一、訓練誤差與泛華誤差
1、在訓練時,我們關心的是泛化誤差,也就是對新數據的預測
2、訓練誤差:模型在訓練數據上的誤差;泛化誤差:模型在新數據上的誤差
二、驗證數據集與測試數據集
1、驗證數據集:用于評估模型好壞的數據集,就像模擬考試
2、測試數據集:只用一次,就像正式考試
3、訓練數據集:訓練模型參數;對于訓練數據集,我們會拿出一部分作為驗證數據集,訓練數據就像平時進行刷題
4、在實際中使用的測試數據集,其實來源于我們的驗證數據集,所以驗證數據集上得出來的超參數可能會在泛化誤差之中虛高
三、K折交叉驗證

1、沒有足夠多的數據時指無論什么情況下,訓練數據都是越多越好。
2、對于k折,數據量大時可以將k取更小的值,數據量小時則反之
3、K折交叉驗證誤差做平均是為了超參數的選擇
四、總結

五、過擬合與欠擬合
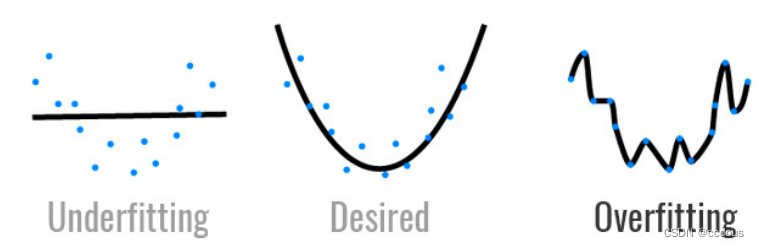
1、模型容量:擬合各種函數的能力,可以理解為模型的復雜程度,低就是簡單模型,高就是復雜模型。復雜模型可以使用復雜函數,簡單模型就不太行;比如線性模型就簡單,多層感知機就比較復雜。
2、簡單數據與復雜數據,簡單數據比如人工數據集

3、簡單數據高模型容量可能過擬合,就相當于模型將數據全部記下來了,包括很多噪音,對新數據沒有泛化性;復雜數據使用簡單模型應該會欠擬合,就是字面意思。
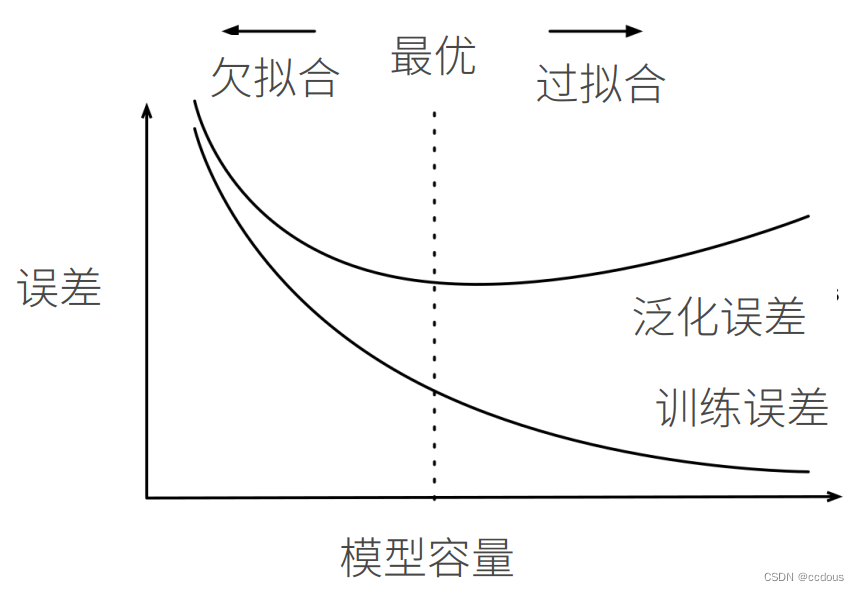
4、估計模型容量
(1)模型容量在不同種類的算法之間難以比較,比如樹模型與神經網絡之間的差別非常大
(2)給定模型種類,有兩個因素估計模型容量:參數個數與參數選擇范圍
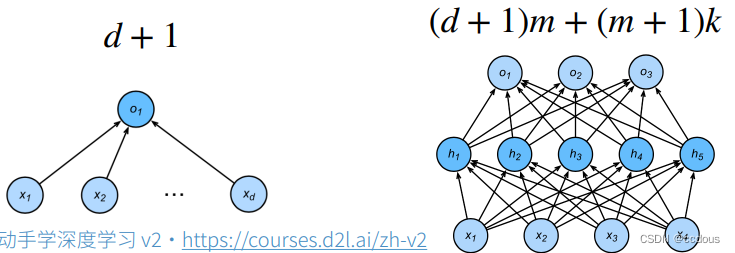
對于上圖線性回歸,輸入為d維向量,自然就有d個權重w,參數就是d個w和一個偏差d;
對于有一層隱藏層的感知機,其中這一層輸出位m維向量,最終輸出層向量為k,按照線性模型反推,輸入->隱藏層(d+1)*m,隱藏層->輸出層(m+1)*k
(3)VC維:VC維度定義了在假設空間中能夠被模型擬合的樣本點的最大數量,例如二維空間的vc維是3,在多1個點,比如四個點就陷入了XOR問題,這里知道大概概念就好了。

支持N維輸入的感知機的VC維是N+1;
一些多層感知機的VC維O(Nlog2N)

5、數據復雜度
(1)數據復雜度是一個相對概念,多樣性指分為幾類,比如softmax輸出分成了許多類
(2)多個重要因素

6、總結

六、多項式生成數據集
、
max_degree = 20 # 多項式的最大階數,除了前面四個其他都是屬于噪音 n_train, n_test = 100, 100 # 訓練和測試數據集大小 true_w = np.zeros(max_degree) # 分配大量的空間 true_w[0:4] = np.array([5, 1.2, -3.4, 5.6]) #總計為200的訓練和測試集 features = np.random.normal(size=(n_train + n_test, 1)) np.random.shuffle(features) #生成了200個,多項式的樣本相當于200*20 poly_features = np.power(features, np.arange(max_degree).reshape(1, -1)) #相當于除以階乘 for i in range(max_degree):poly_features[:, i] /= math.gamma(i + 1) # gamma(n)=(n-1)! # labels的維度:(n_train+n_test,) labels = np.dot(poly_features, true_w) #添加噪聲 labels += np.random.normal(scale=0.1, size=labels.shape)
七、模型進行訓練和測試
1、評估模型在給定數據集上的損失的函數
def evaluate_loss(net, data_iter, loss): ...#跟之前的一樣 return metric[0]/metric[1]
2、定義訓練函數
train(train_features, test_features, train_labels, test_labels,num_epochs=400): 略,跟之前的一樣
3、三階多項式函數擬合(正常)
# 從多項式特征中選擇前4個維度,即1,x,x^2/2!,x^3/3! train(poly_features[:n_train, :4], poly_features[n_train:, :4],labels[:n_train], labels[n_train:])
4、線性函數擬合(欠擬合)
# 從多項式特征中選擇前2個維度,即1和x train(poly_features[:n_train, :2], poly_features[n_train:, :2],labels[:n_train], labels[n_train:])
5、高階多項式函數擬合(過擬合)
# 從多項式特征中選取所有維度 train(poly_features[:n_train, :], poly_features[n_train:, :],labels[:n_train], labels[n_train:], num_epochs=1500)
6、總結
-
欠擬合是指模型無法繼續減少訓練誤差。過擬合是指訓練誤差遠小于驗證誤差。
-
由于不能基于訓練誤差來估計泛化誤差,因此簡單地最小化訓練誤差并不一定意味著泛化誤差的減小。機器學習模型需要注意防止過擬合,即防止泛化誤差過大。
-
驗證集可以用于模型選擇,但不能過于隨意地使用它。
-
我們應該選擇一個復雜度適當的模型,避免使用數量不足的訓練樣本。
)

)









- 多元線性回歸)


注解)



