間相關的數據集(使用當前實現的四個時間布局選項),但存在大量通用和特定領域的數據集,可以利用我們的工作流程進行可視化創建和分析。
這兩個案例研究的參與者都指出,他們認為注釋指導了他們對數據的分析感知,并且 TSI 的“呈現”方面非常具有視覺吸引力和說服力。而李等人。有人質疑單一工具是否應該結合分析和設計過程[26],根據 TSI 框架的設計要求集和案例研究參與者的反饋,我們認為對于這個問題空間來說這是合理的。在這方面,TSI 比 R 或 Python 等簡單繪圖更強大,因為它利用交互式和分析工作流程,向用戶推薦快照和注釋。通過構建可視化數據故事的最終結果,它比純粹為數據分析而設計的高度復雜的技術或多組件方法具有優勢。
在 TSI 中有意使用傳統(甚至簡單)視覺組件是一個額外的優勢。通過不引入新穎的視覺表示,構建 TSI 進行演示的作者知道潛在受眾沒有固有的學習曲線,特別是因為注釋是基于文本的,并且可以專注于分析和總結數據。
7.2 自動評分數據屬性
如第 5.2.1 節所述,我們當前的系統僅支持手動屬性評分。但是,可以根據數據集屬性自動導出屬性分數。當屬性數量擴大到使個人評分變得困難或耗時的數量時,這可能特別有用。為了自動對時間序列進行評分,基于距離的度量(例如歐幾里德距離、明可夫斯基距離或曼哈頓距離)可以測量每個向量之間的相似性;還有類似的技術分類數據[9]。每個數據屬性可以根據其與數據集中其他屬性的總體相似性進行評分。其副產品是可以將特別相似的屬性組合起來形成組合屬性。自動評分的另一種方法是使用數據熵或幅度度量來衡量數據集的整體變化或波動性,并據此對屬性進行排名。組合屬性還可以通過組合具有相似分數的屬性來形成。
7.3 更深入、更廣泛地研究快照注釋
目前,我們計劃以三種方式擴展我們的注釋創建流程,超越系統當前使用的基于 POI 的時間標記。我們可以通過“更深入”、“更廣泛”以及將注釋與數據快照集成來做到這一點。更深入意味著我們將包含信息指標或線索,以幫助解釋每個創建的注釋的重要性(宇宙學案例研究的參與者指出缺乏這一點)。范圍更廣意味著包括系統可識別的更多類型的 POI,例如統計或派生指標。我們還計劃允許 TSI 作者保存手動 POI 查詢,稍后可以檢索這些查詢以生成自定義注釋,就像 SQL 中的存儲過程一樣。
最后,計劃將注釋與數據快照更緊密地集成。實現此目的的一種方法是允許“數據快照注釋”,其中數據快照幀可以直接附加到時間布局。這種類型的注釋可以充當顯示器上特定數據屬性的“放大”數據正交視圖。
7.4 當前設計的限制
雖然 TSI 建議注釋和數據快照時間步長,但對于大多數其他系統交互,幾乎沒有用戶指導。也就是說,設計者必須明確選擇選項,例如用于時間布局和數據快照的技術,以及適當的調色板應該是什么。
然而,這里的一個假設是 TSI 作者熟悉基礎數據集。因此,他們可以簡單地選擇當前在其他繪圖工具中使用的相同視圖,并利用 TSI 框架提供的優勢。雖然像 Show Me [29] 這樣的推薦系統可以有效地向用戶建議新的視覺投影,但該論文的作者指出,一旦用戶“確定”了一組首選視圖,此推薦功能的使用就會顯著增加滴。因此,如果用戶知道哪些一般類型的視圖適合其數據,那么缺乏對此類設計選擇的建議就可以忽略不計。
TSI 也沒有為選擇要顯示的最佳數據快照數量等問題提供指導。顯然,選擇太多會使顯示混亂(我們的實現根據顯示的數量縮小快照,但有最小大小限制)。如果顯示中附加了太多注釋,也會發生同樣的混亂情況。然而我們注意到,雖然這樣的問題可以通過不同的時間步選擇和放置算法來解決,但我們的系統可以輕松地允許用戶交互式地修改這些組件的約束。如果視圖混亂,他們可以更改必要的設置以清除顯示并解決此類問題。
雖然從美學角度來看,我們當前的 TSI 編輯選項大多被認為是通過案例研究反饋來“勝任任務”,但我們正在研究如何擴展用戶調整和設置視圖樣式的方式。最近一篇描述 GraphCoiffure 系統的論文 [39] 提出了一組改進用戶工作流程以創建圖形網絡的演示風格圖像的技術;類似的方法可以集成到我們的系統中,以提高靈活性并加快設計過程。
最后,盡管(正如一位案例研究參與者所總結的)注釋放置算法“似乎運作良好”,但我們目前的結果和反饋都是通俗的。缺乏正式的評估是當前的限制,我們計劃進行全面的可用性研究,以確定最佳的使用實踐和策略。
8 結論
我們提出了時間摘要圖像,這是一種通過交互式探索過程進行解釋性可視化的新方法。通過利用“幕后”技術來協助用戶分析和設計,我們簡化了為復雜或多維數據集創建敘事可視化的過程,幫助彌合數據探索和講故事之間的差距。
TSI 是一種適合許多數據集的分析和總結技術,我們提供了其在一般領域和科學領域中的使用示例,以及驗證我們方法的領域用戶反饋。未來的工作將集中于成熟和改進我們實施的框架,并將其擴展到新的功能和技術。
致謝
作者衷心感謝加州大學戴維斯分校 VIDi 實驗室的 Annie Preston (apreston@ucdavis.edu) 在宇宙學案例研究中提供的幫助。這項研究由 INGVA/LANL、美國國家科學基金會(通過撥款 DRL1323214、IIS-1528203 和 IIS-1320229)以及美國能源部(通過撥款 DE-FC02-12ER26072)部分贊助。本文中使用的千年模擬數據庫以及提供在線訪問這些數據庫的 Web 應用程序是作為德國天體物理虛擬觀測站 (GAVO) 活動的一部分而構建的。
參考文獻








)









?)

