自從 ChatGPT 橫空出世以來,自然語言處理(Natural Language Processing,NLP) 研究領域就出現了一種消極的聲音,認為大模型技術導致 NLP “死了”。在某乎上就有一條熱門問答,大家熱烈地討論了這個問題。

有人認為 NLP 的市場肯定有,但 NLP 的研究會遇到麻煩,因為大模型的訓練建立在海量數據與超高算力之上,普通研究者難以獲取這樣的資源,只能做些應用研究;也有人認為大模型為 NLP 打開了一片新天地,NLP 的研究整體上會再上一個新臺階。
看看專家們怎么說,上海交通大學 ACM 班創辦人俞勇教授等幾位 AI 學界大咖認為,不了解過去,就無法理解當下。NLP 技術的發展歷經了幾十年,期間經歷了多次重大技術革新,如果我們的討論脫離歷史發展,那是沒有意義的。
所以俞勇教授等大佬們決心為 NLP 技術編寫一本在歷史和現代之間更加平衡的教科書——《動手學自然語言處理》,這本書將為我們講透 NLP 的經典技術,梳理整個領域的發展脈絡,啟發我們思考 NLP 的未來。

購買鏈接:https://item.jd.com/14544280.html
本書介紹自然語言處理的原理和方法及其代碼實現,是一本著眼于自然語言處理教學實踐的圖書。
本書分為3個部分。第一部分介紹基礎技術,包括文本規范化、文本表示、文本分類、文本聚類。第二部分介紹自然語言的序列建模,包括語言模型、序列到序列模型、預訓練語言模型、序列標注。第三部分介紹自然語言的結構建模,包括成分句法分析、依存句法分析、語義分析、篇章分析。本書將自然語言處理的理論與實踐相結合,提供所介紹方法的代碼示例,能夠幫助讀者掌握理論知識并進行動手實踐。
本書適合作為高校自然語言處理課程的教材,也可作為相關行業的研究人員和開發人員的參考資料。

本書將 NLP 的知識分為三部分,分別是基礎、序列、結構。
第一步:基礎
從最基礎的自然語言處理技術入手,講解了文本規范化、文本表示、文本分類和文本聚類等內容。通過學習這些基礎知識,讀者可以了解如何將文本轉化為計算機可以理解和處理的形式,以及如何對文本進行分類和聚類,為后續的學習打下堅實的基礎。
第二步:序列
書中深入探討了自然語言的序列建模技術,包括語言模型、序列到序列模型、預訓練語言模型和序列標注等內容。
通過學習這些內容,讀者將了解對文本序列進行概率建模的方法。書中還介紹了預訓練語言模型將語言模型和序列到序列模型在大量數據上進行預訓練,獲取通用語言學知識的過程。
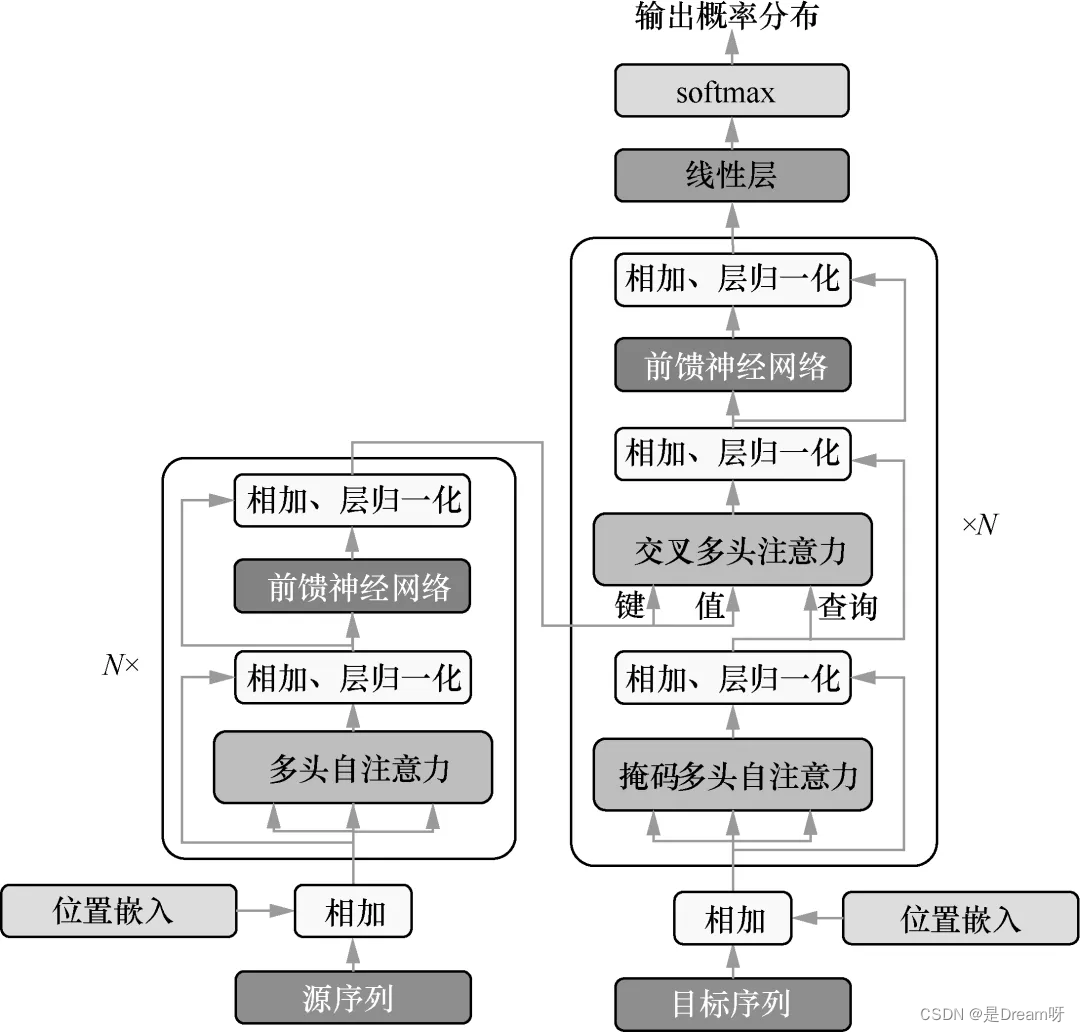
這部分內容是本書的重點,涵蓋了當前應用最廣泛的自然語言處理技術。讀者可以學習到構成大模型的基礎技術,包括循環神經網絡、注意力機制、Transformer 模型。書中對這些知識點給出了詳盡的代碼說明,幫助讀者全盤消化掌握。
第三步:結構
書中探討了自然語言文字序列背后更為復雜的結構,包括句法結構、語義結構和篇章結構等內容。
學習這些知識,讀者可以了解句子中詞語之間的連接關系、文本表達含義的結構化表示,以及多個句子如何組合形成段落和文章,從而更深入地理解和應用自然語言處理技術。
這部分內容曾經是自然語言處理的主流技術,也很有可能是未來自然語言處理的重要發展方向,讀者可以在這里探索將來的發展機會。
把這三步走好,讀者就摸透了 NLP 技術,可以在工作中大顯身手了。
NLP 的研究方法也許會改變,但是 NLP 的應用市場會更加廣闊。學習 NLP 不僅要追蹤熱門技術,也要透徹了解 NLP 發展的來龍去脈,《動手學自然語言處理》就可以很好地幫助讀者通盤掌握 NLP。
本書最大的特色就是理論與實踐緊密結合,提供了大量的配套學習資源。我們來看一下究竟可以獲得哪些資源:紙書 + 可以掃碼觀看的理論視頻課 + 配套課件方便教學 + 課后習題 + 配套代碼(可在線運行也可離線運行)+ 配套代碼實戰課 + 針對高校教師的師資培訓計劃。
這幾乎就是背靠一個強大的后勤軍團,讀者根本不用擔心學習中會遇到困難,只要將這些資源善加利用,定能啃透 NLP 技術。
如書名中的“動手學”所示,本書給讀者提供了極其便利的學習環境,每一章都由一個 Python Notebook 組成, Notebook 中包括概念定義、理論分析、方法講解和可執行代碼。讀者可根據自己的需要學習理論,或者動手實踐。

本書深度整合了自然語言處理的理論精髓與實戰智慧,內容講解深入淺出、代碼實例豐富易學,為培養自然語言處理領域的實戰型人才提供了堅實的理論基石與豐富的實戰資源,是渴望學習自然語言處理的讀者必備的入門寶典。
——文繼榮 中國人民大學高瓴人工智能學院執行院長、信息學院院長
在智能化浪潮下,懂技術、知應用的實戰型人工智能人才的重要性日益凸顯。本書以深入淺出的理論講解為基礎,輔以清晰明了的代碼解析,幫助讀者將自然語言處理的理論與實戰融會貫通,值得廣大讀者深度研讀。
——周明 瀾舟科技創始人,ACL 原主席,CCF 原副理事長,微軟亞洲研究院原副院長
學習自然語言處理需要將理論與實戰相結合。本書憑借其詳盡的理論闡述、可運行的代碼實例以及配套的習題與教學資源,構建了一座連接理論與實戰的橋梁。無論是新手還是老手,均可使用本書深化對自然語言處理的理解并提升實戰能力。
——邱錫鵬 復旦大學計算機科學技術學院教授
本書具有兩大亮點。一是以序列和結構為主線來組織自然語言處理的關鍵技術。序列、結構和語義是語言文字的3個重要屬性,語言文字是離散符號的序列,文本又由帶有語義信息的結構組成。二是以指導動手實戰為目標,每個章節均提供可執行代碼,并加以解讀。本書非常適合作為自然語言處理領域的高校教材,也適合作為工程師的常備工具書。
——李磊 卡內基梅隆大學計算機科學學院助理教授
本書作為一本全面且系統的自然語言處理教材,深入淺出地講解了自然語言處理的基本概念和關鍵方法,無論是學生還是行業人士,都能夠通過本書有效掌握自然語言處理的知識體系并進行動手實戰。
——楊笛一 斯坦福大學計算機科學系助理教授
第 1章 初探自然語言處理 1
1.1 自然語言處理是什么 1
1.2 自然語言處理的應用 2
1.3 自然語言處理的難點 3
1.4 自然語言處理的方法論 4
1.5 小結 5
第 一部分 基礎
第 2章 文本規范化 8
2.1 分詞 8
2.1.1 基于空格與標點符號的分詞 8
2.1.2 基于正則表達式的分詞 9
2.1.3 詞間不含空格的語言的分詞 12
2.1.4 基于子詞的分詞 13
2.2 詞規范化 17
2.2.1 大小寫折疊 17
2.2.2 詞目還原 18
2.2.3 詞干還原 19
2.3 分句 19
2.4 小結 20
第3章 文本表示 22
3.1 詞的表示 22
3.2 稀疏向量表示 24
3.3 稠密向量表示 25
3.3.1 word2vec 25
3.3.2 上下文相關詞嵌入 30
3.4 文檔表示 30
3.4.1 詞-文檔共現矩陣 31
3.4.2 TF-IDF加權 31
3.4.3 文檔的稠密向量表示 33
3.5 小結 33
第4章 文本分類 35
4.1 基于規則的文本分類 35
4.2 基于機器學習的文本分類 36
4.2.1 樸素貝葉斯 36
4.2.2 邏輯斯諦回歸 42
4.3 分類結果評價 45
4.4 小結 47
第5章 文本聚類 49
5.1 k均值聚類算法 49
5.2 基于高斯混合模型的最大期望值算法 53
5.2.1 高斯混合模型 53
5.2.2 最大期望值算法 53
5.3 無監督樸素貝葉斯模型 57
5.4 主題模型 60
5.5 小結 61
第二部分 序列
第6章 語言模型 64
6.1 概述 64
6.2 n元語法模型 66
6.3 循環神經網絡 67
6.3.1 循環神經網絡 67
6.3.2 長短期記憶 73
6.3.3 多層雙向循環神經網絡 76
6.4 注意力機制 80
多頭注意力 83
6.5 Transformer模型 85
6.6 小結 91
第7章 序列到序列模型 93
7.1 基于神經網絡的序列到序列模型 93
7.1.1 循環神經網絡 94
7.1.2 注意力機制 96
7.1.3 Transformer 98
7.2 學習 101
7.3 解碼 106
7.3.1 貪心解碼 106
7.3.2 束搜索解碼 107
7.3.3 其他解碼問題與解決技巧 110
7.4 指針網絡 111
7.5 序列到序列任務的延伸 112
7.6 小結 113
第8章 預訓練語言模型 114
8.1 ELMo:基于語言模型的上下文相關詞嵌入 114
8.2 BERT:基于Transformer的雙向編碼器表示 115
8.2.1 掩碼語言模型 115
8.2.2 BERT模型 116
8.2.3 預訓練 116
8.2.4 微調與提示 117
8.2.5 BERT代碼演示 117
8.2.6 BERT模型擴展 121
8.3 GPT:基于Transformer的生成式預訓練語言模型 122
8.3.1 GPT模型的歷史 122
8.3.2 GPT-2訓練演示 123
8.3.3 GPT的使用 125
8.4 基于編碼器-解碼器的預訓練語言模型 128
8.5 基于HuggingFace的預訓練語言模型使用 129
8.5.1 文本分類 129
8.5.2 文本生成 130
8.5.3 問答 130
8.5.4 文本摘要 131
8.6 小結 131
第9章 序列標注 133
9.1 序列標注任務 133
9.1.1 詞性標注 133
9.1.2 中文分詞 134
9.1.3 命名實體識別 134
9.1.4 語義角色標注 135
9.2 隱馬爾可夫模型 135
9.2.1 模型 135
9.2.2 解碼 136
9.2.3 輸入序列的邊際概率 137
9.2.4 單個標簽的邊際概率 138
9.2.5 監督學習 139
9.2.6 無監督學習 139
9.2.7 部分代碼實現 141
9.3 條件隨機場 146
9.3.1 模型 146
9.3.2 解碼 147
9.3.3 監督學習 148
9.3.4 無監督學習 149
9.3.5 部分代碼實現 149
9.4 神經序列標注模型 154
9.4.1 神經softmax 154
9.4.2 神經條件隨機場 154
9.4.3 代碼實現 155
9.5 小結 156
第三部分 結構
第 10章 成分句法分析 160
10.1 成分結構 160
10.2 成分句法分析概述 161
10.2.1 歧義性與打分 161
10.2.2 解碼 162
10.2.3 學習 162
10.2.4 評價指標 163
10.3 基于跨度的成分句法分析 163
10.3.1 打分 164
10.3.2 解碼 165
10.3.3 學習 170
10.4 基于轉移的成分句法分析 173
10.4.1 狀態與轉移 173
10.4.2 轉移的打分 174
10.4.3 解碼 175
10.4.4 學習 176
10.5 基于上下文無關文法的成分句法分析 177
10.5.1 上下文無關文法 177
10.5.2 解碼和學習 178
10.6 小結 179
第 11章 依存句法分析 181
11.1 依存結構 181
11.1.1 投射性 182
11.1.2 與成分結構的關系 182
11.2 依存句法分析概述 184
11.2.1 打分、解碼和學習 184
11.2.2 評價指標 184
11.3 基于圖的依存句法分析 185
11.3.1 打分 185
11.3.2 解碼 186
11.3.3 Eisner算法 186
11.3.4 MST算法 191
11.3.5 高階方法 194
11.3.6 監督學習 194
11.4 基于轉移的依存句法分析 195
11.4.1 狀態與轉移 196
11.4.2 打分、解碼與學習 196
11.5 小結 198
第 12章 語義分析 200
12.1 顯式和隱式的語義表示 200
12.2 詞義表示 201
12.2.1 WordNet 201
12.2.2 詞義消歧 203
12.3 語義表示 204
12.3.1 專用和通用的語義表示 204
12.3.2 一階邏輯 205
12.3.3 語義圖 205
12.4 語義分析 206
12.4.1 基于句法的語義分析 206
12.4.2 基于神經網絡的語義分析 207
12.4.3 弱監督學習 209
12.5 語義角色標注 209
12.5.1 語義角色標注標準 209
12.5.2 語義角色標注方法 211
12.6 信息提取 211
12.7 小結 212
第 13章 篇章分析 213
13.1 篇章 213
13.1.1 連貫性關系 213
13.1.2 篇章結構 214
13.1.3 篇章分析 215
13.2 共指消解 215
13.2.1 提及檢測 216
13.2.2 提及聚類 216
13.3 小結 220
總結與展望 221
參考文獻 223
中英文術語對照表 228
附 錄 234







 | (WSDM24)預訓練推薦系統:因果去偏視角)






)




