6.1 使用文本數據
????????文本是常用的序列化數據類型之一。文本數據可以看作是一個字符序列或詞的序列。對大多數問題,我們都將文本看作詞序列。深度學習序列模型(如RNN及其變體)能夠從文本數據中學習重要的模式。這些模式可以解決類似以下領域中的問題:
- 自然語言理解;
- 文獻分類;
- 情感分類。
????????這些序列模型還可以作為各種系統的重要構建塊,例如問答(Question and Answering,OA)系統。
????????雖然這些模型在構建這些應用時非常有用,但由于語言固有的復雜性,模型并不能真正理解人類的語言。這些序列模型能夠成功地找到可執行不同任務的有用模式。將深度學習應用于文本是一個快速發展的領域,每月都會有許多新技術出現。我們將會介紹為大多數現代深度學習應用提供支持的基本組件。
????????與其他機器學習模型一樣,深度學習模型并不能理解文本,因此需要將文本轉換為數值的表示形式。將文本轉換為數值表示形式的過程稱為向量化過程,可以用不同的方式來完成,概括如下:
- 將文本轉換為詞并將每個詞表示為向量;
- 將文本轉換為字符并將每個字符表示為向量;
- 創建詞的 n-gram 并將其表示為向量。
????????文本數據可以分解成上述的這些表示。每個較小的文本單元稱為token,將文本分解成 token 的過程稱為分詞(tokenization)。在Python 中有很多強大的庫可以用來進行分詞一旦將文本數據轉換為 token序列,那么就需要將每個 token 映射到向量。one-hot(獨熱)編碼和詞向量是將 token 映射到向量最流行的兩種方法。圖6.1總結了將文本轉換為向量表示的步驟。

????????下面介紹分詞、n-gram 表示法和向量化的更多細節。
6.1.1 分詞
????????將給定的一個句子分為字符或詞的過程稱為分詞。諸如spaCy等一些庫,它們為分詞提供了復雜的解決方案。讓我們使用簡單的Python函數(如split和list)將文本轉換為 token。
????????為了演示分詞如何作用于字符和詞,讓我們看一段關于電影Thor:Ragnarok 的小評論。我們將對這段文本進行分詞處理:
????????The action scenes were top notch in this movie. Thor has never been this epic in the MCUHe does some pretty epic sh*t in this movie and he is definitely not under-powered anymore.Thor in unleashed in this, I love that.
? ? ? ? 1. 將文本轉換為字符
????????Python的list函數接受一個字符串并將其轉換為單個字符的列表。這樣做就將文本轉換為了字符。下面是使用的代碼和結果:
thor review="the action scenes were top notch in this movie.
Thor hasnever been this epic in the McU.
He does some pretty epic sh*t in thismovie and
he is definitely not under-powered anymore.
Thor in unleashed inthis,I love that."
Print(list(thor_review))? ? ? ? 以下是結果:

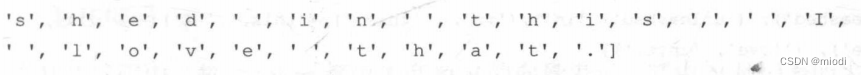
????????結果展示了簡單的 Python 函數如何將文本轉換為token。
? ? ? ? 2. 將文本轉換為詞
????????我們將使用 Python 字符串對象函數中的 split 函數將文本分解為詞。split 函數接受一個參數,并根據該參數將文本拆分為 token。在我們的示例中將使用空格作為分隔符。以下代碼段演示了如何使用 Python 的 split 函數將文本轉換為詞:
print(Thor_review.split())
????????在前面的代碼中,我們沒有使用任何的分隔符,默認情況下,split 函數使用空格來分隔。
? ? ? ? 3. n-gram表示法
????????我們已經看到文本是如何表示為字符和詞的。有時一起查看兩個、三個或更多的單詞非常有用。n-gram是從給定文本中提取的一組詞。在n-gram中,n表示可以一起使用的詞的數量。看一下bigram(當n=2時)的例子,我們使用 Python 的 nltk 包為 thor_review 生成一個 bigram ,以下代碼塊顯示了 bigram 的結果以及用于生成它的代碼:
from nltk import ngrams
print(list(ngrams(thor_review.split(),2)))

????????ngrams 函數接受一個詞序列作為第一個參數,并將組中詞的個數作為第二個參數。以下代碼塊顯示了 trigram 表示的結果以及用于實現它的代碼:
print(list(ngrams(thor_review.split(),3)))
? ? ? ? 在上述代碼中唯一改變的只有函數的第二個參數n的值。
????????許多有監督的機器學習模型,例如樸素貝葉斯(NaiveBayes),都是使用n-gram來改善它的特征空間。n-gram同樣也可用于拼寫校正和文本摘要的任務。
????????n-gram 表示法的一個問題在于它失去了文本的順序性。通常它是和淺層機器學習模型一起使用的。這種技術很少用于深度學習,因為 RNN 和 Conv1D 等架構會自動學習這些表示法。
6.1.2 向量化
????????將生成的 token 映射到數字向量有兩種流行的方法,稱為獨熱編碼和詞向(wordembedding,也稱之為詞嵌入)。讓我們通過編寫一個簡單的Python 程序來理解如何將 token 轉換為這些向量表示。我們還將討論每種方法的各種優缺點。
? ? ? ? 1. 獨熱編碼
????????在獨熱編碼中,每個 token 都由長度為N的向量表示,其中N是詞表的大小。詞表是文檔中唯一詞的總數。讓我們用一個簡單的句子來觀察每個 token 是如何表示為獨熱編碼的向量的。下面是句子及其相關的 token 表示:
?????????An apple a day keeps doctor away said the doctor.
?? ? ? 上面句子的獨熱編碼可以用表格形式進行表示,如下所示。
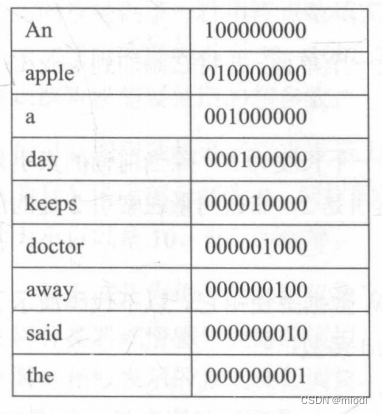
????????該表描述了 token 及其獨熱編碼的表示。因為句子中有9個唯一的單詞,所以這里的向量長度為9。許多機器學習庫已經簡化了創建獨熱編碼變量的過程。我們將編寫自己的代碼來實現這個過程以便更易于理解,并且我們可以使用相同的實現來構建后續示例所需的其他功能。以下代碼包含 Dictionary類,這個類包含了創建唯一詞詞表的功能,以及為特定詞返回其獨熱編碼向量的函數。讓我們來看代碼,然后詳解每個功能:
class Dictionary(object):def _init_(self):self.word2idx={}self.idx2word =[]self.length=0def add_word(self, word):if word not in self.idx2word:self.idx2word.append(word)self.word2idx[word]=self.length + 1self.length +=1return self.word2idx[word]def _len_(self):return len(self.idx2word)def onehot_encoded(self,word):vec =np.zeros(self.length)vec[self.word2idx[word]] = 1return vec? ? ? ? 上述代碼提供了3個功能。
- 初始化函數_init_創建一個 word2idx?字典,它將所有唯一詞與索引一起存儲。idx2word 列表存儲的是所有唯一詞,而 length 變量則是文檔中唯一詞的總數。
- 在詞是唯一的前提下,add_word 函數接受一個單詞,并將它添加到 word2idx 和 idx2word 中,同時增加詞表的長度。
- onehot_encoded函數接受一個詞并返回一個長度為N,除當前詞的索引外其余位置全為0的向量。比如傳如的單詞的索引是2,那么向量在索引2處的值是1,其他索引處的值全為0。
????????在定義好了 Dictionary 類后,準備在 thor_review 數據上使用它。以下代碼演示了如何構建 word2idx 以及如何調用 onehot_encoded 函數:
die = Dictionary()
for tok in thor_review.split():dic.add_word(tok)
print(dic.word2idx)? ? ? ? 上述代碼的輸出如下:

????????單詞were的獨熱編碼如下所示:


????????獨熱表示的問題之一就是數據太稀疏了,并且隨著詞表中唯一詞數量的增加,向量的大小迅速增加,這也是它的一種限制,因此獨熱很少在深度學習中使用。
? ? ? ? 2. 詞向量
????????詞向量是在深度學習算法所解決的問題中,一種非常流行的用于表示文本數據的方式。詞向量提供了一種用浮點數填充的詞的密集表示。向量的維度根據詞表的大小而變化。通常使用維度大小為50、100、256、300,有時為 1000 的詞向量。這里的維度大小是在訓練階段需要使用的超參數。
????????如果試圖用獨熱表示法來表示大小為 20000 的詞表,那么將得到 20000 x 20000 個數字,并且其中大部分都為0。同樣的詞表可以用詞向量表示為 20000 x 維度大小,其中維度的大小可以是 10、50、300等。
????????一種方法是為每個包含隨機數字的 token 從密集向量開始創建詞向量,然后訓練諸如文檔分類器或情感分類器的模型。表示 token 的浮點數以一種可以使語義上更接近的單詞具有相似表示的方式進行調整。為了理解這一點,我們來看看圖6.2,它畫出了基于 5 部電影的二維點圖的詞向量。

????????圖6.2顯示了如何調整密集向量,以使其在語義上相似的單詞具有較小的距離。由于Superman、Thor 和 Batman 等電影都是基于漫畫的動作電影,所以這些電影的向量更為接近,而電影 Titanic 的向量離動作電影較遠,離電影Notebook 更近,因為它們都是浪漫型電影。
????????在數據太少時學習詞向量可能是行不通的,在這種情況下,可以使用由其他機器學習算法訓練好的詞向量。由另一個任務生成的向量稱為預訓練詞向量。下面將學習如何構建自己的詞向量以及使用預訓練詞向量。







)
)


)







