目錄
Dubbo通訊協議
Dubbo負載均衡策略
RPC和HTTP有什么區別?
讓你設計一個RPC框架,如何考慮數據序列化問題?
Dubbo 是一款高性能、輕量級的開源?RPC(遠程過程調用)框架,主要用于構建分布式服務和微服務架構。
要說 Dubbo 運行流程就不得不先來了解一下 Dubbo 的核心組件了,因為 Dubbo 的交互流程是和核心組件息息相關的。
Dubbo 核心組件有以下幾個:
-
服務提供者(Provider):暴露服務的應用,通過 Dubbo 框架將自身的服務接口及實現注冊到注冊中心。
-
服務消費者(Consumer):調用遠程服務的應用,從注冊中心訂閱所需的服務,然后通過遠程調用消費服務。
-
注冊中心(Registry):集中管理服務的地址信息,服務提供者和服務消費者均在此注冊或訂閱服務信息。常見的注冊中心有 ZooKeeper、Nacos 等。
Dubbo 運行流程如下圖所示:
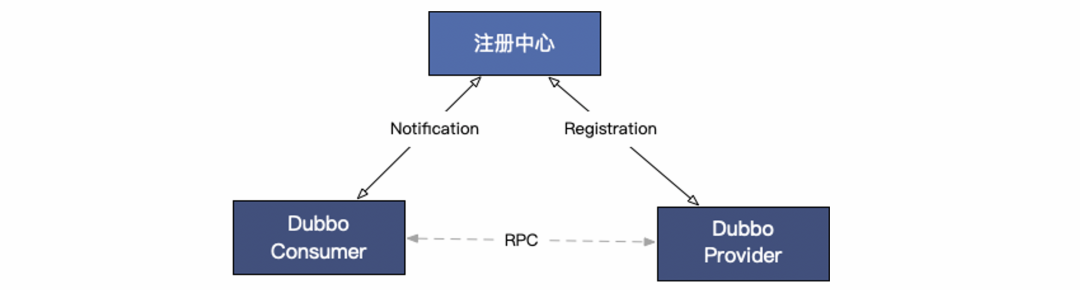
它的執行流程如下:
-
服務提供者會將實例(URL 地址)注冊到注冊中心,注冊中心負責對數據進行聚合(健康檢測)。
-
消費者從注冊中心讀取地址列表并訂閱變更,每當地址列表發生變化,注冊中心將最新的列表通知到所有訂閱的消費者實例。
-
消費者得到服務實例之后,通過 Dubbo 內置的負載均衡策略,選擇其中的一個節點,之后使用 RPC 的方式與服務提供者建立連接,并進行通訊和服務調用。
更詳細的調用流程如下:

Dubbo通訊協議
Dubbo 框架提供了自定義的高性能 RPC 通信協議:基于 HTTP/2 的 Triple 協議和基于 TCP 的 Dubbo2 協議。除此之外,Dubbo 框架支持任意第三方通信協議,如官方支持的 gRPC、Thrift、REST、JsonRPC、Hessian2 等,更多協議可以通過自定義擴展實現。這對于微服務實踐中經常要處理的多協議通信場景非常有用。Dubbo 框架不綁定任何通信協議,在實現上 Dubbo 對多協議的支持也非常靈活,它可以讓你在一個應用內發布多個使用不同協議的服務,并且支持用同一個 port 端口對外發布所有協議。

通過 Dubbo 框架的多協議支持,你可以做到:
-
將任意通信協議無縫地接入 Dubbo 服務治理體系。Dubbo 體系下的所有通信協議,都可以享受到 Dubbo 的編程模型、服務發現、流量管控等優勢。比如 gRPC over Dubbo 的模式,服務治理、編程 API 都能夠零成本接入 Dubbo 體系。
-
兼容不同技術棧,業務系統混合使用不同的服務框架、RPC 框架。比如有些服務使用 gRPC 或者 Spring Cloud 開發,有些服務使用 Dubbo 框架開發,通過 Dubbo 的多協議支持可以很好的實現互通。
-
讓協議遷移變的更簡單。通過多協議、注冊中心的協調,可以快速滿足公司內協議遷移的需求。比如如從自研協議升級到 Dubbo 協議,Dubbo 協議自身升級,從 Dubbo 協議遷移到 gRPC,從 HTTP 遷移到 Dubbo 協議等。
Dubbo負載均衡策略
目前 Dubbo(3.X)內置了如下負載均衡算法如下:
-
Weighted Random LoadBalance(加權隨機):默認負載均衡算法,默認權重相同。按權重設置隨機概率。缺點:存在慢的提供者累積請求的問題,比如:第二臺機器很慢,但沒掛,當請求調到第二臺時就卡在那,久而久之,所有請求都卡在調到第二臺上。
-
RoundRobin LoadBalance(加權輪詢):借鑒于 Nginx 的平滑加權輪詢算法,默認權重相同,按公約后的權重設置輪詢比率,循環調用節點。缺點:同樣存在慢的提供者累積請求的問題。
-
LeastActive LoadBalance(最少活躍優先+加權隨機):背后是能者多勞的思想,活躍數越低,越優先調用,相同活躍數的進行加權隨機。活躍數指調用前后計數差(針對特定提供者:請求發送數 - 響應返回數),表示特定提供者的任務堆積量,活躍數越低,代表該提供者處理能力越強。使慢的提供者收到更少請求,因為越慢的提供者的調用前后計數差會越大;相對的,處理能力越強的節點,處理更多的請求。
-
Shortest-Response LoadBalance(最短響應優先+加權隨機):更加關注響應速度,在最近一個滑動窗口中,響應時間越短,越優先調用。相同響應時間的進行加權隨機。使得響應時間越快的提供者,處理更多的請求。缺點:可能會造成流量過于集中于高性能節點的問題。
-
ConsistentHash LoadBalance(一致性哈希):確定的入參,確定的提供者,適用于有狀態請求。當某一臺提供者掛時,原本發往該提供者的請求,基于虛擬節點,平攤到其它提供者,不會引起劇烈變動。
-
P2C LoadBalance(隨機選擇兩個節點+連接數較小):隨機選擇兩個節點后,繼續選擇“連接數”較小的那個節點。對于每次調用,從可用的 provider 列表中做兩次隨機選擇,選出兩個節點 providerA 和 providerB,比較 providerA 和 providerB 兩個節點,選擇其“當前正在處理的連接數”較小的那個節點。
-
Adaptive LoadBalance(自適應負載均衡):在?P2C?算法基礎上,選擇二者中 load 最小的那個節點,是一種能根據后端實例負載自動調整流量分布的算法實現,它總是嘗試將請求轉發到負載最小的節點。
RPC和HTTP有什么區別?
RPC(Remote Procedure Call,遠程過程調用)和 HTTP(Hypertext Transfer Protocol,超文本傳輸協議)都是用于服務間通訊的,它們主要區別如下:
-
概念和使用場景不同:
-
RPC:RPC 是一種通信模式,允許一個程序在另一個地址空間上執行遠程計算過程,使得客戶端調用遠程服務就像調用本地方法一樣。
-
HTTP:HTTP 是一個應用層協議,用于在客戶端和服務器之間傳輸文本、圖像、視頻等超媒體資源,通常用于 Web 應用之間的通信。
-
-
傳輸數據不同:
-
RPC:RPC 通常基于二進制數據傳輸,可以使用更高效的序列化方式(如 Protobuf、Thrift)進行數據交換。
-
HTTP:HTTP 使用文本協議,請求和響應數據通常是基于文本格式(如 JSON、XML)進行傳輸。
-
-
傳輸效率與性能不同:
-
RPC:因為 RPC 通常使用更高效的二進制序列化(如 Protobuf、Thrift),減少了數據傳輸的體積,且由于其針對性的設計,往往在性能上更為優越,特別是在大量小數據包的傳輸場景。
-
HTTP:傳統上使用文本格式如 JSON 進行數據交換,這可能導致更大的數據包和更多的序列化/反序列化開銷,但在 HTTP/2 中引入了頭部壓縮和多路復用,提升了效率。
-
讓你設計一個RPC框架,如何考慮數據序列化問題?
數據序列化需要考慮的以下問題:
-
性能問題:選擇高性能的序列化庫至關重要。二進制序列化(如 Protocol Buffers, Apache Thrift, FlatBuffers)通常比文本格式(如 JSON、XML)更高效,因為它們占用的空間小,序列化和反序列化的速度更快。對于高性能要求的場景,應優先考慮這些二進制格式。
-
安全性:在序列化過程中,應考慮數據的安全性,避免敏感信息的泄露。可以采用加密序列化內容、過濾敏感字段或使用安全的傳輸層協議(如 TLS/SSL)來增加安全性。
-
兼容性:良好的版本兼容性是長期維護 RPC 框架的關鍵。設計時要考慮向前和向后兼容,即新老版本的序列化庫應能互相理解和處理對方生成的數據格式。可以采用預留字段、版本標識符等機制來支持這一點。
-
跨語言支持:RPC 框架往往需要支持多種編程語言,因此選擇一種跨語言的序列化方案是必要的。Protocol Buffers、Apache Thrift、Avro 等都是很好的選擇,它們提供了多種語言的編解碼庫。
-
可擴展性:設計時應考慮到未來可能增加的數據結構和字段,序列化方案應易于擴展,支持動態字段、自定義類型等特性。
-
可配置性:允許用戶根據實際需求選擇或切換序列化策略。例如,對于對性能要求極高的場景,用戶可以選擇最高效的序列化方式;而對于調試或日志記錄,可能會偏好人類可讀性更好的格式。
-
異常處理:在序列化或反序列化過程中可能會遇到錯誤(如數據損壞、不兼容的版本等)。框架應能優雅地處理這些異常,并提供清晰的錯誤信息,幫助開發者診斷問題。



)









?)





