利用 Swifter 加速 Pandas 操作的詳細教程
引言
Pandas 是數據分析中常用的庫,但在處理大型數據集時效率可能會較低。Swifter 提供了一種簡便的方法,通過并行處理來顯著加速 Pandas 操作。
Swifter 簡介
Swifter 是一個開源庫,旨在自動優化和加速 Pandas 的 apply 操作。它會根據數據規模和復雜度選擇最優的并行處理方式,大大提高數據處理速度。
安裝 Swifter
首先,使用 pip 安裝 Swifter:
pip install swifter
基本用法
以下是如何使用 Swifter 加速 Pandas 操作的基本示例:
import pandas as pd
import swifter# 創建一個示例數據幀
df = pd.DataFrame({'a': range(1, 1000001),'b': range(1000000, 0, -1)
})# 使用 Swifter 加速 apply 操作
df['c'] = df.swifter.apply(lambda x: x['a'] + x['b'], axis=1)
在上述示例中,Swifter 自動選擇最優的并行處理方式,加速了 apply 操作。
詳細示例
假設我們有一個復雜的函數需要應用于數據幀的每一行:
import numpy as np# 定義一個復雜的函數
def complex_function(row):return np.log(row['a']**2 + row['b']**2)# 使用 Swifter 加速復雜函數的應用
df['d'] = df.swifter.apply(complex_function, axis=1)
進階用法
Swifter 還支持 Pandas 的 applymap 和 agg 操作:
# 使用 Swifter 加速 applymap 操作
df = df.swifter.applymap(lambda x: x**2)# 使用 Swifter 加速 groupby 和 agg 操作
df_grouped = df.groupby('a').swifter.agg({'b': 'sum'})
性能對比
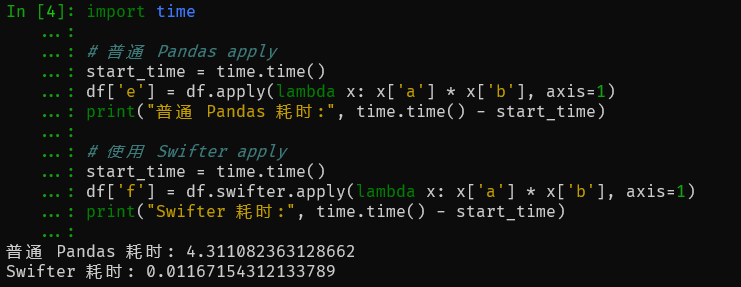
為了更直觀地展示 Swifter 的性能提升,我們可以比較普通 Pandas 和 Swifter 的執行時間:
import time# 普通 Pandas apply
start_time = time.time()
df['e'] = df.apply(lambda x: x['a'] * x['b'], axis=1)
print("普通 Pandas 耗時:", time.time() - start_time)# 使用 Swifter apply
start_time = time.time()
df['f'] = df.swifter.apply(lambda x: x['a'] * x['b'], axis=1)
print("Swifter 耗時:", time.time() - start_time)
注意事項
- Swifter 對小數據集可能不會顯著提高速度,甚至可能略慢于普通 Pandas 操作。
- 確保函數是可并行化的,避免使用全局狀態或不可重入的代碼。
結論
Swifter 是一個簡單而強大的工具,可以大幅提升 Pandas 在大規模數據集上的處理速度。通過自動選擇并行處理方式,Swifter 能夠在大多數情況下顯著加速 Pandas 的 apply、applymap 和 agg 操作。
更多信息和詳細文檔,請訪問 Swifter GitHub 頁面。












)





)
